 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Generative AI for Business Strategy: Using Foundation Models to Create Business Strategy Tools
Aug 27, 2023
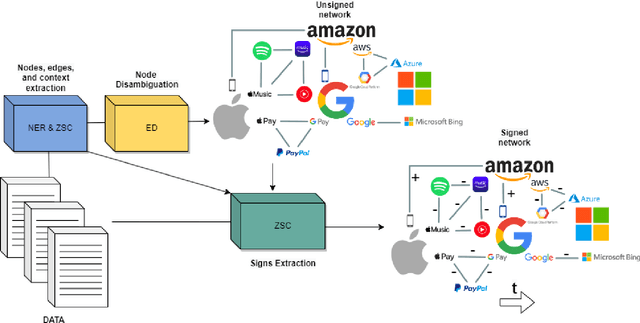
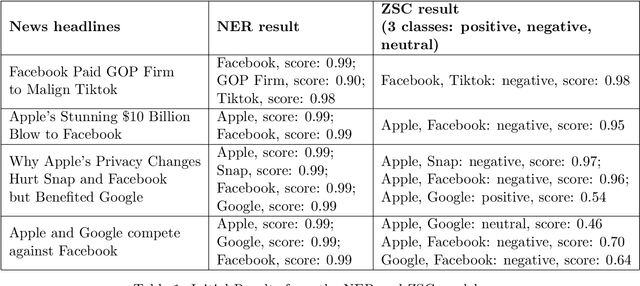
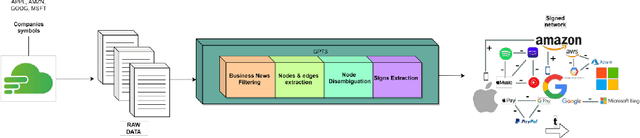
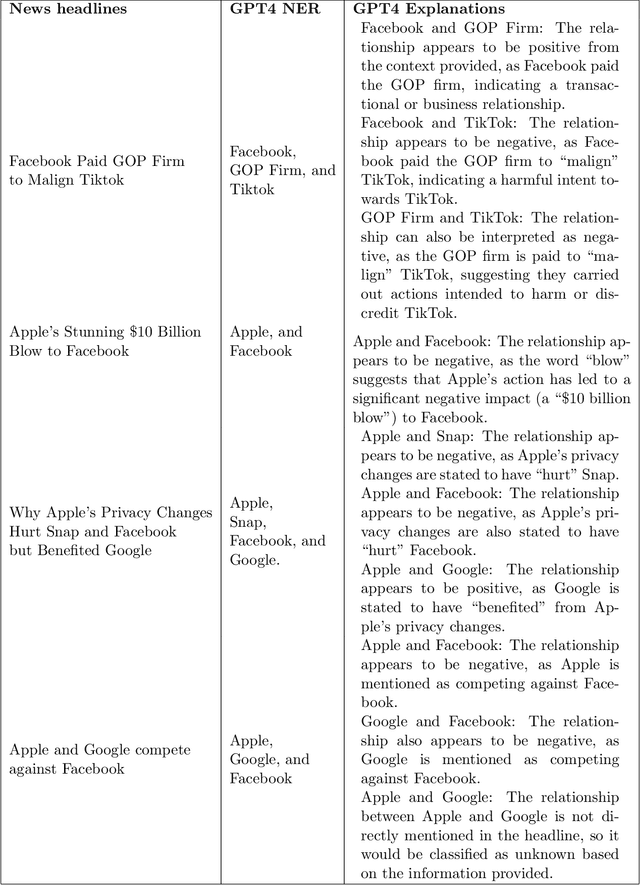
Generative models (foundation models) such as LLMs (large language models) are having a large impact on multiple fields. In this work, we propose the use of such models for business decision making. In particular, we combine unstructured textual data sources (e.g., news data) with multiple foundation models (namely, GPT4, transformer-based Named Entity Recognition (NER) models and Entailment-based Zero-shot Classifiers (ZSC)) to derive IT (information technology) artifacts in the form of a (sequence of) signed business networks. We posit that such artifacts can inform business stakeholders about the state of the market and their own positioning as well as provide quantitative insights into improving their future outlook.
GNFactor: Multi-Task Real Robot Learning with Generalizable Neural Feature Fields
Sep 01, 2023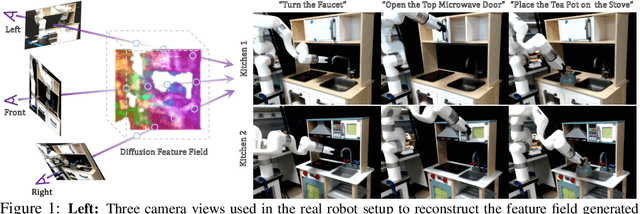



It is a long-standing problem in robotics to develop agents capable of executing diverse manipulation tasks from visual observations in unstructured real-world environments. To achieve this goal, the robot needs to have a comprehensive understanding of the 3D structure and semantics of the scene. In this work, we present $\textbf{GNFactor}$, a visual behavior cloning agent for multi-task robotic manipulation with $\textbf{G}$eneralizable $\textbf{N}$eural feature $\textbf{F}$ields. GNFactor jointly optimizes a generalizable neural field (GNF) as a reconstruction module and a Perceiver Transformer as a decision-making module, leveraging a shared deep 3D voxel representation. To incorporate semantics in 3D, the reconstruction module utilizes a vision-language foundation model ($\textit{e.g.}$, Stable Diffusion) to distill rich semantic information into the deep 3D voxel. We evaluate GNFactor on 3 real robot tasks and perform detailed ablations on 10 RLBench tasks with a limited number of demonstrations. We observe a substantial improvement of GNFactor over current state-of-the-art methods in seen and unseen tasks, demonstrating the strong generalization ability of GNFactor. Our project website is https://yanjieze.com/GNFactor/ .
CSM-H-R: A Context Modeling Framework in Supporting Reasoning Automation for Interoperable Intelligent Systems and Privacy Protection
Sep 01, 2023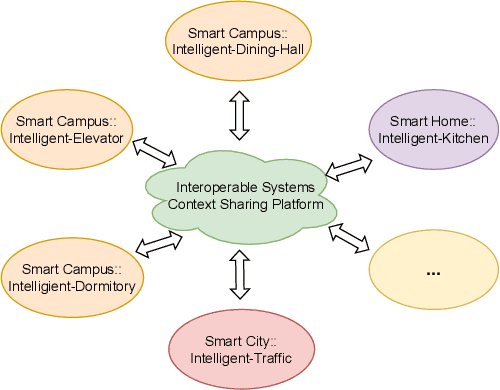
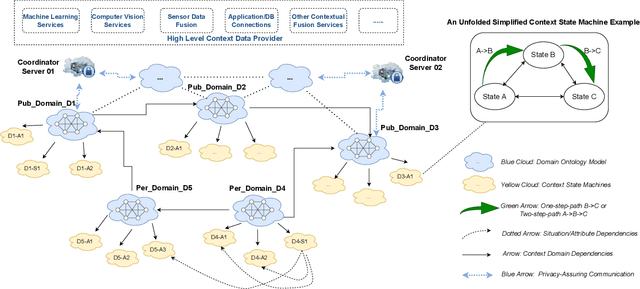
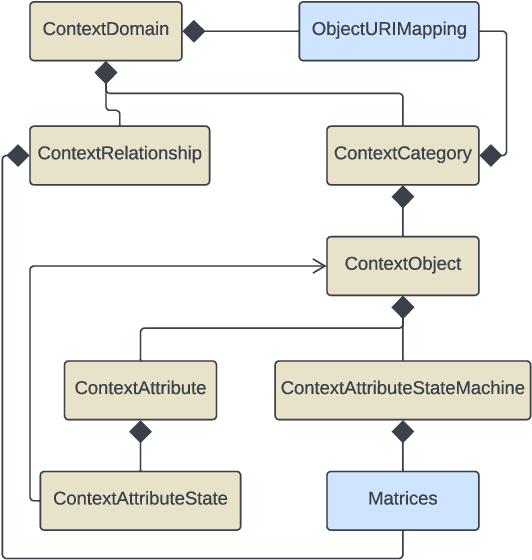
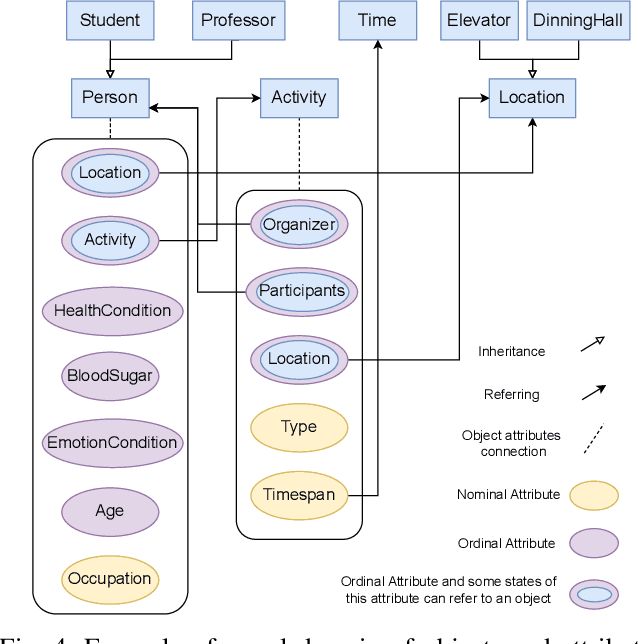
Automation of High-Level Context (HLC) reasoning for intelligent systems at scale is imperative due to the unceasing accumulation of contextual data in the IoT era, the trend of the fusion of data from multi-sources, and the intrinsic complexity and dynamism of the context-based decision-making process. To mitigate this issue, we propose an automatic context reasoning framework CSM-H-R, which programmatically combines ontologies and states at runtime and the model-storage phase for attaining the ability to recognize meaningful HLC, and the resulting data representation can be applied to different reasoning techniques. Case studies are developed based on an intelligent elevator system in a smart campus setting. An implementation of the framework - a CSM Engine, and the experiments of translating the HLC reasoning into vector and matrix computing especially take care of the dynamic aspects of context and present the potentiality of using advanced mathematical and probabilistic models to achieve the next level of automation in integrating intelligent systems; meanwhile, privacy protection support is achieved by anonymization through label embedding and reducing information correlation. The code of this study is available at: https://github.com/songhui01/CSM-H-R.
Learning multi-modal generative models with permutation-invariant encoders and tighter variational bounds
Sep 01, 2023Devising deep latent variable models for multi-modal data has been a long-standing theme in machine learning research. Multi-modal Variational Autoencoders (VAEs) have been a popular generative model class that learns latent representations which jointly explain multiple modalities. Various objective functions for such models have been suggested, often motivated as lower bounds on the multi-modal data log-likelihood or from information-theoretic considerations. In order to encode latent variables from different modality subsets, Product-of-Experts (PoE) or Mixture-of-Experts (MoE) aggregation schemes have been routinely used and shown to yield different trade-offs, for instance, regarding their generative quality or consistency across multiple modalities. In this work, we consider a variational bound that can tightly lower bound the data log-likelihood. We develop more flexible aggregation schemes that generalise PoE or MoE approaches by combining encoded features from different modalities based on permutation-invariant neural networks. Our numerical experiments illustrate trade-offs for multi-modal variational bounds and various aggregation schemes. We show that tighter variational bounds and more flexible aggregation models can become beneficial when one wants to approximate the true joint distribution over observed modalities and latent variables in identifiable models.
MUSIC Algorithm for IRS-Assisted AOA Estimation
Sep 06, 2023Based on the signals received across its antennas, a multi-antenna base station (BS) can apply the classic multiple signal classification (MUSIC) algorithm for estimating the angle of arrivals (AOAs) of its incident signals. This method can be leveraged to localize the users if their line-of-sight (LOS) paths to the BS are available. In this paper, we consider a more challenging AOA estimation setup in the intelligent reflecting surface (IRS) assisted integrated sensing and communication (ISAC) system, where LOS paths do not exist between the BS and the users, while the users' signals can be transmitted to the BS merely via their LOS paths to the IRS as well as the LOS path from the IRS to the BS. Specifically, we treat the IRS as the anchor and are interested in estimating the AOAs of the incident signals from the users to the IRS. Note that we have to achieve the above goal based on the signals received by the BS, because the passive IRS cannot process its received signals. However, the signals received across different antennas of the BS only contain AOA information of its incident signals via the LOS path from the IRS to the BS. To tackle this challenge arising from the spatial-domain received signals, we propose an innovative approach to create temporal-domain multi-dimension received signals for estimating the AOAs of the paths from the users to the IRS. Specifically, via a proper design of the user message pattern and the IRS reflecting pattern, we manage to show that our designed temporal-domain multi-dimension signals can be surprisingly expressed as a function of the virtual steering vectors of the IRS towards the users. This amazing result implies that the classic MUSIC algorithm can be applied to our designed temporal-domain multi-dimension signals for accurately estimating the AOAs of the signals from the users to the IRS.
DiffV2S: Diffusion-based Video-to-Speech Synthesis with Vision-guided Speaker Embedding
Aug 15, 2023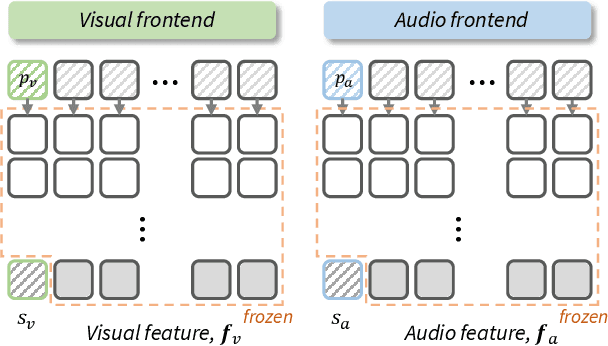
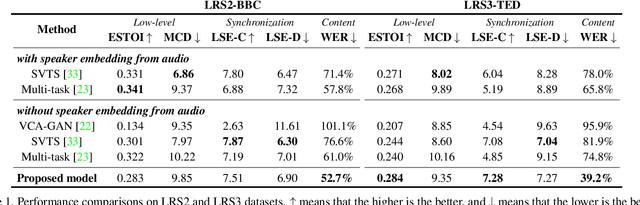
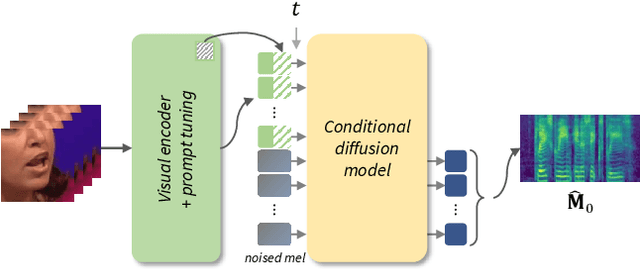
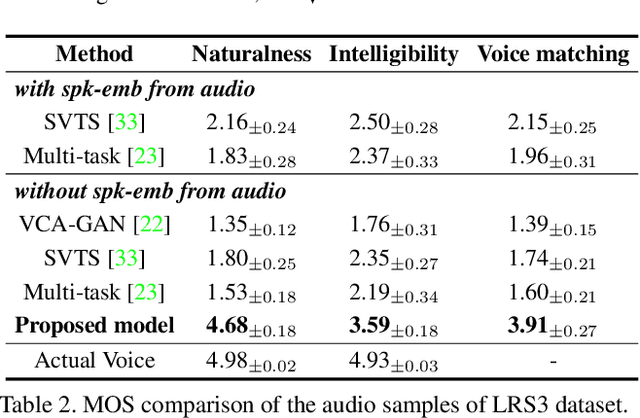
Recent research has demonstrated impressive results in video-to-speech synthesis which involves reconstructing speech solely from visual input. However, previous works have struggled to accurately synthesize speech due to a lack of sufficient guidance for the model to infer the correct content with the appropriate sound. To resolve the issue, they have adopted an extra speaker embedding as a speaking style guidance from a reference auditory information. Nevertheless, it is not always possible to obtain the audio information from the corresponding video input, especially during the inference time. In this paper, we present a novel vision-guided speaker embedding extractor using a self-supervised pre-trained model and prompt tuning technique. In doing so, the rich speaker embedding information can be produced solely from input visual information, and the extra audio information is not necessary during the inference time. Using the extracted vision-guided speaker embedding representations, we further develop a diffusion-based video-to-speech synthesis model, so called DiffV2S, conditioned on those speaker embeddings and the visual representation extracted from the input video. The proposed DiffV2S not only maintains phoneme details contained in the input video frames, but also creates a highly intelligible mel-spectrogram in which the speaker identities of the multiple speakers are all preserved. Our experimental results show that DiffV2S achieves the state-of-the-art performance compared to the previous video-to-speech synthesis technique.
On the physical layer security capabilities of reconfigurable intelligent surface empowered wireless systems
Aug 19, 2023In this paper, we investigate the physical layer security capabilities of reconfigurable intelligent surface (RIS) empowered wireless systems. In more detail, we consider a general system model, in which the links between the transmitter (TX) and the RIS as well as the links between the RIS and the legitimate receiver are modeled as mixture Gamma (MG) random variables (RVs). Moreover, the link between the TX and eavesdropper is also modeled as a MG RV. Building upon this system model, we derive the probability of zero-secrecy capacity as well as the probability of information leakage. Finally, we extract the average secrecy rate for both cases of TX having full and partial channel state information knowledge.
Motion-Guided Masking for Spatiotemporal Representation Learning
Aug 24, 2023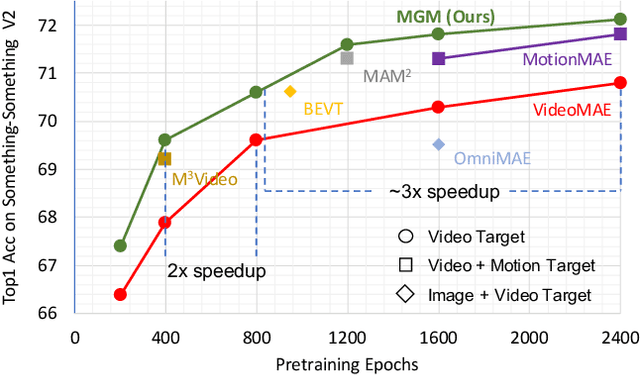
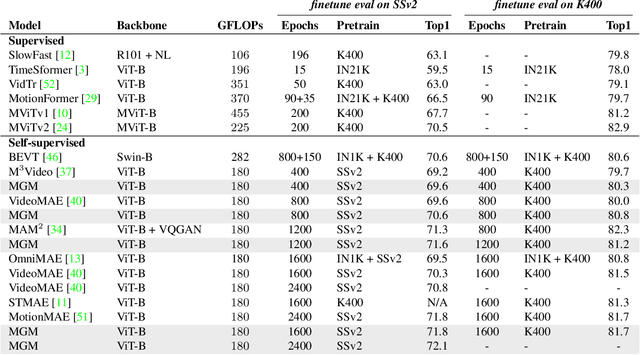
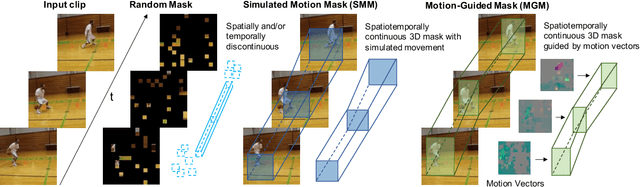
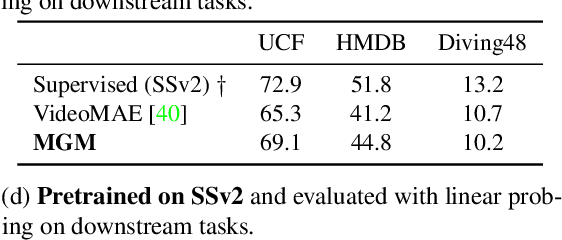
Several recent works have directly extended the image masked autoencoder (MAE) with random masking into video domain, achieving promising results. However, unlike images, both spatial and temporal information are important for video understanding. This suggests that the random masking strategy that is inherited from the image MAE is less effective for video MAE. This motivates the design of a novel masking algorithm that can more efficiently make use of video saliency. Specifically, we propose a motion-guided masking algorithm (MGM) which leverages motion vectors to guide the position of each mask over time. Crucially, these motion-based correspondences can be directly obtained from information stored in the compressed format of the video, which makes our method efficient and scalable. On two challenging large-scale video benchmarks (Kinetics-400 and Something-Something V2), we equip video MAE with our MGM and achieve up to +$1.3\%$ improvement compared to previous state-of-the-art methods. Additionally, our MGM achieves equivalent performance to previous video MAE using up to $66\%$ fewer training epochs. Lastly, we show that MGM generalizes better to downstream transfer learning and domain adaptation tasks on the UCF101, HMDB51, and Diving48 datasets, achieving up to +$4.9\%$ improvement compared to baseline methods.
Deep Semi-supervised Anomaly Detection with Metapath-based Context Knowledge
Aug 21, 2023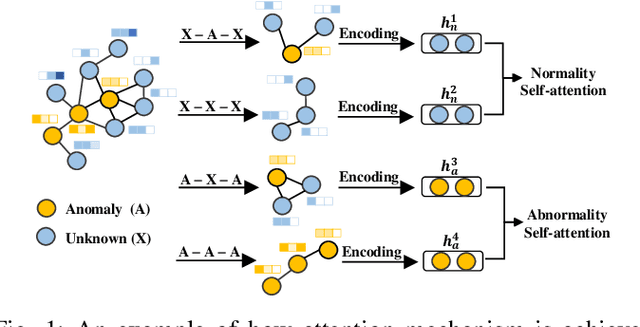
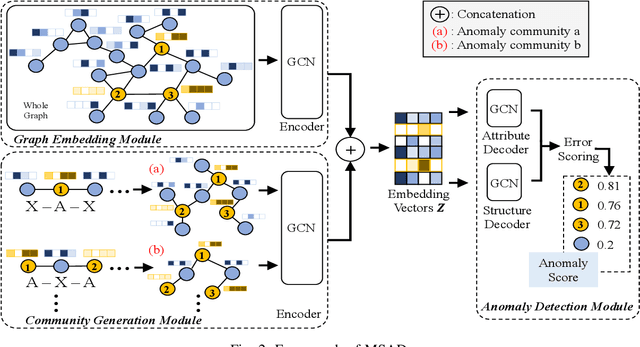
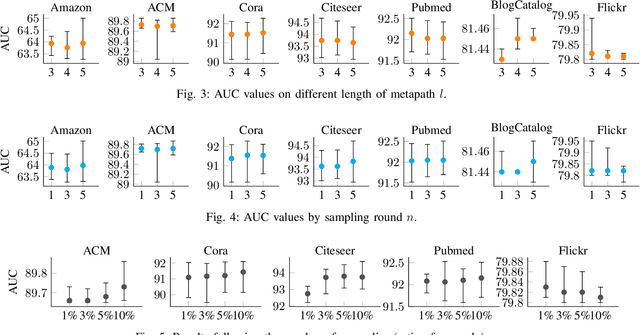
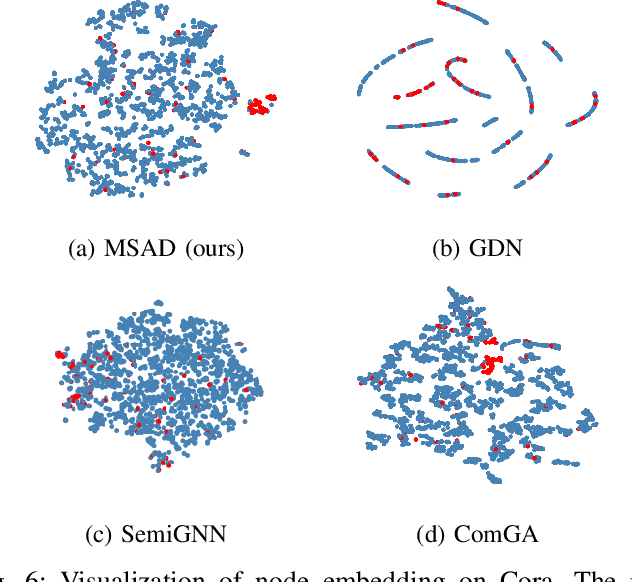
Graph anomaly detection has attracted considerable attention in recent years. This paper introduces a novel approach that leverages metapath-based semi-supervised learning, addressing the limitations of previous methods. We present a new framework, Metapath-based Semi-supervised Anomaly Detection (MSAD), incorporating GCN layers in both the encoder and decoder to efficiently propagate context information between abnormal and normal nodes. The design of metapath-based context information and a specifically crafted anomaly community enhance the process of learning differences in structures and attributes, both globally and locally. Through a comprehensive set of experiments conducted on seven real-world networks, this paper demonstrates the superiority of the MSAD method compared to state-of-the-art techniques. The promising results of this study pave the way for future investigations, focusing on the optimization and analysis of metapath patterns to further enhance the effectiveness of anomaly detection on attributed networks.
Fusing VHR Post-disaster Aerial Imagery and LiDAR Data for Roof Classification in the Caribbean
Aug 20, 2023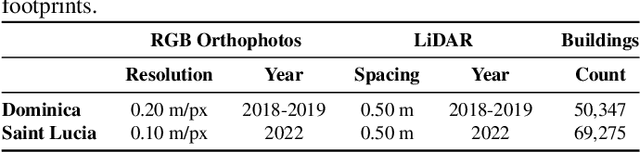

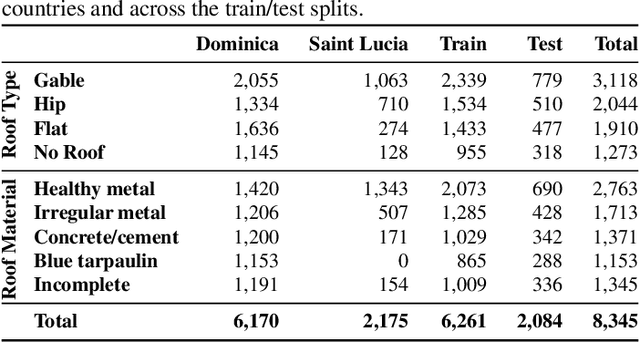

Accurate and up-to-date information on building characteristics is essential for vulnerability assessment; however, the high costs and long timeframes associated with conducting traditional field surveys can be an obstacle to obtaining critical exposure datasets needed for disaster risk management. In this work, we leverage deep learning techniques for the automated classification of roof characteristics from very high-resolution orthophotos and airborne LiDAR data obtained in Dominica following Hurricane Maria in 2017. We demonstrate that the fusion of multimodal earth observation data performs better than using any single data source alone. Using our proposed methods, we achieve F1 scores of 0.93 and 0.92 for roof type and roof material classification, respectively. This work is intended to help governments produce more timely building information to improve resilience and disaster response in the Caribbean.