 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Graph of Thoughts: Solving Elaborate Problems with Large Language Models
Aug 18, 2023
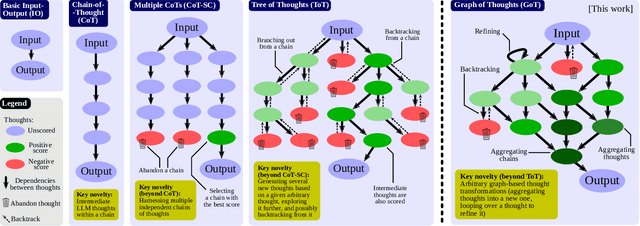
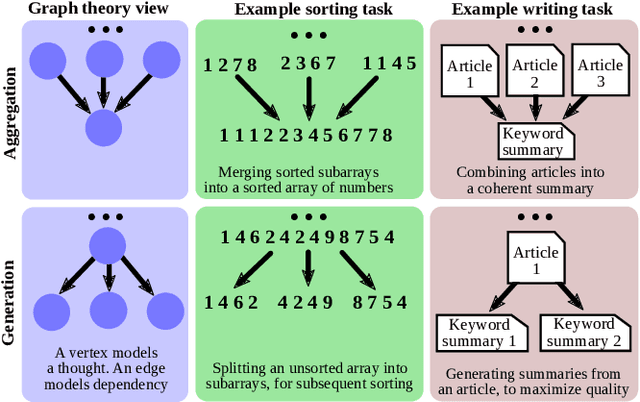
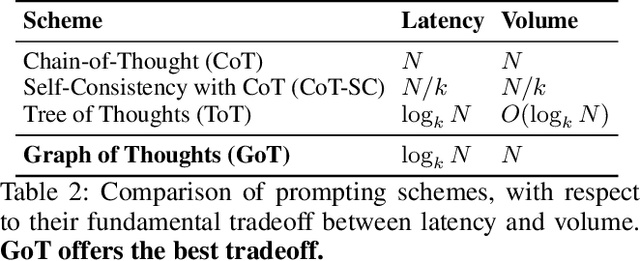
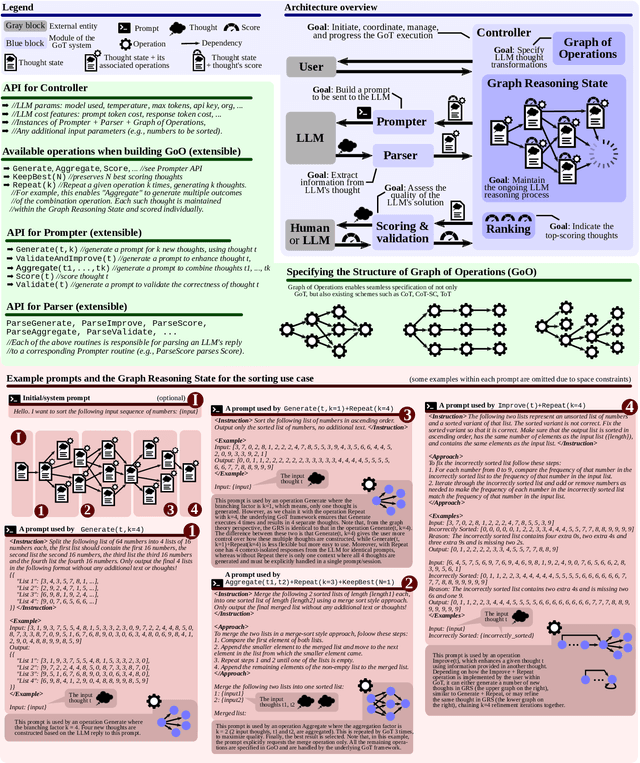
We introduce Graph of Thoughts (GoT): a framework that advances prompting capabilities in large language models (LLMs) beyond those offered by paradigms such as Chain-ofThought or Tree of Thoughts (ToT). The key idea and primary advantage of GoT is the ability to model the information generated by an LLM as an arbitrary graph, where units of information ("LLM thoughts") are vertices, and edges correspond to dependencies between these vertices. This approach enables combining arbitrary LLM thoughts into synergistic outcomes, distilling the essence of whole networks of thoughts, or enhancing thoughts using feedback loops. We illustrate that GoT offers advantages over state of the art on different tasks, for example increasing the quality of sorting by 62% over ToT, while simultaneously reducing costs by >31%. We ensure that GoT is extensible with new thought transformations and thus can be used to spearhead new prompting schemes. This work brings the LLM reasoning closer to human thinking or brain mechanisms such as recurrence, both of which form complex networks.
MapPrior: Bird's-Eye View Map Layout Estimation with Generative Models
Aug 24, 2023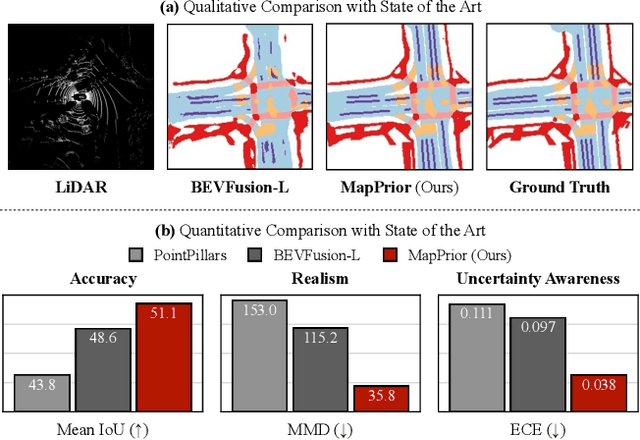
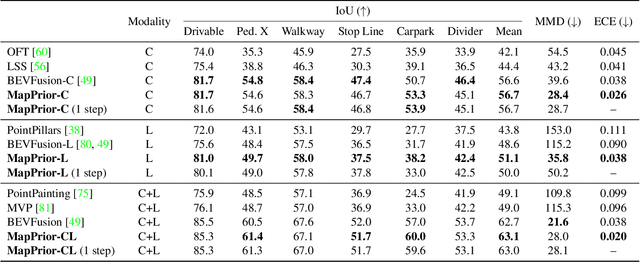
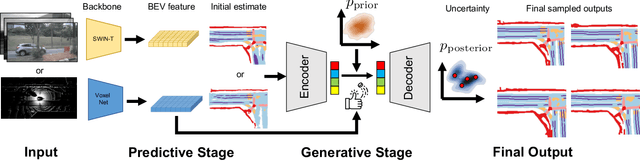
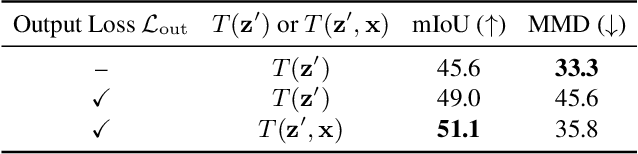
Despite tremendous advancements in bird's-eye view (BEV) perception, existing models fall short in generating realistic and coherent semantic map layouts, and they fail to account for uncertainties arising from partial sensor information (such as occlusion or limited coverage). In this work, we introduce MapPrior, a novel BEV perception framework that combines a traditional discriminative BEV perception model with a learned generative model for semantic map layouts. Our MapPrior delivers predictions with better accuracy, realism, and uncertainty awareness. We evaluate our model on the large-scale nuScenes benchmark. At the time of submission, MapPrior outperforms the strongest competing method, with significantly improved MMD and ECE scores in camera- and LiDAR-based BEV perception.
Escaping the Sample Trap: Fast and Accurate Epistemic Uncertainty Estimation with Pairwise-Distance Estimators
Aug 25, 2023This work introduces a novel approach for epistemic uncertainty estimation for ensemble models using pairwise-distance estimators (PaiDEs). These estimators utilize the pairwise-distance between model components to establish bounds on entropy and uses said bounds as estimates for information-based criterion. Unlike recent deep learning methods for epistemic uncertainty estimation, which rely on sample-based Monte Carlo estimators, PaiDEs are able to estimate epistemic uncertainty up to 100$\times$ faster, over a larger space (up to 100$\times$) and perform more accurately in higher dimensions. To validate our approach, we conducted a series of experiments commonly used to evaluate epistemic uncertainty estimation: 1D sinusoidal data, Pendulum-v0, Hopper-v2, Ant-v2 and Humanoid-v2. For each experimental setting, an Active Learning framework was applied to demonstrate the advantages of PaiDEs for epistemic uncertainty estimation.
A Two-Dimensional Deep Network for RF-based Drone Detection and Identification Towards Secure Coverage Extension
Aug 26, 2023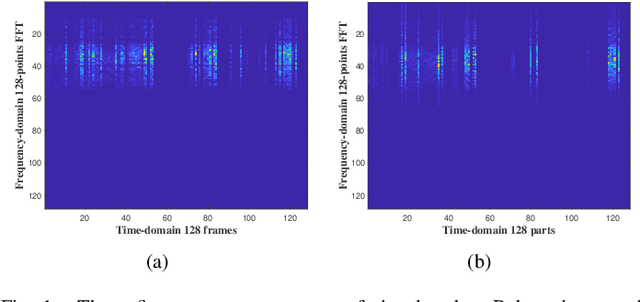
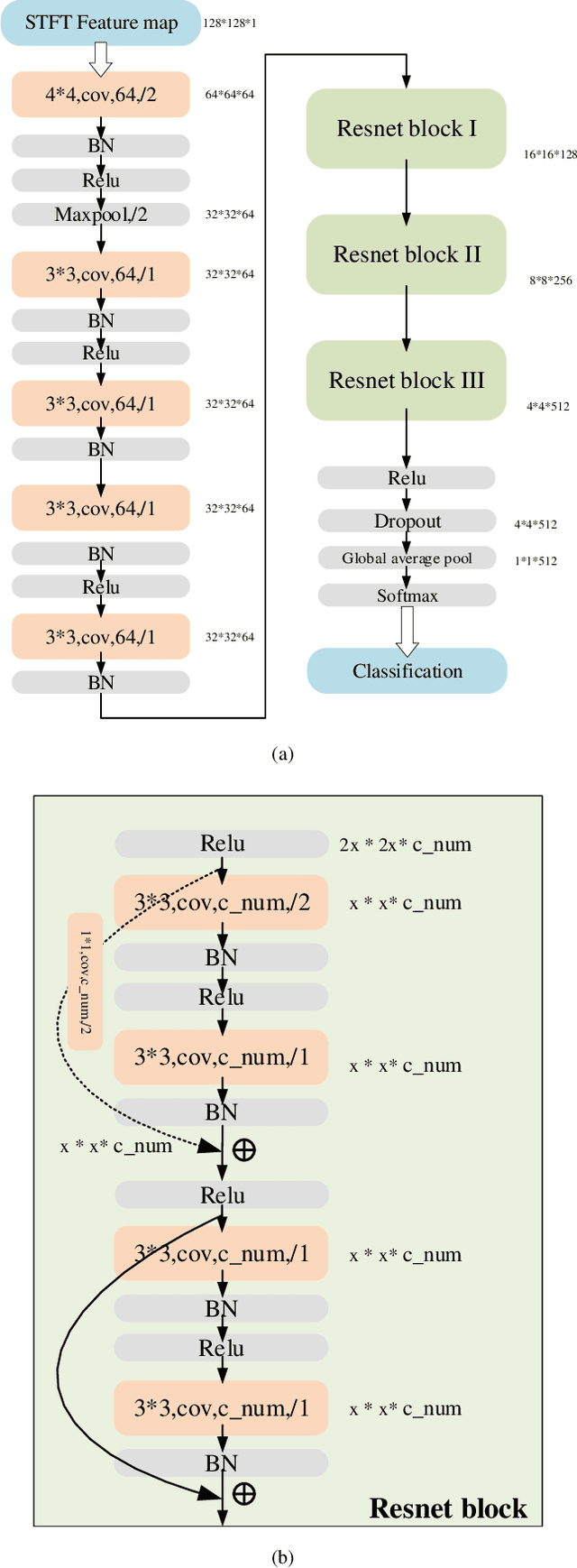
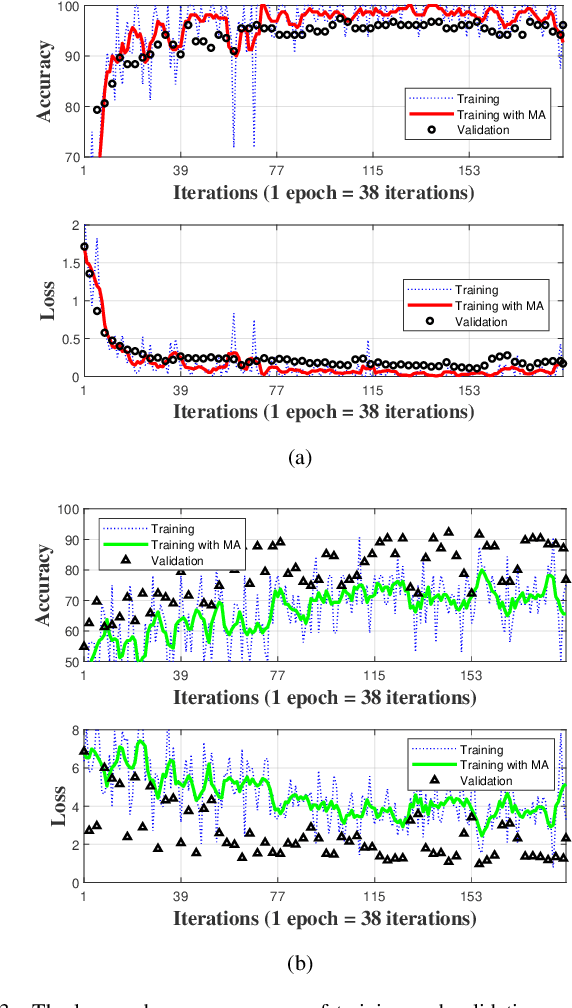
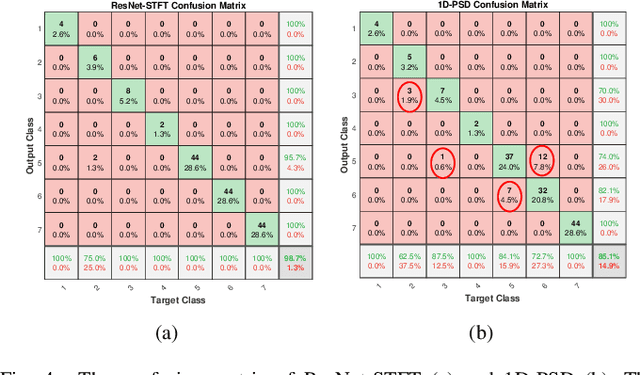
As drones become increasingly prevalent in human life, they also raises security concerns such as unauthorized access and control, as well as collisions and interference with manned aircraft. Therefore, ensuring the ability to accurately detect and identify between different drones holds significant implications for coverage extension. Assisted by machine learning, radio frequency (RF) detection can recognize the type and flight mode of drones based on the sampled drone signals. In this paper, we first utilize Short-Time Fourier. Transform (STFT) to extract two-dimensional features from the raw signals, which contain both time-domain and frequency-domain information. Then, we employ a Convolutional Neural Network (CNN) built with ResNet structure to achieve multi-class classifications. Our experimental results show that the proposed ResNet-STFT can achieve higher accuracy and faster convergence on the extended dataset. Additionally, it exhibits balanced performance compared to other baselines on the raw dataset.
From DDMs to DNNs: Using process data and models of decision-making to improve human-AI interactions
Aug 29, 2023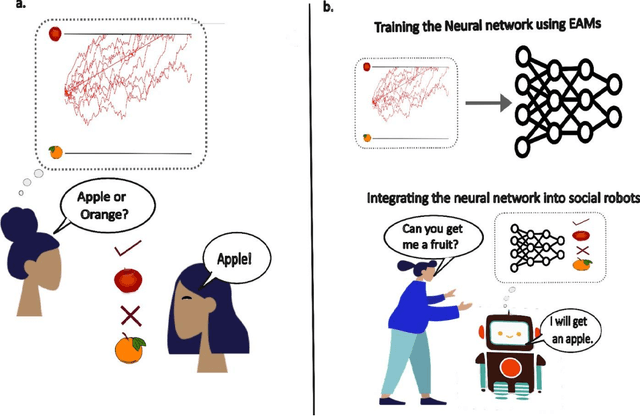
Over the past decades, cognitive neuroscientists and behavioral economists have recognized the value of describing the process of decision making in detail and modeling the emergence of decisions over time. For example, the time it takes to decide can reveal more about an agents true hidden preferences than only the decision itself. Similarly, data that track the ongoing decision process such as eye movements or neural recordings contain critical information that can be exploited, even if no decision is made. Here, we argue that artificial intelligence (AI) research would benefit from a stronger focus on insights about how decisions emerge over time and incorporate related process data to improve AI predictions in general and human-AI interactions in particular. First, we introduce a highly established computational framework that assumes decisions to emerge from the noisy accumulation of evidence, and we present related empirical work in psychology, neuroscience, and economics. Next, we discuss to what extent current approaches in multi-agent AI do or do not incorporate process data and models of decision making. Finally, we outline how a more principled inclusion of the evidence-accumulation framework into the training and use of AI can help to improve human-AI interactions in the future.
Constructive Incremental Learning for Fault Diagnosis of Rolling Bearings with Ensemble Domain Adaptation
Aug 29, 2023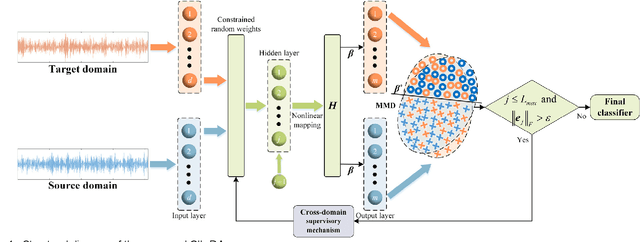
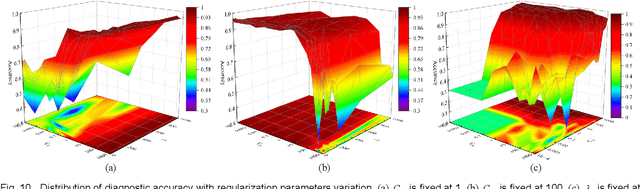
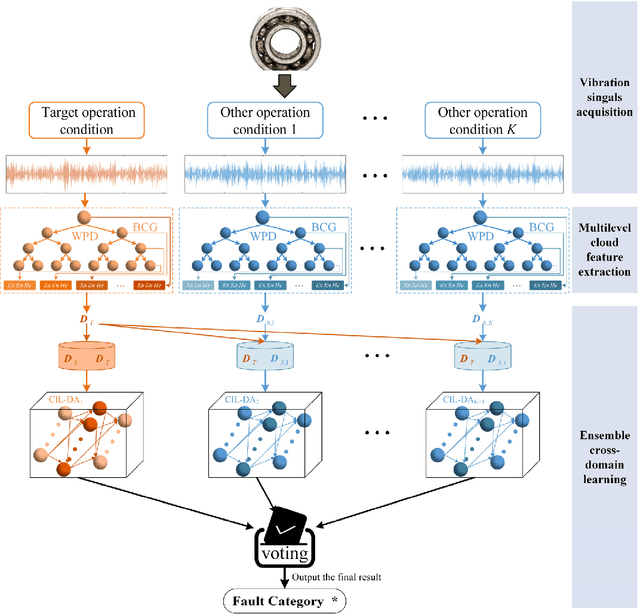
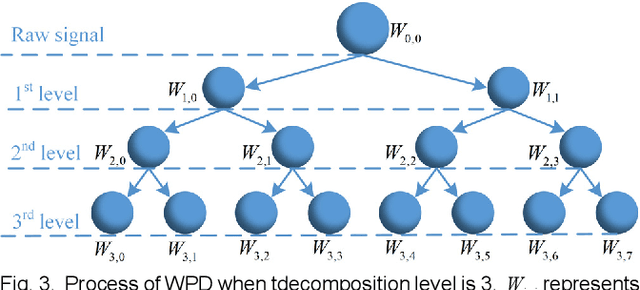
Given the prevalence of rolling bearing fault diagnosis as a practical issue across various working conditions, the limited availability of samples compounds the challenge. Additionally, the complexity of the external environment and the structure of rolling bearings often manifests faults characterized by randomness and fuzziness, hindering the effective extraction of fault characteristics and restricting the accuracy of fault diagnosis. To overcome these problems, this paper presents a novel approach termed constructive Incremental learning-based ensemble domain adaptation (CIL-EDA) approach. Specifically, it is implemented on stochastic configuration networks (SCN) to constructively improve its adaptive performance in multi-domains. Concretely, a cloud feature extraction method is employed in conjunction with wavelet packet decomposition (WPD) to capture the uncertainty of fault information from multiple resolution aspects. Subsequently, constructive Incremental learning-based domain adaptation (CIL-DA) is firstly developed to enhance the cross-domain learning capability of each hidden node through domain matching and construct a robust fault classifier by leveraging limited labeled data from both target and source domains. Finally, fault diagnosis results are obtained by a majority voting of CIL-EDA which integrates CIL-DA and parallel ensemble learning. Experimental results demonstrate that our CIL-DA outperforms several domain adaptation methods and CIL-EDA consistently outperforms state-of-art fault diagnosis methods in few-shot scenarios.
Vision Grid Transformer for Document Layout Analysis
Aug 29, 2023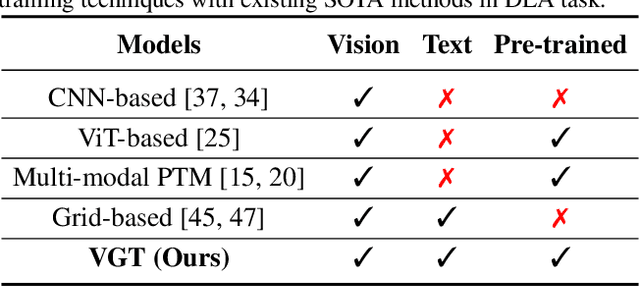



Document pre-trained models and grid-based models have proven to be very effective on various tasks in Document AI. However, for the document layout analysis (DLA) task, existing document pre-trained models, even those pre-trained in a multi-modal fashion, usually rely on either textual features or visual features. Grid-based models for DLA are multi-modality but largely neglect the effect of pre-training. To fully leverage multi-modal information and exploit pre-training techniques to learn better representation for DLA, in this paper, we present VGT, a two-stream Vision Grid Transformer, in which Grid Transformer (GiT) is proposed and pre-trained for 2D token-level and segment-level semantic understanding. Furthermore, a new dataset named D$^4$LA, which is so far the most diverse and detailed manually-annotated benchmark for document layout analysis, is curated and released. Experiment results have illustrated that the proposed VGT model achieves new state-of-the-art results on DLA tasks, e.g. PubLayNet ($95.7\%$$\rightarrow$$96.2\%$), DocBank ($79.6\%$$\rightarrow$$84.1\%$), and D$^4$LA ($67.7\%$$\rightarrow$$68.8\%$). The code and models as well as the D$^4$LA dataset will be made publicly available ~\url{https://github.com/AlibabaResearch/AdvancedLiterateMachinery}.
EquiDiff: A Conditional Equivariant Diffusion Model For Trajectory Prediction
Aug 29, 2023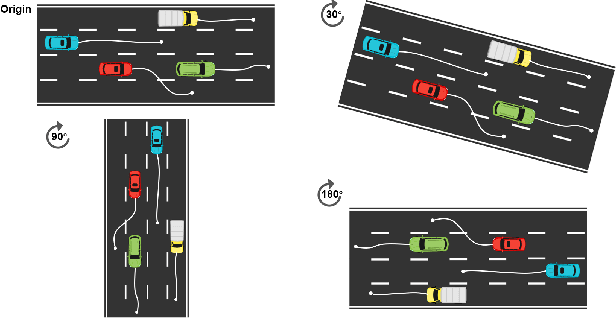
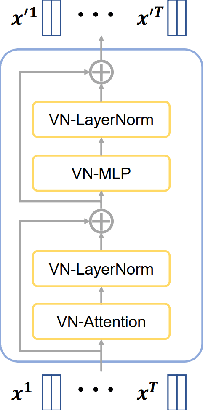
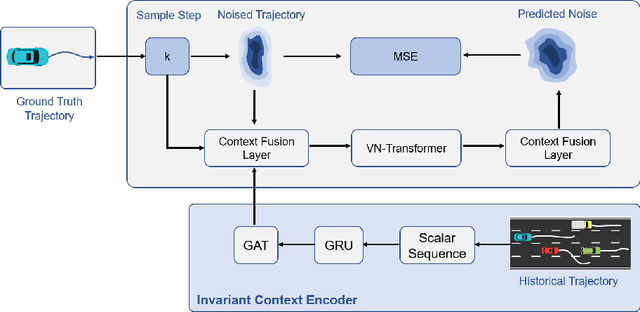
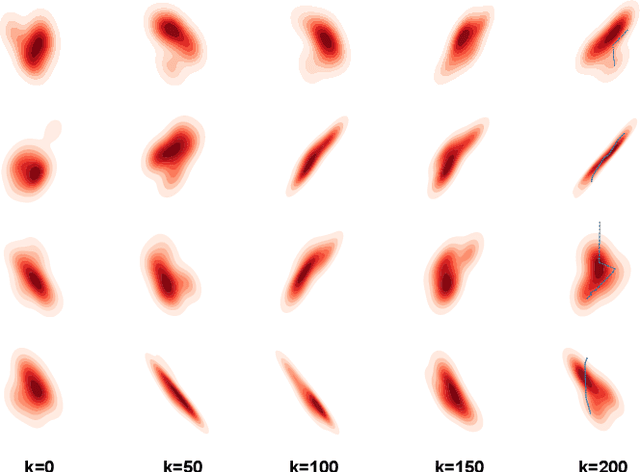
Accurate trajectory prediction is crucial for the safe and efficient operation of autonomous vehicles. The growing popularity of deep learning has led to the development of numerous methods for trajectory prediction. While deterministic deep learning models have been widely used, deep generative models have gained popularity as they learn data distributions from training data and account for trajectory uncertainties. In this study, we propose EquiDiff, a deep generative model for predicting future vehicle trajectories. EquiDiff is based on the conditional diffusion model, which generates future trajectories by incorporating historical information and random Gaussian noise. The backbone model of EquiDiff is an SO(2)-equivariant transformer that fully utilizes the geometric properties of location coordinates. In addition, we employ Recurrent Neural Networks and Graph Attention Networks to extract social interactions from historical trajectories. To evaluate the performance of EquiDiff, we conduct extensive experiments on the NGSIM dataset. Our results demonstrate that EquiDiff outperforms other baseline models in short-term prediction, but has slightly higher errors for long-term prediction. Furthermore, we conduct an ablation study to investigate the contribution of each component of EquiDiff to the prediction accuracy. Additionally, we present a visualization of the generation process of our diffusion model, providing insights into the uncertainty of the prediction.
Artificial intelligence is ineffective and potentially harmful for fact checking
Aug 21, 2023

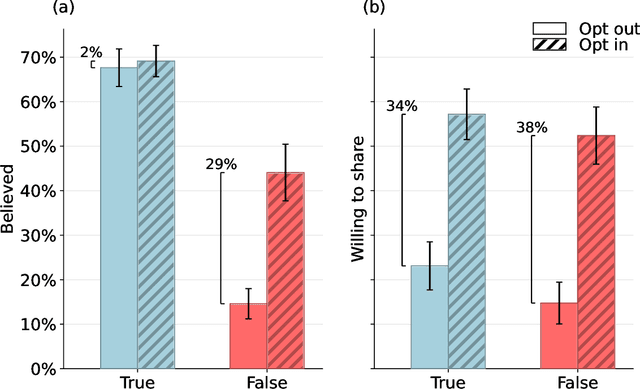
Fact checking can be an effective strategy against misinformation, but its implementation at scale is impeded by the overwhelming volume of information online. Recent artificial intelligence (AI) language models have shown impressive ability in fact-checking tasks, but how humans interact with fact-checking information provided by these models is unclear. Here we investigate the impact of fact checks generated by a popular AI model on belief in, and sharing intent of, political news in a preregistered randomized control experiment. Although the AI performs reasonably well in debunking false headlines, we find that it does not significantly affect participants' ability to discern headline accuracy or share accurate news. However, the AI fact-checker is harmful in specific cases: it decreases beliefs in true headlines that it mislabels as false and increases beliefs for false headlines that it is unsure about. On the positive side, the AI increases sharing intents for correctly labeled true headlines. When participants are given the option to view AI fact checks and choose to do so, they are significantly more likely to share both true and false news but only more likely to believe false news. Our findings highlight an important source of potential harm stemming from AI applications and underscore the critical need for policies to prevent or mitigate such unintended consequences.
Using Large Language Models to Automate Category and Trend Analysis of Scientific Articles: An Application in Ophthalmology
Aug 31, 2023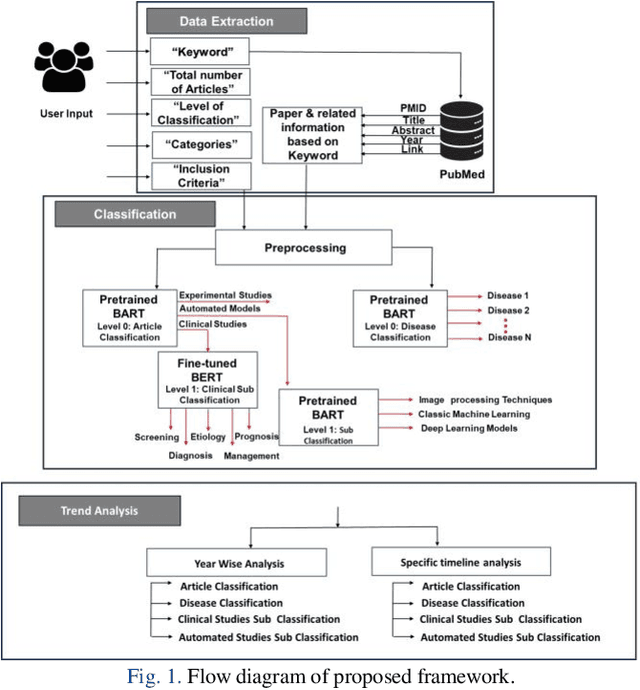
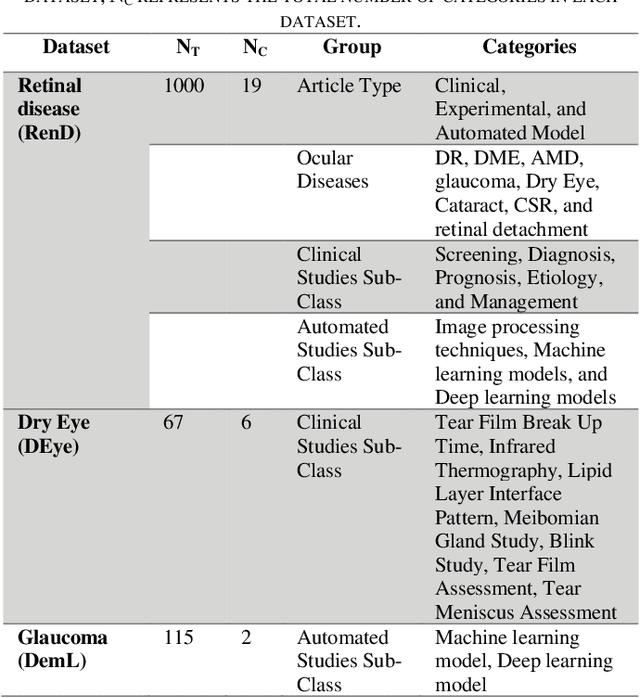
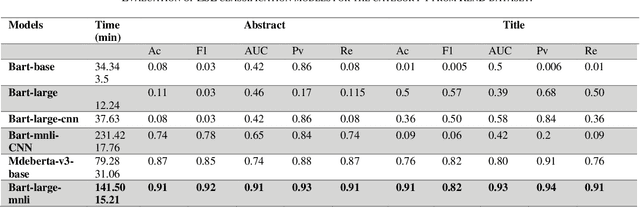
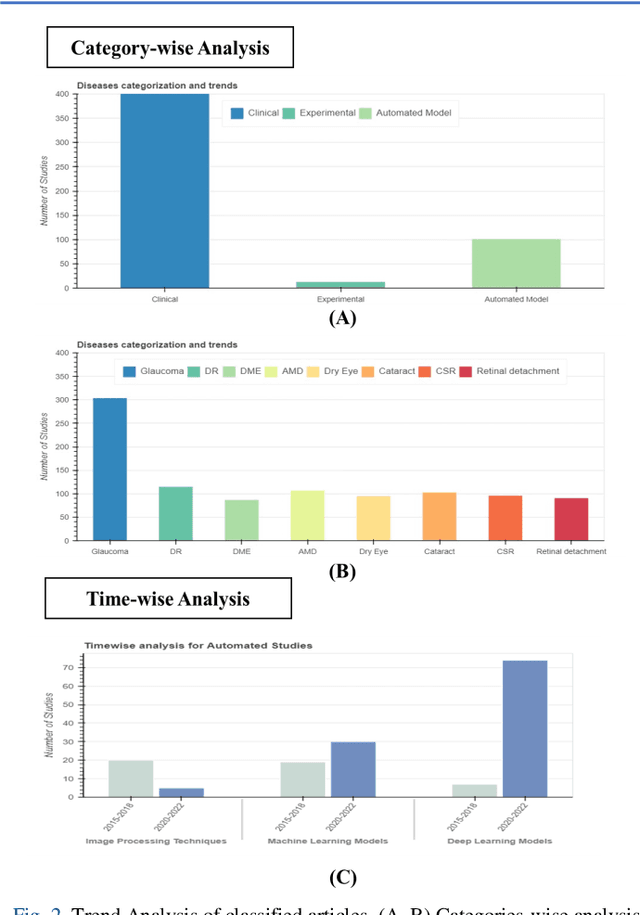
Purpose: In this paper, we present an automated method for article classification, leveraging the power of Large Language Models (LLM). The primary focus is on the field of ophthalmology, but the model is extendable to other fields. Methods: We have developed a model based on Natural Language Processing (NLP) techniques, including advanced LLMs, to process and analyze the textual content of scientific papers. Specifically, we have employed zero-shot learning (ZSL) LLM models and compared against Bidirectional and Auto-Regressive Transformers (BART) and its variants, and Bidirectional Encoder Representations from Transformers (BERT), and its variant such as distilBERT, SciBERT, PubmedBERT, BioBERT. Results: The classification results demonstrate the effectiveness of LLMs in categorizing large number of ophthalmology papers without human intervention. Results: To evalute the LLMs, we compiled a dataset (RenD) of 1000 ocular disease-related articles, which were expertly annotated by a panel of six specialists into 15 distinct categories. The model achieved mean accuracy of 0.86 and mean F1 of 0.85 based on the RenD dataset. Conclusion: The proposed framework achieves notable improvements in both accuracy and efficiency. Its application in the domain of ophthalmology showcases its potential for knowledge organization and retrieval in other domains too. We performed trend analysis that enables the researchers and clinicians to easily categorize and retrieve relevant papers, saving time and effort in literature review and information gathering as well as identification of emerging scientific trends within different disciplines. Moreover, the extendibility of the model to other scientific fields broadens its impact in facilitating research and trend analysis across diverse disciplines.