 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Maximizing the performance for microcomb based microwave photonic transversal signal processors
Sep 10, 2023
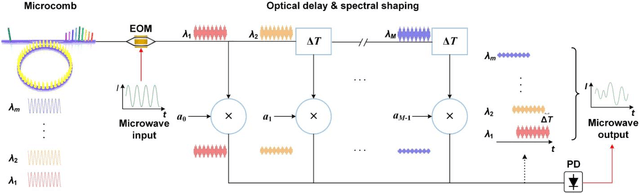

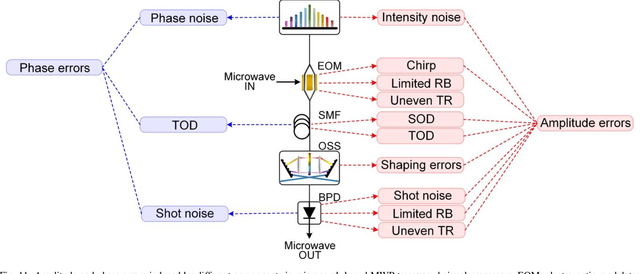
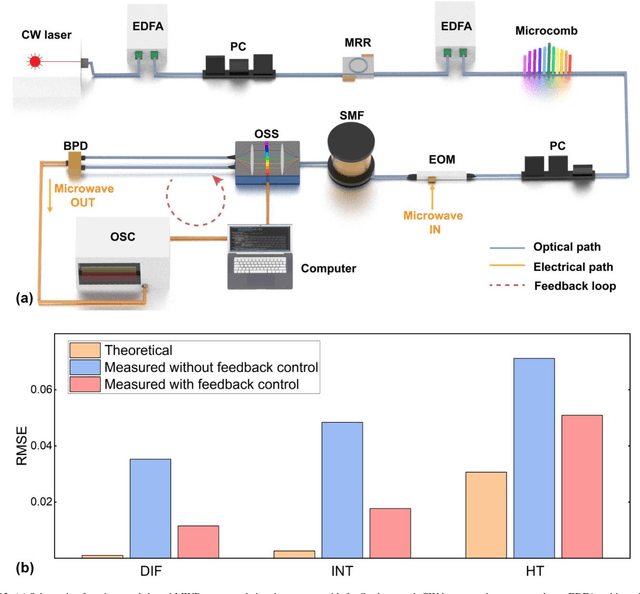
Microwave photonic (MWP) transversal signal processors offer a compelling solution for realizing versatile high-speed information processing by combining the advantages of reconfigurable electrical digital signal processing and high-bandwidth photonic processing. With the capability of generating a number of discrete wavelengths from micro-scale resonators, optical microcombs are powerful multi-wavelength sources for implementing MWP transversal signal processors with significantly reduced size, power consumption, and complexity. By using microcomb-based MWP transversal signal processors, a diverse range of signal processing functions have been demonstrated recently. In this paper, we provide a detailed analysis for the processing inaccuracy that is induced by the imperfect response of experimental components. First, we investigate the errors arising from different sources including imperfections in the microcombs, the chirp of electro-optic modulators, chromatic dispersion of the dispersive module, shaping errors of the optical spectral shapers, and noise of the photodetector. Next, we provide a global picture quantifying the impact of different error sources on the overall system performance. Finally, we introduce feedback control to compensate the errors caused by experimental imperfections and achieve significantly improved accuracy. These results provide a guide for optimizing the accuracy of microcomb-based MWP transversal signal processors.
* 15 pages, 12 figures, 60 references
HopPG: Self-Iterative Program Generation for Multi-Hop Question Answering over Heterogeneous Knowledge
Sep 10, 2023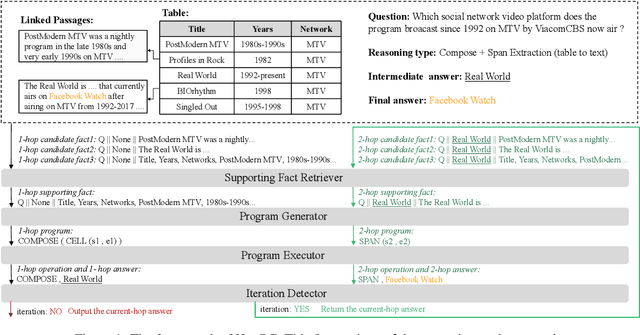


The semantic parsing-based method is an important research branch for knowledge-based question answering. It usually generates executable programs lean upon the question and then conduct them to reason answers over a knowledge base. Benefit from this inherent mechanism, it has advantages in the performance and the interpretability. However, traditional semantic parsing methods usually generate a complete program before executing it, which struggles with multi-hop question answering over heterogeneous knowledge. On one hand, generating a complete multi-hop program relies on multiple heterogeneous supporting facts, and it is difficult for generators to understand these facts simultaneously. On the other hand, this way ignores the semantic information of the intermediate answers at each hop, which is beneficial for subsequent generation. To alleviate these challenges, we propose a self-iterative framework for multi-hop program generation (HopPG) over heterogeneous knowledge, which leverages the previous execution results to retrieve supporting facts and generate subsequent programs hop by hop. We evaluate our model on MMQA-T^2, and the experimental results show that HopPG outperforms existing semantic-parsing-based baselines, especially on the multi-hop questions.
Soft-connected Rigid Body Localization: State-of-the-Art and Research Directions for 6G
Sep 10, 2023This white paper describes a proposed article that will aim to provide a thorough study of the evolution of the typical paradigm of wireless localization (WL), which is based on a single point model of each target, towards wireless rigid body localization (W-RBL). We also look beyond the concept of RBL itself, whereby each target is modeled as an independent multi-point three-dimensional (3D), with shape enforced via a set of conformation constraints, as a step towards a more general approach we refer to as soft-connected RBL, whereby an ensemble of several objects embedded in a given environment, is modeled as a set of soft-connected 3D objects, with rigid and soft conformation constraints enforced within each object and among them, respectively. A first intended contribution of the full version of this article is a compact but comprehensive survey on mechanisms to evolve WL algorithms in W-RBL schemes, considering their peculiarities in terms of the type of information, mathematical approach, and features the build on or offer. A subsequent contribution is a discussion of mechanisms to extend W-RBL techniques to soft-connected rigid body localization (SCW-RBL) algorithms.
Large Language Models in Analyzing Crash Narratives -- A Comparative Study of ChatGPT, BARD and GPT-4
Aug 25, 2023In traffic safety research, extracting information from crash narratives using text analysis is a common practice. With recent advancements of large language models (LLM), it would be useful to know how the popular LLM interfaces perform in classifying or extracting information from crash narratives. To explore this, our study has used the three most popular publicly available LLM interfaces- ChatGPT, BARD and GPT4. This study investigated their usefulness and boundaries in extracting information and answering queries related to accidents from 100 crash narratives from Iowa and Kansas. During the investigation, their capabilities and limitations were assessed and their responses to the queries were compared. Five questions were asked related to the narratives: 1) Who is at-fault? 2) What is the manner of collision? 3) Has the crash occurred in a work-zone? 4) Did the crash involve pedestrians? and 5) What are the sequence of harmful events in the crash? For questions 1 through 4, the overall similarity among the LLMs were 70%, 35%, 96% and 89%, respectively. The similarities were higher while answering direct questions requiring binary responses and significantly lower for complex questions. To compare the responses to question 5, network diagram and centrality measures were analyzed. The network diagram from the three LLMs were not always similar although they sometimes have the same influencing events with high in-degree, out-degree and betweenness centrality. This study suggests using multiple models to extract viable information from narratives. Also, caution must be practiced while using these interfaces to obtain crucial safety related information.
Dual-Path Temporal Map Optimization for Make-up Temporal Video Grounding
Sep 12, 2023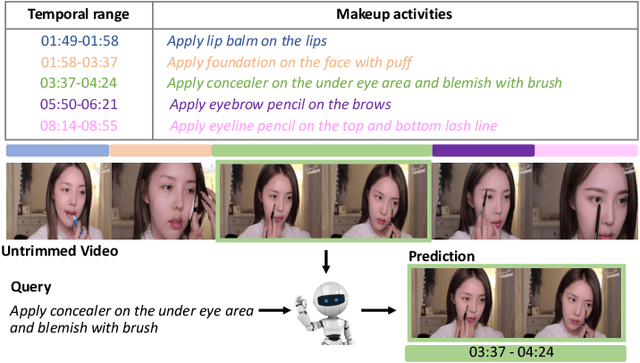
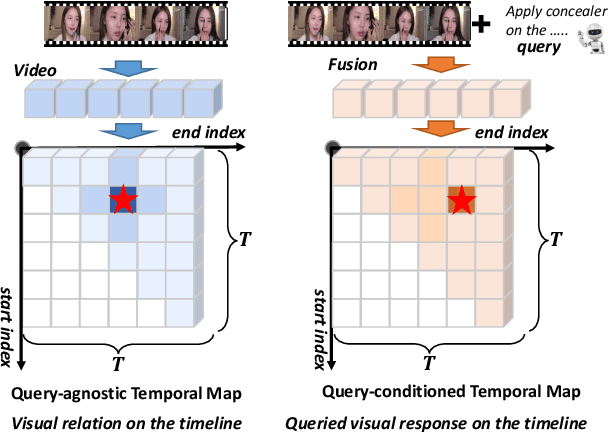
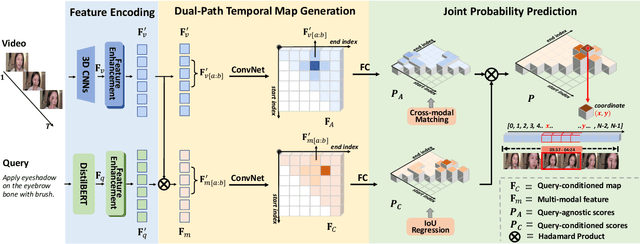
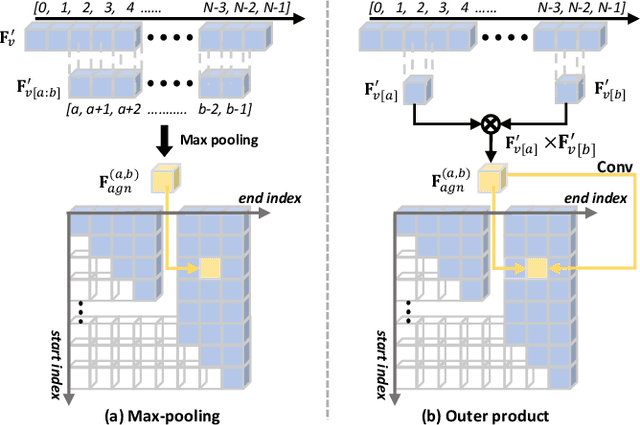
Make-up temporal video grounding (MTVG) aims to localize the target video segment which is semantically related to a sentence describing a make-up activity, given a long video. Compared with the general video grounding task, MTVG focuses on meticulous actions and changes on the face. The make-up instruction step, usually involving detailed differences in products and facial areas, is more fine-grained than general activities (e.g, cooking activity and furniture assembly). Thus, existing general approaches cannot locate the target activity effectually. More specifically, existing proposal generation modules are not yet fully developed in providing semantic cues for the more fine-grained make-up semantic comprehension. To tackle this issue, we propose an effective proposal-based framework named Dual-Path Temporal Map Optimization Network (DPTMO) to capture fine-grained multimodal semantic details of make-up activities. DPTMO extracts both query-agnostic and query-guided features to construct two proposal sets and uses specific evaluation methods for the two sets. Different from the commonly used single structure in previous methods, our dual-path structure can mine more semantic information in make-up videos and distinguish fine-grained actions well. These two candidate sets represent the cross-modal makeup video-text similarity and multi-modal fusion relationship, complementing each other. Each set corresponds to its respective optimization perspective, and their joint prediction enhances the accuracy of video timestamp prediction. Comprehensive experiments on the YouMakeup dataset demonstrate our proposed dual structure excels in fine-grained semantic comprehension.
Normality Learning-based Graph Anomaly Detection via Multi-Scale Contrastive Learning
Sep 12, 2023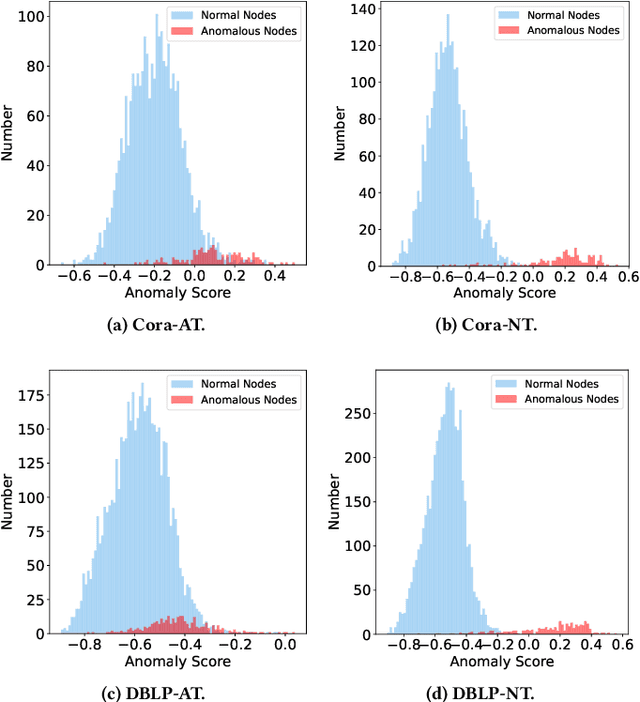
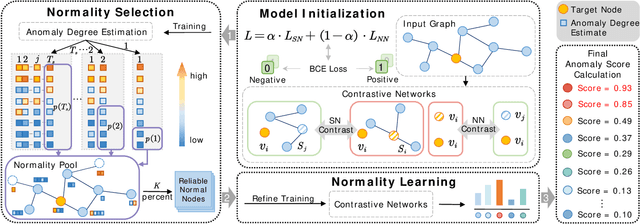
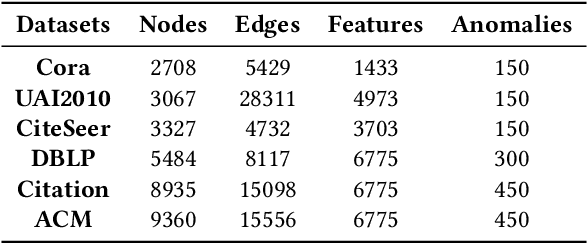
Graph anomaly detection (GAD) has attracted increasing attention in machine learning and data mining. Recent works have mainly focused on how to capture richer information to improve the quality of node embeddings for GAD. Despite their significant advances in detection performance, there is still a relative dearth of research on the properties of the task. GAD aims to discern the anomalies that deviate from most nodes. However, the model is prone to learn the pattern of normal samples which make up the majority of samples. Meanwhile, anomalies can be easily detected when their behaviors differ from normality. Therefore, the performance can be further improved by enhancing the ability to learn the normal pattern. To this end, we propose a normality learning-based GAD framework via multi-scale contrastive learning networks (NLGAD for abbreviation). Specifically, we first initialize the model with the contrastive networks on different scales. To provide sufficient and reliable normal nodes for normality learning, we design an effective hybrid strategy for normality selection. Finally, the model is refined with the only input of reliable normal nodes and learns a more accurate estimate of normality so that anomalous nodes can be more easily distinguished. Eventually, extensive experiments on six benchmark graph datasets demonstrate the effectiveness of our normality learning-based scheme on GAD. Notably, the proposed algorithm improves the detection performance (up to 5.89% AUC gain) compared with the state-of-the-art methods. The source code is released at https://github.com/FelixDJC/NLGAD.
Navigating Out-of-Distribution Electricity Load Forecasting during COVID-19: A Continual Learning Approach Leveraging Human Mobility
Sep 12, 2023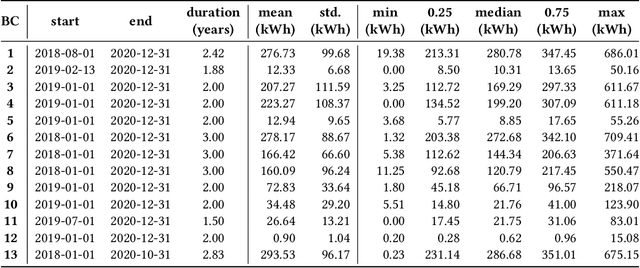
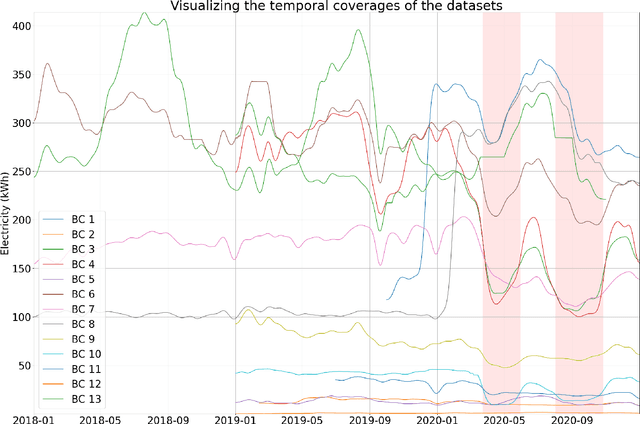
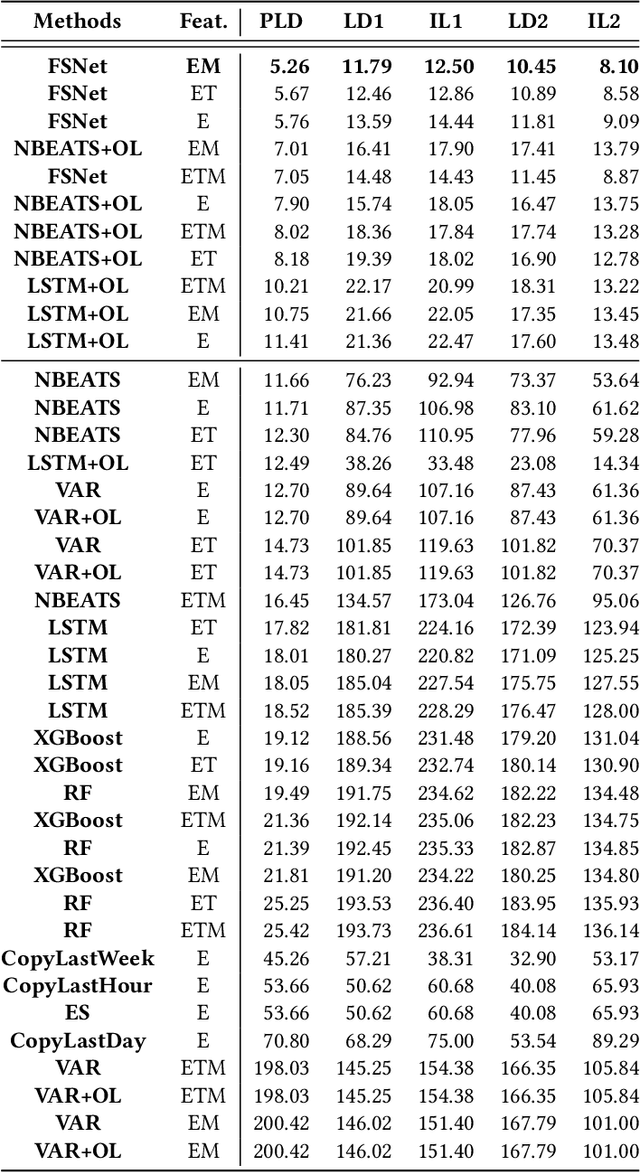
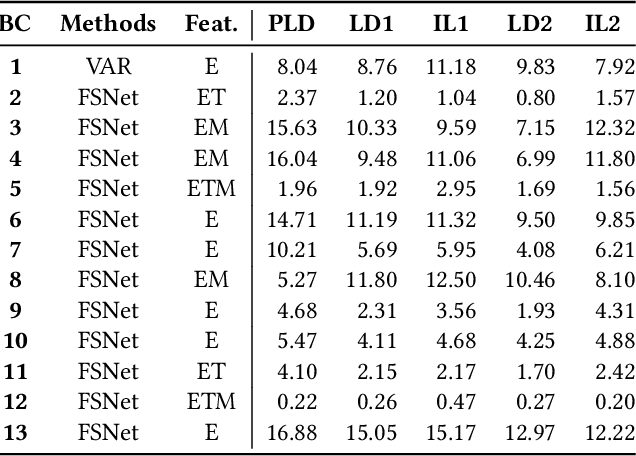
In traditional deep learning algorithms, one of the key assumptions is that the data distribution remains constant during both training and deployment. However, this assumption becomes problematic when faced with Out-of-Distribution periods, such as the COVID-19 lockdowns, where the data distribution significantly deviates from what the model has seen during training. This paper employs a two-fold strategy: utilizing continual learning techniques to update models with new data and harnessing human mobility data collected from privacy-preserving pedestrian counters located outside buildings. In contrast to online learning, which suffers from 'catastrophic forgetting' as newly acquired knowledge often erases prior information, continual learning offers a holistic approach by preserving past insights while integrating new data. This research applies FSNet, a powerful continual learning algorithm, to real-world data from 13 building complexes in Melbourne, Australia, a city which had the second longest total lockdown duration globally during the pandemic. Results underscore the crucial role of continual learning in accurate energy forecasting, particularly during Out-of-Distribution periods. Secondary data such as mobility and temperature provided ancillary support to the primary forecasting model. More importantly, while traditional methods struggled to adapt during lockdowns, models featuring at least online learning demonstrated resilience, with lockdown periods posing fewer challenges once armed with adaptive learning techniques. This study contributes valuable methodologies and insights to the ongoing effort to improve energy load forecasting during future Out-of-Distribution periods.
Knowledge-Enhanced Hierarchical Information Correlation Learning for Multi-Modal Rumor Detection
Jun 28, 2023
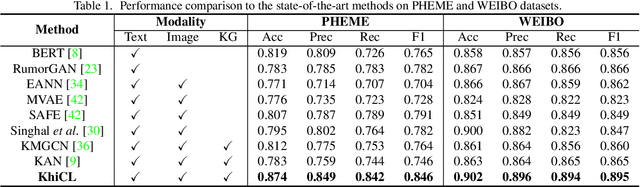
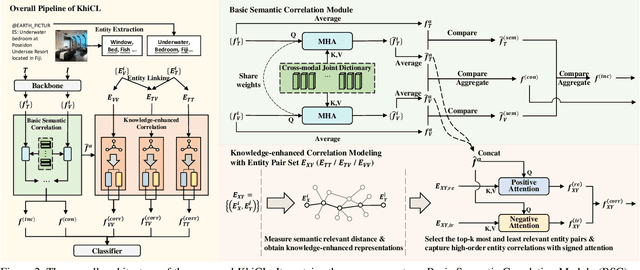
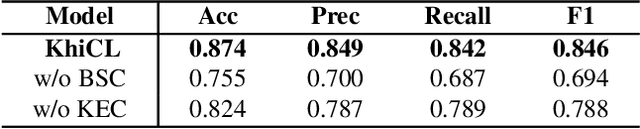
The explosive growth of rumors with text and images on social media platforms has drawn great attention. Existing studies have made significant contributions to cross-modal information interaction and fusion, but they fail to fully explore hierarchical and complex semantic correlation across different modality content, severely limiting their performance on detecting multi-modal rumor. In this work, we propose a novel knowledge-enhanced hierarchical information correlation learning approach (KhiCL) for multi-modal rumor detection by jointly modeling the basic semantic correlation and high-order knowledge-enhanced entity correlation. Specifically, KhiCL exploits cross-modal joint dictionary to transfer the heterogeneous unimodality features into the common feature space and captures the basic cross-modal semantic consistency and inconsistency by a cross-modal fusion layer. Moreover, considering the description of multi-modal content is narrated around entities, KhiCL extracts visual and textual entities from images and text, and designs a knowledge relevance reasoning strategy to find the shortest semantic relevant path between each pair of entities in external knowledge graph, and absorbs all complementary contextual knowledge of other connected entities in this path for learning knowledge-enhanced entity representations. Furthermore, KhiCL utilizes a signed attention mechanism to model the knowledge-enhanced entity consistency and inconsistency of intra-modality and inter-modality entity pairs by measuring their corresponding semantic relevant distance. Extensive experiments have demonstrated the effectiveness of the proposed method.
Data-Driven Information Extraction and Enrichment of Molecular Profiling Data for Cancer Cell Lines
Jul 03, 2023
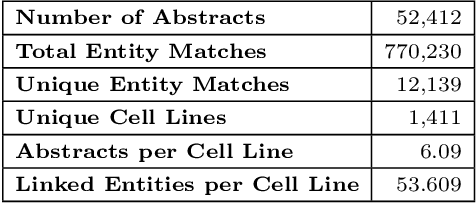

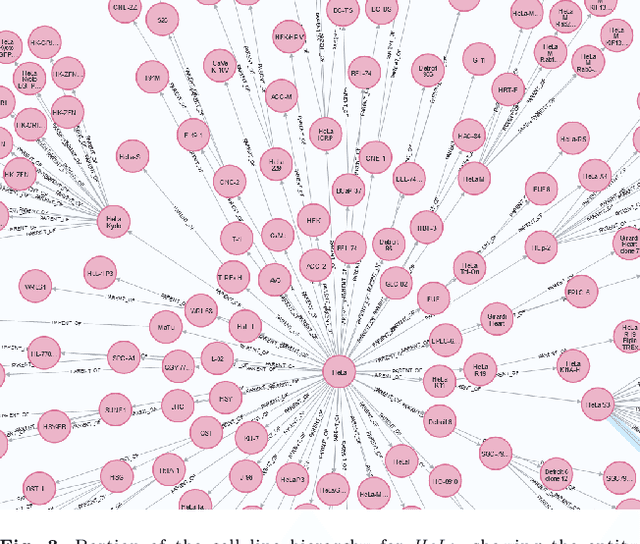
With the proliferation of research means and computational methodologies, published biomedical literature is growing exponentially in numbers and volume. As a consequence, in the fields of biological, medical and clinical research, domain experts have to sift through massive amounts of scientific text to find relevant information. However, this process is extremely tedious and slow to be performed by humans. Hence, novel computational information extraction and correlation mechanisms are required to boost meaningful knowledge extraction. In this work, we present the design, implementation and application of a novel data extraction and exploration system. This system extracts deep semantic relations between textual entities from scientific literature to enrich existing structured clinical data in the domain of cancer cell lines. We introduce a new public data exploration portal, which enables automatic linking of genomic copy number variants plots with ranked, related entities such as affected genes. Each relation is accompanied by literature-derived evidences, allowing for deep, yet rapid, literature search, using existing structured data as a springboard. Our system is publicly available on the web at https://cancercelllines.org
Distributional Data Augmentation Methods for Low Resource Language
Sep 09, 2023Text augmentation is a technique for constructing synthetic data from an under-resourced corpus to improve predictive performance. Synthetic data generation is common in numerous domains. However, recently text augmentation has emerged in natural language processing (NLP) to improve downstream tasks. One of the current state-of-the-art text augmentation techniques is easy data augmentation (EDA), which augments the training data by injecting and replacing synonyms and randomly permuting sentences. One major obstacle with EDA is the need for versatile and complete synonym dictionaries, which cannot be easily found in low-resource languages. To improve the utility of EDA, we propose two extensions, easy distributional data augmentation (EDDA) and type specific similar word replacement (TSSR), which uses semantic word context information and part-of-speech tags for word replacement and augmentation. In an extensive empirical evaluation, we show the utility of the proposed methods, measured by F1 score, on two representative datasets in Swedish as an example of a low-resource language. With the proposed methods, we show that augmented data improve classification performances in low-resource settings.