 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Unleash Model Potential: Bootstrapped Meta Self-supervised Learning
Aug 28, 2023
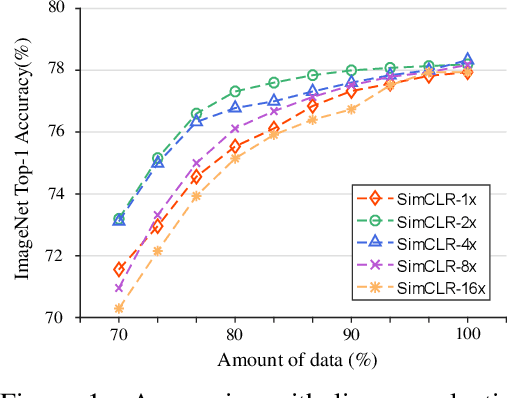
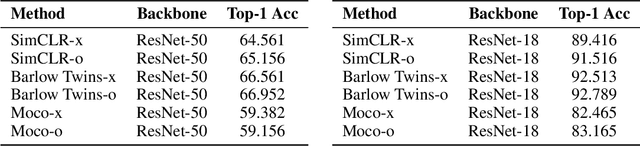
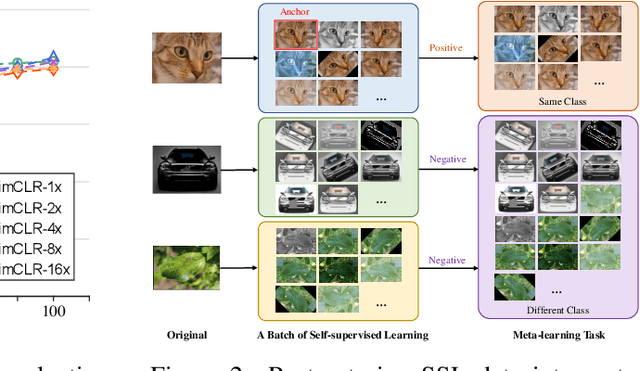
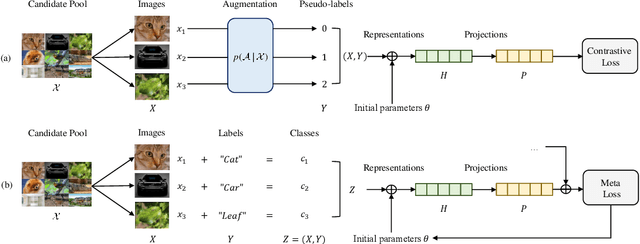
The long-term goal of machine learning is to learn general visual representations from a small amount of data without supervision, mimicking three advantages of human cognition: i) no need for labels, ii) robustness to data scarcity, and iii) learning from experience. Self-supervised learning and meta-learning are two promising techniques to achieve this goal, but they both only partially capture the advantages and fail to address all the problems. Self-supervised learning struggles to overcome the drawbacks of data scarcity, while ignoring prior knowledge that can facilitate learning and generalization. Meta-learning relies on supervised information and suffers from a bottleneck of insufficient learning. To address these issues, we propose a novel Bootstrapped Meta Self-Supervised Learning (BMSSL) framework that aims to simulate the human learning process. We first analyze the close relationship between meta-learning and self-supervised learning. Based on this insight, we reconstruct tasks to leverage the strengths of both paradigms, achieving advantages i and ii. Moreover, we employ a bi-level optimization framework that alternates between solving specific tasks with a learned ability (first level) and improving this ability (second level), attaining advantage iii. To fully harness its power, we introduce a bootstrapped target based on meta-gradient to make the model its own teacher. We validate the effectiveness of our approach with comprehensive theoretical and empirical study.
Text-to-Video: a Two-stage Framework for Zero-shot Identity-agnostic Talking-head Generation
Aug 12, 2023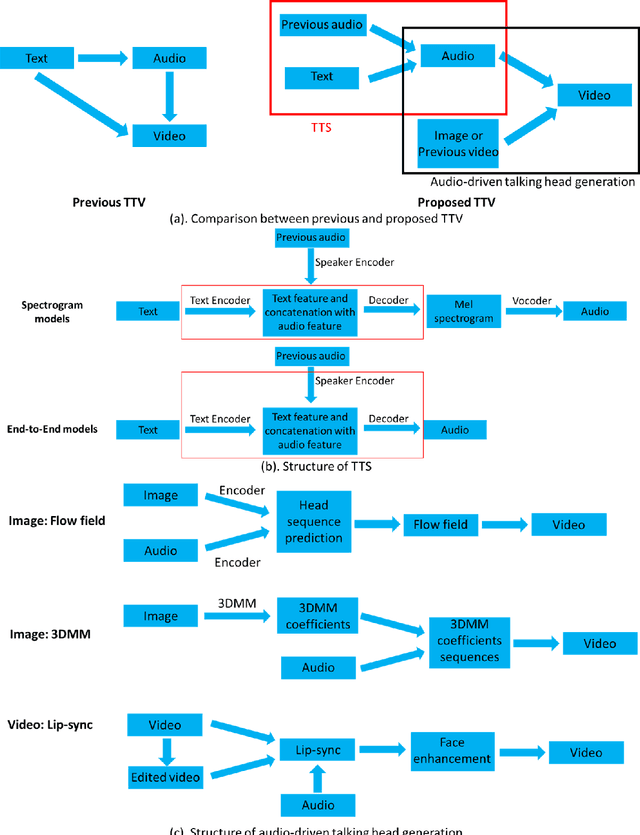

The advent of ChatGPT has introduced innovative methods for information gathering and analysis. However, the information provided by ChatGPT is limited to text, and the visualization of this information remains constrained. Previous research has explored zero-shot text-to-video (TTV) approaches to transform text into videos. However, these methods lacked control over the identity of the generated audio, i.e., not identity-agnostic, hindering their effectiveness. To address this limitation, we propose a novel two-stage framework for person-agnostic video cloning, specifically focusing on TTV generation. In the first stage, we leverage pretrained zero-shot models to achieve text-to-speech (TTS) conversion. In the second stage, an audio-driven talking head generation method is employed to produce compelling videos privided the audio generated in the first stage. This paper presents a comparative analysis of different TTS and audio-driven talking head generation methods, identifying the most promising approach for future research and development. Some audio and videos samples can be found in the following link: https://github.com/ZhichaoWang970201/Text-to-Video/tree/main.
Infomorphic networks: Locally learning neural networks derived from partial information decomposition
Jun 03, 2023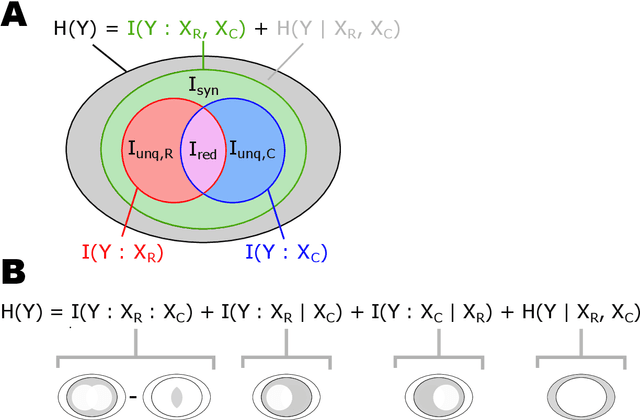
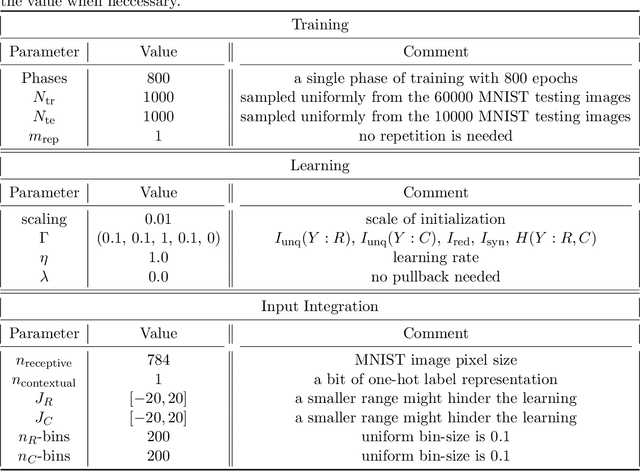
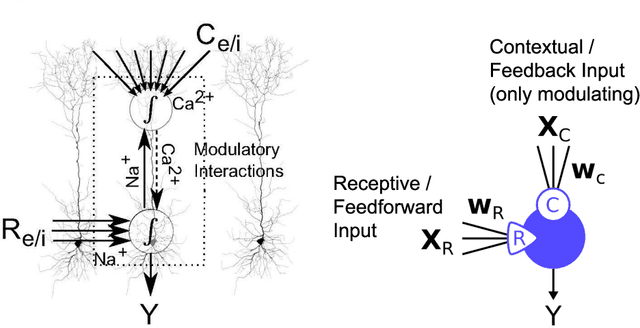
Understanding the intricate cooperation among individual neurons in performing complex tasks remains a challenge to this date. In this paper, we propose a novel type of model neuron that emulates the functional characteristics of biological neurons by optimizing an abstract local information processing goal. We have previously formulated such a goal function based on principles from partial information decomposition (PID). Here, we present a corresponding parametric local learning rule which serves as the foundation of "infomorphic networks" as a novel concrete model of neural networks. We demonstrate the versatility of these networks to perform tasks from supervised, unsupervised and memory learning. By leveraging the explanatory power and interpretable nature of the PID framework, these infomorphic networks represent a valuable tool to advance our understanding of cortical function.
Weakly supervised information extraction from inscrutable handwritten document images
Jun 12, 2023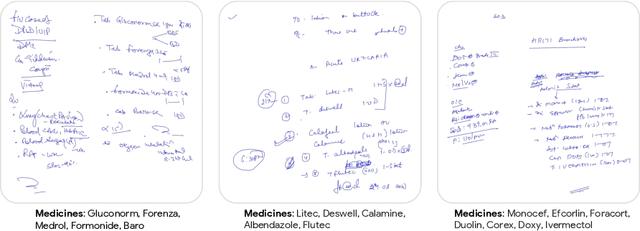

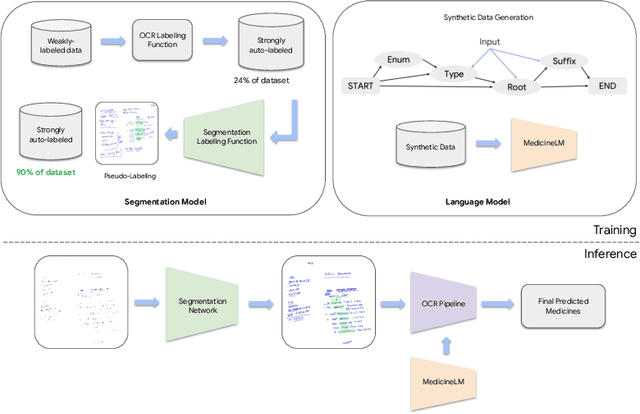
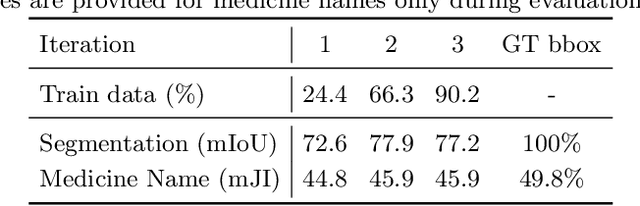
State-of-the-art information extraction methods are limited by OCR errors. They work well for printed text in form-like documents, but unstructured, handwritten documents still remain a challenge. Adapting existing models to domain-specific training data is quite expensive, because of two factors, 1) limited availability of the domain-specific documents (such as handwritten prescriptions, lab notes, etc.), and 2) annotations become even more challenging as one needs domain-specific knowledge to decode inscrutable handwritten document images. In this work, we focus on the complex problem of extracting medicine names from handwritten prescriptions using only weakly labeled data. The data consists of images along with the list of medicine names in it, but not their location in the image. We solve the problem by first identifying the regions of interest, i.e., medicine lines from just weak labels and then injecting a domain-specific medicine language model learned using only synthetically generated data. Compared to off-the-shelf state-of-the-art methods, our approach performs >2.5x better in medicine names extraction from prescriptions.
Scalability of Message Encoding Techniques for Continuous Communication Learned with Multi-Agent Reinforcement Learning
Aug 09, 2023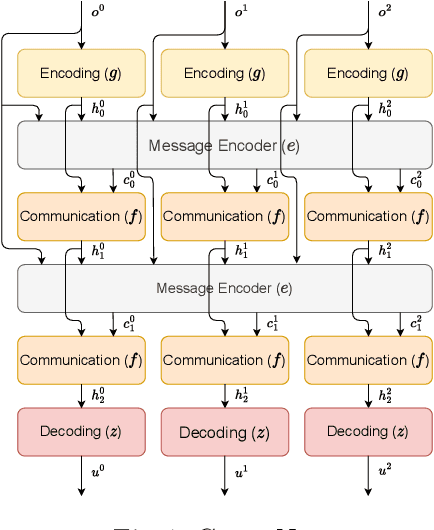
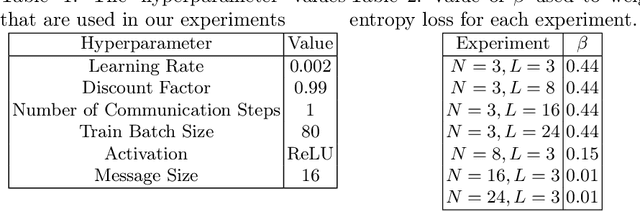
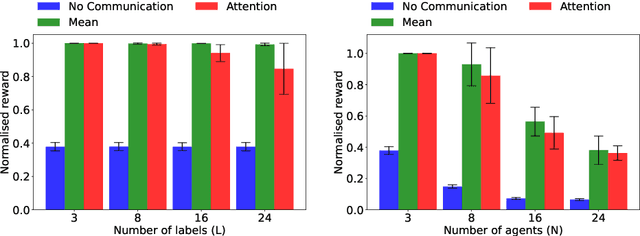
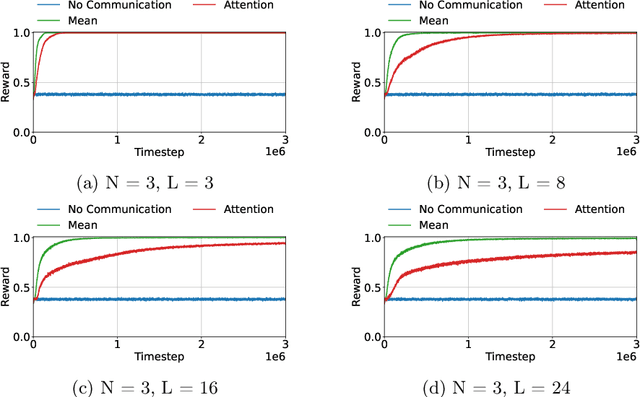
Many multi-agent systems require inter-agent communication to properly achieve their goal. By learning the communication protocol alongside the action protocol using multi-agent reinforcement learning techniques, the agents gain the flexibility to determine which information should be shared. However, when the number of agents increases we need to create an encoding of the information contained in these messages. In this paper, we investigate the effect of increasing the amount of information that should be contained in a message and increasing the number of agents. We evaluate these effects on two different message encoding methods, the mean message encoder and the attention message encoder. We perform our experiments on a matrix environment. Surprisingly, our results show that the mean message encoder consistently outperforms the attention message encoder. Therefore, we analyse the communication protocol used by the agents that use the mean message encoder and can conclude that the agents use a combination of an exponential and a logarithmic function in their communication policy to avoid the loss of important information after applying the mean message encoder.
Topic Identification For Spontaneous Speech: Enriching Audio Features With Embedded Linguistic Information
Jul 21, 2023Traditional topic identification solutions from audio rely on an automatic speech recognition system (ASR) to produce transcripts used as input to a text-based model. These approaches work well in high-resource scenarios, where there are sufficient data to train both components of the pipeline. However, in low-resource situations, the ASR system, even if available, produces low-quality transcripts, leading to a bad text-based classifier. Moreover, spontaneous speech containing hesitations can further degrade the performance of the ASR model. In this paper, we investigate alternatives to the standard text-only solutions by comparing audio-only and hybrid techniques of jointly utilising text and audio features. The models evaluated on spontaneous Finnish speech demonstrate that purely audio-based solutions are a viable option when ASR components are not available, while the hybrid multi-modal solutions achieve the best results.
EgoBlur: Responsible Innovation in Aria
Aug 24, 2023

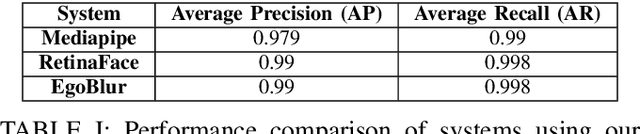
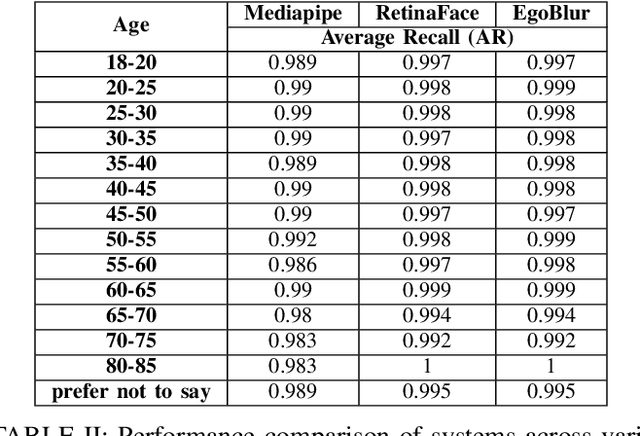
Project Aria pushes the frontiers of Egocentric AI with large-scale real-world data collection using purposely designed glasses with privacy first approach. To protect the privacy of bystanders being recorded by the glasses, our research protocols are designed to ensure recorded video is processed by an AI anonymization model that removes bystander faces and vehicle license plates. Detected face and license plate regions are processed with a Gaussian blur such that these personal identification information (PII) regions are obscured. This process helps to ensure that anonymized versions of the video is retained for research purposes. In Project Aria, we have developed a state-of-the-art anonymization system EgoBlur. In this paper, we present extensive analysis of EgoBlur on challenging datasets comparing its performance with other state-of-the-art systems from industry and academia including extensive Responsible AI analysis on recently released Casual Conversations V2 dataset.
HyperFormer: Enhancing Entity and Relation Interaction for Hyper-Relational Knowledge Graph Completion
Aug 12, 2023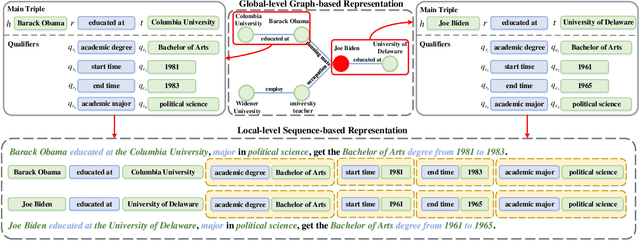
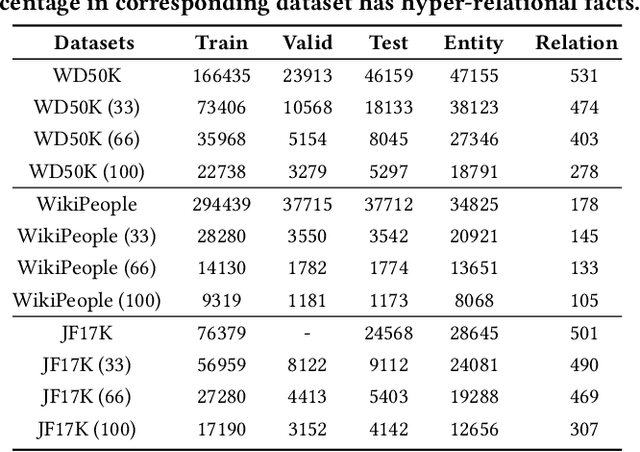
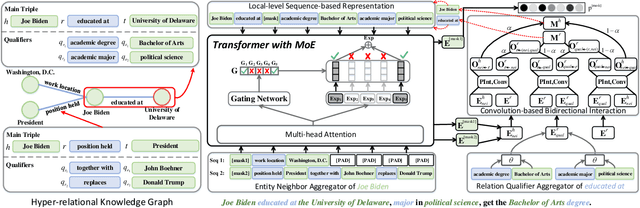
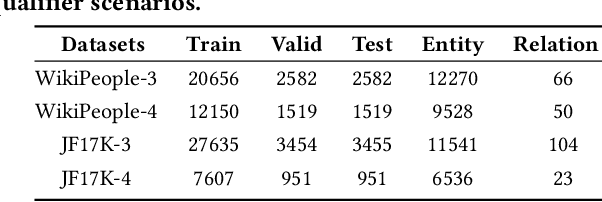
Hyper-relational knowledge graphs (HKGs) extend standard knowledge graphs by associating attribute-value qualifiers to triples, which effectively represent additional fine-grained information about its associated triple. Hyper-relational knowledge graph completion (HKGC) aims at inferring unknown triples while considering its qualifiers. Most existing approaches to HKGC exploit a global-level graph structure to encode hyper-relational knowledge into the graph convolution message passing process. However, the addition of multi-hop information might bring noise into the triple prediction process. To address this problem, we propose HyperFormer, a model that considers local-level sequential information, which encodes the content of the entities, relations and qualifiers of a triple. More precisely, HyperFormer is composed of three different modules: an entity neighbor aggregator module allowing to integrate the information of the neighbors of an entity to capture different perspectives of it; a relation qualifier aggregator module to integrate hyper-relational knowledge into the corresponding relation to refine the representation of relational content; a convolution-based bidirectional interaction module based on a convolutional operation, capturing pairwise bidirectional interactions of entity-relation, entity-qualifier, and relation-qualifier. realize the depth perception of the content related to the current statement. Furthermore, we introduce a Mixture-of-Experts strategy into the feed-forward layers of HyperFormer to strengthen its representation capabilities while reducing the amount of model parameters and computation. Extensive experiments on three well-known datasets with four different conditions demonstrate HyperFormer's effectiveness. Datasets and code are available at https://github.com/zhiweihu1103/HKGC-HyperFormer.
Address Matching Based On Hierarchical Information
May 10, 2023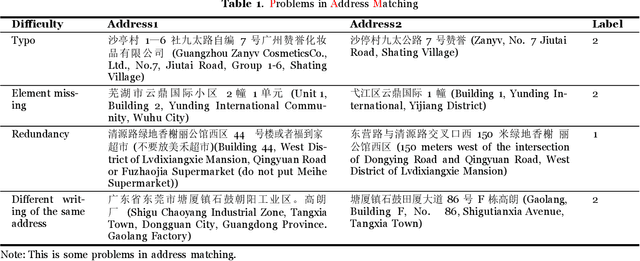
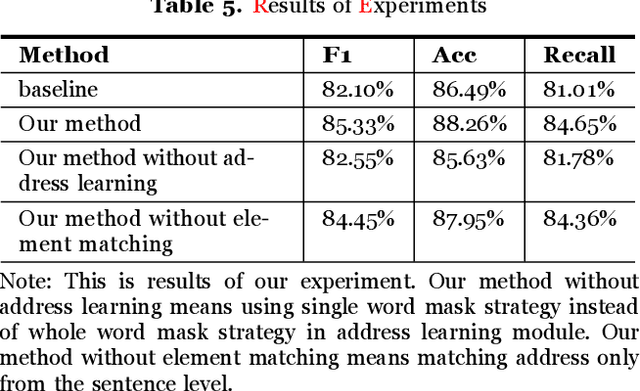
There is evidence that address matching plays a crucial role in many areas such as express delivery, online shopping and so on. Address has a hierarchical structure, in contrast to unstructured texts, which can contribute valuable information for address matching. Based on this idea, this paper proposes a novel method to leverage the hierarchical information in deep learning method that not only improves the ability of existing methods to handle irregular address, but also can pay closer attention to the special part of address. Experimental findings demonstrate that the proposed method improves the current approach by 3.2% points.
Compositional Learning in Transformer-Based Human-Object Interaction Detection
Aug 11, 2023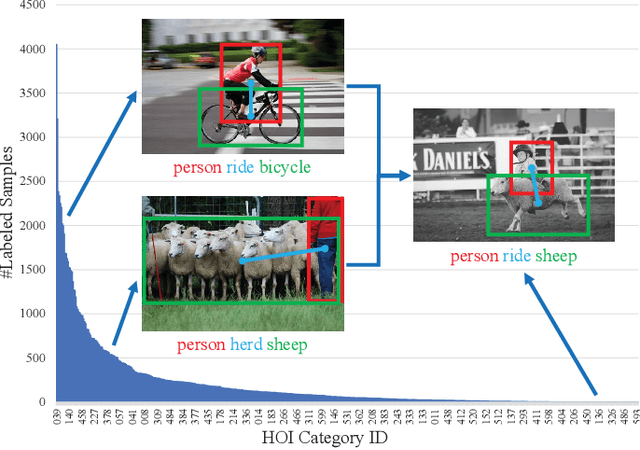
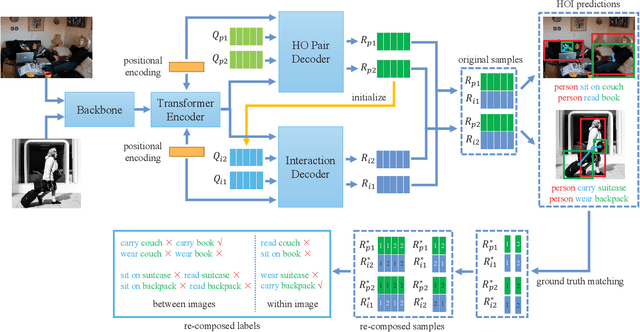

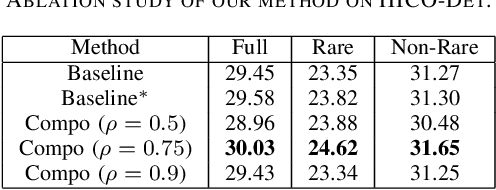
Human-object interaction (HOI) detection is an important part of understanding human activities and visual scenes. The long-tailed distribution of labeled instances is a primary challenge in HOI detection, promoting research in few-shot and zero-shot learning. Inspired by the combinatorial nature of HOI triplets, some existing approaches adopt the idea of compositional learning, in which object and action features are learned individually and re-composed as new training samples. However, these methods follow the CNN-based two-stage paradigm with limited feature extraction ability, and often rely on auxiliary information for better performance. Without introducing any additional information, we creatively propose a transformer-based framework for compositional HOI learning. Human-object pair representations and interaction representations are re-composed across different HOI instances, which involves richer contextual information and promotes the generalization of knowledge. Experiments show our simple but effective method achieves state-of-the-art performance, especially on rare HOI classes.