 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Why do universal adversarial attacks work on large language models?: Geometry might be the answer
Sep 01, 2023
Transformer based large language models with emergent capabilities are becoming increasingly ubiquitous in society. However, the task of understanding and interpreting their internal workings, in the context of adversarial attacks, remains largely unsolved. Gradient-based universal adversarial attacks have been shown to be highly effective on large language models and potentially dangerous due to their input-agnostic nature. This work presents a novel geometric perspective explaining universal adversarial attacks on large language models. By attacking the 117M parameter GPT-2 model, we find evidence indicating that universal adversarial triggers could be embedding vectors which merely approximate the semantic information in their adversarial training region. This hypothesis is supported by white-box model analysis comprising dimensionality reduction and similarity measurement of hidden representations. We believe this new geometric perspective on the underlying mechanism driving universal attacks could help us gain deeper insight into the internal workings and failure modes of LLMs, thus enabling their mitigation.
Affine-Transformation-Invariant Image Classification by Differentiable Arithmetic Distribution Module
Sep 01, 2023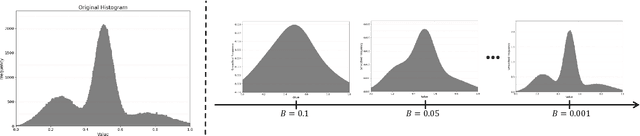
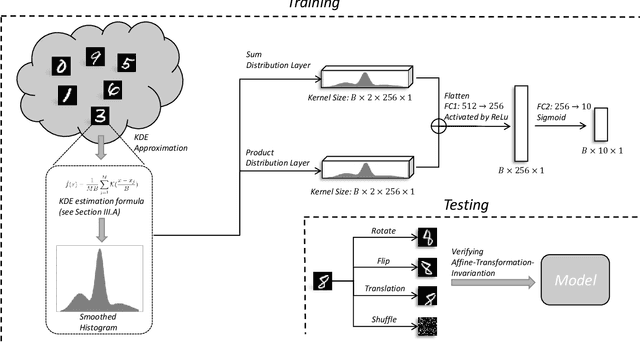
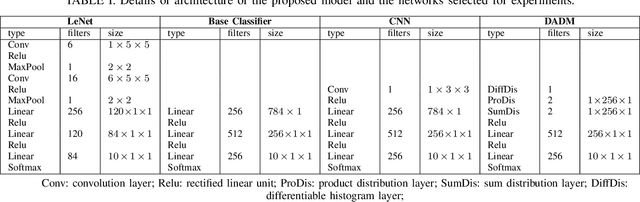

Although Convolutional Neural Networks (CNNs) have achieved promising results in image classification, they still are vulnerable to affine transformations including rotation, translation, flip and shuffle. The drawback motivates us to design a module which can alleviate the impact from different affine transformations. Thus, in this work, we introduce a more robust substitute by incorporating distribution learning techniques, focusing particularly on learning the spatial distribution information of pixels in images. To rectify the issue of non-differentiability of prior distribution learning methods that rely on traditional histograms, we adopt the Kernel Density Estimation (KDE) to formulate differentiable histograms. On this foundation, we present a novel Differentiable Arithmetic Distribution Module (DADM), which is designed to extract the intrinsic probability distributions from images. The proposed approach is able to enhance the model's robustness to affine transformations without sacrificing its feature extraction capabilities, thus bridging the gap between traditional CNNs and distribution-based learning. We validate the effectiveness of the proposed approach through ablation study and comparative experiments with LeNet.
Graph Neural Network-Enhanced Expectation Propagation Algorithm for MIMO Turbo Receivers
Aug 22, 2023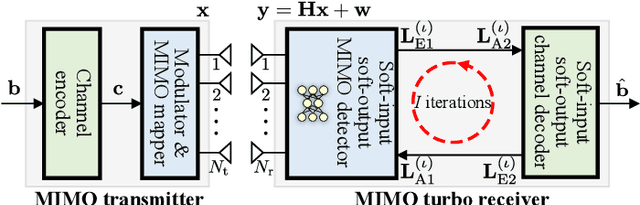
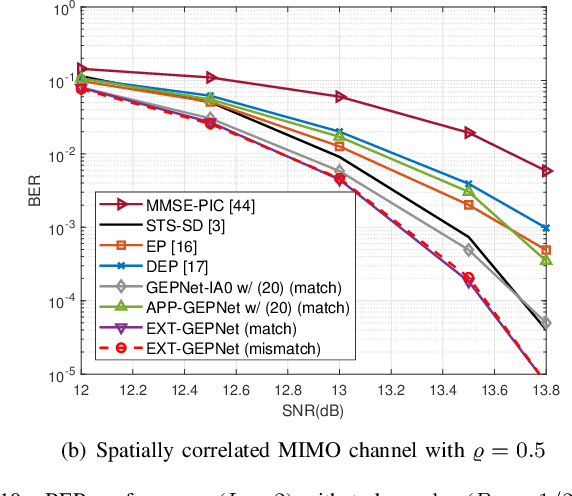
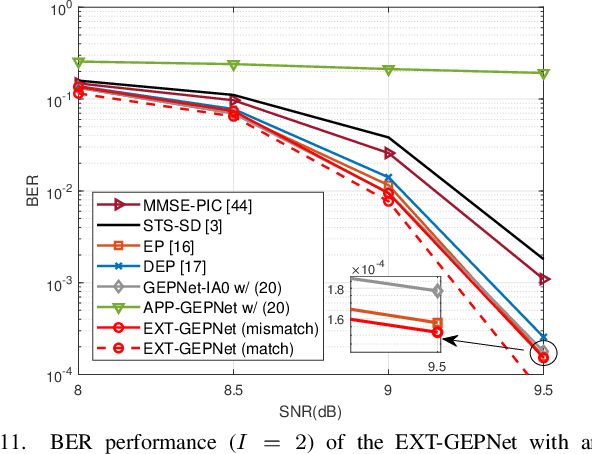
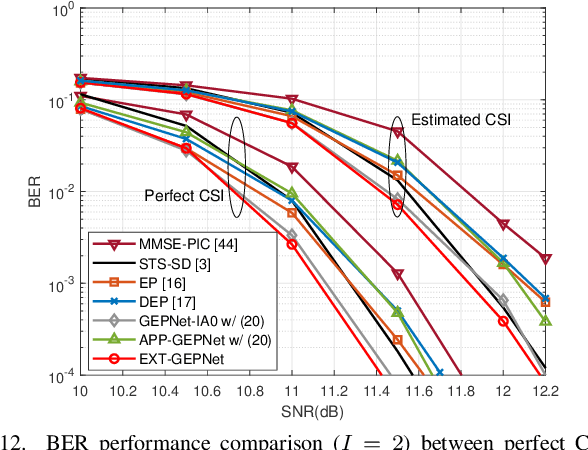
Deep neural networks (NNs) are considered a powerful tool for balancing the performance and complexity of multiple-input multiple-output (MIMO) receivers due to their accurate feature extraction, high parallelism, and excellent inference ability. Graph NNs (GNNs) have recently demonstrated outstanding capability in learning enhanced message passing rules and have shown success in overcoming the drawback of inaccurate Gaussian approximation of expectation propagation (EP)-based MIMO detectors. However, the application of the GNN-enhanced EP detector to MIMO turbo receivers is underexplored and non-trivial due to the requirement of extrinsic information for iterative processing. This paper proposes a GNN-enhanced EP algorithm for MIMO turbo receivers, which realizes the turbo principle of generating extrinsic information from the MIMO detector through a specially designed training procedure. Additionally, an edge pruning strategy is designed to eliminate redundant connections in the original fully connected model of the GNN utilizing the correlation information inherently from the EP algorithm. Edge pruning reduces the computational cost dramatically and enables the network to focus more attention on the weights that are vital for performance. Simulation results and complexity analysis indicate that the proposed MIMO turbo receiver outperforms the EP turbo approaches by over 1 dB at the bit error rate of $10^{-5}$, exhibits performance equivalent to state-of-the-art receivers with 2.5 times shorter running time, and adapts to various scenarios.
MCM: Multi-condition Motion Synthesis Framework for Multi-scenario
Sep 06, 2023The objective of the multi-condition human motion synthesis task is to incorporate diverse conditional inputs, encompassing various forms like text, music, speech, and more. This endows the task with the capability to adapt across multiple scenarios, ranging from text-to-motion and music-to-dance, among others. While existing research has primarily focused on single conditions, the multi-condition human motion generation remains underexplored. In this paper, we address these challenges by introducing MCM, a novel paradigm for motion synthesis that spans multiple scenarios under diverse conditions. The MCM framework is able to integrate with any DDPM-like diffusion model to accommodate multi-conditional information input while preserving its generative capabilities. Specifically, MCM employs two-branch architecture consisting of a main branch and a control branch. The control branch shares the same structure as the main branch and is initialized with the parameters of the main branch, effectively maintaining the generation ability of the main branch and supporting multi-condition input. We also introduce a Transformer-based diffusion model MWNet (DDPM-like) as our main branch that can capture the spatial complexity and inter-joint correlations in motion sequences through a channel-dimension self-attention module. Quantitative comparisons demonstrate that our approach achieves SoTA results in both text-to-motion and competitive results in music-to-dance tasks, comparable to task-specific methods. Furthermore, the qualitative evaluation shows that MCM not only streamlines the adaptation of methodologies originally designed for text-to-motion tasks to domains like music-to-dance and speech-to-gesture, eliminating the need for extensive network re-configurations but also enables effective multi-condition modal control, realizing "once trained is motion need".
Towards Unsupervised Graph Completion Learning on Graphs with Features and Structure Missing
Sep 06, 2023In recent years, graph neural networks (GNN) have achieved significant developments in a variety of graph analytical tasks. Nevertheless, GNN's superior performance will suffer from serious damage when the collected node features or structure relationships are partially missing owning to numerous unpredictable factors. Recently emerged graph completion learning (GCL) has received increasing attention, which aims to reconstruct the missing node features or structure relationships under the guidance of a specifically supervised task. Although these proposed GCL methods have made great success, they still exist the following problems: the reliance on labels, the bias of the reconstructed node features and structure relationships. Besides, the generalization ability of the existing GCL still faces a huge challenge when both collected node features and structure relationships are partially missing at the same time. To solve the above issues, we propose a more general GCL framework with the aid of self-supervised learning for improving the task performance of the existing GNN variants on graphs with features and structure missing, termed unsupervised GCL (UGCL). Specifically, to avoid the mismatch between missing node features and structure during the message-passing process of GNN, we separate the feature reconstruction and structure reconstruction and design its personalized model in turn. Then, a dual contrastive loss on the structure level and feature level is introduced to maximize the mutual information of node representations from feature reconstructing and structure reconstructing paths for providing more supervision signals. Finally, the reconstructed node features and structure can be applied to the downstream node classification task. Extensive experiments on eight datasets, three GNN variants and five missing rates demonstrate the effectiveness of our proposed method.
Homological Convolutional Neural Networks
Aug 26, 2023Deep learning methods have demonstrated outstanding performances on classification and regression tasks on homogeneous data types (e.g., image, audio, and text data). However, tabular data still poses a challenge with classic machine learning approaches being often computationally cheaper and equally effective than increasingly complex deep learning architectures. The challenge arises from the fact that, in tabular data, the correlation among features is weaker than the one from spatial or semantic relationships in images or natural languages, and the dependency structures need to be modeled without any prior information. In this work, we propose a novel deep learning architecture that exploits the data structural organization through topologically constrained network representations to gain spatial information from sparse tabular data. The resulting model leverages the power of convolutions and is centered on a limited number of concepts from network topology to guarantee (i) a data-centric, deterministic building pipeline; (ii) a high level of interpretability over the inference process; and (iii) an adequate room for scalability. We test our model on 18 benchmark datasets against 5 classic machine learning and 3 deep learning models demonstrating that our approach reaches state-of-the-art performances on these challenging datasets. The code to reproduce all our experiments is provided at https://github.com/FinancialComputingUCL/HomologicalCNN.
Video and Audio are Images: A Cross-Modal Mixer for Original Data on Video-Audio Retrieval
Aug 26, 2023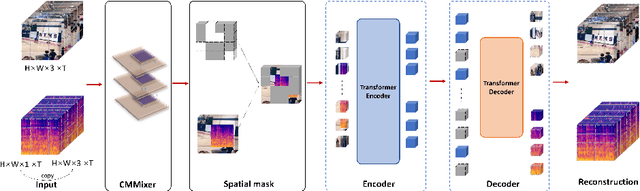
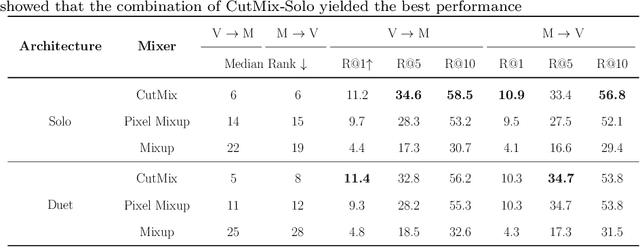

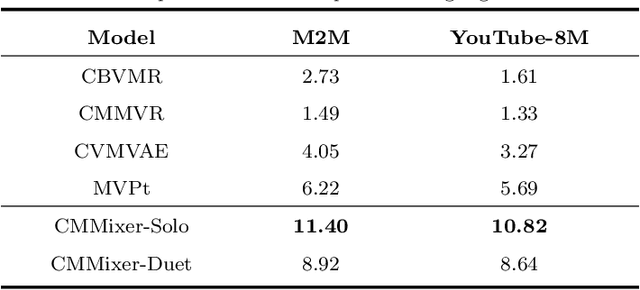
Cross-modal retrieval has become popular in recent years, particularly with the rise of multimedia. Generally, the information from each modality exhibits distinct representations and semantic information, which makes feature tends to be in separate latent spaces encoded with dual-tower architecture and makes it difficult to establish semantic relationships between modalities, resulting in poor retrieval performance. To address this issue, we propose a novel framework for cross-modal retrieval which consists of a cross-modal mixer, a masked autoencoder for pre-training, and a cross-modal retriever for downstream tasks.In specific, we first adopt cross-modal mixer and mask modeling to fuse the original modality and eliminate redundancy. Then, an encoder-decoder architecture is applied to achieve a fuse-then-separate task in the pre-training phase.We feed masked fused representations into the encoder and reconstruct them with the decoder, ultimately separating the original data of two modalities. In downstream tasks, we use the pre-trained encoder to build the cross-modal retrieval method. Extensive experiments on 2 real-world datasets show that our approach outperforms previous state-of-the-art methods in video-audio matching tasks, improving retrieval accuracy by up to 2 times. Furthermore, we prove our model performance by transferring it to other downstream tasks as a universal model.
SA6D: Self-Adaptive Few-Shot 6D Pose Estimator for Novel and Occluded Objects
Aug 31, 2023To enable meaningful robotic manipulation of objects in the real-world, 6D pose estimation is one of the critical aspects. Most existing approaches have difficulties to extend predictions to scenarios where novel object instances are continuously introduced, especially with heavy occlusions. In this work, we propose a few-shot pose estimation (FSPE) approach called SA6D, which uses a self-adaptive segmentation module to identify the novel target object and construct a point cloud model of the target object using only a small number of cluttered reference images. Unlike existing methods, SA6D does not require object-centric reference images or any additional object information, making it a more generalizable and scalable solution across categories. We evaluate SA6D on real-world tabletop object datasets and demonstrate that SA6D outperforms existing FSPE methods, particularly in cluttered scenes with occlusions, while requiring fewer reference images.
Pose-Graph Attentional Graph Neural Network for Lidar Place Recognition
Aug 31, 2023This paper proposes a lidar place recognition approach, called P-GAT, to increase the receptive field between point clouds captured over time. Instead of comparing pairs of point clouds, we compare the similarity between sets of point clouds to use the maximum spatial and temporal information between neighbour clouds utilising the concept of pose-graph SLAM. Leveraging intra- and inter-attention and graph neural network, P-GAT relates point clouds captured in nearby locations in Euclidean space and their embeddings in feature space. Experimental results on the large-scale publically available datasets demonstrate the effectiveness of our approach in recognising scenes lacking distinct features and when training and testing environments have different distributions (domain adaptation). Further, an exhaustive comparison with the state-of-the-art shows improvements in performance gains. Code will be available upon acceptance.
Contrastive Representation Learning Based on Multiple Node-centered Subgraphs
Aug 31, 2023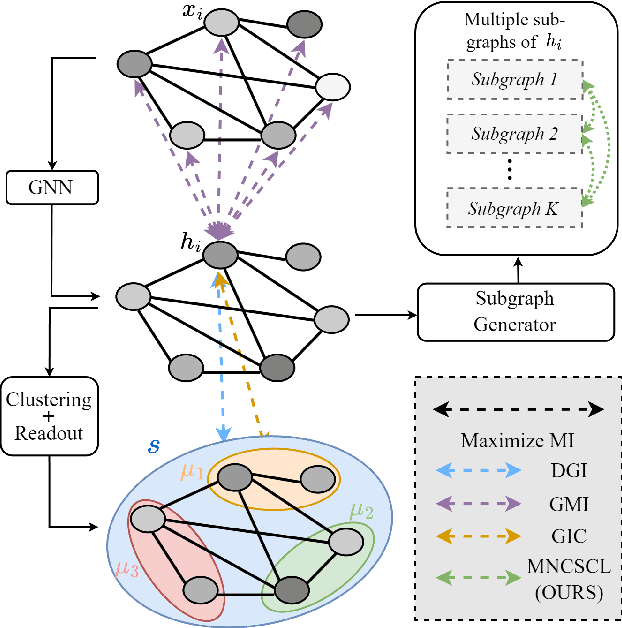

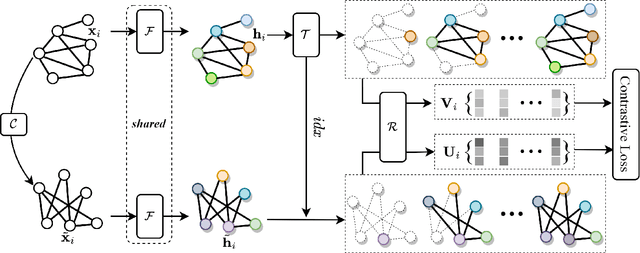

As the basic element of graph-structured data, node has been recognized as the main object of study in graph representation learning. A single node intuitively has multiple node-centered subgraphs from the whole graph (e.g., one person in a social network has multiple social circles based on his different relationships). We study this intuition under the framework of graph contrastive learning, and propose a multiple node-centered subgraphs contrastive representation learning method to learn node representation on graphs in a self-supervised way. Specifically, we carefully design a series of node-centered regional subgraphs of the central node. Then, the mutual information between different subgraphs of the same node is maximized by contrastive loss. Experiments on various real-world datasets and different downstream tasks demonstrate that our model has achieved state-of-the-art results.