 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Artificial intelligence is ineffective and potentially harmful for fact checking
Sep 01, 2023


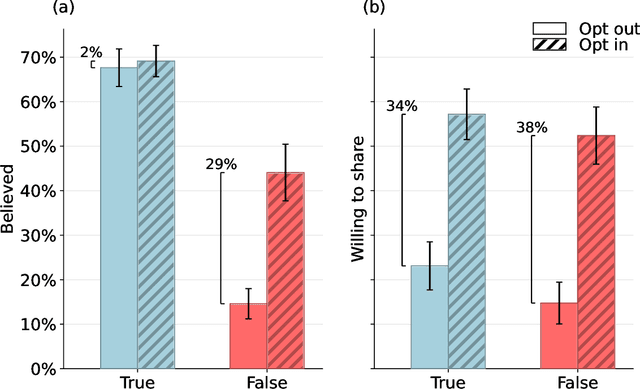
Fact checking can be an effective strategy against misinformation, but its implementation at scale is impeded by the overwhelming volume of information online. Recent artificial intelligence (AI) language models have shown impressive ability in fact-checking tasks, but how humans interact with fact-checking information provided by these models is unclear. Here we investigate the impact of fact checks generated by a popular AI model on belief in, and sharing intent of, political news in a preregistered randomized control experiment. Although the AI performs reasonably well in debunking false headlines, we find that it does not significantly affect participants' ability to discern headline accuracy or share accurate news. However, the AI fact-checker is harmful in specific cases: it decreases beliefs in true headlines that it mislabels as false and increases beliefs for false headlines that it is unsure about. On the positive side, the AI increases sharing intents for correctly labeled true headlines. When participants are given the option to view AI fact checks and choose to do so, they are significantly more likely to share both true and false news but only more likely to believe false news. Our findings highlight an important source of potential harm stemming from AI applications and underscore the critical need for policies to prevent or mitigate such unintended consequences.
FactLLaMA: Optimizing Instruction-Following Language Models with External Knowledge for Automated Fact-Checking
Sep 01, 2023Automatic fact-checking plays a crucial role in combating the spread of misinformation. Large Language Models (LLMs) and Instruction-Following variants, such as InstructGPT and Alpaca, have shown remarkable performance in various natural language processing tasks. However, their knowledge may not always be up-to-date or sufficient, potentially leading to inaccuracies in fact-checking. To address this limitation, we propose combining the power of instruction-following language models with external evidence retrieval to enhance fact-checking performance. Our approach involves leveraging search engines to retrieve relevant evidence for a given input claim. This external evidence serves as valuable supplementary information to augment the knowledge of the pretrained language model. Then, we instruct-tune an open-sourced language model, called LLaMA, using this evidence, enabling it to predict the veracity of the input claim more accurately. To evaluate our method, we conducted experiments on two widely used fact-checking datasets: RAWFC and LIAR. The results demonstrate that our approach achieves state-of-the-art performance in fact-checking tasks. By integrating external evidence, we bridge the gap between the model's knowledge and the most up-to-date and sufficient context available, leading to improved fact-checking outcomes. Our findings have implications for combating misinformation and promoting the dissemination of accurate information on online platforms. Our released materials are accessible at: https://thcheung.github.io/factllama.
Human trajectory prediction using LSTM with Attention mechanism
Sep 01, 2023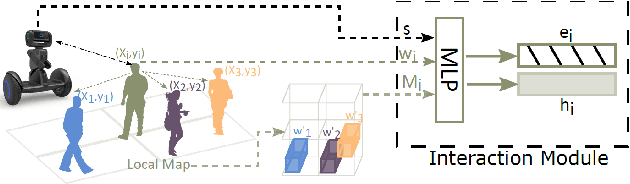
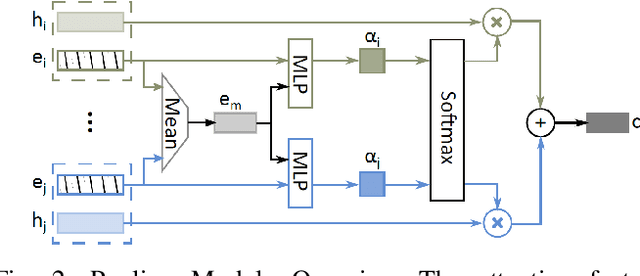
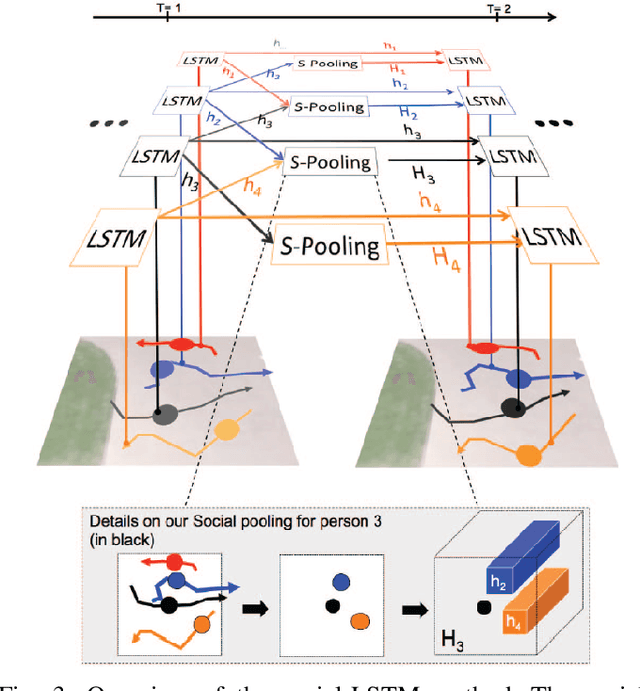
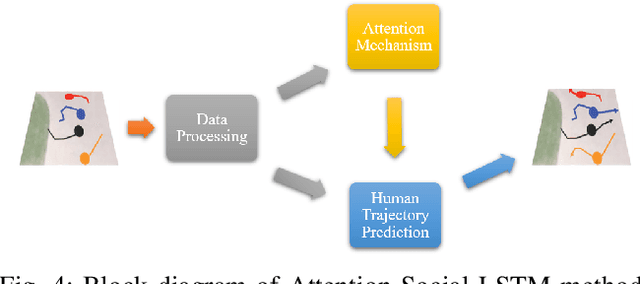
In this paper, we propose a human trajectory prediction model that combines a Long Short-Term Memory (LSTM) network with an attention mechanism. To do that, we use attention scores to determine which parts of the input data the model should focus on when making predictions. Attention scores are calculated for each input feature, with a higher score indicating the greater significance of that feature in predicting the output. Initially, these scores are determined for the target human position, velocity, and their neighboring individual's positions and velocities. By using attention scores, our model can prioritize the most relevant information in the input data and make more accurate predictions. We extract attention scores from our attention mechanism and integrate them into the trajectory prediction module to predict human future trajectories. To achieve this, we introduce a new neural layer that processes attention scores after extracting them and concatenates them with positional information. We evaluate our approach on the publicly available ETH and UCY datasets and measure its performance using the final displacement error (FDE) and average displacement error (ADE) metrics. We show that our modified algorithm performs better than the Social LSTM in predicting the future trajectory of pedestrians in crowded spaces. Specifically, our model achieves an improvement of 6.2% in ADE and 6.3% in FDE compared to the Social LSTM results in the literature.
Trust your Good Friends: Source-free Domain Adaptation by Reciprocal Neighborhood Clustering
Sep 01, 2023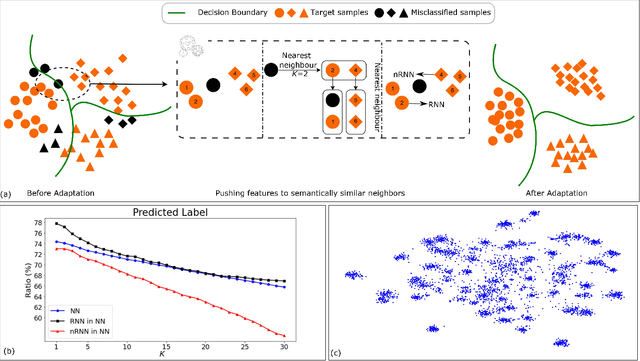
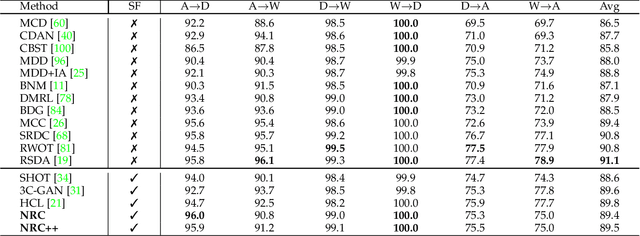
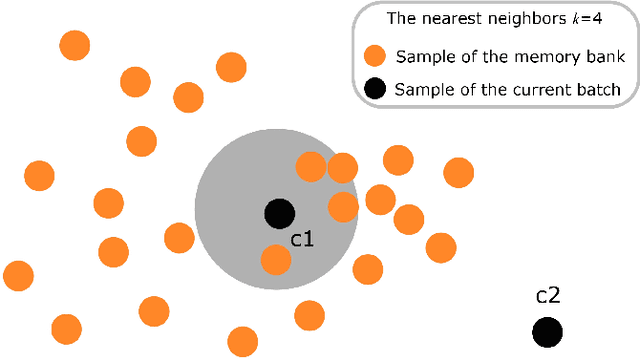
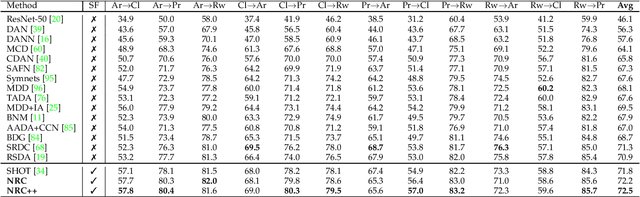
Domain adaptation (DA) aims to alleviate the domain shift between source domain and target domain. Most DA methods require access to the source data, but often that is not possible (e.g. due to data privacy or intellectual property). In this paper, we address the challenging source-free domain adaptation (SFDA) problem, where the source pretrained model is adapted to the target domain in the absence of source data. Our method is based on the observation that target data, which might not align with the source domain classifier, still forms clear clusters. We capture this intrinsic structure by defining local affinity of the target data, and encourage label consistency among data with high local affinity. We observe that higher affinity should be assigned to reciprocal neighbors. To aggregate information with more context, we consider expanded neighborhoods with small affinity values. Furthermore, we consider the density around each target sample, which can alleviate the negative impact of potential outliers. In the experimental results we verify that the inherent structure of the target features is an important source of information for domain adaptation. We demonstrate that this local structure can be efficiently captured by considering the local neighbors, the reciprocal neighbors, and the expanded neighborhood. Finally, we achieve state-of-the-art performance on several 2D image and 3D point cloud recognition datasets.
Motion Compensated Unsupervised Deep Learning for 5D MRI
Sep 08, 2023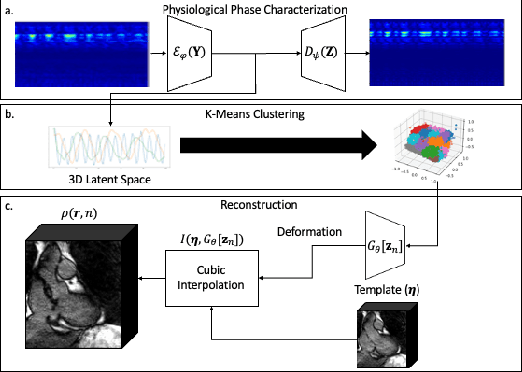
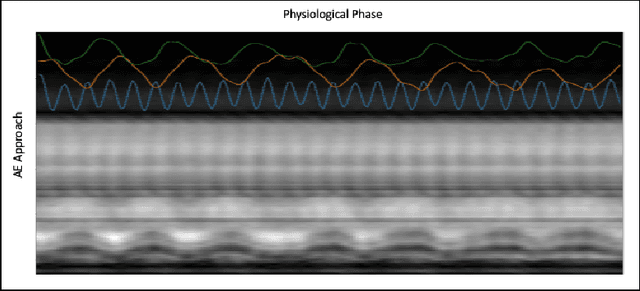
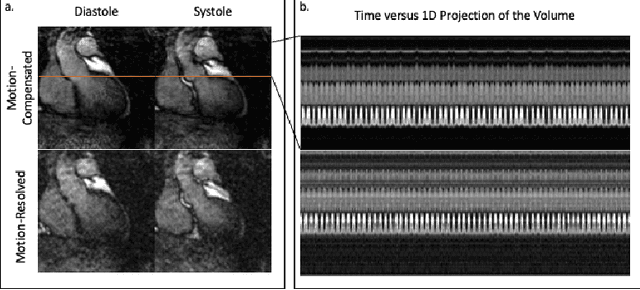
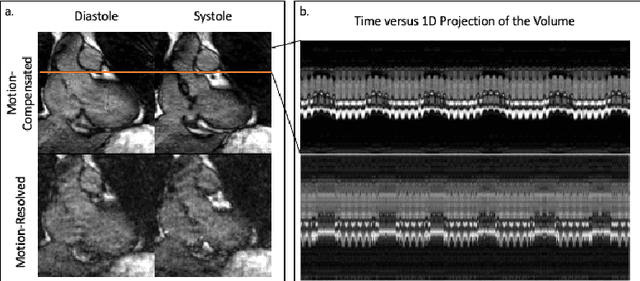
We propose an unsupervised deep learning algorithm for the motion-compensated reconstruction of 5D cardiac MRI data from 3D radial acquisitions. Ungated free-breathing 5D MRI simplifies the scan planning, improves patient comfort, and offers several clinical benefits over breath-held 2D exams, including isotropic spatial resolution and the ability to reslice the data to arbitrary views. However, the current reconstruction algorithms for 5D MRI take very long computational time, and their outcome is greatly dependent on the uniformity of the binning of the acquired data into different physiological phases. The proposed algorithm is a more data-efficient alternative to current motion-resolved reconstructions. This motion-compensated approach models the data in each cardiac/respiratory bin as Fourier samples of the deformed version of a 3D image template. The deformation maps are modeled by a convolutional neural network driven by the physiological phase information. The deformation maps and the template are then jointly estimated from the measured data. The cardiac and respiratory phases are estimated from 1D navigators using an auto-encoder. The proposed algorithm is validated on 5D bSSFP datasets acquired from two subjects.
Postprocessing of Ensemble Weather Forecasts Using Permutation-invariant Neural Networks
Sep 08, 2023Statistical postprocessing is used to translate ensembles of raw numerical weather forecasts into reliable probabilistic forecast distributions. In this study, we examine the use of permutation-invariant neural networks for this task. In contrast to previous approaches, which often operate on ensemble summary statistics and dismiss details of the ensemble distribution, we propose networks which treat forecast ensembles as a set of unordered member forecasts and learn link functions that are by design invariant to permutations of the member ordering. We evaluate the quality of the obtained forecast distributions in terms of calibration and sharpness, and compare the models against classical and neural network-based benchmark methods. In case studies addressing the postprocessing of surface temperature and wind gust forecasts, we demonstrate state-of-the-art prediction quality. To deepen the understanding of the learned inference process, we further propose a permutation-based importance analysis for ensemble-valued predictors, which highlights specific aspects of the ensemble forecast that are considered important by the trained postprocessing models. Our results suggest that most of the relevant information is contained in few ensemble-internal degrees of freedom, which may impact the design of future ensemble forecasting and postprocessing systems.
Emergent learning in physical systems as feedback-based aging in a glassy landscape
Sep 08, 2023By training linear physical networks to learn linear transformations, we discern how their physical properties evolve due to weight update rules. Our findings highlight a striking similarity between the learning behaviors of such networks and the processes of aging and memory formation in disordered and glassy systems. We show that the learning dynamics resembles an aging process, where the system relaxes in response to repeated application of the feedback boundary forces in presence of an input force, thus encoding a memory of the input-output relationship. With this relaxation comes an increase in the correlation length, which is indicated by the two-point correlation function for the components of the network. We also observe that the square root of the mean-squared error as a function of epoch takes on a non-exponential form, which is a typical feature of glassy systems. This physical interpretation suggests that by encoding more detailed information into input and feedback boundary forces, the process of emergent learning can be rather ubiquitous and, thus, serve as a very early physical mechanism, from an evolutionary standpoint, for learning in biological systems.
Mobile V-MoEs: Scaling Down Vision Transformers via Sparse Mixture-of-Experts
Sep 08, 2023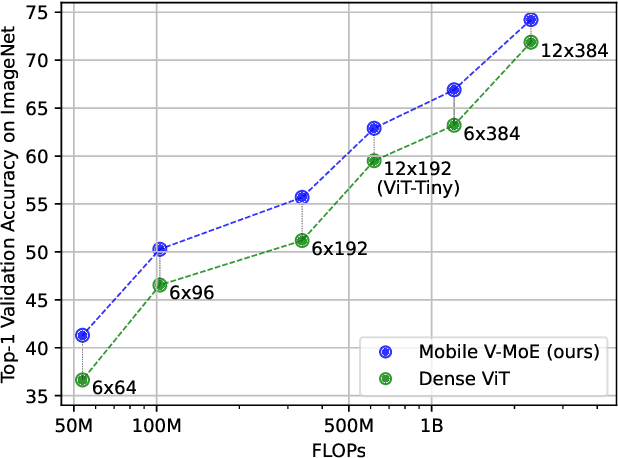

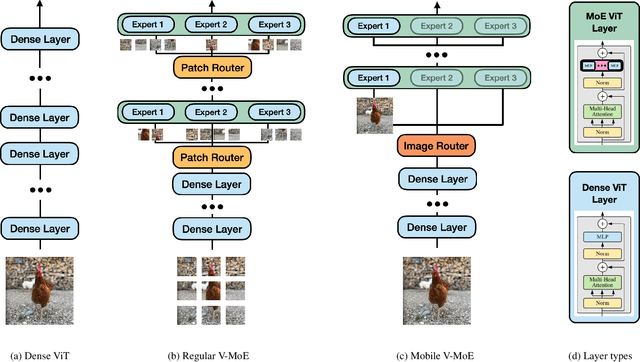
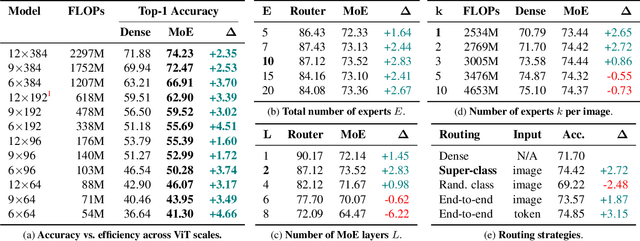
Sparse Mixture-of-Experts models (MoEs) have recently gained popularity due to their ability to decouple model size from inference efficiency by only activating a small subset of the model parameters for any given input token. As such, sparse MoEs have enabled unprecedented scalability, resulting in tremendous successes across domains such as natural language processing and computer vision. In this work, we instead explore the use of sparse MoEs to scale-down Vision Transformers (ViTs) to make them more attractive for resource-constrained vision applications. To this end, we propose a simplified and mobile-friendly MoE design where entire images rather than individual patches are routed to the experts. We also propose a stable MoE training procedure that uses super-class information to guide the router. We empirically show that our sparse Mobile Vision MoEs (V-MoEs) can achieve a better trade-off between performance and efficiency than the corresponding dense ViTs. For example, for the ViT-Tiny model, our Mobile V-MoE outperforms its dense counterpart by 3.39% on ImageNet-1k. For an even smaller ViT variant with only 54M FLOPs inference cost, our MoE achieves an improvement of 4.66%.
Federated Learning for Early Dropout Prediction on Healthy Ageing Applications
Sep 08, 2023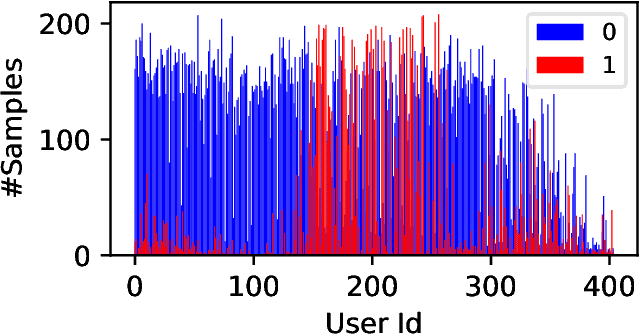
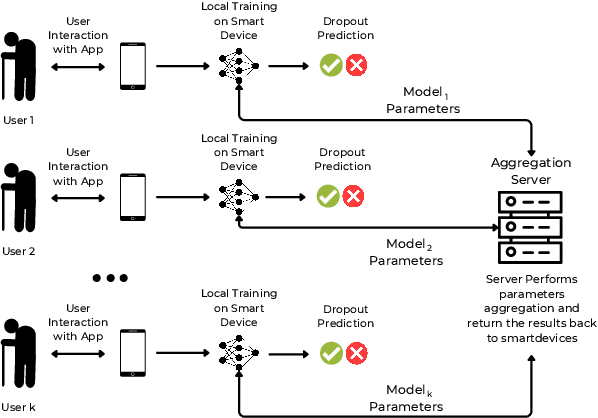
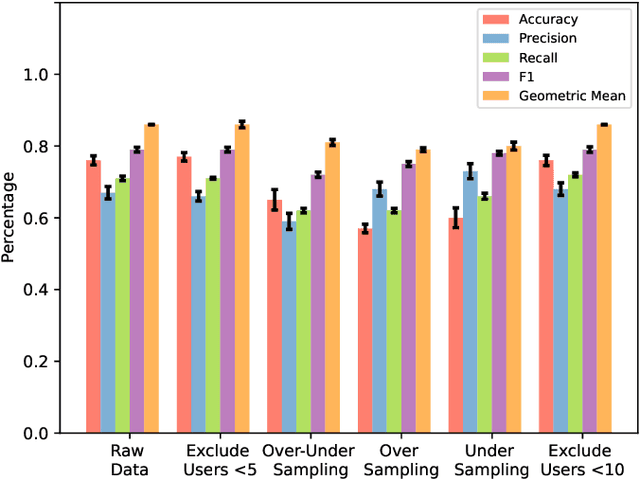
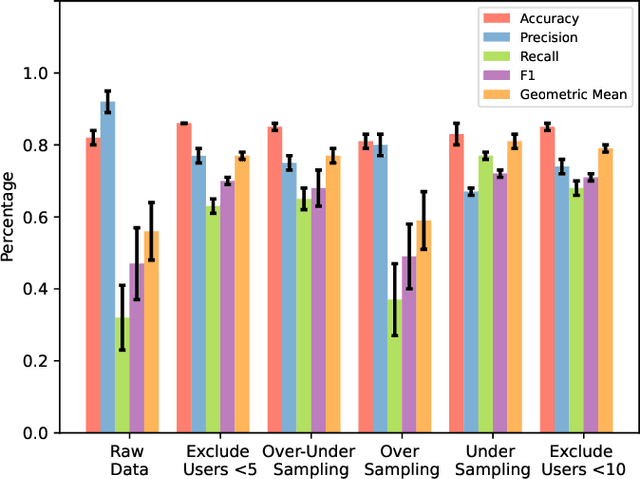
The provision of social care applications is crucial for elderly people to improve their quality of life and enables operators to provide early interventions. Accurate predictions of user dropouts in healthy ageing applications are essential since they are directly related to individual health statuses. Machine Learning (ML) algorithms have enabled highly accurate predictions, outperforming traditional statistical methods that struggle to cope with individual patterns. However, ML requires a substantial amount of data for training, which is challenging due to the presence of personal identifiable information (PII) and the fragmentation posed by regulations. In this paper, we present a federated machine learning (FML) approach that minimizes privacy concerns and enables distributed training, without transferring individual data. We employ collaborative training by considering individuals and organizations under FML, which models both cross-device and cross-silo learning scenarios. Our approach is evaluated on a real-world dataset with non-independent and identically distributed (non-iid) data among clients, class imbalance and label ambiguity. Our results show that data selection and class imbalance handling techniques significantly improve the predictive accuracy of models trained under FML, demonstrating comparable or superior predictive performance than traditional ML models.
Grouping Boundary Proposals for Fast Interactive Image Segmentation
Sep 08, 2023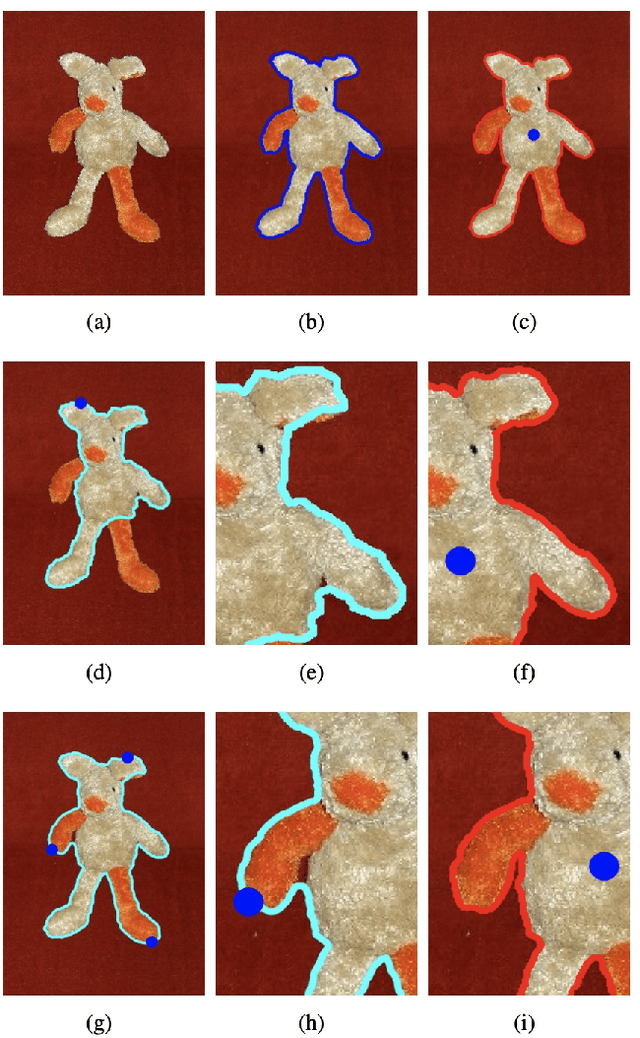
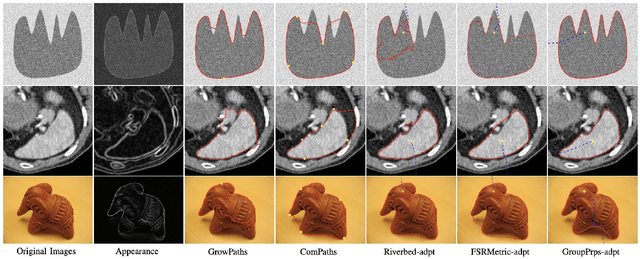

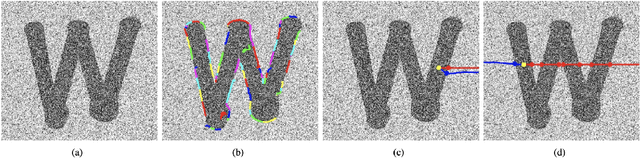
Geodesic models are known as an efficient tool for solving various image segmentation problems. Most of existing approaches only exploit local pointwise image features to track geodesic paths for delineating the objective boundaries. However, such a segmentation strategy cannot take into account the connectivity of the image edge features, increasing the risk of shortcut problem, especially in the case of complicated scenario. In this work, we introduce a new image segmentation model based on the minimal geodesic framework in conjunction with an adaptive cut-based circular optimal path computation scheme and a graph-based boundary proposals grouping scheme. Specifically, the adaptive cut can disconnect the image domain such that the target contours are imposed to pass through this cut only once. The boundary proposals are comprised of precomputed image edge segments, providing the connectivity information for our segmentation model. These boundary proposals are then incorporated into the proposed image segmentation model, such that the target segmentation contours are made up of a set of selected boundary proposals and the corresponding geodesic paths linking them. Experimental results show that the proposed model indeed outperforms state-of-the-art minimal paths-based image segmentation approaches.