 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
TouchStone: Evaluating Vision-Language Models by Language Models
Sep 04, 2023
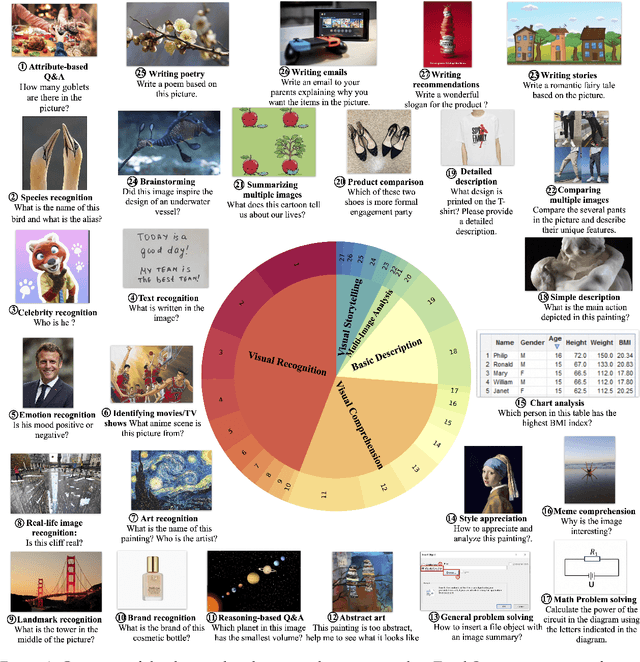


Large vision-language models (LVLMs) have recently witnessed rapid advancements, exhibiting a remarkable capacity for perceiving, understanding, and processing visual information by connecting visual receptor with large language models (LLMs). However, current assessments mainly focus on recognizing and reasoning abilities, lacking direct evaluation of conversational skills and neglecting visual storytelling abilities. In this paper, we propose an evaluation method that uses strong LLMs as judges to comprehensively evaluate the various abilities of LVLMs. Firstly, we construct a comprehensive visual dialogue dataset TouchStone, consisting of open-world images and questions, covering five major categories of abilities and 27 subtasks. This dataset not only covers fundamental recognition and comprehension but also extends to literary creation. Secondly, by integrating detailed image annotations we effectively transform the multimodal input content into a form understandable by LLMs. This enables us to employ advanced LLMs for directly evaluating the quality of the multimodal dialogue without requiring human intervention. Through validation, we demonstrate that powerful LVLMs, such as GPT-4, can effectively score dialogue quality by leveraging their textual capabilities alone, aligning with human preferences. We hope our work can serve as a touchstone for LVLMs' evaluation and pave the way for building stronger LVLMs. The evaluation code is available at https://github.com/OFA-Sys/TouchStone.
A Unified Framework for Guiding Generative AI with Wireless Perception in Resource Constrained Mobile Edge Networks
Sep 04, 2023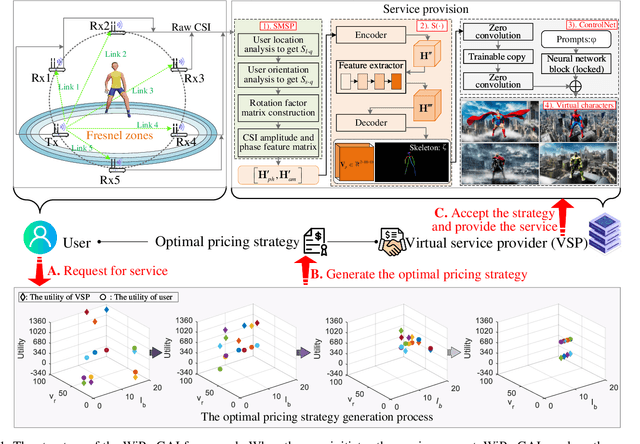

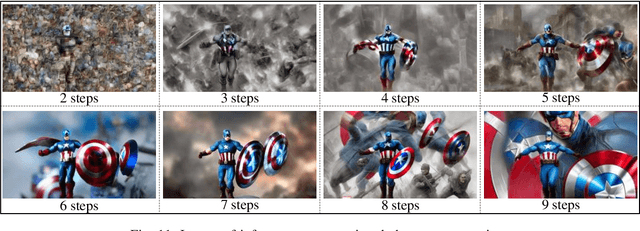
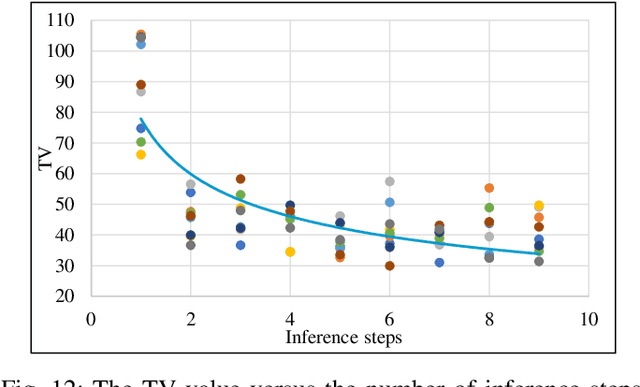
With the significant advancements in artificial intelligence (AI) technologies and powerful computational capabilities, generative AI (GAI) has become a pivotal digital content generation technique for offering superior digital services. However, directing GAI towards desired outputs still suffer the inherent instability of the AI model. In this paper, we design a novel framework that utilizes wireless perception to guide GAI (WiPe-GAI) for providing digital content generation service, i.e., AI-generated content (AIGC), in resource-constrained mobile edge networks. Specifically, we first propose a new sequential multi-scale perception (SMSP) algorithm to predict user skeleton based on the channel state information (CSI) extracted from wireless signals. This prediction then guides GAI to provide users with AIGC, such as virtual character generation. To ensure the efficient operation of the proposed framework in resource constrained networks, we further design a pricing-based incentive mechanism and introduce a diffusion model based approach to generate an optimal pricing strategy for the service provisioning. The strategy maximizes the user's utility while enhancing the participation of the virtual service provider (VSP) in AIGC provision. The experimental results demonstrate the effectiveness of the designed framework in terms of skeleton prediction and optimal pricing strategy generation comparing with other existing solutions.
Adapting Segment Anything Model for Change Detection in HR Remote Sensing Images
Sep 04, 2023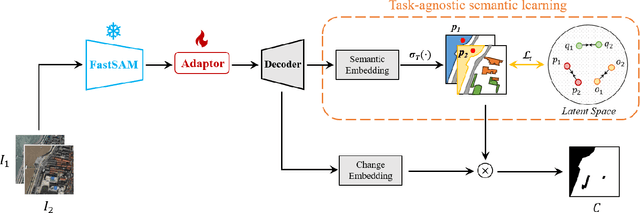
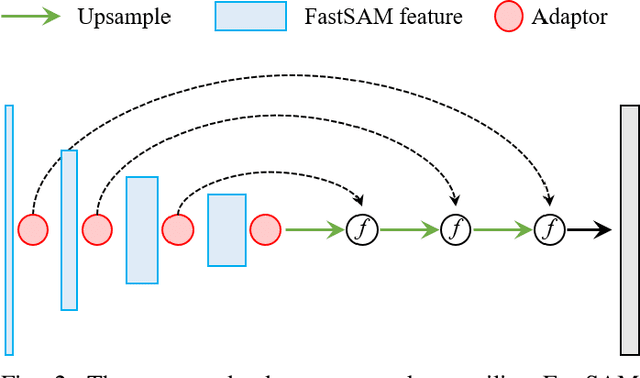

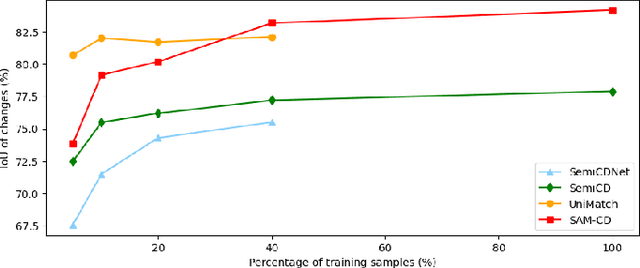
Vision Foundation Models (VFMs) such as the Segment Anything Model (SAM) allow zero-shot or interactive segmentation of visual contents, thus they are quickly applied in a variety of visual scenes. However, their direct use in many Remote Sensing (RS) applications is often unsatisfactory due to the special imaging characteristics of RS images. In this work, we aim to utilize the strong visual recognition capabilities of VFMs to improve the change detection of high-resolution Remote Sensing Images (RSIs). We employ the visual encoder of FastSAM, an efficient variant of the SAM, to extract visual representations in RS scenes. To adapt FastSAM to focus on some specific ground objects in the RS scenes, we propose a convolutional adaptor to aggregate the task-oriented change information. Moreover, to utilize the semantic representations that are inherent to SAM features, we introduce a task-agnostic semantic learning branch to model the semantic latent in bi-temporal RSIs. The resulting method, SAMCD, obtains superior accuracy compared to the SOTA methods and exhibits a sample-efficient learning ability that is comparable to semi-supervised CD methods. To the best of our knowledge, this is the first work that adapts VFMs for the CD of HR RSIs.
Detection of Pedestrian Turning Motions to Enhance Indoor Map Matching Performance
Sep 04, 2023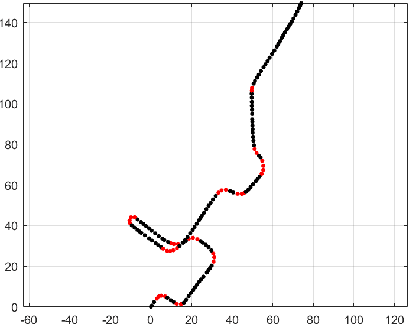
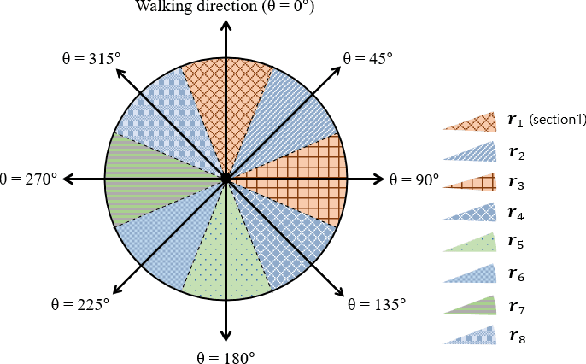
A pedestrian navigation system (PNS) in indoor environments, where global navigation satellite system (GNSS) signal access is difficult, is necessary, particularly for search and rescue (SAR) operations in large buildings. This paper focuses on studying pedestrian walking behaviors to enhance the performance of indoor pedestrian dead reckoning (PDR) and map matching techniques. Specifically, our research aims to detect pedestrian turning motions using smartphone inertial measurement unit (IMU) information in a given PDR trajectory. To improve existing methods, including the threshold-based turn detection method, hidden Markov model (HMM)-based turn detection method, and pruned exact linear time (PELT) algorithm-based turn detection method, we propose enhanced algorithms that better detect pedestrian turning motions. During field tests, using the threshold-based method, we observed a missed detection rate of 20.35% and a false alarm rate of 7.65%. The PELT-based method achieved a significant improvement with a missed detection rate of 8.93% and a false alarm rate of 6.97%. However, the best results were obtained using the HMM-based method, which demonstrated a missed detection rate of 5.14% and a false alarm rate of 2.00%. In summary, our research contributes to the development of a more accurate and reliable pedestrian navigation system by leveraging smartphone IMU data and advanced algorithms for turn detection in indoor environments.
Code Representation Pre-training with Complements from Program Executions
Sep 04, 2023
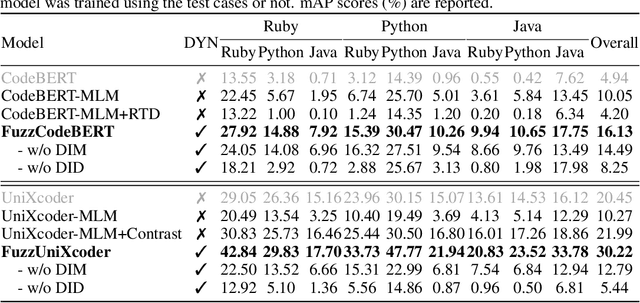
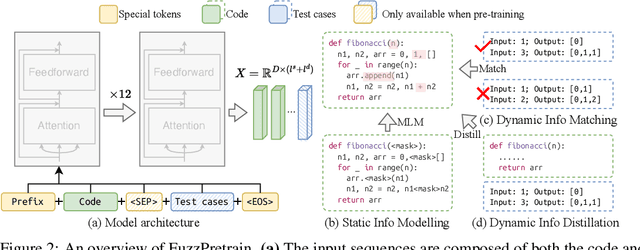
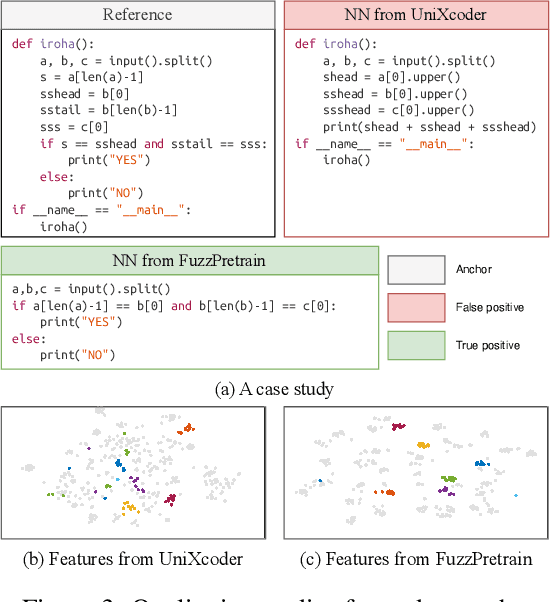
Large language models (LLMs) for natural language processing have been grafted onto programming language modeling for advancing code intelligence. Although it can be represented in the text format, code is syntactically more rigorous in order to be properly compiled or interpreted to perform a desired set of behaviors given any inputs. In this case, existing works benefit from syntactic representations to learn from code less ambiguously in the forms of abstract syntax tree, control-flow graph, etc. However, programs with the same purpose can be implemented in various ways showing different syntactic representations while the ones with similar implementations can have distinct behaviors. Though trivially demonstrated during executions, such semantics about functionality are challenging to be learned directly from code, especially in an unsupervised manner. Hence, in this paper, we propose FuzzPretrain to explore the dynamic information of programs revealed by their test cases and embed it into the feature representations of code as complements. The test cases are obtained with the assistance of a customized fuzzer and are only required during pre-training. FuzzPretrain yielded more than 6%/9% mAP improvements on code search over its counterparts trained with only source code or AST, respectively. Our extensive experimental results show the benefits of learning discriminative code representations with program executions.
A Knowledge-enhanced Two-stage Generative Framework for Medical Dialogue Information Extraction
Jul 30, 2023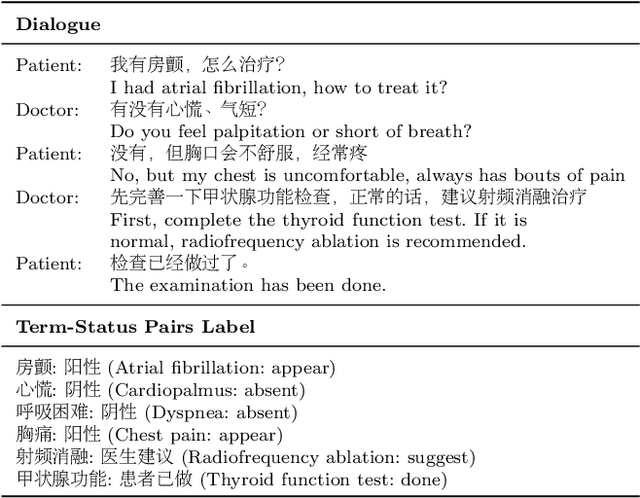
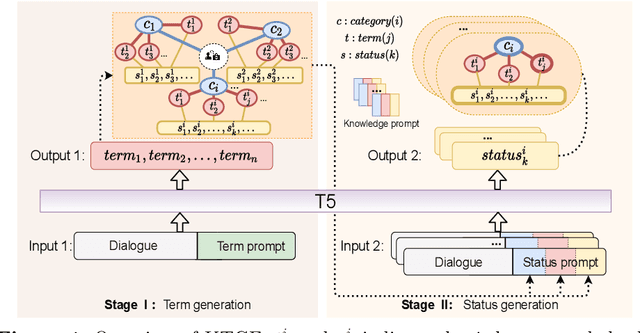
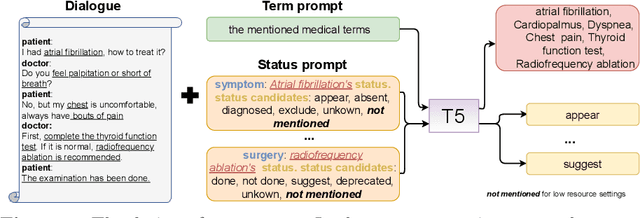
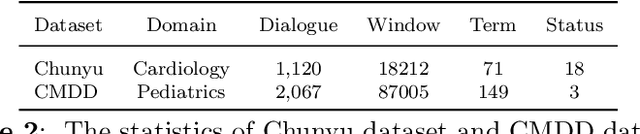
This paper focuses on term-status pair extraction from medical dialogues (MD-TSPE), which is essential in diagnosis dialogue systems and the automatic scribe of electronic medical records (EMRs). In the past few years, works on MD-TSPE have attracted increasing research attention, especially after the remarkable progress made by generative methods. However, these generative methods output a whole sequence consisting of term-status pairs in one stage and ignore integrating prior knowledge, which demands a deeper understanding to model the relationship between terms and infer the status of each term. This paper presents a knowledge-enhanced two-stage generative framework (KTGF) to address the above challenges. Using task-specific prompts, we employ a single model to complete the MD-TSPE through two phases in a unified generative form: we generate all terms the first and then generate the status of each generated term. In this way, the relationship between terms can be learned more effectively from the sequence containing only terms in the first phase, and our designed knowledge-enhanced prompt in the second phase can leverage the category and status candidates of the generated term for status generation. Furthermore, our proposed special status ``not mentioned" makes more terms available and enriches the training data in the second phase, which is critical in the low-resource setting. The experiments on the Chunyu and CMDD datasets show that the proposed method achieves superior results compared to the state-of-the-art models in the full training and low-resource settings.
Text Analysis Using Deep Neural Networks in Digital Humanities and Information Science
Jul 30, 2023Combining computational technologies and humanities is an ongoing effort aimed at making resources such as texts, images, audio, video, and other artifacts digitally available, searchable, and analyzable. In recent years, deep neural networks (DNN) dominate the field of automatic text analysis and natural language processing (NLP), in some cases presenting a super-human performance. DNNs are the state-of-the-art machine learning algorithms solving many NLP tasks that are relevant for Digital Humanities (DH) research, such as spell checking, language detection, entity extraction, author detection, question answering, and other tasks. These supervised algorithms learn patterns from a large number of "right" and "wrong" examples and apply them to new examples. However, using DNNs for analyzing the text resources in DH research presents two main challenges: (un)availability of training data and a need for domain adaptation. This paper explores these challenges by analyzing multiple use-cases of DH studies in recent literature and their possible solutions and lays out a practical decision model for DH experts for when and how to choose the appropriate deep learning approaches for their research. Moreover, in this paper, we aim to raise awareness of the benefits of utilizing deep learning models in the DH community.
Towards Spontaneous Style Modeling with Semi-supervised Pre-training for Conversational Text-to-Speech Synthesis
Aug 31, 2023The spontaneous behavior that often occurs in conversations makes speech more human-like compared to reading-style. However, synthesizing spontaneous-style speech is challenging due to the lack of high-quality spontaneous datasets and the high cost of labeling spontaneous behavior. In this paper, we propose a semi-supervised pre-training method to increase the amount of spontaneous-style speech and spontaneous behavioral labels. In the process of semi-supervised learning, both text and speech information are considered for detecting spontaneous behaviors labels in speech. Moreover, a linguistic-aware encoder is used to model the relationship between each sentence in the conversation. Experimental results indicate that our proposed method achieves superior expressive speech synthesis performance with the ability to model spontaneous behavior in spontaneous-style speech and predict reasonable spontaneous behavior from text.
PhonMatchNet: Phoneme-Guided Zero-Shot Keyword Spotting for User-Defined Keywords
Aug 31, 2023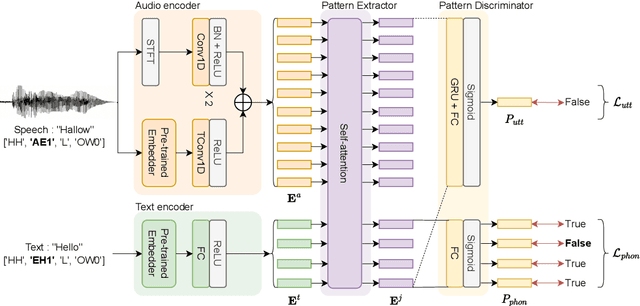

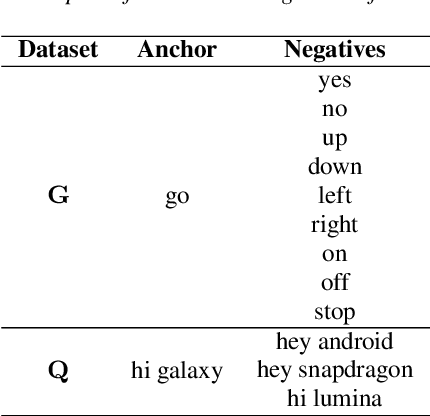
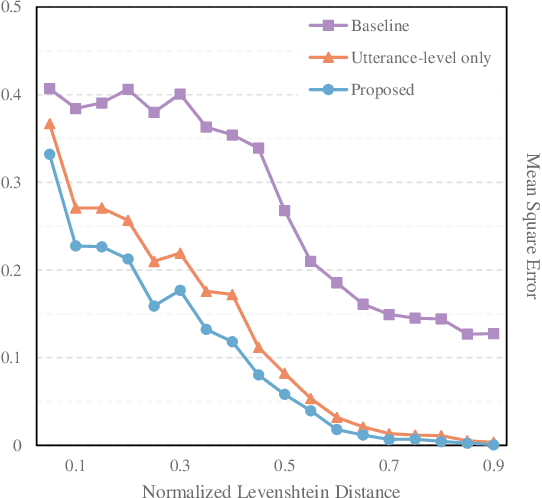
This study presents a novel zero-shot user-defined keyword spotting model that utilizes the audio-phoneme relationship of the keyword to improve performance. Unlike the previous approach that estimates at utterance level, we use both utterance and phoneme level information. Our proposed method comprises a two-stream speech encoder architecture, self-attention-based pattern extractor, and phoneme-level detection loss for high performance in various pronunciation environments. Based on experimental results, our proposed model outperforms the baseline model and achieves competitive performance compared with full-shot keyword spotting models. Our proposed model significantly improves the EER and AUC across all datasets, including familiar words, proper nouns, and indistinguishable pronunciations, with an average relative improvement of 67% and 80%, respectively. The implementation code of our proposed model is available at https://github.com/ncsoft/PhonMatchNet.
Bringing PDEs to JAX with forward and reverse modes automatic differentiation
Aug 31, 2023Partial differential equations (PDEs) are used to describe a variety of physical phenomena. Often these equations do not have analytical solutions and numerical approximations are used instead. One of the common methods to solve PDEs is the finite element method. Computing derivative information of the solution with respect to the input parameters is important in many tasks in scientific computing. We extend JAX automatic differentiation library with an interface to Firedrake finite element library. High-level symbolic representation of PDEs allows bypassing differentiating through low-level possibly many iterations of the underlying nonlinear solvers. Differentiating through Firedrake solvers is done using tangent-linear and adjoint equations. This enables the efficient composition of finite element solvers with arbitrary differentiable programs. The code is available at github.com/IvanYashchuk/jax-firedrake.