 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Doppler-aware Odometry from FMCW Scanning Radar
Aug 21, 2023

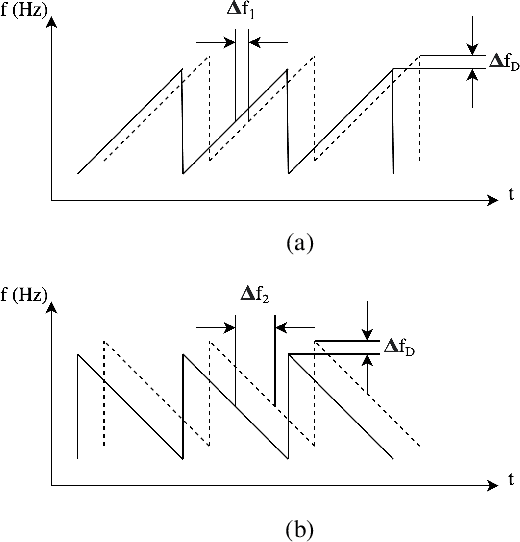
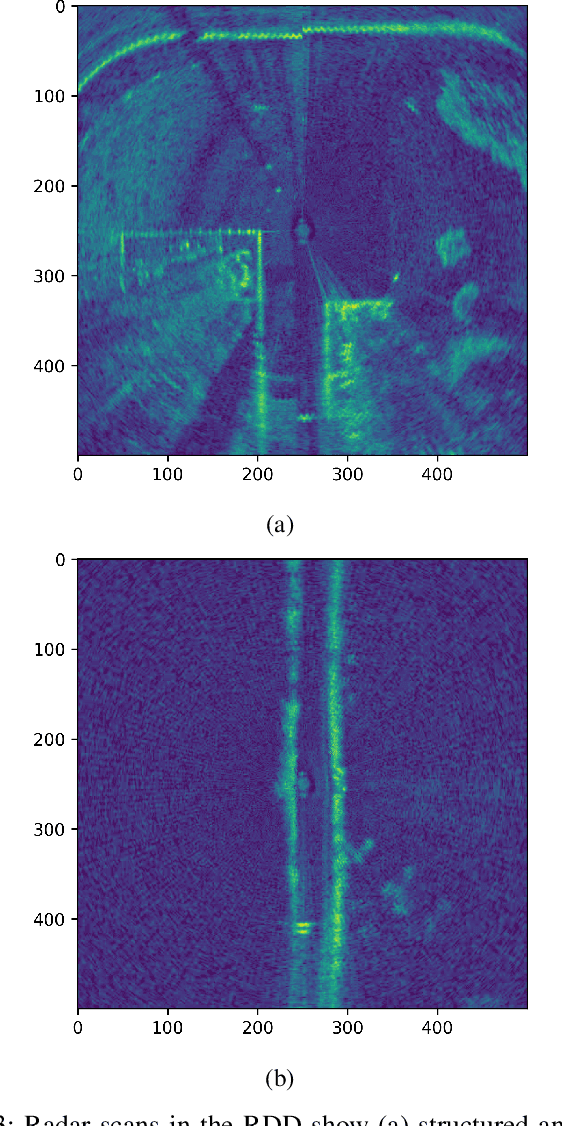
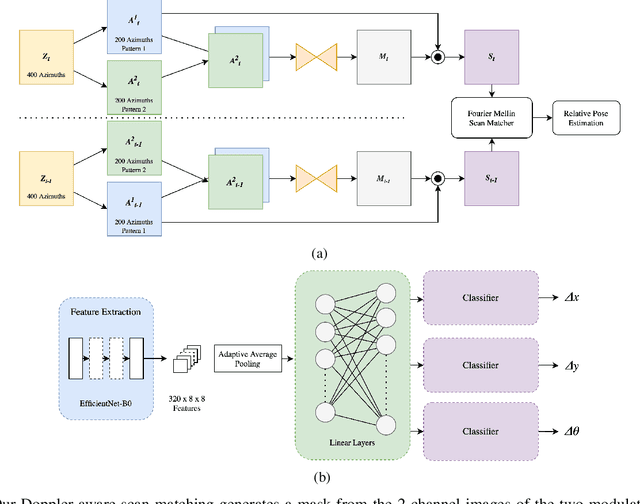
This work explores Doppler information from a millimetre-Wave (mm-W) Frequency-Modulated Continuous-Wave (FMCW) scanning radar to make odometry estimation more robust and accurate. Firstly, doppler information is added to the scan masking process to enhance correlative scan matching. Secondly, we train a Neural Network (NN) for regressing forward velocity directly from a single radar scan; we fuse this estimate with the correlative scan matching estimate and show improved robustness to bad estimates caused by challenging environment geometries, e.g. narrow tunnels. We test our method with a novel custom dataset which is released with this work at https://ori.ox.ac.uk/publications/datasets.
LDL: Line Distance Functions for Panoramic Localization
Aug 27, 2023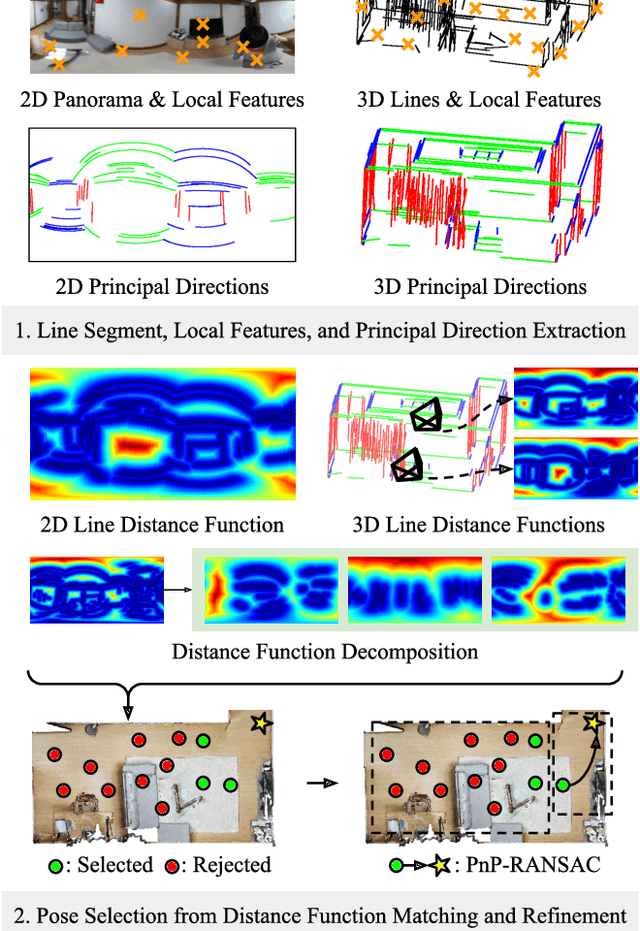
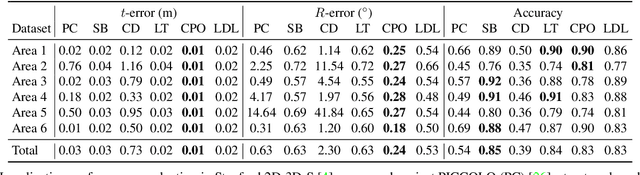
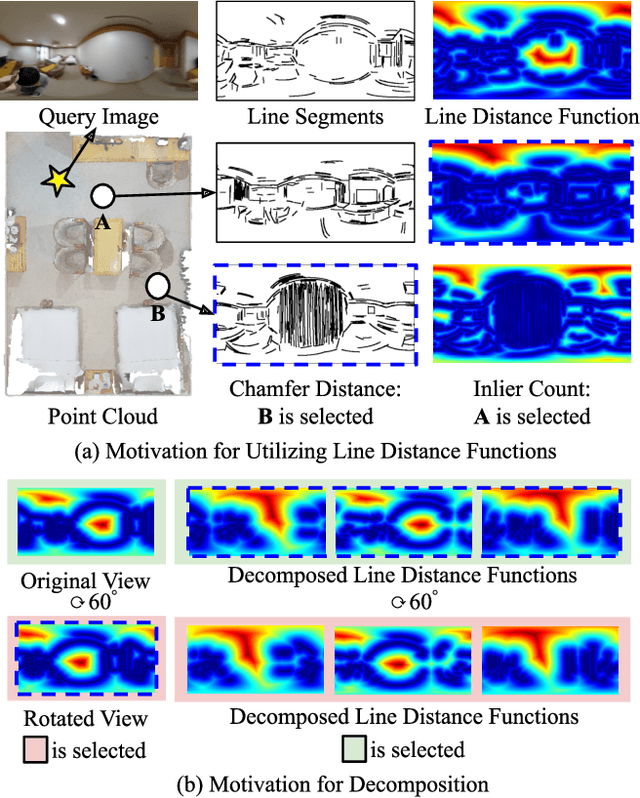
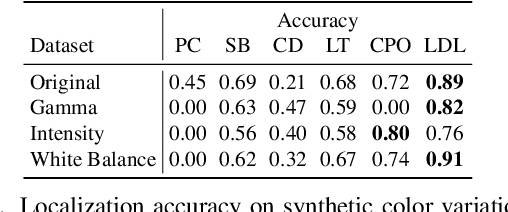
We introduce LDL, a fast and robust algorithm that localizes a panorama to a 3D map using line segments. LDL focuses on the sparse structural information of lines in the scene, which is robust to illumination changes and can potentially enable efficient computation. While previous line-based localization approaches tend to sacrifice accuracy or computation time, our method effectively observes the holistic distribution of lines within panoramic images and 3D maps. Specifically, LDL matches the distribution of lines with 2D and 3D line distance functions, which are further decomposed along principal directions of lines to increase the expressiveness. The distance functions provide coarse pose estimates by comparing the distributional information, where the poses are further optimized using conventional local feature matching. As our pipeline solely leverages line geometry and local features, it does not require costly additional training of line-specific features or correspondence matching. Nevertheless, our method demonstrates robust performance on challenging scenarios including object layout changes, illumination shifts, and large-scale scenes, while exhibiting fast pose search terminating within a matter of milliseconds. We thus expect our method to serve as a practical solution for line-based localization, and complement the well-established point-based paradigm. The code for LDL is available through the following link: https://github.com/82magnolia/panoramic-localization.
SAM++: Enhancing Anatomic Matching using Semantic Information and Structural Inference
Jun 24, 2023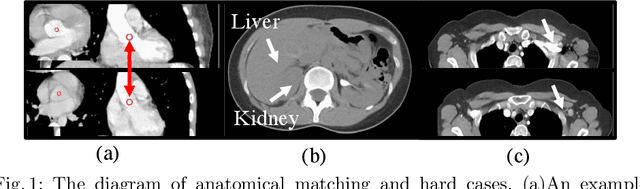
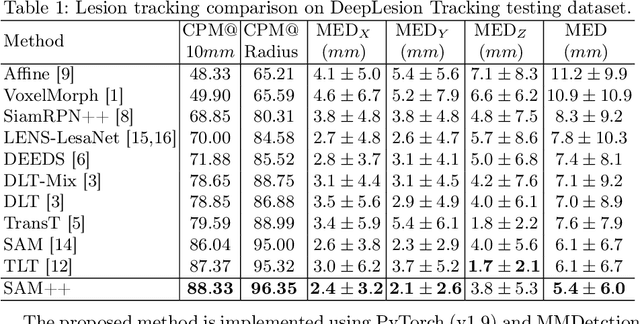
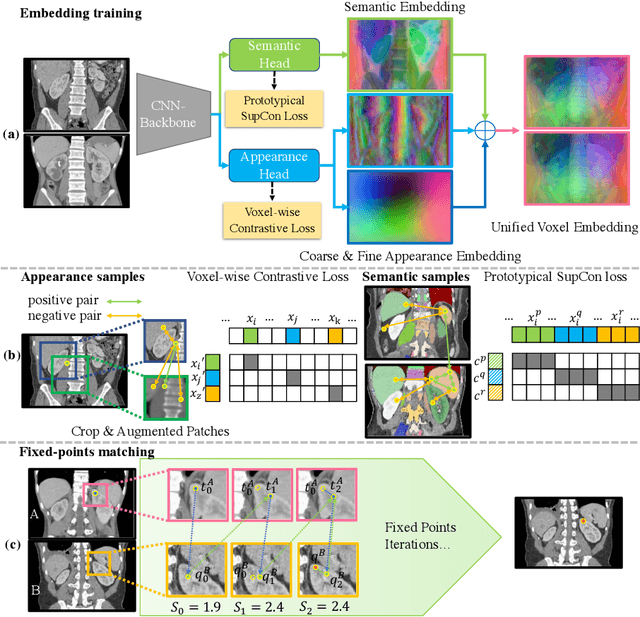
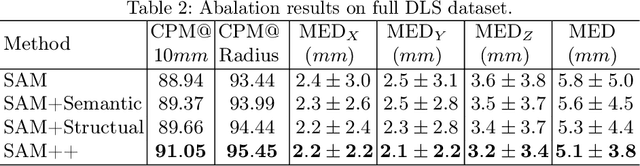
Medical images like CT and MRI provide detailed information about the internal structure of the body, and identifying key anatomical structures from these images plays a crucial role in clinical workflows. Current methods treat it as a registration or key-point regression task, which has limitations in accurate matching and can only handle predefined landmarks. Recently, some methods have been introduced to address these limitations. One such method, called SAM, proposes using a dense self-supervised approach to learn a distinct embedding for each point on the CT image and achieving promising results. Nonetheless, SAM may still face difficulties when dealing with structures that have similar appearances but different semantic meanings or similar semantic meanings but different appearances. To overcome these limitations, we propose SAM++, a framework that simultaneously learns appearance and semantic embeddings with a novel fixed-points matching mechanism. We tested the SAM++ framework on two challenging tasks, demonstrating a significant improvement over the performance of SAM and outperforming other existing methods.
NF4 Isn't Information Theoretically Optimal (and that's Good)
Jun 12, 2023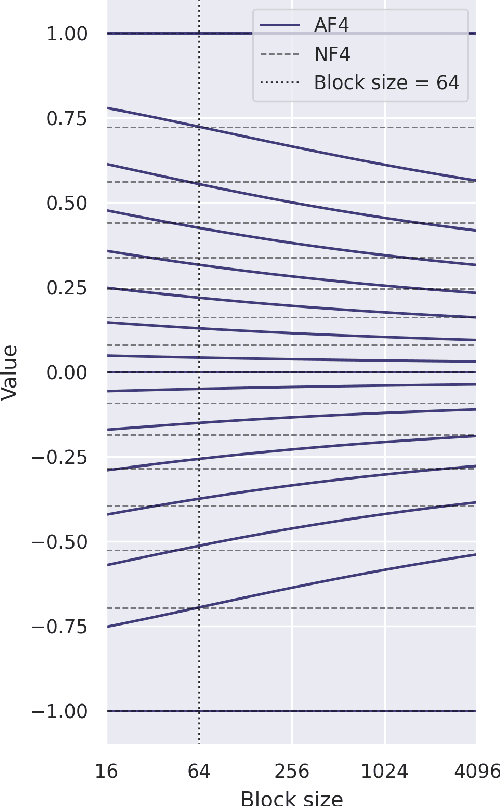
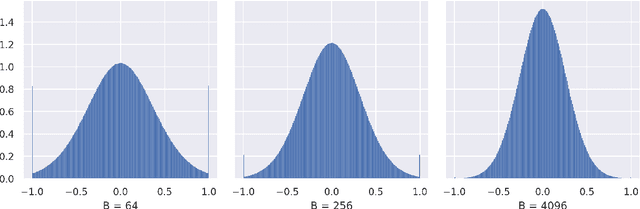
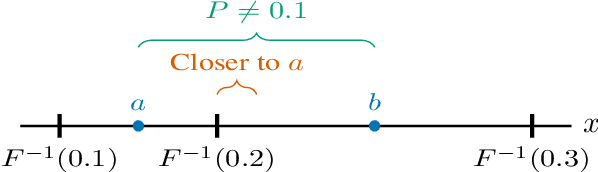
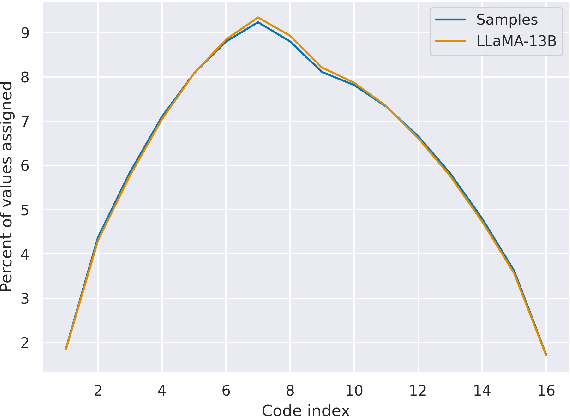
This note shares some simple calculations and experiments related to absmax-based blockwise quantization, as used in Dettmers et al., 2023. Their proposed NF4 data type is said to be information theoretically optimal for representing normally distributed weights. I show that this is can't quite be the case, as the distribution of the values to be quantized depends on the block-size. I attempt to apply these insights to derive an improved code based on minimizing the expected L1 reconstruction error, rather than the quantile based method. This leads to improved performance for larger quantization block sizes, while both codes perform similarly at smaller block sizes.
Large AI Model Empowered Multimodal Semantic Communications
Sep 03, 2023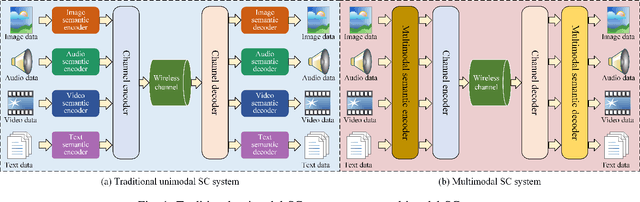
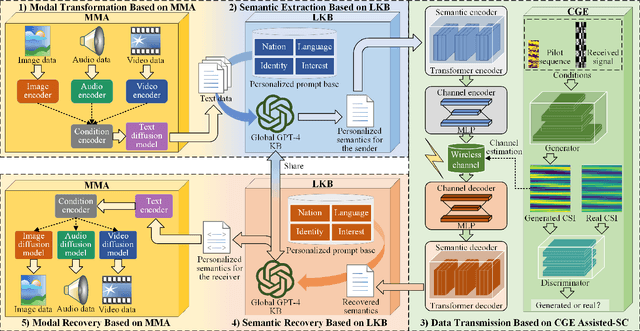
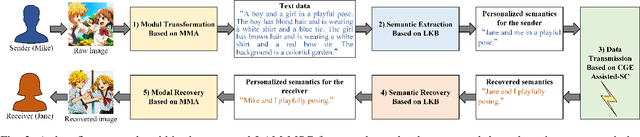
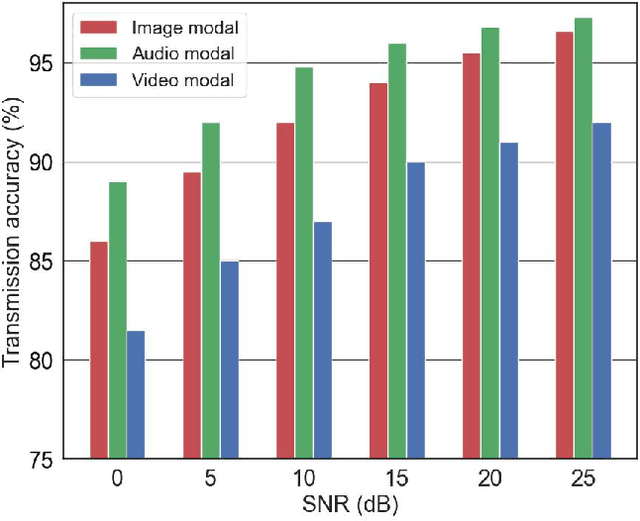
Multimodal signals, including text, audio, image and video, can be integrated into Semantic Communication (SC) for providing an immersive experience with low latency and high quality at the semantic level. However, the multimodal SC has several challenges, including data heterogeneity, semantic ambiguity, and signal fading. Recent advancements in large AI models, particularly in Multimodal Language Model (MLM) and Large Language Model (LLM), offer potential solutions for these issues. To this end, we propose a Large AI Model-based Multimodal SC (LAM-MSC) framework, in which we first present the MLM-based Multimodal Alignment (MMA) that utilizes the MLM to enable the transformation between multimodal and unimodal data while preserving semantic consistency. Then, a personalized LLM-based Knowledge Base (LKB) is proposed, which allows users to perform personalized semantic extraction or recovery through the LLM. This effectively addresses the semantic ambiguity. Finally, we apply the Conditional Generative adversarial networks-based channel Estimation (CGE) to obtain Channel State Information (CSI). This approach effectively mitigates the impact of fading channels in SC. Finally, we conduct simulations that demonstrate the superior performance of the LAM-MSC framework.
UnsMOT: Unified Framework for Unsupervised Multi-Object Tracking with Geometric Topology Guidance
Sep 03, 2023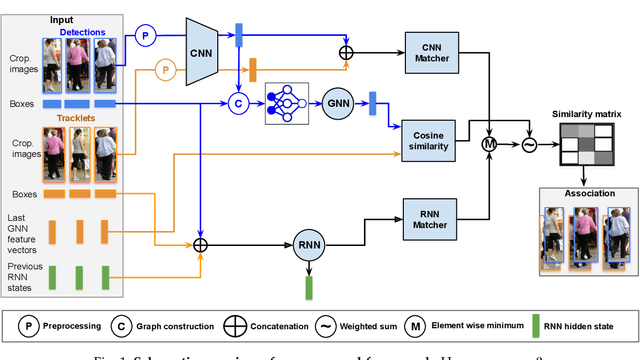
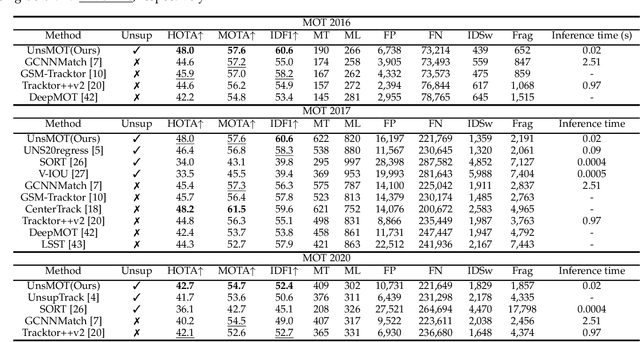

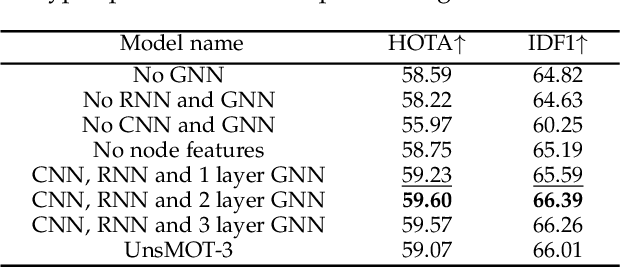
Object detection has long been a topic of high interest in computer vision literature. Motivated by the fact that annotating data for the multi-object tracking (MOT) problem is immensely expensive, recent studies have turned their attention to the unsupervised learning setting. In this paper, we push forward the state-of-the-art performance of unsupervised MOT methods by proposing UnsMOT, a novel framework that explicitly combines the appearance and motion features of objects with geometric information to provide more accurate tracking. Specifically, we first extract the appearance and motion features using CNN and RNN models, respectively. Then, we construct a graph of objects based on their relative distances in a frame, which is fed into a GNN model together with CNN features to output geometric embedding of objects optimized using an unsupervised loss function. Finally, associations between objects are found by matching not only similar extracted features but also geometric embedding of detections and tracklets. Experimental results show remarkable performance in terms of HOTA, IDF1, and MOTA metrics in comparison with state-of-the-art methods.
Face Clustering for Connection Discovery from Event Images
Sep 03, 2023Social graphs are very useful for many applications, such as recommendations and community detections. However, they are only accessible to big social network operators due to both data availability and privacy concerns. Event images also capture the interactions among the participants, from which social connections can be discovered to form a social graph. Unlike online social graphs, social connections carried by event images can be extracted without user inputs, and hence many social graph-based applications become possible, even without access to online social graphs. This paper proposes a system to discover social connections from event images. By utilizing the social information from even images, such as co-occurrence, a face clustering method is proposed and implemented, and connections can be discovered without the identity of the event participants. By collecting over 40000 faces from over 3000 participants, it is shown that the faces can be well clustered with 80% in F1 score, and social graphs can be constructed. Utilizing offline event images may create a long-term impact on social network analytics.
Bayesian inference of composition-dependent phase diagrams
Sep 03, 2023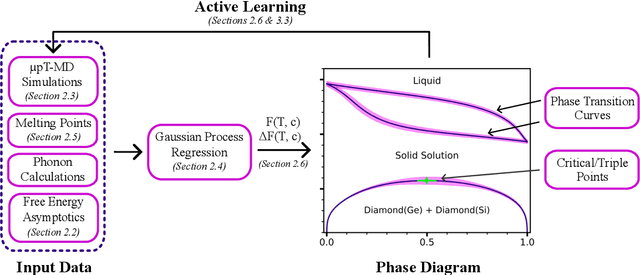
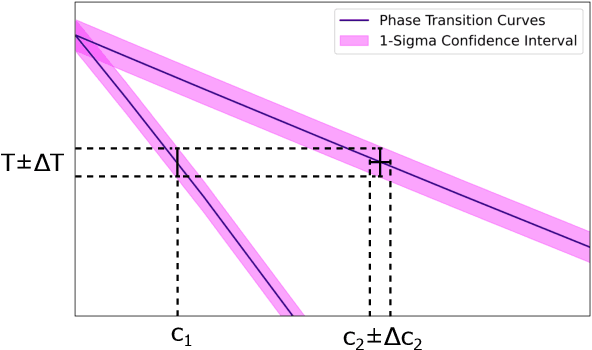
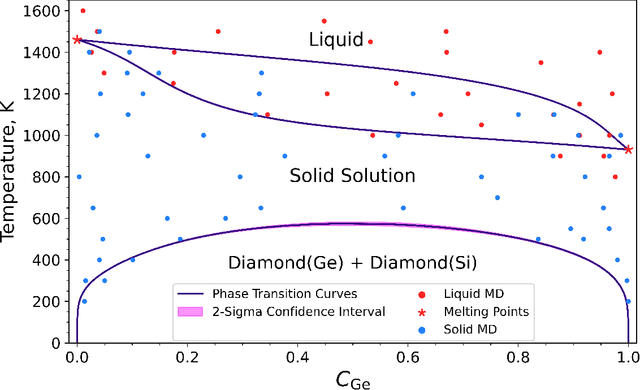
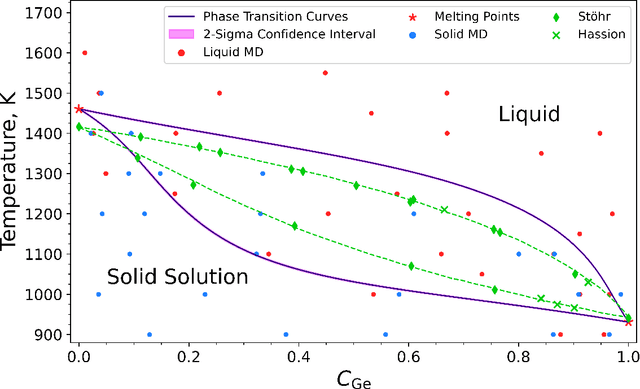
Phase diagrams serve as a highly informative tool for materials design, encapsulating information about the phases that a material can manifest under specific conditions. In this work, we develop a method in which Bayesian inference is employed to combine thermodynamic data from molecular dynamics (MD), melting point simulations, and phonon calculations, process these data, and yield a temperature-concentration phase diagram. The employed Bayesian framework yields us not only the free energies of different phases as functions of temperature and concentration but also the uncertainties of these free energies originating from statistical errors inherent to finite-length MD trajectories. Furthermore, it extrapolates the results of the finite-atom calculations to the infinite-atom limit and facilitates the choice of temperature, chemical potentials, and the number of atoms conducting the next simulation with which will be the most efficient in reducing the uncertainty of the phase diagram. The developed algorithm was successfully tested on two binary systems, Ge-Si and K-Na, in the full range of concentrations and temperatures.
Diffusion Model is Secretly a Training-free Open Vocabulary Semantic Segmenter
Sep 06, 2023Recent research has explored the utilization of pre-trained text-image discriminative models, such as CLIP, to tackle the challenges associated with open-vocabulary semantic segmentation. However, it is worth noting that the alignment process based on contrastive learning employed by these models may unintentionally result in the loss of crucial localization information and object completeness, which are essential for achieving accurate semantic segmentation. More recently, there has been an emerging interest in extending the application of diffusion models beyond text-to-image generation tasks, particularly in the domain of semantic segmentation. These approaches utilize diffusion models either for generating annotated data or for extracting features to facilitate semantic segmentation. This typically involves training segmentation models by generating a considerable amount of synthetic data or incorporating additional mask annotations. To this end, we uncover the potential of generative text-to-image conditional diffusion models as highly efficient open-vocabulary semantic segmenters, and introduce a novel training-free approach named DiffSegmenter. Specifically, by feeding an input image and candidate classes into an off-the-shelf pre-trained conditional latent diffusion model, the cross-attention maps produced by the denoising U-Net are directly used as segmentation scores, which are further refined and completed by the followed self-attention maps. Additionally, we carefully design effective textual prompts and a category filtering mechanism to further enhance the segmentation results. Extensive experiments on three benchmark datasets show that the proposed DiffSegmenter achieves impressive results for open-vocabulary semantic segmentation.
Subsethood Measures of Spatial Granules
Sep 06, 2023Subsethood, which is to measure the degree of set inclusion relation, is predominant in fuzzy set theory. This paper introduces some basic concepts of spatial granules, coarse-fine relation, and operations like meet, join, quotient meet and quotient join. All the atomic granules can be hierarchized by set-inclusion relation and all the granules can be hierarchized by coarse-fine relation. Viewing an information system from the micro and the macro perspectives, we can get a micro knowledge space and a micro knowledge space, from which a rough set model and a spatial rough granule model are respectively obtained. The classical rough set model is the special case of the rough set model induced from the micro knowledge space, while the spatial rough granule model will be play a pivotal role in the problem-solving of structures. We discuss twelve axioms of monotone increasing subsethood and twelve corresponding axioms of monotone decreasing supsethood, and generalize subsethood and supsethood to conditional granularity and conditional fineness respectively. We develop five conditional granularity measures and five conditional fineness measures and prove that each conditional granularity or fineness measure satisfies its corresponding twelve axioms although its subsethood or supsethood measure only hold one of the two boundary conditions. We further define five conditional granularity entropies and five conditional fineness entropies respectively, and each entropy only satisfies part of the boundary conditions but all the ten monotone conditions.