 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Affine-Transformation-Invariant Image Classification by Differentiable Arithmetic Distribution Module
Sep 01, 2023
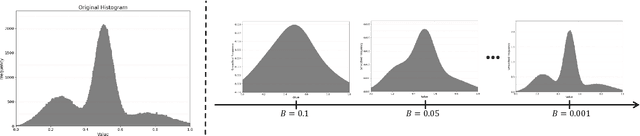
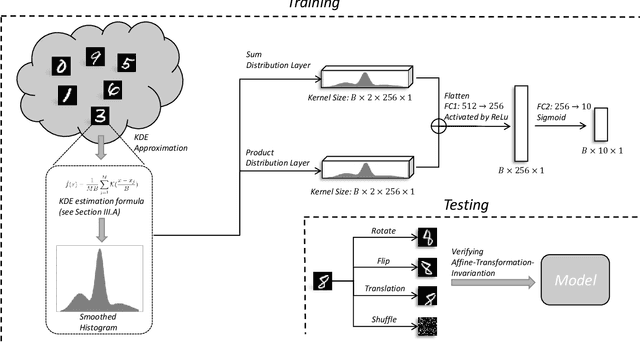
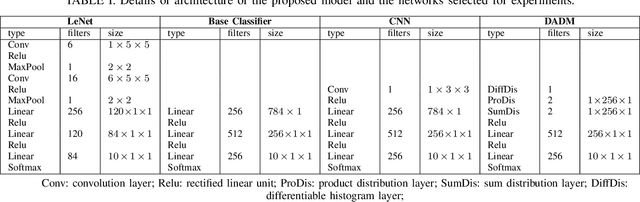

Although Convolutional Neural Networks (CNNs) have achieved promising results in image classification, they still are vulnerable to affine transformations including rotation, translation, flip and shuffle. The drawback motivates us to design a module which can alleviate the impact from different affine transformations. Thus, in this work, we introduce a more robust substitute by incorporating distribution learning techniques, focusing particularly on learning the spatial distribution information of pixels in images. To rectify the issue of non-differentiability of prior distribution learning methods that rely on traditional histograms, we adopt the Kernel Density Estimation (KDE) to formulate differentiable histograms. On this foundation, we present a novel Differentiable Arithmetic Distribution Module (DADM), which is designed to extract the intrinsic probability distributions from images. The proposed approach is able to enhance the model's robustness to affine transformations without sacrificing its feature extraction capabilities, thus bridging the gap between traditional CNNs and distribution-based learning. We validate the effectiveness of the proposed approach through ablation study and comparative experiments with LeNet.
MeDM: Mediating Image Diffusion Models for Video-to-Video Translation with Temporal Correspondence Guidance
Sep 01, 2023
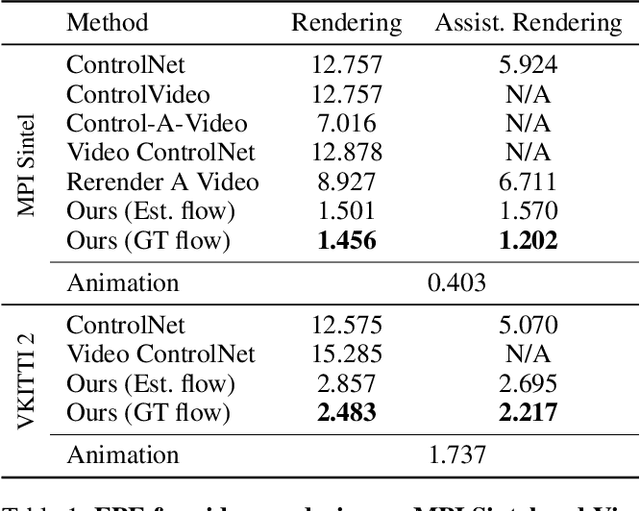
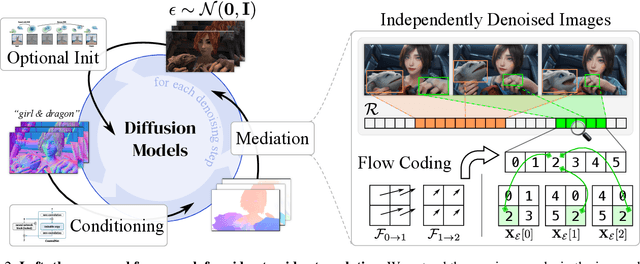
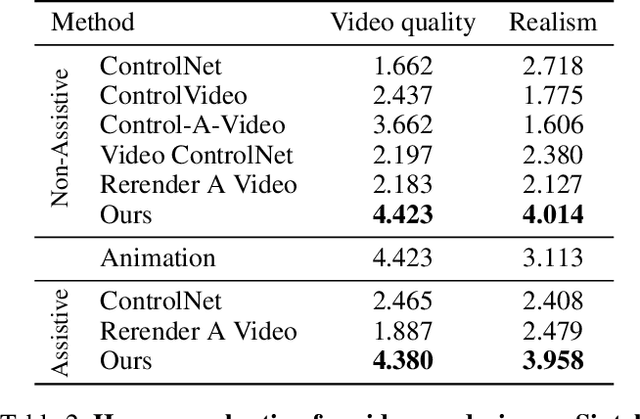
This study introduces an efficient and effective method, MeDM, that utilizes pre-trained image Diffusion Models for video-to-video translation with consistent temporal flow. The proposed framework can render videos from scene position information, such as a normal G-buffer, or perform text-guided editing on videos captured in real-world scenarios. We employ explicit optical flows to construct a practical coding that enforces physical constraints on generated frames and mediates independent frame-wise scores. By leveraging this coding, maintaining temporal consistency in the generated videos can be framed as an optimization problem with a closed-form solution. To ensure compatibility with Stable Diffusion, we also suggest a workaround for modifying observed-space scores in latent-space Diffusion Models. Notably, MeDM does not require fine-tuning or test-time optimization of the Diffusion Models. Through extensive qualitative, quantitative, and subjective experiments on various benchmarks, the study demonstrates the effectiveness and superiority of the proposed approach. Project page can be found at https://medm2023.github.io
Why do universal adversarial attacks work on large language models?: Geometry might be the answer
Sep 01, 2023Transformer based large language models with emergent capabilities are becoming increasingly ubiquitous in society. However, the task of understanding and interpreting their internal workings, in the context of adversarial attacks, remains largely unsolved. Gradient-based universal adversarial attacks have been shown to be highly effective on large language models and potentially dangerous due to their input-agnostic nature. This work presents a novel geometric perspective explaining universal adversarial attacks on large language models. By attacking the 117M parameter GPT-2 model, we find evidence indicating that universal adversarial triggers could be embedding vectors which merely approximate the semantic information in their adversarial training region. This hypothesis is supported by white-box model analysis comprising dimensionality reduction and similarity measurement of hidden representations. We believe this new geometric perspective on the underlying mechanism driving universal attacks could help us gain deeper insight into the internal workings and failure modes of LLMs, thus enabling their mitigation.
Domain Information Control at Inference Time for Acoustic Scene Classification
Jun 13, 2023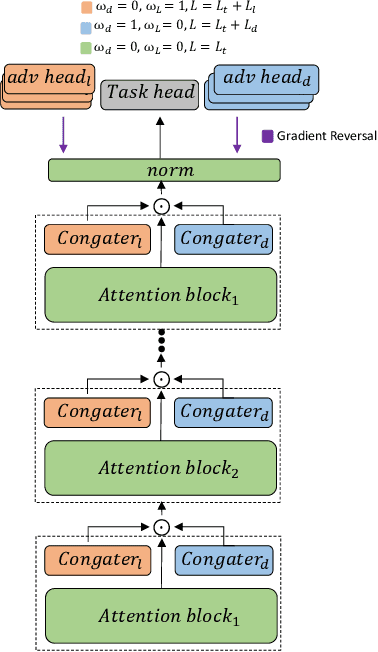
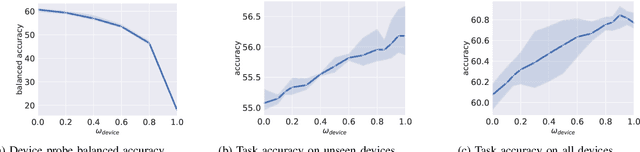

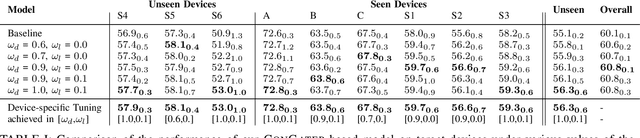
Domain shift is considered a challenge in machine learning as it causes significant degradation of model performance. In the Acoustic Scene Classification task (ASC), domain shift is mainly caused by different recording devices. Several studies have already targeted domain generalization to improve the performance of ASC models on unseen domains, such as new devices. Recently, the Controllable Gate Adapter ConGater has been proposed in Natural Language Processing to address the biased training data problem. ConGater allows controlling the debiasing process at inference time. ConGater's main advantage is the continuous and selective debiasing of a trained model, during inference. In this work, we adapt ConGater to the audio spectrogram transformer for an acoustic scene classification task. We show that ConGater can be used to selectively adapt the learned representations to be invariant to device domain shifts such as recording devices. Our analysis shows that ConGater can progressively remove device information from the learned representations and improve the model generalization, especially under domain shift conditions (e.g. unseen devices). We show that information removal can be extended to both device and location domain. Finally, we demonstrate ConGater's ability to enhance specific device performance without further training.
Unveiling the Role of Message Passing in Dual-Privacy Preservation on GNNs
Aug 25, 2023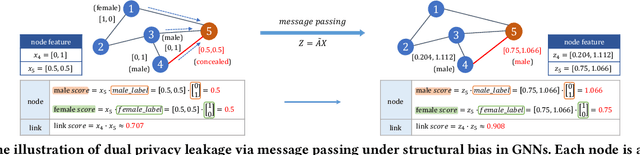

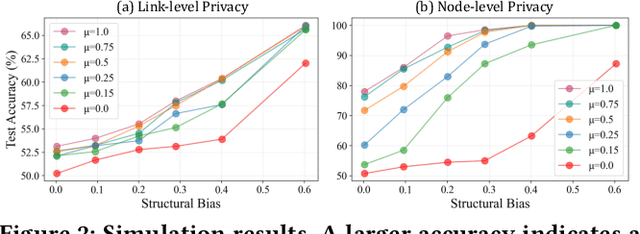
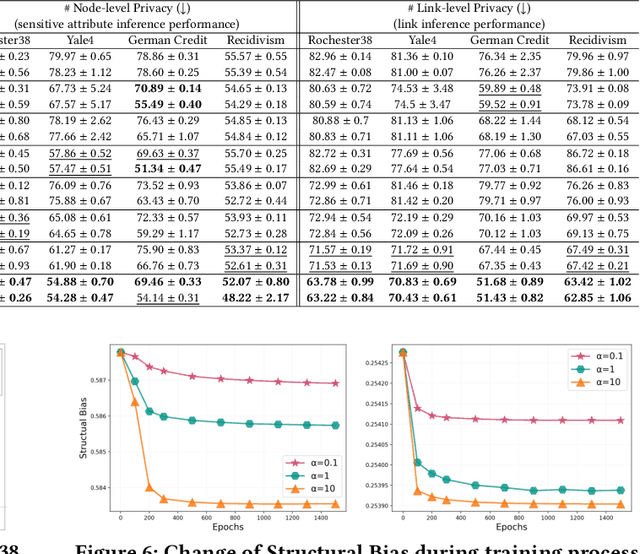
Graph Neural Networks (GNNs) are powerful tools for learning representations on graphs, such as social networks. However, their vulnerability to privacy inference attacks restricts their practicality, especially in high-stake domains. To address this issue, privacy-preserving GNNs have been proposed, focusing on preserving node and/or link privacy. This work takes a step back and investigates how GNNs contribute to privacy leakage. Through theoretical analysis and simulations, we identify message passing under structural bias as the core component that allows GNNs to \textit{propagate} and \textit{amplify} privacy leakage. Building upon these findings, we propose a principled privacy-preserving GNN framework that effectively safeguards both node and link privacy, referred to as dual-privacy preservation. The framework comprises three major modules: a Sensitive Information Obfuscation Module that removes sensitive information from node embeddings, a Dynamic Structure Debiasing Module that dynamically corrects the structural bias, and an Adversarial Learning Module that optimizes the privacy-utility trade-off. Experimental results on four benchmark datasets validate the effectiveness of the proposed model in protecting both node and link privacy while preserving high utility for downstream tasks, such as node classification.
RestNet: Boosting Cross-Domain Few-Shot Segmentation with Residual Transformation Network
Aug 25, 2023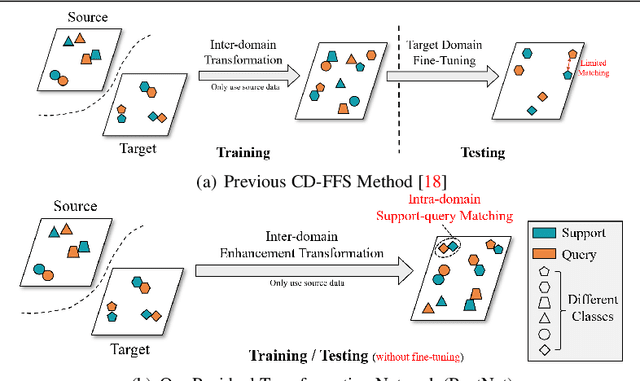
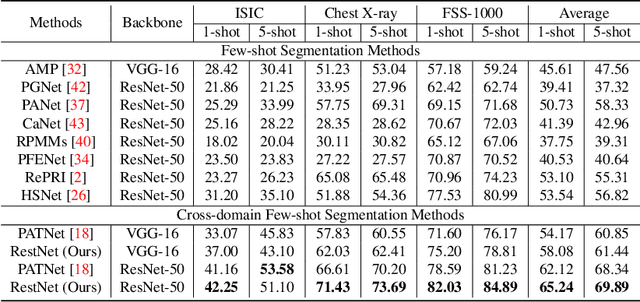
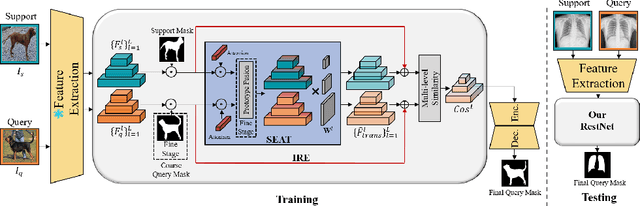

Cross-domain few-shot segmentation (CD-FSS) aims to achieve semantic segmentation in previously unseen domains with a limited number of annotated samples. Although existing CD-FSS models focus on cross-domain feature transformation, relying exclusively on inter-domain knowledge transfer may lead to the loss of critical intra-domain information. To this end, we propose a novel residual transformation network (RestNet) that facilitates knowledge transfer while retaining the intra-domain support-query feature information. Specifically, we propose a Semantic Enhanced Anchor Transform (SEAT) module that maps features to a stable domain-agnostic space using advanced semantics. Additionally, an Intra-domain Residual Enhancement (IRE) module is designed to maintain the intra-domain representation of the original discriminant space in the new space. We also propose a mask prediction strategy based on prototype fusion to help the model gradually learn how to segment. Our RestNet can transfer cross-domain knowledge from both inter-domain and intra-domain without requiring additional fine-tuning. Extensive experiments on ISIC, Chest X-ray, and FSS-1000 show that our RestNet achieves state-of-the-art performance. Our code will be available soon.
TriGait: Aligning and Fusing Skeleton and Silhouette Gait Data via a Tri-Branch Network
Aug 25, 2023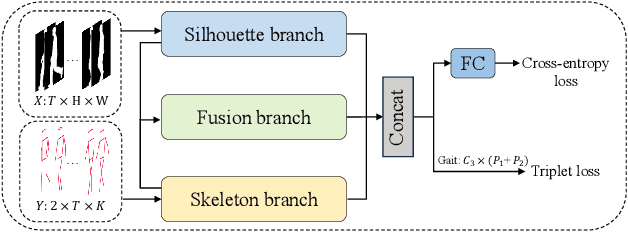
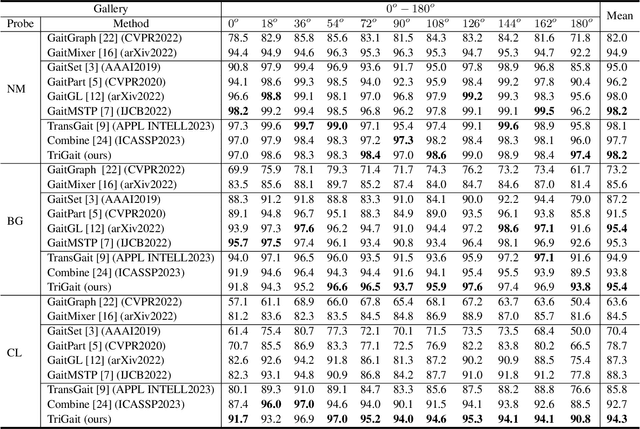

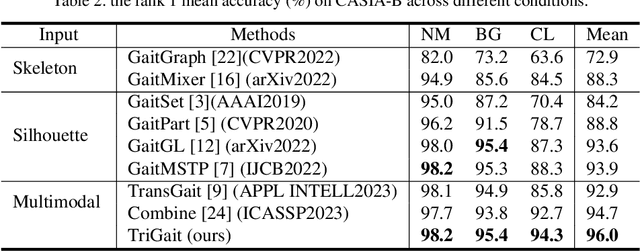
Gait recognition is a promising biometric technology for identification due to its non-invasiveness and long-distance. However, external variations such as clothing changes and viewpoint differences pose significant challenges to gait recognition. Silhouette-based methods preserve body shape but neglect internal structure information, while skeleton-based methods preserve structure information but omit appearance. To fully exploit the complementary nature of the two modalities, a novel triple branch gait recognition framework, TriGait, is proposed in this paper. It effectively integrates features from the skeleton and silhouette data in a hybrid fusion manner, including a two-stream network to extract static and motion features from appearance, a simple yet effective module named JSA-TC to capture dependencies between all joints, and a third branch for cross-modal learning by aligning and fusing low-level features of two modalities. Experimental results demonstrate the superiority and effectiveness of TriGait for gait recognition. The proposed method achieves a mean rank-1 accuracy of 96.0% over all conditions on CASIA-B dataset and 94.3% accuracy for CL, significantly outperforming all the state-of-the-art methods. The source code will be available at https://github.com/feng-xueling/TriGait/.
Construction Grammar and Language Models
Aug 25, 2023
Recent progress in deep learning and natural language processing has given rise to powerful models that are primarily trained on a cloze-like task and show some evidence of having access to substantial linguistic information, including some constructional knowledge. This groundbreaking discovery presents an exciting opportunity for a synergistic relationship between computational methods and Construction Grammar research. In this chapter, we explore three distinct approaches to the interplay between computational methods and Construction Grammar: (i) computational methods for text analysis, (ii) computational Construction Grammar, and (iii) deep learning models, with a particular focus on language models. We touch upon the first two approaches as a contextual foundation for the use of computational methods before providing an accessible, yet comprehensive overview of deep learning models, which also addresses reservations construction grammarians may have. Additionally, we delve into experiments that explore the emergence of constructionally relevant information within these models while also examining the aspects of Construction Grammar that may pose challenges for these models. This chapter aims to foster collaboration between researchers in the fields of natural language processing and Construction Grammar. By doing so, we hope to pave the way for new insights and advancements in both these fields.
MMBAttn: Max-Mean and Bit-wise Attention for CTR Prediction
Aug 25, 2023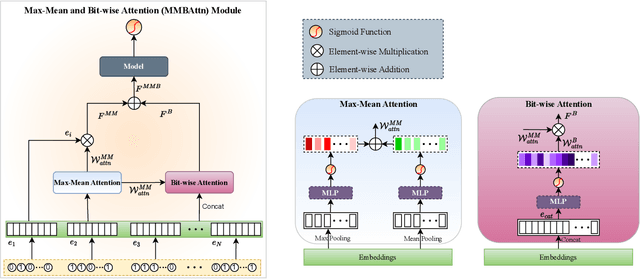
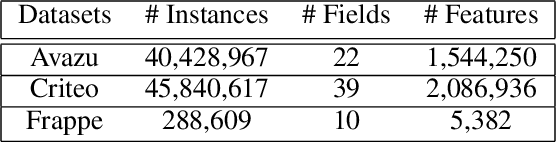
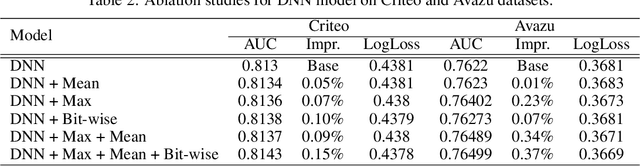
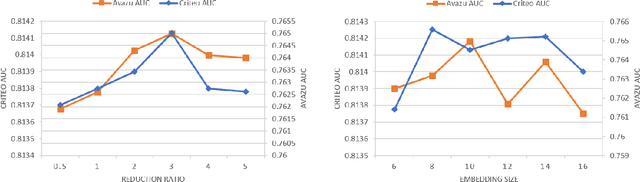
With the increasing complexity and scale of click-through rate (CTR) prediction tasks in online advertising and recommendation systems, accurately estimating the importance of features has become a critical aspect of developing effective models. In this paper, we propose an attention-based approach that leverages max and mean pooling operations, along with a bit-wise attention mechanism, to enhance feature importance estimation in CTR prediction. Traditionally, pooling operations such as max and mean pooling have been widely used to extract relevant information from features. However, these operations can lead to information loss and hinder the accurate determination of feature importance. To address this challenge, we propose a novel attention architecture that utilizes a bit-based attention structure that emphasizes the relationships between all bits in features, together with maximum and mean pooling. By considering the fine-grained interactions at the bit level, our method aims to capture intricate patterns and dependencies that might be overlooked by traditional pooling operations. To examine the effectiveness of the proposed method, experiments have been conducted on three public datasets. The experiments demonstrated that the proposed method significantly improves the performance of the base models to achieve state-of-the-art results.
Chunk, Align, Select: A Simple Long-sequence Processing Method for Transformers
Aug 25, 2023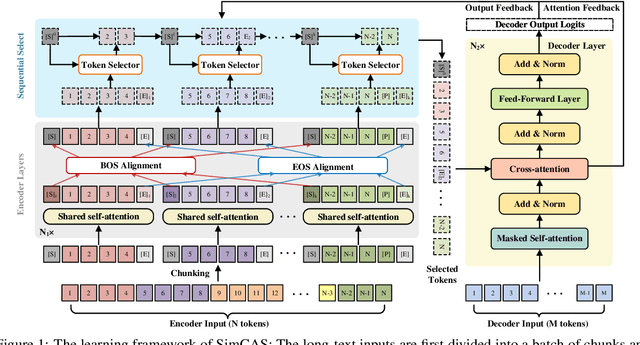
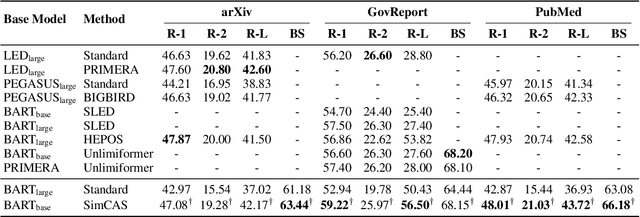
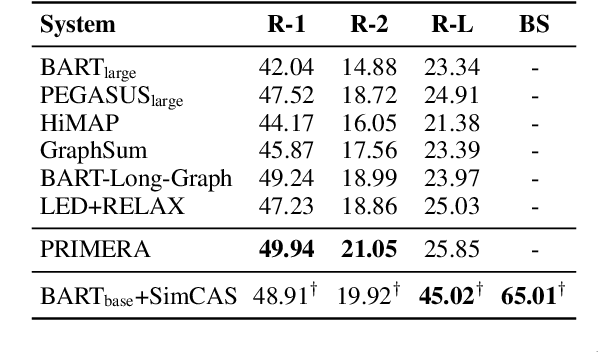
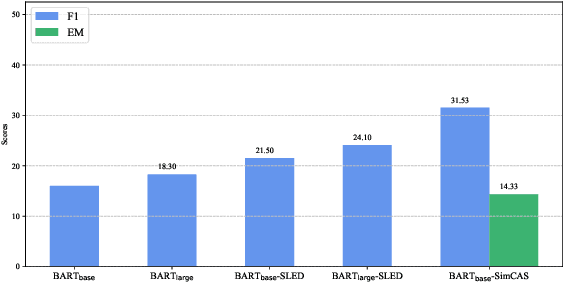
Although dominant in natural language processing, transformer-based models remain challenged by the task of long-sequence processing, because the computational cost of self-attention operations in transformers swells quadratically with the input sequence length. To alleviate the complexity of long-sequence processing, we propose a simple framework to enable the offthe-shelf pre-trained transformers to process much longer sequences, while the computation and memory costs remain growing linearly with the input sequence lengths. More specifically, our method divides each long-sequence input into a batch of chunks, then aligns the interchunk information during the encoding steps, and finally selects the most representative hidden states from the encoder for the decoding process. To extract inter-chunk semantic information, we align the start and end token embeddings among chunks in each encoding transformer block. To learn an effective hidden selection policy, we design a dual updating scheme inspired by reinforcement learning, which regards the decoders of transformers as environments, and the downstream performance metrics as the rewards to evaluate the hidden selection actions. Our empirical results on real-world long-text summarization and reading comprehension tasks demonstrate effective improvements compared to prior longsequence processing baselines.