 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Minimal Effective Theory for Phonotactic Memory: Capturing Local Correlations due to Errors in Speech
Sep 04, 2023
Spoken language evolves constrained by the economy of speech, which depends on factors such as the structure of the human mouth. This gives rise to local phonetic correlations in spoken words. Here we demonstrate that these local correlations facilitate the learning of spoken words by reducing their information content. We do this by constructing a locally-connected tensor-network model, inspired by similar variational models used for many-body physics, which exploits these local phonetic correlations to facilitate the learning of spoken words. The model is therefore a minimal model of phonetic memory, where "learning to pronounce" and "learning a word" are one and the same. A consequence of which is the learned ability to produce new words which are phonetically reasonable for the target language; as well as providing a hierarchy of the most likely errors that could be produced during the action of speech. We test our model against Latin and Turkish words. (The code is available on GitHub.)
UniSA: Unified Generative Framework for Sentiment Analysis
Sep 04, 2023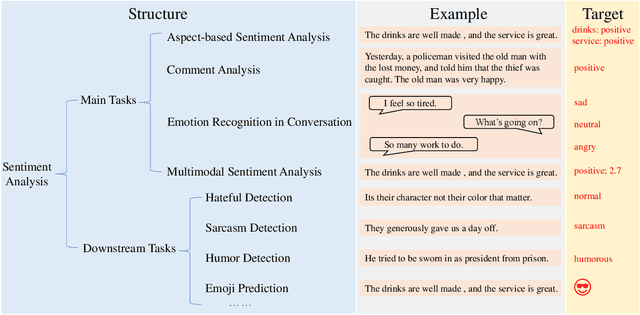
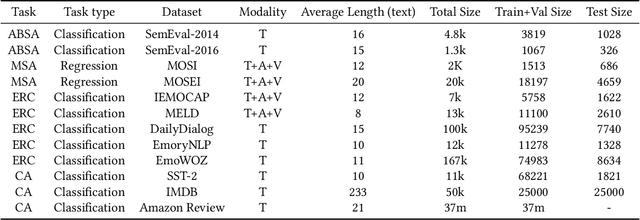
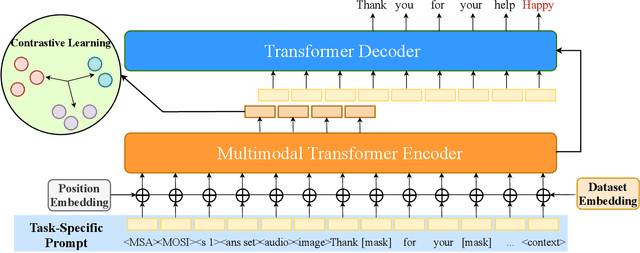

Sentiment analysis is a crucial task that aims to understand people's emotional states and predict emotional categories based on multimodal information. It consists of several subtasks, such as emotion recognition in conversation (ERC), aspect-based sentiment analysis (ABSA), and multimodal sentiment analysis (MSA). However, unifying all subtasks in sentiment analysis presents numerous challenges, including modality alignment, unified input/output forms, and dataset bias. To address these challenges, we propose a Task-Specific Prompt method to jointly model subtasks and introduce a multimodal generative framework called UniSA. Additionally, we organize the benchmark datasets of main subtasks into a new Sentiment Analysis Evaluation benchmark, SAEval. We design novel pre-training tasks and training methods to enable the model to learn generic sentiment knowledge among subtasks to improve the model's multimodal sentiment perception ability. Our experimental results show that UniSA performs comparably to the state-of-the-art on all subtasks and generalizes well to various subtasks in sentiment analysis.
Bayes optimal learning in high-dimensional linear regression with network side information
Jun 09, 2023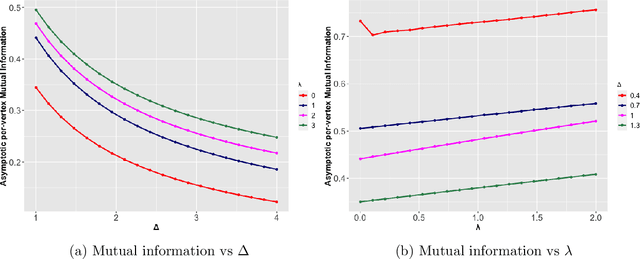
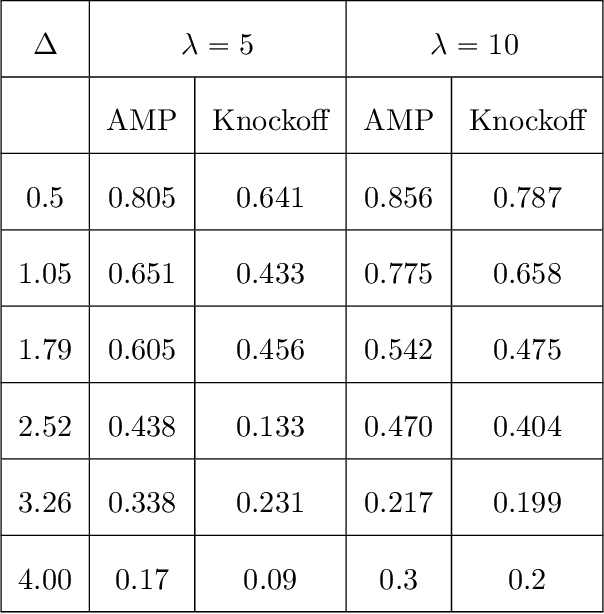
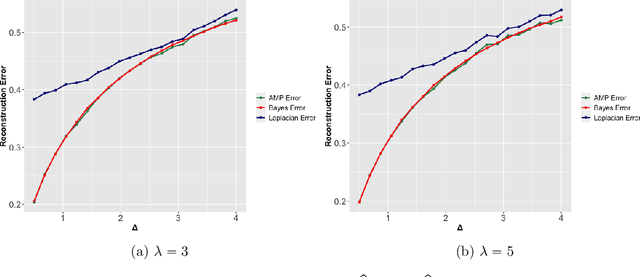
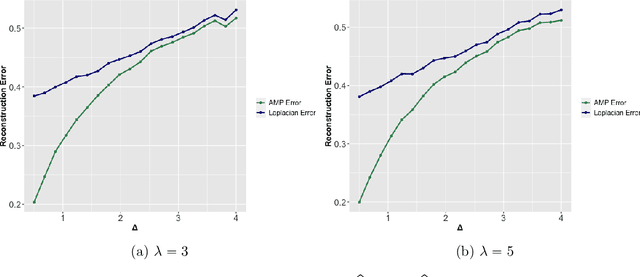
Supervised learning problems with side information in the form of a network arise frequently in applications in genomics, proteomics and neuroscience. For example, in genetic applications, the network side information can accurately capture background biological information on the intricate relations among the relevant genes. In this paper, we initiate a study of Bayes optimal learning in high-dimensional linear regression with network side information. To this end, we first introduce a simple generative model (called the Reg-Graph model) which posits a joint distribution for the supervised data and the observed network through a common set of latent parameters. Next, we introduce an iterative algorithm based on Approximate Message Passing (AMP) which is provably Bayes optimal under very general conditions. In addition, we characterize the limiting mutual information between the latent signal and the data observed, and thus precisely quantify the statistical impact of the network side information. Finally, supporting numerical experiments suggest that the introduced algorithm has excellent performance in finite samples.
Learning Strong Graph Neural Networks with Weak Information
May 29, 2023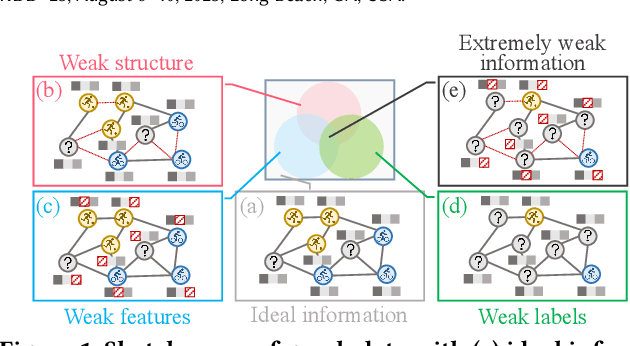
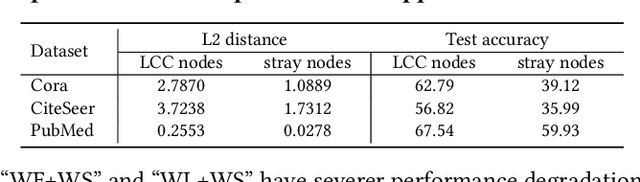
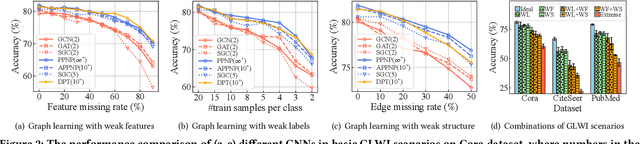
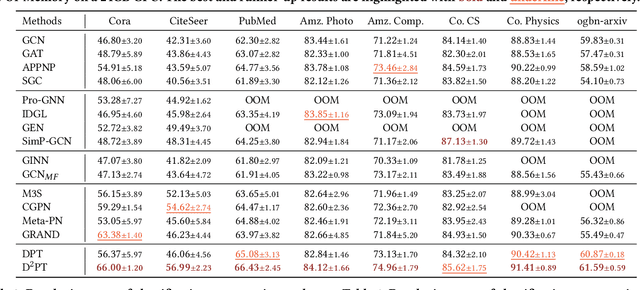
Graph Neural Networks (GNNs) have exhibited impressive performance in many graph learning tasks. Nevertheless, the performance of GNNs can deteriorate when the input graph data suffer from weak information, i.e., incomplete structure, incomplete features, and insufficient labels. Most prior studies, which attempt to learn from the graph data with a specific type of weak information, are far from effective in dealing with the scenario where diverse data deficiencies exist and mutually affect each other. To fill the gap, in this paper, we aim to develop an effective and principled approach to the problem of graph learning with weak information (GLWI). Based on the findings from our empirical analysis, we derive two design focal points for solving the problem of GLWI, i.e., enabling long-range propagation in GNNs and allowing information propagation to those stray nodes isolated from the largest connected component. Accordingly, we propose D$^2$PT, a dual-channel GNN framework that performs long-range information propagation not only on the input graph with incomplete structure, but also on a global graph that encodes global semantic similarities. We further develop a prototype contrastive alignment algorithm that aligns the class-level prototypes learned from two channels, such that the two different information propagation processes can mutually benefit from each other and the finally learned model can well handle the GLWI problem. Extensive experiments on eight real-world benchmark datasets demonstrate the effectiveness and efficiency of our proposed methods in various GLWI scenarios.
Measuring Spurious Correlation in Classification: 'Clever Hans' in Translationese
Aug 25, 2023Recent work has shown evidence of 'Clever Hans' behavior in high-performance neural translationese classifiers, where BERT-based classifiers capitalize on spurious correlations, in particular topic information, between data and target classification labels, rather than genuine translationese signals. Translationese signals are subtle (especially for professional translation) and compete with many other signals in the data such as genre, style, author, and, in particular, topic. This raises the general question of how much of the performance of a classifier is really due to spurious correlations in the data versus the signals actually targeted for by the classifier, especially for subtle target signals and in challenging (low resource) data settings. We focus on topic-based spurious correlation and approach the question from two directions: (i) where we have no knowledge about spurious topic information and its distribution in the data, (ii) where we have some indication about the nature of spurious topic correlations. For (i) we develop a measure from first principles capturing alignment of unsupervised topics with target classification labels as an indication of spurious topic information in the data. We show that our measure is the same as purity in clustering and propose a 'topic floor' (as in a 'noise floor') for classification. For (ii) we investigate masking of known spurious topic carriers in classification. Both (i) and (ii) contribute to quantifying and (ii) to mitigating spurious correlations.
PyGraft: Configurable Generation of Schemas and Knowledge Graphs at Your Fingertips
Sep 07, 2023Knowledge graphs (KGs) have emerged as a prominent data representation and management paradigm. Being usually underpinned by a schema (e.g. an ontology), KGs capture not only factual information but also contextual knowledge. In some tasks, a few KGs established themselves as standard benchmarks. However, recent works outline that relying on a limited collection of datasets is not sufficient to assess the generalization capability of an approach. In some data-sensitive fields such as education or medicine, access to public datasets is even more limited. To remedy the aforementioned issues, we release PyGraft, a Python-based tool that generates highly customized, domain-agnostic schemas and knowledge graphs. The synthesized schemas encompass various RDFS and OWL constructs, while the synthesized KGs emulate the characteristics and scale of real-world KGs. Logical consistency of the generated resources is ultimately ensured by running a description logic (DL) reasoner. By providing a way of generating both a schema and KG in a single pipeline, PyGraft's aim is to empower the generation of a more diverse array of KGs for benchmarking novel approaches in areas such as graph-based machine learning (ML), or more generally KG processing. In graph-based ML in particular, this should foster a more holistic evaluation of model performance and generalization capability, thereby going beyond the limited collection of available benchmarks. PyGraft is available at: https://github.com/nicolas-hbt/pygraft.
Sparse Federated Training of Object Detection in the Internet of Vehicles
Sep 07, 2023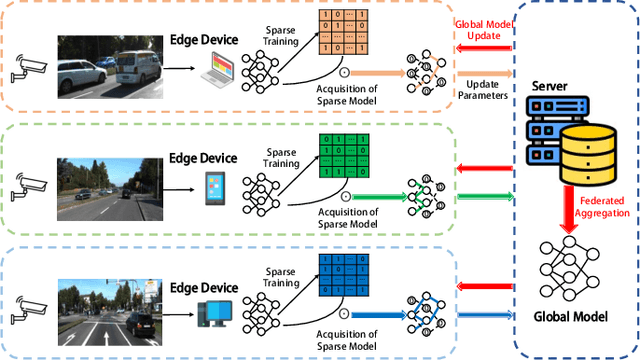
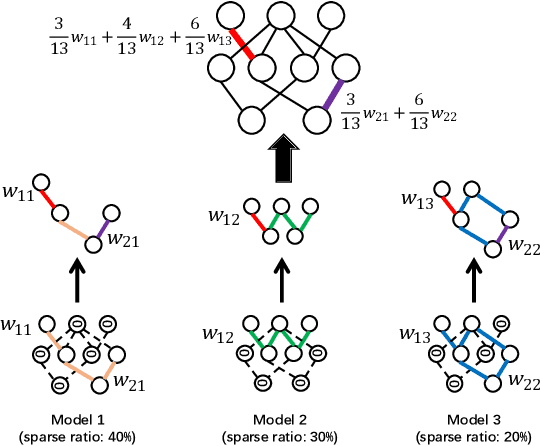

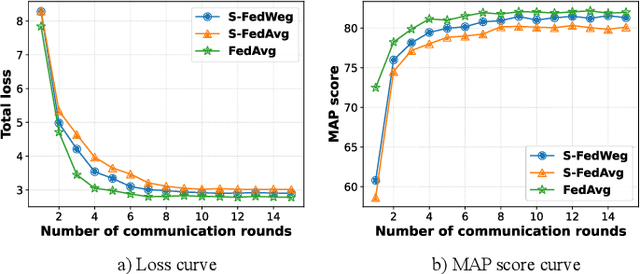
As an essential component part of the Intelligent Transportation System (ITS), the Internet of Vehicles (IoV) plays a vital role in alleviating traffic issues. Object detection is one of the key technologies in the IoV, which has been widely used to provide traffic management services by analyzing timely and sensitive vehicle-related information. However, the current object detection methods are mostly based on centralized deep training, that is, the sensitive data obtained by edge devices need to be uploaded to the server, which raises privacy concerns. To mitigate such privacy leakage, we first propose a federated learning-based framework, where well-trained local models are shared in the central server. However, since edge devices usually have limited computing power, plus a strict requirement of low latency in IoVs, we further propose a sparse training process on edge devices, which can effectively lighten the model, and ensure its training efficiency on edge devices, thereby reducing communication overheads. In addition, due to the diverse computing capabilities and dynamic environment, different sparsity rates are applied to edge devices. To further guarantee the performance, we propose, FedWeg, an improved aggregation scheme based on FedAvg, which is designed by the inverse ratio of sparsity rates. Experiments on the real-life dataset using YOLO show that the proposed scheme can achieve the required object detection rate while saving considerable communication costs.
ConDA: Contrastive Domain Adaptation for AI-generated Text Detection
Sep 07, 2023
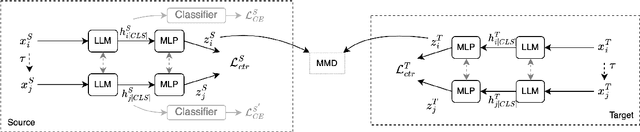
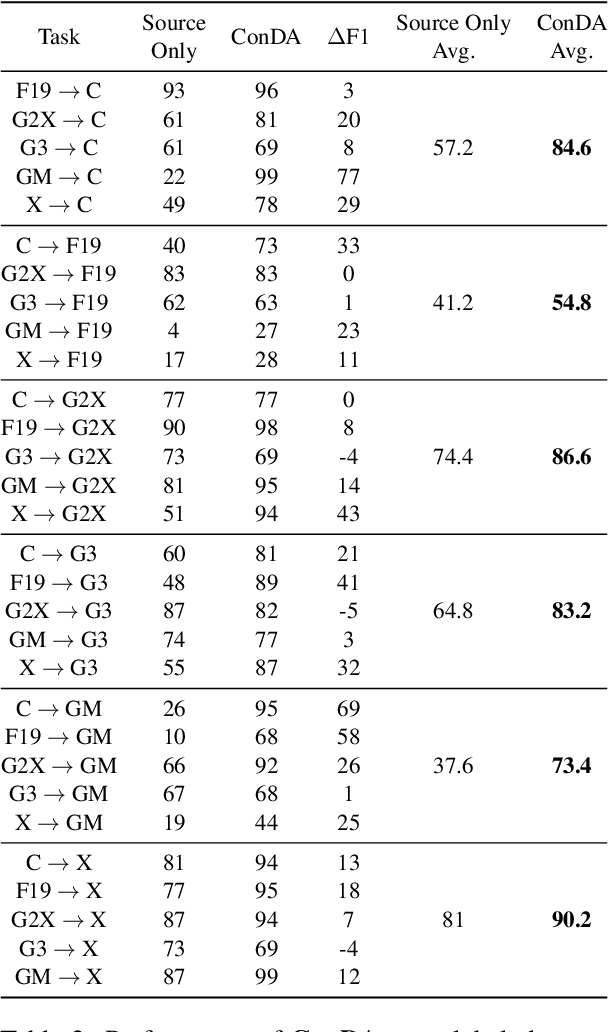
Large language models (LLMs) are increasingly being used for generating text in a variety of use cases, including journalistic news articles. Given the potential malicious nature in which these LLMs can be used to generate disinformation at scale, it is important to build effective detectors for such AI-generated text. Given the surge in development of new LLMs, acquiring labeled training data for supervised detectors is a bottleneck. However, there might be plenty of unlabeled text data available, without information on which generator it came from. In this work we tackle this data problem, in detecting AI-generated news text, and frame the problem as an unsupervised domain adaptation task. Here the domains are the different text generators, i.e. LLMs, and we assume we have access to only the labeled source data and unlabeled target data. We develop a Contrastive Domain Adaptation framework, called ConDA, that blends standard domain adaptation techniques with the representation power of contrastive learning to learn domain invariant representations that are effective for the final unsupervised detection task. Our experiments demonstrate the effectiveness of our framework, resulting in average performance gains of 31.7% from the best performing baselines, and within 0.8% margin of a fully supervised detector. All our code and data is available at https://github.com/AmritaBh/ConDA-gen-text-detection.
A Generic Machine Learning Framework for Fully-Unsupervised Anomaly Detection with Contaminated Data
Sep 07, 2023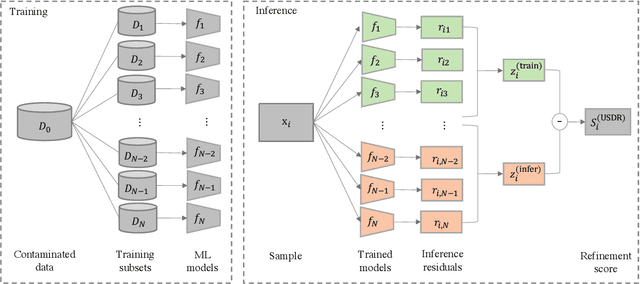
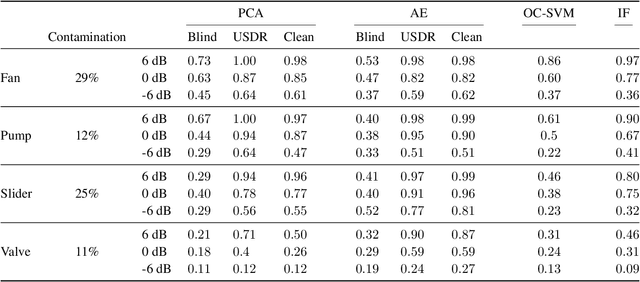
Anomaly detection (AD) tasks have been solved using machine learning algorithms in various domains and applications. The great majority of these algorithms use normal data to train a residual-based model, and assign anomaly scores to unseen samples based on their dissimilarity with the learned normal regime. The underlying assumption of these approaches is that anomaly-free data is available for training. This is, however, often not the case in real-world operational settings, where the training data may be contaminated with a certain fraction of abnormal samples. Training with contaminated data, in turn, inevitably leads to a deteriorated AD performance of the residual-based algorithms. In this paper we introduce a framework for a fully unsupervised refinement of contaminated training data for AD tasks. The framework is generic and can be applied to any residual-based machine learning model. We demonstrate the application of the framework to two public datasets of multivariate time series machine data from different application fields. We show its clear superiority over the naive approach of training with contaminated data without refinement. Moreover, we compare it to the ideal, unrealistic reference in which anomaly-free data would be available for training. Since the approach exploits information from the anomalies, and not only from the normal regime, it is comparable and often outperforms the ideal baseline as well.
Application of MUSIC-type imaging for anomaly detection without background information
Jul 03, 2023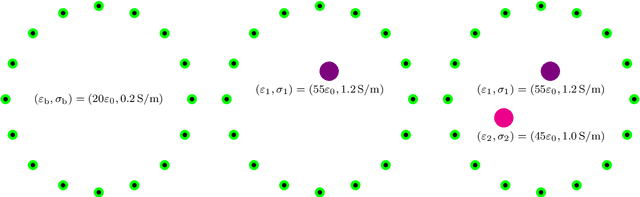
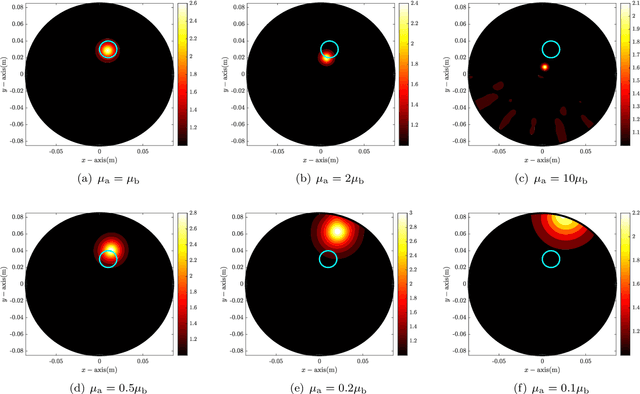
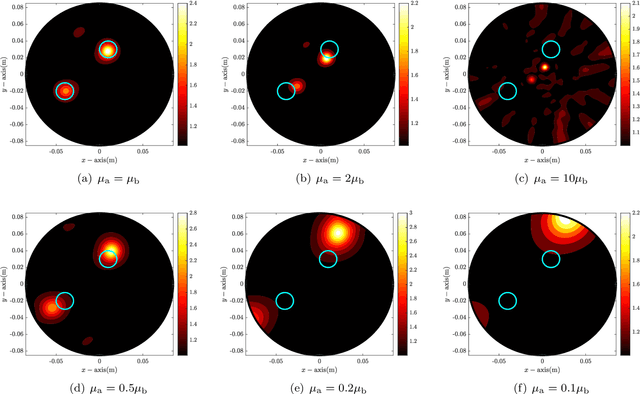
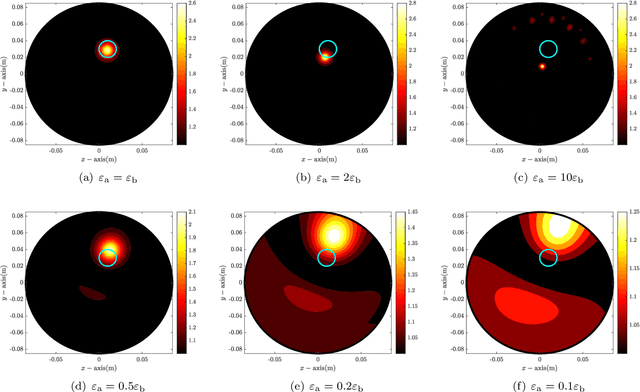
It has been demonstrated that the MUltiple SIgnal Classification (MUSIC) algorithm is fast, stable, and effective for localizing small anomalies in microwave imaging. For the successful application of MUSIC, exact values of permittivity, conductivity, and permeability of the background must be known. If one of these values is unknown, it will fail to identify the location of an anomaly. However, to the best of our knowledge, no explanation of this failure has been provided yet. In this paper, we consider the application of MUSIC to the localization of a small anomaly from scattering parameter data when complete information of the background is not available. Thanks to the framework of the integral equation formulation for the scattering parameter data, an analytical expression of the MUSIC-type imaging function in terms of the infinite series of Bessel functions of integer order is derived. Based on the theoretical result, we confirm that the identification of a small anomaly is significantly affected by the applied values of permittivity and conductivity. However, fortunately, it is possible to recognize the anomaly if the applied value of conductivity is small. Simulation results with synthetic data are reported to demonstrate the theoretical result.