 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Resources and Evaluations for Multi-Distribution Dense Information Retrieval
Jun 21, 2023
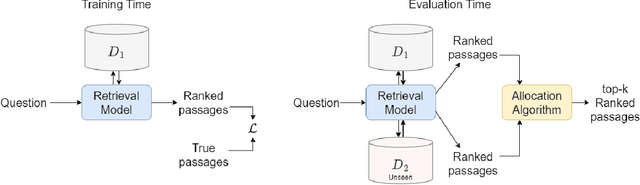

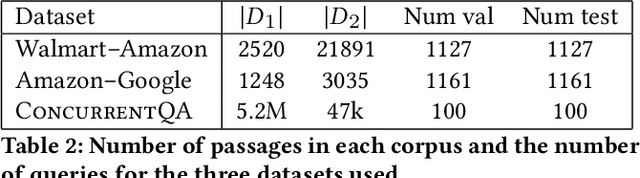
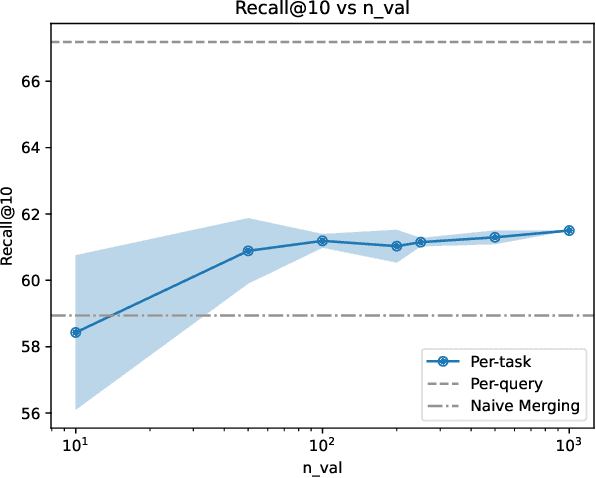
We introduce and define the novel problem of multi-distribution information retrieval (IR) where given a query, systems need to retrieve passages from within multiple collections, each drawn from a different distribution. Some of these collections and distributions might not be available at training time. To evaluate methods for multi-distribution retrieval, we design three benchmarks for this task from existing single-distribution datasets, namely, a dataset based on question answering and two based on entity matching. We propose simple methods for this task which allocate the fixed retrieval budget (top-k passages) strategically across domains to prevent the known domains from consuming most of the budget. We show that our methods lead to an average of 3.8+ and up to 8.0 points improvements in Recall@100 across the datasets and that improvements are consistent when fine-tuning different base retrieval models. Our benchmarks are made publicly available.
ClusterFusion: Leveraging Radar Spatial Features for Radar-Camera 3D Object Detection in Autonomous Vehicles
Sep 07, 2023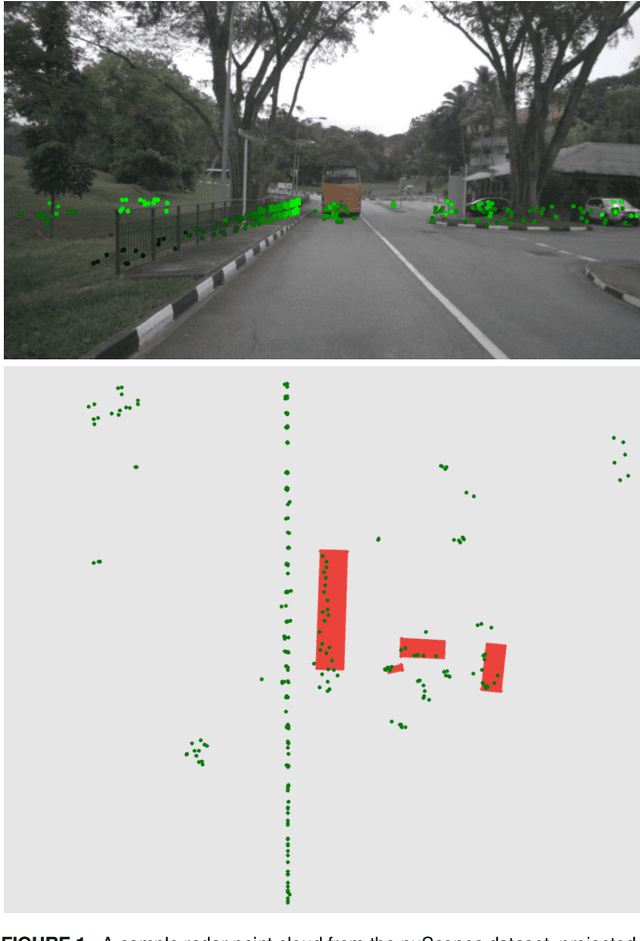

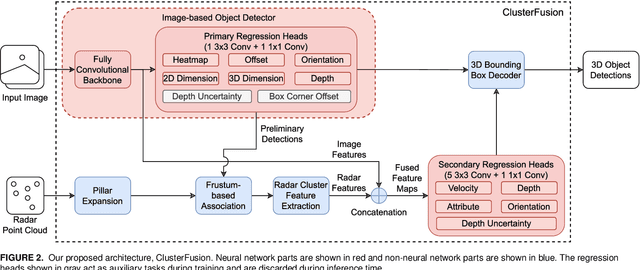

Thanks to the complementary nature of millimeter wave radar and camera, deep learning-based radar-camera 3D object detection methods may reliably produce accurate detections even in low-visibility conditions. This makes them preferable to use in autonomous vehicles' perception systems, especially as the combined cost of both sensors is cheaper than the cost of a lidar. Recent radar-camera methods commonly perform feature-level fusion which often involves projecting the radar points onto the same plane as the image features and fusing the extracted features from both modalities. While performing fusion on the image plane is generally simpler and faster, projecting radar points onto the image plane flattens the depth dimension of the point cloud which might lead to information loss and makes extracting the spatial features of the point cloud harder. We proposed ClusterFusion, an architecture that leverages the local spatial features of the radar point cloud by clustering the point cloud and performing feature extraction directly on the point cloud clusters before projecting the features onto the image plane. ClusterFusion achieved the state-of-the-art performance among all radar-monocular camera methods on the test slice of the nuScenes dataset with 48.7% nuScenes detection score (NDS). We also investigated the performance of different radar feature extraction strategies on point cloud clusters: a handcrafted strategy, a learning-based strategy, and a combination of both, and found that the handcrafted strategy yielded the best performance. The main goal of this work is to explore the use of radar's local spatial and point-wise features by extracting them directly from radar point cloud clusters for a radar-monocular camera 3D object detection method that performs cross-modal feature fusion on the image plane.
Adaptive Ordered Information Extraction with Deep Reinforcement Learning
Jun 19, 2023
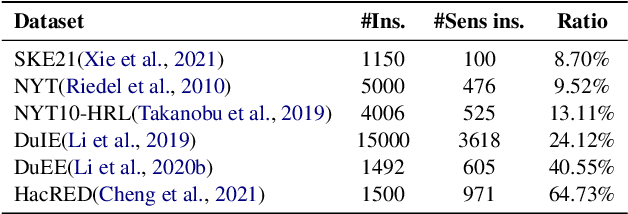
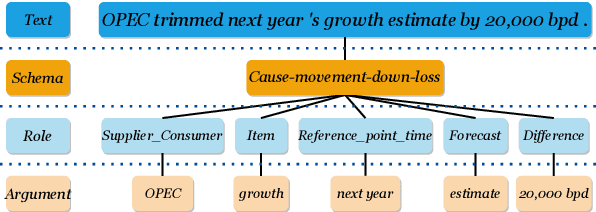
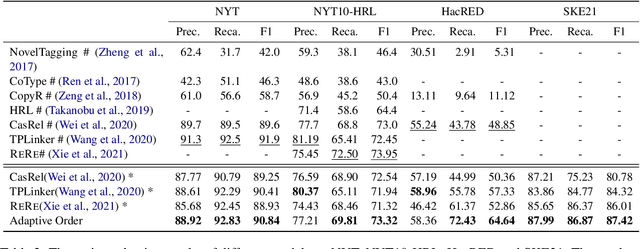
Information extraction (IE) has been studied extensively. The existing methods always follow a fixed extraction order for complex IE tasks with multiple elements to be extracted in one instance such as event extraction. However, we conduct experiments on several complex IE datasets and observe that different extraction orders can significantly affect the extraction results for a great portion of instances, and the ratio of sentences that are sensitive to extraction orders increases dramatically with the complexity of the IE task. Therefore, this paper proposes a novel adaptive ordered IE paradigm to find the optimal element extraction order for different instances, so as to achieve the best extraction results. We also propose an reinforcement learning (RL) based framework to generate optimal extraction order for each instance dynamically. Additionally, we propose a co-training framework adapted to RL to mitigate the exposure bias during the extractor training phase. Extensive experiments conducted on several public datasets demonstrate that our proposed method can beat previous methods and effectively improve the performance of various IE tasks, especially for complex ones.
Hybrid-Supervised Dual-Search: Leveraging Automatic Learning for Loss-free Multi-Exposure Image Fusion
Sep 03, 2023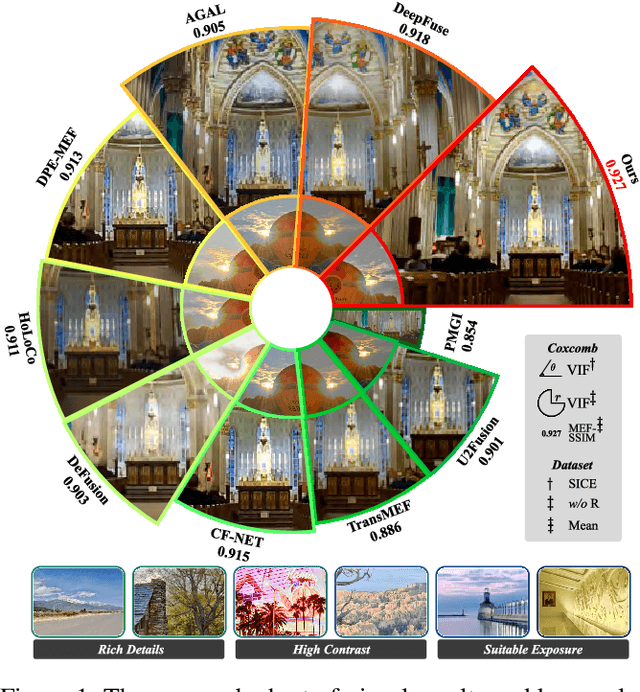

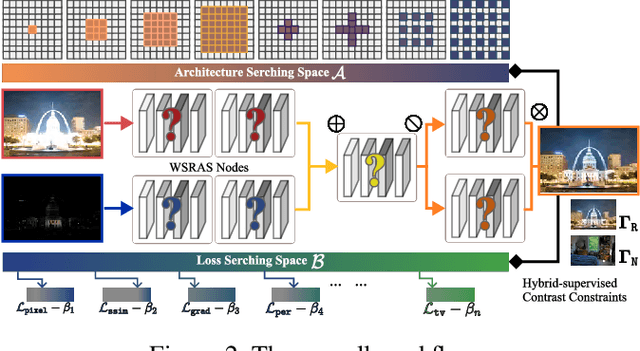
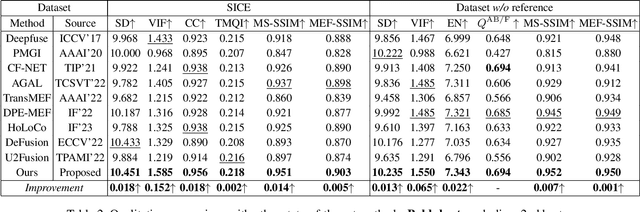
Multi-exposure image fusion (MEF) has emerged as a prominent solution to address the limitations of digital imaging in representing varied exposure levels. Despite its advancements, the field grapples with challenges, notably the reliance on manual designs for network structures and loss functions, and the constraints of utilizing simulated reference images as ground truths. Consequently, current methodologies often suffer from color distortions and exposure artifacts, further complicating the quest for authentic image representation. In addressing these challenges, this paper presents a Hybrid-Supervised Dual-Search approach for MEF, dubbed HSDS-MEF, which introduces a bi-level optimization search scheme for automatic design of both network structures and loss functions. More specifically, we harnesses a unique dual research mechanism rooted in a novel weighted structure refinement architecture search. Besides, a hybrid supervised contrast constraint seamlessly guides and integrates with searching process, facilitating a more adaptive and comprehensive search for optimal loss functions. We realize the state-of-the-art performance in comparison to various competitive schemes, yielding a 10.61% and 4.38% improvement in Visual Information Fidelity (VIF) for general and no-reference scenarios, respectively, while providing results with high contrast, rich details and colors.
MAP: Domain Generalization via Meta-Learning on Anatomy-Consistent Pseudo-Modalities
Sep 03, 2023

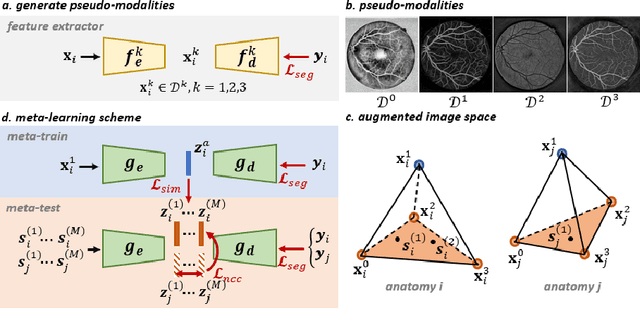
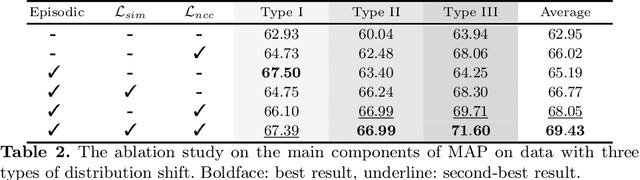
Deep models suffer from limited generalization capability to unseen domains, which has severely hindered their clinical applicability. Specifically for the retinal vessel segmentation task, although the model is supposed to learn the anatomy of the target, it can be distracted by confounding factors like intensity and contrast. We propose Meta learning on Anatomy-consistent Pseudo-modalities (MAP), a method that improves model generalizability by learning structural features. We first leverage a feature extraction network to generate three distinct pseudo-modalities that share the vessel structure of the original image. Next, we use the episodic learning paradigm by selecting one of the pseudo-modalities as the meta-train dataset, and perform meta-testing on a continuous augmented image space generated through Dirichlet mixup of the remaining pseudo-modalities. Further, we introduce two loss functions that facilitate the model's focus on shape information by clustering the latent vectors obtained from images featuring identical vasculature. We evaluate our model on seven public datasets of various retinal imaging modalities and we conclude that MAP has substantially better generalizability. Our code is publically available at https://github.com/DeweiHu/MAP.
FaceCoresetNet: Differentiable Coresets for Face Set Recognition
Aug 27, 2023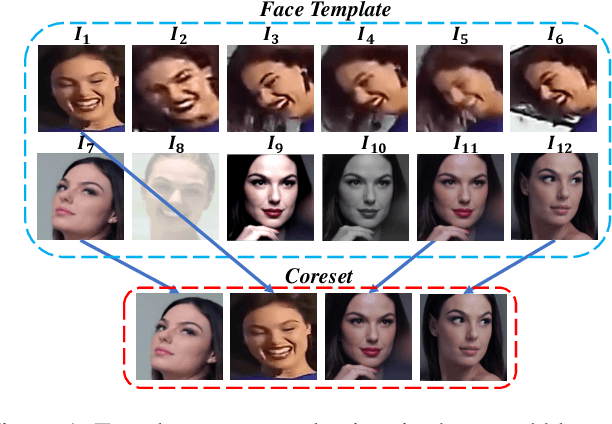
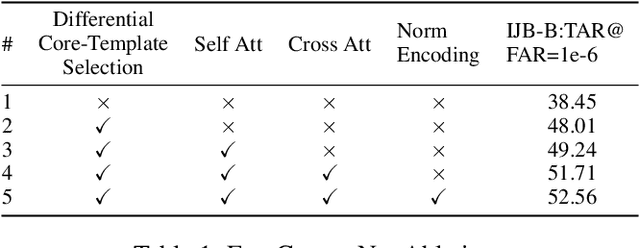
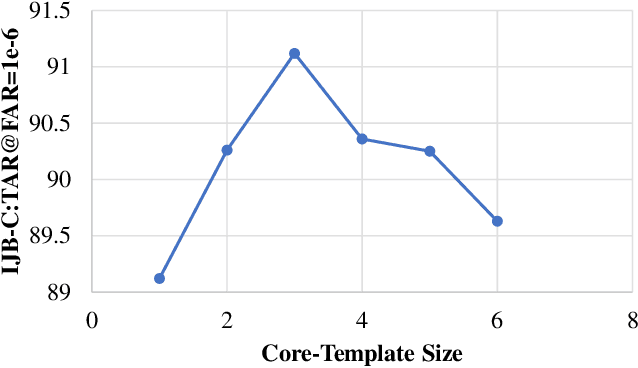
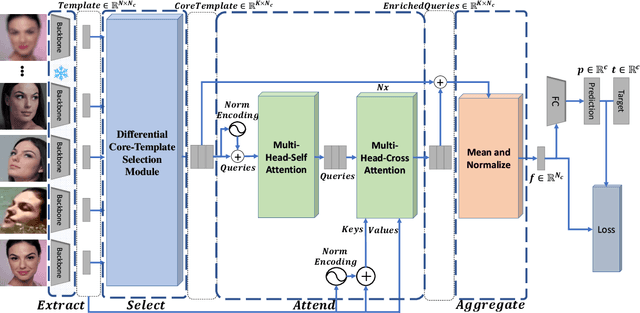
In set-based face recognition, we aim to compute the most discriminative descriptor from an unbounded set of images and videos showing a single person. A discriminative descriptor balances two policies when aggregating information from a given set. The first is a quality-based policy: emphasizing high-quality and down-weighting low-quality images. The second is a diversity-based policy: emphasizing unique images in the set and down-weighting multiple occurrences of similar images as found in video clips which can overwhelm the set representation. This work frames face-set representation as a differentiable coreset selection problem. Our model learns how to select a small coreset of the input set that balances quality and diversity policies using a learned metric parameterized by the face quality, optimized end-to-end. The selection process is a differentiable farthest-point sampling (FPS) realized by approximating the non-differentiable Argmax operation with differentiable sampling from the Gumbel-Softmax distribution of distances. The small coreset is later used as queries in a self and cross-attention architecture to enrich the descriptor with information from the whole set. Our model is order-invariant and linear in the input set size. We set a new SOTA to set face verification on the IJB-B and IJB-C datasets. Our code is publicly available.
A Knowledge-enhanced Two-stage Generative Framework for Medical Dialogue Information Extraction
Jul 30, 2023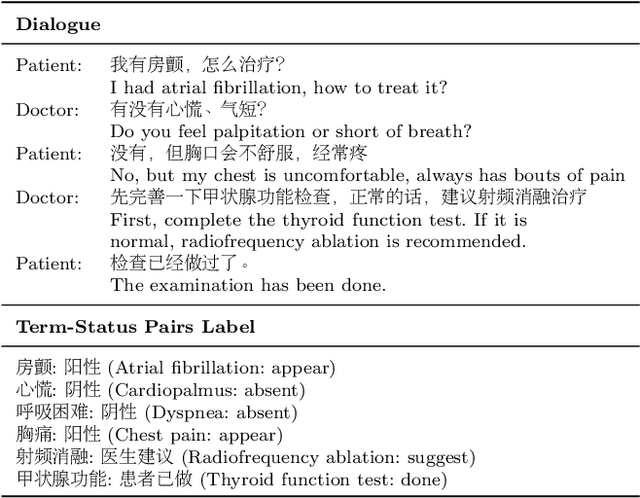
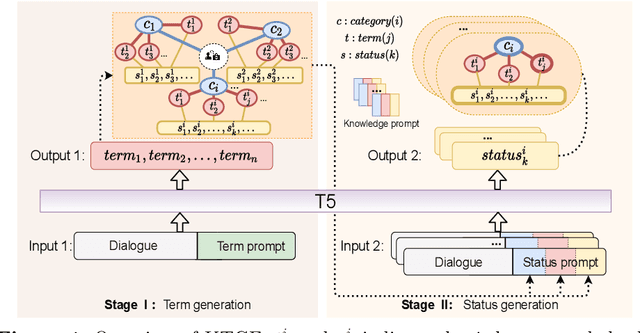
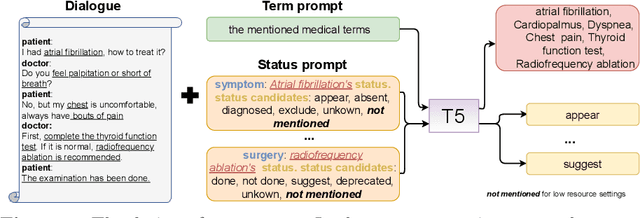
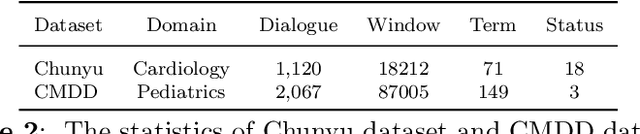
This paper focuses on term-status pair extraction from medical dialogues (MD-TSPE), which is essential in diagnosis dialogue systems and the automatic scribe of electronic medical records (EMRs). In the past few years, works on MD-TSPE have attracted increasing research attention, especially after the remarkable progress made by generative methods. However, these generative methods output a whole sequence consisting of term-status pairs in one stage and ignore integrating prior knowledge, which demands a deeper understanding to model the relationship between terms and infer the status of each term. This paper presents a knowledge-enhanced two-stage generative framework (KTGF) to address the above challenges. Using task-specific prompts, we employ a single model to complete the MD-TSPE through two phases in a unified generative form: we generate all terms the first and then generate the status of each generated term. In this way, the relationship between terms can be learned more effectively from the sequence containing only terms in the first phase, and our designed knowledge-enhanced prompt in the second phase can leverage the category and status candidates of the generated term for status generation. Furthermore, our proposed special status ``not mentioned" makes more terms available and enriches the training data in the second phase, which is critical in the low-resource setting. The experiments on the Chunyu and CMDD datasets show that the proposed method achieves superior results compared to the state-of-the-art models in the full training and low-resource settings.
Text Analysis Using Deep Neural Networks in Digital Humanities and Information Science
Jul 30, 2023Combining computational technologies and humanities is an ongoing effort aimed at making resources such as texts, images, audio, video, and other artifacts digitally available, searchable, and analyzable. In recent years, deep neural networks (DNN) dominate the field of automatic text analysis and natural language processing (NLP), in some cases presenting a super-human performance. DNNs are the state-of-the-art machine learning algorithms solving many NLP tasks that are relevant for Digital Humanities (DH) research, such as spell checking, language detection, entity extraction, author detection, question answering, and other tasks. These supervised algorithms learn patterns from a large number of "right" and "wrong" examples and apply them to new examples. However, using DNNs for analyzing the text resources in DH research presents two main challenges: (un)availability of training data and a need for domain adaptation. This paper explores these challenges by analyzing multiple use-cases of DH studies in recent literature and their possible solutions and lays out a practical decision model for DH experts for when and how to choose the appropriate deep learning approaches for their research. Moreover, in this paper, we aim to raise awareness of the benefits of utilizing deep learning models in the DH community.
GeodesicPSIM: Predicting the Quality of Static Mesh with Texture Map via Geodesic Patch Similarity
Aug 24, 2023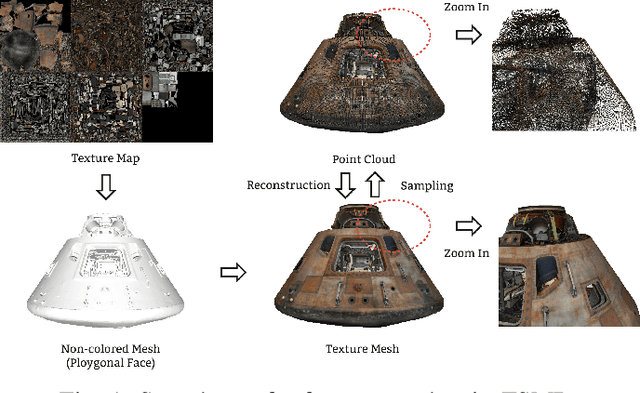
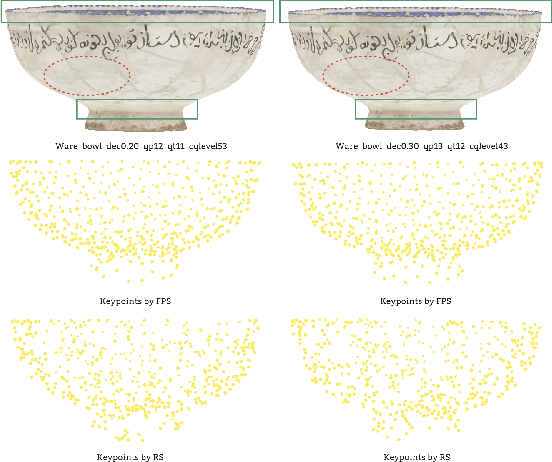
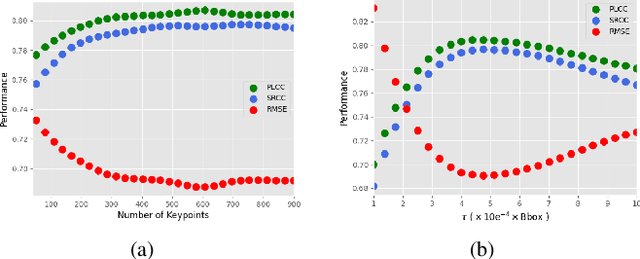
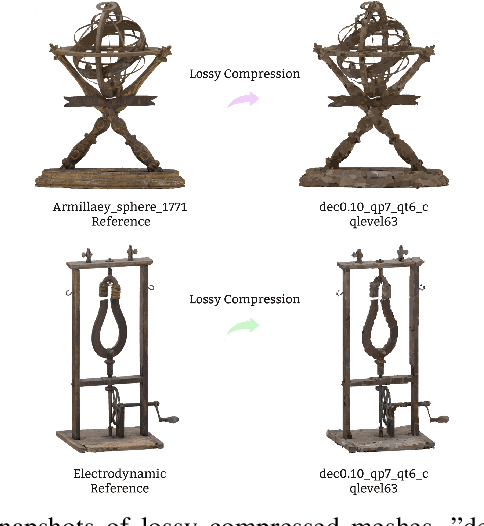
Static meshes with texture maps have attracted considerable attention in both industrial manufacturing and academic research, leading to an urgent requirement for effective and robust objective quality evaluation. However, current model-based static mesh quality metrics have obvious limitations: most of them only consider geometry information, while color information is ignored, and they have strict constraints for the meshes' geometrical topology. Other metrics, such as image-based and point-based metrics, are easily influenced by the prepossessing algorithms, e.g., projection and sampling, hampering their ability to perform at their best. In this paper, we propose Geodesic Patch Similarity (GeodesicPSIM), a novel model-based metric to accurately predict human perception quality for static meshes. After selecting a group keypoints, 1-hop geodesic patches are constructed based on both the reference and distorted meshes cleaned by an effective mesh cleaning algorithm. A two-step patch cropping algorithm and a patch texture mapping module refine the size of 1-hop geodesic patches and build the relationship between the mesh geometry and color information, resulting in the generation of 1-hop textured geodesic patches. Three types of features are extracted to quantify the distortion: patch color smoothness, patch discrete mean curvature, and patch pixel color average and variance. To the best of our knowledge, GeodesicPSIM is the first model-based metric especially designed for static meshes with texture maps. GeodesicPSIM provides state-of-the-art performance in comparison with image-based, point-based, and video-based metrics on a newly created and challenging database. We also prove the robustness of GeodesicPSIM by introducing different settings of hyperparameters. Ablation studies also exhibit the effectiveness of three proposed features and the patch cropping algorithm.
Exchanging-based Multimodal Fusion with Transformer
Sep 05, 2023
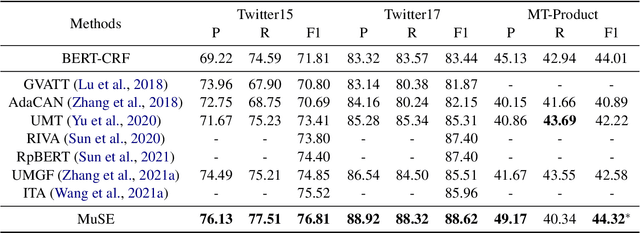
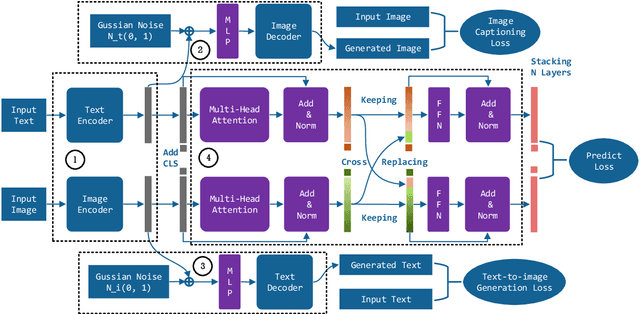
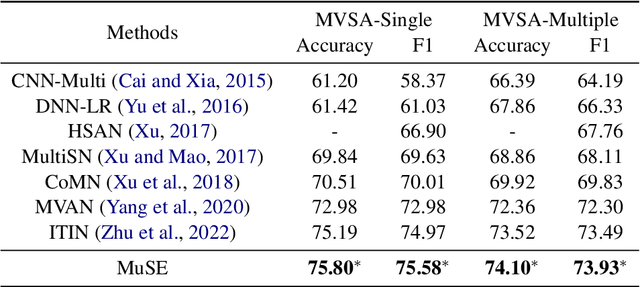
We study the problem of multimodal fusion in this paper. Recent exchanging-based methods have been proposed for vision-vision fusion, which aim to exchange embeddings learned from one modality to the other. However, most of them project inputs of multimodalities into different low-dimensional spaces and cannot be applied to the sequential input data. To solve these issues, in this paper, we propose a novel exchanging-based multimodal fusion model MuSE for text-vision fusion based on Transformer. We first use two encoders to separately map multimodal inputs into different low-dimensional spaces. Then we employ two decoders to regularize the embeddings and pull them into the same space. The two decoders capture the correlations between texts and images with the image captioning task and the text-to-image generation task, respectively. Further, based on the regularized embeddings, we present CrossTransformer, which uses two Transformer encoders with shared parameters as the backbone model to exchange knowledge between multimodalities. Specifically, CrossTransformer first learns the global contextual information of the inputs in the shallow layers. After that, it performs inter-modal exchange by selecting a proportion of tokens in one modality and replacing their embeddings with the average of embeddings in the other modality. We conduct extensive experiments to evaluate the performance of MuSE on the Multimodal Named Entity Recognition task and the Multimodal Sentiment Analysis task. Our results show the superiority of MuSE against other competitors. Our code and data are provided at https://github.com/RecklessRonan/MuSE.