 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Space-Time Shift Keying Aided OTFS Modulation for Orthogonal Multiple Access
Sep 07, 2023
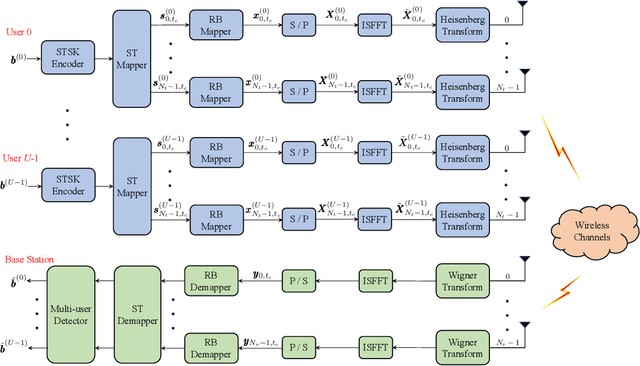
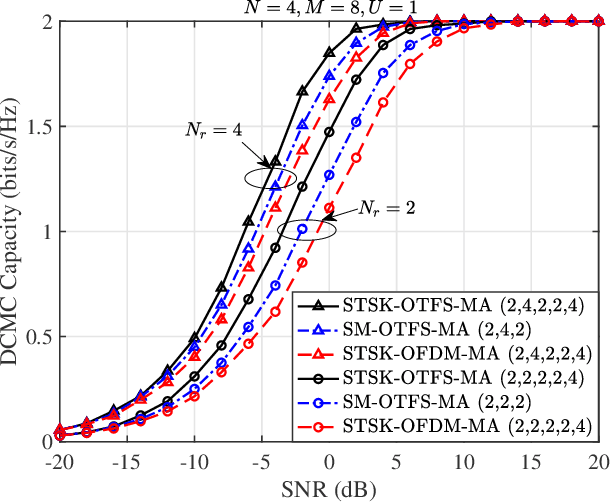
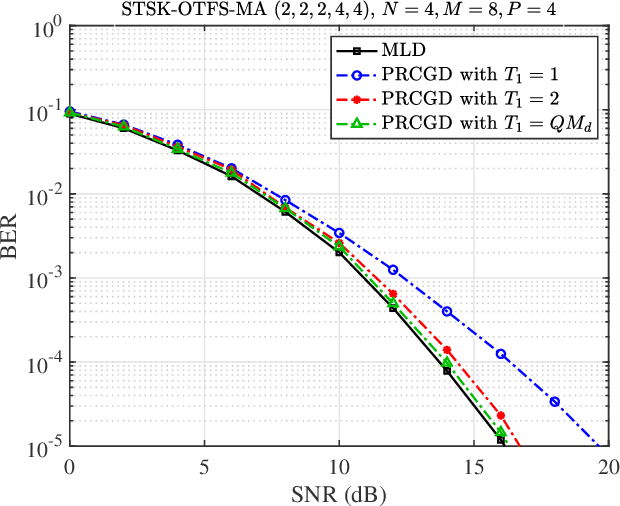
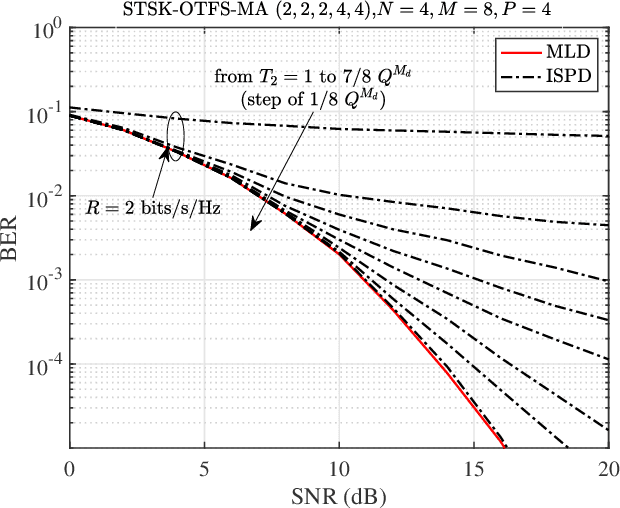
Space-time shift keying-aided orthogonal time frequency space modulation-based multiple access (STSK-OTFS-MA) is proposed for reliable uplink transmission in high-Doppler scenarios. As a beneficial feature of our STSK-OTFS-MA system, extra information bits are mapped onto the indices of the active dispersion matrices, which allows the system to enjoy the joint benefits of both STSK and OTFS signalling. Due to the fact that both the time-, space- and DD-domain degrees of freedom are jointly exploited, our STSK-OTFS-MA achieves increased diversity and coding gains. To mitigate the potentially excessive detection complexity, the sparse structure of the equivalent transmitted symbol vector is exploited, resulting in a pair of low-complexity near-maximum likelihood (ML) multiuser detection algorithms. Explicitly, we conceive a progressive residual check-based greedy detector (PRCGD) and an iterative reduced-space check-based detector (IRCD). Then, we derive both the unconditional single-user pairwise error probability (SU-UPEP) and a tight bit error ratio (BER) union-bound for our single-user STSK-OTFS-MA system employing the ML detector. Furthermore, the discrete-input continuous-output memoryless channel (DCMC) capacity of the proposed system is derived. The optimal dispersion matrices (DMs) are designed based on the maximum attainable diversity and coding gain metrics. Finally, it is demonstrated that our STSK-OTFS-MA system achieves both a lower BER and a higher DCMC capacity than its conventional spatial modulation (SM) {and its orthogonal frequency-division multiplexing (OFDM) counterparts. As a benefit, the proposed system strikes a compelling BER vs. system complexity as well as BER vs. detection complexity trade-offs.
Learning Compact Compositional Embeddings via Regularized Pruning for Recommendation
Sep 07, 2023
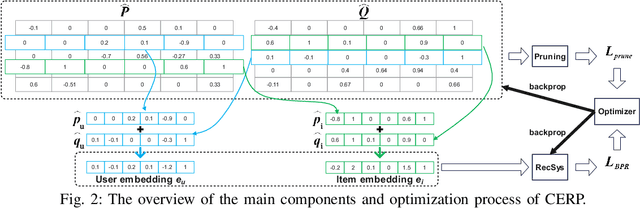
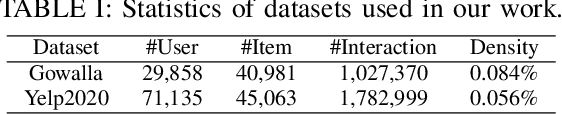
Latent factor models are the dominant backbones of contemporary recommender systems (RSs) given their performance advantages, where a unique vector embedding with a fixed dimensionality (e.g., 128) is required to represent each entity (commonly a user/item). Due to the large number of users and items on e-commerce sites, the embedding table is arguably the least memory-efficient component of RSs. For any lightweight recommender that aims to efficiently scale with the growing size of users/items or to remain applicable in resource-constrained settings, existing solutions either reduce the number of embeddings needed via hashing, or sparsify the full embedding table to switch off selected embedding dimensions. However, as hash collision arises or embeddings become overly sparse, especially when adapting to a tighter memory budget, those lightweight recommenders inevitably have to compromise their accuracy. To this end, we propose a novel compact embedding framework for RSs, namely Compositional Embedding with Regularized Pruning (CERP). Specifically, CERP represents each entity by combining a pair of embeddings from two independent, substantially smaller meta-embedding tables, which are then jointly pruned via a learnable element-wise threshold. In addition, we innovatively design a regularized pruning mechanism in CERP, such that the two sparsified meta-embedding tables are encouraged to encode information that is mutually complementary. Given the compatibility with agnostic latent factor models, we pair CERP with two popular recommendation models for extensive experiments, where results on two real-world datasets under different memory budgets demonstrate its superiority against state-of-the-art baselines. The codebase of CERP is available in https://github.com/xurong-liang/CERP.
SVQNet: Sparse Voxel-Adjacent Query Network for 4D Spatio-Temporal LiDAR Semantic Segmentation
Aug 25, 2023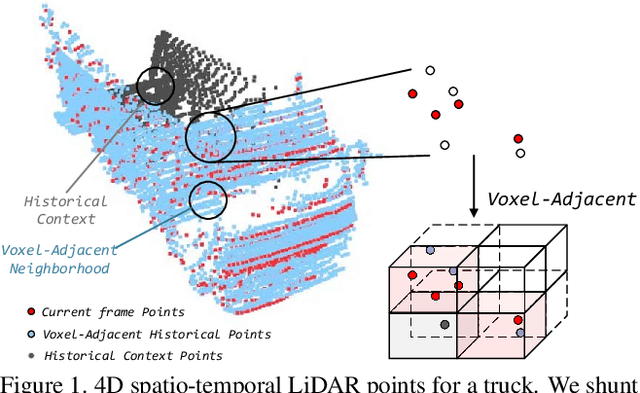
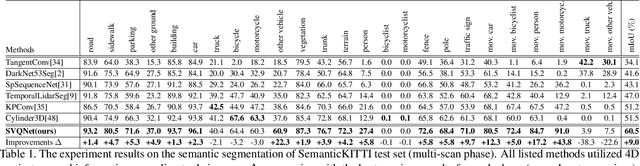
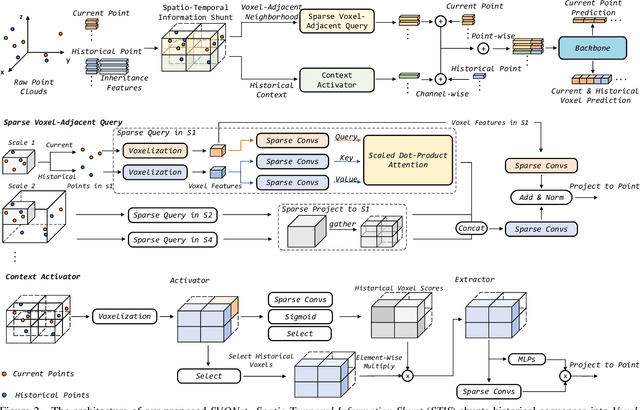
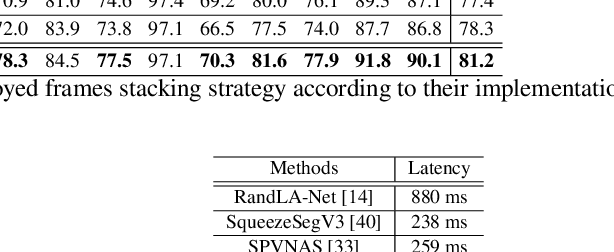
LiDAR-based semantic perception tasks are critical yet challenging for autonomous driving. Due to the motion of objects and static/dynamic occlusion, temporal information plays an essential role in reinforcing perception by enhancing and completing single-frame knowledge. Previous approaches either directly stack historical frames to the current frame or build a 4D spatio-temporal neighborhood using KNN, which duplicates computation and hinders realtime performance. Based on our observation that stacking all the historical points would damage performance due to a large amount of redundant and misleading information, we propose the Sparse Voxel-Adjacent Query Network (SVQNet) for 4D LiDAR semantic segmentation. To take full advantage of the historical frames high-efficiently, we shunt the historical points into two groups with reference to the current points. One is the Voxel-Adjacent Neighborhood carrying local enhancing knowledge. The other is the Historical Context completing the global knowledge. Then we propose new modules to select and extract the instructive features from the two groups. Our SVQNet achieves state-of-the-art performance in LiDAR semantic segmentation of the SemanticKITTI benchmark and the nuScenes dataset.
LLM2KB: Constructing Knowledge Bases using instruction tuned context aware Large Language Models
Aug 25, 2023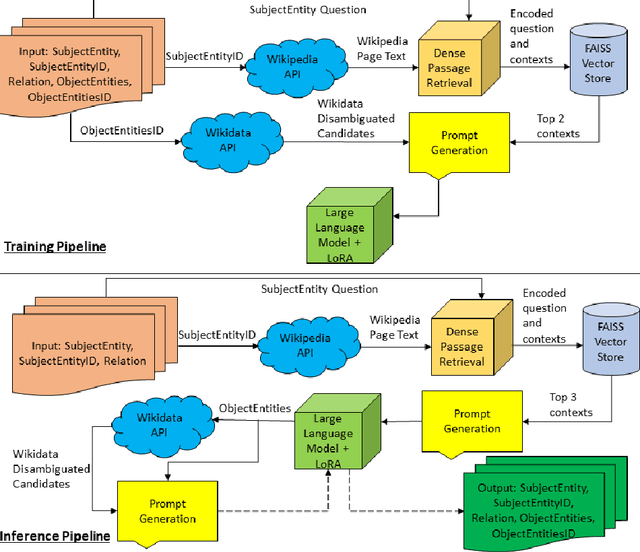
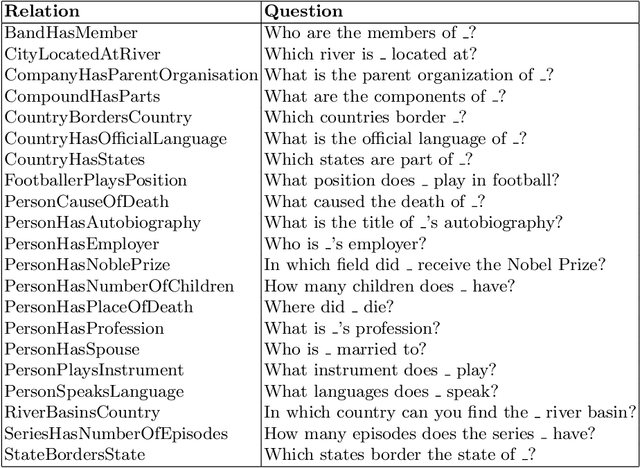
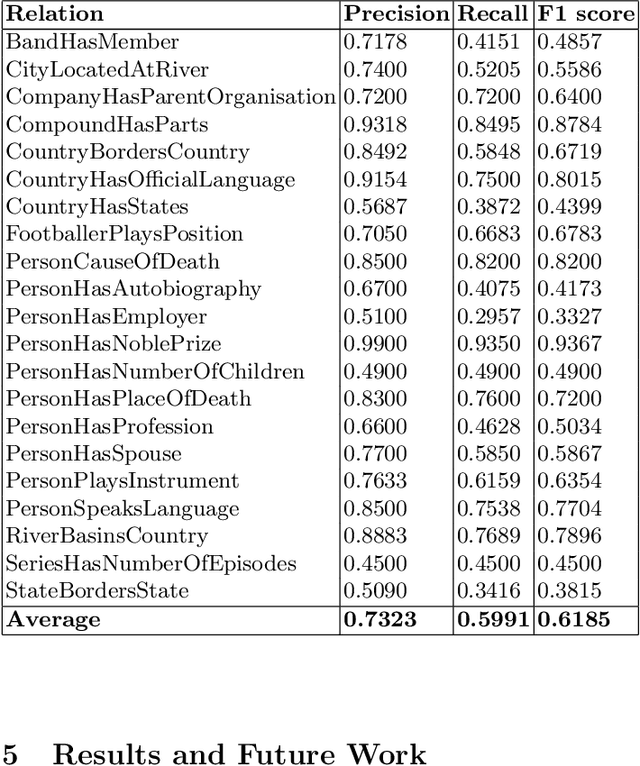
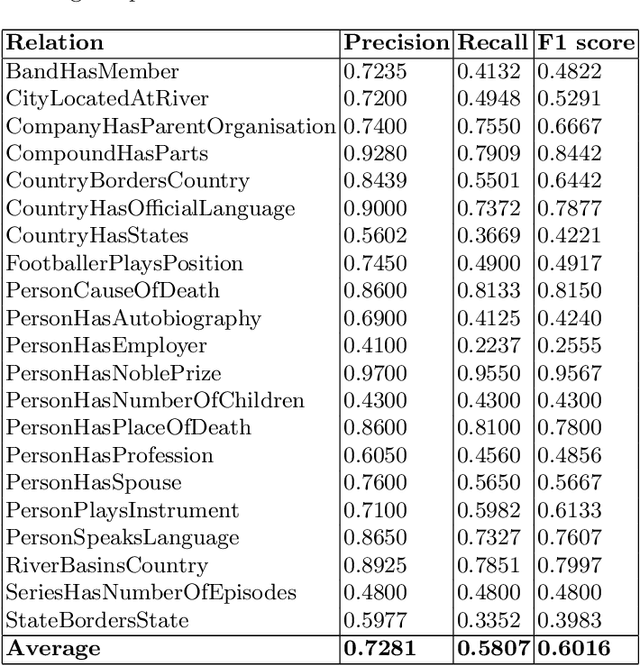
The advent of Large Language Models (LLM) has revolutionized the field of natural language processing, enabling significant progress in various applications. One key area of interest is the construction of Knowledge Bases (KB) using these powerful models. Knowledge bases serve as repositories of structured information, facilitating information retrieval and inference tasks. Our paper proposes LLM2KB, a system for constructing knowledge bases using large language models, with a focus on the Llama 2 architecture and the Wikipedia dataset. We perform parameter efficient instruction tuning for Llama-2-13b-chat and StableBeluga-13B by training small injection models that have only 0.05 % of the parameters of the base models using the Low Rank Adaptation (LoRA) technique. These injection models have been trained with prompts that are engineered to utilize Wikipedia page contexts of subject entities fetched using a Dense Passage Retrieval (DPR) algorithm, to answer relevant object entities for a given subject entity and relation. Our best performing model achieved an average F1 score of 0.6185 across 21 relations in the LM-KBC challenge held at the ISWC 2023 conference.
Learning Cross-Modal Affinity for Referring Video Object Segmentation Targeting Limited Samples
Sep 05, 2023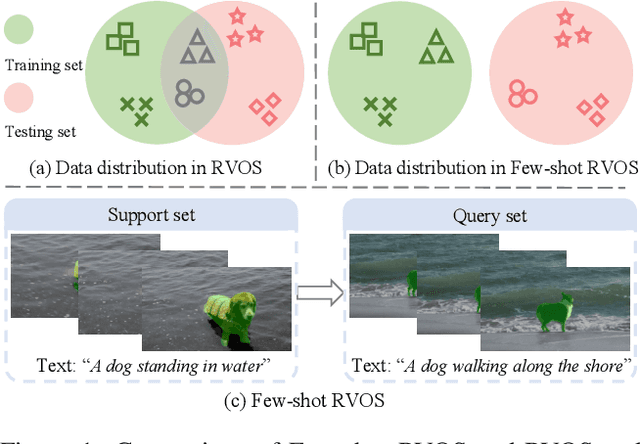
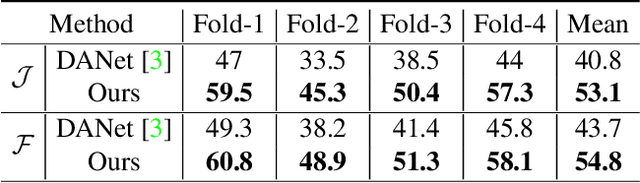
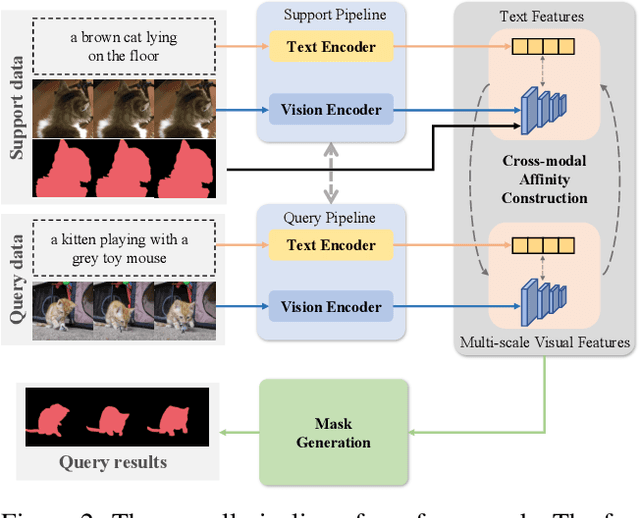
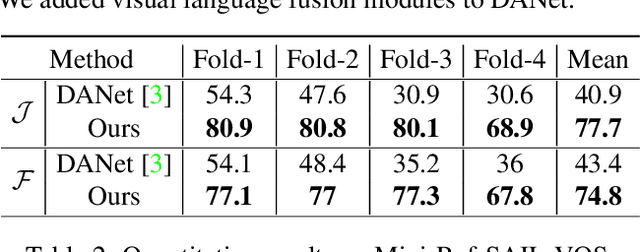
Referring video object segmentation (RVOS), as a supervised learning task, relies on sufficient annotated data for a given scene. However, in more realistic scenarios, only minimal annotations are available for a new scene, which poses significant challenges to existing RVOS methods. With this in mind, we propose a simple yet effective model with a newly designed cross-modal affinity (CMA) module based on a Transformer architecture. The CMA module builds multimodal affinity with a few samples, thus quickly learning new semantic information, and enabling the model to adapt to different scenarios. Since the proposed method targets limited samples for new scenes, we generalize the problem as - few-shot referring video object segmentation (FS-RVOS). To foster research in this direction, we build up a new FS-RVOS benchmark based on currently available datasets. The benchmark covers a wide range and includes multiple situations, which can maximally simulate real-world scenarios. Extensive experiments show that our model adapts well to different scenarios with only a few samples, reaching state-of-the-art performance on the benchmark. On Mini-Ref-YouTube-VOS, our model achieves an average performance of 53.1 J and 54.8 F, which are 10% better than the baselines. Furthermore, we show impressive results of 77.7 J and 74.8 F on Mini-Ref-SAIL-VOS, which are significantly better than the baselines. Code is publicly available at https://github.com/hengliusky/Few_shot_RVOS.
Recurrence-Free Survival Prediction for Anal Squamous Cell Carcinoma Chemoradiotherapy using Planning CT-based Radiomics Model
Sep 05, 2023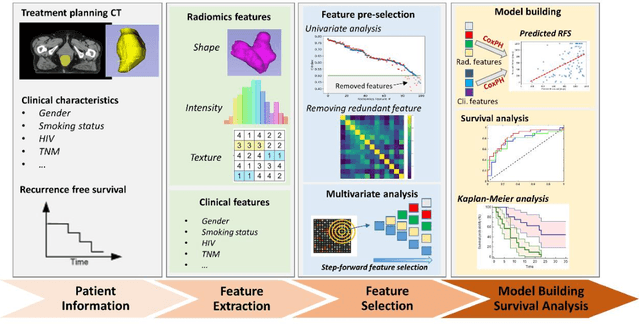
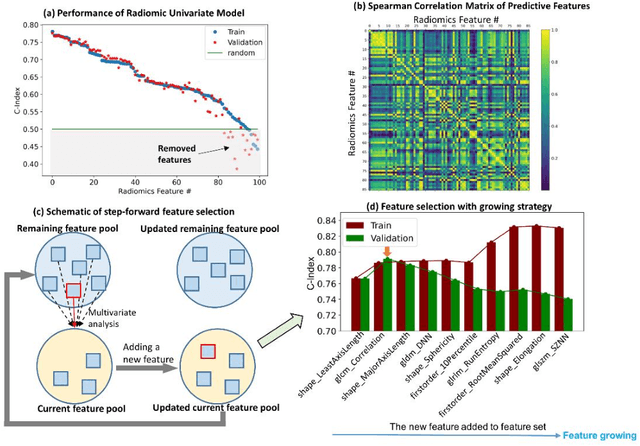
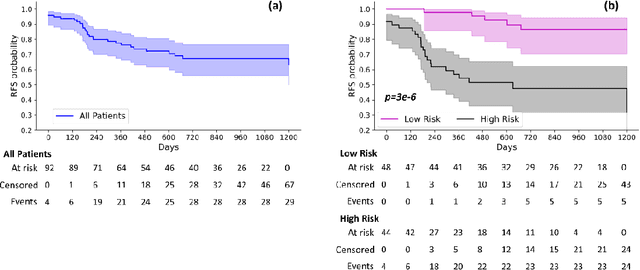
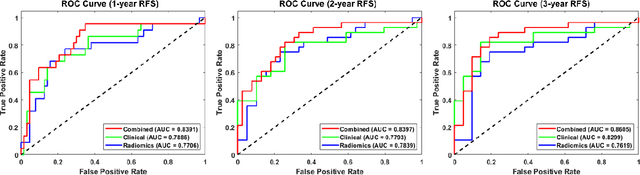
Objectives: Approximately 30% of non-metastatic anal squamous cell carcinoma (ASCC) patients will experience recurrence after chemoradiotherapy (CRT), and currently available clinical variables are poor predictors of treatment response. We aimed to develop a model leveraging information extracted from radiation pretreatment planning CT to predict recurrence-free survival (RFS) in ASCC patients after CRT. Methods: Radiomics features were extracted from planning CT images of 96 ASCC patients. Following pre-feature selection, the optimal feature set was selected via step-forward feature selection with a multivariate Cox proportional hazard model. The RFS prediction was generated from a radiomics-clinical combined model based on an optimal feature set with five repeats of five-fold cross validation. The risk stratification ability of the proposed model was evaluated with Kaplan-Meier analysis. Results: Shape- and texture-based radiomics features significantly predicted RFS. Compared to a clinical-only model, radiomics-clinical combined model achieves better performance in the testing cohort with higher C-index (0.80 vs 0.73) and AUC (0.84 vs 0.79 for 1-year RFS, 0.84 vs 0.78 for 2-year RFS, and 0.86 vs 0.83 for 3-year RFS), leading to distinctive high- and low-risk of recurrence groups (p<0.001). Conclusions: A treatment planning CT based radiomics and clinical combined model had improved prognostic performance in predicting RFS for ASCC patients treated with CRT as compared to a model using clinical features only.
On the Complexity of Differentially Private Best-Arm Identification with Fixed Confidence
Sep 05, 2023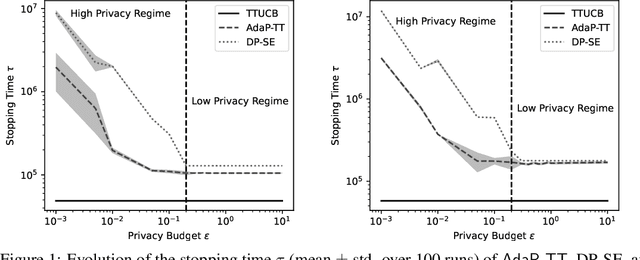
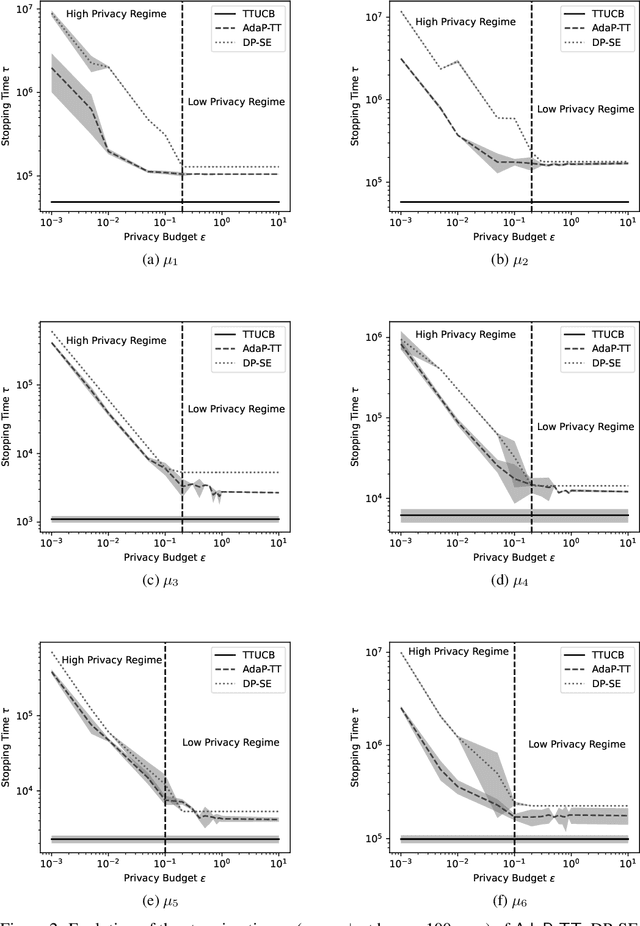
Best Arm Identification (BAI) problems are progressively used for data-sensitive applications, such as designing adaptive clinical trials, tuning hyper-parameters, and conducting user studies to name a few. Motivated by the data privacy concerns invoked by these applications, we study the problem of BAI with fixed confidence under $\epsilon$-global Differential Privacy (DP). First, to quantify the cost of privacy, we derive a lower bound on the sample complexity of any $\delta$-correct BAI algorithm satisfying $\epsilon$-global DP. Our lower bound suggests the existence of two privacy regimes depending on the privacy budget $\epsilon$. In the high-privacy regime (small $\epsilon$), the hardness depends on a coupled effect of privacy and a novel information-theoretic quantity, called the Total Variation Characteristic Time. In the low-privacy regime (large $\epsilon$), the sample complexity lower bound reduces to the classical non-private lower bound. Second, we propose AdaP-TT, an $\epsilon$-global DP variant of the Top Two algorithm. AdaP-TT runs in arm-dependent adaptive episodes and adds Laplace noise to ensure a good privacy-utility trade-off. We derive an asymptotic upper bound on the sample complexity of AdaP-TT that matches with the lower bound up to multiplicative constants in the high-privacy regime. Finally, we provide an experimental analysis of AdaP-TT that validates our theoretical results.
BigFUSE: Global Context-Aware Image Fusion in Dual-View Light-Sheet Fluorescence Microscopy with Image Formation Prior
Sep 05, 2023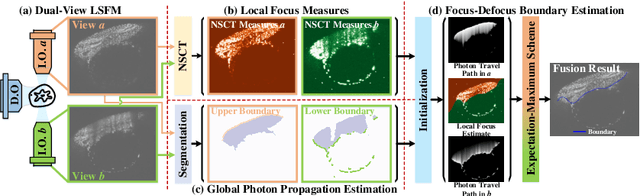
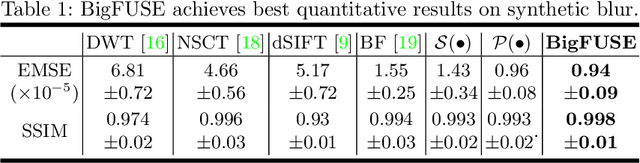


Light-sheet fluorescence microscopy (LSFM), a planar illumination technique that enables high-resolution imaging of samples, experiences defocused image quality caused by light scattering when photons propagate through thick tissues. To circumvent this issue, dualview imaging is helpful. It allows various sections of the specimen to be scanned ideally by viewing the sample from opposing orientations. Recent image fusion approaches can then be applied to determine in-focus pixels by comparing image qualities of two views locally and thus yield spatially inconsistent focus measures due to their limited field-of-view. Here, we propose BigFUSE, a global context-aware image fuser that stabilizes image fusion in LSFM by considering the global impact of photon propagation in the specimen while determining focus-defocus based on local image qualities. Inspired by the image formation prior in dual-view LSFM, image fusion is considered as estimating a focus-defocus boundary using Bayes Theorem, where (i) the effect of light scattering onto focus measures is included within Likelihood; and (ii) the spatial consistency regarding focus-defocus is imposed in Prior. The expectation-maximum algorithm is then adopted to estimate the focus-defocus boundary. Competitive experimental results show that BigFUSE is the first dual-view LSFM fuser that is able to exclude structured artifacts when fusing information, highlighting its abilities of automatic image fusion.
Label Budget Allocation in Multi-Task Learning
Aug 24, 2023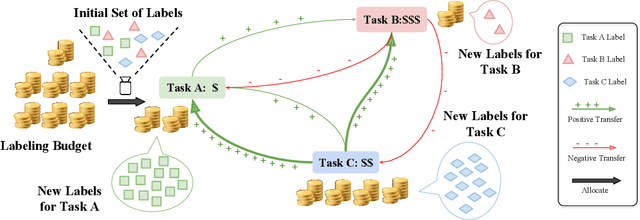
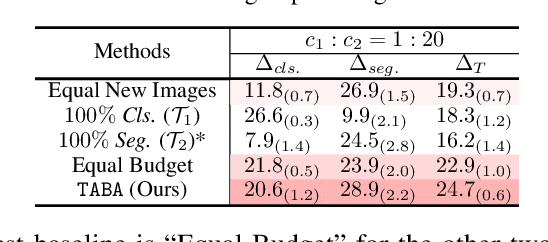
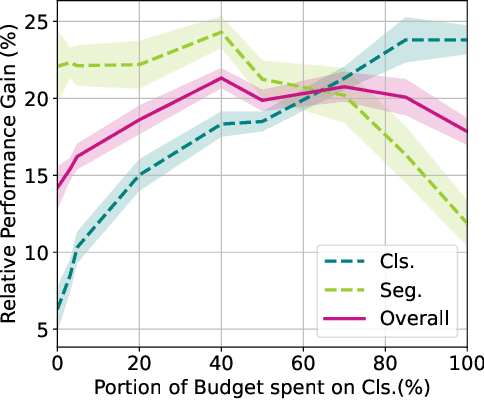
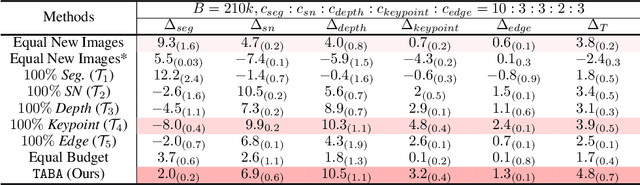
The cost of labeling data often limits the performance of machine learning systems. In multi-task learning, related tasks provide information to each other and improve overall performance, but the label cost can vary among tasks. How should the label budget (i.e. the amount of money spent on labeling) be allocated among different tasks to achieve optimal multi-task performance? We are the first to propose and formally define the label budget allocation problem in multi-task learning and to empirically show that different budget allocation strategies make a big difference to its performance. We propose a Task-Adaptive Budget Allocation algorithm to robustly generate the optimal budget allocation adaptive to different multi-task learning settings. Specifically, we estimate and then maximize the extent of new information obtained from the allocated budget as a proxy for multi-task learning performance. Experiments on PASCAL VOC and Taskonomy demonstrate the efficacy of our approach over other widely used heuristic labeling strategies.
Optimizer's Information Criterion: Dissecting and Correcting Bias in Data-Driven Optimization
Jun 16, 2023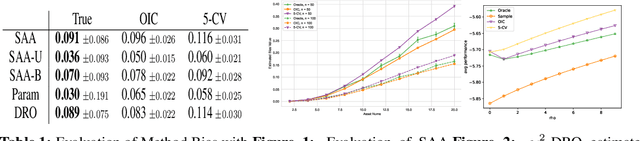
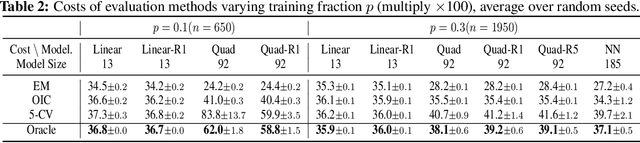

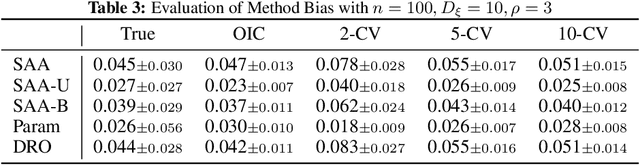
In data-driven optimization, the sample performance of the obtained decision typically incurs an optimistic bias against the true performance, a phenomenon commonly known as the Optimizer's Curse and intimately related to overfitting in machine learning. Common techniques to correct this bias, such as cross-validation, require repeatedly solving additional optimization problems and are therefore computationally expensive. We develop a general bias correction approach, building on what we call Optimizer's Information Criterion (OIC), that directly approximates the first-order bias and does not require solving any additional optimization problems. Our OIC generalizes the celebrated Akaike Information Criterion to evaluate the objective performance in data-driven optimization, which crucially involves not only model fitting but also its interplay with the downstream optimization. As such it can be used for decision selection instead of only model selection. We apply our approach to a range of data-driven optimization formulations comprising empirical and parametric models, their regularized counterparts, and furthermore contextual optimization. Finally, we provide numerical validation on the superior performance of our approach under synthetic and real-world datasets.