 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fragment and Integrate Network (FIN): A Novel Spatial-Temporal Modeling Based on Long Sequential Behavior for Online Food Ordering Click-Through Rate Prediction
Aug 30, 2023
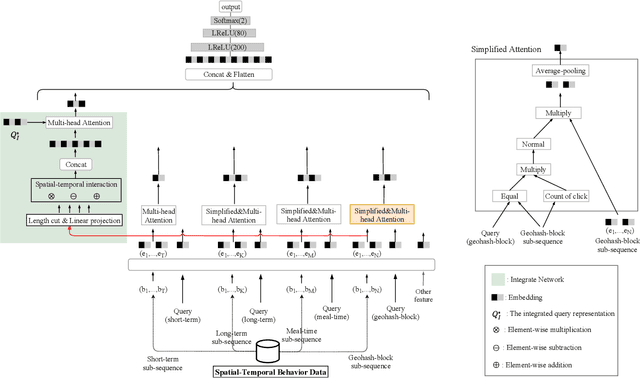

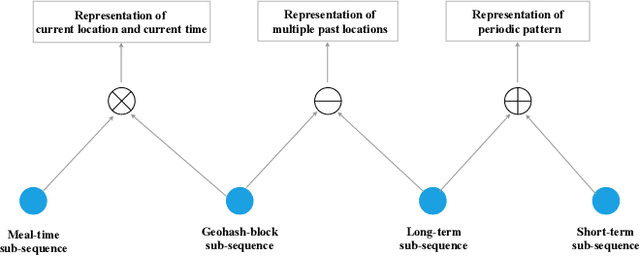
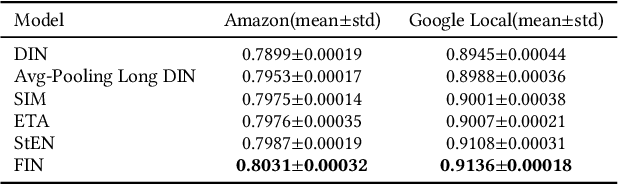
Spatial-temporal information has been proven to be of great significance for click-through rate prediction tasks in online Location-Based Services (LBS), especially in mainstream food ordering platforms such as DoorDash, Uber Eats, Meituan, and Ele.me. Modeling user spatial-temporal preferences with sequential behavior data has become a hot topic in recommendation systems and online advertising. However, most of existing methods either lack the representation of rich spatial-temporal information or only handle user behaviors with limited length, e.g. 100. In this paper, we tackle these problems by designing a new spatial-temporal modeling paradigm named Fragment and Integrate Network (FIN). FIN consists of two networks: (i) Fragment Network (FN) extracts Multiple Sub-Sequences (MSS) from lifelong sequential behavior data, and captures the specific spatial-temporal representation by modeling each MSS respectively. Here both a simplified attention and a complicated attention are adopted to balance the performance gain and resource consumption. (ii) Integrate Network (IN) builds a new integrated sequence by utilizing spatial-temporal interaction on MSS and captures the comprehensive spatial-temporal representation by modeling the integrated sequence with a complicated attention. Both public datasets and production datasets have demonstrated the accuracy and scalability of FIN. Since 2022, FIN has been fully deployed in the recommendation advertising system of Ele.me, one of the most popular online food ordering platforms in China, obtaining 5.7% improvement on Click-Through Rate (CTR) and 7.3% increase on Revenue Per Mille (RPM).
TransFace: Calibrating Transformer Training for Face Recognition from a Data-Centric Perspective
Aug 20, 2023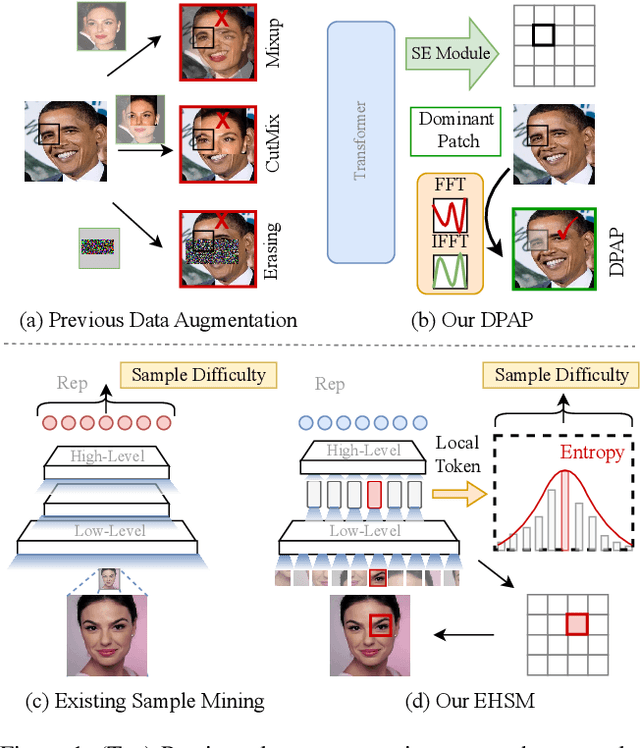
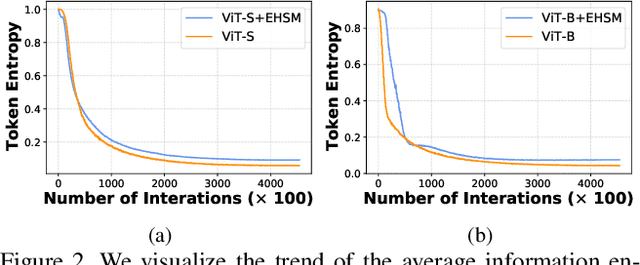
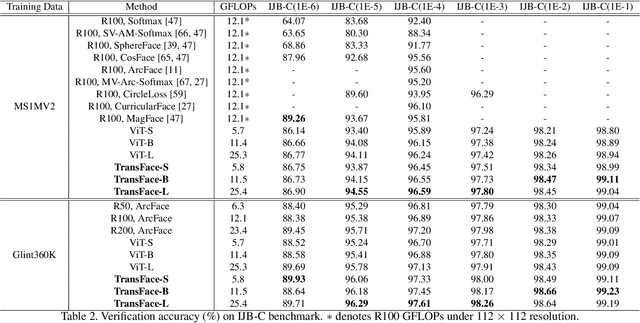
Vision Transformers (ViTs) have demonstrated powerful representation ability in various visual tasks thanks to their intrinsic data-hungry nature. However, we unexpectedly find that ViTs perform vulnerably when applied to face recognition (FR) scenarios with extremely large datasets. We investigate the reasons for this phenomenon and discover that the existing data augmentation approach and hard sample mining strategy are incompatible with ViTs-based FR backbone due to the lack of tailored consideration on preserving face structural information and leveraging each local token information. To remedy these problems, this paper proposes a superior FR model called TransFace, which employs a patch-level data augmentation strategy named DPAP and a hard sample mining strategy named EHSM. Specially, DPAP randomly perturbs the amplitude information of dominant patches to expand sample diversity, which effectively alleviates the overfitting problem in ViTs. EHSM utilizes the information entropy in the local tokens to dynamically adjust the importance weight of easy and hard samples during training, leading to a more stable prediction. Experiments on several benchmarks demonstrate the superiority of our TransFace. Code and models are available at https://github.com/DanJun6737/TransFace.
QKSAN: A Quantum Kernel Self-Attention Network
Aug 25, 2023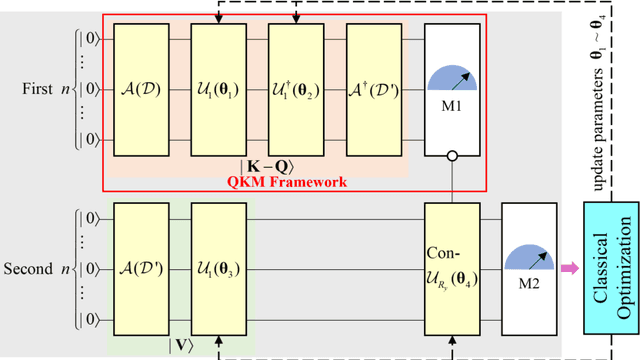

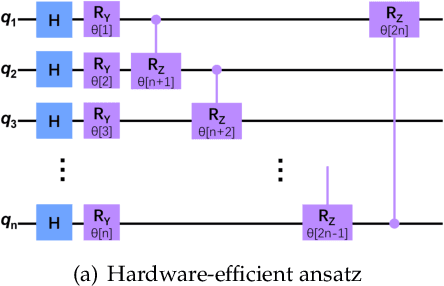
Self-Attention Mechanism (SAM) is skilled at extracting important information from the interior of data to improve the computational efficiency of models. Nevertheless, many Quantum Machine Learning (QML) models lack the ability to distinguish the intrinsic connections of information like SAM, which limits their effectiveness on massive high-dimensional quantum data. To address this issue, a Quantum Kernel Self-Attention Mechanism (QKSAM) is introduced, which combines the data representation benefit of Quantum Kernel Methods (QKM) with the efficient information extraction capability of SAM. A Quantum Kernel Self-Attention Network (QKSAN) framework is built based on QKSAM, with Deferred Measurement Principle (DMP) and conditional measurement techniques, which releases half of the quantum resources with probabilistic measurements during computation. The Quantum Kernel Self-Attention Score (QKSAS) determines the measurement conditions and reflects the probabilistic nature of quantum systems. Finally, four QKSAN models are deployed on the Pennylane platform to perform binary classification on MNIST images. The best-performing among the four models is assessed for noise immunity and learning ability. Remarkably, the potential learning benefit of partial QKSAN models over classical deep learning is that they require few parameters for a high return of 98\% $\pm$ 1\% test and train accuracy, even with highly compressed images. QKSAN lays the foundation for future quantum computers to perform machine learning on massive amounts of data, while driving advances in areas such as quantum Natural Language Processing (NLP).
CS-Mixer: A Cross-Scale Vision MLP Model with Spatial-Channel Mixing
Aug 25, 2023Despite their simpler information fusion designs compared with Vision Transformers and Convolutional Neural Networks, Vision MLP architectures have demonstrated strong performance and high data efficiency in recent research. However, existing works such as CycleMLP and Vision Permutator typically model spatial information in equal-size spatial regions and do not consider cross-scale spatial interactions. Further, their token mixers only model 1- or 2-axis correlations, avoiding 3-axis spatial-channel mixing due to its computational demands. We therefore propose CS-Mixer, a hierarchical Vision MLP that learns dynamic low-rank transformations for spatial-channel mixing through cross-scale local and global aggregation. The proposed methodology achieves competitive results on popular image recognition benchmarks without incurring substantially more compute. Our largest model, CS-Mixer-L, reaches 83.2% top-1 accuracy on ImageNet-1k with 13.7 GFLOPs and 94 M parameters.
StratMed: Relevance Stratification for Low-resource Medication Recommendation
Sep 06, 2023
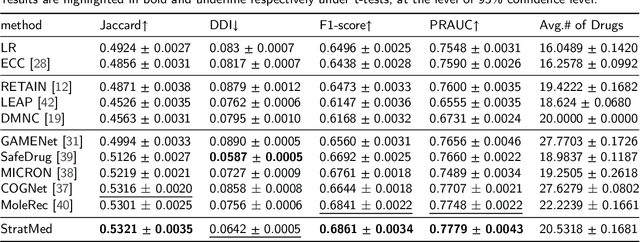
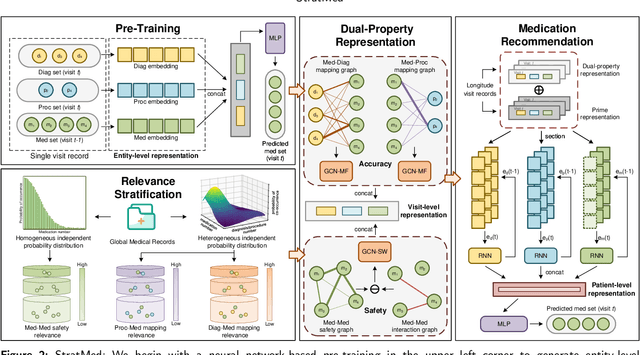

With the growing imbalance between limited medical resources and escalating demands, AI-based clinical tasks have become paramount. Medication recommendation, as a sub-domain, aims to amalgamate longitudinal patient history with medical knowledge, assisting physicians in prescribing safer and more accurate medication combinations. Existing methods overlook the inherent long-tail distribution in medical data, lacking balanced representation between head and tail data, which leads to sub-optimal model performance. To address this challenge, we introduce StratMed, a model that incorporates an innovative relevance stratification mechanism. It harmonizes discrepancies in data long-tail distribution and strikes a balance between the safety and accuracy of medication combinations. Specifically, we first construct a pre-training method using deep learning networks to obtain entity representation. After that, we design a pyramid-like data stratification method to obtain more generalized entity relationships by reinforcing the features of unpopular entities. Based on this relationship, we designed two graph structures to express medication precision and safety at the same level to obtain visit representations. Finally, the patient's historical clinical information is fitted to generate medication combinations for the current health condition. Experiments on the MIMIC-III dataset demonstrate that our method has outperformed current state-of-the-art methods in four evaluation metrics (including safety and accuracy).
Reconfigurable Intelligent Surface Aided Space Shift Keying With Imperfect CSI
Sep 06, 2023In this paper, we investigate the performance of reconfigurable intelligent surface (RIS)-aided spatial shift keying (SSK) wireless communication systems in the presence of imperfect channel state information (CSI). Specifically, we analyze the average bit error probability (ABEP) of two RIS-SSK systems respectively based on intelligent reflection and blind reflection of RIS. For the intelligent RIS-SSK scheme, we first derive the conditional pairwise error probability of the composite channel through maximum likelihood (ML) detection. Subsequently, we derive the probability density function of the combined channel. Due to the intricacies of the composite channel formulation, an exact closed-form ABEP expression is unattainable through direct derivation. To this end, we resort to employing the Gaussian-Chebyshev quadrature method to estimate the results. In addition, we employ the Q-function approximation to derive the non-exact closed-form expression when CSI imperfections are present. For the blind RIS-SSK scheme, we derive both closed-form ABEP expression and asymptotic ABEP expression with imperfect CSI by adopting the ML detector. To offer deeper insights, we explore the impact of discrete reflection phase shifts on the performance of the RIS-SSK system. Lastly, we extensively validate all the analytical derivations using Monte Carlo simulations.
PDiscoNet: Semantically consistent part discovery for fine-grained recognition
Sep 06, 2023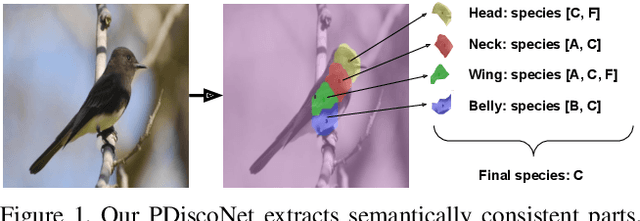
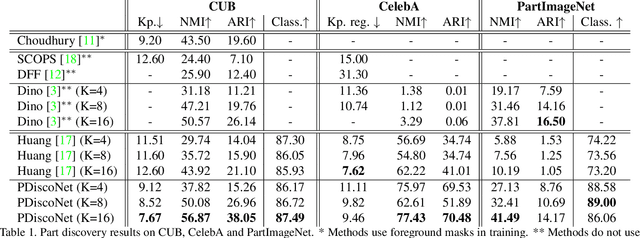
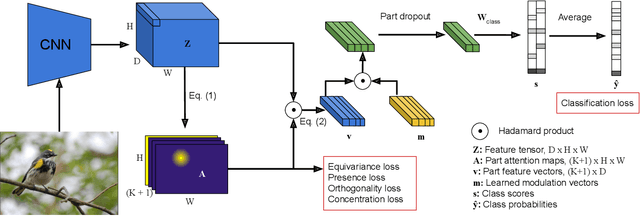
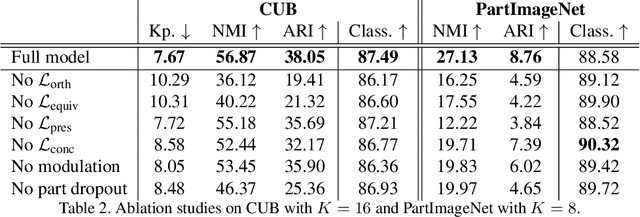
Fine-grained classification often requires recognizing specific object parts, such as beak shape and wing patterns for birds. Encouraging a fine-grained classification model to first detect such parts and then using them to infer the class could help us gauge whether the model is indeed looking at the right details better than with interpretability methods that provide a single attribution map. We propose PDiscoNet to discover object parts by using only image-level class labels along with priors encouraging the parts to be: discriminative, compact, distinct from each other, equivariant to rigid transforms, and active in at least some of the images. In addition to using the appropriate losses to encode these priors, we propose to use part-dropout, where full part feature vectors are dropped at once to prevent a single part from dominating in the classification, and part feature vector modulation, which makes the information coming from each part distinct from the perspective of the classifier. Our results on CUB, CelebA, and PartImageNet show that the proposed method provides substantially better part discovery performance than previous methods while not requiring any additional hyper-parameter tuning and without penalizing the classification performance. The code is available at https://github.com/robertdvdk/part_detection.
My Art My Choice: Adversarial Protection Against Unruly AI
Sep 06, 2023Generative AI is on the rise, enabling everyone to produce realistic content via publicly available interfaces. Especially for guided image generation, diffusion models are changing the creator economy by producing high quality low cost content. In parallel, artists are rising against unruly AI, since their artwork are leveraged, distributed, and dissimulated by large generative models. Our approach, My Art My Choice (MAMC), aims to empower content owners by protecting their copyrighted materials from being utilized by diffusion models in an adversarial fashion. MAMC learns to generate adversarially perturbed "protected" versions of images which can in turn "break" diffusion models. The perturbation amount is decided by the artist to balance distortion vs. protection of the content. MAMC is designed with a simple UNet-based generator, attacking black box diffusion models, combining several losses to create adversarial twins of the original artwork. We experiment on three datasets for various image-to-image tasks, with different user control values. Both protected image and diffusion output results are evaluated in visual, noise, structure, pixel, and generative spaces to validate our claims. We believe that MAMC is a crucial step for preserving ownership information for AI generated content in a flawless, based-on-need, and human-centric way.
Using Neural Networks for Fast SAR Roughness Estimation of High Resolution Images
Sep 06, 2023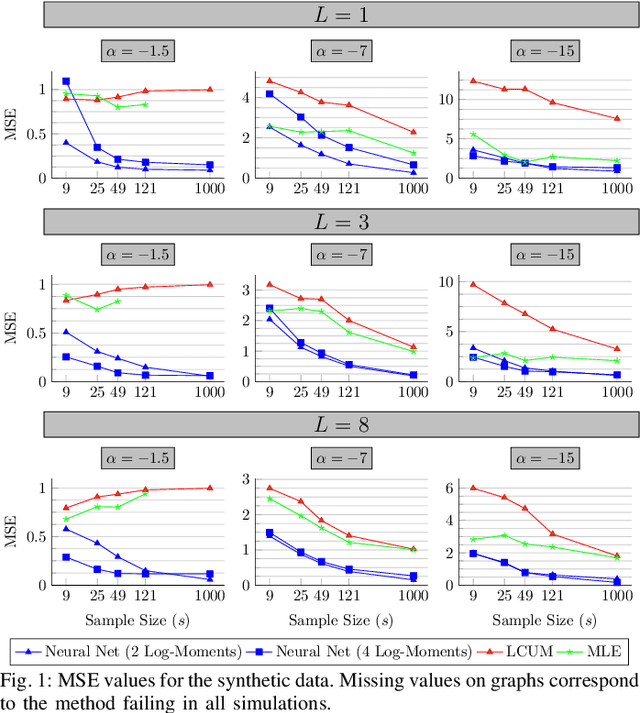


The analysis of Synthetic Aperture Radar (SAR) imagery is an important step in remote sensing applications, and it is a challenging problem due to its inherent speckle noise. One typical solution is to model the data using the $G_I^0$ distribution and extract its roughness information, which in turn can be used in posterior imaging tasks, such as segmentation, classification and interpretation. This leads to the need of quick and reliable estimation of the roughness parameter from SAR data, especially with high resolution images. Unfortunately, traditional parameter estimation procedures are slow and prone to estimation failures. In this work, we proposed a neural network-based estimation framework that first learns how to predict underlying parameters of $G_I^0$ samples and then can be used to estimate the roughness of unseen data. We show that this approach leads to an estimator that is quicker, yields less estimation error and is less prone to failures than the traditional estimation procedures for this problem, even when we use a simple network. More importantly, we show that this same methodology can be generalized to handle image inputs and, even if trained on purely synthetic data for a few seconds, is able to perform real time pixel-wise roughness estimation for high resolution real SAR imagery.
Large Content And Behavior Models To Understand, Simulate, And Optimize Content And Behavior
Sep 08, 2023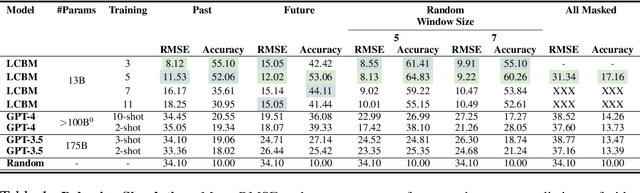
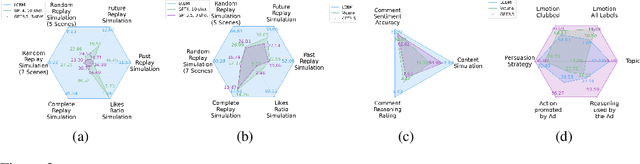
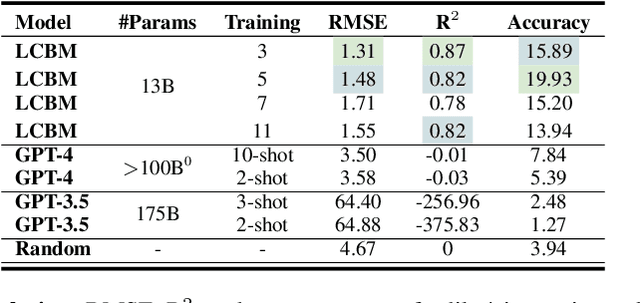
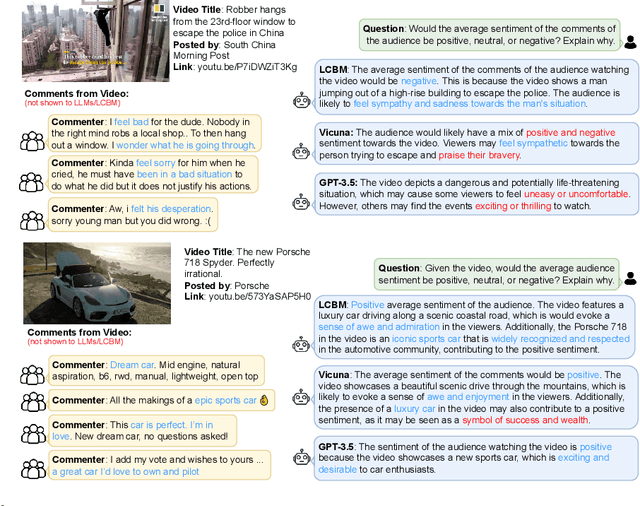
Shannon, in his seminal paper introducing information theory, divided the communication into three levels: technical, semantic, and effectivenss. While the technical level is concerned with accurate reconstruction of transmitted symbols, the semantic and effectiveness levels deal with the inferred meaning and its effect on the receiver. Thanks to telecommunications, the first level problem has produced great advances like the internet. Large Language Models (LLMs) make some progress towards the second goal, but the third level still remains largely untouched. The third problem deals with predicting and optimizing communication for desired receiver behavior. LLMs, while showing wide generalization capabilities across a wide range of tasks, are unable to solve for this. One reason for the underperformance could be a lack of "behavior tokens" in LLMs' training corpora. Behavior tokens define receiver behavior over a communication, such as shares, likes, clicks, purchases, retweets, etc. While preprocessing data for LLM training, behavior tokens are often removed from the corpora as noise. Therefore, in this paper, we make some initial progress towards reintroducing behavior tokens in LLM training. The trained models, other than showing similar performance to LLMs on content understanding tasks, show generalization capabilities on behavior simulation, content simulation, behavior understanding, and behavior domain adaptation. Using a wide range of tasks on two corpora, we show results on all these capabilities. We call these models Large Content and Behavior Models (LCBMs). Further, to spur more research on LCBMs, we release our new Content Behavior Corpus (CBC), a repository containing communicator, message, and corresponding receiver behavior.