 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ReFuSeg: Regularized Multi-Modal Fusion for Precise Brain Tumour Segmentation
Aug 26, 2023
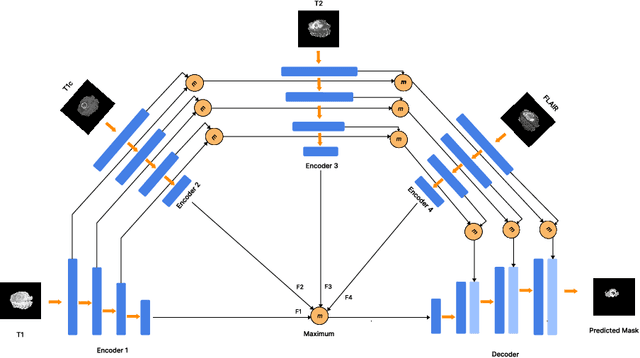
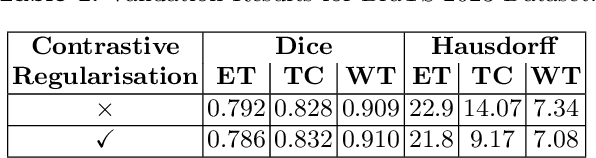
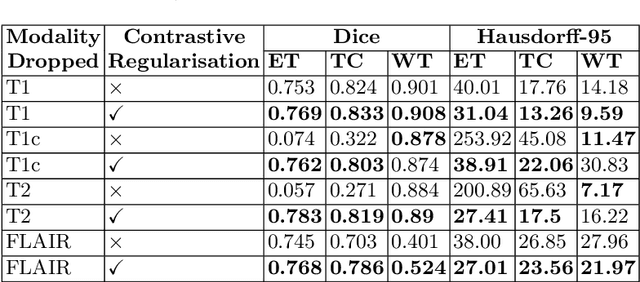
Semantic segmentation of brain tumours is a fundamental task in medical image analysis that can help clinicians in diagnosing the patient and tracking the progression of any malignant entities. Accurate segmentation of brain lesions is essential for medical diagnosis and treatment planning. However, failure to acquire specific MRI imaging modalities can prevent applications from operating in critical situations, raising concerns about their reliability and overall trustworthiness. This paper presents a novel multi-modal approach for brain lesion segmentation that leverages information from four distinct imaging modalities while being robust to real-world scenarios of missing modalities, such as T1, T1c, T2, and FLAIR MRI of brains. Our proposed method can help address the challenges posed by artifacts in medical imagery due to data acquisition errors (such as patient motion) or a reconstruction algorithm's inability to represent the anatomy while ensuring a trade-off in accuracy. Our proposed regularization module makes it robust to these scenarios and ensures the reliability of lesion segmentation.
Contrastive Learning-based Imputation-Prediction Networks for In-hospital Mortality Risk Modeling using EHRs
Aug 19, 2023
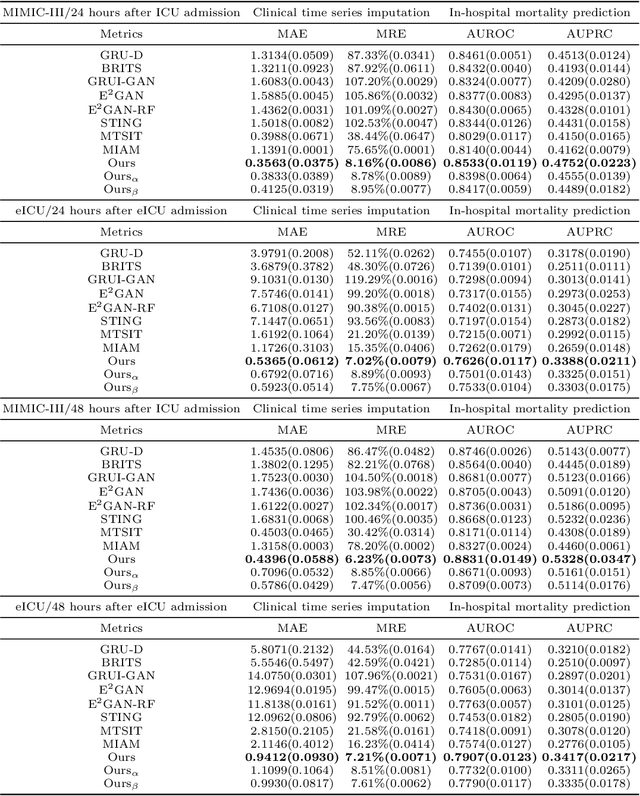

Predicting the risk of in-hospital mortality from electronic health records (EHRs) has received considerable attention. Such predictions will provide early warning of a patient's health condition to healthcare professionals so that timely interventions can be taken. This prediction task is challenging since EHR data are intrinsically irregular, with not only many missing values but also varying time intervals between medical records. Existing approaches focus on exploiting the variable correlations in patient medical records to impute missing values and establishing time-decay mechanisms to deal with such irregularity. This paper presents a novel contrastive learning-based imputation-prediction network for predicting in-hospital mortality risks using EHR data. Our approach introduces graph analysis-based patient stratification modeling in the imputation process to group similar patients. This allows information of similar patients only to be used, in addition to personal contextual information, for missing value imputation. Moreover, our approach can integrate contrastive learning into the proposed network architecture to enhance patient representation learning and predictive performance on the classification task. Experiments on two real-world EHR datasets show that our approach outperforms the state-of-the-art approaches in both imputation and prediction tasks.
Contextual Bandits with Budgeted Information Reveal
May 29, 2023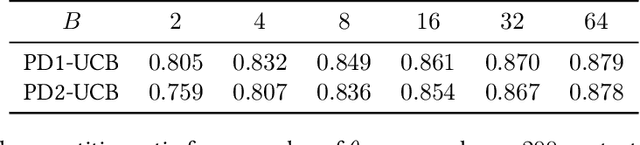
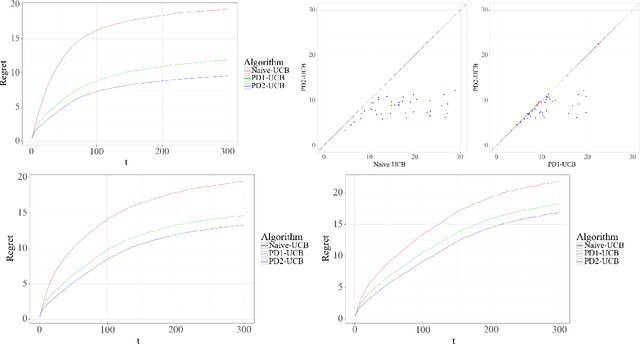
Contextual bandit algorithms are commonly used in digital health to recommend personalized treatments. However, to ensure the effectiveness of the treatments, patients are often requested to take actions that have no immediate benefit to them, which we refer to as pro-treatment actions. In practice, clinicians have a limited budget to encourage patients to take these actions and collect additional information. We introduce a novel optimization and learning algorithm to address this problem. This algorithm effectively combines the strengths of two algorithmic approaches in a seamless manner, including 1) an online primal-dual algorithm for deciding the optimal timing to reach out to patients, and 2) a contextual bandit learning algorithm to deliver personalized treatment to the patient. We prove that this algorithm admits a sub-linear regret bound. We illustrate the usefulness of this algorithm on both synthetic and real-world data.
Mobility-Aware Computation Offloading for Swarm Robotics using Deep Reinforcement Learning
Aug 22, 2023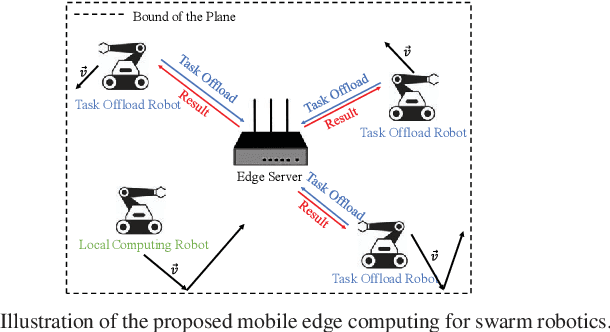
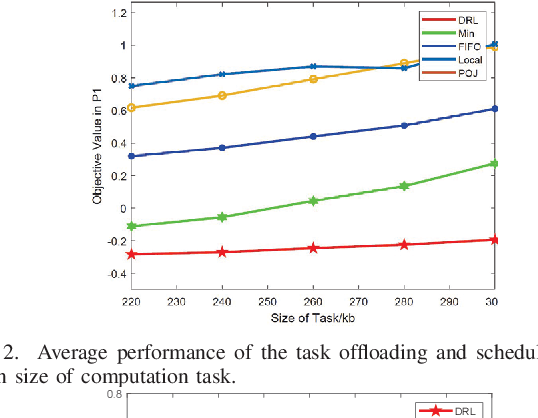
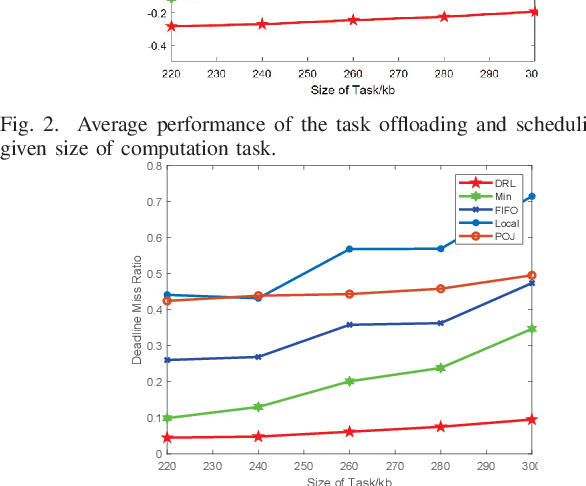
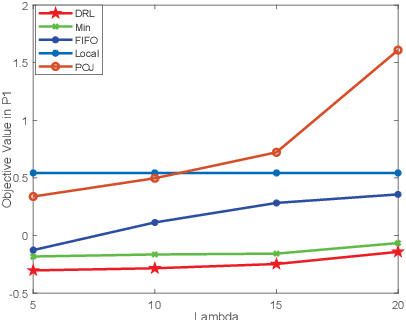
Swarm robotics is envisioned to automate a large number of dirty, dangerous, and dull tasks. Robots have limited energy, computation capability, and communication resources. Therefore, current swarm robotics have a small number of robots, which can only provide limited spatio-temporal information. In this paper, we propose to leverage the mobile edge computing to alleviate the computation burden. We develop an effective solution based on a mobility-aware deep reinforcement learning model at the edge server side for computing scheduling and resource. Our results show that the proposed approach can meet delay requirements and guarantee computation precision by using minimum robot energy.
Action Recognition with Multi-stream Motion Modeling and Mutual Information Maximization
Jun 13, 2023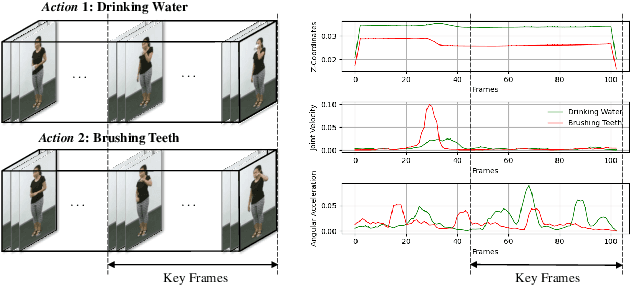
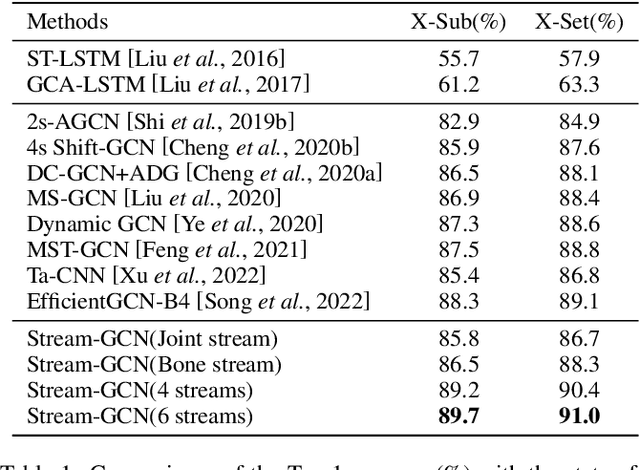
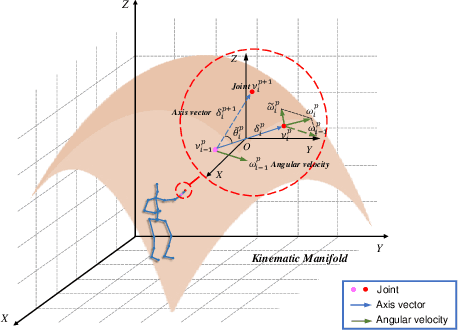
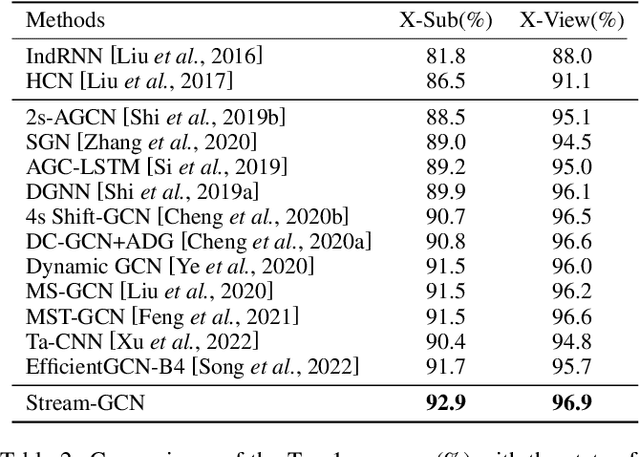
Action recognition has long been a fundamental and intriguing problem in artificial intelligence. The task is challenging due to the high dimensionality nature of an action, as well as the subtle motion details to be considered. Current state-of-the-art approaches typically learn from articulated motion sequences in the straightforward 3D Euclidean space. However, the vanilla Euclidean space is not efficient for modeling important motion characteristics such as the joint-wise angular acceleration, which reveals the driving force behind the motion. Moreover, current methods typically attend to each channel equally and lack theoretical constrains on extracting task-relevant features from the input. In this paper, we seek to tackle these challenges from three aspects: (1) We propose to incorporate an acceleration representation, explicitly modeling the higher-order variations in motion. (2) We introduce a novel Stream-GCN network equipped with multi-stream components and channel attention, where different representations (i.e., streams) supplement each other towards a more precise action recognition while attention capitalizes on those important channels. (3) We explore feature-level supervision for maximizing the extraction of task-relevant information and formulate this into a mutual information loss. Empirically, our approach sets the new state-of-the-art performance on three benchmark datasets, NTU RGB+D, NTU RGB+D 120, and NW-UCLA. Our code is anonymously released at https://github.com/ActionR-Group/Stream-GCN, hoping to inspire the community.
Adaptive Face Recognition Using Adversarial Information Network
May 23, 2023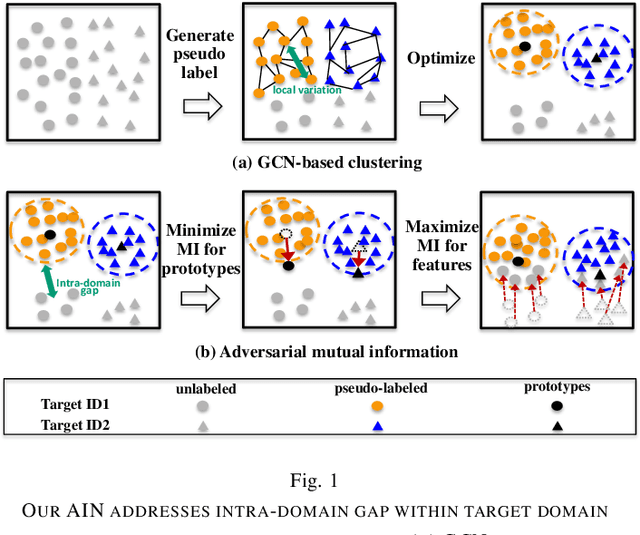

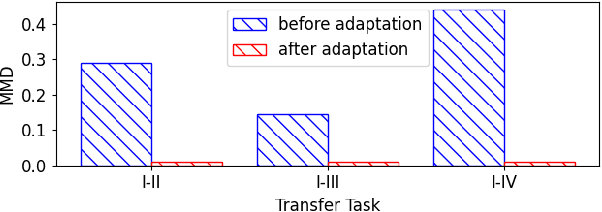
In many real-world applications, face recognition models often degenerate when training data (referred to as source domain) are different from testing data (referred to as target domain). To alleviate this mismatch caused by some factors like pose and skin tone, the utilization of pseudo-labels generated by clustering algorithms is an effective way in unsupervised domain adaptation. However, they always miss some hard positive samples. Supervision on pseudo-labeled samples attracts them towards their prototypes and would cause an intra-domain gap between pseudo-labeled samples and the remaining unlabeled samples within target domain, which results in the lack of discrimination in face recognition. In this paper, considering the particularity of face recognition, we propose a novel adversarial information network (AIN) to address it. First, a novel adversarial mutual information (MI) loss is proposed to alternately minimize MI with respect to the target classifier and maximize MI with respect to the feature extractor. By this min-max manner, the positions of target prototypes are adaptively modified which makes unlabeled images clustered more easily such that intra-domain gap can be mitigated. Second, to assist adversarial MI loss, we utilize a graph convolution network to predict linkage likelihoods between target data and generate pseudo-labels. It leverages valuable information in the context of nodes and can achieve more reliable results. The proposed method is evaluated under two scenarios, i.e., domain adaptation across poses and image conditions, and domain adaptation across faces with different skin tones. Extensive experiments show that AIN successfully improves cross-domain generalization and offers a new state-of-the-art on RFW dataset.
Meta-learning enhanced next POI recommendation by leveraging check-ins from auxiliary cities
Aug 18, 2023Most existing point-of-interest (POI) recommenders aim to capture user preference by employing city-level user historical check-ins, thus facilitating users' exploration of the city. However, the scarcity of city-level user check-ins brings a significant challenge to user preference learning. Although prior studies attempt to mitigate this challenge by exploiting various context information, e.g., spatio-temporal information, they ignore to transfer the knowledge (i.e., common behavioral pattern) from other relevant cities (i.e., auxiliary cities). In this paper, we investigate the effect of knowledge distilled from auxiliary cities and thus propose a novel Meta-learning Enhanced next POI Recommendation framework (MERec). The MERec leverages the correlation of check-in behaviors among various cities into the meta-learning paradigm to help infer user preference in the target city, by holding the principle of "paying more attention to more correlated knowledge". Particularly, a city-level correlation strategy is devised to attentively capture common patterns among cities, so as to transfer more relevant knowledge from more correlated cities. Extensive experiments verify the superiority of the proposed MERec against state-of-the-art algorithms.
Spatio-Temporal Branching for Motion Prediction using Motion Increments
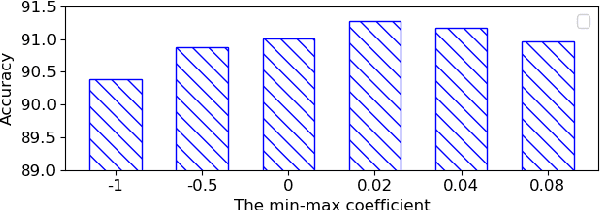
Aug 11, 2023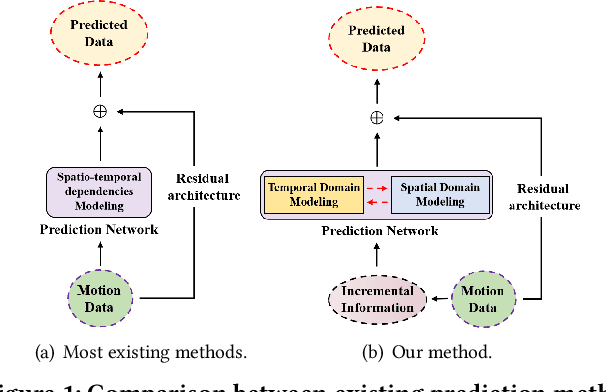
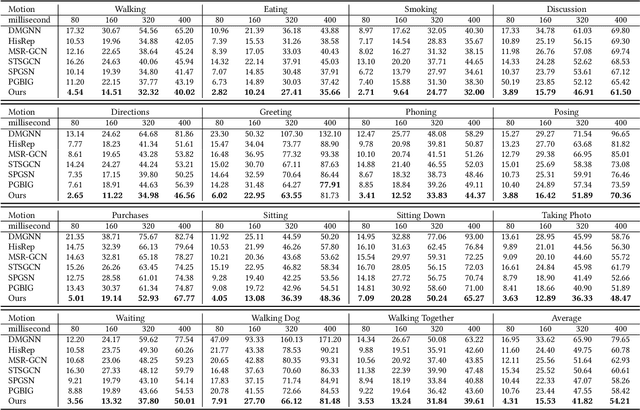
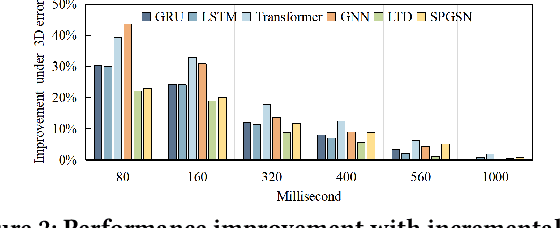
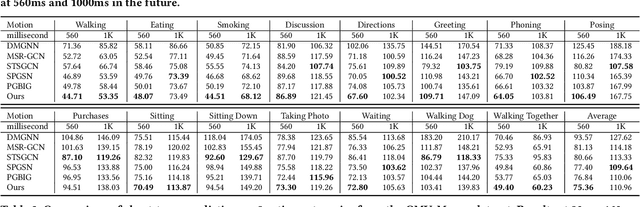
Human motion prediction (HMP) has emerged as a popular research topic due to its diverse applications, but it remains a challenging task due to the stochastic and aperiodic nature of future poses. Traditional methods rely on hand-crafted features and machine learning techniques, which often struggle to model the complex dynamics of human motion. Recent deep learning-based methods have achieved success by learning spatio-temporal representations of motion, but these models often overlook the reliability of motion data. Additionally, the temporal and spatial dependencies of skeleton nodes are distinct. The temporal relationship captures motion information over time, while the spatial relationship describes body structure and the relationships between different nodes. In this paper, we propose a novel spatio-temporal branching network using incremental information for HMP, which decouples the learning of temporal-domain and spatial-domain features, extracts more motion information, and achieves complementary cross-domain knowledge learning through knowledge distillation. Our approach effectively reduces noise interference and provides more expressive information for characterizing motion by separately extracting temporal and spatial features. We evaluate our approach on standard HMP benchmarks and outperform state-of-the-art methods in terms of prediction accuracy.
Scalable Incomplete Multi-View Clustering with Structure Alignment
Aug 31, 2023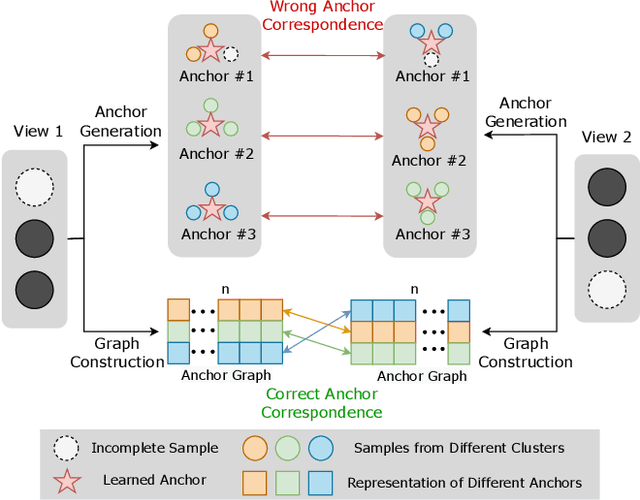
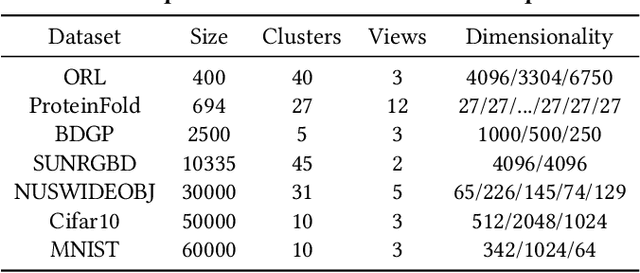
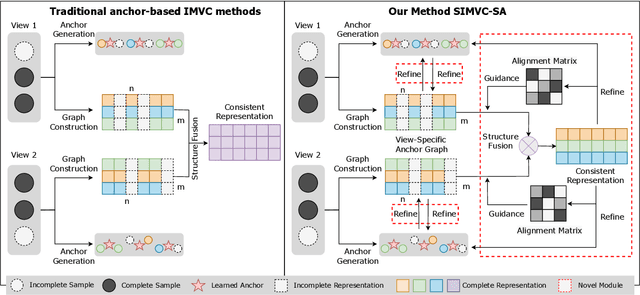
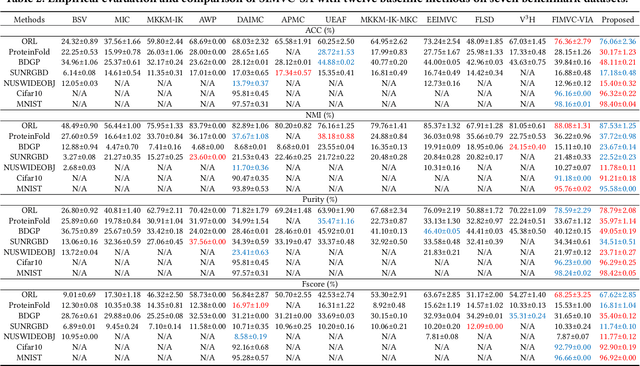
The success of existing multi-view clustering (MVC) relies on the assumption that all views are complete. However, samples are usually partially available due to data corruption or sensor malfunction, which raises the research of incomplete multi-view clustering (IMVC). Although several anchor-based IMVC methods have been proposed to process the large-scale incomplete data, they still suffer from the following drawbacks: i) Most existing approaches neglect the inter-view discrepancy and enforce cross-view representation to be consistent, which would corrupt the representation capability of the model; ii) Due to the samples disparity between different views, the learned anchor might be misaligned, which we referred as the Anchor-Unaligned Problem for Incomplete data (AUP-ID). Such the AUP-ID would cause inaccurate graph fusion and degrades clustering performance. To tackle these issues, we propose a novel incomplete anchor graph learning framework termed Scalable Incomplete Multi-View Clustering with Structure Alignment (SIMVC-SA). Specially, we construct the view-specific anchor graph to capture the complementary information from different views. In order to solve the AUP-ID, we propose a novel structure alignment module to refine the cross-view anchor correspondence. Meanwhile, the anchor graph construction and alignment are jointly optimized in our unified framework to enhance clustering quality. Through anchor graph construction instead of full graphs, the time and space complexity of the proposed SIMVC-SA is proven to be linearly correlated with the number of samples. Extensive experiments on seven incomplete benchmark datasets demonstrate the effectiveness and efficiency of our proposed method. Our code is publicly available at https://github.com/wy1019/SIMVC-SA.
In-class Data Analysis Replications: Teaching Students while Testing Science
Aug 31, 2023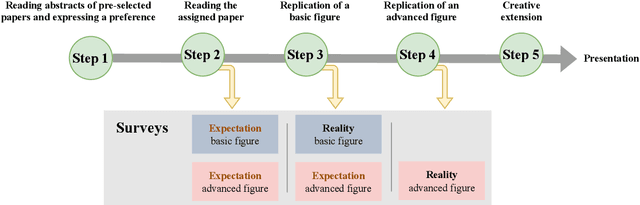

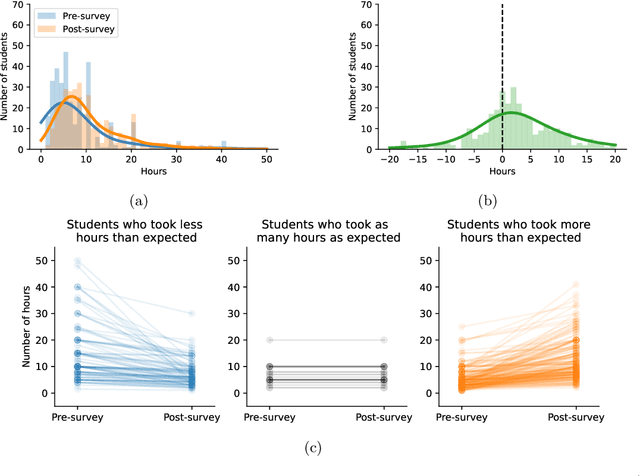
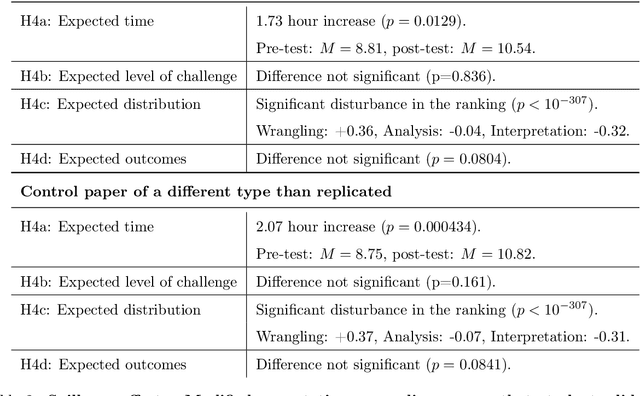
Science is facing a reproducibility crisis. Previous work has proposed incorporating data analysis replications into classrooms as a potential solution. However, despite the potential benefits, it is unclear whether this approach is feasible, and if so, what the involved stakeholders-students, educators, and scientists-should expect from it. Can students perform a data analysis replication over the course of a class? What are the costs and benefits for educators? And how can this solution help benchmark and improve the state of science? In the present study, we incorporated data analysis replications in the project component of the Applied Data Analysis course (CS-401) taught at EPFL (N=354 students). Here we report pre-registered findings based on surveys administered throughout the course. First, we demonstrate that students can replicate previously published scientific papers, most of them qualitatively and some exactly. We find discrepancies between what students expect of data analysis replications and what they experience by doing them along with changes in expectations about reproducibility, which together serve as evidence of attitude shifts to foster students' critical thinking. Second, we provide information for educators about how much overhead is needed to incorporate replications into the classroom and identify concerns that replications bring as compared to more traditional assignments. Third, we identify tangible benefits of the in-class data analysis replications for scientific communities, such as a collection of replication reports and insights about replication barriers in scientific work that should be avoided going forward. Overall, we demonstrate that incorporating replication tasks into a large data science class can increase the reproducibility of scientific work as a by-product of data science instruction, thus benefiting both science and students.