 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
On the Practicality of Dynamic Updates in Fast Searchable Encryption
Aug 25, 2023




Searchable encrypted (SE) indexing systems are a useful tool for utilizing cloud services to store and manage sensitive information. However, much of the work on SE systems to date has remained theoretical. In order to make them of practical use, more work is needed to develop optimal protocols and working models for them. This includes, in particular, the creation of a working update model in order to maintain an encrypted index of a dynamic document set such as an email inbox. I have created a working, real-world end-to-end SE implementation that satisfies these needs, including the first empirical performance evaluation of the dynamic SE update operation. In doing so, I show a viable path to move from the theoretical concepts described by previous researchers to a future production-worthy implementation and identify issues for follow-on investigation.
Incorporating Annotator Uncertainty into Representations of Discourse Relations
Aug 14, 2023Annotation of discourse relations is a known difficult task, especially for non-expert annotators. In this paper, we investigate novice annotators' uncertainty on the annotation of discourse relations on spoken conversational data. We find that dialogue context (single turn, pair of turns within speaker, and pair of turns across speakers) is a significant predictor of confidence scores. We compute distributed representations of discourse relations from co-occurrence statistics that incorporate information about confidence scores and dialogue context. We perform a hierarchical clustering analysis using these representations and show that weighting discourse relation representations with information about confidence and dialogue context coherently models our annotators' uncertainty about discourse relation labels.
Meta-learning enhanced next POI recommendation by leveraging check-ins from auxiliary cities
Aug 18, 2023Most existing point-of-interest (POI) recommenders aim to capture user preference by employing city-level user historical check-ins, thus facilitating users' exploration of the city. However, the scarcity of city-level user check-ins brings a significant challenge to user preference learning. Although prior studies attempt to mitigate this challenge by exploiting various context information, e.g., spatio-temporal information, they ignore to transfer the knowledge (i.e., common behavioral pattern) from other relevant cities (i.e., auxiliary cities). In this paper, we investigate the effect of knowledge distilled from auxiliary cities and thus propose a novel Meta-learning Enhanced next POI Recommendation framework (MERec). The MERec leverages the correlation of check-in behaviors among various cities into the meta-learning paradigm to help infer user preference in the target city, by holding the principle of "paying more attention to more correlated knowledge". Particularly, a city-level correlation strategy is devised to attentively capture common patterns among cities, so as to transfer more relevant knowledge from more correlated cities. Extensive experiments verify the superiority of the proposed MERec against state-of-the-art algorithms.
Differentiable Weight Masks for Domain Transfer
Aug 26, 2023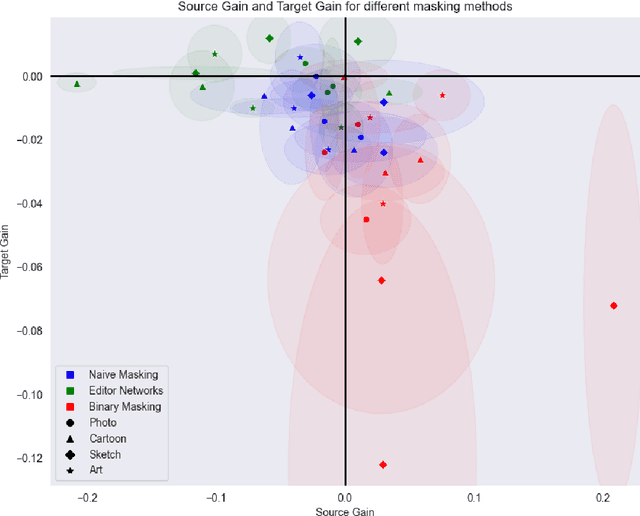

One of the major drawbacks of deep learning models for computer vision has been their inability to retain multiple sources of information in a modular fashion. For instance, given a network that has been trained on a source task, we would like to re-train this network on a similar, yet different, target task while maintaining its performance on the source task. Simultaneously, researchers have extensively studied modularization of network weights to localize and identify the set of weights culpable for eliciting the observed performance on a given task. One set of works studies the modularization induced in the weights of a neural network by learning and analysing weight masks. In this work, we combine these fields to study three such weight masking methods and analyse their ability to mitigate "forgetting'' on the source task while also allowing for efficient finetuning on the target task. We find that different masking techniques have trade-offs in retaining knowledge in the source task without adversely affecting target task performance.
ReFuSeg: Regularized Multi-Modal Fusion for Precise Brain Tumour Segmentation
Aug 26, 2023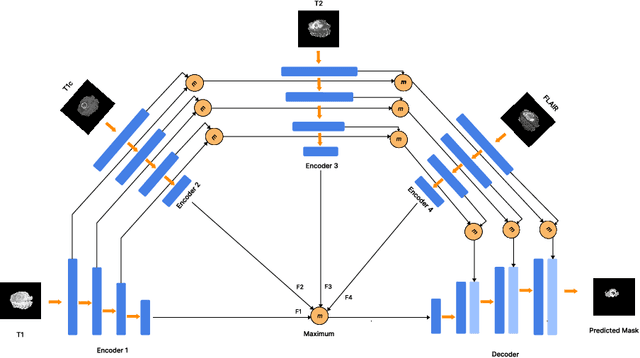
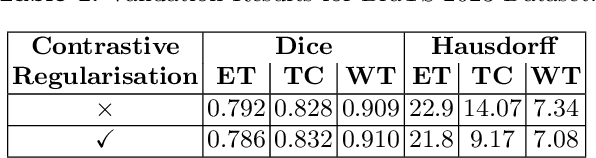
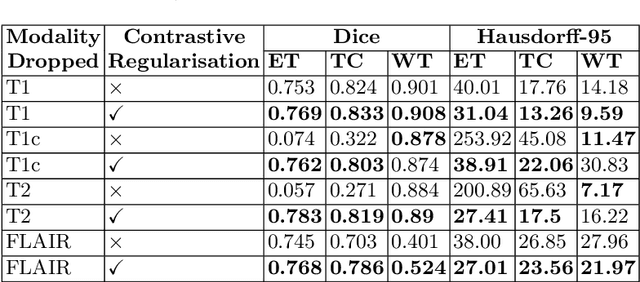
Semantic segmentation of brain tumours is a fundamental task in medical image analysis that can help clinicians in diagnosing the patient and tracking the progression of any malignant entities. Accurate segmentation of brain lesions is essential for medical diagnosis and treatment planning. However, failure to acquire specific MRI imaging modalities can prevent applications from operating in critical situations, raising concerns about their reliability and overall trustworthiness. This paper presents a novel multi-modal approach for brain lesion segmentation that leverages information from four distinct imaging modalities while being robust to real-world scenarios of missing modalities, such as T1, T1c, T2, and FLAIR MRI of brains. Our proposed method can help address the challenges posed by artifacts in medical imagery due to data acquisition errors (such as patient motion) or a reconstruction algorithm's inability to represent the anatomy while ensuring a trade-off in accuracy. Our proposed regularization module makes it robust to these scenarios and ensures the reliability of lesion segmentation.
SPM: Structured Pretraining and Matching Architectures for Relevance Modeling in Meituan Search
Aug 16, 2023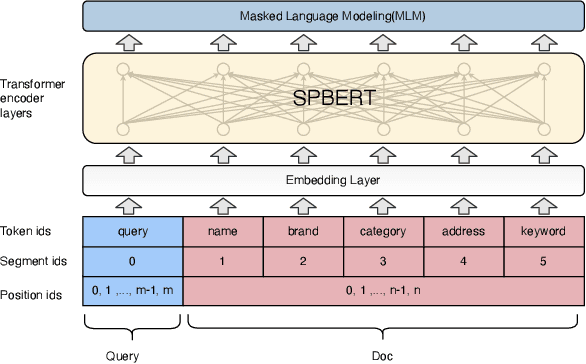
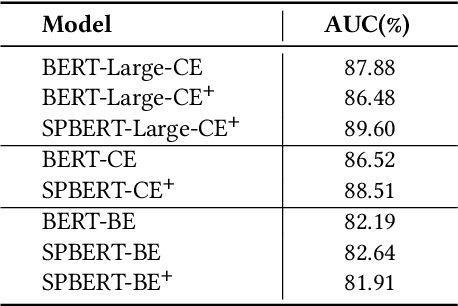
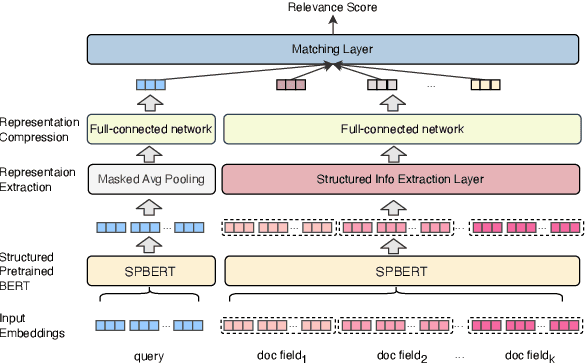
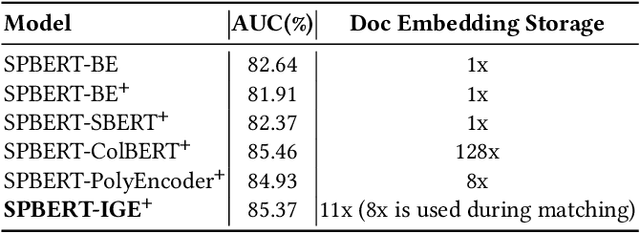
In e-commerce search, relevance between query and documents is an essential requirement for satisfying user experience. Different from traditional e-commerce platforms that offer products, users search on life service platforms such as Meituan mainly for product providers, which usually have abundant structured information, e.g. name, address, category, thousands of products. Modeling search relevance with these rich structured contents is challenging due to the following issues: (1) there is language distribution discrepancy among different fields of structured document, making it difficult to directly adopt off-the-shelf pretrained language model based methods like BERT. (2) different fields usually have different importance and their length vary greatly, making it difficult to extract document information helpful for relevance matching. To tackle these issues, in this paper we propose a novel two-stage pretraining and matching architecture for relevance matching with rich structured documents. At pretraining stage, we propose an effective pretraining method that employs both query and multiple fields of document as inputs, including an effective information compression method for lengthy fields. At relevance matching stage, a novel matching method is proposed by leveraging domain knowledge in search query to generate more effective document representations for relevance scoring. Extensive offline experiments and online A/B tests on millions of users verify that the proposed architectures effectively improve the performance of relevance modeling. The model has already been deployed online, serving the search traffic of Meituan for over a year.
Automatic Vision-Based Parking Slot Detection and Occupancy Classification
Aug 16, 2023Parking guidance information (PGI) systems are used to provide information to drivers about the nearest parking lots and the number of vacant parking slots. Recently, vision-based solutions started to appear as a cost-effective alternative to standard PGI systems based on hardware sensors mounted on each parking slot. Vision-based systems provide information about parking occupancy based on images taken by a camera that is recording a parking lot. However, such systems are challenging to develop due to various possible viewpoints, weather conditions, and object occlusions. Most notably, they require manual labeling of parking slot locations in the input image which is sensitive to camera angle change, replacement, or maintenance. In this paper, the algorithm that performs Automatic Parking Slot Detection and Occupancy Classification (APSD-OC) solely on input images is proposed. Automatic parking slot detection is based on vehicle detections in a series of parking lot images upon which clustering is applied in bird's eye view to detect parking slots. Once the parking slots positions are determined in the input image, each detected parking slot is classified as occupied or vacant using a specifically trained ResNet34 deep classifier. The proposed approach is extensively evaluated on well-known publicly available datasets (PKLot and CNRPark+EXT), showing high efficiency in parking slot detection and robustness to the presence of illegal parking or passing vehicles. Trained classifier achieves high accuracy in parking slot occupancy classification.
* 39 pages, 8 figures, 9 tables
Can Knowledge Graphs Simplify Text?
Aug 17, 2023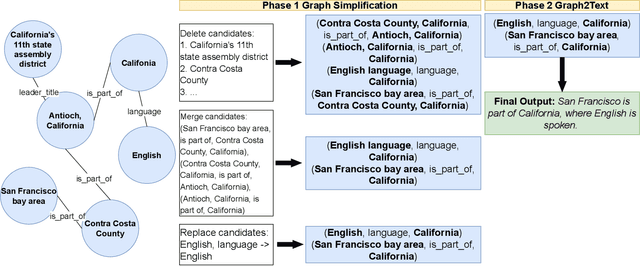
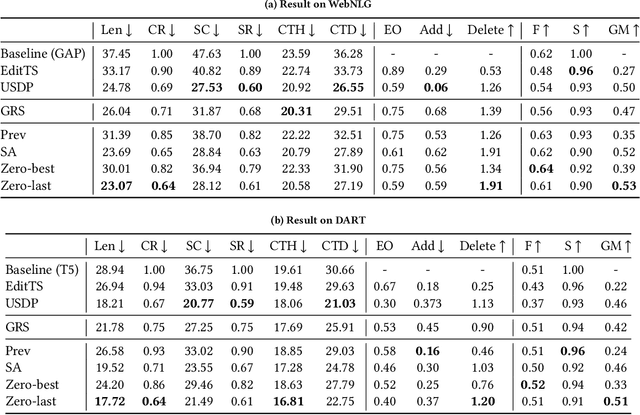
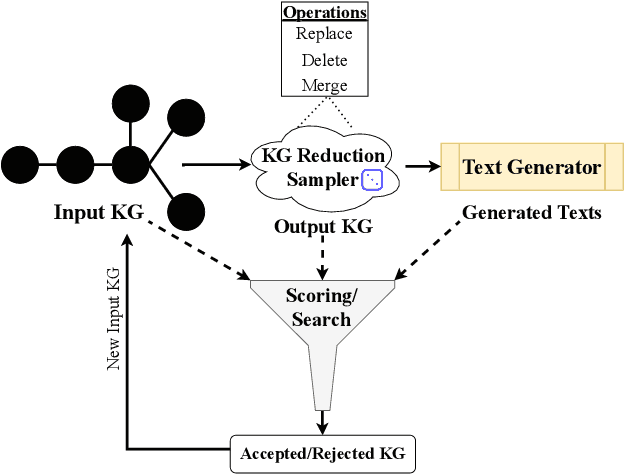
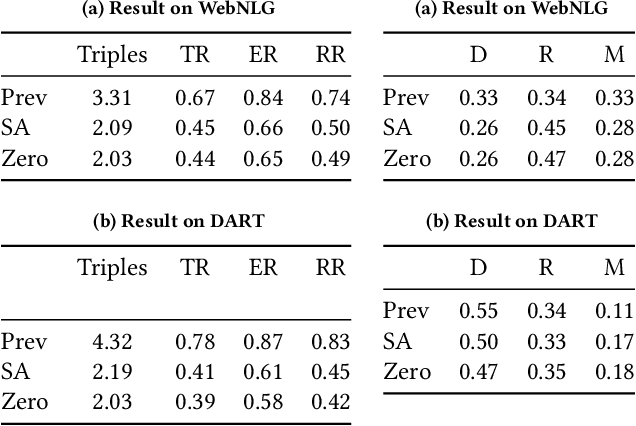
Knowledge Graph (KG)-to-Text Generation has seen recent improvements in generating fluent and informative sentences which describe a given KG. As KGs are widespread across multiple domains and contain important entity-relation information, and as text simplification aims to reduce the complexity of a text while preserving the meaning of the original text, we propose KGSimple, a novel approach to unsupervised text simplification which infuses KG-established techniques in order to construct a simplified KG path and generate a concise text which preserves the original input's meaning. Through an iterative and sampling KG-first approach, our model is capable of simplifying text when starting from a KG by learning to keep important information while harnessing KG-to-text generation to output fluent and descriptive sentences. We evaluate various settings of the KGSimple model on currently-available KG-to-text datasets, demonstrating its effectiveness compared to unsupervised text simplification models which start with a given complex text. Our code is available on GitHub.
Introducing Language Guidance in Prompt-based Continual Learning
Aug 30, 2023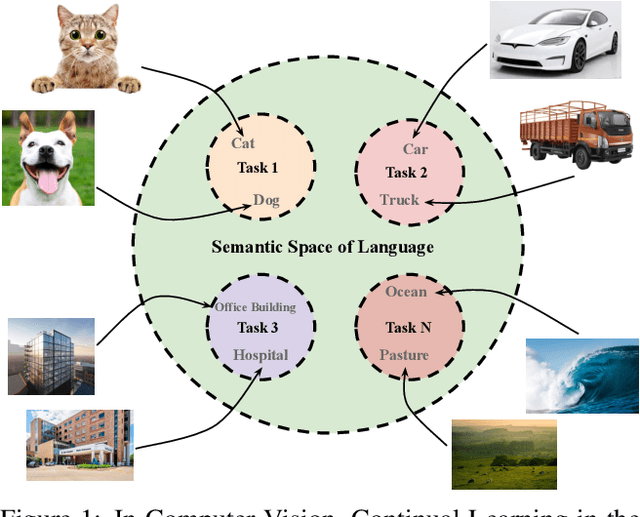
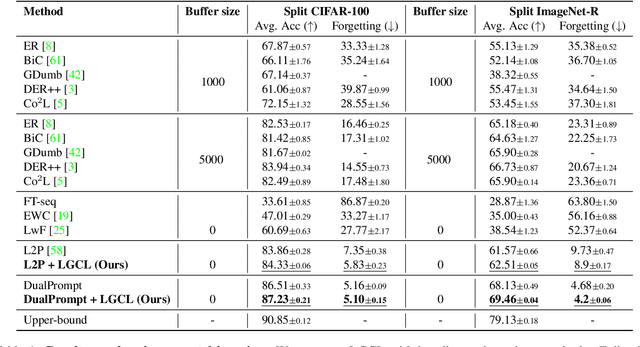
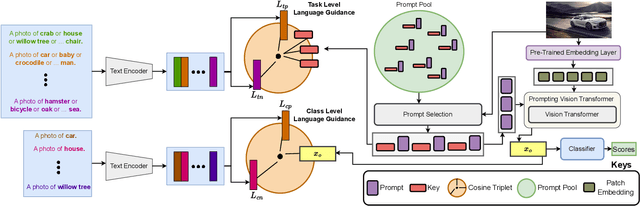
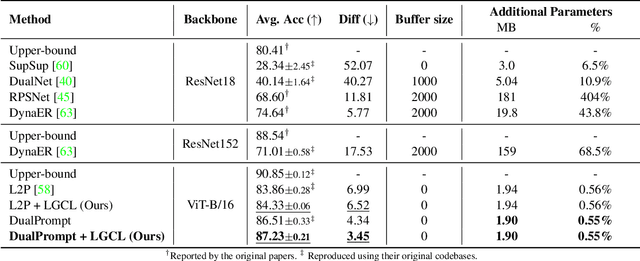
Continual Learning aims to learn a single model on a sequence of tasks without having access to data from previous tasks. The biggest challenge in the domain still remains catastrophic forgetting: a loss in performance on seen classes of earlier tasks. Some existing methods rely on an expensive replay buffer to store a chunk of data from previous tasks. This, while promising, becomes expensive when the number of tasks becomes large or data can not be stored for privacy reasons. As an alternative, prompt-based methods have been proposed that store the task information in a learnable prompt pool. This prompt pool instructs a frozen image encoder on how to solve each task. While the model faces a disjoint set of classes in each task in this setting, we argue that these classes can be encoded to the same embedding space of a pre-trained language encoder. In this work, we propose Language Guidance for Prompt-based Continual Learning (LGCL) as a plug-in for prompt-based methods. LGCL is model agnostic and introduces language guidance at the task level in the prompt pool and at the class level on the output feature of the vision encoder. We show with extensive experimentation that LGCL consistently improves the performance of prompt-based continual learning methods to set a new state-of-the art. LGCL achieves these performance improvements without needing any additional learnable parameters.
Calibrated Explanations for Regression
Aug 30, 2023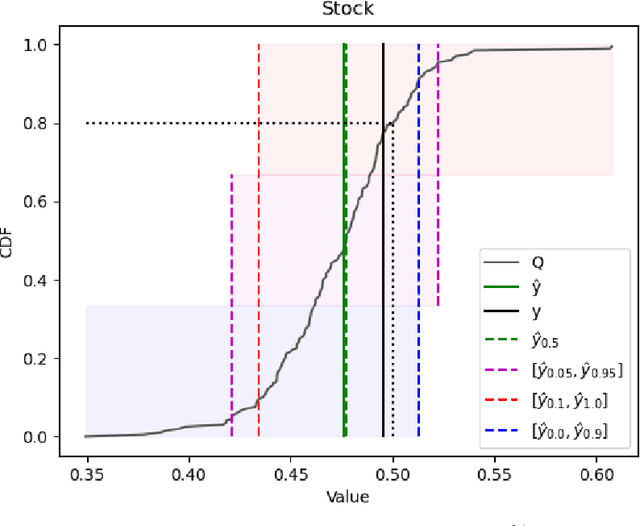

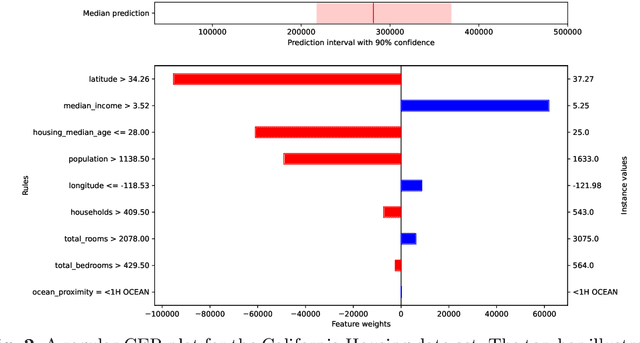

Artificial Intelligence (AI) is often an integral part of modern decision support systems (DSSs). The best-performing predictive models used in AI-based DSSs lack transparency. Explainable Artificial Intelligence (XAI) aims to create AI systems that can explain their rationale to human users. Local explanations in XAI can provide information about the causes of individual predictions in terms of feature importance. However, a critical drawback of existing local explanation methods is their inability to quantify the uncertainty associated with a feature's importance. This paper introduces an extension of a feature importance explanation method, Calibrated Explanations (CE), previously only supporting classification, with support for standard regression and probabilistic regression, i.e., the probability that the target is above an arbitrary threshold. The extension for regression keeps all the benefits of CE, such as calibration of the prediction from the underlying model with confidence intervals, uncertainty quantification of feature importance, and allows both factual and counterfactual explanations. CE for standard regression provides fast, reliable, stable, and robust explanations. CE for probabilistic regression provides an entirely new way of creating probabilistic explanations from any ordinary regression model and with a dynamic selection of thresholds. The performance of CE for probabilistic regression regarding stability and speed is comparable to LIME. The method is model agnostic with easily understood conditional rules. An implementation in Python is freely available on GitHub and for installation using pip making the results in this paper easily replicable.