 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Materials Informatics Transformer: A Language Model for Interpretable Materials Properties Prediction
Sep 01, 2023
Recently, the remarkable capabilities of large language models (LLMs) have been illustrated across a variety of research domains such as natural language processing, computer vision, and molecular modeling. We extend this paradigm by utilizing LLMs for material property prediction by introducing our model Materials Informatics Transformer (MatInFormer). Specifically, we introduce a novel approach that involves learning the grammar of crystallography through the tokenization of pertinent space group information. We further illustrate the adaptability of MatInFormer by incorporating task-specific data pertaining to Metal-Organic Frameworks (MOFs). Through attention visualization, we uncover the key features that the model prioritizes during property prediction. The effectiveness of our proposed model is empirically validated across 14 distinct datasets, hereby underscoring its potential for high throughput screening through accurate material property prediction.
A Smart Robotic System for Industrial Plant Supervision
Sep 01, 2023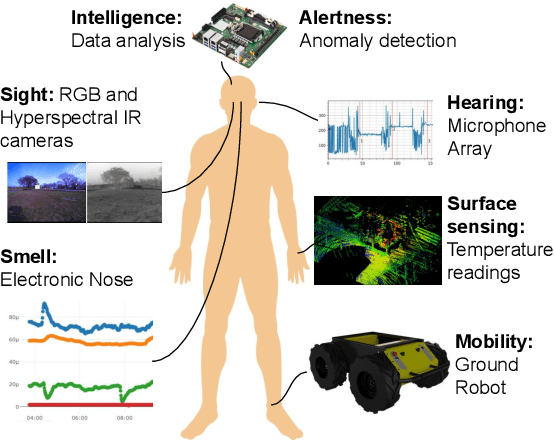

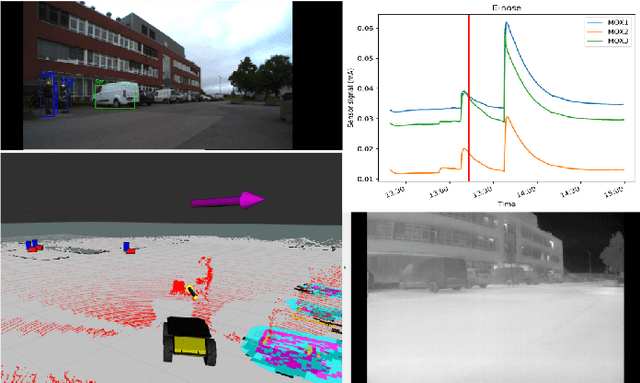
In today's chemical plants, human field operators perform frequent integrity checks to guarantee high safety standards, and thus are possibly the first to encounter dangerous operating conditions. To alleviate their task, we present a system consisting of an autonomously navigating robot integrated with various sensors and intelligent data processing. It is able to detect methane leaks and estimate its flow rate, detect more general gas anomalies, recognize oil films, localize sound sources and detect failure cases, map the environment in 3D, and navigate autonomously, employing recognition and avoidance of dynamic obstacles. We evaluate our system at a wastewater facility in full working conditions. Our results demonstrate that the system is able to robustly navigate the plant and provide useful information about critical operating conditions.
Attention Where It Matters: Rethinking Visual Document Understanding with Selective Region Concentration
Sep 03, 2023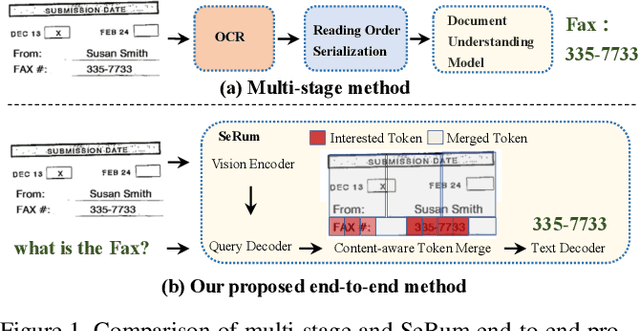
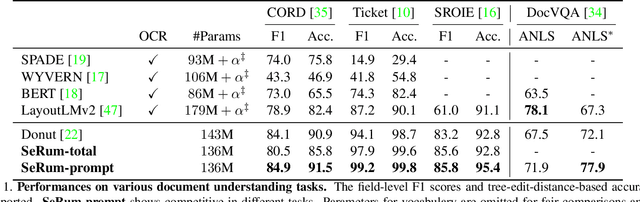
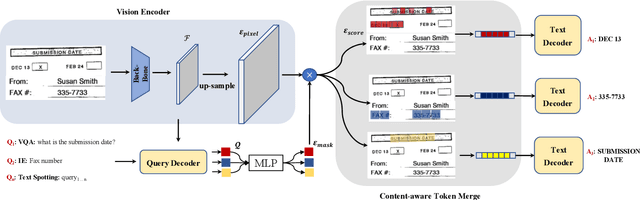

We propose a novel end-to-end document understanding model called SeRum (SElective Region Understanding Model) for extracting meaningful information from document images, including document analysis, retrieval, and office automation. Unlike state-of-the-art approaches that rely on multi-stage technical schemes and are computationally expensive, SeRum converts document image understanding and recognition tasks into a local decoding process of the visual tokens of interest, using a content-aware token merge module. This mechanism enables the model to pay more attention to regions of interest generated by the query decoder, improving the model's effectiveness and speeding up the decoding speed of the generative scheme. We also designed several pre-training tasks to enhance the understanding and local awareness of the model. Experimental results demonstrate that SeRum achieves state-of-the-art performance on document understanding tasks and competitive results on text spotting tasks. SeRum represents a substantial advancement towards enabling efficient and effective end-to-end document understanding.
CARE: Co-Attention Network for Joint Entity and Relation Extraction
Aug 24, 2023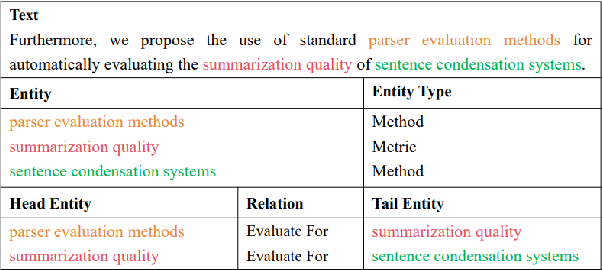
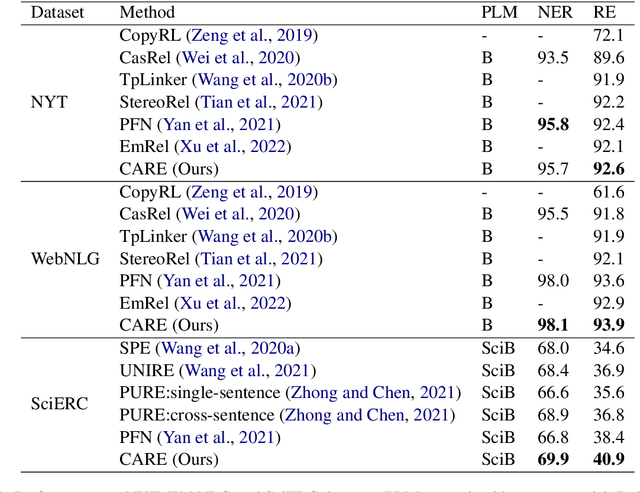
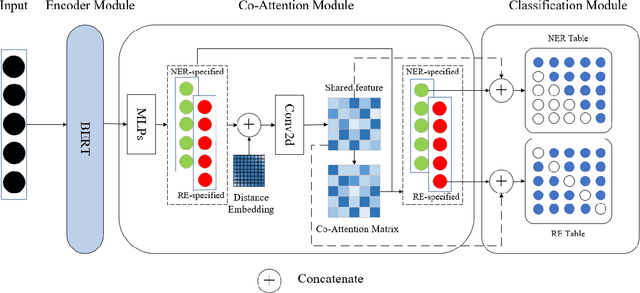
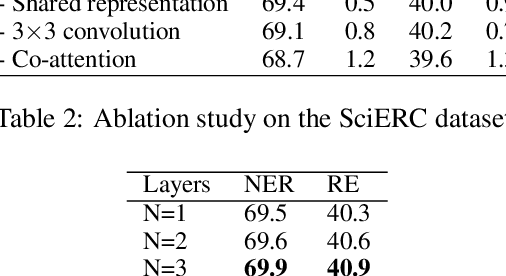
Joint entity and relation extraction is the fundamental task of information extraction, consisting of two subtasks: named entity recognition and relation extraction. Most existing joint extraction methods suffer from issues of feature confusion or inadequate interaction between two subtasks. In this work, we propose a Co-Attention network for joint entity and Relation Extraction (CARE). Our approach involves learning separate representations for each subtask, aiming to avoid feature overlap. At the core of our approach is the co-attention module that captures two-way interaction between two subtasks, allowing the model to leverage entity information for relation prediction and vice versa, thus promoting mutual enhancement. Extensive experiments on three joint entity-relation extraction benchmark datasets (NYT, WebNLG and SciERC) show that our proposed model achieves superior performance, surpassing existing baseline models.
Face Encryption via Frequency-Restricted Identity-Agnostic Attacks
Aug 25, 2023
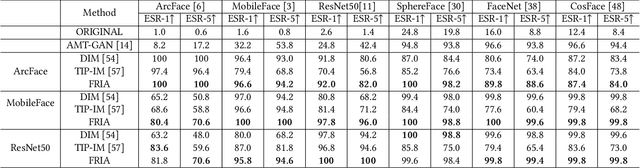
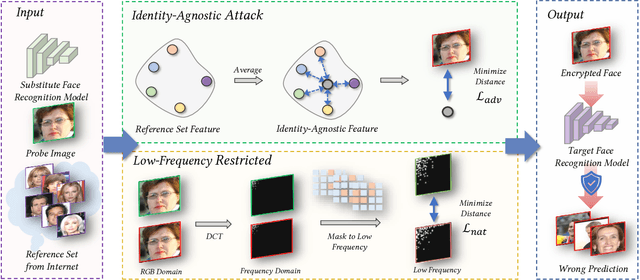
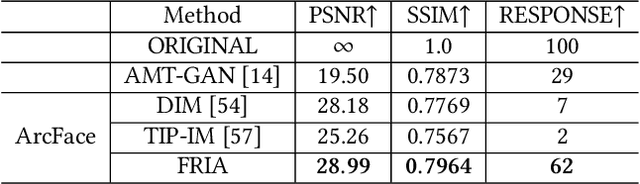
Billions of people are sharing their daily live images on social media everyday. However, malicious collectors use deep face recognition systems to easily steal their biometric information (e.g., faces) from these images. Some studies are being conducted to generate encrypted face photos using adversarial attacks by introducing imperceptible perturbations to reduce face information leakage. However, existing studies need stronger black-box scenario feasibility and more natural visual appearances, which challenge the feasibility of privacy protection. To address these problems, we propose a frequency-restricted identity-agnostic (FRIA) framework to encrypt face images from unauthorized face recognition without access to personal information. As for the weak black-box scenario feasibility, we obverse that representations of the average feature in multiple face recognition models are similar, thus we propose to utilize the average feature via the crawled dataset from the Internet as the target to guide the generation, which is also agnostic to identities of unknown face recognition systems; in nature, the low-frequency perturbations are more visually perceptible by the human vision system. Inspired by this, we restrict the perturbation in the low-frequency facial regions by discrete cosine transform to achieve the visual naturalness guarantee. Extensive experiments on several face recognition models demonstrate that our FRIA outperforms other state-of-the-art methods in generating more natural encrypted faces while attaining high black-box attack success rates of 96%. In addition, we validate the efficacy of FRIA using real-world black-box commercial API, which reveals the potential of FRIA in practice. Our codes can be found in https://github.com/XinDong10/FRIA.
"Would life be more interesting if I were in AI?" Answering Counterfactuals based on Probabilistic Inductive Logic Programming
Aug 30, 2023Probabilistic logic programs are logic programs where some facts hold with a specified probability. Here, we investigate these programs with a causal framework that allows counterfactual queries. Learning the program structure from observational data is usually done through heuristic search relying on statistical tests. However, these statistical tests lack information about the causal mechanism generating the data, which makes it unfeasible to use the resulting programs for counterfactual reasoning. To address this, we propose a language fragment that allows reconstructing a program from its induced distribution. This further enables us to learn programs supporting counterfactual queries.
* In Proceedings ICLP 2023, arXiv:2308.14898
Task-Based MoE for Multitask Multilingual Machine Translation
Aug 30, 2023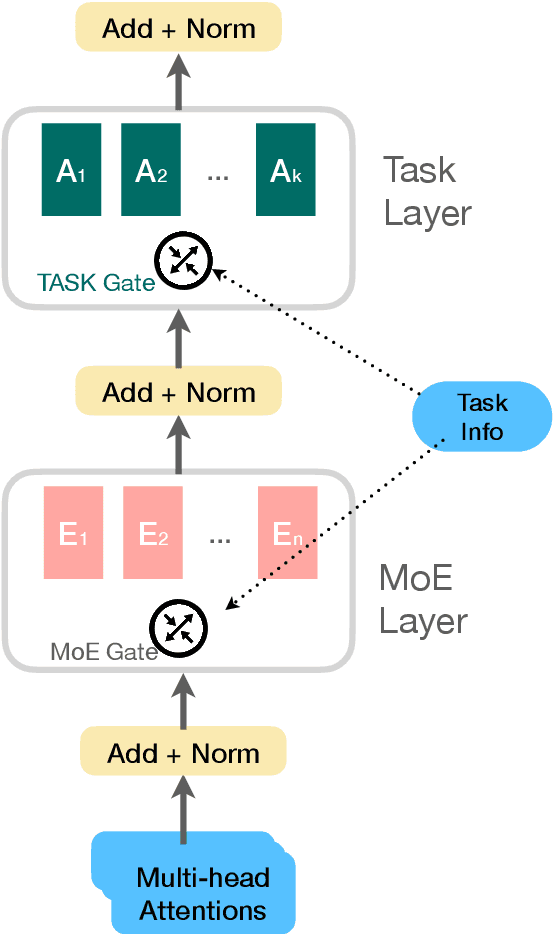
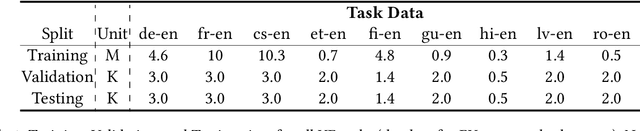
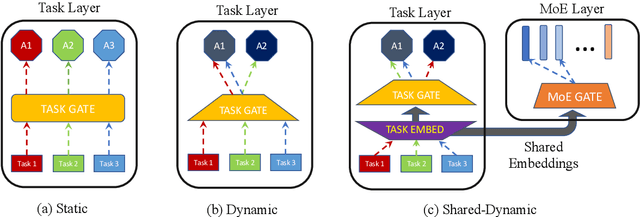
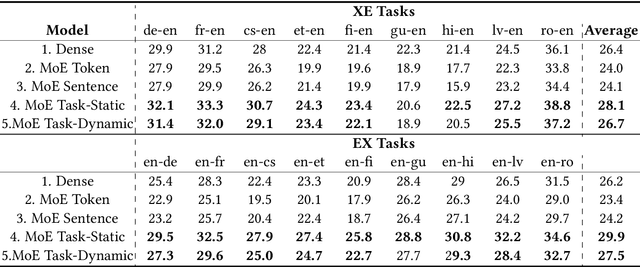
Mixture-of-experts (MoE) architecture has been proven a powerful method for diverse tasks in training deep models in many applications. However, current MoE implementations are task agnostic, treating all tokens from different tasks in the same manner. In this work, we instead design a novel method that incorporates task information into MoE models at different granular levels with shared dynamic task-based adapters. Our experiments and analysis show the advantages of our approaches over the dense and canonical MoE models on multi-task multilingual machine translations. With task-specific adapters, our models can additionally generalize to new tasks efficiently.
StreamMapNet: Streaming Mapping Network for Vectorized Online HD Map Construction
Aug 27, 2023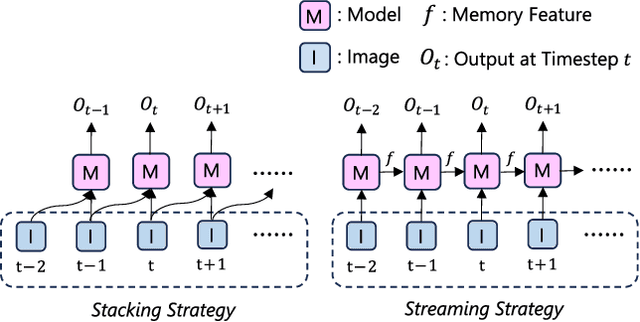
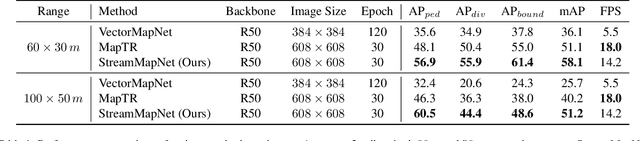
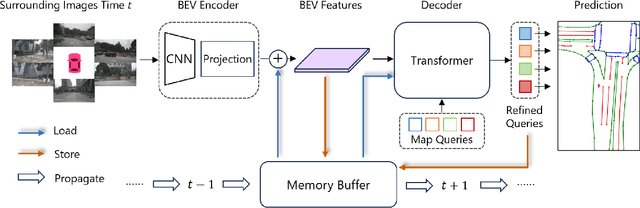
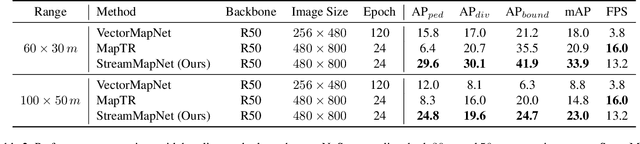
High-Definition (HD) maps are essential for the safety of autonomous driving systems. While existing techniques employ camera images and onboard sensors to generate vectorized high-precision maps, they are constrained by their reliance on single-frame input. This approach limits their stability and performance in complex scenarios such as occlusions, largely due to the absence of temporal information. Moreover, their performance diminishes when applied to broader perception ranges. In this paper, we present StreamMapNet, a novel online mapping pipeline adept at long-sequence temporal modeling of videos. StreamMapNet employs multi-point attention and temporal information which empowers the construction of large-range local HD maps with high stability and further addresses the limitations of existing methods. Furthermore, we critically examine widely used online HD Map construction benchmark and datasets, Argoverse2 and nuScenes, revealing significant bias in the existing evaluation protocols. We propose to resplit the benchmarks according to geographical spans, promoting fair and precise evaluations. Experimental results validate that StreamMapNet significantly outperforms existing methods across all settings while maintaining an online inference speed of $14.2$ FPS. Our code is available at https://github.com/yuantianyuan01/StreamMapNet.
Learning Compact Compositional Embeddings via Regularized Pruning for Recommendation
Sep 08, 2023
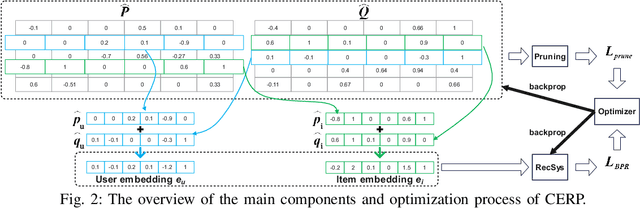
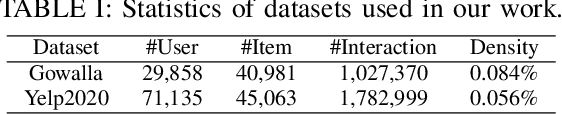
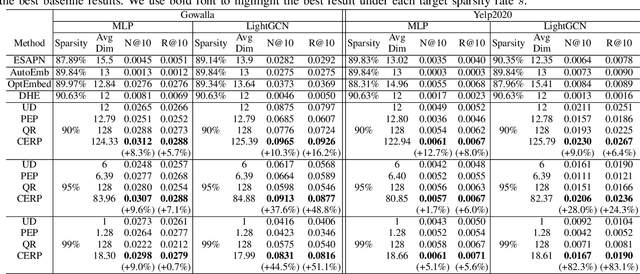
Latent factor models are the dominant backbones of contemporary recommender systems (RSs) given their performance advantages, where a unique vector embedding with a fixed dimensionality (e.g., 128) is required to represent each entity (commonly a user/item). Due to the large number of users and items on e-commerce sites, the embedding table is arguably the least memory-efficient component of RSs. For any lightweight recommender that aims to efficiently scale with the growing size of users/items or to remain applicable in resource-constrained settings, existing solutions either reduce the number of embeddings needed via hashing, or sparsify the full embedding table to switch off selected embedding dimensions. However, as hash collision arises or embeddings become overly sparse, especially when adapting to a tighter memory budget, those lightweight recommenders inevitably have to compromise their accuracy. To this end, we propose a novel compact embedding framework for RSs, namely Compositional Embedding with Regularized Pruning (CERP). Specifically, CERP represents each entity by combining a pair of embeddings from two independent, substantially smaller meta-embedding tables, which are then jointly pruned via a learnable element-wise threshold. In addition, we innovatively design a regularized pruning mechanism in CERP, such that the two sparsified meta-embedding tables are encouraged to encode information that is mutually complementary. Given the compatibility with agnostic latent factor models, we pair CERP with two popular recommendation models for extensive experiments, where results on two real-world datasets under different memory budgets demonstrate its superiority against state-of-the-art baselines. The codebase of CERP is available in https://github.com/xurong-liang/CERP.
Stereo Matching in Time: 100+ FPS Video Stereo Matching for Extended Reality
Sep 08, 2023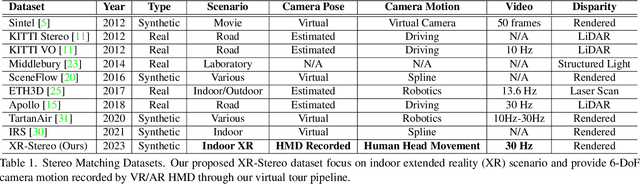
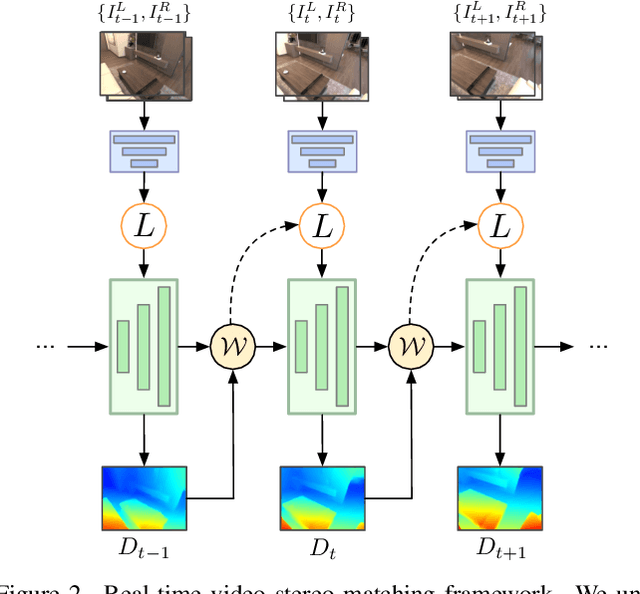
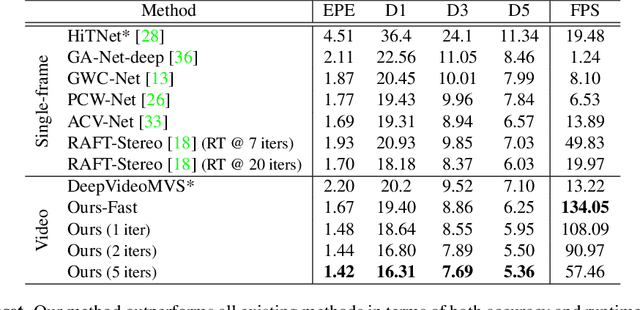
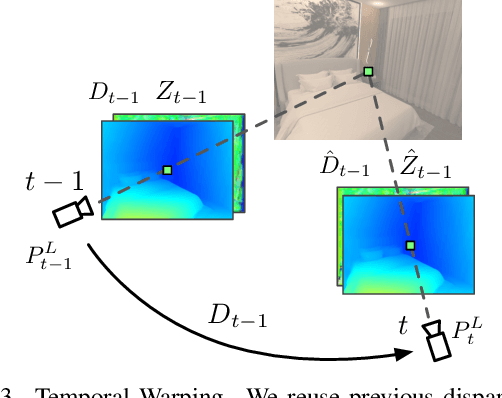
Real-time Stereo Matching is a cornerstone algorithm for many Extended Reality (XR) applications, such as indoor 3D understanding, video pass-through, and mixed-reality games. Despite significant advancements in deep stereo methods, achieving real-time depth inference with high accuracy on a low-power device remains a major challenge. One of the major difficulties is the lack of high-quality indoor video stereo training datasets captured by head-mounted VR/AR glasses. To address this issue, we introduce a novel video stereo synthetic dataset that comprises photorealistic renderings of various indoor scenes and realistic camera motion captured by a 6-DoF moving VR/AR head-mounted display (HMD). This facilitates the evaluation of existing approaches and promotes further research on indoor augmented reality scenarios. Our newly proposed dataset enables us to develop a novel framework for continuous video-rate stereo matching. As another contribution, our dataset enables us to proposed a new video-based stereo matching approach tailored for XR applications, which achieves real-time inference at an impressive 134fps on a standard desktop computer, or 30fps on a battery-powered HMD. Our key insight is that disparity and contextual information are highly correlated and redundant between consecutive stereo frames. By unrolling an iterative cost aggregation in time (i.e. in the temporal dimension), we are able to distribute and reuse the aggregated features over time. This approach leads to a substantial reduction in computation without sacrificing accuracy. We conducted extensive evaluations and comparisons and demonstrated that our method achieves superior performance compared to the current state-of-the-art, making it a strong contender for real-time stereo matching in VR/AR applications.