 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Pseudo Flow Consistency for Self-Supervised 6D Object Pose Estimation
Aug 19, 2023
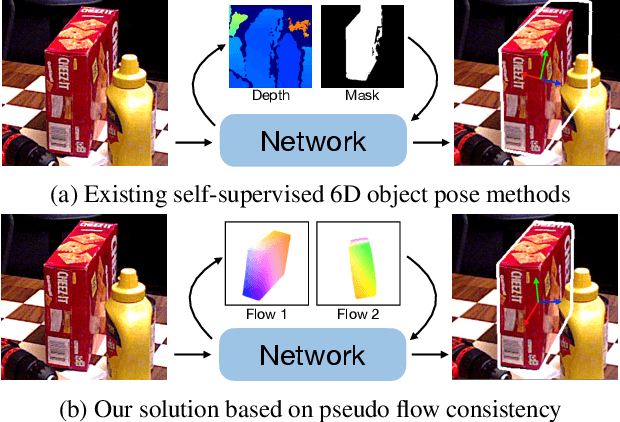
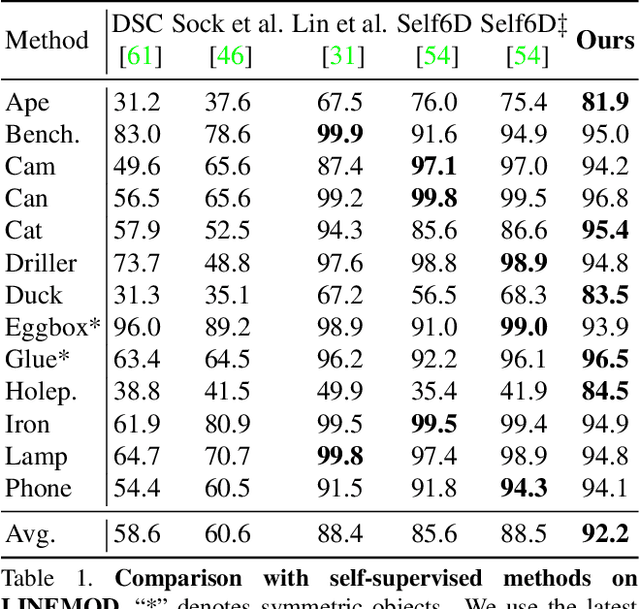
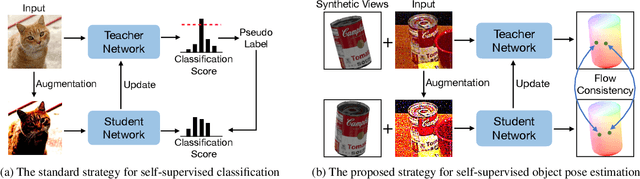
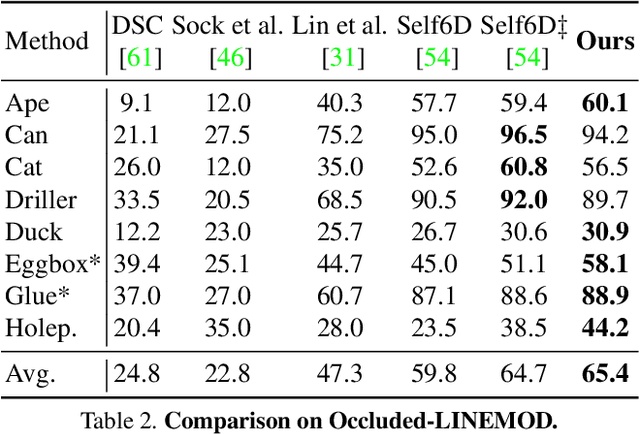
Most self-supervised 6D object pose estimation methods can only work with additional depth information or rely on the accurate annotation of 2D segmentation masks, limiting their application range. In this paper, we propose a 6D object pose estimation method that can be trained with pure RGB images without any auxiliary information. We first obtain a rough pose initialization from networks trained on synthetic images rendered from the target's 3D mesh. Then, we introduce a refinement strategy leveraging the geometry constraint in synthetic-to-real image pairs from multiple different views. We formulate this geometry constraint as pixel-level flow consistency between the training images with dynamically generated pseudo labels. We evaluate our method on three challenging datasets and demonstrate that it outperforms state-of-the-art self-supervised methods significantly, with neither 2D annotations nor additional depth images.
Multi-Subdomain Adversarial Network for Cross-Subject EEG-based Emotion Recognition
Aug 27, 2023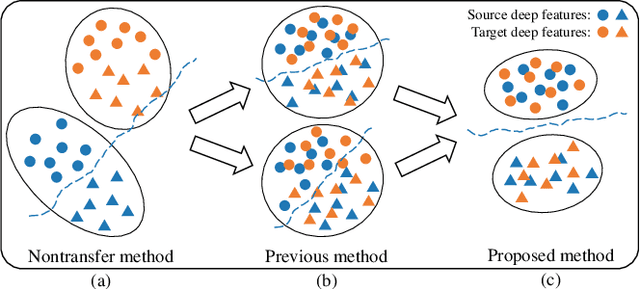
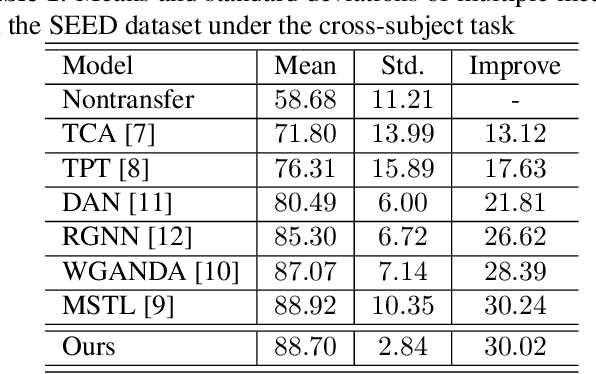
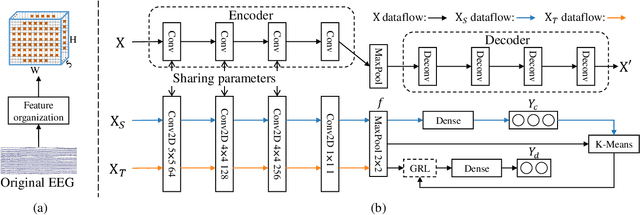
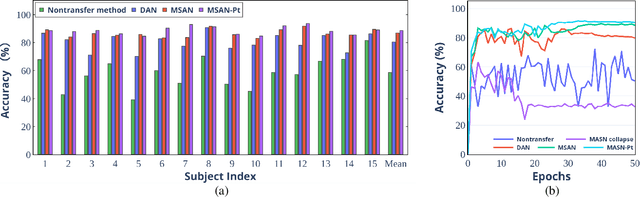
The individual difference between subjects is significant in EEG-based emotion recognition, resulting in the difficulty of sharing the model across subjects. Previous studies use domain adaptation algorithms to minimize the global domain discrepancy while ignoring the class information, which may cause misalignment of subdomains and reduce model performance. This paper proposes a multi-subdomain adversarial network (MSAN) for cross-subject EEG-based emotion recognition. MSAN uses adversarial training to model the discrepancy in the global domain and subdomain to reduce the intra-class distance and enlarge the inter-class distance. In addition, MSAN initializes parameters through a pre-trained autoencoder to ensure the stability and convertibility of the model. The experimental results show that the accuracy of MSAN is improved by 30.02\% on the SEED dataset comparing with the nontransfer method.
Multi-agent Coordination Under Temporal Logic Tasks and Team-Wise Intermittent Communication
Aug 27, 2023Multi-agent systems outperform single agent in complex collaborative tasks. However, in large-scale scenarios, ensuring timely information exchange during decentralized task execution remains a challenge. This work presents an online decentralized coordination scheme for multi-agent systems under complex local tasks and intermittent communication constraints. Unlike existing strategies that enforce all-time or intermittent connectivity, our approach allows agents to join or leave communication networks at aperiodic intervals, as deemed optimal by their online task execution. This scheme concurrently determines local plans and refines the communication strategy, i.e., where and when to communicate as a team. A decentralized potential game is modeled among agents, for which a Nash equilibrium is generated iteratively through online local search. It guarantees local task completion and intermittent communication constraints. Extensive numerical simulations are conducted against several strong baselines.
Online Distillation-enhanced Multi-modal Transformer for Sequential Recommendation
Aug 14, 2023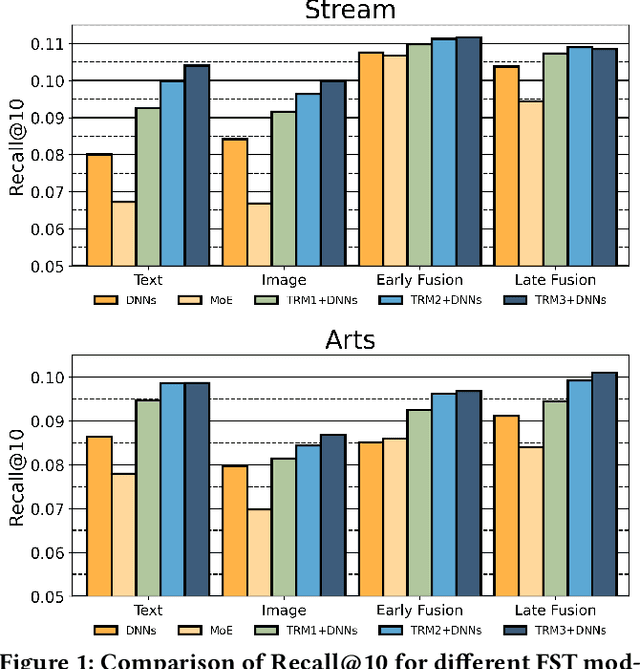
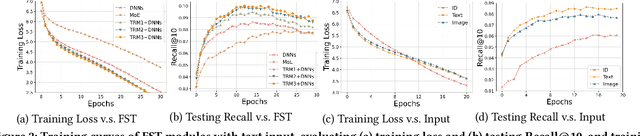
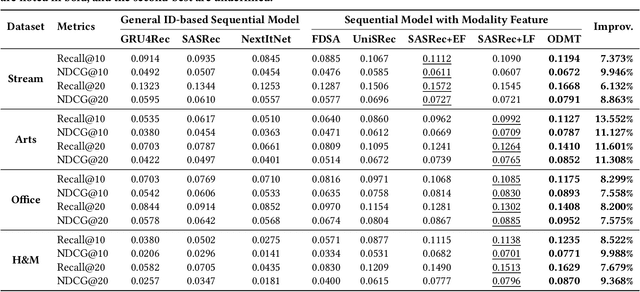
Multi-modal recommendation systems, which integrate diverse types of information, have gained widespread attention in recent years. However, compared to traditional collaborative filtering-based multi-modal recommendation systems, research on multi-modal sequential recommendation is still in its nascent stages. Unlike traditional sequential recommendation models that solely rely on item identifier (ID) information and focus on network structure design, multi-modal recommendation models need to emphasize item representation learning and the fusion of heterogeneous data sources. This paper investigates the impact of item representation learning on downstream recommendation tasks and examines the disparities in information fusion at different stages. Empirical experiments are conducted to demonstrate the need to design a framework suitable for collaborative learning and fusion of diverse information. Based on this, we propose a new model-agnostic framework for multi-modal sequential recommendation tasks, called Online Distillation-enhanced Multi-modal Transformer (ODMT), to enhance feature interaction and mutual learning among multi-source input (ID, text, and image), while avoiding conflicts among different features during training, thereby improving recommendation accuracy. To be specific, we first introduce an ID-aware Multi-modal Transformer module in the item representation learning stage to facilitate information interaction among different features. Secondly, we employ an online distillation training strategy in the prediction optimization stage to make multi-source data learn from each other and improve prediction robustness. Experimental results on a stream media recommendation dataset and three e-commerce recommendation datasets demonstrate the effectiveness of the proposed two modules, which is approximately 10% improvement in performance compared to baseline models.
Model-based learning for location-to-channel mapping
Aug 28, 2023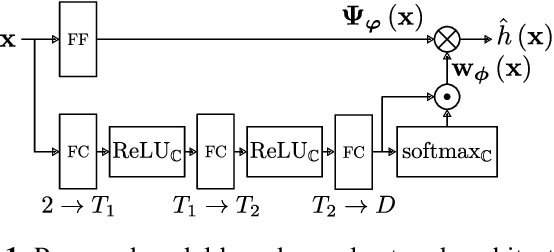

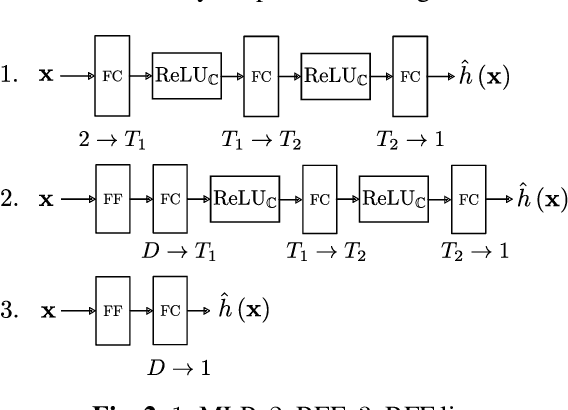
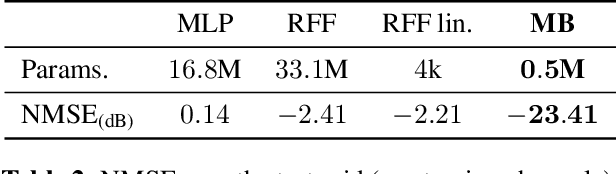
Modern communication systems rely on accurate channel estimation to achieve efficient and reliable transmission of information. As the communication channel response is highly related to the user's location, one can use a neural network to map the user's spatial coordinates to the channel coefficients. However, these latter are rapidly varying as a function of the location, on the order of the wavelength. Classical neural architectures being biased towards learning low frequency functions (spectral bias), such mapping is therefore notably difficult to learn. In order to overcome this limitation, this paper presents a frugal, model-based network that separates the low frequency from the high frequency components of the target mapping function. This yields an hypernetwork architecture where the neural network only learns low frequency sparse coefficients in a dictionary of high frequency components. Simulation results show that the proposed neural network outperforms standard approaches on realistic synthetic data.
PointLLM: Empowering Large Language Models to Understand Point Clouds
Aug 31, 2023
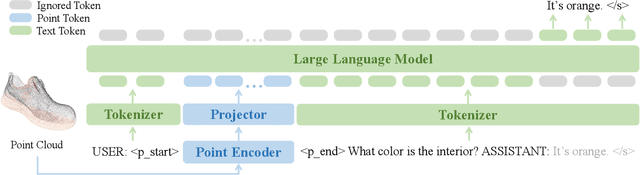


The unprecedented advancements in Large Language Models (LLMs) have created a profound impact on natural language processing but are yet to fully embrace the realm of 3D understanding. This paper introduces PointLLM, a preliminary effort to fill this gap, thereby enabling LLMs to understand point clouds and offering a new avenue beyond 2D visual data. PointLLM processes colored object point clouds with human instructions and generates contextually appropriate responses, illustrating its grasp of point clouds and common sense. Specifically, it leverages a point cloud encoder with a powerful LLM to effectively fuse geometric, appearance, and linguistic information. We collect a novel dataset comprising 660K simple and 70K complex point-text instruction pairs to enable a two-stage training strategy: initially aligning latent spaces and subsequently instruction-tuning the unified model. To rigorously evaluate our model's perceptual abilities and its generalization capabilities, we establish two benchmarks: Generative 3D Object Classification and 3D Object Captioning, assessed through three different methods, including human evaluation, GPT-4/ChatGPT evaluation, and traditional metrics. Experiment results show that PointLLM demonstrates superior performance over existing 2D baselines. Remarkably, in human-evaluated object captioning tasks, PointLLM outperforms human annotators in over 50% of the samples. Codes, datasets, and benchmarks are available at https://github.com/OpenRobotLab/PointLLM .
StratMed: Relevance Stratification for Low-resource Medication Recommendation
Aug 31, 2023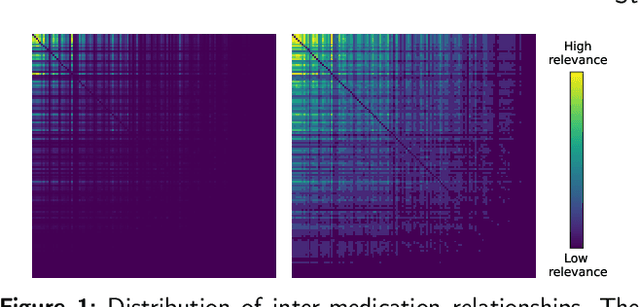
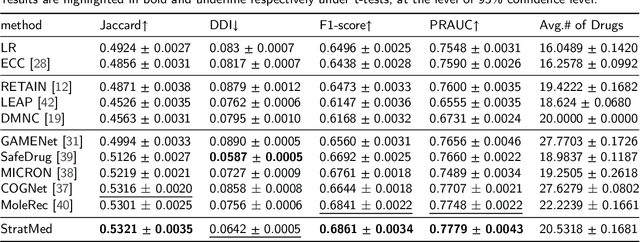
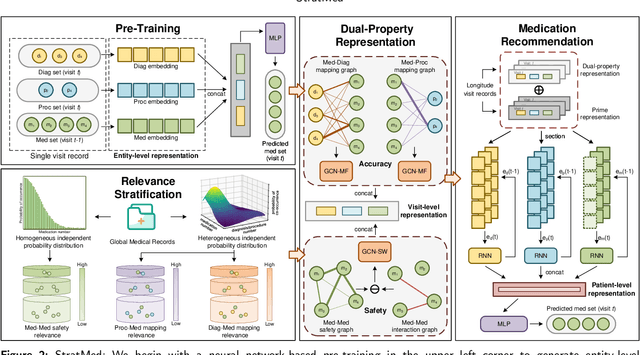

With the growing imbalance between limited medical resources and escalating demands, AI-based clinical tasks have become paramount. Medication recommendation, as a sub-domain, aims to amalgamate longitudinal patient history with medical knowledge, assisting physicians in prescribing safer and more accurate medication combinations. Existing methods overlook the inherent long-tail distribution in medical data, lacking balanced representation between head and tail data, which leads to sub-optimal model performance. To address this challenge, we introduce StratMed, a model that incorporates an innovative relevance stratification mechanism. It harmonizes discrepancies in data long-tail distribution and strikes a balance between the safety and accuracy of medication combinations. Specifically, we first construct a pre-training method using deep learning networks to obtain entity representation. After that, we design a pyramid-like data stratification method to obtain more generalized entity relationships by reinforcing the features of unpopular entities. Based on this relationship, we designed two graph structures to express medication precision and safety at the same level to obtain visit representations. Finally, the patient's historical clinical information is fitted to generate medication combinations for the current health condition. Experiments on the MIMIC-III dataset demonstrate that our method has outperformed current state-of-the-art methods in four evaluation metrics (including safety and accuracy).
TouchStone: Evaluating Vision-Language Models by Language Models
Aug 31, 2023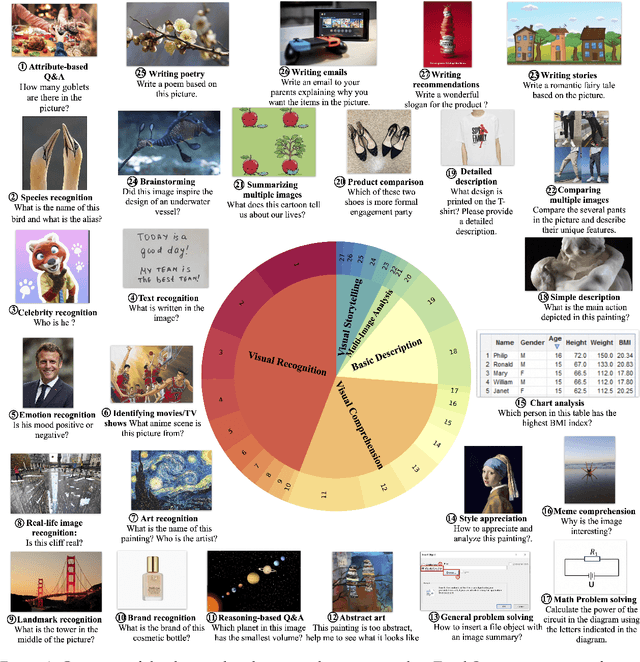
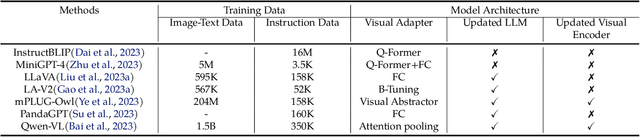


Large vision-language models (LVLMs) have recently witnessed rapid advancements, exhibiting a remarkable capacity for perceiving, understanding, and processing visual information by connecting visual receptor with large language models (LLMs). However, current assessments mainly focus on recognizing and reasoning abilities, lacking direct evaluation of conversational skills and neglecting visual storytelling abilities. In this paper, we propose an evaluation method that uses strong LLMs as judges to comprehensively evaluate the various abilities of LVLMs. Firstly, we construct a comprehensive visual dialogue dataset TouchStone, consisting of open-world images and questions, covering five major categories of abilities and 27 subtasks. This dataset not only covers fundamental recognition and comprehension but also extends to literary creation. Secondly, by integrating detailed image annotations we effectively transform the multimodal input content into a form understandable by LLMs. This enables us to employ advanced LLMs for directly evaluating the quality of the multimodal dialogue without requiring human intervention. Through validation, we demonstrate that powerful LVLMs, such as GPT-4, can effectively score dialogue quality by leveraging their textual capabilities alone, aligning with human preferences. We hope our work can serve as a touchstone for LVLMs' evaluation and pave the way for building stronger LVLMs. The evaluation code is available at https://github.com/OFA-Sys/TouchStone.
Federated Learning in UAV-Enhanced Networks: Joint Coverage and Convergence Time Optimization
Aug 31, 2023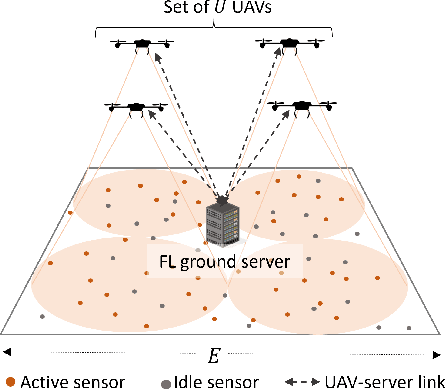
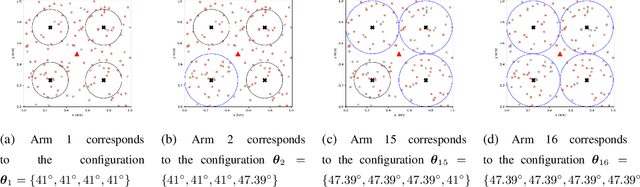
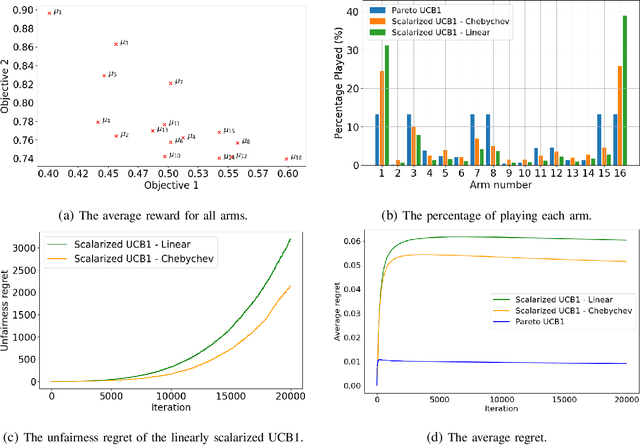
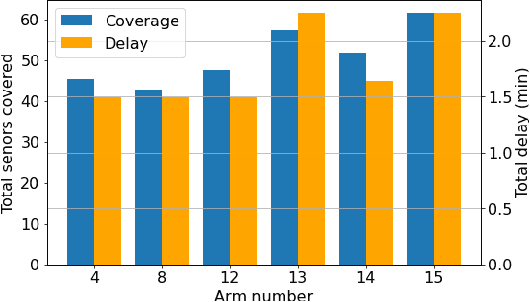
Federated learning (FL) involves several devices that collaboratively train a shared model without transferring their local data. FL reduces the communication overhead, making it a promising learning method in UAV-enhanced wireless networks with scarce energy resources. Despite the potential, implementing FL in UAV-enhanced networks is challenging, as conventional UAV placement methods that maximize coverage increase the FL delay significantly. Moreover, the uncertainty and lack of a priori information about crucial variables, such as channel quality, exacerbate the problem. In this paper, we first analyze the statistical characteristics of a UAV-enhanced wireless sensor network (WSN) with energy harvesting. We then develop a model and solution based on the multi-objective multi-armed bandit theory to maximize the network coverage while minimizing the FL delay. Besides, we propose another solution that is particularly useful with large action sets and strict energy constraints at the UAVs. Our proposal uses a scalarized best-arm identification algorithm to find the optimal arms that maximize the ratio of the expected reward to the expected energy cost by sequentially eliminating one or more arms in each round. Then, we derive the upper bound on the error probability of our multi-objective and cost-aware algorithm. Numerical results show the effectiveness of our approach.
Post-Deployment Adaptation with Access to Source Data via Federated Learning and Source-Target Remote Gradient Alignment
Aug 31, 2023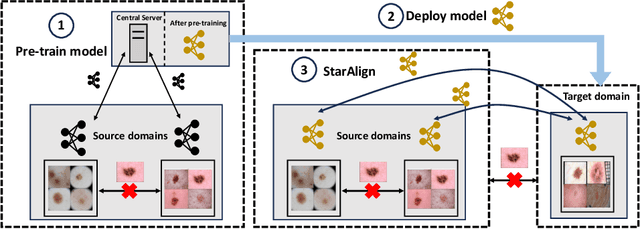
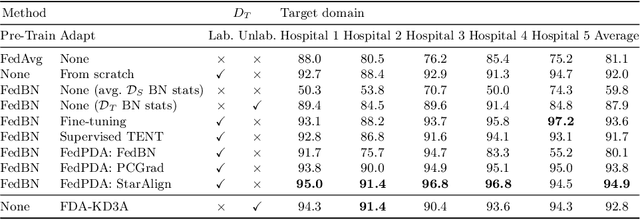
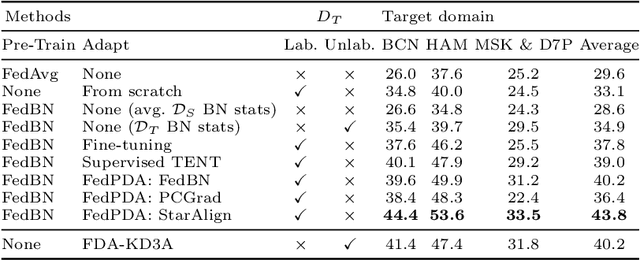
Deployment of Deep Neural Networks in medical imaging is hindered by distribution shift between training data and data processed after deployment, causing performance degradation. Post-Deployment Adaptation (PDA) addresses this by tailoring a pre-trained, deployed model to the target data distribution using limited labelled or entirely unlabelled target data, while assuming no access to source training data as they cannot be deployed with the model due to privacy concerns and their large size. This makes reliable adaptation challenging due to limited learning signal. This paper challenges this assumption and introduces FedPDA, a novel adaptation framework that brings the utility of learning from remote data from Federated Learning into PDA. FedPDA enables a deployed model to obtain information from source data via remote gradient exchange, while aiming to optimize the model specifically for the target domain. Tailored for FedPDA, we introduce a novel optimization method StarAlign (Source-Target Remote Gradient Alignment) that aligns gradients between source-target domain pairs by maximizing their inner product, to facilitate learning a target-specific model. We demonstrate the method's effectiveness using multi-center databases for the tasks of cancer metastases detection and skin lesion classification, where our method compares favourably to previous work. Code is available at: https://github.com/FelixWag/StarAlign