 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
PESTO: Pitch Estimation with Self-supervised Transposition-equivariant Objective
Sep 05, 2023
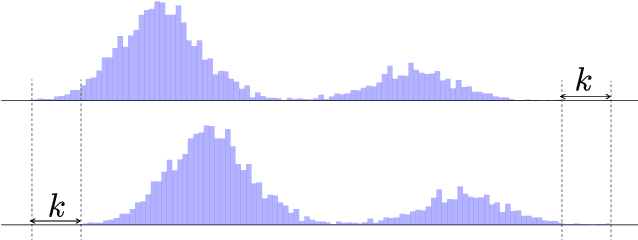

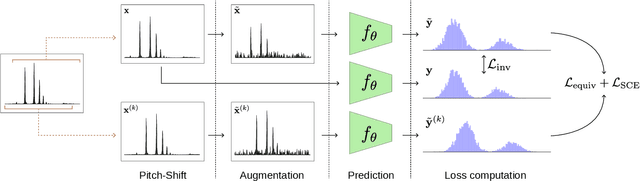
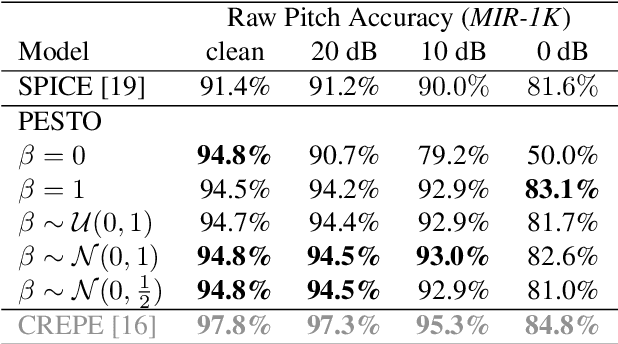
In this paper, we address the problem of pitch estimation using Self Supervised Learning (SSL). The SSL paradigm we use is equivariance to pitch transposition, which enables our model to accurately perform pitch estimation on monophonic audio after being trained only on a small unlabeled dataset. We use a lightweight ($<$ 30k parameters) Siamese neural network that takes as inputs two different pitch-shifted versions of the same audio represented by its Constant-Q Transform. To prevent the model from collapsing in an encoder-only setting, we propose a novel class-based transposition-equivariant objective which captures pitch information. Furthermore, we design the architecture of our network to be transposition-preserving by introducing learnable Toeplitz matrices. We evaluate our model for the two tasks of singing voice and musical instrument pitch estimation and show that our model is able to generalize across tasks and datasets while being lightweight, hence remaining compatible with low-resource devices and suitable for real-time applications. In particular, our results surpass self-supervised baselines and narrow the performance gap between self-supervised and supervised methods for pitch estimation.
Navigating Out-of-Distribution Electricity Load Forecasting during COVID-19: A Continual Learning Approach Leveraging Human Mobility
Sep 08, 2023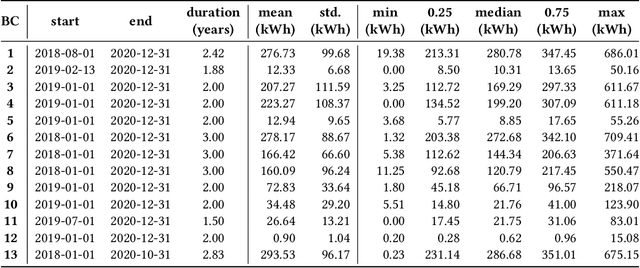
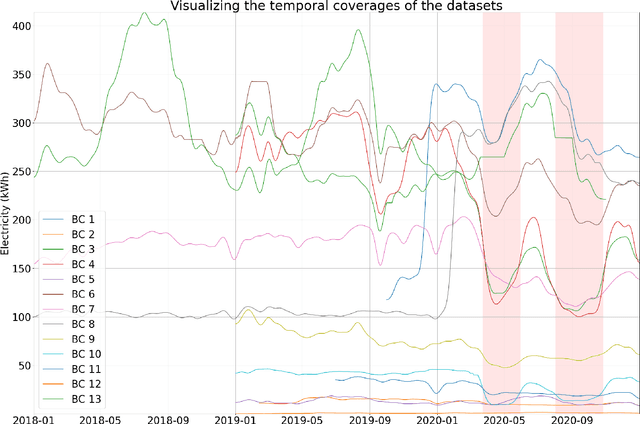
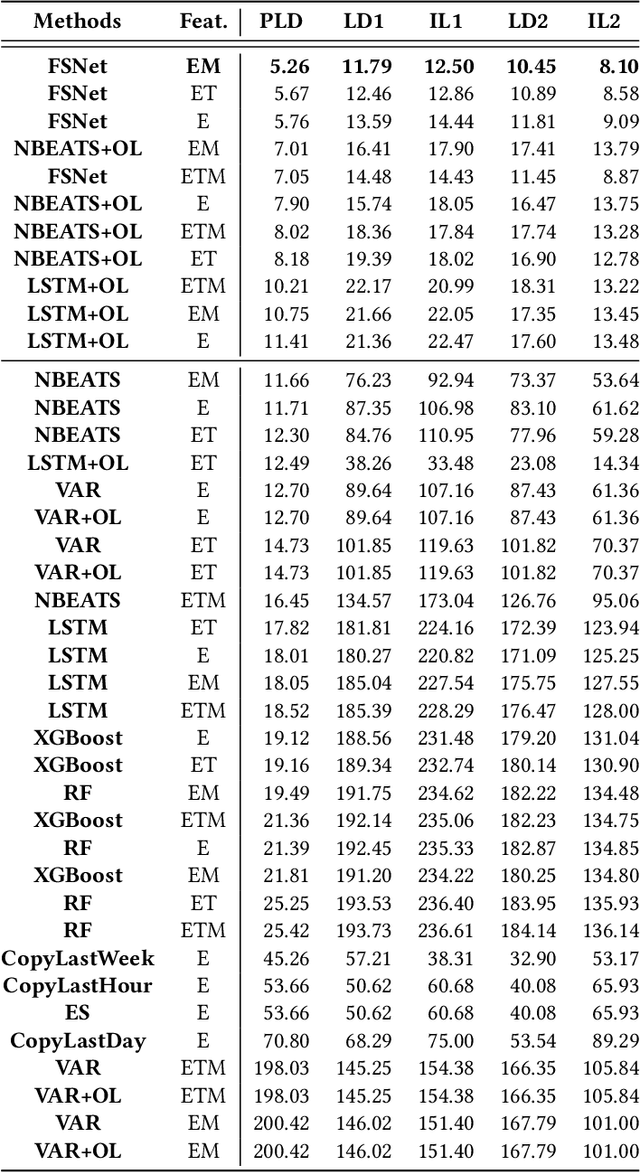
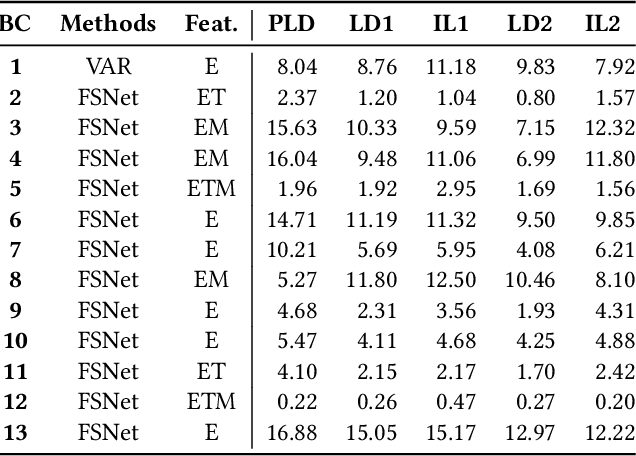
In traditional deep learning algorithms, one of the key assumptions is that the data distribution remains constant during both training and deployment. However, this assumption becomes problematic when faced with Out-of-Distribution periods, such as the COVID-19 lockdowns, where the data distribution significantly deviates from what the model has seen during training. This paper employs a two-fold strategy: utilizing continual learning techniques to update models with new data and harnessing human mobility data collected from privacy-preserving pedestrian counters located outside buildings. In contrast to online learning, which suffers from 'catastrophic forgetting' as newly acquired knowledge often erases prior information, continual learning offers a holistic approach by preserving past insights while integrating new data. This research applies FSNet, a powerful continual learning algorithm, to real-world data from 13 building complexes in Melbourne, Australia, a city which had the second longest total lockdown duration globally during the pandemic. Results underscore the crucial role of continual learning in accurate energy forecasting, particularly during Out-of-Distribution periods. Secondary data such as mobility and temperature provided ancillary support to the primary forecasting model. More importantly, while traditional methods struggled to adapt during lockdowns, models featuring at least online learning demonstrated resilience, with lockdown periods posing fewer challenges once armed with adaptive learning techniques. This study contributes valuable methodologies and insights to the ongoing effort to improve energy load forecasting during future Out-of-Distribution periods.
Robot Localization and Mapping Final Report -- Sequential Adversarial Learning for Self-Supervised Deep Visual Odometry
Sep 08, 2023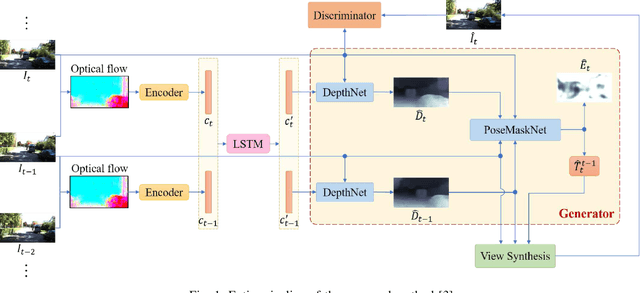

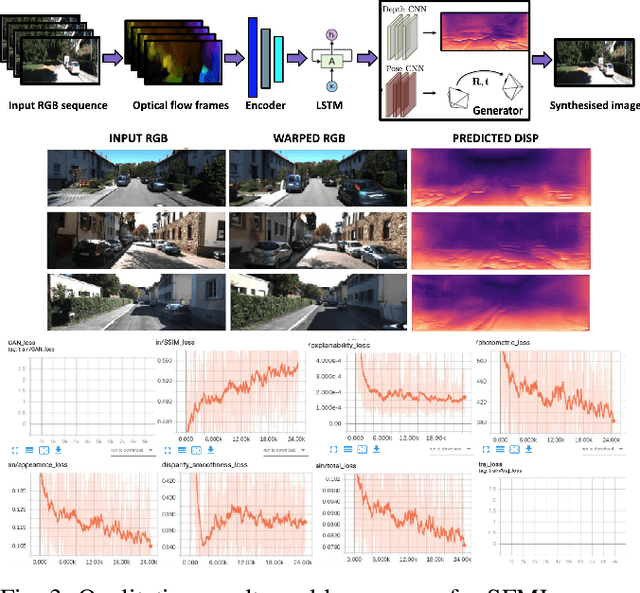
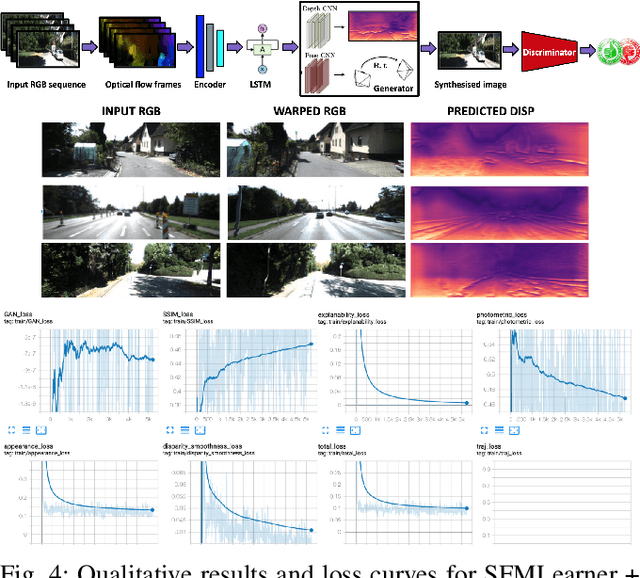
Visual odometry (VO) and SLAM have been using multi-view geometry via local structure from motion for decades. These methods have a slight disadvantage in challenging scenarios such as low-texture images, dynamic scenarios, etc. Meanwhile, use of deep neural networks to extract high level features is ubiquitous in computer vision. For VO, we can use these deep networks to extract depth and pose estimates using these high level features. The visual odometry task then can be modeled as an image generation task where the pose estimation is the by-product. This can also be achieved in a self-supervised manner, thereby eliminating the data (supervised) intensive nature of training deep neural networks. Although some works tried the similar approach [1], the depth and pose estimation in the previous works are vague sometimes resulting in accumulation of error (drift) along the trajectory. The goal of this work is to tackle these limitations of past approaches and to develop a method that can provide better depths and pose estimates. To address this, a couple of approaches are explored: 1) Modeling: Using optical flow and recurrent neural networks (RNN) in order to exploit spatio-temporal correlations which can provide more information to estimate depth. 2) Loss function: Generative adversarial network (GAN) [2] is deployed to improve the depth estimation (and thereby pose too), as shown in Figure 1. This additional loss term improves the realism in generated images and reduces artifacts.
ControlMat: A Controlled Generative Approach to Material Capture
Sep 04, 2023Material reconstruction from a photograph is a key component of 3D content creation democratization. We propose to formulate this ill-posed problem as a controlled synthesis one, leveraging the recent progress in generative deep networks. We present ControlMat, a method which, given a single photograph with uncontrolled illumination as input, conditions a diffusion model to generate plausible, tileable, high-resolution physically-based digital materials. We carefully analyze the behavior of diffusion models for multi-channel outputs, adapt the sampling process to fuse multi-scale information and introduce rolled diffusion to enable both tileability and patched diffusion for high-resolution outputs. Our generative approach further permits exploration of a variety of materials which could correspond to the input image, mitigating the unknown lighting conditions. We show that our approach outperforms recent inference and latent-space-optimization methods, and carefully validate our diffusion process design choices. Supplemental materials and additional details are available at: https://gvecchio.com/controlmat/.
Minimal Effective Theory for Phonotactic Memory: Capturing Local Correlations due to Errors in Speech
Sep 04, 2023Spoken language evolves constrained by the economy of speech, which depends on factors such as the structure of the human mouth. This gives rise to local phonetic correlations in spoken words. Here we demonstrate that these local correlations facilitate the learning of spoken words by reducing their information content. We do this by constructing a locally-connected tensor-network model, inspired by similar variational models used for many-body physics, which exploits these local phonetic correlations to facilitate the learning of spoken words. The model is therefore a minimal model of phonetic memory, where "learning to pronounce" and "learning a word" are one and the same. A consequence of which is the learned ability to produce new words which are phonetically reasonable for the target language; as well as providing a hierarchy of the most likely errors that could be produced during the action of speech. We test our model against Latin and Turkish words. (The code is available on GitHub.)
UniSA: Unified Generative Framework for Sentiment Analysis
Sep 04, 2023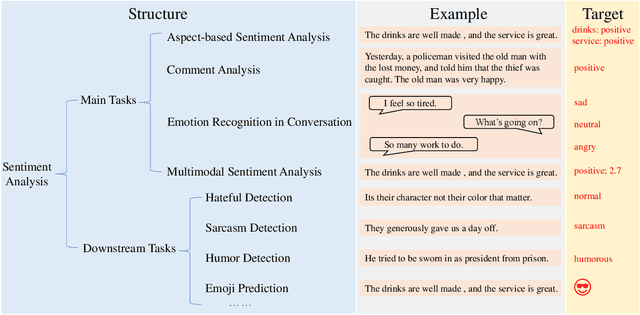
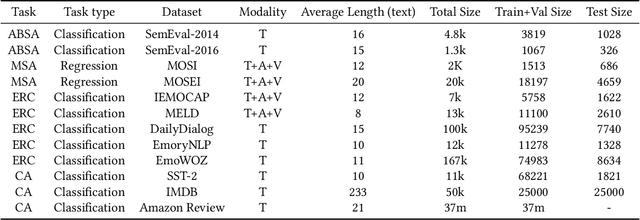
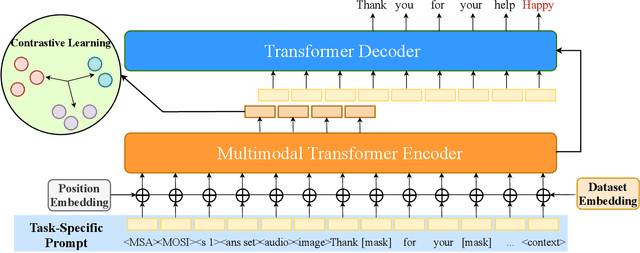

Sentiment analysis is a crucial task that aims to understand people's emotional states and predict emotional categories based on multimodal information. It consists of several subtasks, such as emotion recognition in conversation (ERC), aspect-based sentiment analysis (ABSA), and multimodal sentiment analysis (MSA). However, unifying all subtasks in sentiment analysis presents numerous challenges, including modality alignment, unified input/output forms, and dataset bias. To address these challenges, we propose a Task-Specific Prompt method to jointly model subtasks and introduce a multimodal generative framework called UniSA. Additionally, we organize the benchmark datasets of main subtasks into a new Sentiment Analysis Evaluation benchmark, SAEval. We design novel pre-training tasks and training methods to enable the model to learn generic sentiment knowledge among subtasks to improve the model's multimodal sentiment perception ability. Our experimental results show that UniSA performs comparably to the state-of-the-art on all subtasks and generalizes well to various subtasks in sentiment analysis.
Mobile robots sampling algorithms for monitoring of insects populations in agricultural fields
Aug 26, 2023Plant diseases are major causes of production losses and may have a significant impact on the agricultural sector. Detecting pests as early as possible can help increase crop yields and production efficiency. Several robotic monitoring systems have been developed allowing to collect data and provide a greater understanding of environmental processes. An agricultural robot can enable accurate timely detection of pests, by traversing the field autonomously and monitoring the entire cropped area within a field. However, in many cases it is impossible to sample all plants due to resource limitations. In this thesis, the development and evaluation of several sampling algorithms are presented to address the challenge of an agriculture-monitoring ground robot designed to locate insects in an agricultural field, where complete sampling of all the plants is infeasible. Two situations were investigated in simulation models that were specially developed as part of this thesis: where no a-priori information on the insects is available and where prior information on the insects distributions within the field is known. For the first situation, seven algorithms were tested, each utilizing an approach to sample the field without prior knowledge of it. For the second situation, we present the development and evaluation of a dynamic sampling algorithm which utilizes real-time information to prioritize sampling at suspected points, locate hot spots and adapt sampling plans accordingly. The algorithm's performance was compared to two existing algorithms using Tetranychidae insect data from previous research. Analyses revealed that the dynamic algorithm outperformed the others.
How much Training is Needed in Downlink Cell-Free mMIMO under LoS/NLoS channels?
Aug 28, 2023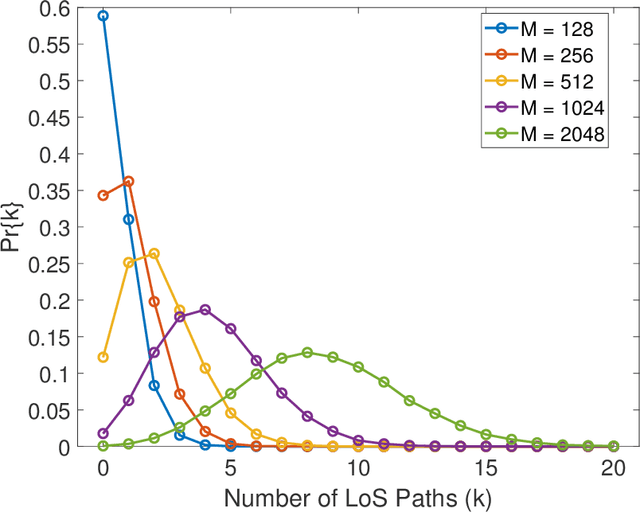
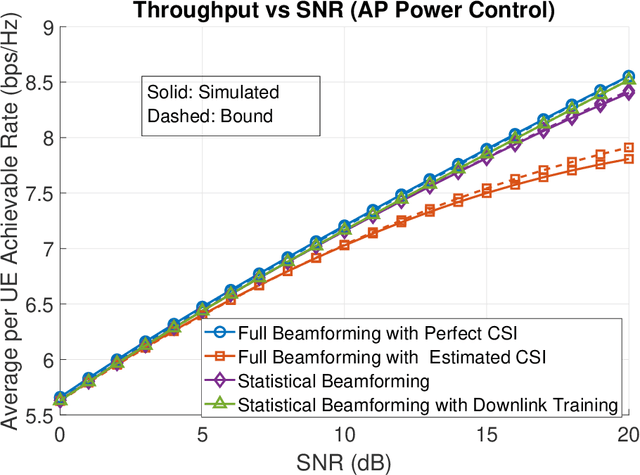
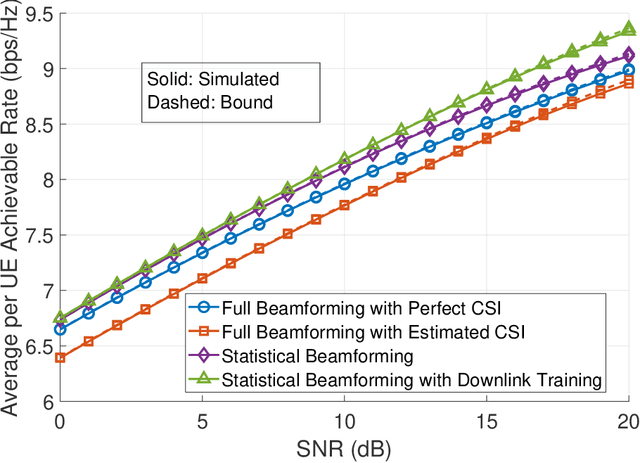
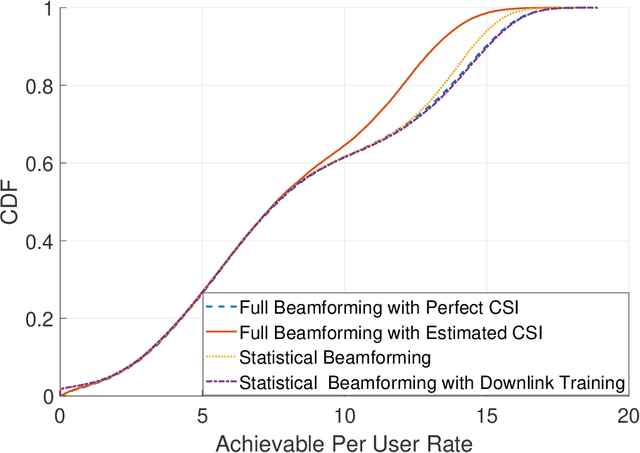
The assumption that no LoS channels exist between wireless access points~(APs) and user equipments~(UEs) becomes questionable in the context of the recent developments in the direction of cell free massive multiple input multiple output MIMO~(CF-mMIMO) systems. In CF-mMIMO systems, the access point density is assumed to be comparable to, or much larger than the the user density, thereby leading to the possibility of existence of LoS links between the UEs and the APs, depending on the local propagation conditions. In this paper, we compare the rates achievable by CF-mMIMO systems under probabilistic LoS/ NLos channels, with and without acquiring the channel state information~(CSI) of the fast fading components. We show that, under sufficiently large AP densities, statistical beamforming that does not require the knowledge about the fast fading components of the channels, performs almost at par with full beamforming, utilizing the information about the fast fading channel coefficients, thus potentially avoiding the need for training during every frame. We validate our results via detailed Monte Carlo simulations, and also elaborate the conditions under which statistical beamforming can be successfully employed in massive MIMO systems with LoS/ NLoS channels.
NF4 Isn't Information Theoretically Optimal (and that's Good)
Jun 14, 2023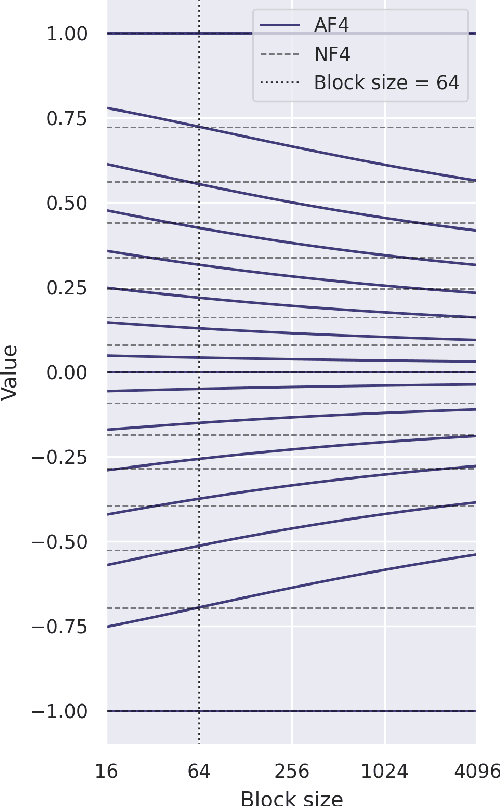
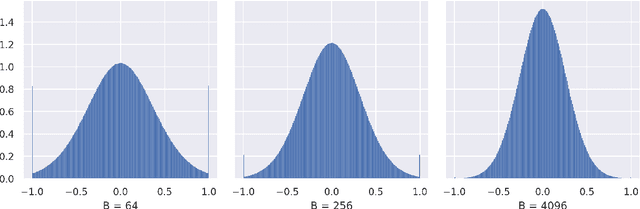
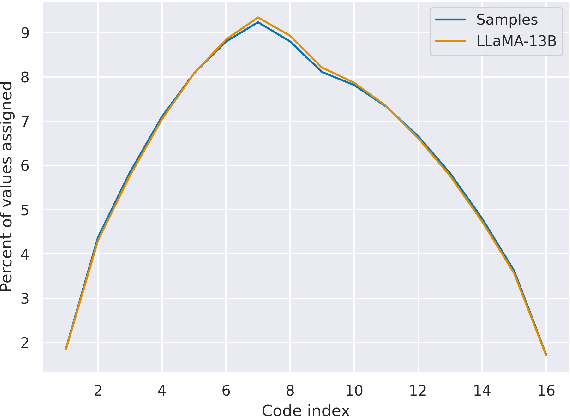
This note shares some simple calculations and experiments related to absmax-based blockwise quantization, as used in Dettmers et al., 2023. Their proposed NF4 data type is said to be information theoretically optimal for representing normally distributed weights. I show that this can't quite be the case, as the distribution of the values to be quantized depends on the block-size. I attempt to apply these insights to derive an improved code based on minimizing the expected L1 reconstruction error, rather than the quantile based method. This leads to improved performance for larger quantization block sizes, while both codes perform similarly at smaller block sizes.
Pre-training with Aspect-Content Text Mutual Prediction for Multi-Aspect Dense Retrieval
Aug 22, 2023Grounded on pre-trained language models (PLMs), dense retrieval has been studied extensively on plain text. In contrast, there has been little research on retrieving data with multiple aspects using dense models. In the scenarios such as product search, the aspect information plays an essential role in relevance matching, e.g., category: Electronics, Computers, and Pet Supplies. A common way of leveraging aspect information for multi-aspect retrieval is to introduce an auxiliary classification objective, i.e., using item contents to predict the annotated value IDs of item aspects. However, by learning the value embeddings from scratch, this approach may not capture the various semantic similarities between the values sufficiently. To address this limitation, we leverage the aspect information as text strings rather than class IDs during pre-training so that their semantic similarities can be naturally captured in the PLMs. To facilitate effective retrieval with the aspect strings, we propose mutual prediction objectives between the text of the item aspect and content. In this way, our model makes more sufficient use of aspect information than conducting undifferentiated masked language modeling (MLM) on the concatenated text of aspects and content. Extensive experiments on two real-world datasets (product and mini-program search) show that our approach can outperform competitive baselines both treating aspect values as classes and conducting the same MLM for aspect and content strings. Code and related dataset will be available at the URL \footnote{https://github.com/sunxiaojie99/ATTEMPT}.