 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Edge-aware Hard Clustering Graph Pooling for Brain Imaging Data
Sep 13, 2023

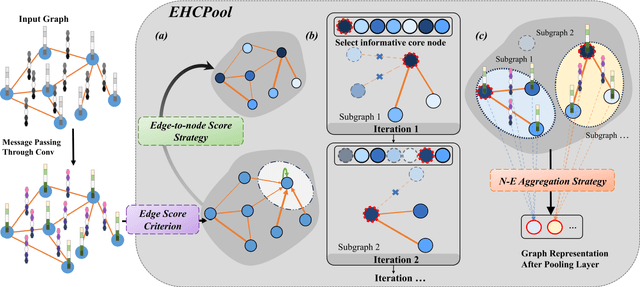
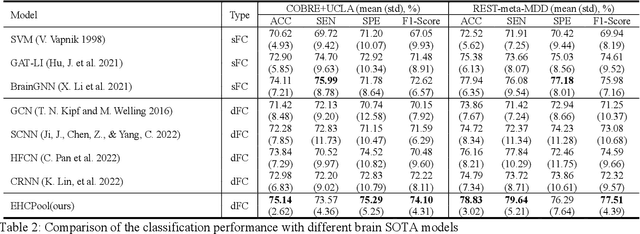

Graph Convolutional Networks (GCNs) can capture non-Euclidean spatial dependence between different brain regions, and the graph pooling operator in GCNs is key to enhancing the representation learning capability and acquiring abnormal brain maps. However, the majority of existing research designs graph pooling operators only from the perspective of nodes while disregarding the original edge features, in a way that not only confines graph pooling application scenarios, but also diminishes its ability to capture critical substructures. In this study, a clustering graph pooling method that first supports multidimensional edge features, called Edge-aware hard clustering graph pooling (EHCPool), is developed. EHCPool proposes the first 'Edge-to-node' score evaluation criterion based on edge features to assess node feature significance. To more effectively capture the critical subgraphs, a novel Iteration n-top strategy is further designed to adaptively learn sparse hard clustering assignments for graphs. Subsequently, an innovative N-E Aggregation strategy is presented to aggregate node and edge feature information in each independent subgraph. The proposed model was evaluated on multi-site brain imaging public datasets and yielded state-of-the-art performance. We believe this method is the first deep learning tool with the potential to probe different types of abnormal functional brain networks from data-driven perspective. Core code is at: https://github.com/swfen/EHCPool.
A Multi-Task Semantic Decomposition Framework with Task-specific Pre-training for Few-Shot NER
Aug 28, 2023The objective of few-shot named entity recognition is to identify named entities with limited labeled instances. Previous works have primarily focused on optimizing the traditional token-wise classification framework, while neglecting the exploration of information based on NER data characteristics. To address this issue, we propose a Multi-Task Semantic Decomposition Framework via Joint Task-specific Pre-training (MSDP) for few-shot NER. Drawing inspiration from demonstration-based and contrastive learning, we introduce two novel pre-training tasks: Demonstration-based Masked Language Modeling (MLM) and Class Contrastive Discrimination. These tasks effectively incorporate entity boundary information and enhance entity representation in Pre-trained Language Models (PLMs). In the downstream main task, we introduce a multi-task joint optimization framework with the semantic decomposing method, which facilitates the model to integrate two different semantic information for entity classification. Experimental results of two few-shot NER benchmarks demonstrate that MSDP consistently outperforms strong baselines by a large margin. Extensive analyses validate the effectiveness and generalization of MSDP.
FurChat: An Embodied Conversational Agent using LLMs, Combining Open and Closed-Domain Dialogue with Facial Expressions
Aug 30, 2023
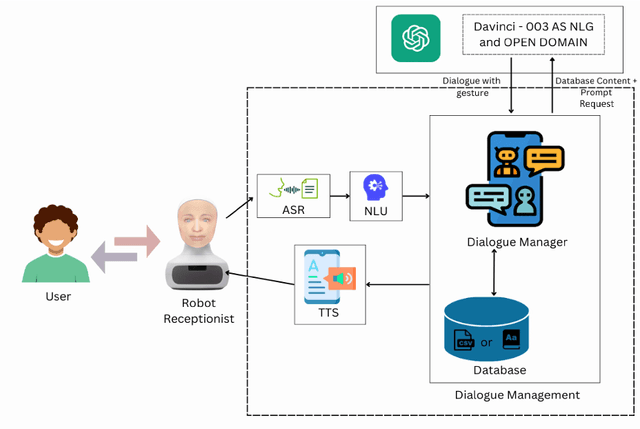
We demonstrate an embodied conversational agent that can function as a receptionist and generate a mixture of open and closed-domain dialogue along with facial expressions, by using a large language model (LLM) to develop an engaging conversation. We deployed the system onto a Furhat robot, which is highly expressive and capable of using both verbal and nonverbal cues during interaction. The system was designed specifically for the National Robotarium to interact with visitors through natural conversations, providing them with information about the facilities, research, news, upcoming events, etc. The system utilises the state-of-the-art GPT-3.5 model to generate such information along with domain-general conversations and facial expressions based on prompt engineering.
SOAR: Scene-debiasing Open-set Action Recognition
Sep 03, 2023

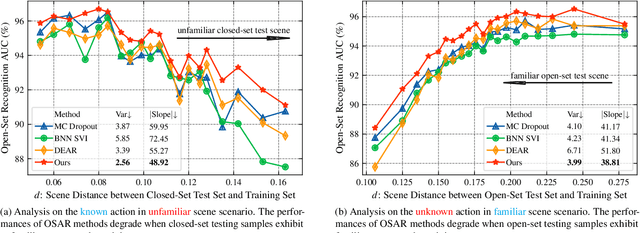

Deep learning models have a risk of utilizing spurious clues to make predictions, such as recognizing actions based on the background scene. This issue can severely degrade the open-set action recognition performance when the testing samples have different scene distributions from the training samples. To mitigate this problem, we propose a novel method, called Scene-debiasing Open-set Action Recognition (SOAR), which features an adversarial scene reconstruction module and an adaptive adversarial scene classification module. The former prevents the decoder from reconstructing the video background given video features, and thus helps reduce the background information in feature learning. The latter aims to confuse scene type classification given video features, with a specific emphasis on the action foreground, and helps to learn scene-invariant information. In addition, we design an experiment to quantify the scene bias. The results indicate that the current open-set action recognizers are biased toward the scene, and our proposed SOAR method better mitigates such bias. Furthermore, our extensive experiments demonstrate that our method outperforms state-of-the-art methods, and the ablation studies confirm the effectiveness of our proposed modules.
SAR ATR Method with Limited Training Data via an Embedded Feature Augmenter and Dynamic Hierarchical-Feature Refiner
Sep 01, 2023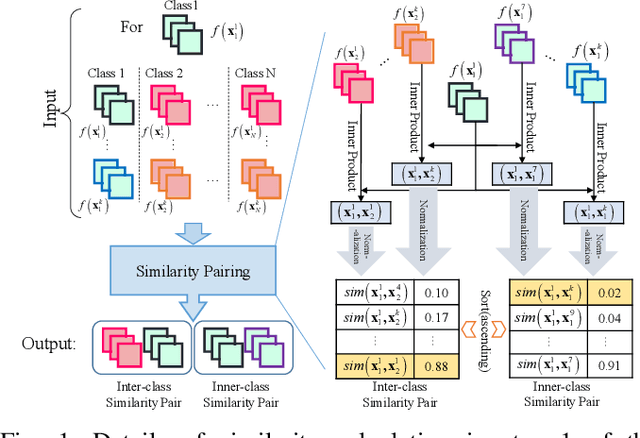
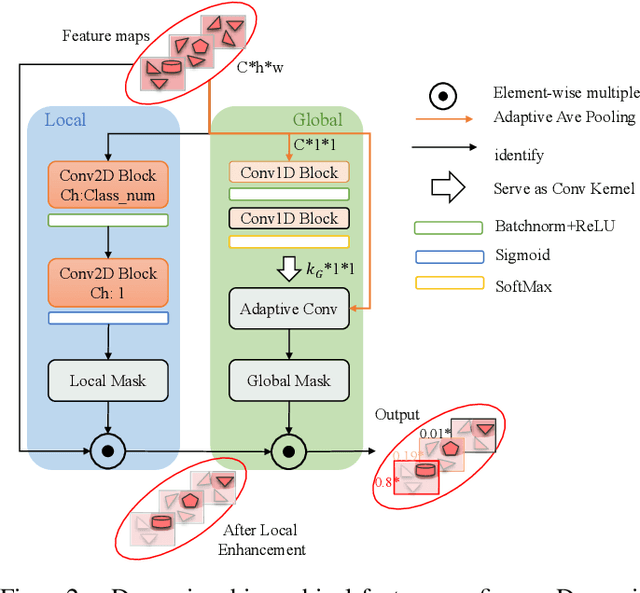


Without sufficient data, the quantity of information available for supervised training is constrained, as obtaining sufficient synthetic aperture radar (SAR) training data in practice is frequently challenging. Therefore, current SAR automatic target recognition (ATR) algorithms perform poorly with limited training data availability, resulting in a critical need to increase SAR ATR performance. In this study, a new method to improve SAR ATR when training data are limited is proposed. First, an embedded feature augmenter is designed to enhance the extracted virtual features located far away from the class center. Based on the relative distribution of the features, the algorithm pulls the corresponding virtual features with different strengths toward the corresponding class center. The designed augmenter increases the amount of information available for supervised training and improves the separability of the extracted features. Second, a dynamic hierarchical-feature refiner is proposed to capture the discriminative local features of the samples. Through dynamically generated kernels, the proposed refiner integrates the discriminative local features of different dimensions into the global features, further enhancing the inner-class compactness and inter-class separability of the extracted features. The proposed method not only increases the amount of information available for supervised training but also extracts the discriminative features from the samples, resulting in superior ATR performance in problems with limited SAR training data. Experimental results on the moving and stationary target acquisition and recognition (MSTAR), OpenSARShip, and FUSAR-Ship benchmark datasets demonstrate the robustness and outstanding ATR performance of the proposed method in response to limited SAR training data.
Focus on the Sound around You: Monaural Target Speaker Extraction via Distance and Speaker Information
Jun 28, 2023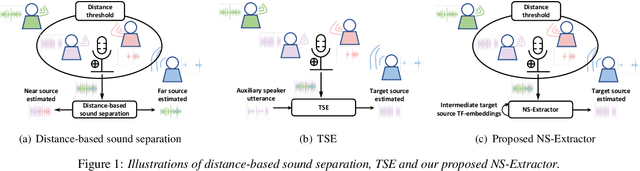
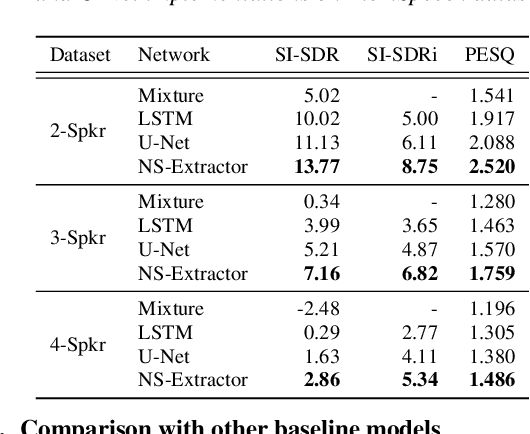
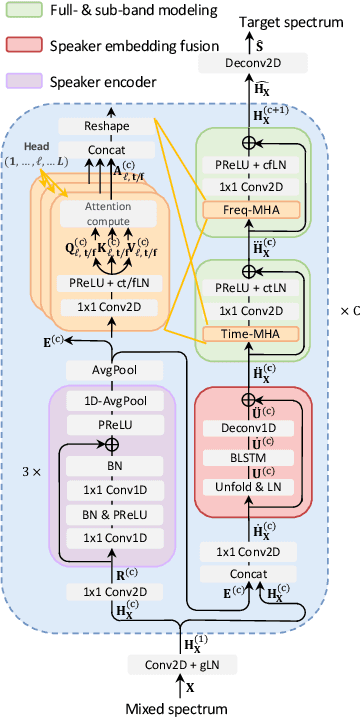
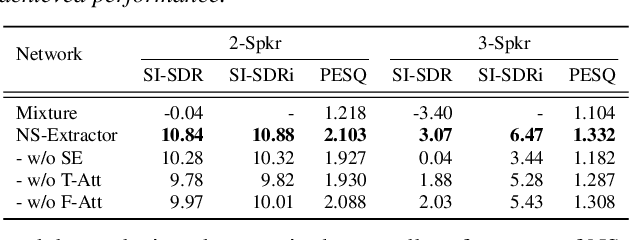
Previously, Target Speaker Extraction (TSE) has yielded outstanding performance in certain application scenarios for speech enhancement and source separation. However, obtaining auxiliary speaker-related information is still challenging in noisy environments with significant reverberation. inspired by the recently proposed distance-based sound separation, we propose the near sound (NS) extractor, which leverages distance information for TSE to reliably extract speaker information without requiring previous speaker enrolment, called speaker embedding self-enrollment (SESE). Full- & sub-band modeling is introduced to enhance our NS-Extractor's adaptability towards environments with significant reverberation. Experimental results on several cross-datasets demonstrate the effectiveness of our improvements and the excellent performance of our proposed NS-Extractor in different application scenarios.
Mutual-Guided Dynamic Network for Image Fusion
Aug 24, 2023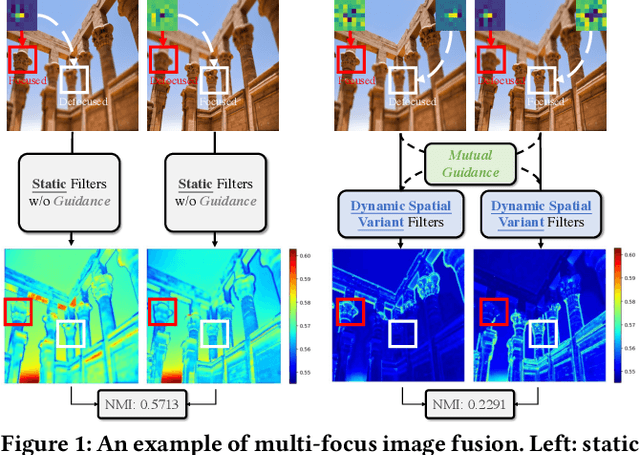

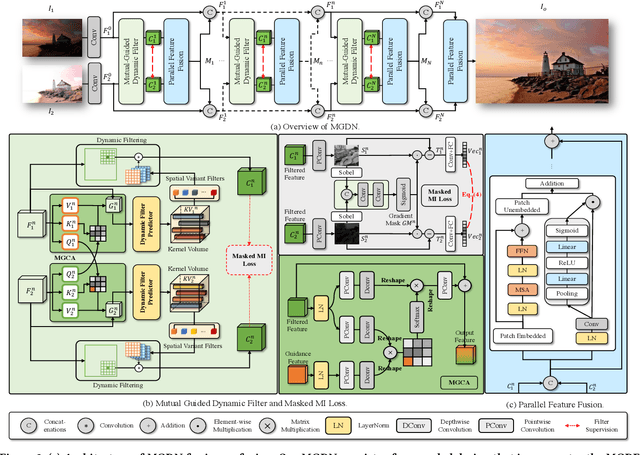
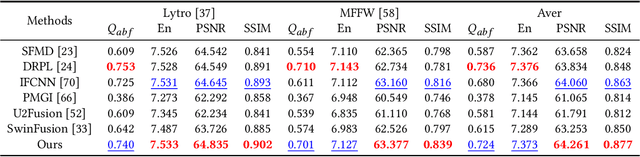
Image fusion aims to generate a high-quality image from multiple images captured under varying conditions. The key problem of this task is to preserve complementary information while filtering out irrelevant information for the fused result. However, existing methods address this problem by leveraging static convolutional neural networks (CNNs), suffering two inherent limitations during feature extraction, i.e., being unable to handle spatial-variant contents and lacking guidance from multiple inputs. In this paper, we propose a novel mutual-guided dynamic network (MGDN) for image fusion, which allows for effective information utilization across different locations and inputs. Specifically, we design a mutual-guided dynamic filter (MGDF) for adaptive feature extraction, composed of a mutual-guided cross-attention (MGCA) module and a dynamic filter predictor, where the former incorporates additional guidance from different inputs and the latter generates spatial-variant kernels for different locations. In addition, we introduce a parallel feature fusion (PFF) module to effectively fuse local and global information of the extracted features. To further reduce the redundancy among the extracted features while simultaneously preserving their shared structural information, we devise a novel loss function that combines the minimization of normalized mutual information (NMI) with an estimated gradient mask. Experimental results on five benchmark datasets demonstrate that our proposed method outperforms existing methods on four image fusion tasks. The code and model are publicly available at: https://github.com/Guanys-dar/MGDN.
Joint Modeling of Feature, Correspondence, and a Compressed Memory for Video Object Segmentation
Aug 25, 2023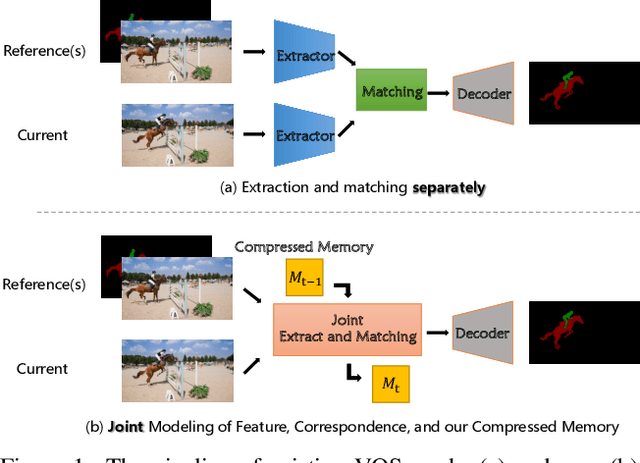
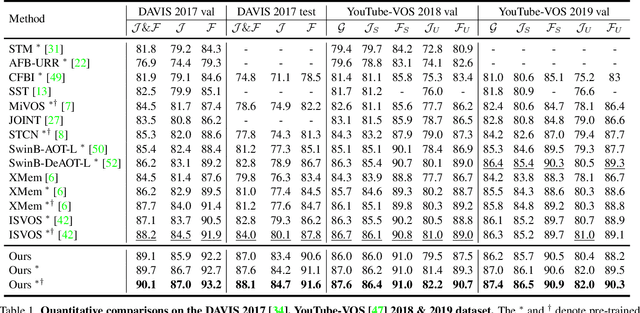
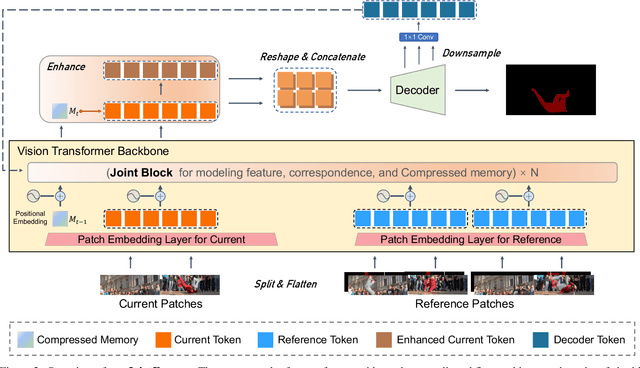
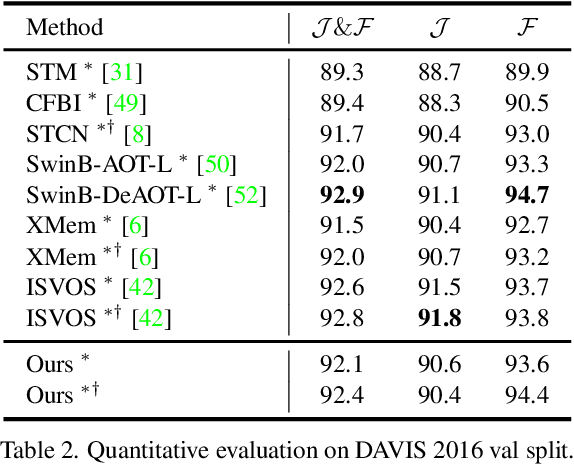
Current prevailing Video Object Segmentation (VOS) methods usually perform dense matching between the current and reference frames after extracting their features. One on hand, the decoupled modeling restricts the targets information propagation only at high-level feature space. On the other hand, the pixel-wise matching leads to a lack of holistic understanding of the targets. To overcome these issues, we propose a unified VOS framework, coined as JointFormer, for joint modeling the three elements of feature, correspondence, and a compressed memory. The core design is the Joint Block, utilizing the flexibility of attention to simultaneously extract feature and propagate the targets information to the current tokens and the compressed memory token. This scheme allows to perform extensive information propagation and discriminative feature learning. To incorporate the long-term temporal targets information, we also devise a customized online updating mechanism for the compressed memory token, which can prompt the information flow along the temporal dimension and thus improve the global modeling capability. Under the design, our method achieves a new state-of-art performance on DAVIS 2017 val/test-dev (89.7% and 87.6%) and YouTube-VOS 2018/2019 val (87.0% and 87.0%) benchmarks, outperforming existing works by a large margin.
CALM: Contrastive Cross-modal Speaking Style Modeling for Expressive Text-to-Speech Synthesis
Aug 30, 2023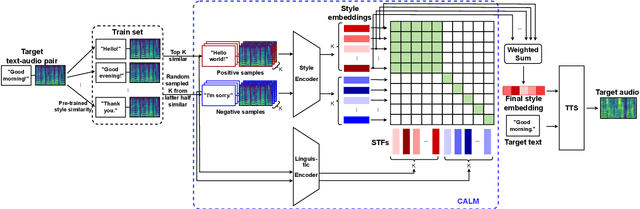
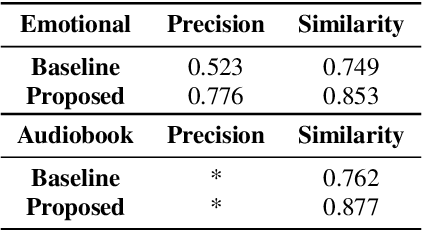
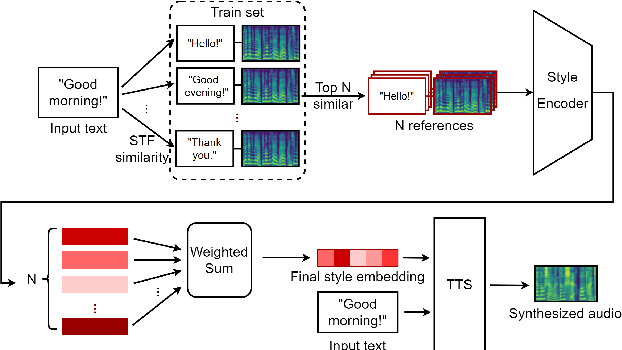

To further improve the speaking styles of synthesized speeches, current text-to-speech (TTS) synthesis systems commonly employ reference speeches to stylize their outputs instead of just the input texts. These reference speeches are obtained by manual selection which is resource-consuming, or selected by semantic features. However, semantic features contain not only style-related information, but also style irrelevant information. The information irrelevant to speaking style in the text could interfere the reference audio selection and result in improper speaking styles. To improve the reference selection, we propose Contrastive Acoustic-Linguistic Module (CALM) to extract the Style-related Text Feature (STF) from the text. CALM optimizes the correlation between the speaking style embedding and the extracted STF with contrastive learning. Thus, a certain number of the most appropriate reference speeches for the input text are selected by retrieving the speeches with the top STF similarities. Then the style embeddings are weighted summarized according to their STF similarities and used to stylize the synthesized speech of TTS. Experiment results demonstrate the effectiveness of our proposed approach, with both objective evaluations and subjective evaluations on the speaking styles of the synthesized speeches outperform a baseline approach with semantic-feature-based reference selection.
CPMR: Context-Aware Incremental Sequential Recommendation with Pseudo-Multi-Task Learning
Sep 14, 2023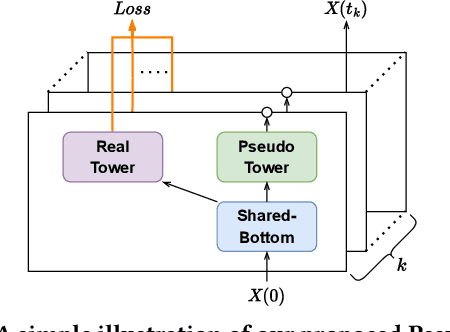
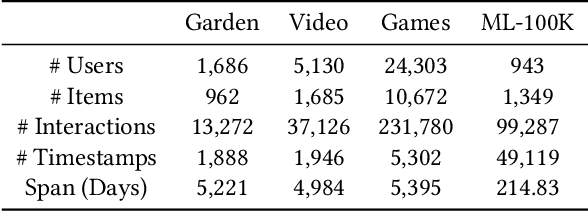


The motivations of users to make interactions can be divided into static preference and dynamic interest. To accurately model user representations over time, recent studies in sequential recommendation utilize information propagation and evolution to mine from batches of arriving interactions. However, they ignore the fact that people are easily influenced by the recent actions of other users in the contextual scenario, and applying evolution across all historical interactions dilutes the importance of recent ones, thus failing to model the evolution of dynamic interest accurately. To address this issue, we propose a Context-Aware Pseudo-Multi-Task Recommender System (CPMR) to model the evolution in both historical and contextual scenarios by creating three representations for each user and item under different dynamics: static embedding, historical temporal states, and contextual temporal states. To dually improve the performance of temporal states evolution and incremental recommendation, we design a Pseudo-Multi-Task Learning (PMTL) paradigm by stacking the incremental single-target recommendations into one multi-target task for joint optimization. Within the PMTL paradigm, CPMR employs a shared-bottom network to conduct the evolution of temporal states across historical and contextual scenarios, as well as the fusion of them at the user-item level. In addition, CPMR incorporates one real tower for incremental predictions, and two pseudo towers dedicated to updating the respective temporal states based on new batches of interactions. Experimental results on four benchmark recommendation datasets show that CPMR consistently outperforms state-of-the-art baselines and achieves significant gains on three of them. The code is available at: https://github.com/DiMarzioBian/CPMR.
* Accepted by CIKM 2023. Alias: "Modeling Context-Aware Temporal Dynamics via Pseudo-Multi-Task Learning"