 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CS-Mixer: A Cross-Scale Vision MLP Model with Spatial-Channel Mixing
Aug 25, 2023
Despite their simpler information fusion designs compared with Vision Transformers and Convolutional Neural Networks, Vision MLP architectures have demonstrated strong performance and high data efficiency in recent research. However, existing works such as CycleMLP and Vision Permutator typically model spatial information in equal-size spatial regions and do not consider cross-scale spatial interactions. Further, their token mixers only model 1- or 2-axis correlations, avoiding 3-axis spatial-channel mixing due to its computational demands. We therefore propose CS-Mixer, a hierarchical Vision MLP that learns dynamic low-rank transformations for spatial-channel mixing through cross-scale local and global aggregation. The proposed methodology achieves competitive results on popular image recognition benchmarks without incurring substantially more compute. Our largest model, CS-Mixer-L, reaches 83.2% top-1 accuracy on ImageNet-1k with 13.7 GFLOPs and 94 M parameters.
Does Character-level Information Always Improve DRS-based Semantic Parsing?
Jun 04, 2023
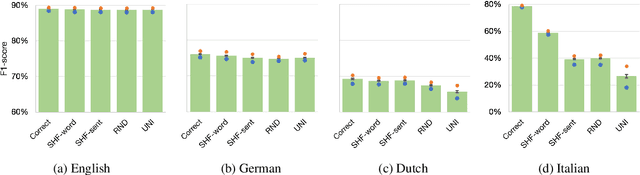
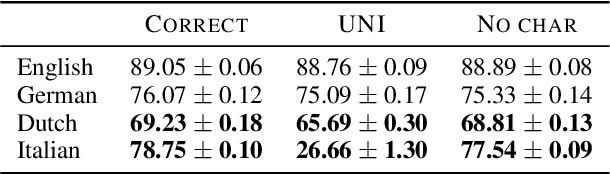
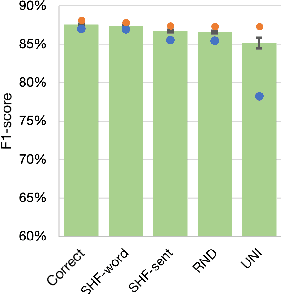
Even in the era of massive language models, it has been suggested that character-level representations improve the performance of neural models. The state-of-the-art neural semantic parser for Discourse Representation Structures uses character-level representations, improving performance in the four languages (i.e., English, German, Dutch, and Italian) in the Parallel Meaning Bank dataset. However, how and why character-level information improves the parser's performance remains unclear. This study provides an in-depth analysis of performance changes by order of character sequences. In the experiments, we compare F1-scores by shuffling the order and randomizing character sequences after testing the performance of character-level information. Our results indicate that incorporating character-level information does not improve the performance in English and German. In addition, we find that the parser is not sensitive to correct character order in Dutch. Nevertheless, performance improvements are observed when using character-level information.
Occlusion-Aware Deep Convolutional Neural Network via Homogeneous Tanh-transforms for Face Parsing
Aug 29, 2023Face parsing infers a pixel-wise label map for each semantic facial component. Previous methods generally work well for uncovered faces, however overlook the facial occlusion and ignore some contextual area outside a single face, especially when facial occlusion has become a common situation during the COVID-19 epidemic. Inspired by the illumination theory of image, we propose a novel homogeneous tanh-transforms for image preprocessing, which made up of four tanh-transforms, that fuse the central vision and the peripheral vision together. Our proposed method addresses the dilemma of face parsing under occlusion and compresses more information of surrounding context. Based on homogeneous tanh-transforms, we propose an occlusion-aware convolutional neural network for occluded face parsing. It combines the information both in Tanh-polar space and Tanh-Cartesian space, capable of enhancing receptive fields. Furthermore, we introduce an occlusion-aware loss to focus on the boundaries of occluded regions. The network is simple and flexible, and can be trained end-to-end. To facilitate future research of occluded face parsing, we also contribute a new cleaned face parsing dataset, which is manually purified from several academic or industrial datasets, including CelebAMask-HQ, Short-video Face Parsing as well as Helen dataset and will make it public. Experiments demonstrate that our method surpasses state-of-art methods of face parsing under occlusion.
Complementing Onboard Sensors with Satellite Map: A New Perspective for HD Map Construction
Aug 29, 2023
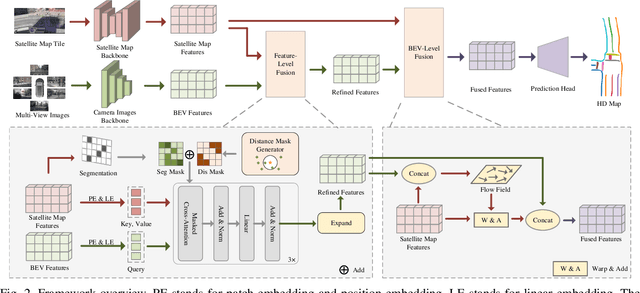
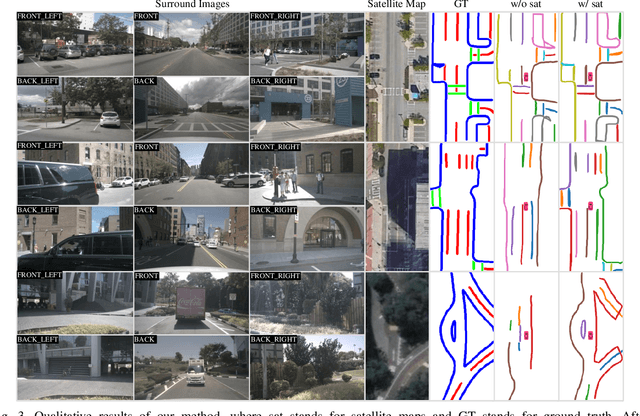
High-Definition (HD) maps play a crucial role in autonomous driving systems. Recent methods have attempted to construct HD maps in real-time based on information obtained from vehicle onboard sensors. However, the performance of these methods is significantly susceptible to the environment surrounding the vehicle due to the inherent limitation of onboard sensors, such as weak capacity for long-range detection. In this study, we demonstrate that supplementing onboard sensors with satellite maps can enhance the performance of HD map construction methods, leveraging the broad coverage capability of satellite maps. For the purpose of further research, we release the satellite map tiles as a complementary dataset of nuScenes dataset. Meanwhile, we propose a hierarchical fusion module that enables better fusion of satellite maps information with existing methods. Specifically, we design an attention mask based on segmentation and distance, applying the cross-attention mechanism to fuse onboard Bird's Eye View (BEV) features and satellite features in feature-level fusion. An alignment module is introduced before concatenation in BEV-level fusion to mitigate the impact of misalignment between the two features. The experimental results on the augmented nuScenes dataset showcase the seamless integration of our module into three existing HD map construction methods. It notably enhances their performance in both HD map semantic segmentation and instance detection tasks.
High Dynamic Range Imaging of Dynamic Scenes with Saturation Compensation but without Explicit Motion Compensation
Aug 22, 2023

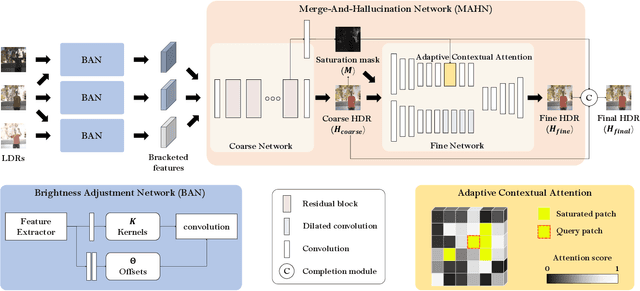
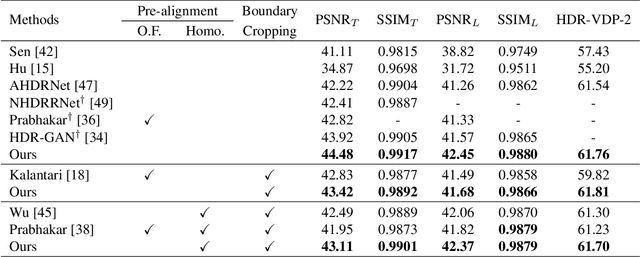
High dynamic range (HDR) imaging is a highly challenging task since a large amount of information is lost due to the limitations of camera sensors. For HDR imaging, some methods capture multiple low dynamic range (LDR) images with altering exposures to aggregate more information. However, these approaches introduce ghosting artifacts when significant inter-frame motions are present. Moreover, although multi-exposure images are given, we have little information in severely over-exposed areas. Most existing methods focus on motion compensation, i.e., alignment of multiple LDR shots to reduce the ghosting artifacts, but they still produce unsatisfying results. These methods also rather overlook the need to restore the saturated areas. In this paper, we generate well-aligned multi-exposure features by reformulating a motion alignment problem into a simple brightness adjustment problem. In addition, we propose a coarse-to-fine merging strategy with explicit saturation compensation. The saturated areas are reconstructed with similar well-exposed content using adaptive contextual attention. We demonstrate that our method outperforms the state-of-the-art methods regarding qualitative and quantitative evaluations.
WMFormer++: Nested Transformer for Visible Watermark Removal via Implict Joint Learning
Aug 22, 2023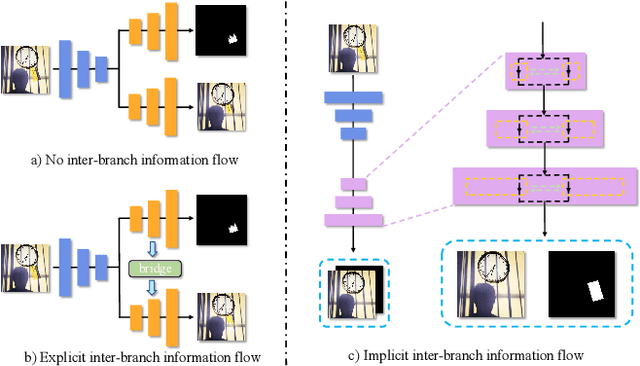
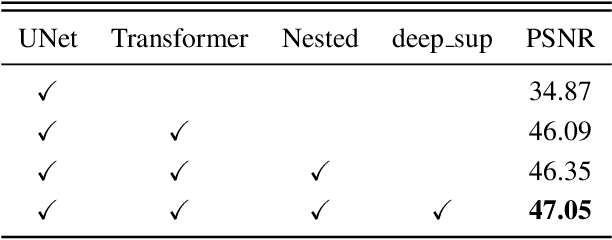

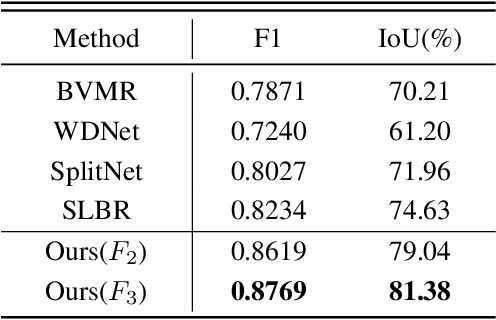
Watermarking serves as a widely adopted approach to safeguard media copyright. In parallel, the research focus has extended to watermark removal techniques, offering an adversarial means to enhance watermark robustness and foster advancements in the watermarking field. Existing watermark removal methods mainly rely on UNet with task-specific decoder branches--one for watermark localization and the other for background image restoration. However, watermark localization and background restoration are not isolated tasks; precise watermark localization inherently implies regions necessitating restoration, and the background restoration process contributes to more accurate watermark localization. To holistically integrate information from both branches, we introduce an implicit joint learning paradigm. This empowers the network to autonomously navigate the flow of information between implicit branches through a gate mechanism. Furthermore, we employ cross-channel attention to facilitate local detail restoration and holistic structural comprehension, while harnessing nested structures to integrate multi-scale information. Extensive experiments are conducted on various challenging benchmarks to validate the effectiveness of our proposed method. The results demonstrate our approach's remarkable superiority, surpassing existing state-of-the-art methods by a large margin.
Link Prediction for Wikipedia Articles as a Natural Language Inference Task
Sep 05, 2023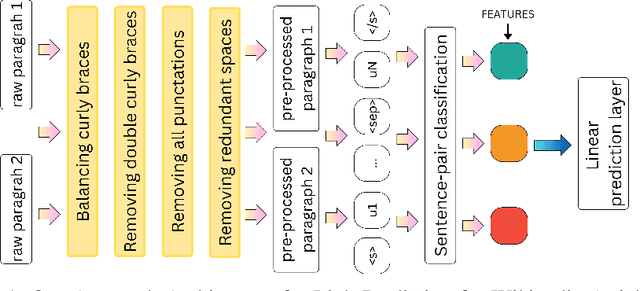
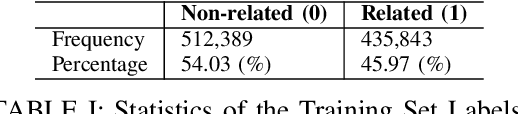
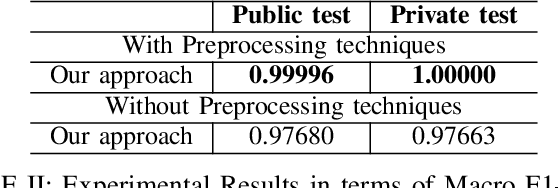
Link prediction task is vital to automatically understanding the structure of large knowledge bases. In this paper, we present our system to solve this task at the Data Science and Advanced Analytics 2023 Competition "Efficient and Effective Link Prediction" (DSAA-2023 Competition) with a corpus containing 948,233 training and 238,265 for public testing. This paper introduces an approach to link prediction in Wikipedia articles by formulating it as a natural language inference (NLI) task. Drawing inspiration from recent advancements in natural language processing and understanding, we cast link prediction as an NLI task, wherein the presence of a link between two articles is treated as a premise, and the task is to determine whether this premise holds based on the information presented in the articles. We implemented our system based on the Sentence Pair Classification for Link Prediction for the Wikipedia Articles task. Our system achieved 0.99996 Macro F1-score and 1.00000 Macro F1-score for the public and private test sets, respectively. Our team UIT-NLP ranked 3rd in performance on the private test set, equal to the scores of the first and second places. Our code is publicly for research purposes.
Robustness and Generalizability of Deepfake Detection: A Study with Diffusion Models
Sep 05, 2023
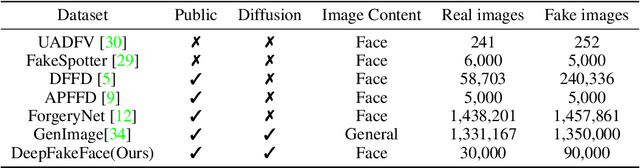
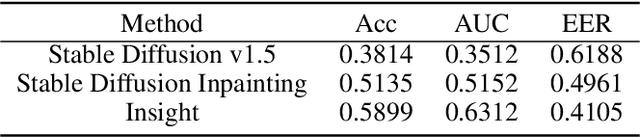

The rise of deepfake images, especially of well-known personalities, poses a serious threat to the dissemination of authentic information. To tackle this, we present a thorough investigation into how deepfakes are produced and how they can be identified. The cornerstone of our research is a rich collection of artificial celebrity faces, titled DeepFakeFace (DFF). We crafted the DFF dataset using advanced diffusion models and have shared it with the community through online platforms. This data serves as a robust foundation to train and test algorithms designed to spot deepfakes. We carried out a thorough review of the DFF dataset and suggest two evaluation methods to gauge the strength and adaptability of deepfake recognition tools. The first method tests whether an algorithm trained on one type of fake images can recognize those produced by other methods. The second evaluates the algorithm's performance with imperfect images, like those that are blurry, of low quality, or compressed. Given varied results across deepfake methods and image changes, our findings stress the need for better deepfake detectors. Our DFF dataset and tests aim to boost the development of more effective tools against deepfakes.
An Automatic Evaluation Framework for Multi-turn Medical Consultations Capabilities of Large Language Models
Sep 05, 2023Large language models (LLMs) have achieved significant success in interacting with human. However, recent studies have revealed that these models often suffer from hallucinations, leading to overly confident but incorrect judgments. This limits their application in the medical domain, where tasks require the utmost accuracy. This paper introduces an automated evaluation framework that assesses the practical capabilities of LLMs as virtual doctors during multi-turn consultations. Consultation tasks are designed to require LLMs to be aware of what they do not know, to inquire about missing medical information from patients, and to ultimately make diagnoses. To evaluate the performance of LLMs for these tasks, a benchmark is proposed by reformulating medical multiple-choice questions from the United States Medical Licensing Examinations (USMLE), and comprehensive evaluation metrics are developed and evaluated on three constructed test sets. A medical consultation training set is further constructed to improve the consultation ability of LLMs. The results of the experiments show that fine-tuning with the training set can alleviate hallucinations and improve LLMs' performance on the proposed benchmark. Extensive experiments and ablation studies are conducted to validate the effectiveness and robustness of the proposed framework.
CIEM: Contrastive Instruction Evaluation Method for Better Instruction Tuning
Sep 05, 2023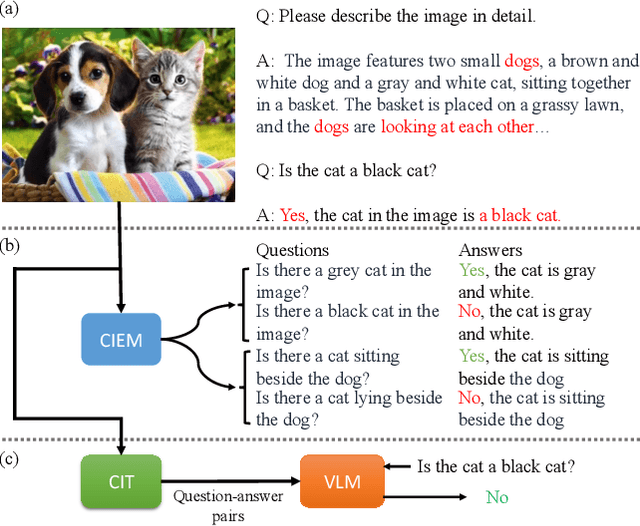

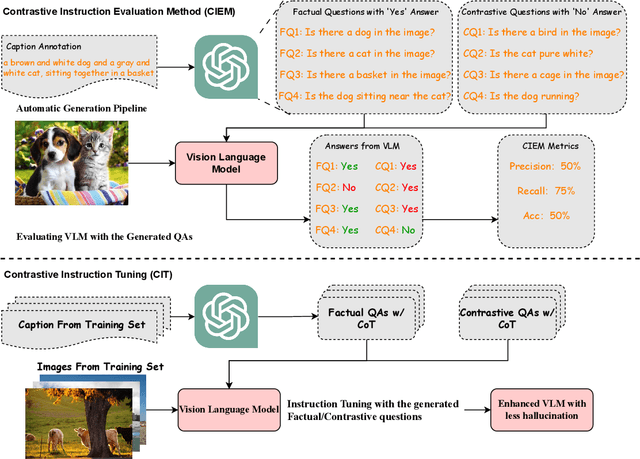

Nowadays, the research on Large Vision-Language Models (LVLMs) has been significantly promoted thanks to the success of Large Language Models (LLM). Nevertheless, these Vision-Language Models (VLMs) are suffering from the drawback of hallucination -- due to insufficient understanding of vision and language modalities, VLMs may generate incorrect perception information when doing downstream applications, for example, captioning a non-existent entity. To address the hallucination phenomenon, on the one hand, we introduce a Contrastive Instruction Evaluation Method (CIEM), which is an automatic pipeline that leverages an annotated image-text dataset coupled with an LLM to generate factual/contrastive question-answer pairs for the evaluation of the hallucination of VLMs. On the other hand, based on CIEM, we further propose a new instruction tuning method called CIT (the abbreviation of Contrastive Instruction Tuning) to alleviate the hallucination of VLMs by automatically producing high-quality factual/contrastive question-answer pairs and corresponding justifications for model tuning. Through extensive experiments on CIEM and CIT, we pinpoint the hallucination issues commonly present in existing VLMs, the disability of the current instruction-tuning dataset to handle the hallucination phenomenon and the superiority of CIT-tuned VLMs over both CIEM and public datasets.