 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Implicit Discriminative Knowledge Learning for Visible-Infrared Person Re-Identification
Mar 26, 2024
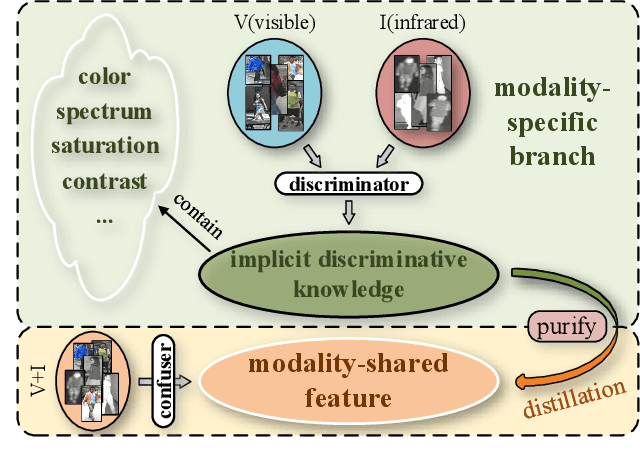
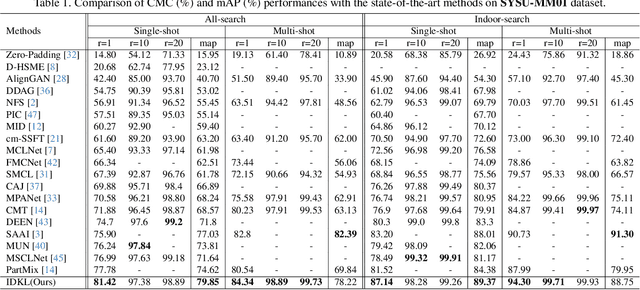
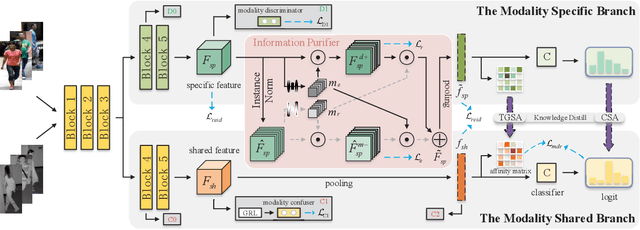
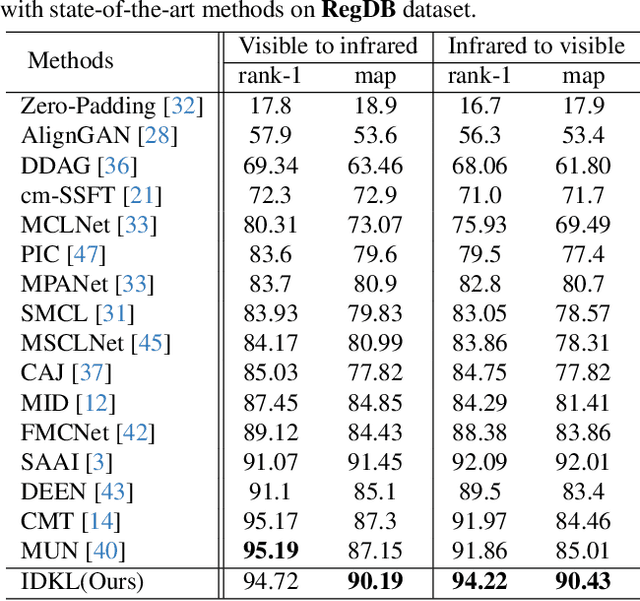
Visible-Infrared Person Re-identification (VI-ReID) is a challenging cross-modal pedestrian retrieval task, due to significant intra-class variations and cross-modal discrepancies among different cameras. Existing works mainly focus on embedding images of different modalities into a unified space to mine modality-shared features. They only seek distinctive information within these shared features, while ignoring the identity-aware useful information that is implicit in the modality-specific features. To address this issue, we propose a novel Implicit Discriminative Knowledge Learning (IDKL) network to uncover and leverage the implicit discriminative information contained within the modality-specific. First, we extract modality-specific and modality-shared features using a novel dual-stream network. Then, the modality-specific features undergo purification to reduce their modality style discrepancies while preserving identity-aware discriminative knowledge. Subsequently, this kind of implicit knowledge is distilled into the modality-shared feature to enhance its distinctiveness. Finally, an alignment loss is proposed to minimize modality discrepancy on enhanced modality-shared features. Extensive experiments on multiple public datasets demonstrate the superiority of IDKL network over the state-of-the-art methods. Code is available at https://github.com/1KK077/IDKL.
Channel Deduction: A New Learning Framework to Acquire Channel from Outdated Samples and Coarse Estimate
Mar 28, 2024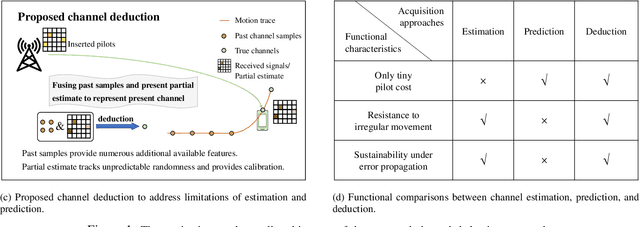
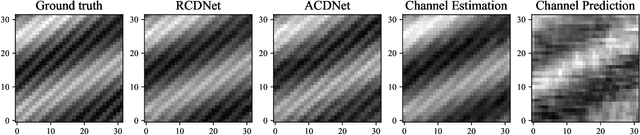
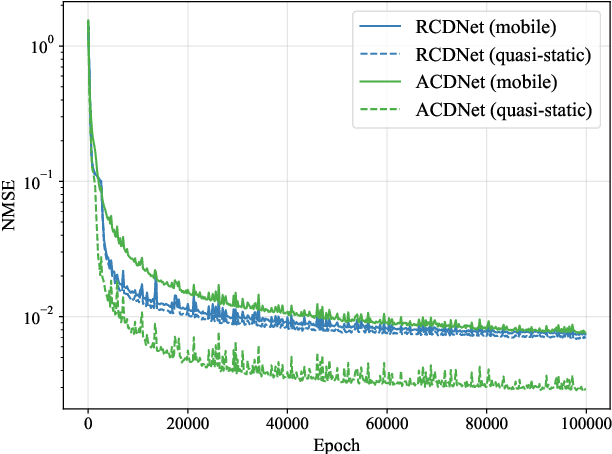
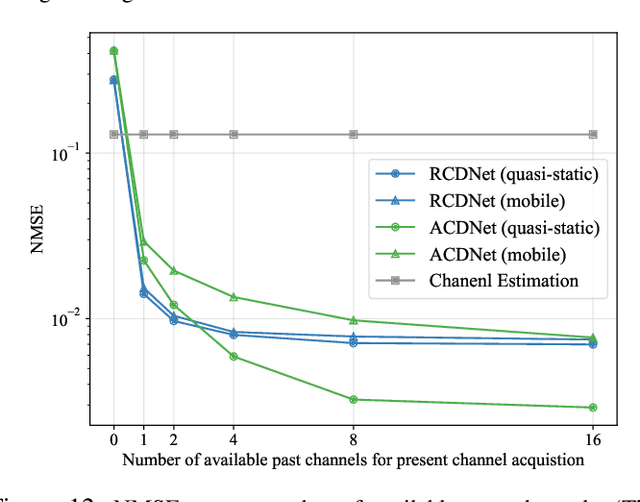
How to reduce the pilot overhead required for channel estimation? How to deal with the channel dynamic changes and error propagation in channel prediction? To jointly address these two critical issues in next-generation transceiver design, in this paper, we propose a novel framework named channel deduction for high-dimensional channel acquisition in multiple-input multiple-output (MIMO)-orthogonal frequency division multiplexing (OFDM) systems. Specifically, it makes use of the outdated channel information of past time slots, performs coarse estimation for the current channel with a relatively small number of pilots, and then fuses these two information to obtain a complete representation of the present channel. The rationale is to align the current channel representation to both the latent channel features within the past samples and the coarse estimate of current channel at the pilots, which, in a sense, behaves as a complementary combination of estimation and prediction and thus reduces the overall overhead. To fully exploit the highly nonlinear correlations in time, space, and frequency domains, we resort to learning-based implementation approaches. By using the highly efficient complex-domain multilayer perceptron (MLP)-mixer for crossing space-frequency domain representation and the recurrence-based or attention-based mechanisms for the past-present interaction, we respectively design two different channel deduction neural networks (CDNets). We provide a general procedure of data collection, training, and deployment to standardize the application of CDNets. Comprehensive experimental evaluations in accuracy, robustness, and efficiency demonstrate the superiority of the proposed approach, which reduces the pilot overhead by up to 88.9% compared to state-of-the-art estimation approaches and enables continuous operating even under unknown user movement and error propagation.
Multi-Agent Clarity-Aware Dynamic Coverage with Gaussian Processes
Mar 26, 2024This paper presents two algorithms for multi-agent dynamic coverage in spatiotemporal environments, where the coverage algorithms are informed by the method of data assimilation. In particular, we show that by considering the information assimilation algorithm, here a Numerical Gaussian Process Kalman Filter, the influence of measurements taken at one position on the uncertainty of the estimate at another location can be computed. We use this relationship to propose new coverage algorithms. Furthermore, we show that the controllers naturally extend to the multi-agent context, allowing for a distributed-control central-information paradigm for multi-agent coverage. Finally, we demonstrate the algorithms through a realistic simulation of a team of UAVs collecting wind data over a region in Austria.
Talk3D: High-Fidelity Talking Portrait Synthesis via Personalized 3D Generative Prior
Mar 29, 2024
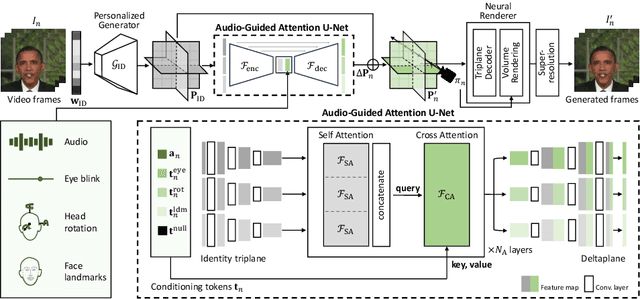

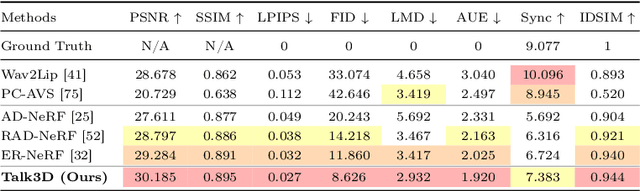
Recent methods for audio-driven talking head synthesis often optimize neural radiance fields (NeRF) on a monocular talking portrait video, leveraging its capability to render high-fidelity and 3D-consistent novel-view frames. However, they often struggle to reconstruct complete face geometry due to the absence of comprehensive 3D information in the input monocular videos. In this paper, we introduce a novel audio-driven talking head synthesis framework, called Talk3D, that can faithfully reconstruct its plausible facial geometries by effectively adopting the pre-trained 3D-aware generative prior. Given the personalized 3D generative model, we present a novel audio-guided attention U-Net architecture that predicts the dynamic face variations in the NeRF space driven by audio. Furthermore, our model is further modulated by audio-unrelated conditioning tokens which effectively disentangle variations unrelated to audio features. Compared to existing methods, our method excels in generating realistic facial geometries even under extreme head poses. We also conduct extensive experiments showing our approach surpasses state-of-the-art benchmarks in terms of both quantitative and qualitative evaluations.
SGD: Street View Synthesis with Gaussian Splatting and Diffusion Prior
Mar 29, 2024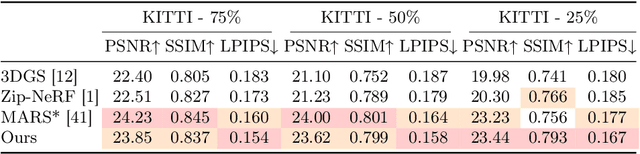
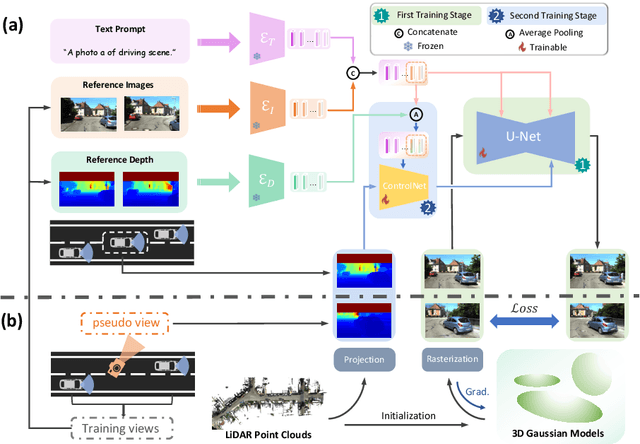
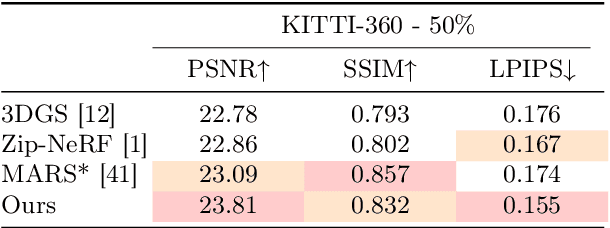
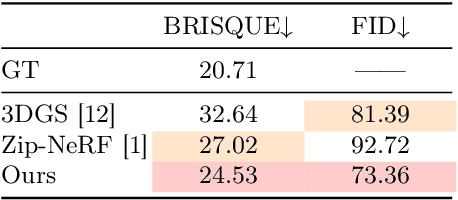
Novel View Synthesis (NVS) for street scenes play a critical role in the autonomous driving simulation. The current mainstream technique to achieve it is neural rendering, such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS). Although thrilling progress has been made, when handling street scenes, current methods struggle to maintain rendering quality at the viewpoint that deviates significantly from the training viewpoints. This issue stems from the sparse training views captured by a fixed camera on a moving vehicle. To tackle this problem, we propose a novel approach that enhances the capacity of 3DGS by leveraging prior from a Diffusion Model along with complementary multi-modal data. Specifically, we first fine-tune a Diffusion Model by adding images from adjacent frames as condition, meanwhile exploiting depth data from LiDAR point clouds to supply additional spatial information. Then we apply the Diffusion Model to regularize the 3DGS at unseen views during training. Experimental results validate the effectiveness of our method compared with current state-of-the-art models, and demonstrate its advance in rendering images from broader views.
Beyond the Known: Novel Class Discovery for Open-world Graph Learning
Mar 29, 2024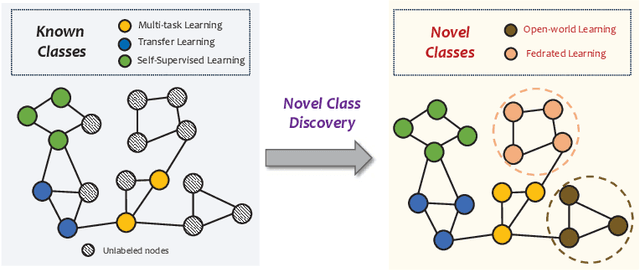
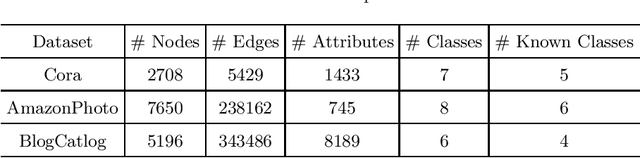
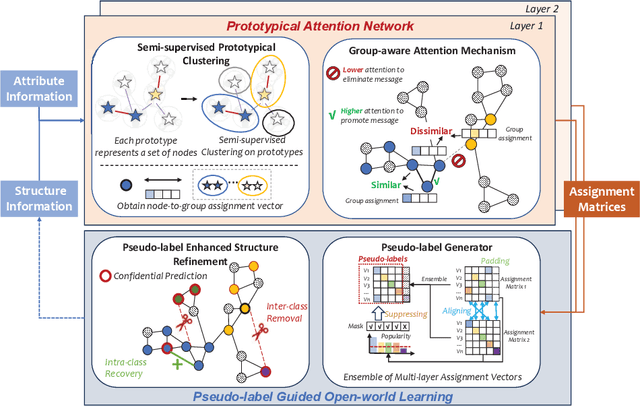
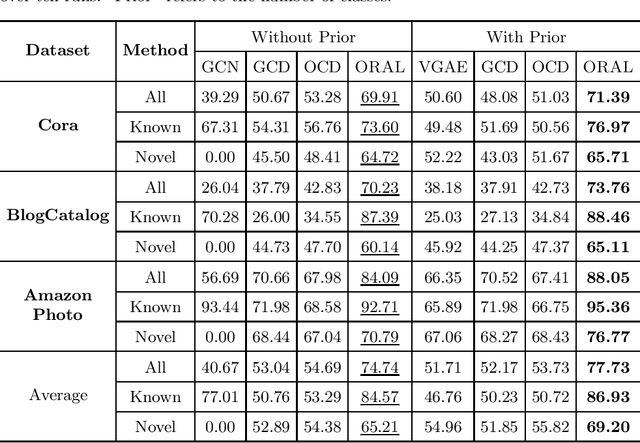
Node classification on graphs is of great importance in many applications. Due to the limited labeling capability and evolution in real-world open scenarios, novel classes can emerge on unlabeled testing nodes. However, little attention has been paid to novel class discovery on graphs. Discovering novel classes is challenging as novel and known class nodes are correlated by edges, which makes their representations indistinguishable when applying message passing GNNs. Furthermore, the novel classes lack labeling information to guide the learning process. In this paper, we propose a novel method Open-world gRAph neuraL network (ORAL) to tackle these challenges. ORAL first detects correlations between classes through semi-supervised prototypical learning. Inter-class correlations are subsequently eliminated by the prototypical attention network, leading to distinctive representations for different classes. Furthermore, to fully explore multi-scale graph features for alleviating label deficiencies, ORAL generates pseudo-labels by aligning and ensembling label estimations from multiple stacked prototypical attention networks. Extensive experiments on several benchmark datasets show the effectiveness of our proposed method.
MI-NeRF: Learning a Single Face NeRF from Multiple Identities
Mar 29, 2024
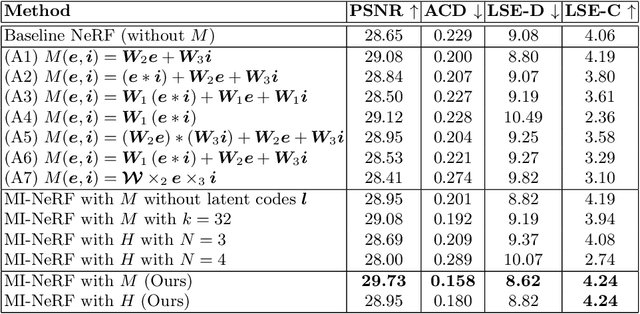
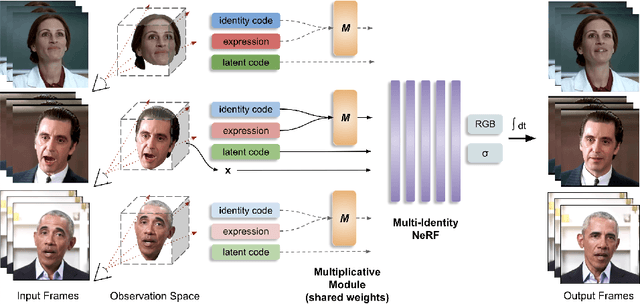
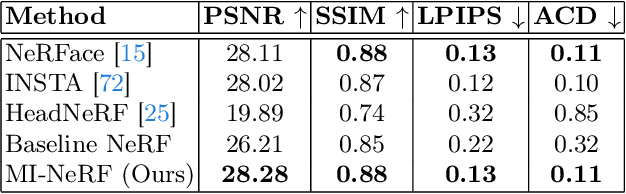
In this work, we introduce a method that learns a single dynamic neural radiance field (NeRF) from monocular talking face videos of multiple identities. NeRFs have shown remarkable results in modeling the 4D dynamics and appearance of human faces. However, they require per-identity optimization. Although recent approaches have proposed techniques to reduce the training and rendering time, increasing the number of identities can be expensive. We introduce MI-NeRF (multi-identity NeRF), a single unified network that models complex non-rigid facial motion for multiple identities, using only monocular videos of arbitrary length. The core premise in our method is to learn the non-linear interactions between identity and non-identity specific information with a multiplicative module. By training on multiple videos simultaneously, MI-NeRF not only reduces the total training time compared to standard single-identity NeRFs, but also demonstrates robustness in synthesizing novel expressions for any input identity. We present results for both facial expression transfer and talking face video synthesis. Our method can be further personalized for a target identity given only a short video.
Learning using granularity statistical invariants for classification
Mar 29, 2024
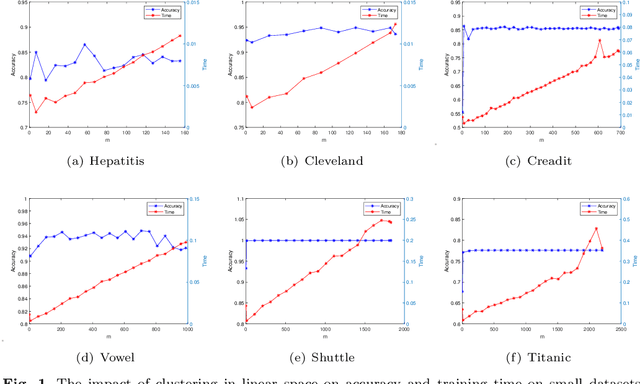
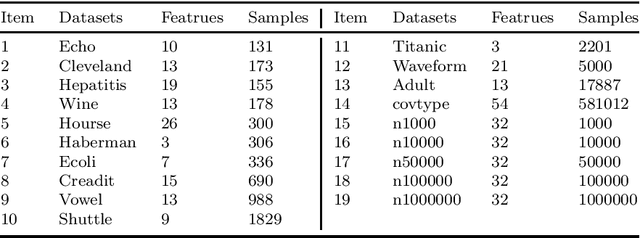
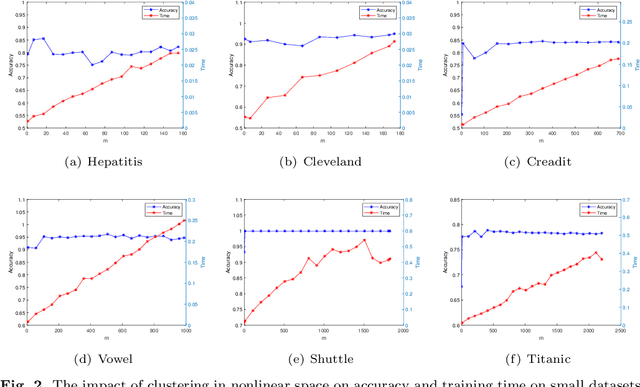
Learning using statistical invariants (LUSI) is a new learning paradigm, which adopts weak convergence mechanism, and can be applied to a wider range of classification problems. However, the computation cost of invariant matrices in LUSI is high for large-scale datasets during training. To settle this issue, this paper introduces a granularity statistical invariant for LUSI, and develops a new learning paradigm called learning using granularity statistical invariants (LUGSI). LUGSI employs both strong and weak convergence mechanisms, taking a perspective of minimizing expected risk. As far as we know, it is the first time to construct granularity statistical invariants. Compared to LUSI, the introduction of this new statistical invariant brings two advantages. Firstly, it enhances the structural information of the data. Secondly, LUGSI transforms a large invariant matrix into a smaller one by maximizing the distance between classes, achieving feasibility for large-scale datasets classification problems and significantly enhancing the training speed of model operations. Experimental results indicate that LUGSI not only exhibits improved generalization capabilities but also demonstrates faster training speed, particularly for large-scale datasets.
Using Images as Covariates: Measuring Curb Appeal with Deep Learning
Mar 29, 2024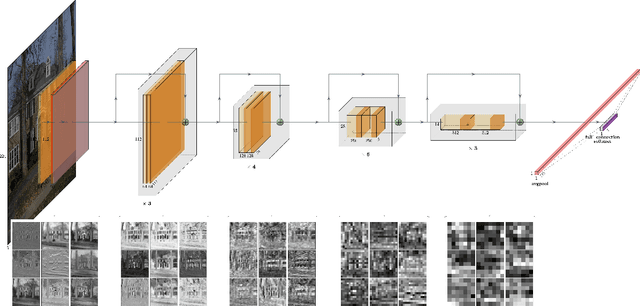
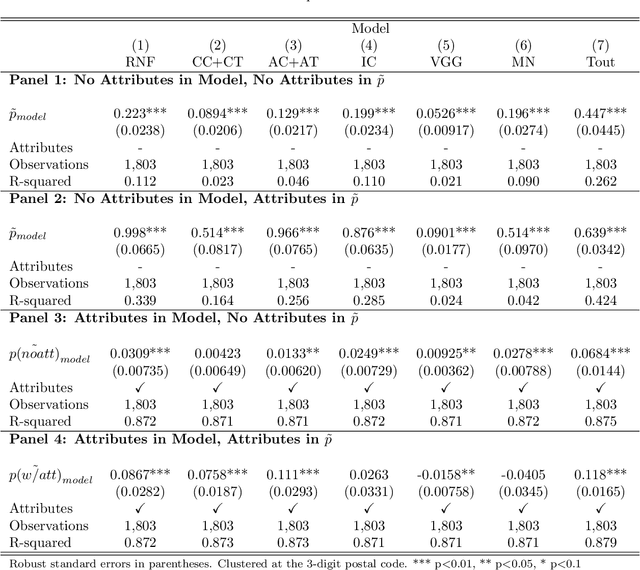

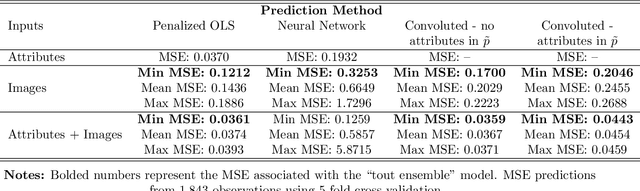
This paper details an innovative methodology to integrate image data into traditional econometric models. Motivated by forecasting sales prices for residential real estate, we harness the power of deep learning to add "information" contained in images as covariates. Specifically, images of homes were categorized and encoded using an ensemble of image classifiers (ResNet-50, VGG16, MobileNet, and Inception V3). Unique features presented within each image were further encoded through panoptic segmentation. Forecasts from a neural network trained on the encoded data results in improved out-of-sample predictive power. We also combine these image-based forecasts with standard hedonic real estate property and location characteristics, resulting in a unified dataset. We show that image-based forecasts increase the accuracy of hedonic forecasts when encoded features are regarded as additional covariates. We also attempt to "explain" which covariates the image-based forecasts are most highly correlated with. The study exemplifies the benefits of interdisciplinary methodologies, merging machine learning and econometrics to harness untapped data sources for more accurate forecasting.
Cyber-Security Knowledge Graph Generation by Hierarchical Nonnegative Matrix Factorization
Mar 26, 2024Much of human knowledge in cybersecurity is encapsulated within the ever-growing volume of scientific papers. As this textual data continues to expand, the importance of document organization methods becomes increasingly crucial for extracting actionable insights hidden within large text datasets. Knowledge Graphs (KGs) serve as a means to store factual information in a structured manner, providing explicit, interpretable knowledge that includes domain-specific information from the cybersecurity scientific literature. One of the challenges in constructing a KG from scientific literature is the extraction of ontology from unstructured text. In this paper, we address this topic and introduce a method for building a multi-modal KG by extracting structured ontology from scientific papers. We demonstrate this concept in the cybersecurity domain. One modality of the KG represents observable information from the papers, such as the categories in which they were published or the authors. The second modality uncovers latent (hidden) patterns of text extracted through hierarchical and semantic non-negative matrix factorization (NMF), such as named entities, topics or clusters, and keywords. We illustrate this concept by consolidating more than two million scientific papers uploaded to arXiv into the cyber-domain, using hierarchical and semantic NMF, and by building a cyber-domain-specific KG.