 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GPT-4 Understands Discourse at Least as Well as Humans Do
Mar 25, 2024
We test whether a leading AI system GPT-4 understands discourse as well as humans do, using a standardized test of discourse comprehension. Participants are presented with brief stories and then answer eight yes/no questions probing their comprehension of the story. The questions are formatted to assess the separate impacts of directness (stated vs. implied) and salience (main idea vs. details). GPT-4 performs slightly, but not statistically significantly, better than humans given the very high level of human performance. Both GPT-4 and humans exhibit a strong ability to make inferences about information that is not explicitly stated in a story, a critical test of understanding.
ROXIE: Defining a Robotic eXplanation and Interpretability Engine
Mar 25, 2024In an era where autonomous robots increasingly inhabit public spaces, the imperative for transparency and interpretability in their decision-making processes becomes paramount. This paper presents the overview of a Robotic eXplanation and Interpretability Engine (ROXIE), which addresses this critical need, aiming to demystify the opaque nature of complex robotic behaviors. This paper elucidates the key features and requirements needed for providing information and explanations about robot decision-making processes. It also overviews the suite of software components and libraries available for deployment with ROS 2, empowering users to provide comprehensive explanations and interpretations of robot processes and behaviors, thereby fostering trust and collaboration in human-robot interactions.
Tensor-based Graph Learning with Consistency and Specificity for Multi-view Clustering
Mar 27, 2024Graph learning is widely recognized as a crucial technique in multi-view clustering. Existing graph learning methods typically involve constructing an adaptive neighbor graph based on probabilistic neighbors and then learning a consensus graph to for clustering, however, they are confronted with two limitations. Firstly, they often rely on Euclidean distance to measure similarity when constructing the adaptive neighbor graph, which proves inadequate in capturing the intrinsic structure among data points in many real-world scenarios. Secondly, most of these methods focus solely on consensus graph, ignoring view-specific graph information. In response to the aforementioned drawbacks, we in this paper propose a novel tensor-based graph learning framework that simultaneously considers consistency and specificity for multi-view clustering. Specifically, we calculate the similarity distance on the Stiefel manifold to preserve the intrinsic structure among data points. By making an assumption that the learned neighbor graph of each view comprises both a consistent graph and a view-specific graph, we formulate a new tensor-based target graph learning paradigm. Owing to the benefits of tensor singular value decomposition (t-SVD) in uncovering high-order correlations, this model is capable of achieving a complete understanding of the target graph. Furthermore, we develop an iterative algorithm to solve the proposed objective optimization problem. Experiments conducted on real-world datasets have demonstrated the superior performance of the proposed method over some state-of-the-art multi-view clustering methods. The source code has been released on https://github.com/lshi91/CSTGL-Code.
DELTA: Pre-train a Discriminative Encoder for Legal Case Retrieval via Structural Word Alignment
Mar 27, 2024Recent research demonstrates the effectiveness of using pre-trained language models for legal case retrieval. Most of the existing works focus on improving the representation ability for the contextualized embedding of the [CLS] token and calculate relevance using textual semantic similarity. However, in the legal domain, textual semantic similarity does not always imply that the cases are relevant enough. Instead, relevance in legal cases primarily depends on the similarity of key facts that impact the final judgment. Without proper treatments, the discriminative ability of learned representations could be limited since legal cases are lengthy and contain numerous non-key facts. To this end, we introduce DELTA, a discriminative model designed for legal case retrieval. The basic idea involves pinpointing key facts in legal cases and pulling the contextualized embedding of the [CLS] token closer to the key facts while pushing away from the non-key facts, which can warm up the case embedding space in an unsupervised manner. To be specific, this study brings the word alignment mechanism to the contextual masked auto-encoder. First, we leverage shallow decoders to create information bottlenecks, aiming to enhance the representation ability. Second, we employ the deep decoder to enable translation between different structures, with the goal of pinpointing key facts to enhance discriminative ability. Comprehensive experiments conducted on publicly available legal benchmarks show that our approach can outperform existing state-of-the-art methods in legal case retrieval. It provides a new perspective on the in-depth understanding and processing of legal case documents.
MonoHair: High-Fidelity Hair Modeling from a Monocular Video
Mar 27, 2024Undoubtedly, high-fidelity 3D hair is crucial for achieving realism, artistic expression, and immersion in computer graphics. While existing 3D hair modeling methods have achieved impressive performance, the challenge of achieving high-quality hair reconstruction persists: they either require strict capture conditions, making practical applications difficult, or heavily rely on learned prior data, obscuring fine-grained details in images. To address these challenges, we propose MonoHair,a generic framework to achieve high-fidelity hair reconstruction from a monocular video, without specific requirements for environments. Our approach bifurcates the hair modeling process into two main stages: precise exterior reconstruction and interior structure inference. The exterior is meticulously crafted using our Patch-based Multi-View Optimization (PMVO). This method strategically collects and integrates hair information from multiple views, independent of prior data, to produce a high-fidelity exterior 3D line map. This map not only captures intricate details but also facilitates the inference of the hair's inner structure. For the interior, we employ a data-driven, multi-view 3D hair reconstruction method. This method utilizes 2D structural renderings derived from the reconstructed exterior, mirroring the synthetic 2D inputs used during training. This alignment effectively bridges the domain gap between our training data and real-world data, thereby enhancing the accuracy and reliability of our interior structure inference. Lastly, we generate a strand model and resolve the directional ambiguity by our hair growth algorithm. Our experiments demonstrate that our method exhibits robustness across diverse hairstyles and achieves state-of-the-art performance. For more results, please refer to our project page https://keyuwu-cs.github.io/MonoHair/.
Connecting the Dots: Inferring Patent Phrase Similarity with Retrieved Phrase Graphs
Mar 24, 2024We study the patent phrase similarity inference task, which measures the semantic similarity between two patent phrases. As patent documents employ legal and highly technical language, existing semantic textual similarity methods that use localized contextual information do not perform satisfactorily in inferring patent phrase similarity. To address this, we introduce a graph-augmented approach to amplify the global contextual information of the patent phrases. For each patent phrase, we construct a phrase graph that links to its focal patents and a list of patents that are either cited by or cite these focal patents. The augmented phrase embedding is then derived from combining its localized contextual embedding with its global embedding within the phrase graph. We further propose a self-supervised learning objective that capitalizes on the retrieved topology to refine both the contextualized embedding and the graph parameters in an end-to-end manner. Experimental results from a unique patent phrase similarity dataset demonstrate that our approach significantly enhances the representation of patent phrases, resulting in marked improvements in similarity inference in a self-supervised fashion. Substantial improvements are also observed in the supervised setting, underscoring the potential benefits of leveraging retrieved phrase graph augmentation.
Cross-domain Multi-modal Few-shot Object Detection via Rich Text
Mar 24, 2024Cross-modal feature extraction and integration have led to steady performance improvements in few-shot learning tasks due to generating richer features. However, existing multi-modal object detection (MM-OD) methods degrade when facing significant domain-shift and are sample insufficient. We hypothesize that rich text information could more effectively help the model to build a knowledge relationship between the vision instance and its language description and can help mitigate domain shift. Specifically, we study the Cross-Domain few-shot generalization of MM-OD (CDMM-FSOD) and propose a meta-learning based multi-modal few-shot object detection method that utilizes rich text semantic information as an auxiliary modality to achieve domain adaptation in the context of FSOD. Our proposed network contains (i) a multi-modal feature aggregation module that aligns the vision and language support feature embeddings and (ii) a rich text semantic rectify module that utilizes bidirectional text feature generation to reinforce multi-modal feature alignment and thus to enhance the model's language understanding capability. We evaluate our model on common standard cross-domain object detection datasets and demonstrate that our approach considerably outperforms existing FSOD methods.
FedNMUT -- Federated Noisy Model Update Tracking Convergence Analysis
Mar 24, 2024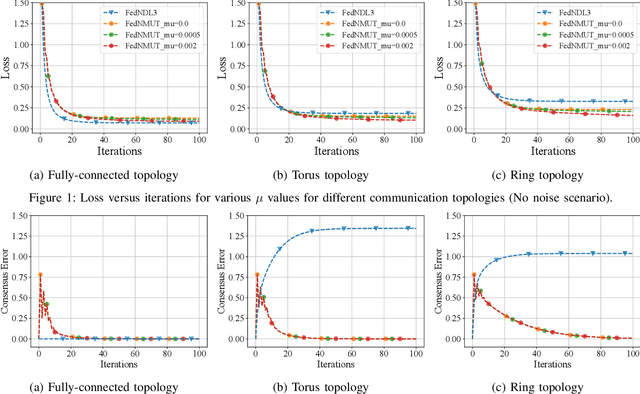
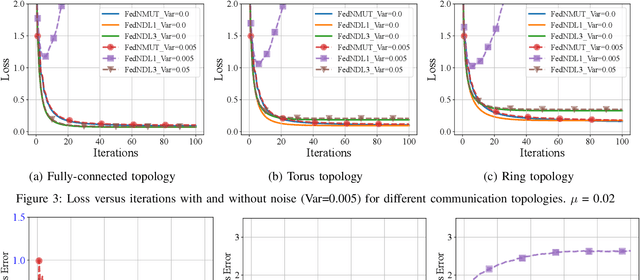
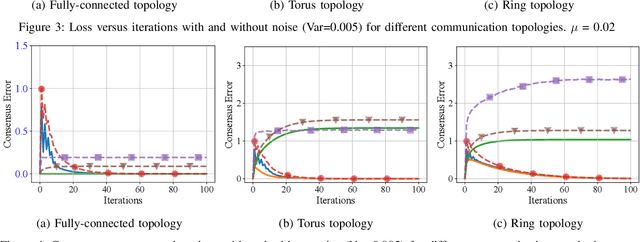
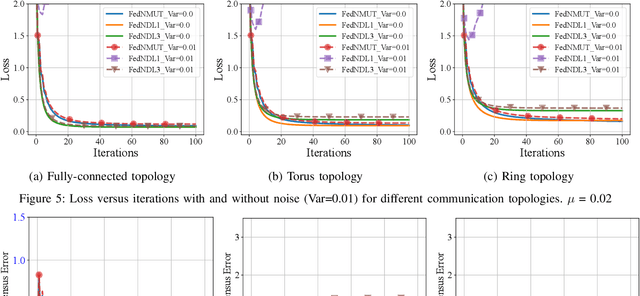
A novel Decentralized Noisy Model Update Tracking Federated Learning algorithm (FedNMUT) is proposed that is tailored to function efficiently in the presence of noisy communication channels that reflect imperfect information exchange. This algorithm uses gradient tracking to minimize the impact of data heterogeneity while minimizing communication overhead. The proposed algorithm incorporates noise into its parameters to mimic the conditions of noisy communication channels, thereby enabling consensus among clients through a communication graph topology in such challenging environments. FedNMUT prioritizes parameter sharing and noise incorporation to increase the resilience of decentralized learning systems against noisy communications. Theoretical results for the smooth non-convex objective function are provided by us, and it is shown that the $\epsilon-$stationary solution is achieved by our algorithm at the rate of $\mathcal{O}\left(\frac{1}{\sqrt{T}}\right)$, where $T$ is the total number of communication rounds. Additionally, via empirical validation, we demonstrated that the performance of FedNMUT is superior to the existing state-of-the-art methods and conventional parameter-mixing approaches in dealing with imperfect information sharing. This proves the capability of the proposed algorithm to counteract the negative effects of communication noise in a decentralized learning framework.
Enhancing Historical Image Retrieval with Compositional Cues
Mar 21, 2024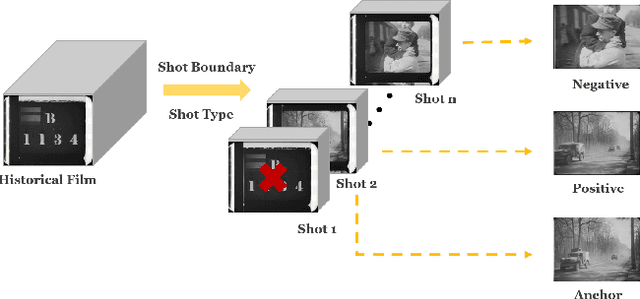

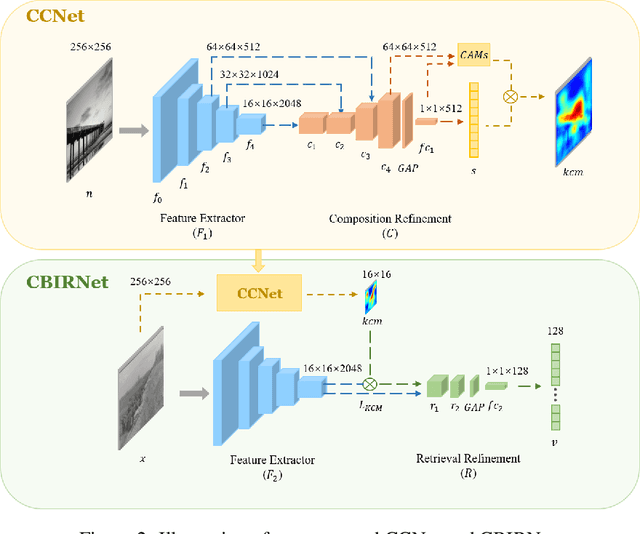
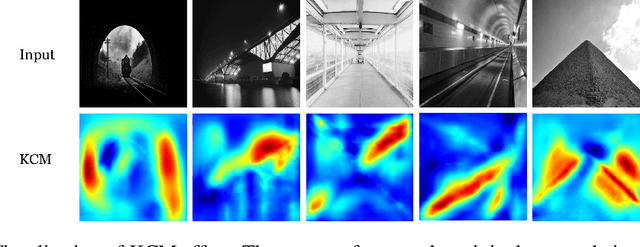
In analyzing vast amounts of digitally stored historical image data, existing content-based retrieval methods often overlook significant non-semantic information, limiting their effectiveness for flexible exploration across varied themes. To broaden the applicability of image retrieval methods for diverse purposes and uncover more general patterns, we innovatively introduce a crucial factor from computational aesthetics, namely image composition, into this topic. By explicitly integrating composition-related information extracted by CNN into the designed retrieval model, our method considers both the image's composition rules and semantic information. Qualitative and quantitative experiments demonstrate that the image retrieval network guided by composition information outperforms those relying solely on content information, facilitating the identification of images in databases closer to the target image in human perception. Please visit https://github.com/linty5/CCBIR to try our codes.
AE SemRL: Learning Semantic Association Rules with Autoencoders
Mar 26, 2024Association Rule Mining (ARM) is the task of learning associations among data features in the form of logical rules. Mining association rules from high-dimensional numerical data, for example, time series data from a large number of sensors in a smart environment, is a computationally intensive task. In this study, we propose an Autoencoder-based approach to learn and extract association rules from time series data (AE SemRL). Moreover, we argue that in the presence of semantic information related to time series data sources, semantics can facilitate learning generalizable and explainable association rules. Despite enriching time series data with additional semantic features, AE SemRL makes learning association rules from high-dimensional data feasible. Our experiments show that semantic association rules can be extracted from a latent representation created by an Autoencoder and this method has in the order of hundreds of times faster execution time than state-of-the-art ARM approaches in many scenarios. We believe that this study advances a new way of extracting associations from representations and has the potential to inspire more research in this field.