 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Spatiotemporal Deep Neural Network for Fine-Grained Multi-Horizon Wind Prediction
Sep 09, 2023
The prediction of wind in terms of both wind speed and direction, which has a crucial impact on many real-world applications like aviation and wind power generation, is extremely challenging due to the high stochasticity and complicated correlation in the weather data. Existing methods typically focus on a sub-set of influential factors and thus lack a systematic treatment of the problem. In addition, fine-grained forecasting is essential for efficient industry operations, but has been less attended in the literature. In this work, we propose a novel data-driven model, Multi-Horizon SpatioTemporal Network (MHSTN), generally for accurate and efficient fine-grained wind prediction. MHSTN integrates multiple deep neural networks targeting different factors in a sequence-to-sequence (Seq2Seq) backbone to effectively extract features from various data sources and produce multi-horizon predictions for all sites within a given region. MHSTN is composed of four major modules. First, a temporal module fuses coarse-grained forecasts derived by Numerical Weather Prediction (NWP) and historical on-site observation data at stations so as to leverage both global and local atmospheric information. Second, a spatial module exploits spatial correlation by modeling the joint representation of all stations. Third, an ensemble module weighs the above two modules for final predictions. Furthermore, a covariate selection module automatically choose influential meteorological variables as initial input. MHSTN is already integrated into the scheduling platform of one of the busiest international airports of China. The evaluation results demonstrate that our model outperforms competitors by a significant margin.
Timely Fusion of Surround Radar/Lidar for Object Detection in Autonomous Driving Systems
Sep 09, 2023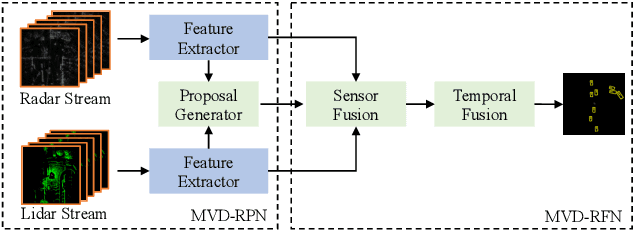
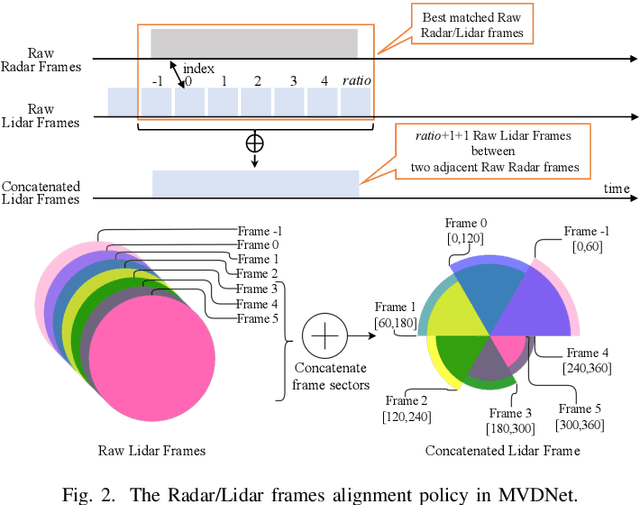
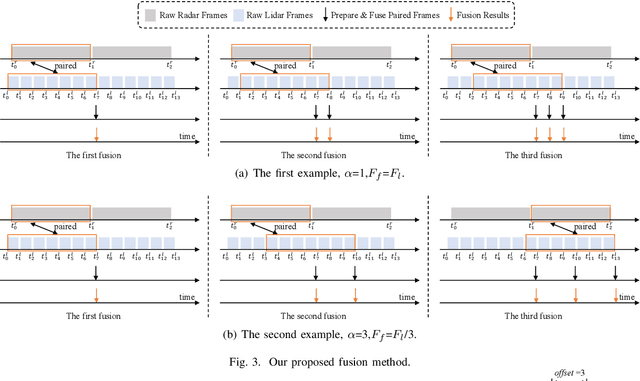
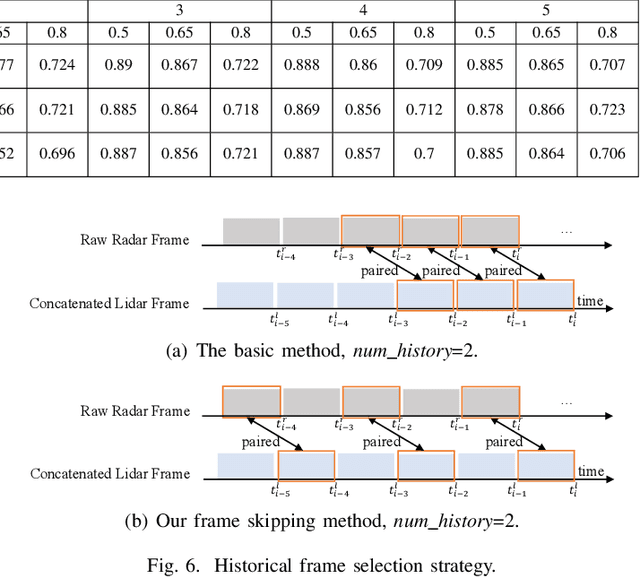
Fusing Radar and Lidar sensor data can fully utilize their complementary advantages and provide more accurate reconstruction of the surrounding for autonomous driving systems. Surround Radar/Lidar can provide 360-degree view sampling with the minimal cost, which are promising sensing hardware solutions for autonomous driving systems. However, due to the intrinsic physical constraints, the rotating speed of surround Radar, and thus the frequency to generate Radar data frames, is much lower than surround Lidar. Existing Radar/Lidar fusion methods have to work at the low frequency of surround Radar, which cannot meet the high responsiveness requirement of autonomous driving systems.This paper develops techniques to fuse surround Radar/Lidar with working frequency only limited by the faster surround Lidar instead of the slower surround Radar, based on the state-of-the-art object detection model MVDNet. The basic idea of our approach is simple: we let MVDNet work with temporally unaligned data from Radar/Lidar, so that fusion can take place at any time when a new Lidar data frame arrives, instead of waiting for the slow Radar data frame. However, directly applying MVDNet to temporally unaligned Radar/Lidar data greatly degrades its object detection accuracy. The key information revealed in this paper is that we can achieve high output frequency with little accuracy loss by enhancing the training procedure to explore the temporal redundancy in MVDNet so that it can tolerate the temporal unalignment of input data. We explore several different ways of training enhancement and compare them quantitatively with experiments.
Solving Recurrence Relations using Machine Learning, with Application to Cost Analysis
Aug 30, 2023Automatic static cost analysis infers information about the resources used by programs without actually running them with concrete data, and presents such information as functions of input data sizes. Most of the analysis tools for logic programs (and other languages) are based on setting up recurrence relations representing (bounds on) the computational cost of predicates, and solving them to find closed-form functions that are equivalent to (or a bound on) them. Such recurrence solving is a bottleneck in current tools: many of the recurrences that arise during the analysis cannot be solved with current solvers, such as Computer Algebra Systems (CASs), so that specific methods for different classes of recurrences need to be developed. We address such a challenge by developing a novel, general approach for solving arbitrary, constrained recurrence relations, that uses machine-learning sparse regression techniques to guess a candidate closed-form function, and a combination of an SMT-solver and a CAS to check whether such function is actually a solution of the recurrence. We have implemented a prototype and evaluated it with recurrences generated by a cost analysis system (the one in CiaoPP). The experimental results are quite promising, showing that our approach can find closed-form solutions, in a reasonable time, for classes of recurrences that cannot be solved by such a system, nor by current CASs.
* In Proceedings ICLP 2023, arXiv:2308.14898
Physics-Informed DeepMRI: Bridging the Gap from Heat Diffusion to k-Space Interpolation
Aug 30, 2023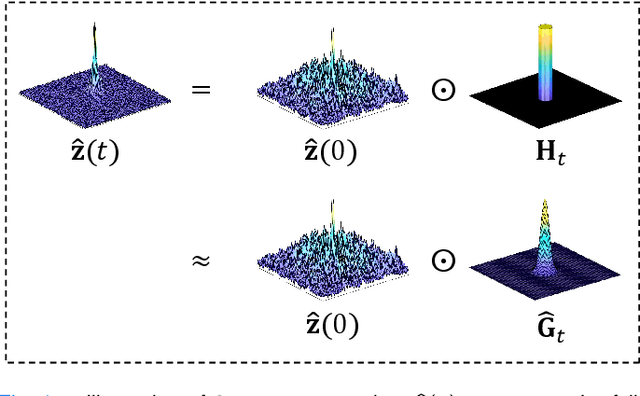
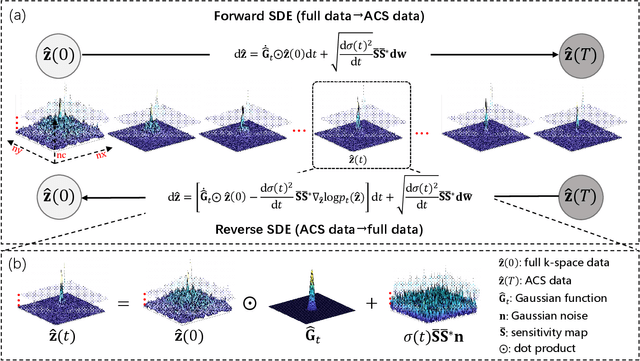

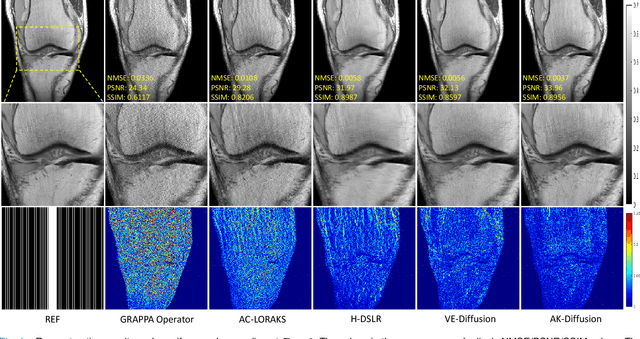
In the field of parallel imaging (PI), alongside image-domain regularization methods, substantial research has been dedicated to exploring $k$-space interpolation. However, the interpretability of these methods remains an unresolved issue. Furthermore, these approaches currently face acceleration limitations that are comparable to those experienced by image-domain methods. In order to enhance interpretability and overcome the acceleration limitations, this paper introduces an interpretable framework that unifies both $k$-space interpolation techniques and image-domain methods, grounded in the physical principles of heat diffusion equations. Building upon this foundational framework, a novel $k$-space interpolation method is proposed. Specifically, we model the process of high-frequency information attenuation in $k$-space as a heat diffusion equation, while the effort to reconstruct high-frequency information from low-frequency regions can be conceptualized as a reverse heat equation. However, solving the reverse heat equation poses a challenging inverse problem. To tackle this challenge, we modify the heat equation to align with the principles of magnetic resonance PI physics and employ the score-based generative method to precisely execute the modified reverse heat diffusion. Finally, experimental validation conducted on publicly available datasets demonstrates the superiority of the proposed approach over traditional $k$-space interpolation methods, deep learning-based $k$-space interpolation methods, and conventional diffusion models in terms of reconstruction accuracy, particularly in high-frequency regions.
DiffuVolume: Diffusion Model for Volume based Stereo Matching
Aug 30, 2023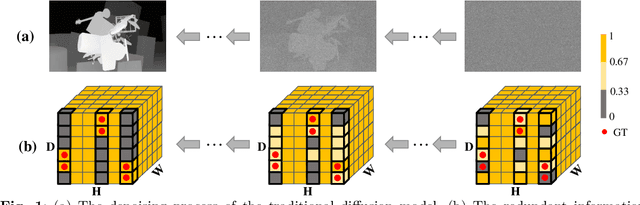

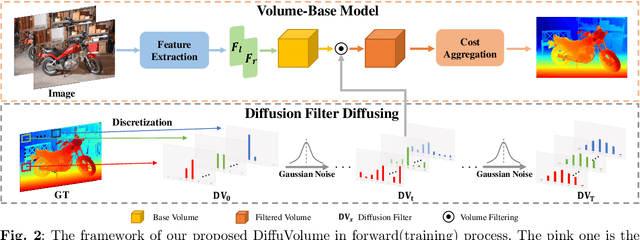
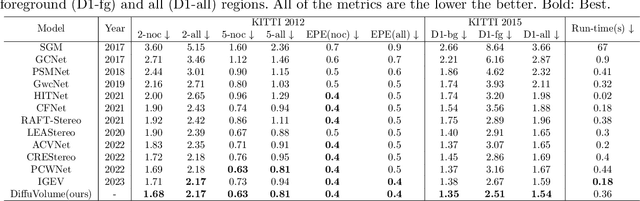
Stereo matching is a significant part in many computer vision tasks and driving-based applications. Recently cost volume-based methods have achieved great success benefiting from the rich geometry information in paired images. However, the redundancy of cost volume also interferes with the model training and limits the performance. To construct a more precise cost volume, we pioneeringly apply the diffusion model to stereo matching. Our method, termed DiffuVolume, considers the diffusion model as a cost volume filter, which will recurrently remove the redundant information from the cost volume. Two main designs make our method not trivial. Firstly, to make the diffusion model more adaptive to stereo matching, we eschew the traditional manner of directly adding noise into the image but embed the diffusion model into a task-specific module. In this way, we outperform the traditional diffusion stereo matching method by 22% EPE improvement and 240 times inference acceleration. Secondly, DiffuVolume can be easily embedded into any volume-based stereo matching network with boost performance but slight parameters rise (only 2%). By adding the DiffuVolume into well-performed methods, we outperform all the published methods on Scene Flow, KITTI2012, KITTI2015 benchmarks and zero-shot generalization setting. It is worth mentioning that the proposed model ranks 1st on KITTI 2012 leader board, 2nd on KITTI 2015 leader board since 15, July 2023.
Information-Computation Tradeoffs for Learning Margin Halfspaces with Random Classification Noise
Jun 28, 2023We study the problem of PAC learning $\gamma$-margin halfspaces with Random Classification Noise. We establish an information-computation tradeoff suggesting an inherent gap between the sample complexity of the problem and the sample complexity of computationally efficient algorithms. Concretely, the sample complexity of the problem is $\widetilde{\Theta}(1/(\gamma^2 \epsilon))$. We start by giving a simple efficient algorithm with sample complexity $\widetilde{O}(1/(\gamma^2 \epsilon^2))$. Our main result is a lower bound for Statistical Query (SQ) algorithms and low-degree polynomial tests suggesting that the quadratic dependence on $1/\epsilon$ in the sample complexity is inherent for computationally efficient algorithms. Specifically, our results imply a lower bound of $\widetilde{\Omega}(1/(\gamma^{1/2} \epsilon^2))$ on the sample complexity of any efficient SQ learner or low-degree test.
Advancing Personalized Federated Learning: Group Privacy, Fairness, and Beyond
Sep 01, 2023Federated learning (FL) is a framework for training machine learning models in a distributed and collaborative manner. During training, a set of participating clients process their data stored locally, sharing only the model updates obtained by minimizing a cost function over their local inputs. FL was proposed as a stepping-stone towards privacy-preserving machine learning, but it has been shown vulnerable to issues such as leakage of private information, lack of personalization of the model, and the possibility of having a trained model that is fairer to some groups than to others. In this paper, we address the triadic interaction among personalization, privacy guarantees, and fairness attained by models trained within the FL framework. Differential privacy and its variants have been studied and applied as cutting-edge standards for providing formal privacy guarantees. However, clients in FL often hold very diverse datasets representing heterogeneous communities, making it important to protect their sensitive information while still ensuring that the trained model upholds the aspect of fairness for the users. To attain this objective, a method is put forth that introduces group privacy assurances through the utilization of $d$-privacy (aka metric privacy). $d$-privacy represents a localized form of differential privacy that relies on a metric-oriented obfuscation approach to maintain the original data's topological distribution. This method, besides enabling personalized model training in a federated approach and providing formal privacy guarantees, possesses significantly better group fairness measured under a variety of standard metrics than a global model trained within a classical FL template. Theoretical justifications for the applicability are provided, as well as experimental validation on real-world datasets to illustrate the working of the proposed method.
Duplicate Question Retrieval and Confirmation Time Prediction in Software Communities
Sep 10, 2023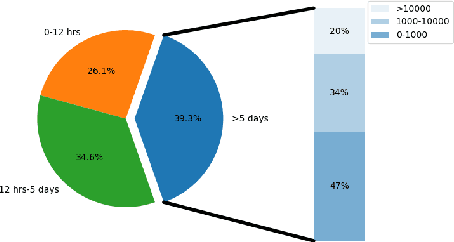
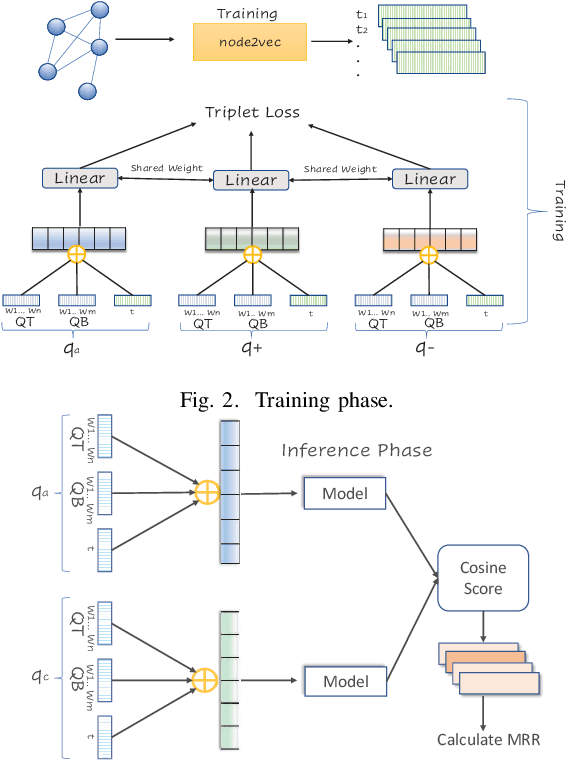


Community Question Answering (CQA) in different domains is growing at a large scale because of the availability of several platforms and huge shareable information among users. With the rapid growth of such online platforms, a massive amount of archived data makes it difficult for moderators to retrieve possible duplicates for a new question and identify and confirm existing question pairs as duplicates at the right time. This problem is even more critical in CQAs corresponding to large software systems like askubuntu where moderators need to be experts to comprehend something as a duplicate. Note that the prime challenge in such CQA platforms is that the moderators are themselves experts and are therefore usually extremely busy with their time being extraordinarily expensive. To facilitate the task of the moderators, in this work, we have tackled two significant issues for the askubuntu CQA platform: (1) retrieval of duplicate questions given a new question and (2) duplicate question confirmation time prediction. In the first task, we focus on retrieving duplicate questions from a question pool for a particular newly posted question. In the second task, we solve a regression problem to rank a pair of questions that could potentially take a long time to get confirmed as duplicates. For duplicate question retrieval, we propose a Siamese neural network based approach by exploiting both text and network-based features, which outperforms several state-of-the-art baseline techniques. Our method outperforms DupPredictor and DUPE by 5% and 7% respectively. For duplicate confirmation time prediction, we have used both the standard machine learning models and neural network along with the text and graph-based features. We obtain Spearman's rank correlation of 0.20 and 0.213 (statistically significant) for text and graph based features respectively.
Learning Whole-body Manipulation for Quadrupedal Robot
Sep 06, 2023
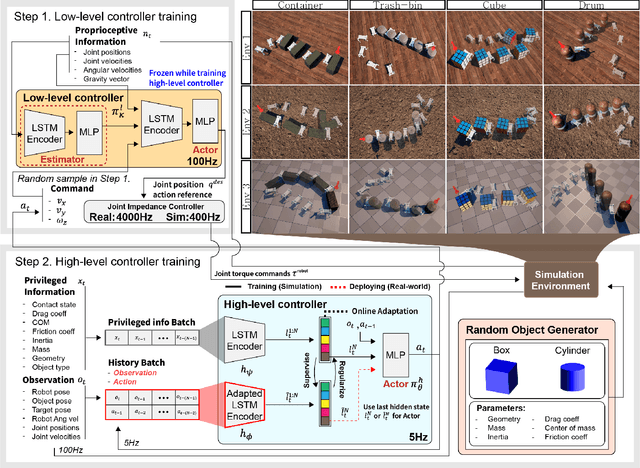
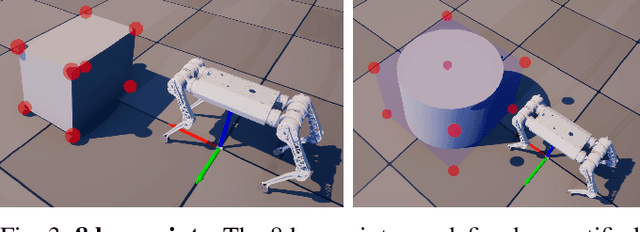

We propose a learning-based system for enabling quadrupedal robots to manipulate large, heavy objects using their whole body. Our system is based on a hierarchical control strategy that uses the deep latent variable embedding which captures manipulation-relevant information from interactions, proprioception, and action history, allowing the robot to implicitly understand object properties. We evaluate our framework in both simulation and real-world scenarios. In the simulation, it achieves a success rate of 93.6 % in accurately re-positioning and re-orienting various objects within a tolerance of 0.03 m and 5 {\deg}. Real-world experiments demonstrate the successful manipulation of objects such as a 19.2 kg water-filled drum and a 15.3 kg plastic box filled with heavy objects while the robot weighs 27 kg. Unlike previous works that focus on manipulating small and light objects using prehensile manipulation, our framework illustrates the possibility of using quadrupeds for manipulating large and heavy objects that are ungraspable with the robot's entire body. Our method does not require explicit object modeling and offers significant computational efficiency compared to optimization-based methods. The video can be found at https://youtu.be/fO_PVr27QxU.
InstructME: An Instruction Guided Music Edit And Remix Framework with Latent Diffusion Models
Sep 06, 2023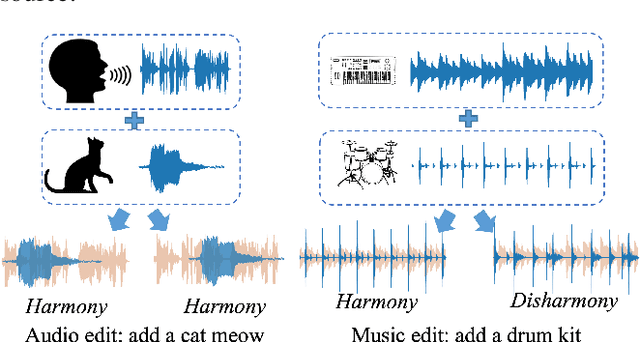
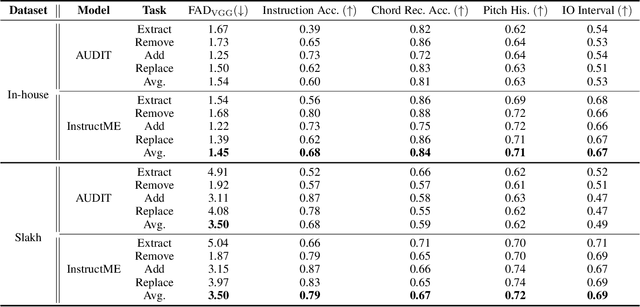
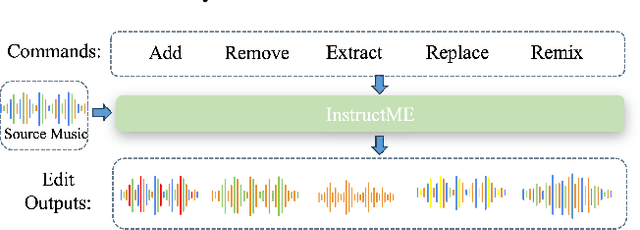
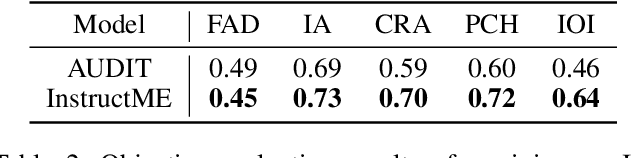
Music editing primarily entails the modification of instrument tracks or remixing in the whole, which offers a novel reinterpretation of the original piece through a series of operations. These music processing methods hold immense potential across various applications but demand substantial expertise. Prior methodologies, although effective for image and audio modifications, falter when directly applied to music. This is attributed to music's distinctive data nature, where such methods can inadvertently compromise the intrinsic harmony and coherence of music. In this paper, we develop InstructME, an Instruction guided Music Editing and remixing framework based on latent diffusion models. Our framework fortifies the U-Net with multi-scale aggregation in order to maintain consistency before and after editing. In addition, we introduce chord progression matrix as condition information and incorporate it in the semantic space to improve melodic harmony while editing. For accommodating extended musical pieces, InstructME employs a chunk transformer, enabling it to discern long-term temporal dependencies within music sequences. We tested InstructME in instrument-editing, remixing, and multi-round editing. Both subjective and objective evaluations indicate that our proposed method significantly surpasses preceding systems in music quality, text relevance and harmony. Demo samples are available at https://musicedit.github.io/