 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Decomposed Guided Dynamic Filters for Efficient RGB-Guided Depth Completion
Sep 05, 2023
RGB-guided depth completion aims at predicting dense depth maps from sparse depth measurements and corresponding RGB images, where how to effectively and efficiently exploit the multi-modal information is a key issue. Guided dynamic filters, which generate spatially-variant depth-wise separable convolutional filters from RGB features to guide depth features, have been proven to be effective in this task. However, the dynamically generated filters require massive model parameters, computational costs and memory footprints when the number of feature channels is large. In this paper, we propose to decompose the guided dynamic filters into a spatially-shared component multiplied by content-adaptive adaptors at each spatial location. Based on the proposed idea, we introduce two decomposition schemes A and B, which decompose the filters by splitting the filter structure and using spatial-wise attention, respectively. The decomposed filters not only maintain the favorable properties of guided dynamic filters as being content-dependent and spatially-variant, but also reduce model parameters and hardware costs, as the learned adaptors are decoupled with the number of feature channels. Extensive experimental results demonstrate that the methods using our schemes outperform state-of-the-art methods on the KITTI dataset, and rank 1st and 2nd on the KITTI benchmark at the time of submission. Meanwhile, they also achieve comparable performance on the NYUv2 dataset. In addition, our proposed methods are general and could be employed as plug-and-play feature fusion blocks in other multi-modal fusion tasks such as RGB-D salient object detection.
Feature-Suppressed Contrast for Self-Supervised Food Pre-training
Aug 21, 2023
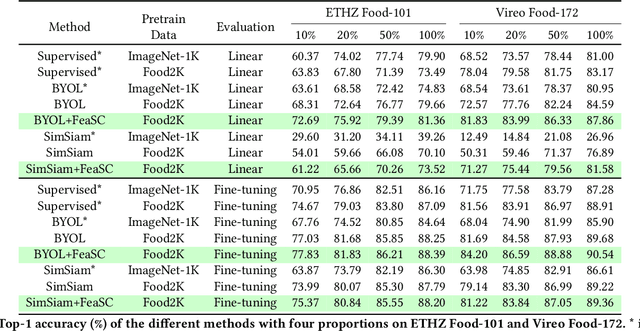

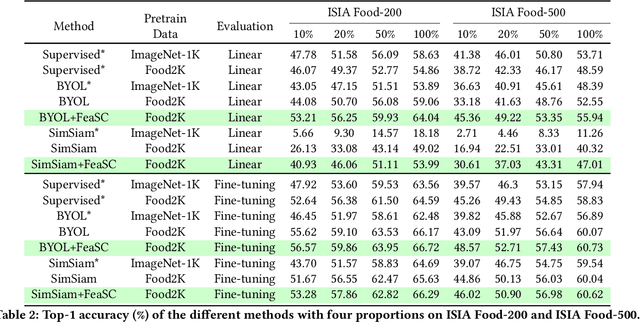
Most previous approaches for analyzing food images have relied on extensively annotated datasets, resulting in significant human labeling expenses due to the varied and intricate nature of such images. Inspired by the effectiveness of contrastive self-supervised methods in utilizing unlabelled data, weiqing explore leveraging these techniques on unlabelled food images. In contrastive self-supervised methods, two views are randomly generated from an image by data augmentations. However, regarding food images, the two views tend to contain similar informative contents, causing large mutual information, which impedes the efficacy of contrastive self-supervised learning. To address this problem, we propose Feature Suppressed Contrast (FeaSC) to reduce mutual information between views. As the similar contents of the two views are salient or highly responsive in the feature map, the proposed FeaSC uses a response-aware scheme to localize salient features in an unsupervised manner. By suppressing some salient features in one view while leaving another contrast view unchanged, the mutual information between the two views is reduced, thereby enhancing the effectiveness of contrast learning for self-supervised food pre-training. As a plug-and-play module, the proposed method consistently improves BYOL and SimSiam by 1.70\% $\sim$ 6.69\% classification accuracy on four publicly available food recognition datasets. Superior results have also been achieved on downstream segmentation tasks, demonstrating the effectiveness of the proposed method.
A Unified Framework of Graph Information Bottleneck for Robustness and Membership Privacy
Jun 14, 2023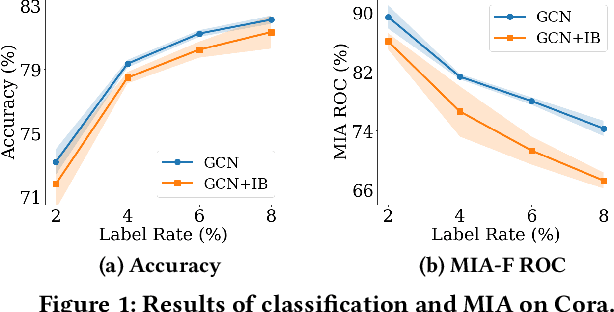
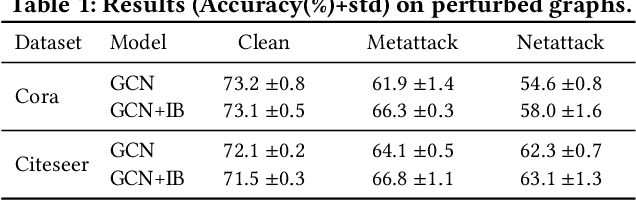
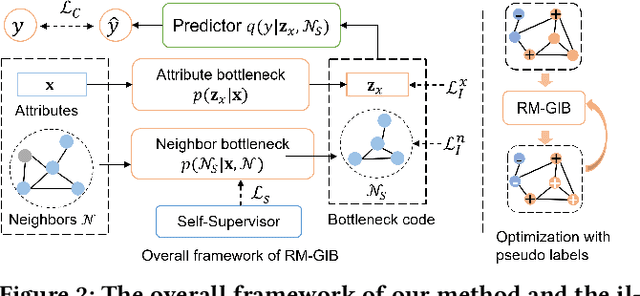
Graph Neural Networks (GNNs) have achieved great success in modeling graph-structured data. However, recent works show that GNNs are vulnerable to adversarial attacks which can fool the GNN model to make desired predictions of the attacker. In addition, training data of GNNs can be leaked under membership inference attacks. This largely hinders the adoption of GNNs in high-stake domains such as e-commerce, finance and bioinformatics. Though investigations have been made in conducting robust predictions and protecting membership privacy, they generally fail to simultaneously consider the robustness and membership privacy. Therefore, in this work, we study a novel problem of developing robust and membership privacy-preserving GNNs. Our analysis shows that Information Bottleneck (IB) can help filter out noisy information and regularize the predictions on labeled samples, which can benefit robustness and membership privacy. However, structural noises and lack of labels in node classification challenge the deployment of IB on graph-structured data. To mitigate these issues, we propose a novel graph information bottleneck framework that can alleviate structural noises with neighbor bottleneck. Pseudo labels are also incorporated in the optimization to minimize the gap between the predictions on the labeled set and unlabeled set for membership privacy. Extensive experiments on real-world datasets demonstrate that our method can give robust predictions and simultaneously preserve membership privacy.
Angle-Delay Profile-Based and Timestamp-Aided Dissimilarity Metrics for Channel Charting
Aug 18, 2023Channel charting is a self-supervised learning technique whose objective is to reconstruct a map of the radio environment, called channel chart, by taking advantage of similarity relationships in high-dimensional channel state information. We provide an overview of processing steps and evaluation methods for channel charting and propose a novel dissimilarity metric that takes into account angular-domain information as well as a novel deep learning-based metric. Furthermore, we suggest a method to fuse dissimilarity metrics such that both the time at which channels were measured as well as similarities in channel state information can be taken into consideration while learning a channel chart. By applying both classical and deep learning-based manifold learning to a dataset containing sub-6GHz distributed massive MIMO channel measurements, we show that our metrics outperform previously proposed dissimilarity measures. The results indicate that the new metrics improve channel charting performance, even under non-line-of-sight conditions.
Uncertainty-driven Affordance Discovery for Efficient Robotics Manipulation
Aug 28, 2023Robotics affordances, providing information about what actions can be taken in a given situation, can aid robotics manipulation. However, learning about affordances requires expensive large annotated datasets of interactions or demonstrations. In this work, we show active learning can mitigate this problem and propose the use of uncertainty to drive an interactive affordance discovery process. We show that our method enables the efficient discovery of visual affordances for several action primitives, such as grasping, stacking objects, or opening drawers, strongly improving data efficiency and allowing us to learn grasping affordances on a real-world setup with an xArm 6 robot arm in a small number of trials.
Bayesian artificial brain with ChatGPT
Aug 28, 2023This paper aims to investigate the mathematical problem-solving capabilities of Chat Generative Pre-Trained Transformer (ChatGPT) in case of Bayesian reasoning. The study draws inspiration from Zhu & Gigerenzer's research in 2006, which posed the question: Can children reason the Bayesian way? In the pursuit of answering this question, a set of 10 Bayesian reasoning problems were presented. The results of their work revealed that children's ability to reason effectively using Bayesian principles is contingent upon a well-structured information representation. In this paper, we present the same set of 10 Bayesian reasoning problems to ChatGPT. Remarkably, the results demonstrate that ChatGPT provides the right solutions to all problems.
Efficient Annotation for Medical Image Analysis: A One-Pass Selective Annotation Approach
Aug 25, 2023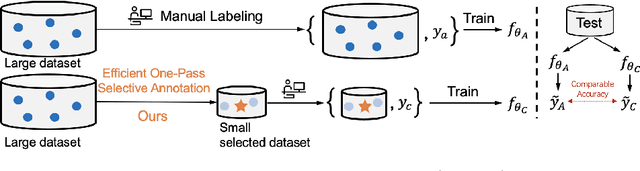
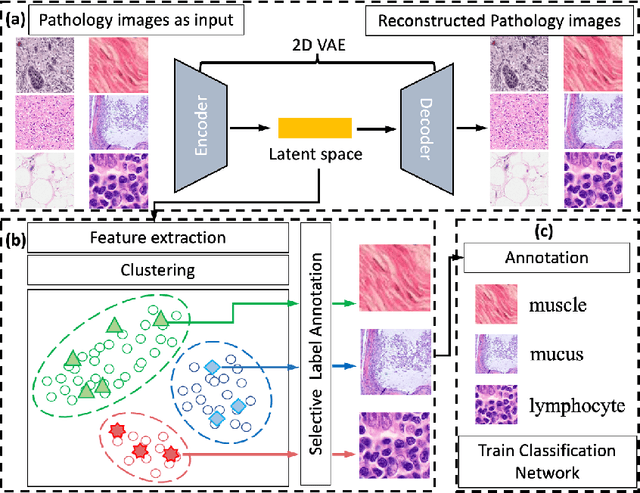
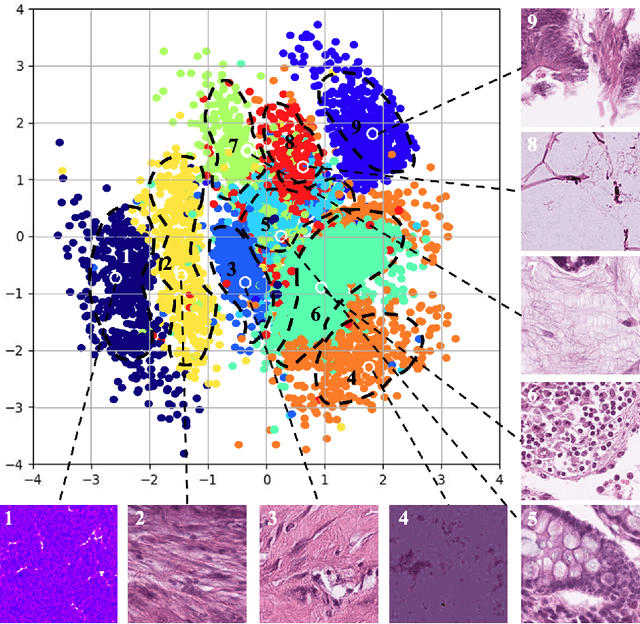
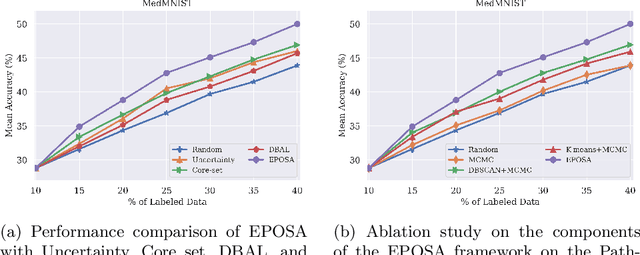
Annotating biomedical images for supervised learning is a complex and labor-intensive task due to data diversity and its intricate nature. In this paper, we propose an innovative method, the efficient one-pass selective annotation (EPOSA), that significantly reduces the annotation burden while maintaining robust model performance. Our approach employs a variational autoencoder (VAE) to extract salient features from unannotated images, which are subsequently clustered using the DBSCAN algorithm. This process groups similar images together, forming distinct clusters. We then use a two-stage sample selection algorithm, called representative selection (RepSel), to form a selected dataset. The first stage is a Markov Chain Monte Carlo (MCMC) sampling technique to select representative samples from each cluster for annotations. This selection process is the second stage, which is guided by the principle of maximizing intra-cluster mutual information and minimizing inter-cluster mutual information. This ensures a diverse set of features for model training and minimizes outlier inclusion. The selected samples are used to train a VGG-16 network for image classification. Experimental results on the Med-MNIST dataset demonstrate that our proposed EPOSA outperforms random selection and other state-of-the-art methods under the same annotation budget, presenting a promising direction for efficient and effective annotation in medical image analysis.
Generalising sequence models for epigenome predictions with tissue and assay embeddings
Aug 22, 2023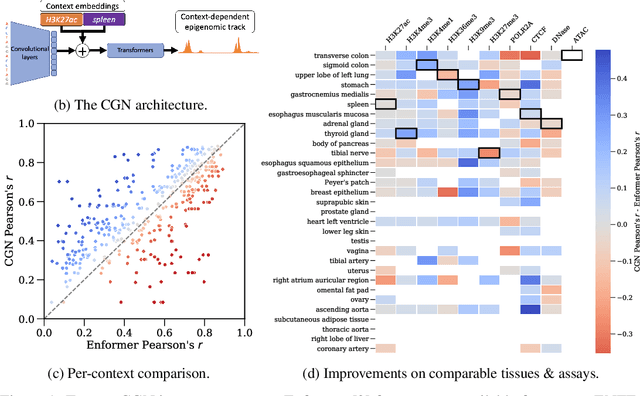


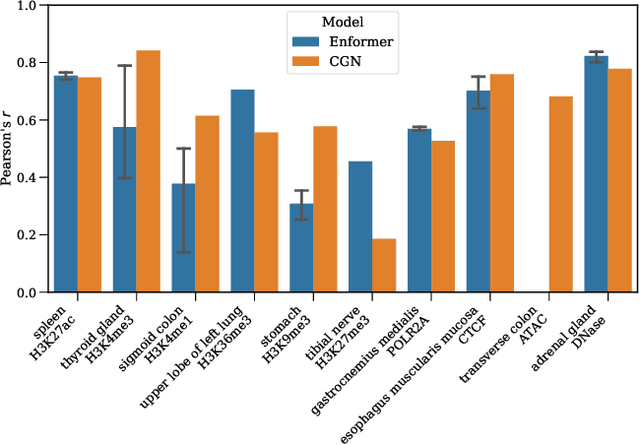
Sequence modelling approaches for epigenetic profile prediction have recently expanded in terms of sequence length, model size, and profile diversity. However, current models cannot infer on many experimentally feasible tissue and assay pairs due to poor usage of contextual information, limiting $\textit{in silico}$ understanding of regulatory genomics. We demonstrate that strong correlation can be achieved across a large range of experimental conditions by integrating tissue and assay embeddings into a Contextualised Genomic Network (CGN). In contrast to previous approaches, we enhance long-range sequence embeddings with contextual information in the input space, rather than expanding the output space. We exhibit the efficacy of our approach across a broad set of epigenetic profiles and provide the first insights into the effect of genetic variants on epigenetic sequence model training. Our general approach to context integration exceeds state of the art in multiple settings while employing a more rigorous validation procedure.
AKVSR: Audio Knowledge Empowered Visual Speech Recognition by Compressing Audio Knowledge of a Pretrained Model
Aug 15, 2023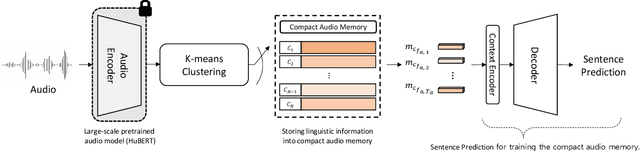
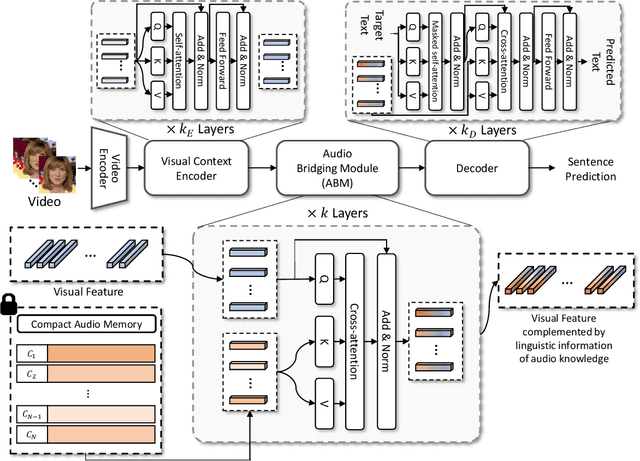
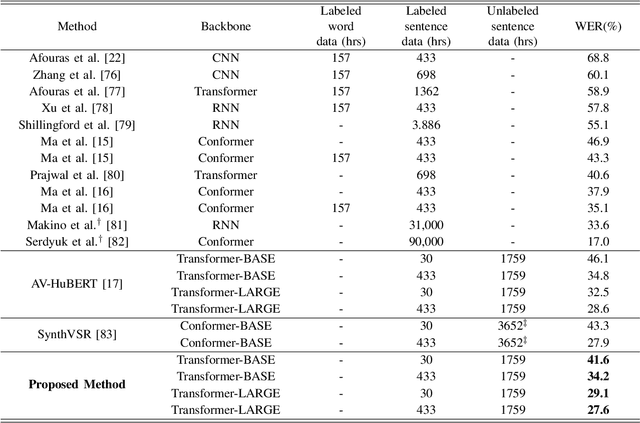
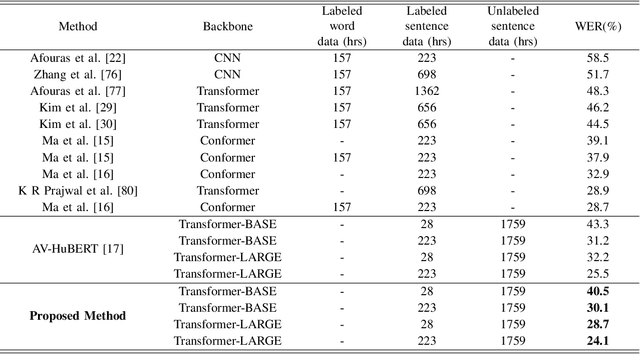
Visual Speech Recognition (VSR) is the task of predicting spoken words from silent lip movements. VSR is regarded as a challenging task because of the insufficient information on lip movements. In this paper, we propose an Audio Knowledge empowered Visual Speech Recognition framework (AKVSR) to complement the insufficient speech information of visual modality by using audio modality. Different from the previous methods, the proposed AKVSR 1) utilizes rich audio knowledge encoded by a large-scale pretrained audio model, 2) saves the linguistic information of audio knowledge in compact audio memory by discarding the non-linguistic information from the audio through quantization, and 3) includes Audio Bridging Module which can find the best-matched audio features from the compact audio memory, which makes our training possible without audio inputs, once after the compact audio memory is composed. We validate the effectiveness of the proposed method through extensive experiments, and achieve new state-of-the-art performances on the widely-used datasets, LRS2 and LRS3.
Taxonomic Loss for Morphological Glossing of Low-Resource Languages
Aug 29, 2023Morpheme glossing is a critical task in automated language documentation and can benefit other downstream applications greatly. While state-of-the-art glossing systems perform very well for languages with large amounts of existing data, it is more difficult to create useful models for low-resource languages. In this paper, we propose the use of a taxonomic loss function that exploits morphological information to make morphological glossing more performant when data is scarce. We find that while the use of this loss function does not outperform a standard loss function with regards to single-label prediction accuracy, it produces better predictions when considering the top-n predicted labels. We suggest this property makes the taxonomic loss function useful in a human-in-the-loop annotation setting.