 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Diverse, Top-k, and Top-Quality Planning Over Simulators
Aug 25, 2023
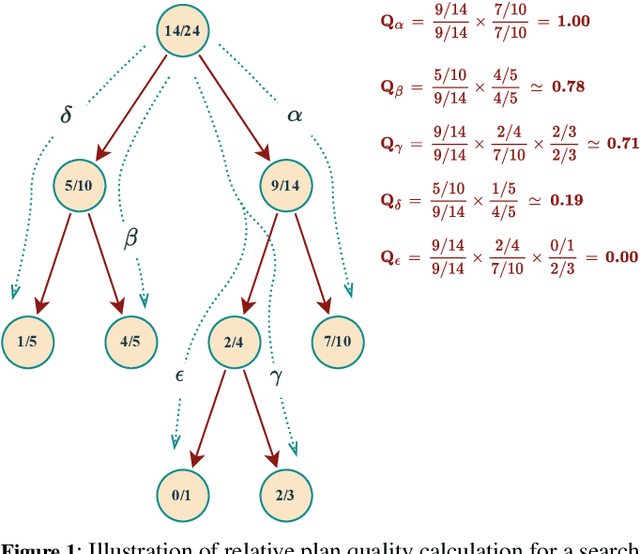
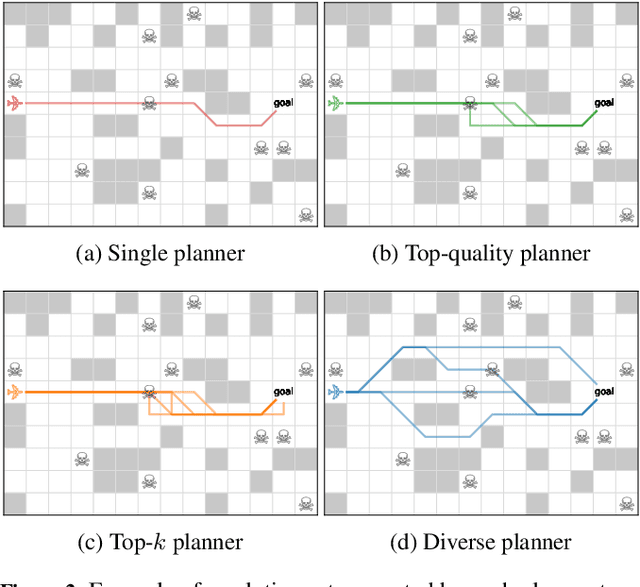
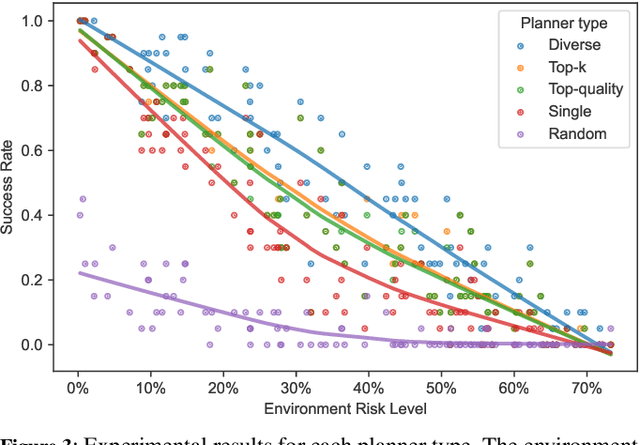
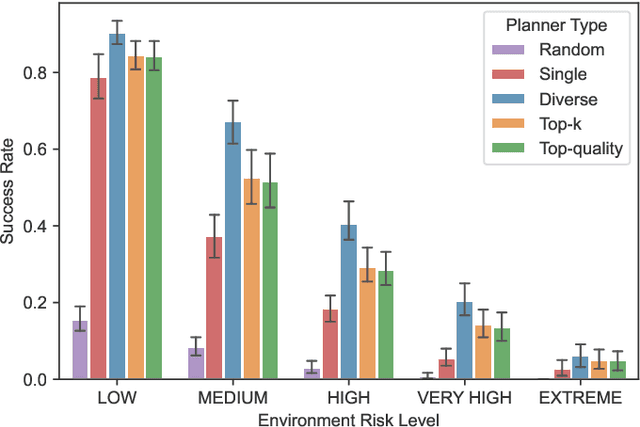
Diverse, top-k, and top-quality planning are concerned with the generation of sets of solutions to sequential decision problems. Previously this area has been the domain of classical planners that require a symbolic model of the problem instance. This paper proposes a novel alternative approach that uses Monte Carlo Tree Search (MCTS), enabling application to problems for which only a black-box simulation model is available. We present a procedure for extracting bounded sets of plans from pre-generated search trees in best-first order, and a metric for evaluating the relative quality of paths through a search tree. We demonstrate this approach on a path-planning problem with hidden information, and suggest adaptations to the MCTS algorithm to increase the diversity of generated plans. Our results show that our method can generate diverse and high-quality plan sets in domains where classical planners are not applicable.
FIRE: Food Image to REcipe generation
Aug 28, 2023
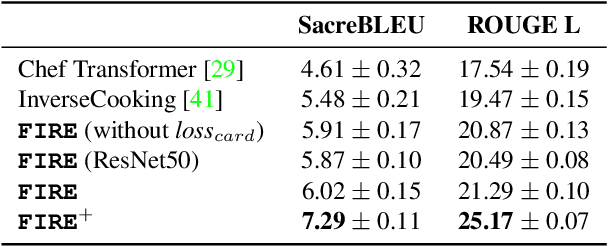
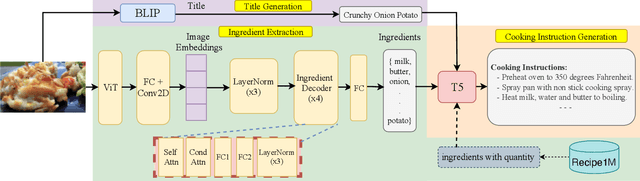
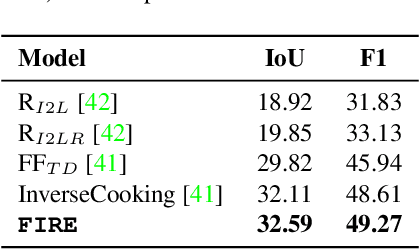
Food computing has emerged as a prominent multidisciplinary field of research in recent years. An ambitious goal of food computing is to develop end-to-end intelligent systems capable of autonomously producing recipe information for a food image. Current image-to-recipe methods are retrieval-based and their success depends heavily on the dataset size and diversity, as well as the quality of learned embeddings. Meanwhile, the emergence of powerful attention-based vision and language models presents a promising avenue for accurate and generalizable recipe generation, which has yet to be extensively explored. This paper proposes FIRE, a novel multimodal methodology tailored to recipe generation in the food computing domain, which generates the food title, ingredients, and cooking instructions based on input food images. FIRE leverages the BLIP model to generate titles, utilizes a Vision Transformer with a decoder for ingredient extraction, and employs the T5 model to generate recipes incorporating titles and ingredients as inputs. We showcase two practical applications that can benefit from integrating FIRE with large language model prompting: recipe customization to fit recipes to user preferences and recipe-to-code transformation to enable automated cooking processes. Our experimental findings validate the efficacy of our proposed approach, underscoring its potential for future advancements and widespread adoption in food computing.
On the Statistical Relation of Ultra-Reliable Wireless and Location Estimation
Aug 28, 2023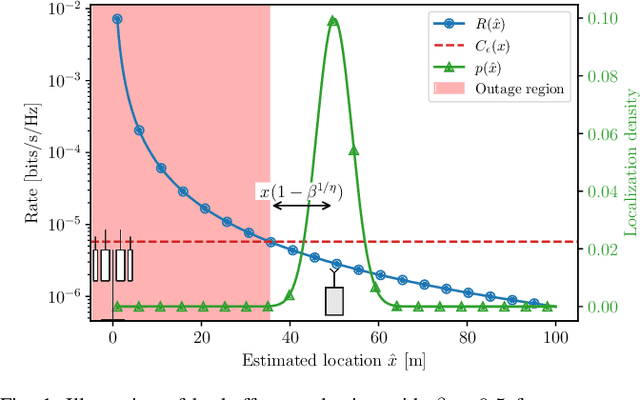
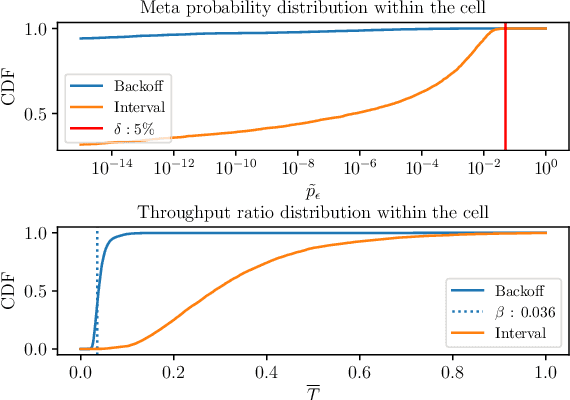
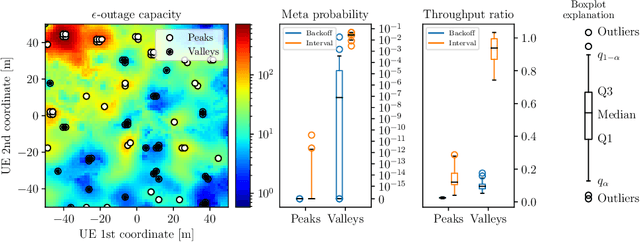
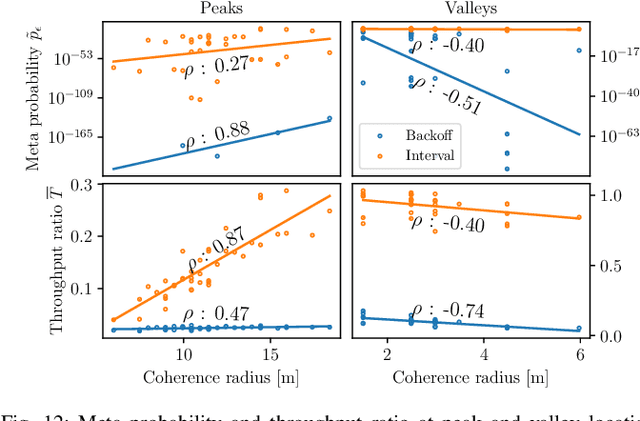
Location information is often used as a proxy to guarantee the performance of a wireless communication link. However, localization errors can result in a significant mismatch with the guarantees, particularly detrimental to users operating the ultra-reliable low-latency communication (URLLC) regime. This paper unveils the fundamental statistical relations between location estimation uncertainty and wireless link reliability, specifically in the context of rate selection for ultra-reliable communication. We start with a simple one-dimensional narrowband Rayleigh fading scenario and build towards a two-dimensional scenario in a rich scattering environment. The wireless link reliability is characterized by the meta-probability, the probability with respect to localization error of exceeding the outage capacity, and by removing other sources of errors in the system, we show that reliability is sensitive to localization errors. The $\epsilon$-outage coherence radius is defined and shown to provide valuable insight into the problem of location-based rate selection. However, it is generally challenging to guarantee reliability without accurate knowledge of the propagation environment. Finally, several rate-selection schemes are proposed, showcasing the problem's dynamics and revealing that properly accounting for the localization error is critical to ensure good performance in terms of reliability and achievable throughput.
Online Continual Learning on Hierarchical Label Expansion
Aug 28, 2023Continual learning (CL) enables models to adapt to new tasks and environments without forgetting previously learned knowledge. While current CL setups have ignored the relationship between labels in the past task and the new task with or without small task overlaps, real-world scenarios often involve hierarchical relationships between old and new tasks, posing another challenge for traditional CL approaches. To address this challenge, we propose a novel multi-level hierarchical class incremental task configuration with an online learning constraint, called hierarchical label expansion (HLE). Our configuration allows a network to first learn coarse-grained classes, with data labels continually expanding to more fine-grained classes in various hierarchy depths. To tackle this new setup, we propose a rehearsal-based method that utilizes hierarchy-aware pseudo-labeling to incorporate hierarchical class information. Additionally, we propose a simple yet effective memory management and sampling strategy that selectively adopts samples of newly encountered classes. Our experiments demonstrate that our proposed method can effectively use hierarchy on our HLE setup to improve classification accuracy across all levels of hierarchies, regardless of depth and class imbalance ratio, outperforming prior state-of-the-art works by significant margins while also outperforming them on the conventional disjoint, blurry and i-Blurry CL setups.
Improving the performance of object detection by preserving label distribution
Aug 28, 2023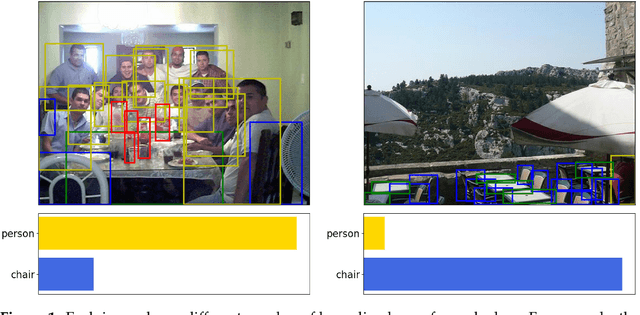


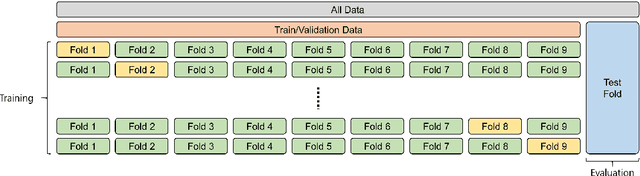
Object detection is a task that performs position identification and label classification of objects in images or videos. The information obtained through this process plays an essential role in various tasks in the field of computer vision. In object detection, the data utilized for training and validation typically originate from public datasets that are well-balanced in terms of the number of objects ascribed to each class in an image. However, in real-world scenarios, handling datasets with much greater class imbalance, i.e., very different numbers of objects for each class , is much more common, and this imbalance may reduce the performance of object detection when predicting unseen test images. In our study, thus, we propose a method that evenly distributes the classes in an image for training and validation, solving the class imbalance problem in object detection. Our proposed method aims to maintain a uniform class distribution through multi-label stratification. We tested our proposed method not only on public datasets that typically exhibit balanced class distribution but also on custom datasets that may have imbalanced class distribution. We found that our proposed method was more effective on datasets containing severe imbalance and less data. Our findings indicate that the proposed method can be effectively used on datasets with substantially imbalanced class distribution.
Patient-specific, mechanistic models of tumor growth incorporating artificial intelligence and big data
Aug 28, 2023Despite the remarkable advances in cancer diagnosis, treatment, and management that have occurred over the past decade, malignant tumors remain a major public health problem. Further progress in combating cancer may be enabled by personalizing the delivery of therapies according to the predicted response for each individual patient. The design of personalized therapies requires patient-specific information integrated into an appropriate mathematical model of tumor response. A fundamental barrier to realizing this paradigm is the current lack of a rigorous, yet practical, mathematical theory of tumor initiation, development, invasion, and response to therapy. In this review, we begin by providing an overview of different approaches to modeling tumor growth and treatment, including mechanistic as well as data-driven models based on ``big data" and artificial intelligence. Next, we present illustrative examples of mathematical models manifesting their utility and discussing the limitations of stand-alone mechanistic and data-driven models. We further discuss the potential of mechanistic models for not only predicting, but also optimizing response to therapy on a patient-specific basis. We then discuss current efforts and future possibilities to integrate mechanistic and data-driven models. We conclude by proposing five fundamental challenges that must be addressed to fully realize personalized care for cancer patients driven by computational models.
Hierarchical Time Series Forecasting with Bayesian Modeling
Aug 28, 2023
We encounter time series data in many domains such as finance, physics, business, and weather. One of the main tasks of time series analysis, one that helps to take informed decisions under uncertainty, is forecasting. Time series are often hierarchically structured, e.g., a company sales might be broken down into different regions, and each region into different stores. In some cases the number of series in the hierarchy is too big to fit in a single model to produce forecasts in relevant time, and a decentralized approach is beneficial. One way to do this is to train independent forecasting models for each series and for some summary statistics series implied by the hierarchy (e.g. the sum of all series) and to pass those models to a reconciliation algorithm to improve those forecasts by sharing information between the series. In this work we focus on the reconciliation step, and propose a method to do so from a Bayesian perspective - Bayesian forecast reconciliation. We also define the common case of linear Gaussian reconciliation, where the forecasts are Gaussian and the hierarchy has linear structure, and show that we can compute reconciliation in closed form. We evaluate these methods on synthetic and real data sets, and compare them to other work in this field.
Enhancing Language Representation with Constructional Information for Natural Language Understanding
Jun 05, 2023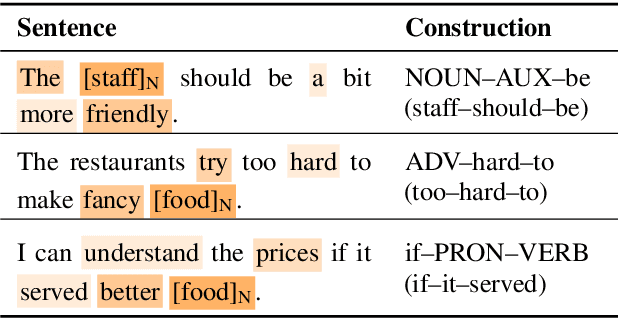
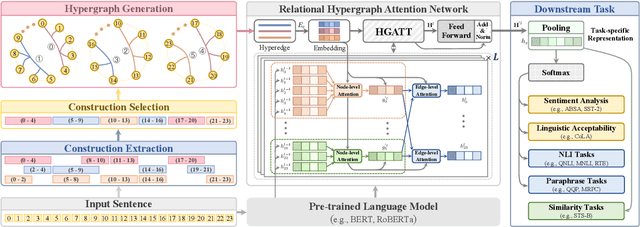

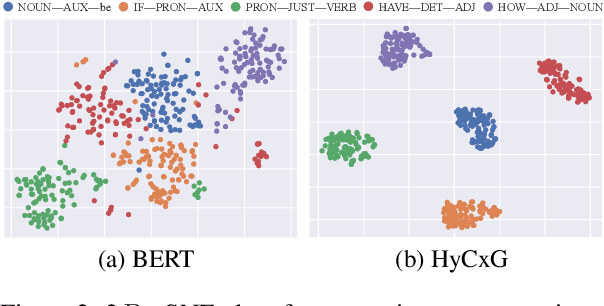
Natural language understanding (NLU) is an essential branch of natural language processing, which relies on representations generated by pre-trained language models (PLMs). However, PLMs primarily focus on acquiring lexico-semantic information, while they may be unable to adequately handle the meaning of constructions. To address this issue, we introduce construction grammar (CxG), which highlights the pairings of form and meaning, to enrich language representation. We adopt usage-based construction grammar as the basis of our work, which is highly compatible with statistical models such as PLMs. Then a HyCxG framework is proposed to enhance language representation through a three-stage solution. First, all constructions are extracted from sentences via a slot-constraints approach. As constructions can overlap with each other, bringing redundancy and imbalance, we formulate the conditional max coverage problem for selecting the discriminative constructions. Finally, we propose a relational hypergraph attention network to acquire representation from constructional information by capturing high-order word interactions among constructions. Extensive experiments demonstrate the superiority of the proposed model on a variety of NLU tasks.
FashionNTM: Multi-turn Fashion Image Retrieval via Cascaded Memory
Aug 20, 2023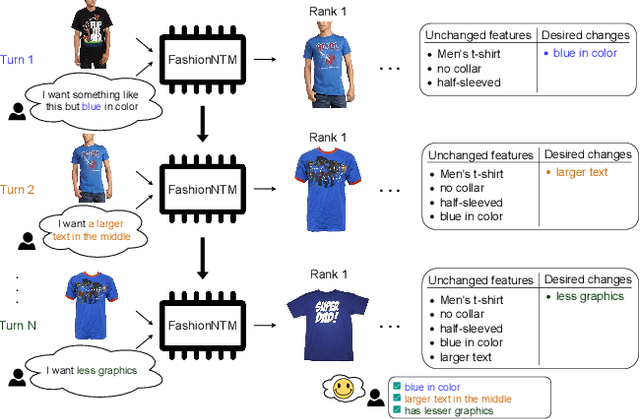
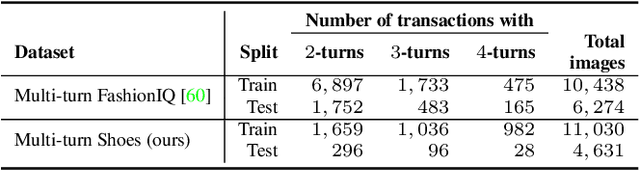
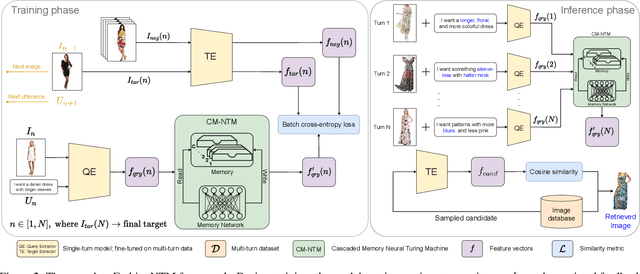
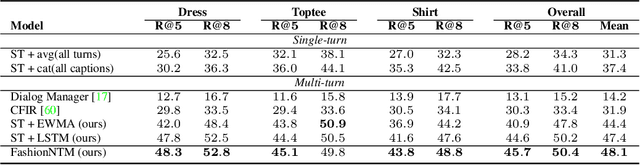
Multi-turn textual feedback-based fashion image retrieval focuses on a real-world setting, where users can iteratively provide information to refine retrieval results until they find an item that fits all their requirements. In this work, we present a novel memory-based method, called FashionNTM, for such a multi-turn system. Our framework incorporates a new Cascaded Memory Neural Turing Machine (CM-NTM) approach for implicit state management, thereby learning to integrate information across all past turns to retrieve new images, for a given turn. Unlike vanilla Neural Turing Machine (NTM), our CM-NTM operates on multiple inputs, which interact with their respective memories via individual read and write heads, to learn complex relationships. Extensive evaluation results show that our proposed method outperforms the previous state-of-the-art algorithm by 50.5%, on Multi-turn FashionIQ -- the only existing multi-turn fashion dataset currently, in addition to having a relative improvement of 12.6% on Multi-turn Shoes -- an extension of the single-turn Shoes dataset that we created in this work. Further analysis of the model in a real-world interactive setting demonstrates two important capabilities of our model -- memory retention across turns, and agnosticity to turn order for non-contradictory feedback. Finally, user study results show that images retrieved by FashionNTM were favored by 83.1% over other multi-turn models. Project page: https://sites.google.com/eng.ucsd.edu/fashionntm
A unified framework for information-theoretic generalization bounds
May 18, 2023This paper presents a general methodology for deriving information-theoretic generalization bounds for learning algorithms. The main technical tool is a probabilistic decorrelation lemma based on a change of measure and a relaxation of Young's inequality in $L_{\psi_p}$ Orlicz spaces. Using the decorrelation lemma in combination with other techniques, such as symmetrization, couplings, and chaining in the space of probability measures, we obtain new upper bounds on the generalization error, both in expectation and in high probability, and recover as special cases many of the existing generalization bounds, including the ones based on mutual information, conditional mutual information, stochastic chaining, and PAC-Bayes inequalities. In addition, the Fernique-Talagrand upper bound on the expected supremum of a subgaussian process emerges as a special case.