 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Enhancing Hyperedge Prediction with Context-Aware Self-Supervised Learning
Sep 11, 2023
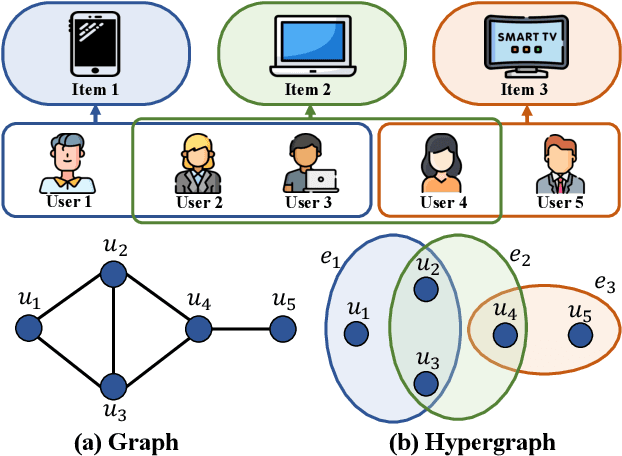
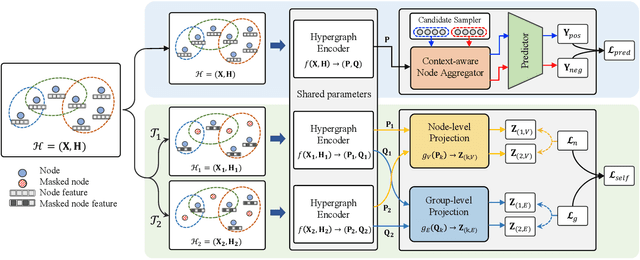
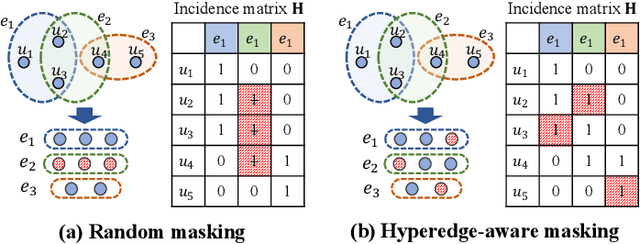
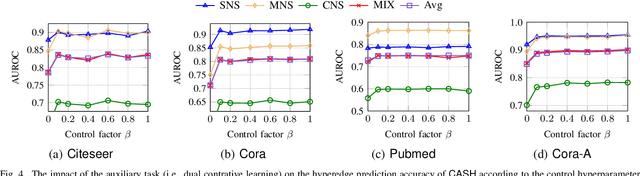
Hypergraphs can naturally model group-wise relations (e.g., a group of users who co-purchase an item) as hyperedges. Hyperedge prediction is to predict future or unobserved hyperedges, which is a fundamental task in many real-world applications (e.g., group recommendation). Despite the recent breakthrough of hyperedge prediction methods, the following challenges have been rarely studied: (C1) How to aggregate the nodes in each hyperedge candidate for accurate hyperedge prediction? and (C2) How to mitigate the inherent data sparsity problem in hyperedge prediction? To tackle both challenges together, in this paper, we propose a novel hyperedge prediction framework (CASH) that employs (1) context-aware node aggregation to precisely capture complex relations among nodes in each hyperedge for (C1) and (2) self-supervised contrastive learning in the context of hyperedge prediction to enhance hypergraph representations for (C2). Furthermore, as for (C2), we propose a hyperedge-aware augmentation method to fully exploit the latent semantics behind the original hypergraph and consider both node-level and group-level contrasts (i.e., dual contrasts) for better node and hyperedge representations. Extensive experiments on six real-world hypergraphs reveal that CASH consistently outperforms all competing methods in terms of the accuracy in hyperedge prediction and each of the proposed strategies is effective in improving the model accuracy of CASH. For the detailed information of CASH, we provide the code and datasets at: https://github.com/yy-ko/cash.
SayNav: Grounding Large Language Models for Dynamic Planning to Navigation in New Environments
Sep 11, 2023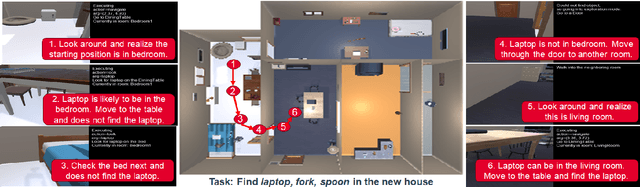
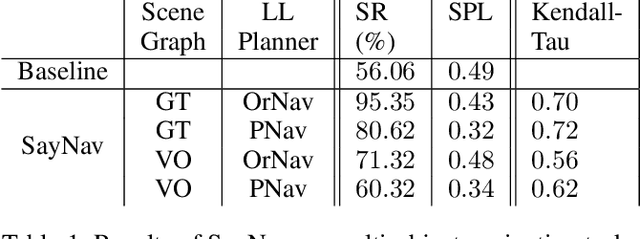
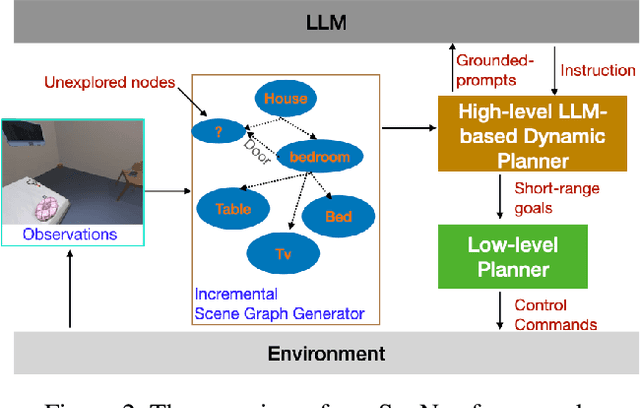
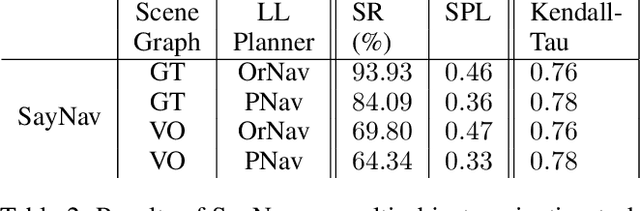
Semantic reasoning and dynamic planning capabilities are crucial for an autonomous agent to perform complex navigation tasks in unknown environments. It requires a large amount of common-sense knowledge, that humans possess, to succeed in these tasks. We present SayNav, a new approach that leverages human knowledge from Large Language Models (LLMs) for efficient generalization to complex navigation tasks in unknown large-scale environments. SayNav uses a novel grounding mechanism, that incrementally builds a 3D scene graph of the explored environment as inputs to LLMs, for generating feasible and contextually appropriate high-level plans for navigation. The LLM-generated plan is then executed by a pre-trained low-level planner, that treats each planned step as a short-distance point-goal navigation sub-task. SayNav dynamically generates step-by-step instructions during navigation and continuously refines future steps based on newly perceived information. We evaluate SayNav on a new multi-object navigation task, that requires the agent to utilize a massive amount of human knowledge to efficiently search multiple different objects in an unknown environment. SayNav outperforms an oracle based Point-nav baseline, achieving a success rate of 95.35% (vs 56.06% for the baseline), under the ideal settings on this task, highlighting its ability to generate dynamic plans for successfully locating objects in large-scale new environments. In addition, SayNav also enables efficient generalization from simulation to real environments.
Towards Content-based Pixel Retrieval in Revisited Oxford and Paris
Sep 11, 2023
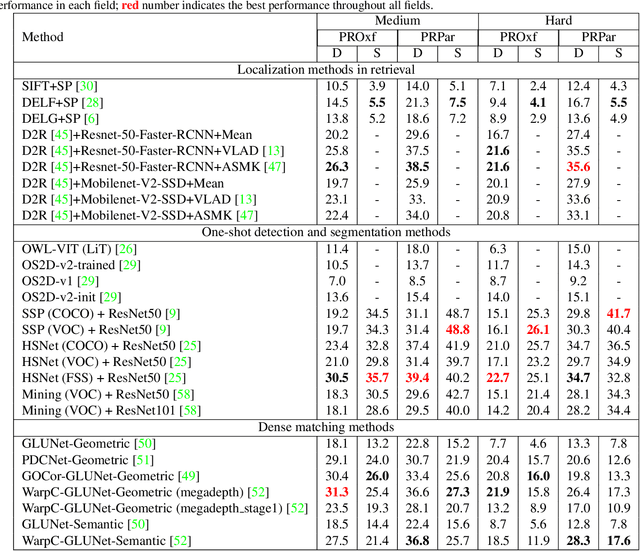
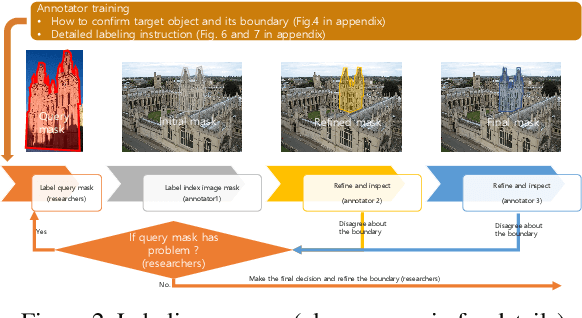
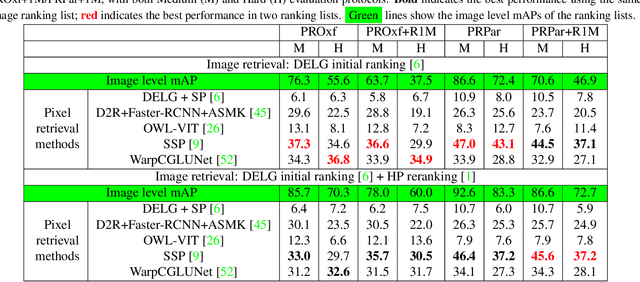
This paper introduces the first two pixel retrieval benchmarks. Pixel retrieval is segmented instance retrieval. Like semantic segmentation extends classification to the pixel level, pixel retrieval is an extension of image retrieval and offers information about which pixels are related to the query object. In addition to retrieving images for the given query, it helps users quickly identify the query object in true positive images and exclude false positive images by denoting the correlated pixels. Our user study results show pixel-level annotation can significantly improve the user experience. Compared with semantic and instance segmentation, pixel retrieval requires a fine-grained recognition capability for variable-granularity targets. To this end, we propose pixel retrieval benchmarks named PROxford and PRParis, which are based on the widely used image retrieval datasets, ROxford and RParis. Three professional annotators label 5,942 images with two rounds of double-checking and refinement. Furthermore, we conduct extensive experiments and analysis on the SOTA methods in image search, image matching, detection, segmentation, and dense matching using our pixel retrieval benchmarks. Results show that the pixel retrieval task is challenging to these approaches and distinctive from existing problems, suggesting that further research can advance the content-based pixel-retrieval and thus user search experience. The datasets can be downloaded from \href{https://github.com/anguoyuan/Pixel_retrieval-Segmented_instance_retrieval}{this link}.
Large Process Models: Business Process Management in the Age of Generative AI
Sep 11, 2023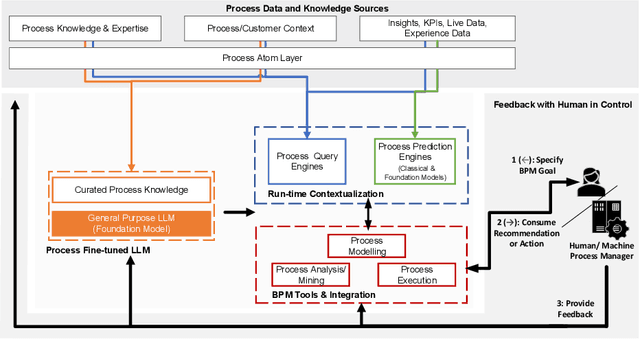
The continued success of Large Language Models (LLMs) and other generative artificial intelligence approaches highlights the advantages that large information corpora can have over rigidly defined symbolic models, but also serves as a proof-point of the challenges that purely statistics-based approaches have in terms of safety and trustworthiness. As a framework for contextualizing the potential, as well as the limitations of LLMs and other foundation model-based technologies, we propose the concept of a Large Process Model (LPM) that combines the correlation power of LLMs with the analytical precision and reliability of knowledge-based systems and automated reasoning approaches. LPMs are envisioned to directly utilize the wealth of process management experience that experts have accumulated, as well as process performance data of organizations with diverse characteristics, e.g., regarding size, region, or industry. In this vision, the proposed LPM would allow organizations to receive context-specific (tailored) process and other business models, analytical deep-dives, and improvement recommendations. As such, they would allow to substantially decrease the time and effort required for business transformation, while also allowing for deeper, more impactful, and more actionable insights than previously possible. We argue that implementing an LPM is feasible, but also highlight limitations and research challenges that need to be solved to implement particular aspects of the LPM vision.
ECG-based estimation of respiratory modulation of AV nodal conduction during atrial fibrillation
Sep 11, 2023
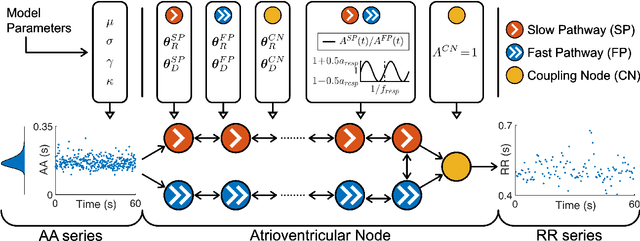
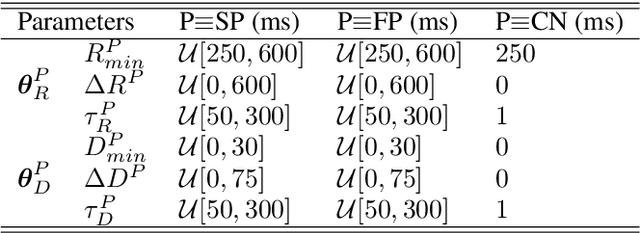
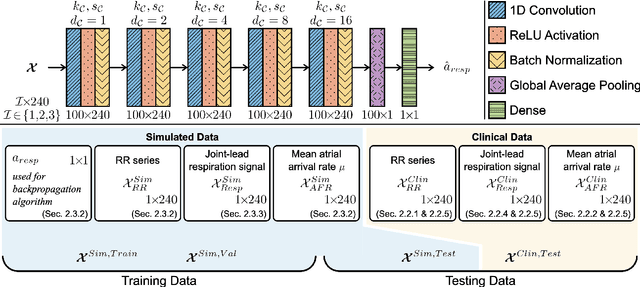
Information about autonomic nervous system (ANS) activity may be valuable for personalized atrial fibrillation (AF) treatment but is not easily accessible from the ECG. In this study, we propose a new approach for ECG-based assessment of respiratory modulation in AV nodal refractory period and conduction delay. A 1-dimensional convolutional neural network (1D-CNN) was trained to estimate respiratory modulation of AV nodal conduction properties from 1-minute segments of RR series, respiration signals, and atrial fibrillatory rates (AFR) using synthetic data that replicates clinical ECG-derived data. The synthetic data were generated using a network model of the AV node and 4 million unique model parameter sets. The 1D-CNN was then used to analyze respiratory modulation in clinical deep breathing test data of 28 patients in AF, where a ECG-derived respiration signal was extracted using a novel approach based on periodic component analysis. We demonstrated using synthetic data that the 1D-CNN can predict the respiratory modulation from RR series alone ($\rho$ = 0.805) and that the addition of either respiration signal ($\rho$ = 0.830), AFR ($\rho$ = 0.837), or both ($\rho$ = 0.855) improves the prediction. Results from analysis of clinical ECG data of 20 patients with sufficient signal quality suggest that respiratory modulation decreased in response to deep breathing for five patients, increased for five patients, and remained similar for ten patients, indicating a large inter-patient variability.
Contextual Biasing of Named-Entities with Large Language Models
Sep 01, 2023
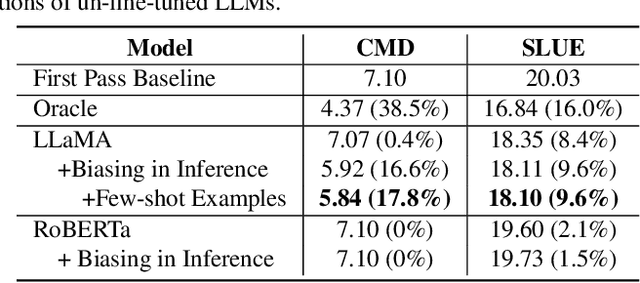
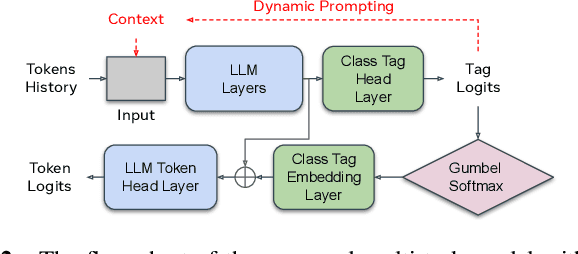
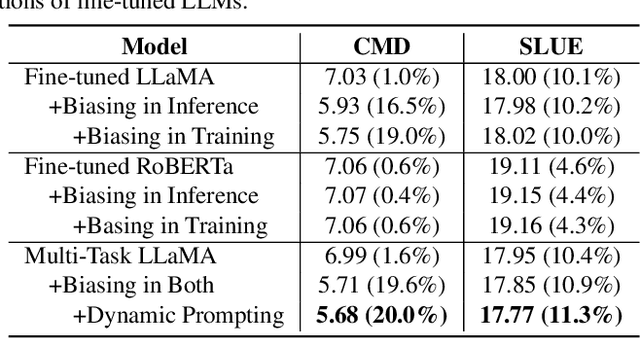
This paper studies contextual biasing with Large Language Models (LLMs), where during second-pass rescoring additional contextual information is provided to a LLM to boost Automatic Speech Recognition (ASR) performance. We propose to leverage prompts for a LLM without fine tuning during rescoring which incorporate a biasing list and few-shot examples to serve as additional information when calculating the score for the hypothesis. In addition to few-shot prompt learning, we propose multi-task training of the LLM to predict both the entity class and the next token. To improve the efficiency for contextual biasing and to avoid exceeding LLMs' maximum sequence lengths, we propose dynamic prompting, where we select the most likely class using the class tag prediction, and only use entities in this class as contexts for next token prediction. Word Error Rate (WER) evaluation is performed on i) an internal calling, messaging, and dictation dataset, and ii) the SLUE-Voxpopuli dataset. Results indicate that biasing lists and few-shot examples can achieve 17.8% and 9.6% relative improvement compared to first pass ASR, and that multi-task training and dynamic prompting can achieve 20.0% and 11.3% relative WER improvement, respectively.
Deep Segmented DMP Networks for Learning Discontinuous Motions
Sep 01, 2023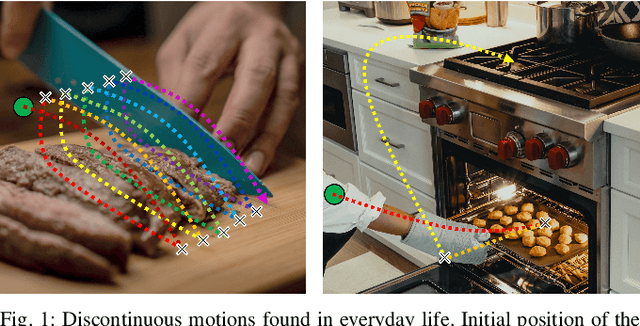
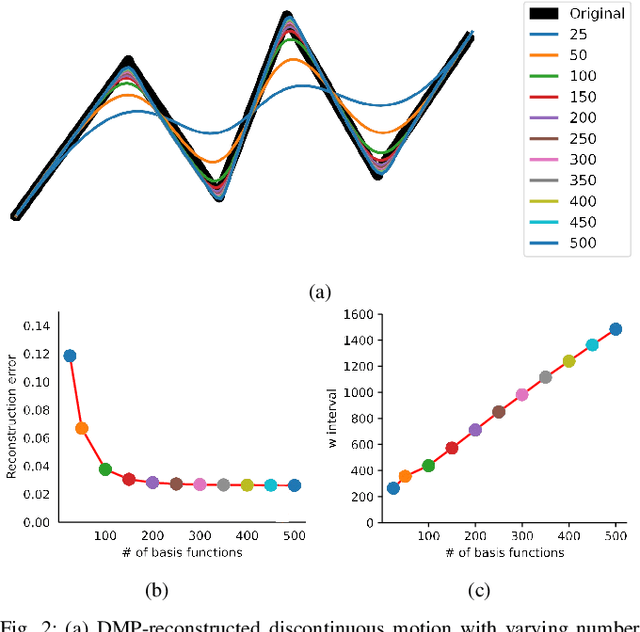
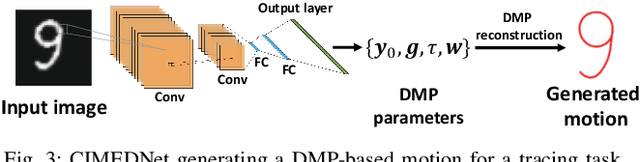
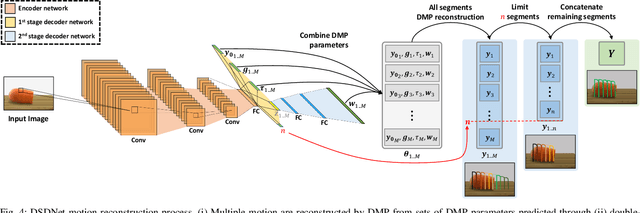
Discontinuous motion which is a motion composed of multiple continuous motions with sudden change in direction or velocity in between, can be seen in state-aware robotic tasks. Such robotic tasks are often coordinated with sensor information such as image. In recent years, Dynamic Movement Primitives (DMP) which is a method for generating motor behaviors suitable for robotics has garnered several deep learning based improvements to allow associations between sensor information and DMP parameters. While the implementation of deep learning framework does improve upon DMP's inability to directly associate to an input, we found that it has difficulty learning DMP parameters for complex motion which requires large number of basis functions to reconstruct. In this paper we propose a novel deep learning network architecture called Deep Segmented DMP Network (DSDNet) which generates variable-length segmented motion by utilizing the combination of multiple DMP parameters predicting network architecture, double-stage decoder network, and number of segments predictor. The proposed method is evaluated on both artificial data (object cutting & pick-and-place) and real data (object cutting) where our proposed method could achieve high generalization capability, task-achievement, and data-efficiency compared to previous method on generating discontinuous long-horizon motions.
Cream Skimming the Underground: Identifying Relevant Information Points from Online Forums
Aug 03, 2023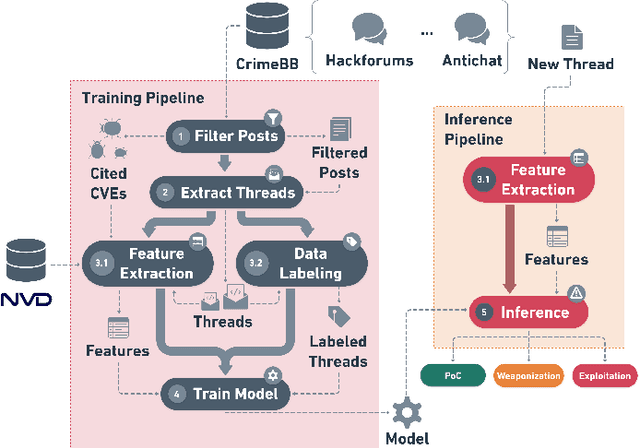
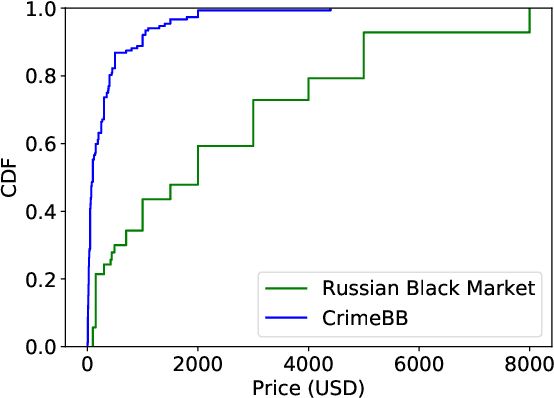
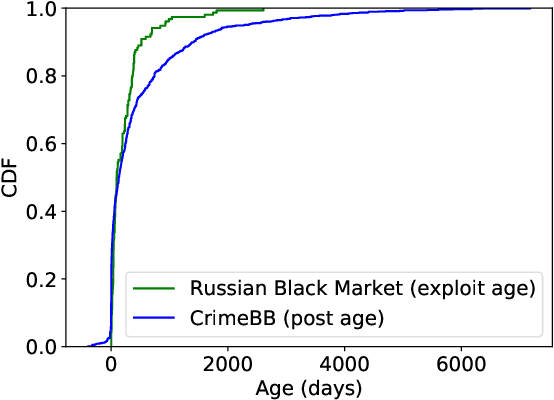
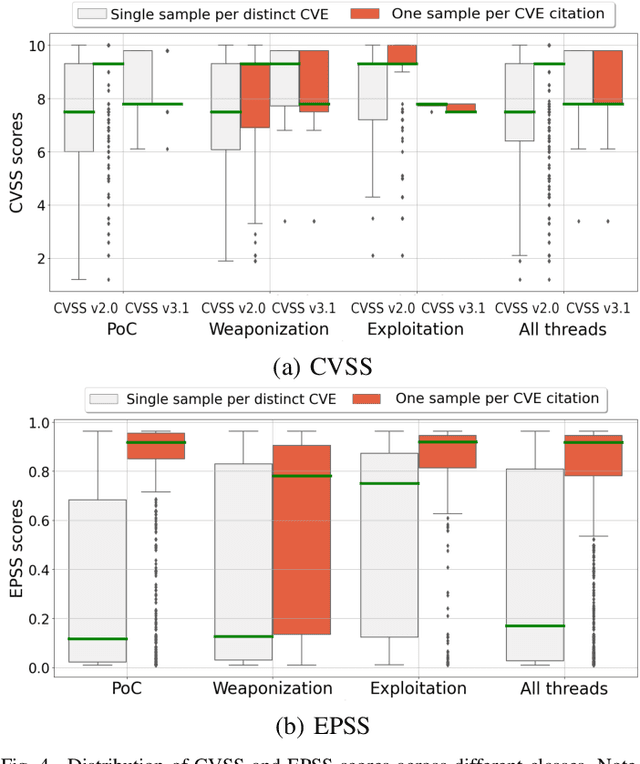
This paper proposes a machine learning-based approach for detecting the exploitation of vulnerabilities in the wild by monitoring underground hacking forums. The increasing volume of posts discussing exploitation in the wild calls for an automatic approach to process threads and posts that will eventually trigger alarms depending on their content. To illustrate the proposed system, we use the CrimeBB dataset, which contains data scraped from multiple underground forums, and develop a supervised machine learning model that can filter threads citing CVEs and label them as Proof-of-Concept, Weaponization, or Exploitation. Leveraging random forests, we indicate that accuracy, precision and recall above 0.99 are attainable for the classification task. Additionally, we provide insights into the difference in nature between weaponization and exploitation, e.g., interpreting the output of a decision tree, and analyze the profits and other aspects related to the hacking communities. Overall, our work sheds insight into the exploitation of vulnerabilities in the wild and can be used to provide additional ground truth to models such as EPSS and Expected Exploitability.
Do You Trust ChatGPT? -- Perceived Credibility of Human and AI-Generated Content
Sep 05, 2023This paper examines how individuals perceive the credibility of content originating from human authors versus content generated by large language models, like the GPT language model family that powers ChatGPT, in different user interface versions. Surprisingly, our results demonstrate that regardless of the user interface presentation, participants tend to attribute similar levels of credibility. While participants also do not report any different perceptions of competence and trustworthiness between human and AI-generated content, they rate AI-generated content as being clearer and more engaging. The findings from this study serve as a call for a more discerning approach to evaluating information sources, encouraging users to exercise caution and critical thinking when engaging with content generated by AI systems.
An Improved Upper Bound on the Rate-Distortion Function of Images
Sep 05, 2023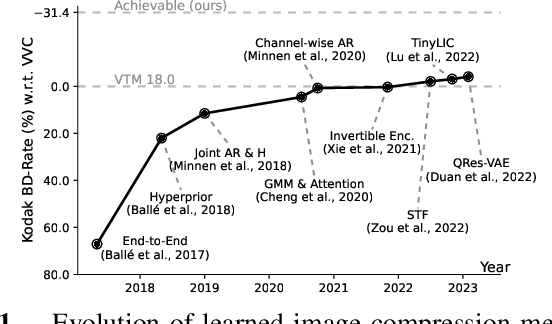

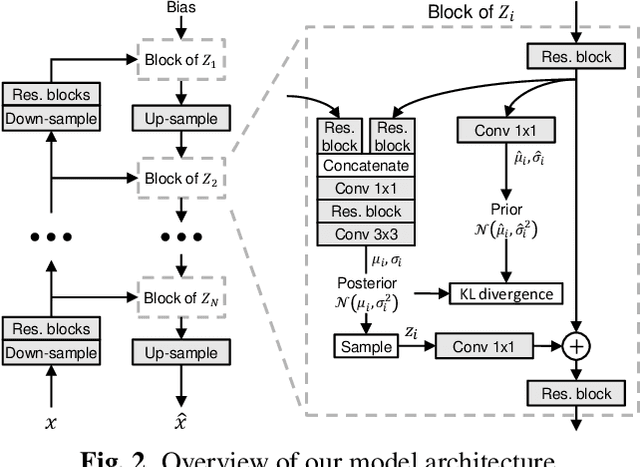
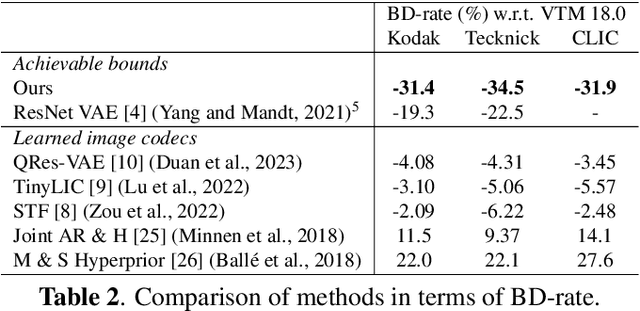
Recent work has shown that Variational Autoencoders (VAEs) can be used to upper-bound the information rate-distortion (R-D) function of images, i.e., the fundamental limit of lossy image compression. In this paper, we report an improved upper bound on the R-D function of images implemented by (1) introducing a new VAE model architecture, (2) applying variable-rate compression techniques, and (3) proposing a novel \ourfunction{} to stabilize training. We demonstrate that at least 30\% BD-rate reduction w.r.t. the intra prediction mode in VVC codec is achievable, suggesting that there is still great potential for improving lossy image compression. Code is made publicly available at https://github.com/duanzhiihao/lossy-vae.