 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MoCoSA: Momentum Contrast for Knowledge Graph Completion with Structure-Augmented Pre-trained Language Models
Aug 16, 2023
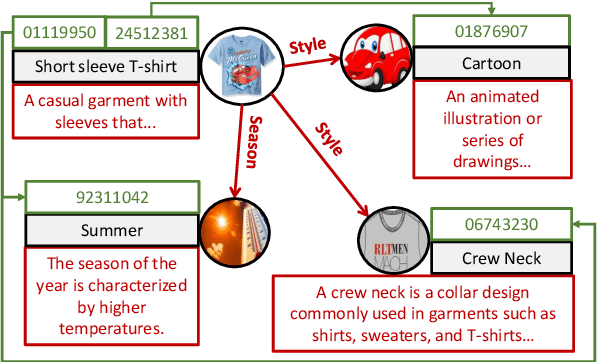
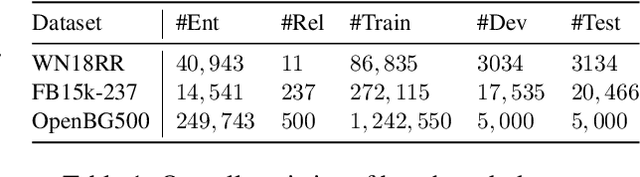
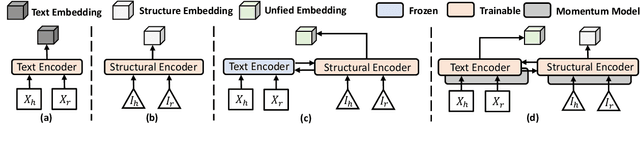
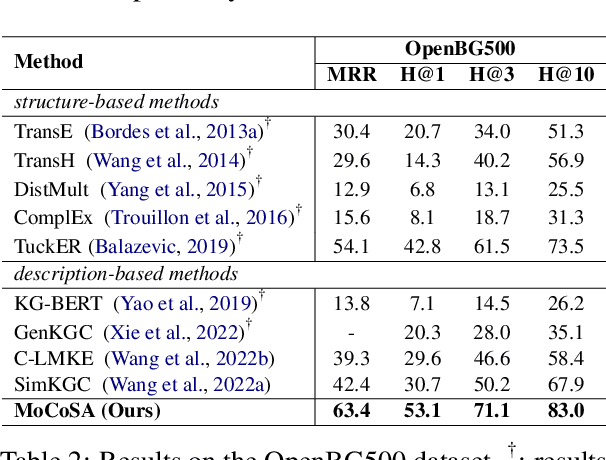
Knowledge Graph Completion (KGC) aims to conduct reasoning on the facts within knowledge graphs and automatically infer missing links. Existing methods can mainly be categorized into structure-based or description-based. On the one hand, structure-based methods effectively represent relational facts in knowledge graphs using entity embeddings. However, they struggle with semantically rich real-world entities due to limited structural information and fail to generalize to unseen entities. On the other hand, description-based methods leverage pre-trained language models (PLMs) to understand textual information. They exhibit strong robustness towards unseen entities. However, they have difficulty with larger negative sampling and often lag behind structure-based methods. To address these issues, in this paper, we propose Momentum Contrast for knowledge graph completion with Structure-Augmented pre-trained language models (MoCoSA), which allows the PLM to perceive the structural information by the adaptable structure encoder. To improve learning efficiency, we proposed momentum hard negative and intra-relation negative sampling. Experimental results demonstrate that our approach achieves state-of-the-art performance in terms of mean reciprocal rank (MRR), with improvements of 2.5% on WN18RR and 21% on OpenBG500.
CVNN-based Channel Estimation and Equalization in OFDM Systems Without Cyclic Prefix
Aug 25, 2023In modern communication systems operating with Orthogonal Frequency-Division Multiplexing (OFDM), channel estimation requires minimal complexity with one-tap equalizers. However, this depends on cyclic prefixes, which must be sufficiently large to cover the channel impulse response. Conversely, the use of cyclic prefix (CP) decreases the useful information that can be conveyed in an OFDM frame, thereby degrading the spectral efficiency of the system. In this context, we study the impact of CPs on channel estimation with complex-valued neural networks (CVNNs). We show that the phase-transmittance radial basis function neural network offers superior results, in terms of required energy per bit, compared to classical minimum mean-squared error and least squares algorithms in scenarios without CP.
Leveraging Knowledge and Reinforcement Learning for Enhanced Reliability of Language Models
Aug 25, 2023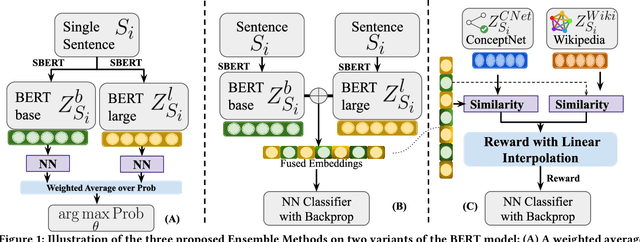
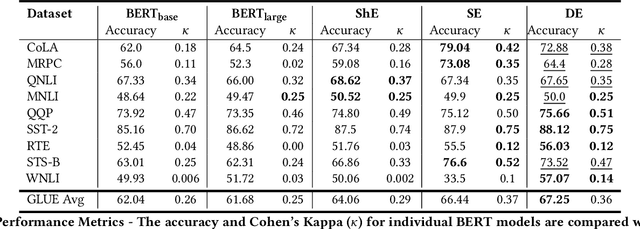
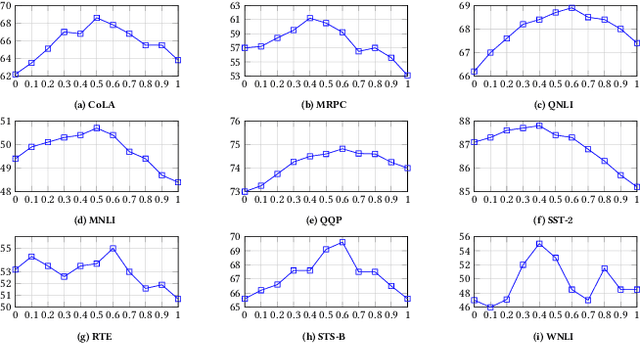
The Natural Language Processing(NLP) community has been using crowd sourcing techniques to create benchmark datasets such as General Language Understanding and Evaluation(GLUE) for training modern Language Models such as BERT. GLUE tasks measure the reliability scores using inter annotator metrics i.e. Cohens Kappa. However, the reliability aspect of LMs has often been overlooked. To counter this problem, we explore a knowledge-guided LM ensembling approach that leverages reinforcement learning to integrate knowledge from ConceptNet and Wikipedia as knowledge graph embeddings. This approach mimics human annotators resorting to external knowledge to compensate for information deficits in the datasets. Across nine GLUE datasets, our research shows that ensembling strengthens reliability and accuracy scores, outperforming state of the art.
Nougat: Neural Optical Understanding for Academic Documents
Aug 25, 2023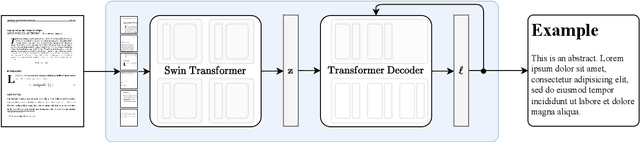
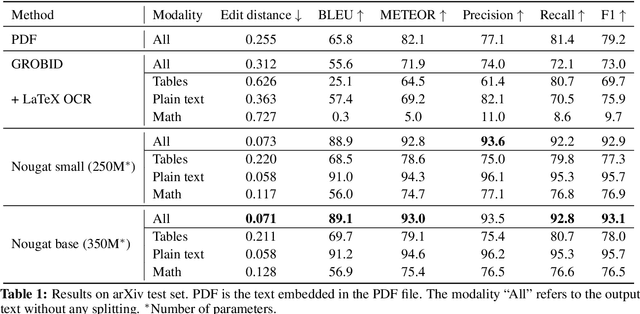


Scientific knowledge is predominantly stored in books and scientific journals, often in the form of PDFs. However, the PDF format leads to a loss of semantic information, particularly for mathematical expressions. We propose Nougat (Neural Optical Understanding for Academic Documents), a Visual Transformer model that performs an Optical Character Recognition (OCR) task for processing scientific documents into a markup language, and demonstrate the effectiveness of our model on a new dataset of scientific documents. The proposed approach offers a promising solution to enhance the accessibility of scientific knowledge in the digital age, by bridging the gap between human-readable documents and machine-readable text. We release the models and code to accelerate future work on scientific text recognition.
Explaining Predictive Uncertainty with Information Theoretic Shapley Values
Jun 09, 2023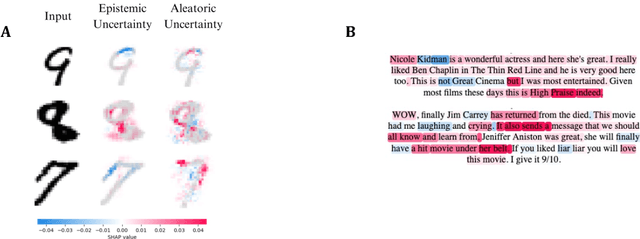
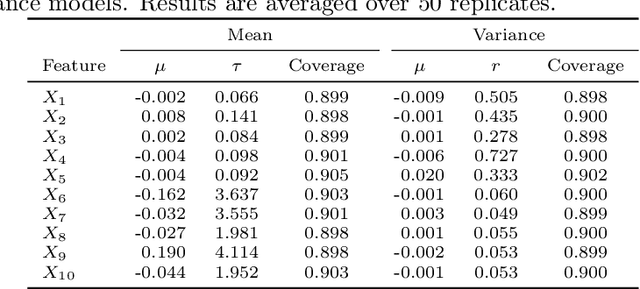
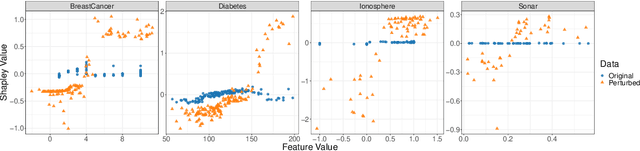
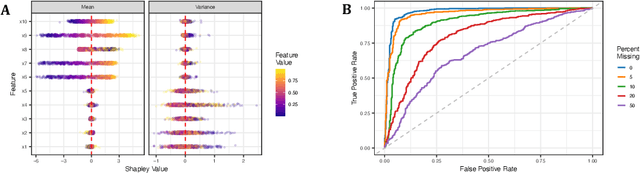
Researchers in explainable artificial intelligence have developed numerous methods for helping users understand the predictions of complex supervised learning models. By contrast, explaining the $\textit{uncertainty}$ of model outputs has received relatively little attention. We adapt the popular Shapley value framework to explain various types of predictive uncertainty, quantifying each feature's contribution to the conditional entropy of individual model outputs. We consider games with modified characteristic functions and find deep connections between the resulting Shapley values and fundamental quantities from information theory and conditional independence testing. We outline inference procedures for finite sample error rate control with provable guarantees, and implement an efficient algorithm that performs well in a range of experiments on real and simulated data. Our method has applications to covariate shift detection, active learning, feature selection, and active feature-value acquisition.
Projecting Robot Intentions Through Visual Cues: Static vs. Dynamic Signaling
Aug 19, 2023
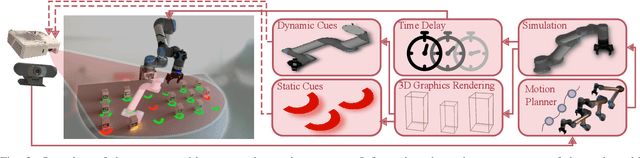

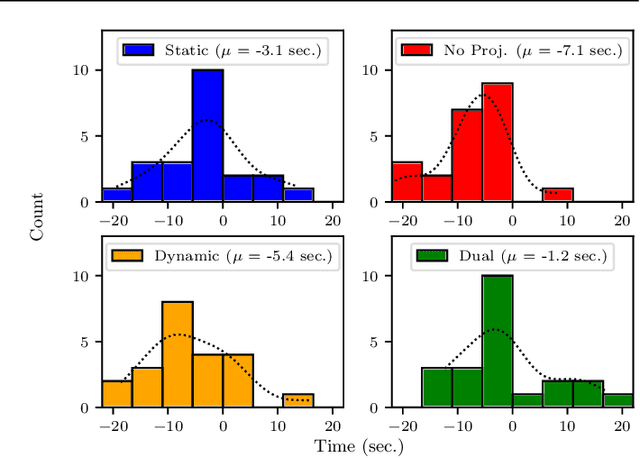
Augmented and mixed-reality techniques harbor a great potential for improving human-robot collaboration. Visual signals and cues may be projected to a human partner in order to explicitly communicate robot intentions and goals. However, it is unclear what type of signals support such a process and whether signals can be combined without adding additional cognitive stress to the partner. This paper focuses on identifying the effective types of visual signals and quantify their impact through empirical evaluations. In particular, the study compares static and dynamic visual signals within a collaborative object sorting task and assesses their ability to shape human behavior. Furthermore, an information-theoretic analysis is performed to numerically quantify the degree of information transfer between visual signals and human behavior. The results of a human subject experiment show that there are significant advantages to combining multiple visual signals within a single task, i.e., increased task efficiency and reduced cognitive load.
Contrastive Learning for Non-Local Graphs with Multi-Resolution Structural Views
Aug 19, 2023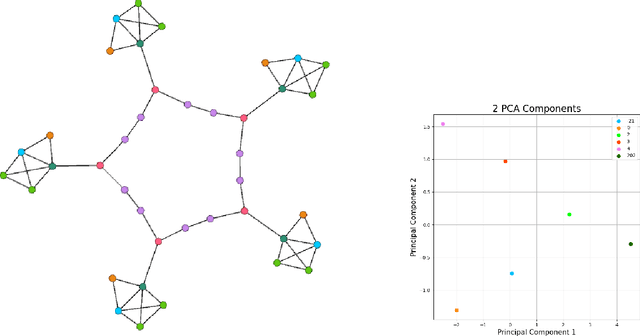
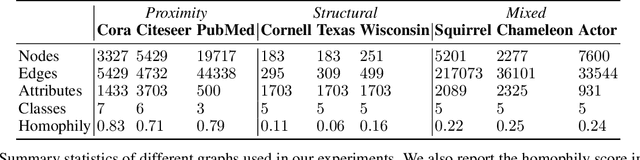
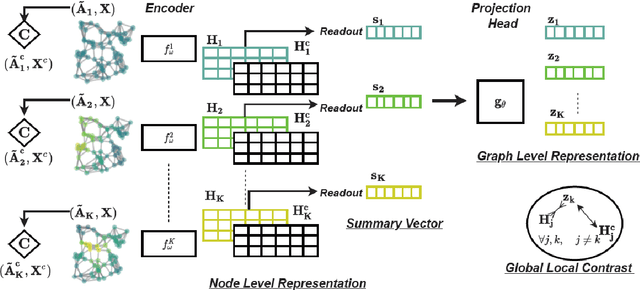
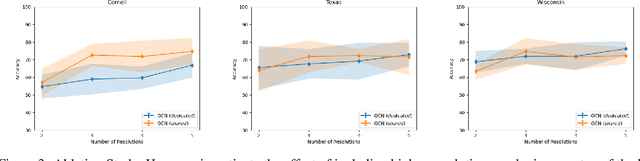
Learning node-level representations of heterophilic graphs is crucial for various applications, including fraudster detection and protein function prediction. In such graphs, nodes share structural similarity identified by the equivalence of their connectivity which is implicitly encoded in the form of higher-order hierarchical information in the graphs. The contrastive methods are popular choices for learning the representation of nodes in a graph. However, existing contrastive methods struggle to capture higher-order graph structures. To address this limitation, we propose a novel multiview contrastive learning approach that integrates diffusion filters on graphs. By incorporating multiple graph views as augmentations, our method captures the structural equivalence in heterophilic graphs, enabling the discovery of hidden relationships and similarities not apparent in traditional node representations. Our approach outperforms baselines on synthetic and real structural datasets, surpassing the best baseline by $16.06\%$ on Cornell, $3.27\%$ on Texas, and $8.04\%$ on Wisconsin. Additionally, it consistently achieves superior performance on proximal tasks, demonstrating its effectiveness in uncovering structural information and improving downstream applications.
How Object Information Improves Skeleton-based Human Action Recognition in Assembly Tasks
Jun 09, 2023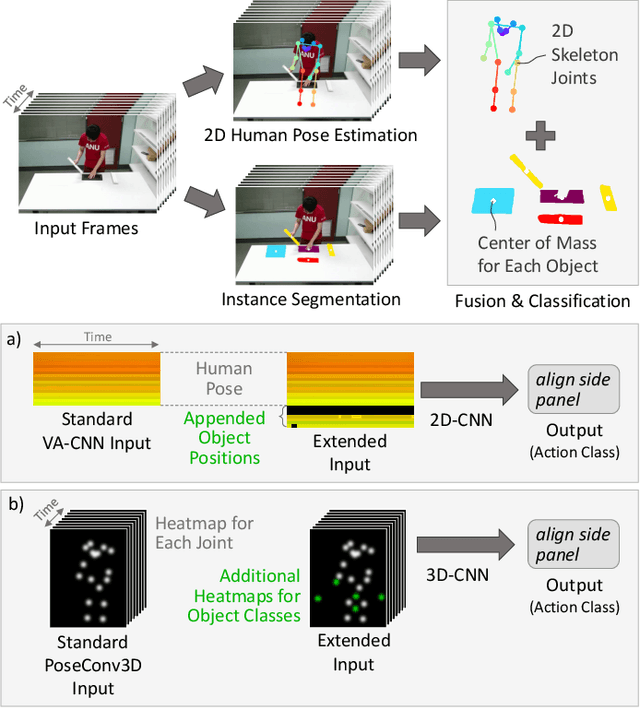

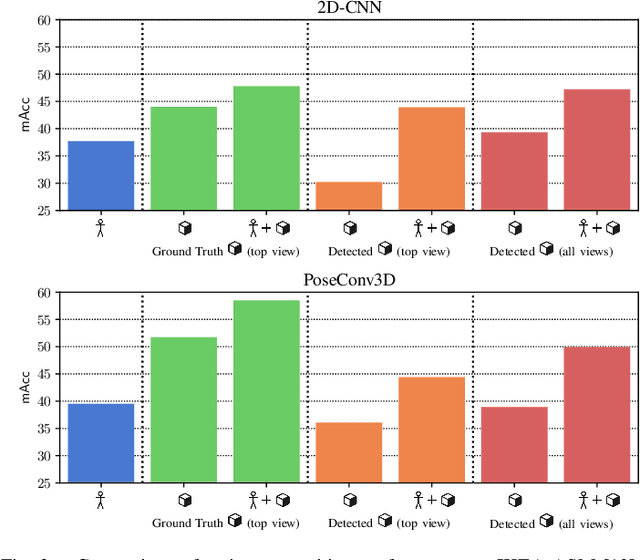
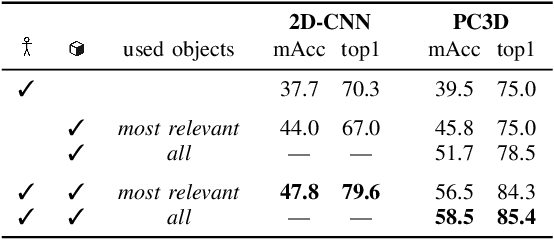
As the use of collaborative robots (cobots) in industrial manufacturing continues to grow, human action recognition for effective human-robot collaboration becomes increasingly important. This ability is crucial for cobots to act autonomously and assist in assembly tasks. Recently, skeleton-based approaches are often used as they tend to generalize better to different people and environments. However, when processing skeletons alone, information about the objects a human interacts with is lost. Therefore, we present a novel approach of integrating object information into skeleton-based action recognition. We enhance two state-of-the-art methods by treating object centers as further skeleton joints. Our experiments on the assembly dataset IKEA ASM show that our approach improves the performance of these state-of-the-art methods to a large extent when combining skeleton joints with objects predicted by a state-of-the-art instance segmentation model. Our research sheds light on the benefits of combining skeleton joints with object information for human action recognition in assembly tasks. We analyze the effect of the object detector on the combination for action classification and discuss the important factors that must be taken into account.
STAEformer: Spatio-Temporal Adaptive Embedding Makes Vanilla Transformer SOTA for Traffic Forecasting
Aug 26, 2023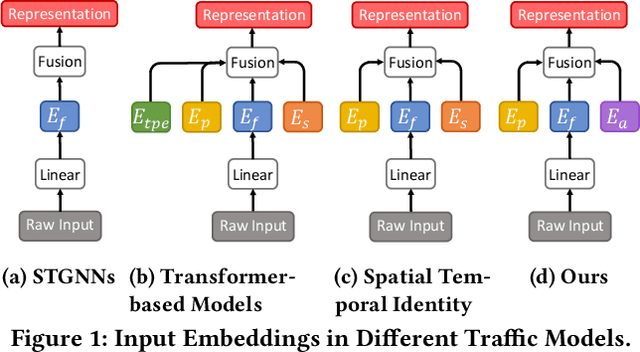
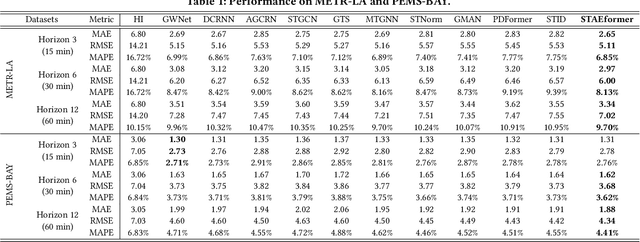
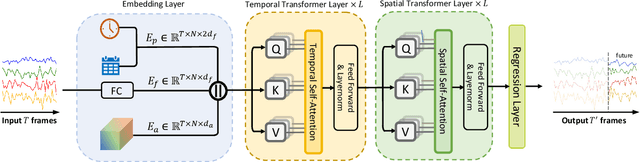
With the rapid development of the Intelligent Transportation System (ITS), accurate traffic forecasting has emerged as a critical challenge. The key bottleneck lies in capturing the intricate spatio-temporal traffic patterns. In recent years, numerous neural networks with complicated architectures have been proposed to address this issue. However, the advancements in network architectures have encountered diminishing performance gains. In this study, we present a novel component called spatio-temporal adaptive embedding that can yield outstanding results with vanilla transformers. Our proposed Spatio-Temporal Adaptive Embedding transformer (STAEformer) achieves state-of-the-art performance on five real-world traffic forecasting datasets. Further experiments demonstrate that spatio-temporal adaptive embedding plays a crucial role in traffic forecasting by effectively capturing intrinsic spatio-temporal relations and chronological information in traffic time series.
Exploring Human Crowd Patterns and Categorization in Video Footage for Enhanced Security and Surveillance using Computer Vision and Machine Learning
Aug 26, 2023Computer vision and machine learning have brought revolutionary shifts in perception for researchers, scientists, and the general populace. Once thought to be unattainable, these technologies have achieved the seemingly impossible. Their exceptional applications in diverse fields like security, agriculture, and education are a testament to their impact. However, the full potential of computer vision remains untapped. This paper explores computer vision's potential in security and surveillance, presenting a novel approach to track motion in videos. By categorizing motion into Arcs, Lanes, Converging/Diverging, and Random/Block motions using Motion Information Images and Blockwise dominant motion data, the paper examines different optical flow techniques, CNN models, and machine learning models. Successfully achieving its objectives with promising accuracy, the results can train anomaly-detection models, provide behavioral insights based on motion, and enhance scene comprehension.