 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Four years of multi-modal odometry and mapping on the rail vehicles
Aug 22, 2023


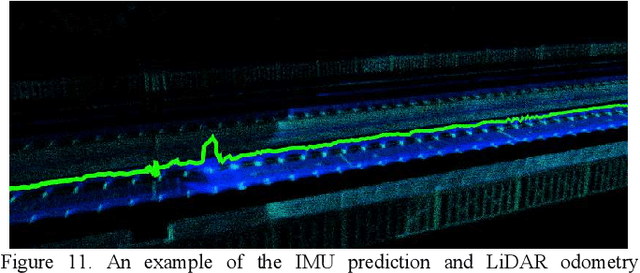
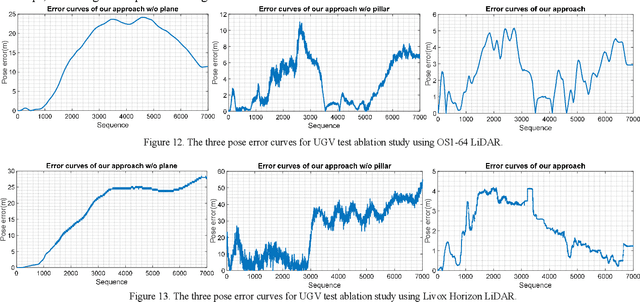
Precise, seamless, and efficient train localization as well as long-term railway environment monitoring is the essential property towards reliability, availability, maintainability, and safety (RAMS) engineering for railroad systems. Simultaneous localization and mapping (SLAM) is right at the core of solving the two problems concurrently. In this end, we propose a high-performance and versatile multi-modal framework in this paper, targeted for the odometry and mapping task for various rail vehicles. Our system is built atop an inertial-centric state estimator that tightly couples light detection and ranging (LiDAR), visual, optionally satellite navigation and map-based localization information with the convenience and extendibility of loosely coupled methods. The inertial sensors IMU and wheel encoder are treated as the primary sensor, which achieves the observations from subsystems to constrain the accelerometer and gyroscope biases. Compared to point-only LiDAR-inertial methods, our approach leverages more geometry information by introducing both track plane and electric power pillars into state estimation. The Visual-inertial subsystem also utilizes the environmental structure information by employing both lines and points. Besides, the method is capable of handling sensor failures by automatic reconfiguration bypassing failure modules. Our proposed method has been extensively tested in the long-during railway environments over four years, including general-speed, high-speed and metro, both passenger and freight traffic are investigated. Further, we aim to share, in an open way, the experience, problems, and successes of our group with the robotics community so that those that work in such environments can avoid these errors. In this view, we open source some of the datasets to benefit the research community.
Unlocking Fine-Grained Details with Wavelet-based High-Frequency Enhancement in Transformers
Aug 25, 2023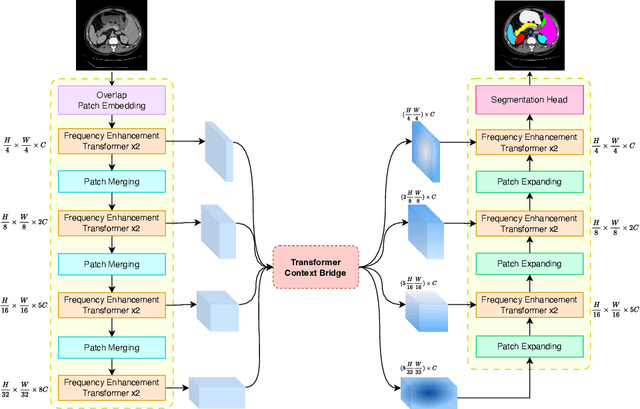
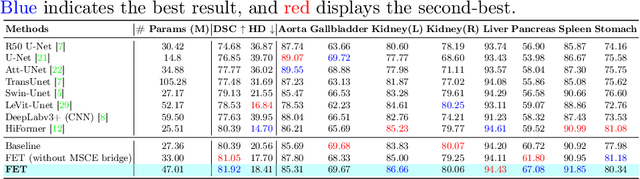
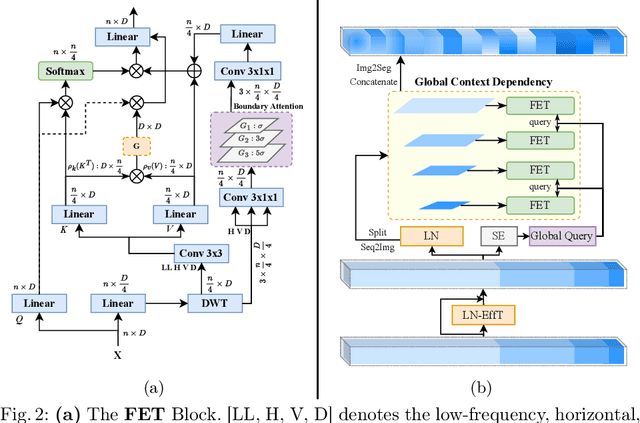
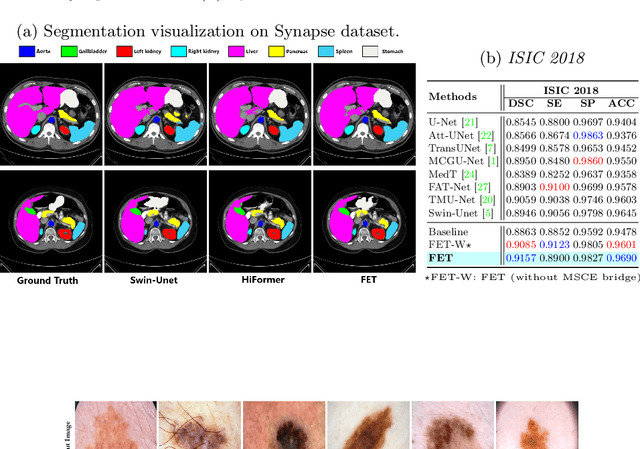
Medical image segmentation is a critical task that plays a vital role in diagnosis, treatment planning, and disease monitoring. Accurate segmentation of anatomical structures and abnormalities from medical images can aid in the early detection and treatment of various diseases. In this paper, we address the local feature deficiency of the Transformer model by carefully re-designing the self-attention map to produce accurate dense prediction in medical images. To this end, we first apply the wavelet transformation to decompose the input feature map into low-frequency (LF) and high-frequency (HF) subbands. The LF segment is associated with coarse-grained features while the HF components preserve fine-grained features such as texture and edge information. Next, we reformulate the self-attention operation using the efficient Transformer to perform both spatial and context attention on top of the frequency representation. Furthermore, to intensify the importance of the boundary information, we impose an additional attention map by creating a Gaussian pyramid on top of the HF components. Moreover, we propose a multi-scale context enhancement block within skip connections to adaptively model inter-scale dependencies to overcome the semantic gap among stages of the encoder and decoder modules. Throughout comprehensive experiments, we demonstrate the effectiveness of our strategy on multi-organ and skin lesion segmentation benchmarks. The implementation code will be available upon acceptance. \href{https://github.com/mindflow-institue/WaveFormer}{GitHub}.
* Accepted in MICCAI 2023 workshop MLMI
Staleness-Alleviated Distributed GNN Training via Online Dynamic-Embedding Prediction
Aug 25, 2023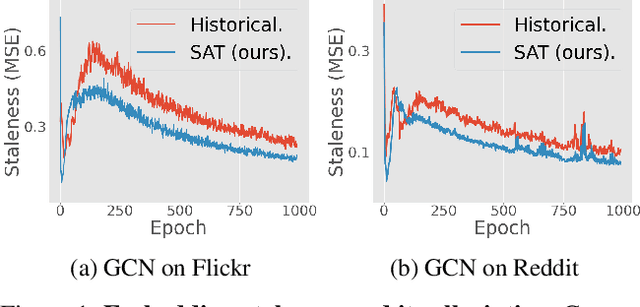
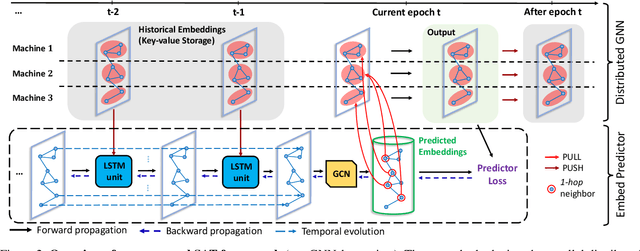
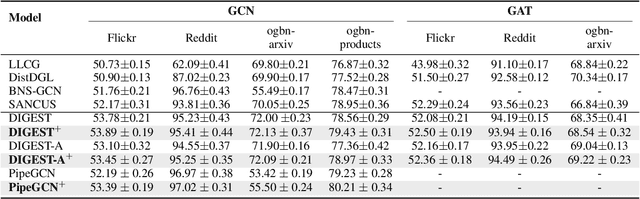
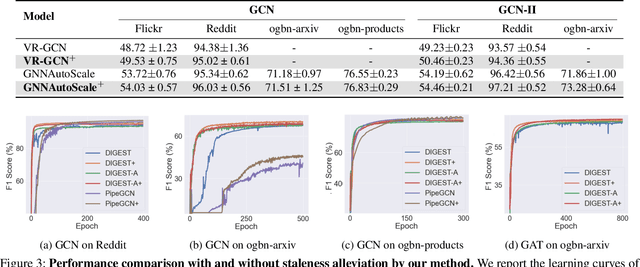
Despite the recent success of Graph Neural Networks (GNNs), it remains challenging to train GNNs on large-scale graphs due to neighbor explosions. As a remedy, distributed computing becomes a promising solution by leveraging abundant computing resources (e.g., GPU). However, the node dependency of graph data increases the difficulty of achieving high concurrency in distributed GNN training, which suffers from the massive communication overhead. To address it, Historical value approximation is deemed a promising class of distributed training techniques. It utilizes an offline memory to cache historical information (e.g., node embedding) as an affordable approximation of the exact value and achieves high concurrency. However, such benefits come at the cost of involving dated training information, leading to staleness, imprecision, and convergence issues. To overcome these challenges, this paper proposes SAT (Staleness-Alleviated Training), a novel and scalable distributed GNN training framework that reduces the embedding staleness adaptively. The key idea of SAT is to model the GNN's embedding evolution as a temporal graph and build a model upon it to predict future embedding, which effectively alleviates the staleness of the cached historical embedding. We propose an online algorithm to train the embedding predictor and the distributed GNN alternatively and further provide a convergence analysis. Empirically, we demonstrate that SAT can effectively reduce embedding staleness and thus achieve better performance and convergence speed on multiple large-scale graph datasets.
Direction-aware Video Demoireing with Temporal-guided Bilateral Learning
Aug 25, 2023



Moire patterns occur when capturing images or videos on screens, severely degrading the quality of the captured images or videos. Despite the recent progresses, existing video demoireing methods neglect the physical characteristics and formation process of moire patterns, significantly limiting the effectiveness of video recovery. This paper presents a unified framework, DTNet, a direction-aware and temporal-guided bilateral learning network for video demoireing. DTNet effectively incorporates the process of moire pattern removal, alignment, color correction, and detail refinement. Our proposed DTNet comprises two primary stages: Frame-level Direction-aware Demoireing and Alignment (FDDA) and Tone and Detail Refinement (TDR). In FDDA, we employ multiple directional DCT modes to perform the moire pattern removal process in the frequency domain, effectively detecting the prominent moire edges. Then, the coarse and fine-grained alignment is applied on the demoired features for facilitating the utilization of neighboring information. In TDR, we propose a temporal-guided bilateral learning pipeline to mitigate the degradation of color and details caused by the moire patterns while preserving the restored frequency information in FDDA. Guided by the aligned temporal features from FDDA, the affine transformations for the recovery of the ultimate clean frames are learned in TDR. Extensive experiments demonstrate that our video demoireing method outperforms state-of-the-art approaches by 2.3 dB in PSNR, and also delivers a superior visual experience.
Big-model Driven Few-shot Continual Learning
Sep 02, 2023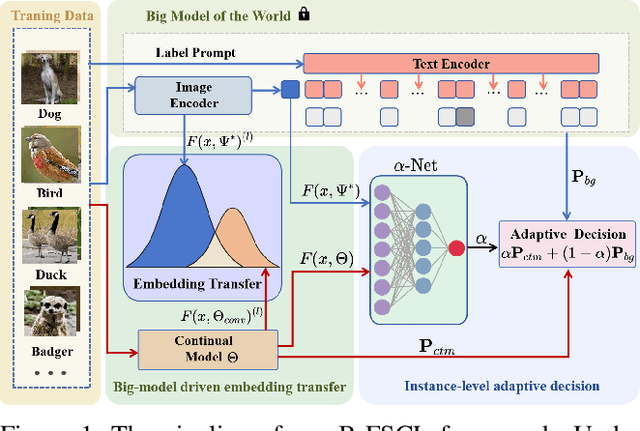
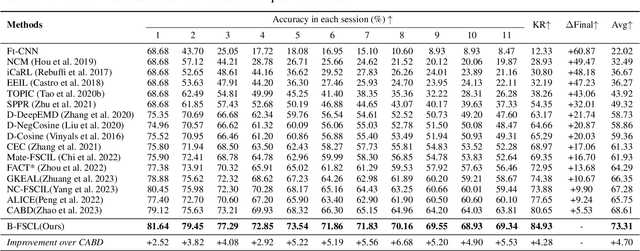
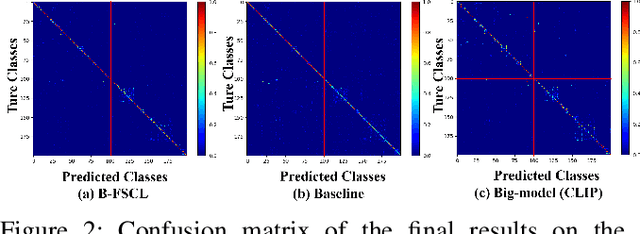
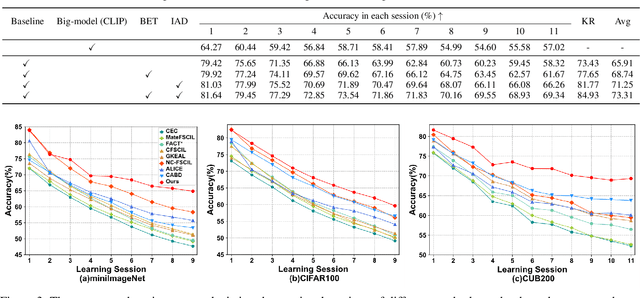
Few-shot continual learning (FSCL) has attracted intensive attention and achieved some advances in recent years, but now it is difficult to again make a big stride in accuracy due to the limitation of only few-shot incremental samples. Inspired by distinctive human cognition ability in life learning, in this work, we propose a novel Big-model driven Few-shot Continual Learning (B-FSCL) framework to gradually evolve the model under the traction of the world's big-models (like human accumulative knowledge). Specifically, we perform the big-model driven transfer learning to leverage the powerful encoding capability of these existing big-models, which can adapt the continual model to a few of newly added samples while avoiding the over-fitting problem. Considering that the big-model and the continual model may have different perceived results for the identical images, we introduce an instance-level adaptive decision mechanism to provide the high-level flexibility cognitive support adjusted to varying samples. In turn, the adaptive decision can be further adopted to optimize the parameters of the continual model, performing the adaptive distillation of big-model's knowledge information. Experimental results of our proposed B-FSCL on three popular datasets (including CIFAR100, minilmageNet and CUB200) completely surpass all state-of-the-art FSCL methods.
Regularly Truncated M-estimators for Learning with Noisy Labels
Sep 02, 2023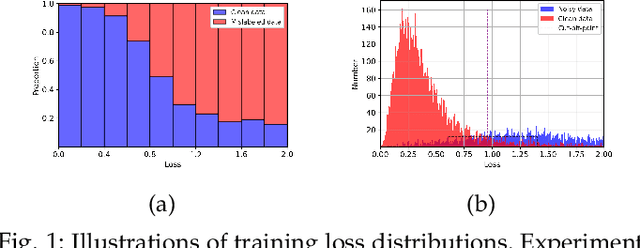
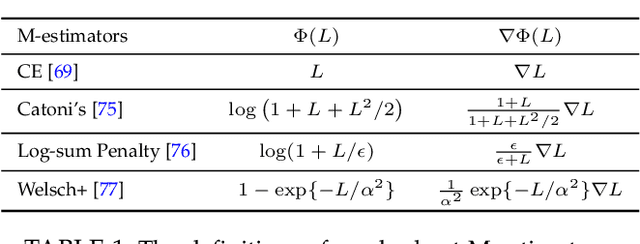
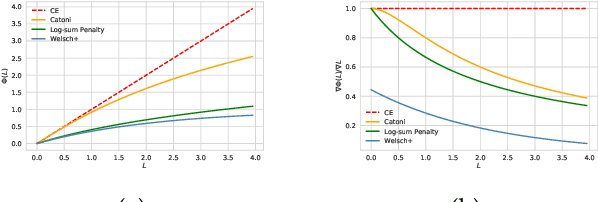
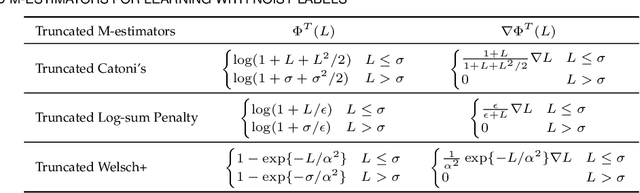
The sample selection approach is very popular in learning with noisy labels. As deep networks learn pattern first, prior methods built on sample selection share a similar training procedure: the small-loss examples can be regarded as clean examples and used for helping generalization, while the large-loss examples are treated as mislabeled ones and excluded from network parameter updates. However, such a procedure is arguably debatable from two folds: (a) it does not consider the bad influence of noisy labels in selected small-loss examples; (b) it does not make good use of the discarded large-loss examples, which may be clean or have meaningful information for generalization. In this paper, we propose regularly truncated M-estimators (RTME) to address the above two issues simultaneously. Specifically, RTME can alternately switch modes between truncated M-estimators and original M-estimators. The former can adaptively select small-losses examples without knowing the noise rate and reduce the side-effects of noisy labels in them. The latter makes the possibly clean examples but with large losses involved to help generalization. Theoretically, we demonstrate that our strategies are label-noise-tolerant. Empirically, comprehensive experimental results show that our method can outperform multiple baselines and is robust to broad noise types and levels.
Short-term power load forecasting method based on CNN-SAEDN-Res
Sep 02, 2023In deep learning, the load data with non-temporal factors are difficult to process by sequence models. This problem results in insufficient precision of the prediction. Therefore, a short-term load forecasting method based on convolutional neural network (CNN), self-attention encoder-decoder network (SAEDN) and residual-refinement (Res) is proposed. In this method, feature extraction module is composed of a two-dimensional convolutional neural network, which is used to mine the local correlation between data and obtain high-dimensional data features. The initial load fore-casting module consists of a self-attention encoder-decoder network and a feedforward neural network (FFN). The module utilizes self-attention mechanisms to encode high-dimensional features. This operation can obtain the global correlation between data. Therefore, the model is able to retain important information based on the coupling relationship between the data in data mixed with non-time series factors. Then, self-attention decoding is per-formed and the feedforward neural network is used to regression initial load. This paper introduces the residual mechanism to build the load optimization module. The module generates residual load values to optimize the initial load. The simulation results show that the proposed load forecasting method has advantages in terms of prediction accuracy and prediction stability.
DVGaze: Dual-View Gaze Estimation
Aug 20, 2023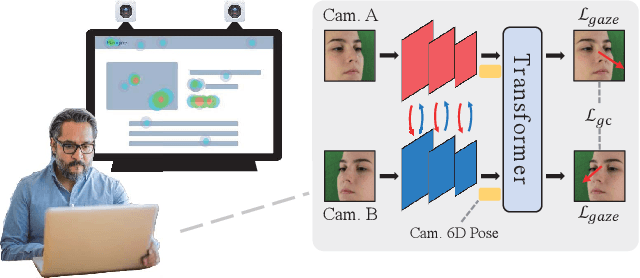
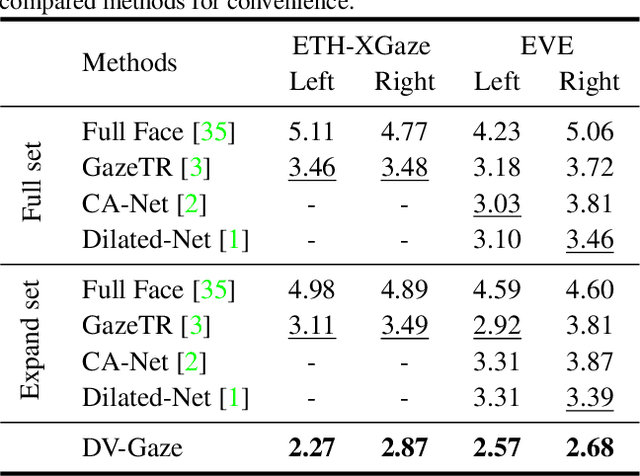
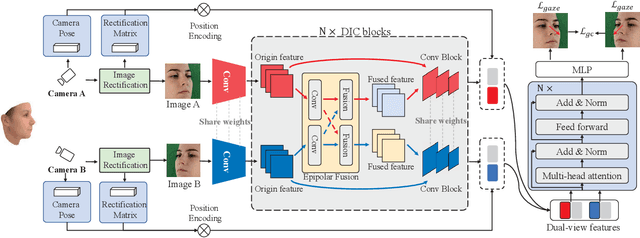
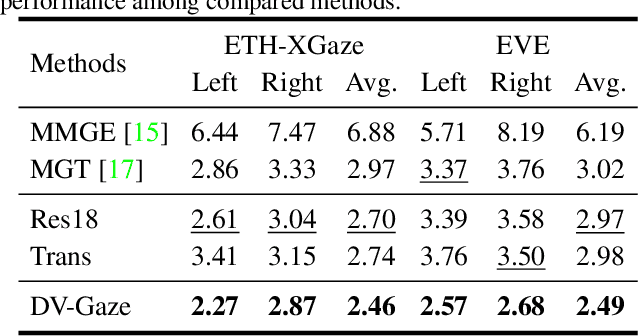
Gaze estimation methods estimate gaze from facial appearance with a single camera. However, due to the limited view of a single camera, the captured facial appearance cannot provide complete facial information and thus complicate the gaze estimation problem. Recently, camera devices are rapidly updated. Dual cameras are affordable for users and have been integrated in many devices. This development suggests that we can further improve gaze estimation performance with dual-view gaze estimation. In this paper, we propose a dual-view gaze estimation network (DV-Gaze). DV-Gaze estimates dual-view gaze directions from a pair of images. We first propose a dual-view interactive convolution (DIC) block in DV-Gaze. DIC blocks exchange dual-view information during convolution in multiple feature scales. It fuses dual-view features along epipolar lines and compensates for the original feature with the fused feature. We further propose a dual-view transformer to estimate gaze from dual-view features. Camera poses are encoded to indicate the position information in the transformer. We also consider the geometric relation between dual-view gaze directions and propose a dual-view gaze consistency loss for DV-Gaze. DV-Gaze achieves state-of-the-art performance on ETH-XGaze and EVE datasets. Our experiments also prove the potential of dual-view gaze estimation. We release codes in https://github.com/yihuacheng/DVGaze.
ADC/DAC-Free Analog Acceleration of Deep Neural Networks with Frequency Transformation
Sep 04, 2023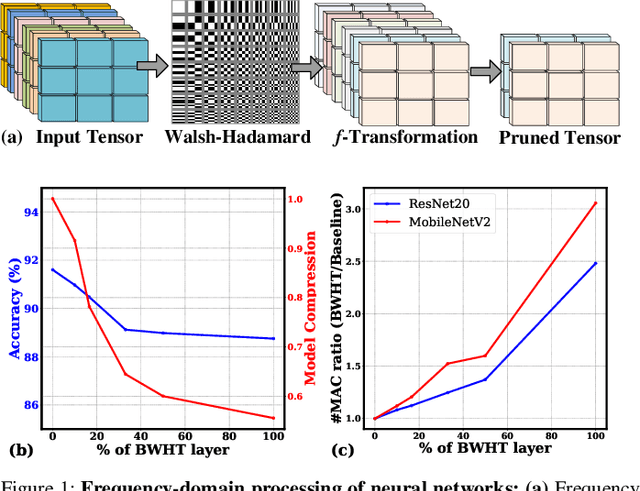
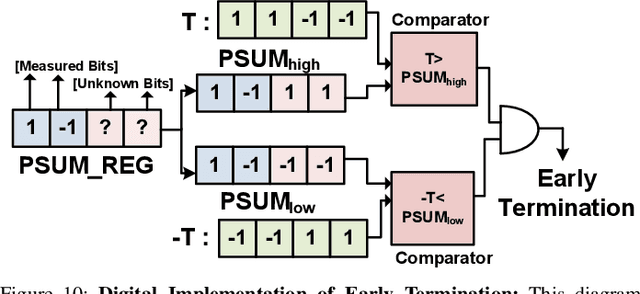
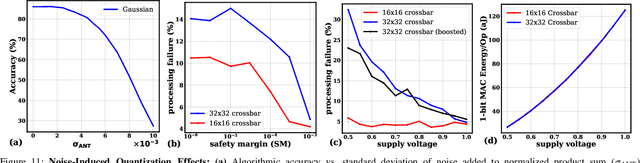
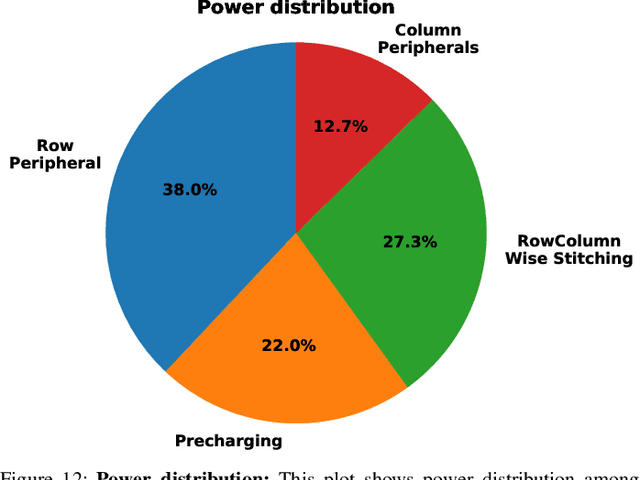
The edge processing of deep neural networks (DNNs) is becoming increasingly important due to its ability to extract valuable information directly at the data source to minimize latency and energy consumption. Frequency-domain model compression, such as with the Walsh-Hadamard transform (WHT), has been identified as an efficient alternative. However, the benefits of frequency-domain processing are often offset by the increased multiply-accumulate (MAC) operations required. This paper proposes a novel approach to an energy-efficient acceleration of frequency-domain neural networks by utilizing analog-domain frequency-based tensor transformations. Our approach offers unique opportunities to enhance computational efficiency, resulting in several high-level advantages, including array micro-architecture with parallelism, ADC/DAC-free analog computations, and increased output sparsity. Our approach achieves more compact cells by eliminating the need for trainable parameters in the transformation matrix. Moreover, our novel array micro-architecture enables adaptive stitching of cells column-wise and row-wise, thereby facilitating perfect parallelism in computations. Additionally, our scheme enables ADC/DAC-free computations by training against highly quantized matrix-vector products, leveraging the parameter-free nature of matrix multiplications. Another crucial aspect of our design is its ability to handle signed-bit processing for frequency-based transformations. This leads to increased output sparsity and reduced digitization workload. On a 16$\times$16 crossbars, for 8-bit input processing, the proposed approach achieves the energy efficiency of 1602 tera operations per second per Watt (TOPS/W) without early termination strategy and 5311 TOPS/W with early termination strategy at VDD = 0.8 V.
Distributional Domain-Invariant Preference Matching for Cross-Domain Recommendation
Sep 04, 2023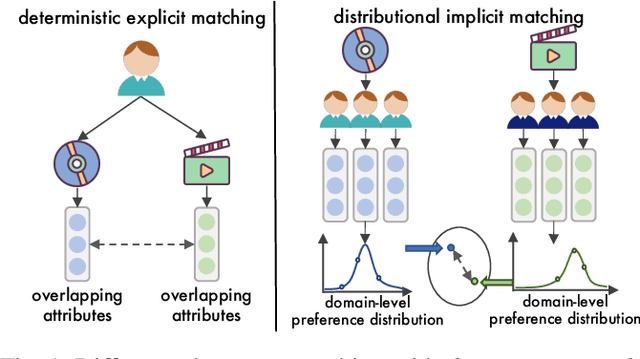
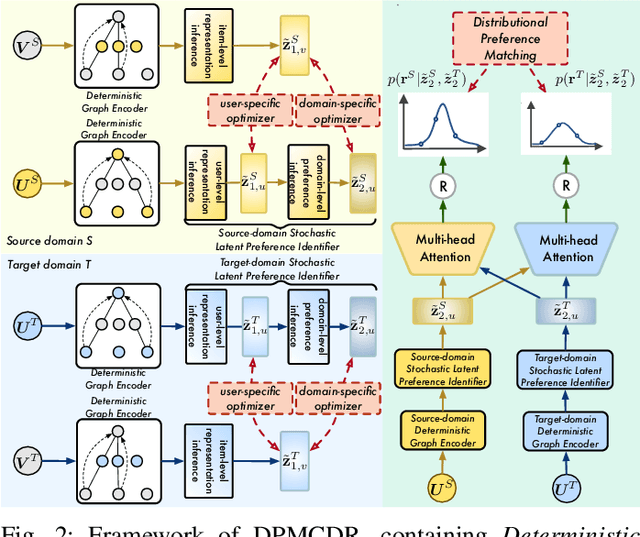
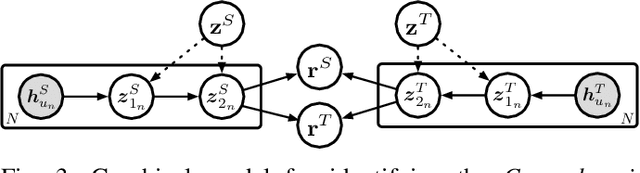
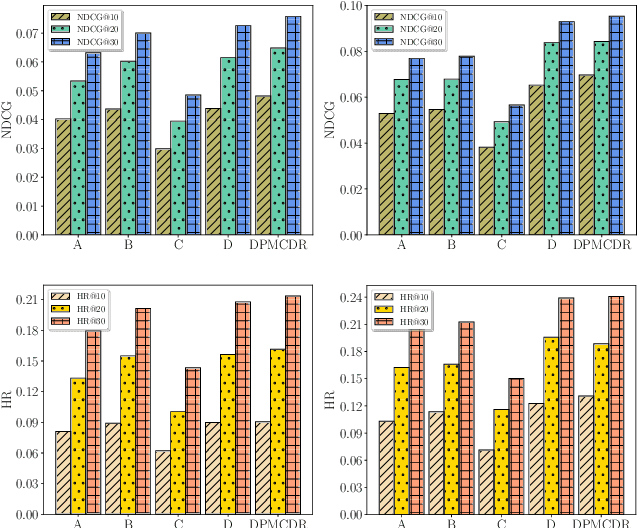
Learning accurate cross-domain preference mappings in the absence of overlapped users/items has presented a persistent challenge in Non-overlapping Cross-domain Recommendation (NOCDR). Despite the efforts made in previous studies to address NOCDR, several limitations still exist. Specifically, 1) while some approaches substitute overlapping users/items with overlapping behaviors, they cannot handle NOCDR scenarios where such auxiliary information is unavailable; 2) often, cross-domain preference mapping is modeled by learning deterministic explicit representation matchings between sampled users in two domains. However, this can be biased due to individual preferences and thus fails to incorporate preference continuity and universality of the general population. In light of this, we assume that despite the scattered nature of user behaviors, there exists a consistent latent preference distribution shared among common people. Modeling such distributions further allows us to capture the continuity in user behaviors within each domain and discover preference invariance across domains. To this end, we propose a Distributional domain-invariant Preference Matching method for non-overlapping Cross-Domain Recommendation (DPMCDR). For each domain, we hierarchically approximate a posterior of domain-level preference distribution with empirical evidence derived from user-item interactions. Next, we aim to build distributional implicit matchings between the domain-level preferences of two domains. This process involves mapping them to a shared latent space and seeking a consensus on domain-invariant preference by minimizing the distance between their distributional representations therein. In this way, we can identify the alignment of two non-overlapping domains if they exhibit similar patterns of domain-invariant preference.