 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Anti-Jamming Precoding Against Disco Intelligent Reflecting Surfaces Based Fully-Passive Jamming Attacks
Aug 30, 2023
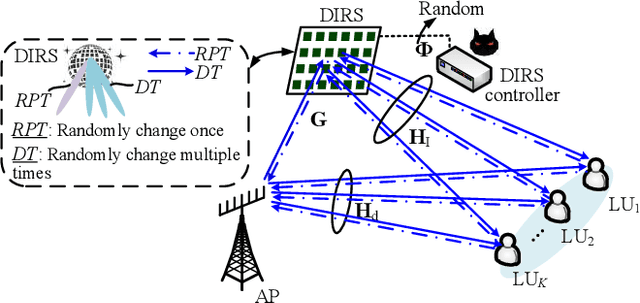
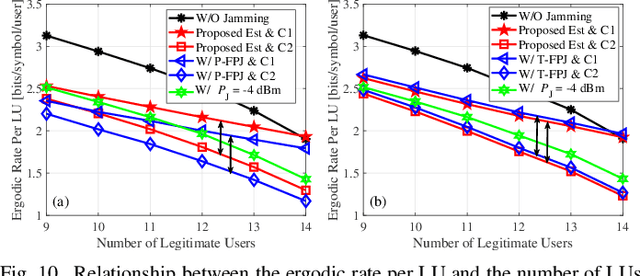
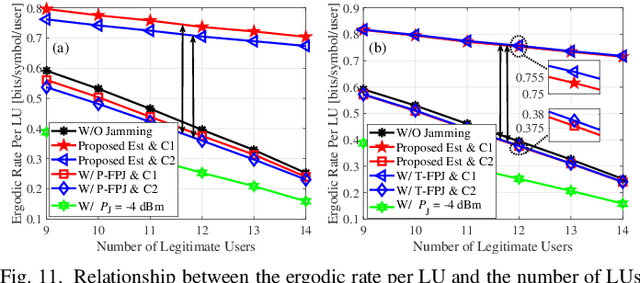
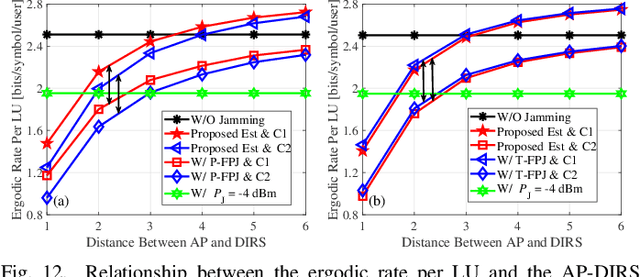
Emerging intelligent reflecting surfaces (IRSs) significantly improve system performance, but also pose a huge risk for physical layer security. Existing works have illustrated that a disco IRS (DIRS), i.e., an illegitimate IRS with random time-varying reflection properties (like a "disco ball"), can be employed by an attacker to actively age the channels of legitimate users (LUs). Such active channel aging (ACA) generated by the DIRS can be employed to jam multi-user multiple-input single-output (MU-MISO) systems without relying on either jamming power or LU channel state information (CSI). To address the significant threats posed by DIRS-based fully-passive jammers (FPJs), an anti-jamming precoder is proposed that requires only the statistical characteristics of the DIRS-based ACA channels instead of their CSI. The statistical characteristics of DIRS-jammed channels are first derived, and then the anti-jamming precoder is derived based on the statistical characteristics. Furthermore, we prove that the anti-jamming precoder can achieve the maximum signal-to-jamming-plus-noise ratio (SJNR). To acquire the ACA statistics without changing the system architecture or cooperating with the illegitimate DIRS, we design a data frame structure that the legitimate access point (AP) can use to estimate the statistical characteristics. During the designed data frame, the LUs only need to feed back their received power to the legitimate AP when they detect jamming attacks. Numerical results are also presented to evaluate the effectiveness of the proposed anti-jamming precoder against the DIRS-based FPJs and the feasibility of the designed data frame used by the legitimate AP to estimate the statistical characteristics.
A Novel Ehanced Move Recognition Algorithm Based on Pre-trained Models with Positional Embeddings
Aug 14, 2023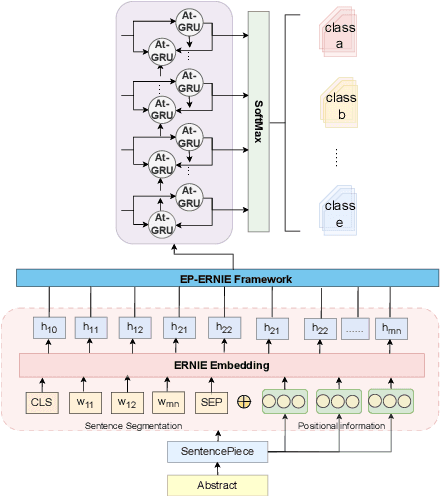
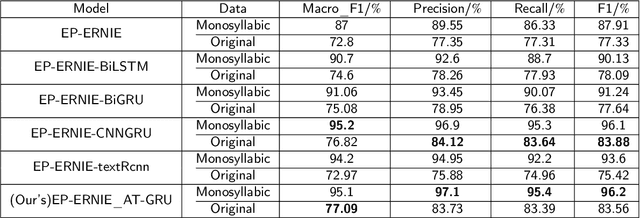
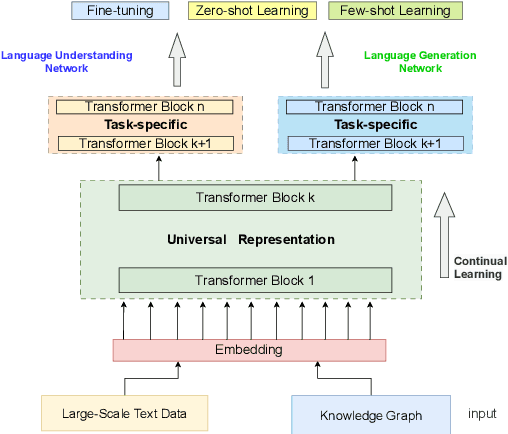
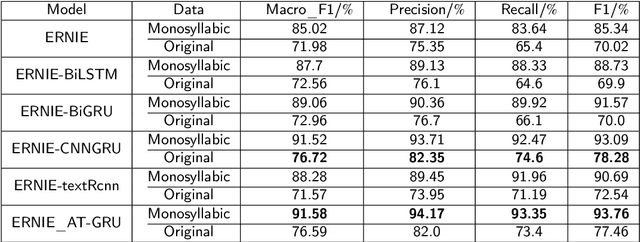
The recognition of abstracts is crucial for effectively locating the content and clarifying the article. Existing move recognition algorithms lack the ability to learn word position information to obtain contextual semantics. This paper proposes a novel enhanced move recognition algorithm with an improved pre-trained model and a gated network with attention mechanism for unstructured abstracts of Chinese scientific and technological papers. The proposed algorithm first performs summary data segmentation and vocabulary training. The EP-ERNIE$\_$AT-GRU framework is leveraged to incorporate word positional information, facilitating deep semantic learning and targeted feature extraction. Experimental results demonstrate that the proposed algorithm achieves 13.37$\%$ higher accuracy on the split dataset than on the original dataset and a 7.55$\%$ improvement in accuracy over the basic comparison model.
Data Race Detection Using Large Language Models
Aug 15, 2023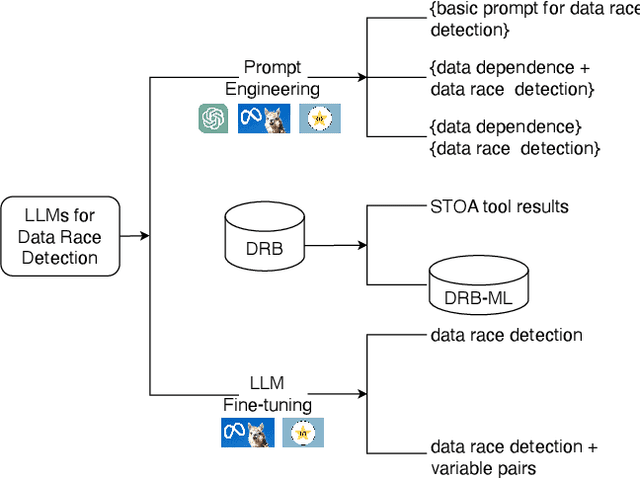


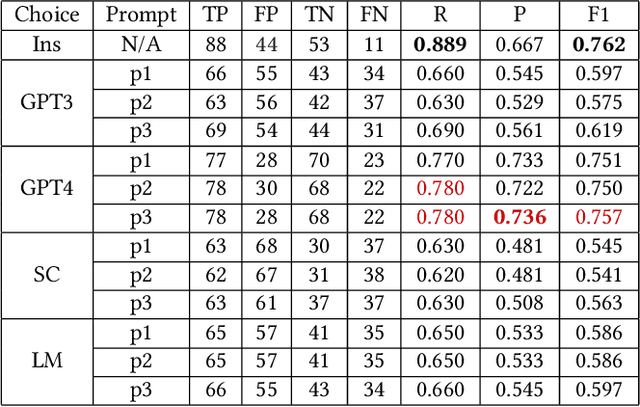
Large language models (LLMs) are demonstrating significant promise as an alternate strategy to facilitate analyses and optimizations of high-performance computing programs, circumventing the need for resource-intensive manual tool creation. In this paper, we explore a novel LLM-based data race detection approach combining prompting engineering and fine-tuning techniques. We create a dedicated dataset named DRB-ML, which is derived from DataRaceBench, with fine-grain labels showing the presence of data race pairs and their associated variables, line numbers, and read/write information. DRB-ML is then used to evaluate representative LLMs and fine-tune open-source ones. Our experiment shows that LLMs can be a viable approach to data race detection. However, they still cannot compete with traditional data race detection tools when we need detailed information about variable pairs causing data races.
End-to-End Document Classification and Key Information Extraction using Assignment Optimization
Jun 01, 2023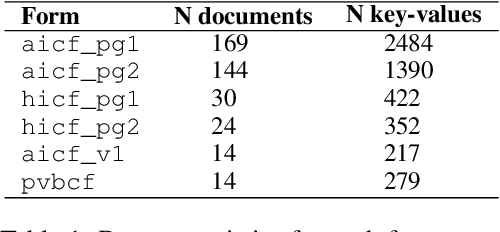

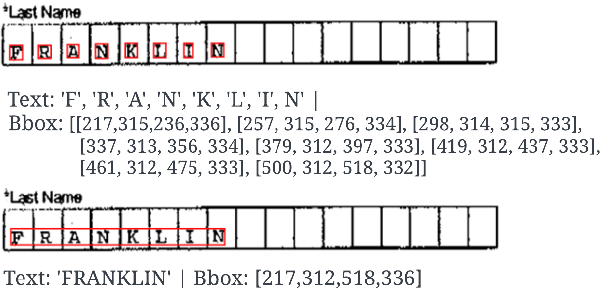
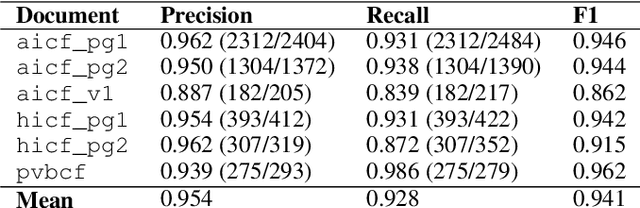
We propose end-to-end document classification and key information extraction (KIE) for automating document processing in forms. Through accurate document classification we harness known information from templates to enhance KIE from forms. We use text and layout encoding with a cosine similarity measure to classify visually-similar documents. We then demonstrate a novel application of mixed integer programming by using assignment optimization to extract key information from documents. Our approach is validated on an in-house dataset of noisy scanned forms. The best performing document classification approach achieved 0.97 f1 score. A mean f1 score of 0.94 for the KIE task suggests there is significant potential in applying optimization techniques. Abation results show that the method relies on document preprocessing techniques to mitigate Type II errors and achieve optimal performance.
Extracting Relational Triples Based on Graph Recursive Neural Network via Dynamic Feedback Forest Algorithm
Aug 22, 2023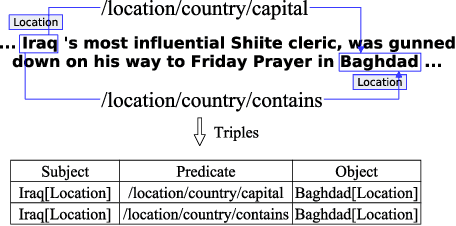
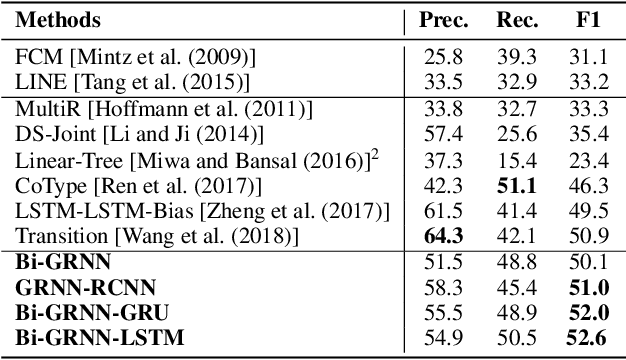
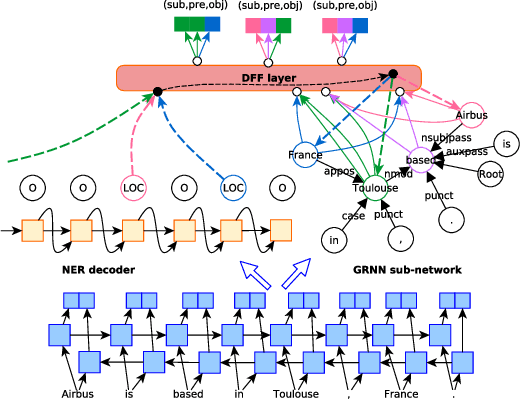
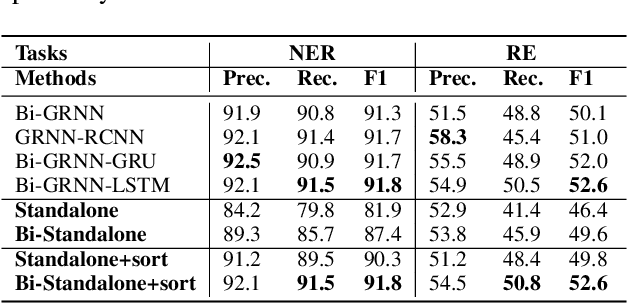
Extracting relational triples (subject, predicate, object) from text enables the transformation of unstructured text data into structured knowledge. The named entity recognition (NER) and the relation extraction (RE) are two foundational subtasks in this knowledge generation pipeline. The integration of subtasks poses a considerable challenge due to their disparate nature. This paper presents a novel approach that converts the triple extraction task into a graph labeling problem, capitalizing on the structural information of dependency parsing and graph recursive neural networks (GRNNs). To integrate subtasks, this paper proposes a dynamic feedback forest algorithm that connects the representations of subtasks by inference operations during model training. Experimental results demonstrate the effectiveness of the proposed method.
MELT: Mining Effective Lightweight Transformations from Pull Requests
Aug 28, 2023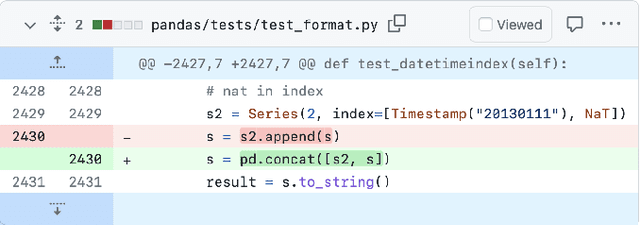
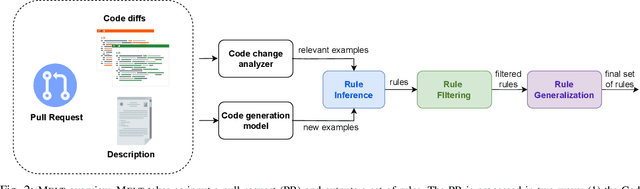
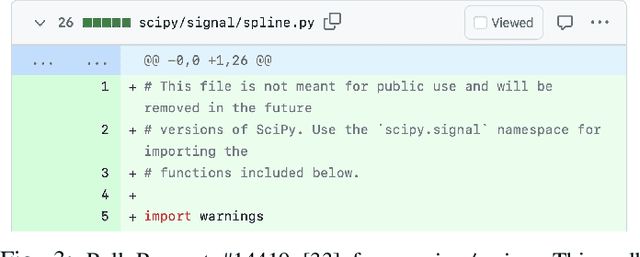

Software developers often struggle to update APIs, leading to manual, time-consuming, and error-prone processes. We introduce MELT, a new approach that generates lightweight API migration rules directly from pull requests in popular library repositories. Our key insight is that pull requests merged into open-source libraries are a rich source of information sufficient to mine API migration rules. By leveraging code examples mined from the library source and automatically generated code examples based on the pull requests, we infer transformation rules in \comby, a language for structural code search and replace. Since inferred rules from single code examples may be too specific, we propose a generalization procedure to make the rules more applicable to client projects. MELT rules are syntax-driven, interpretable, and easily adaptable. Moreover, unlike previous work, our approach enables rule inference to seamlessly integrate into the library workflow, removing the need to wait for client code migrations. We evaluated MELT on pull requests from four popular libraries, successfully mining 461 migration rules from code examples in pull requests and 114 rules from auto-generated code examples. Our generalization procedure increases the number of matches for mined rules by 9x. We applied these rules to client projects and ran their tests, which led to an overall decrease in the number of warnings and fixing some test cases demonstrating MELT's effectiveness in real-world scenarios.
ANER: Arabic and Arabizi Named Entity Recognition using Transformer-Based Approach
Aug 28, 2023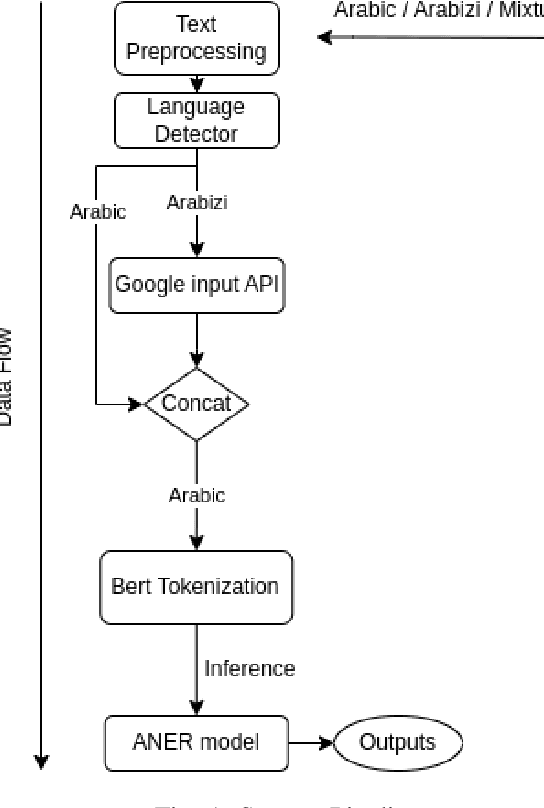
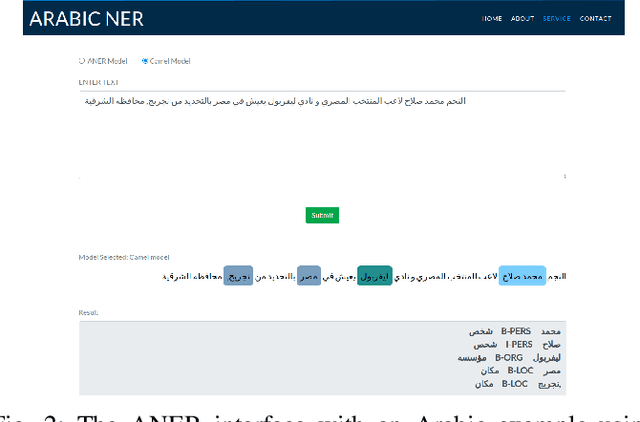
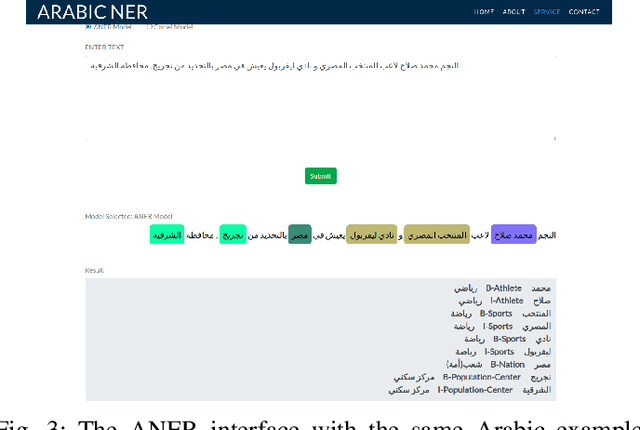
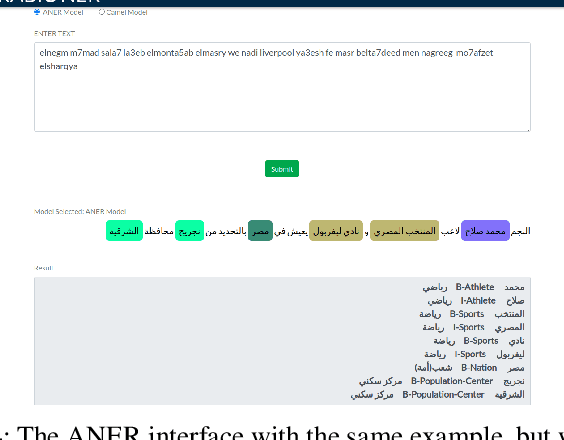
One of the main tasks of Natural Language Processing (NLP), is Named Entity Recognition (NER). It is used in many applications and also can be used as an intermediate step for other tasks. We present ANER, a web-based named entity recognizer for the Arabic, and Arabizi languages. The model is built upon BERT, which is a transformer-based encoder. It can recognize 50 different entity classes, covering various fields. We trained our model on the WikiFANE\_Gold dataset which consists of Wikipedia articles. We achieved an F1 score of 88.7\%, which beats CAMeL Tools' F1 score of 83\% on the ANERcorp dataset, which has only 4 classes. We also got an F1 score of 77.7\% on the NewsFANE\_Gold dataset which contains out-of-domain data from News articles. The system is deployed on a user-friendly web interface that accepts users' inputs in Arabic, or Arabizi. It allows users to explore the entities in the text by highlighting them. It can also direct users to get information about entities through Wikipedia directly. We added the ability to do NER using our model, or CAMeL Tools' model through our website. ANER is publicly accessible at \url{http://www.aner.online}. We also deployed our model on HuggingFace at https://huggingface.co/boda/ANER, to allow developers to test and use it.
Direct initial orbit determination
Aug 28, 2023Initial orbit determination (IOD) is an important early step in the processing chain that makes sense of and reconciles the multiple optical observations of a resident space object. IOD methods generally operate on line-of-sight (LOS) vectors extracted from images of the object, hence the LOS vectors can be seen as discrete point samples of the raw optical measurements. Typically, the number of LOS vectors used by an IOD method is much smaller than the available measurements (\ie, the set of pixel intensity values), hence current IOD methods arguably under-utilize the rich information present in the data. In this paper, we propose a \emph{direct} IOD method called D-IOD that fits the orbital parameters directly on the observed streak images, without requiring LOS extraction. Since it does not utilize LOS vectors, D-IOD avoids potential inaccuracies or errors due to an imperfect LOS extraction step. Two innovations underpin our novel orbit-fitting paradigm: first, we introduce a novel non-linear least-squares objective function that computes the loss between the candidate-orbit-generated streak images and the observed streak images. Second, the objective function is minimized with a gradient descent approach that is embedded in our proposed optimization strategies designed for streak images. We demonstrate the effectiveness of D-IOD on a variety of simulated scenarios and challenging real streak images.
Utilizing Mood-Inducing Background Music in Human-Robot Interaction
Aug 28, 2023Past research has clearly established that music can affect mood and that mood affects emotional and cognitive processing, and thus decision-making. It follows that if a robot interacting with a person needs to predict the person's behavior, knowledge of the music the person is listening to when acting is a potentially relevant feature. To date, however, there has not been any concrete evidence that a robot can improve its human-interactive decision-making by taking into account what the person is listening to. This research fills this gap by reporting the results of an experiment in which human participants were required to complete a task in the presence of an autonomous agent while listening to background music. Specifically, the participants drove a simulated car through an intersection while listening to music. The intersection was not empty, as another simulated vehicle, controlled autonomously, was also crossing the intersection in a different direction. Our results clearly indicate that such background information can be effectively incorporated in an agent's world representation in order to better predict people's behavior. We subsequently analyze how knowledge of music impacted both participant behavior and the resulting learned policy.\setcounter{footnote}{2}\footnote{An earlier version of part of the material in this paper appeared originally in the first author's Ph.D. Dissertation~\cite{liebman2020sequential} but it has not appeared in any pear-reviewed conference or journal.}
MS-Net: A Multi-modal Self-supervised Network for Fine-Grained Classification of Aircraft in SAR Images
Aug 28, 2023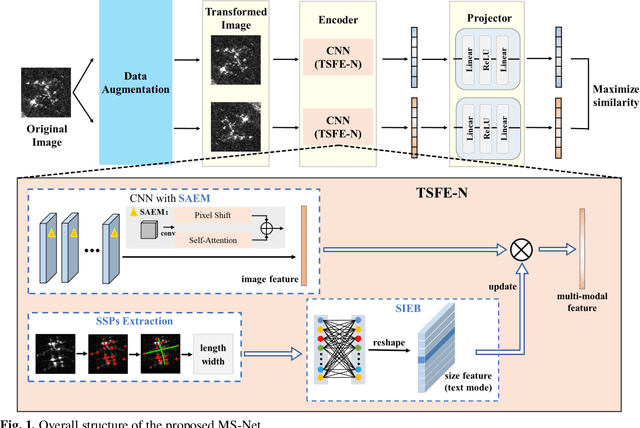
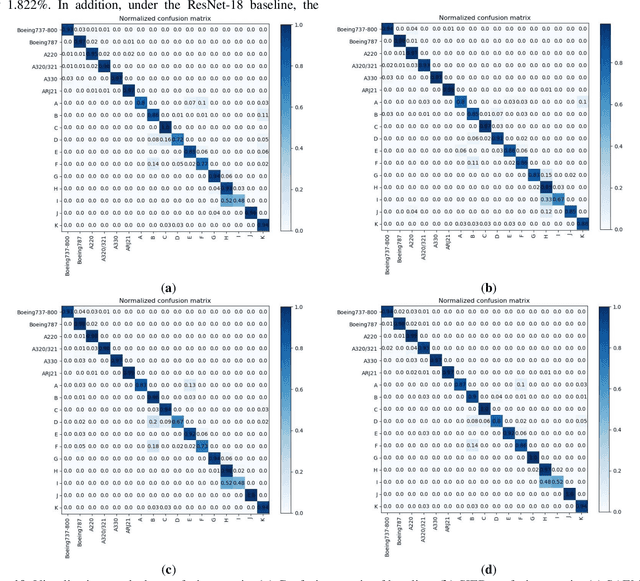
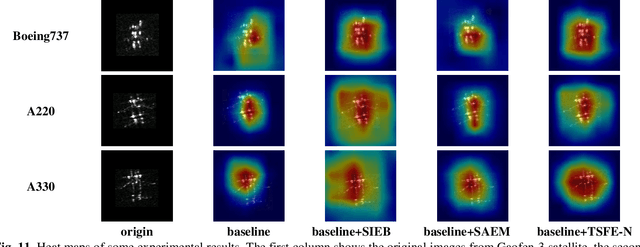
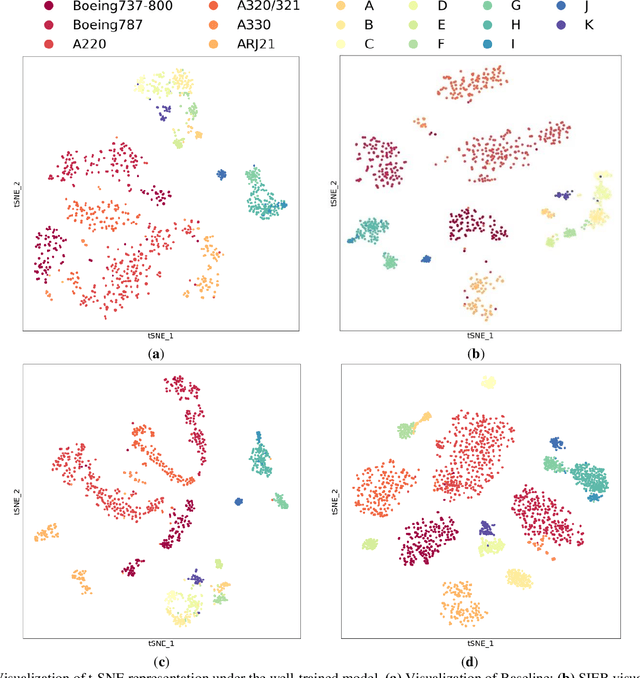
Synthetic aperture radar (SAR) imaging technology is commonly used to provide 24-hour all-weather earth observation. However, it still has some drawbacks in SAR target classification, especially in fine-grained classification of aircraft: aircrafts in SAR images have large intra-class diversity and inter-class similarity; the number of effective samples is insufficient and it's hard to annotate. To address these issues, this article proposes a novel multi-modal self-supervised network (MS-Net) for fine-grained classification of aircraft. Firstly, in order to entirely exploit the potential of multi-modal information, a two-sided path feature extraction network (TSFE-N) is constructed to enhance the image feature of the target and obtain the domain knowledge feature of text mode. Secondly, a contrastive self-supervised learning (CSSL) framework is employed to effectively learn useful label-independent feature from unbalanced data, a similarity per-ception loss (SPloss) is proposed to avoid network overfitting. Finally, TSFE-N is used as the encoder of CSSL to obtain the classification results. Through a large number of experiments, our MS-Net can effectively reduce the difficulty of classifying similar types of aircrafts. In the case of no label, the proposed algorithm achieves an accuracy of 88.46% for 17 types of air-craft classification task, which has pioneering significance in the field of fine-grained classification of aircraft in SAR images.