 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CIEM: Contrastive Instruction Evaluation Method for Better Instruction Tuning
Sep 05, 2023
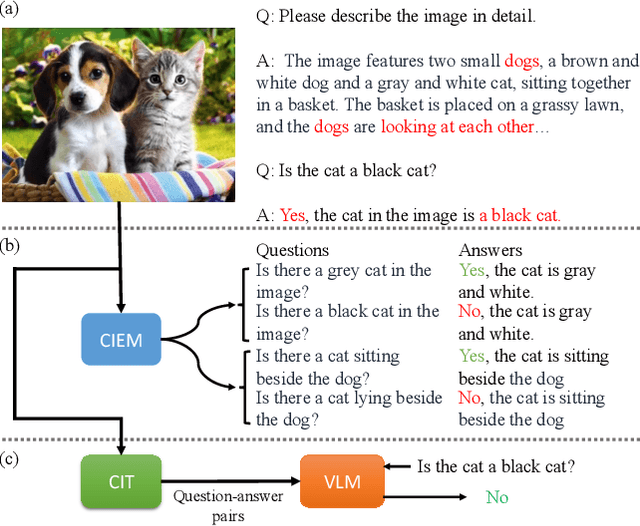

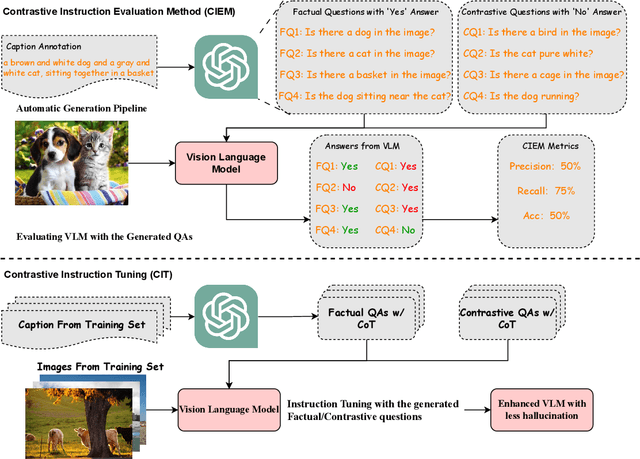

Nowadays, the research on Large Vision-Language Models (LVLMs) has been significantly promoted thanks to the success of Large Language Models (LLM). Nevertheless, these Vision-Language Models (VLMs) are suffering from the drawback of hallucination -- due to insufficient understanding of vision and language modalities, VLMs may generate incorrect perception information when doing downstream applications, for example, captioning a non-existent entity. To address the hallucination phenomenon, on the one hand, we introduce a Contrastive Instruction Evaluation Method (CIEM), which is an automatic pipeline that leverages an annotated image-text dataset coupled with an LLM to generate factual/contrastive question-answer pairs for the evaluation of the hallucination of VLMs. On the other hand, based on CIEM, we further propose a new instruction tuning method called CIT (the abbreviation of Contrastive Instruction Tuning) to alleviate the hallucination of VLMs by automatically producing high-quality factual/contrastive question-answer pairs and corresponding justifications for model tuning. Through extensive experiments on CIEM and CIT, we pinpoint the hallucination issues commonly present in existing VLMs, the disability of the current instruction-tuning dataset to handle the hallucination phenomenon and the superiority of CIT-tuned VLMs over both CIEM and public datasets.
DR-Pose: A Two-stage Deformation-and-Registration Pipeline for Category-level 6D Object Pose Estimation
Sep 05, 2023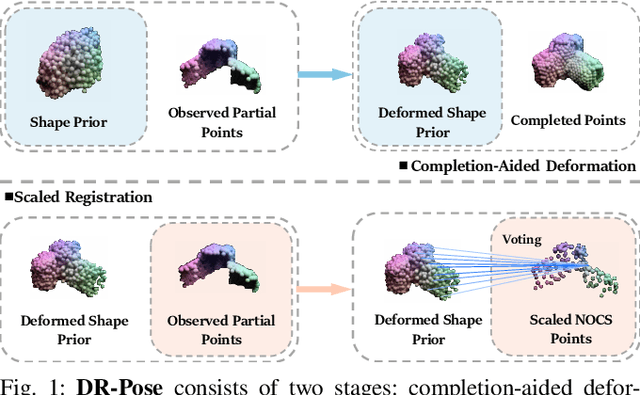
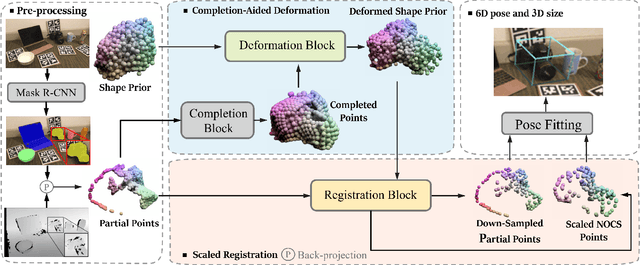
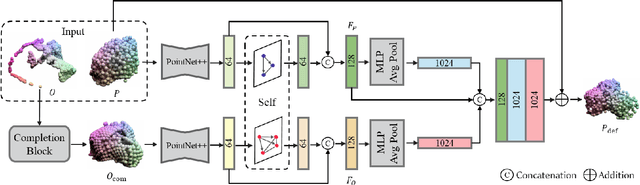
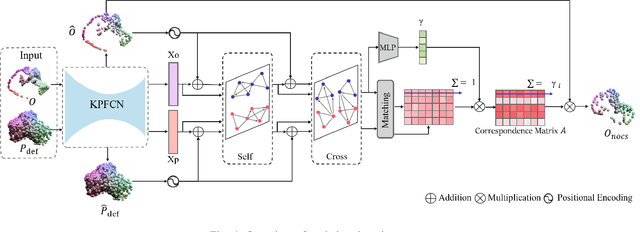
Category-level object pose estimation involves estimating the 6D pose and the 3D metric size of objects from predetermined categories. While recent approaches take categorical shape prior information as reference to improve pose estimation accuracy, the single-stage network design and training manner lead to sub-optimal performance since there are two distinct tasks in the pipeline. In this paper, the advantage of two-stage pipeline over single-stage design is discussed. To this end, we propose a two-stage deformation-and registration pipeline called DR-Pose, which consists of completion-aided deformation stage and scaled registration stage. The first stage uses a point cloud completion method to generate unseen parts of target object, guiding subsequent deformation on the shape prior. In the second stage, a novel registration network is designed to extract pose-sensitive features and predict the representation of object partial point cloud in canonical space based on the deformation results from the first stage. DR-Pose produces superior results to the state-of-the-art shape prior-based methods on both CAMERA25 and REAL275 benchmarks. Codes are available at https://github.com/Zray26/DR-Pose.git.
Adaptive Ordered Information Extraction with Deep Reinforcement Learning
Jun 19, 2023
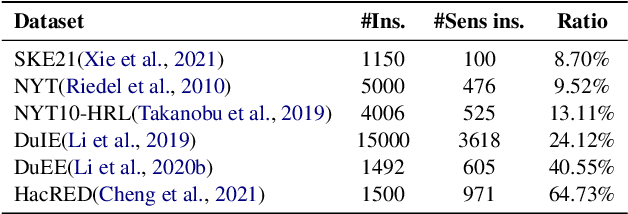
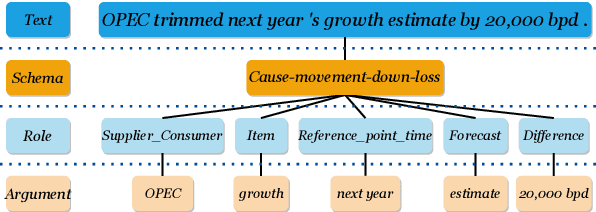
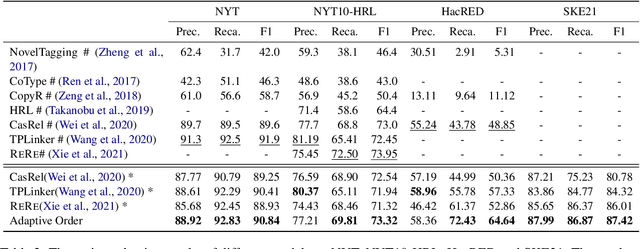
Information extraction (IE) has been studied extensively. The existing methods always follow a fixed extraction order for complex IE tasks with multiple elements to be extracted in one instance such as event extraction. However, we conduct experiments on several complex IE datasets and observe that different extraction orders can significantly affect the extraction results for a great portion of instances, and the ratio of sentences that are sensitive to extraction orders increases dramatically with the complexity of the IE task. Therefore, this paper proposes a novel adaptive ordered IE paradigm to find the optimal element extraction order for different instances, so as to achieve the best extraction results. We also propose an reinforcement learning (RL) based framework to generate optimal extraction order for each instance dynamically. Additionally, we propose a co-training framework adapted to RL to mitigate the exposure bias during the extractor training phase. Extensive experiments conducted on several public datasets demonstrate that our proposed method can beat previous methods and effectively improve the performance of various IE tasks, especially for complex ones.
On the Achievable Rate of MIMO Narrowband PLC with Spatio-Temporal Correlated Noise
Aug 28, 2023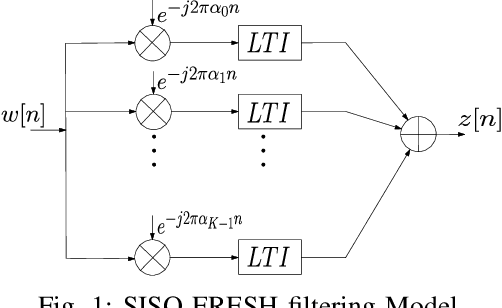
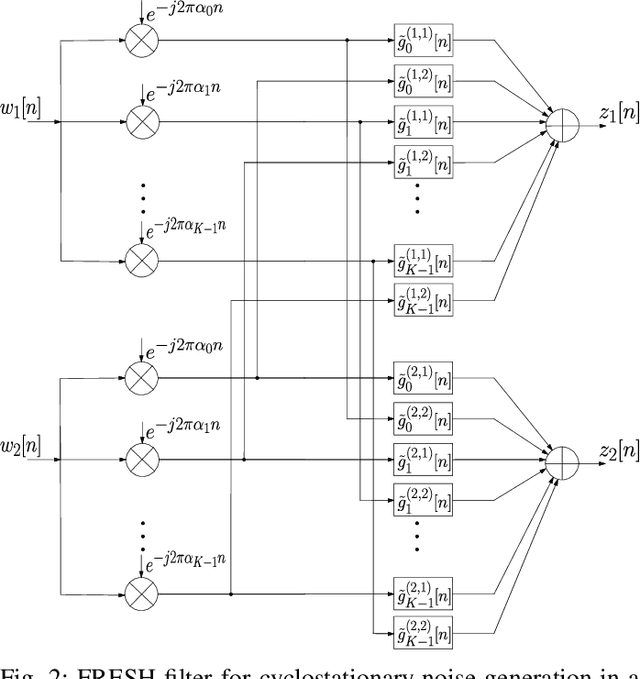
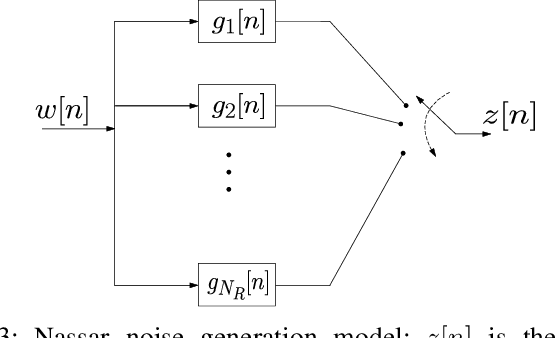

Narrowband power line communication (NB-PLC) systems are an attractive solution for supporting current and future smart grids. A technology proposed to enhance data rate in NB-PLC is multiple-input multiple-output (MIMO) transmission over multiple power line phases. To achieve reliable communication over MIMO NB-PLC, a key challenge is to take into account and mitigate the effects of temporally and spatially correlated cyclostationary noise. Noise samples in a cycle can be divided into three classes with different distributions, i.e. Gaussian, moderate impulsive, and strong impulsive. However, in this paper we first show that the impulsive classes in their turn can be divided into sub-classes with normal distributions and, after deriving the theoretical capacity, two noise sample sets with such characteristics are used to evaluate achievable information rates: one sample set is the measured noise in laboratory and the other is produced through MIMO frequency-shift (FRESH) filtering. The achievable information rates are attained by means of a spatio-temporal whitening of the portions of the cyclostationary correlated noise samples that belong to the Gaussian sub-classes. The proposed approach can be useful to design the optimal receiver in terms of bit allocation using waterfilling algorithm and to adapt modulation order.
Systematic reduction of Hyperspectral Images for high-throughput Plastic Characterization
Aug 28, 2023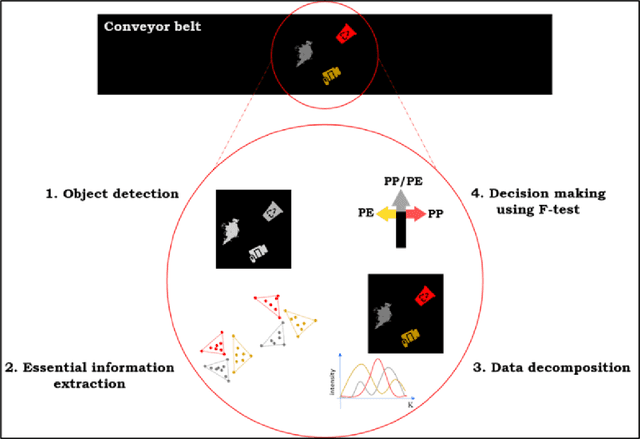
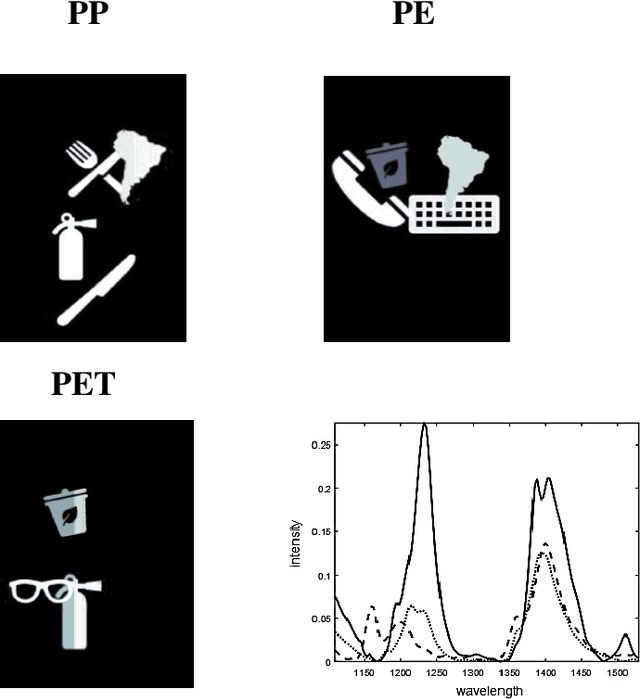
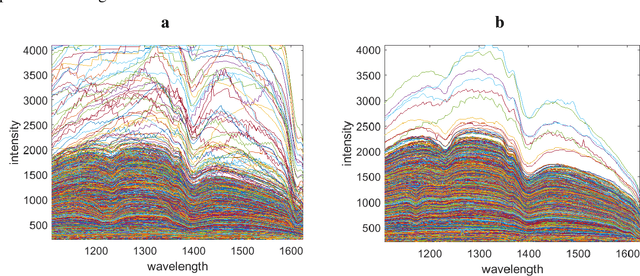
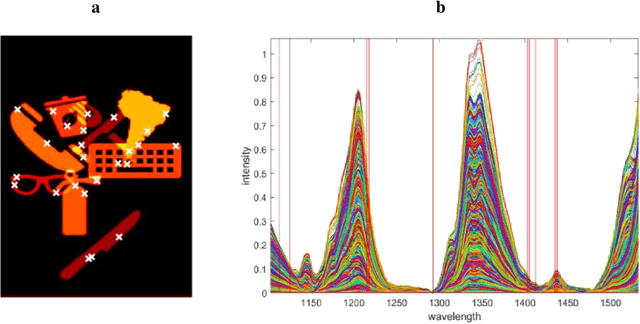
Hyperspectral Imaging (HSI) combines microscopy and spectroscopy to assess the spatial distribution of spectroscopically active compounds in objects, and has diverse applications in food quality control, pharmaceutical processes, and waste sorting. However, due to the large size of HSI datasets, it can be challenging to analyze and store them within a reasonable digital infrastructure, especially in waste sorting where speed and data storage resources are limited. Additionally, as with most spectroscopic data, there is significant redundancy, making pixel and variable selection crucial for retaining chemical information. Recent high-tech developments in chemometrics enable automated and evidence-based data reduction, which can substantially enhance the speed and performance of Non-Negative Matrix Factorization (NMF), a widely used algorithm for chemical resolution of HSI data. By recovering the pure contribution maps and spectral profiles of distributed compounds, NMF can provide evidence-based sorting decisions for efficient waste management. To improve the quality and efficiency of data analysis on hyperspectral imaging (HSI) data, we apply a convex-hull method to select essential pixels and wavelengths and remove uninformative and redundant information. This process minimizes computational strain and effectively eliminates highly mixed pixels. By reducing data redundancy, data investigation and analysis become more straightforward, as demonstrated in both simulated and real HSI data for plastic sorting.
Joint Multiple Intent Detection and Slot Filling with Supervised Contrastive Learning and Self-Distillation
Aug 28, 2023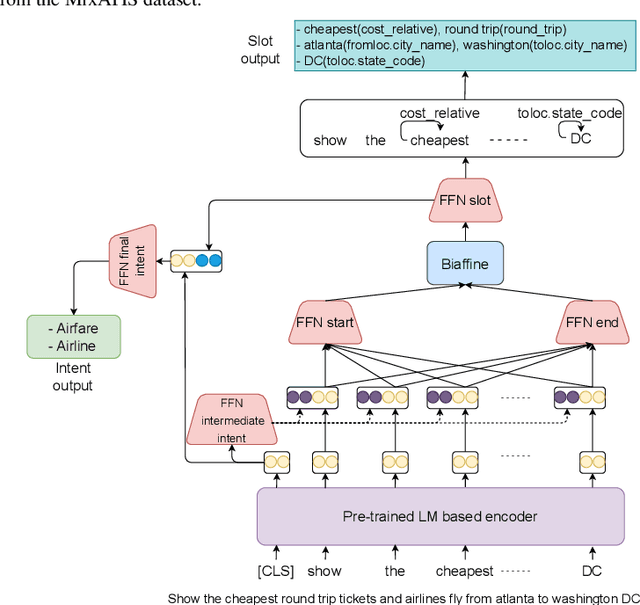
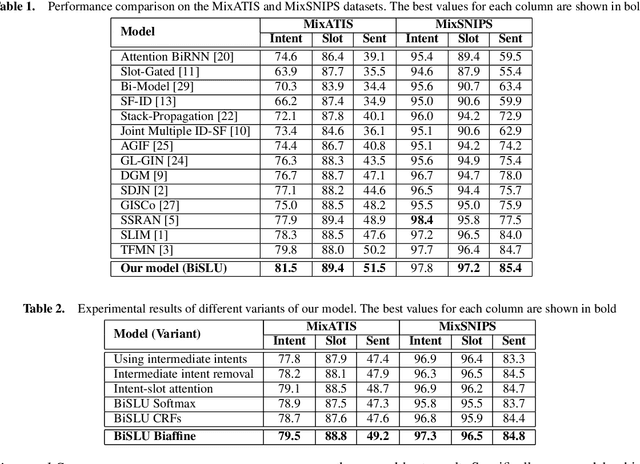
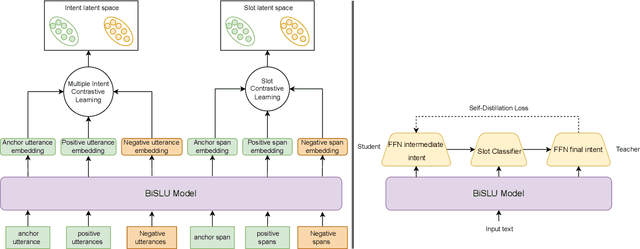
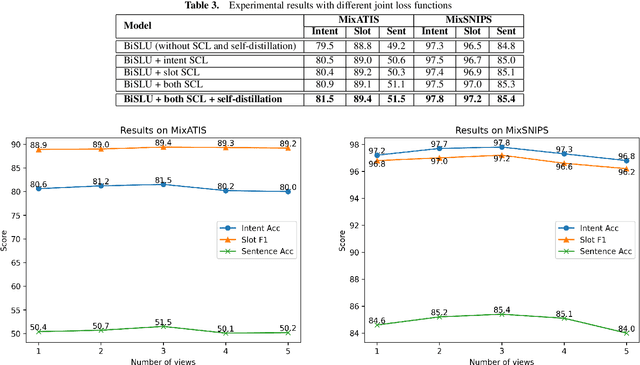
Multiple intent detection and slot filling are two fundamental and crucial tasks in spoken language understanding. Motivated by the fact that the two tasks are closely related, joint models that can detect intents and extract slots simultaneously are preferred to individual models that perform each task independently. The accuracy of a joint model depends heavily on the ability of the model to transfer information between the two tasks so that the result of one task can correct the result of the other. In addition, since a joint model has multiple outputs, how to train the model effectively is also challenging. In this paper, we present a method for multiple intent detection and slot filling by addressing these challenges. First, we propose a bidirectional joint model that explicitly employs intent information to recognize slots and slot features to detect intents. Second, we introduce a novel method for training the proposed joint model using supervised contrastive learning and self-distillation. Experimental results on two benchmark datasets MixATIS and MixSNIPS show that our method outperforms state-of-the-art models in both tasks. The results also demonstrate the contributions of both bidirectional design and the training method to the accuracy improvement. Our source code is available at https://github.com/anhtunguyen98/BiSLU
Materials Informatics Transformer: A Language Model for Interpretable Materials Properties Prediction
Sep 01, 2023Recently, the remarkable capabilities of large language models (LLMs) have been illustrated across a variety of research domains such as natural language processing, computer vision, and molecular modeling. We extend this paradigm by utilizing LLMs for material property prediction by introducing our model Materials Informatics Transformer (MatInFormer). Specifically, we introduce a novel approach that involves learning the grammar of crystallography through the tokenization of pertinent space group information. We further illustrate the adaptability of MatInFormer by incorporating task-specific data pertaining to Metal-Organic Frameworks (MOFs). Through attention visualization, we uncover the key features that the model prioritizes during property prediction. The effectiveness of our proposed model is empirically validated across 14 distinct datasets, hereby underscoring its potential for high throughput screening through accurate material property prediction.
A Smart Robotic System for Industrial Plant Supervision
Sep 01, 2023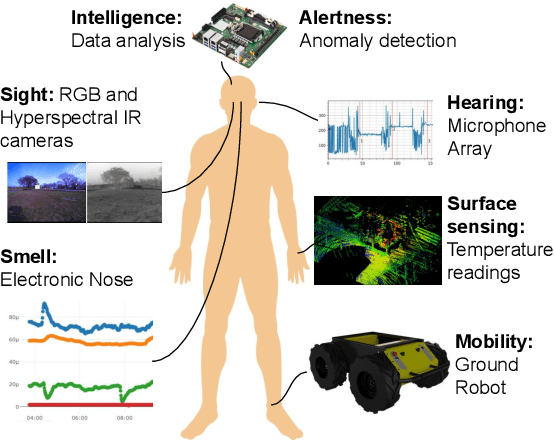

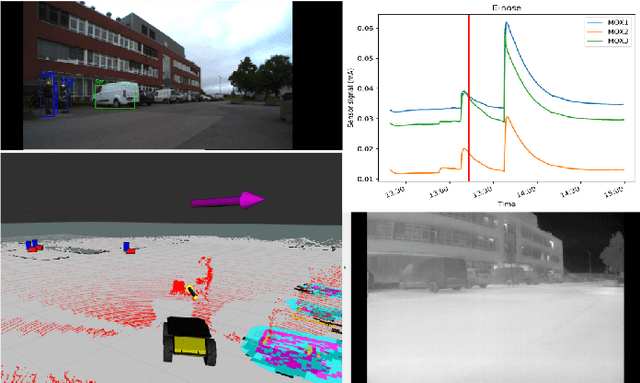
In today's chemical plants, human field operators perform frequent integrity checks to guarantee high safety standards, and thus are possibly the first to encounter dangerous operating conditions. To alleviate their task, we present a system consisting of an autonomously navigating robot integrated with various sensors and intelligent data processing. It is able to detect methane leaks and estimate its flow rate, detect more general gas anomalies, recognize oil films, localize sound sources and detect failure cases, map the environment in 3D, and navigate autonomously, employing recognition and avoidance of dynamic obstacles. We evaluate our system at a wastewater facility in full working conditions. Our results demonstrate that the system is able to robustly navigate the plant and provide useful information about critical operating conditions.
CARE: Co-Attention Network for Joint Entity and Relation Extraction
Aug 24, 2023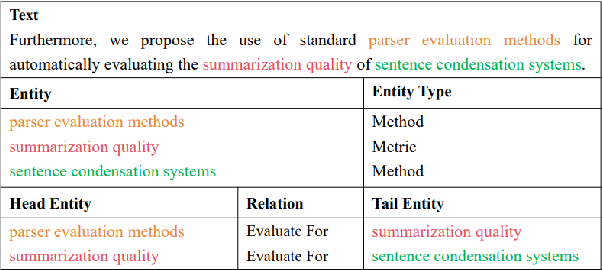
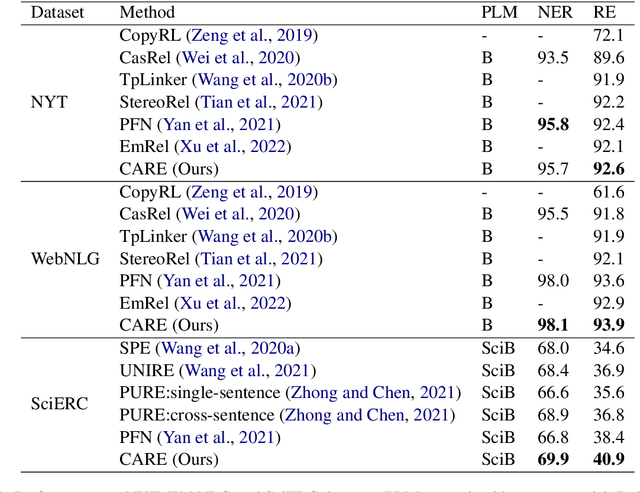
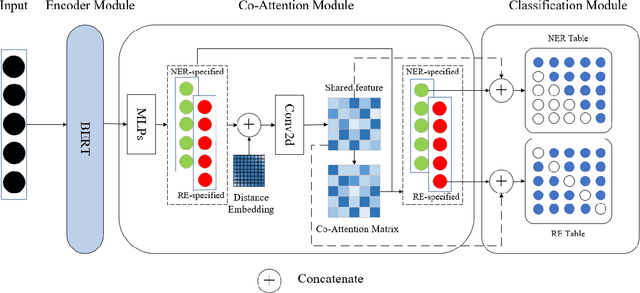
Joint entity and relation extraction is the fundamental task of information extraction, consisting of two subtasks: named entity recognition and relation extraction. Most existing joint extraction methods suffer from issues of feature confusion or inadequate interaction between two subtasks. In this work, we propose a Co-Attention network for joint entity and Relation Extraction (CARE). Our approach involves learning separate representations for each subtask, aiming to avoid feature overlap. At the core of our approach is the co-attention module that captures two-way interaction between two subtasks, allowing the model to leverage entity information for relation prediction and vice versa, thus promoting mutual enhancement. Extensive experiments on three joint entity-relation extraction benchmark datasets (NYT, WebNLG and SciERC) show that our proposed model achieves superior performance, surpassing existing baseline models.
Ground Truth Generation Algorithm for Medium-Frequency R-Mode Skywave Detection
Sep 04, 2023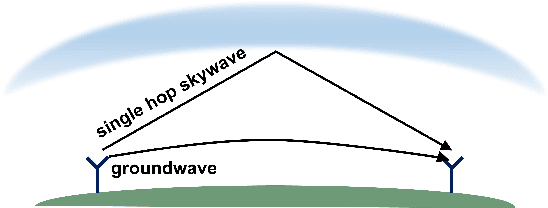

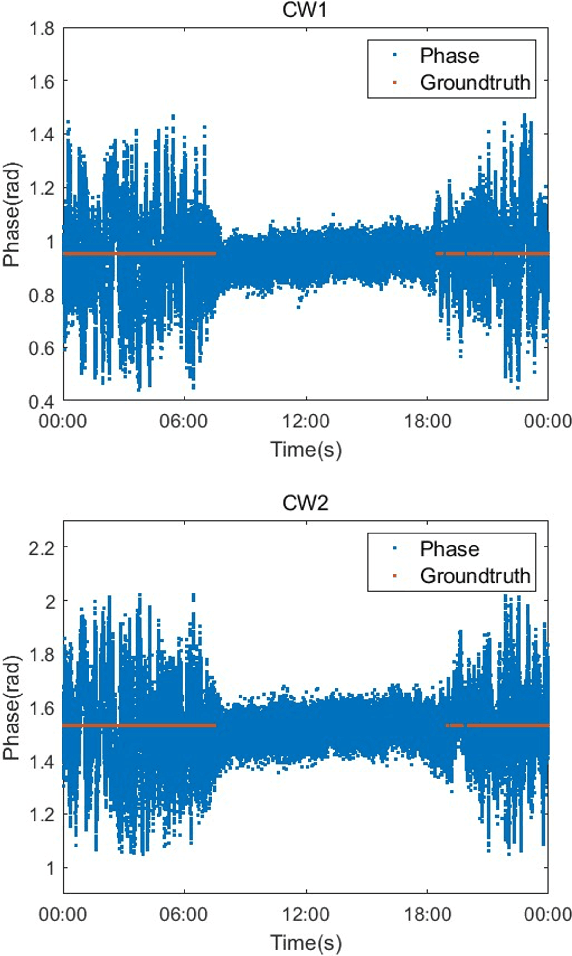
With the advancement of transportation vehicles, the importance and utility of navigation systems providing positioning, navigation, and timing (PNT) information have been increasing. Global navigation satellite systems (GNSS) are widely used navigation systems, but they are vulnerable to radio frequency interference (RFI), resulting in disruptions of satellite navigation signals. Recognizing this limitation, extensive research is being conducted on alternative navigation systems. In the maritime industry, ongoing research focuses on a groundbased integrated navigation system called R-Mode. R-Mode utilizes medium frequency (MF) differential GNSS (DGNSS) and very high-frequency data exchange system (VDES) signals as ranging signals for positioning and incorporates the existing ground-based navigation system known as enhanced long-range navigation (eLoran). However, MF R-Mode, which uses MF DGNSS signals for positioning, exhibits significant performance differences between daytime and nighttime due to skywave interference caused by signals reflecting off the ionosphere. In this study, we propose a skywave ground truth generation algorithm that is crucial for studying mitigation methods for MF R-Mode skywave interference. Furthermore, we demonstrate the proposed algorithm using field-test data.