 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Zero-Resource Hallucination Prevention for Large Language Models
Sep 06, 2023

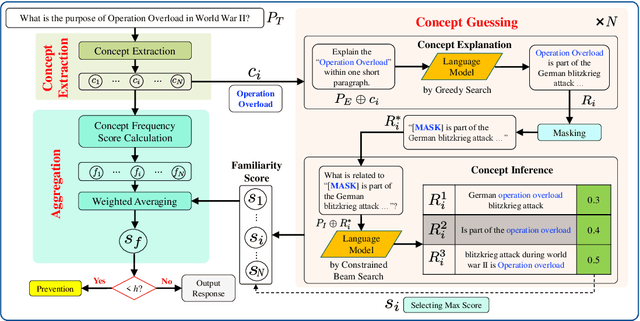

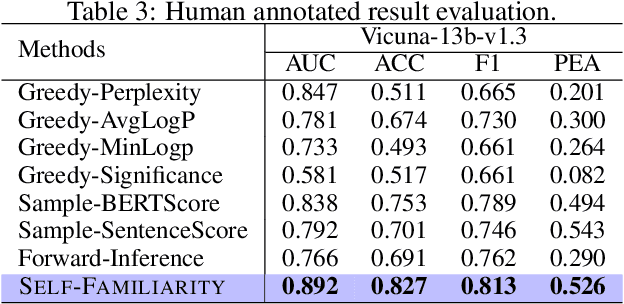
The prevalent use of large language models (LLMs) in various domains has drawn attention to the issue of "hallucination," which refers to instances where LLMs generate factually inaccurate or ungrounded information. Existing techniques for hallucination detection in language assistants rely on intricate fuzzy, specific free-language-based chain of thought (CoT) techniques or parameter-based methods that suffer from interpretability issues. Additionally, the methods that identify hallucinations post-generation could not prevent their occurrence and suffer from inconsistent performance due to the influence of the instruction format and model style. In this paper, we introduce a novel pre-detection self-evaluation technique, referred to as {\method}, which focuses on evaluating the model's familiarity with the concepts present in the input instruction and withholding the generation of response in case of unfamiliar concepts. This approach emulates the human ability to refrain from responding to unfamiliar topics, thus reducing hallucinations. We validate {\method} across four different large language models, demonstrating consistently superior performance compared to existing techniques. Our findings propose a significant shift towards preemptive strategies for hallucination mitigation in LLM assistants, promising improvements in reliability, applicability, and interpretability.
MEGANet: Multi-Scale Edge-Guided Attention Network for Weak Boundary Polyp Segmentation
Sep 06, 2023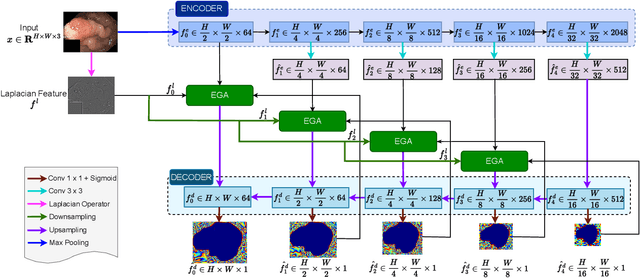
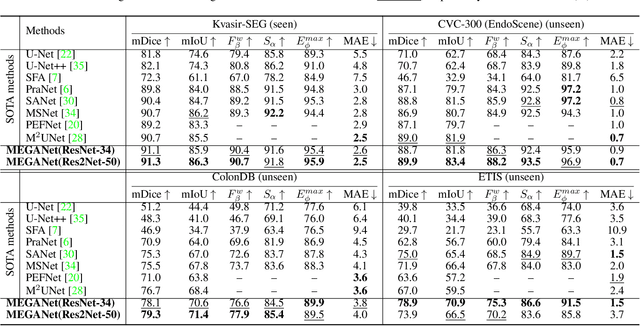
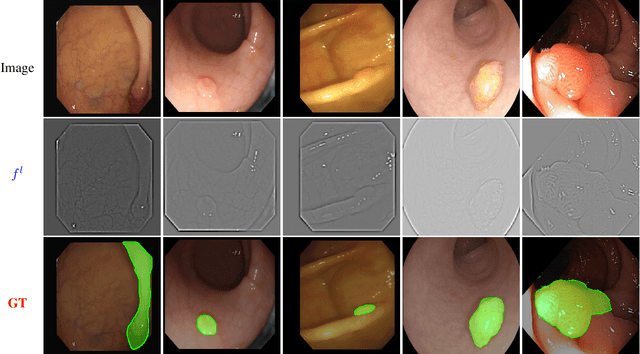
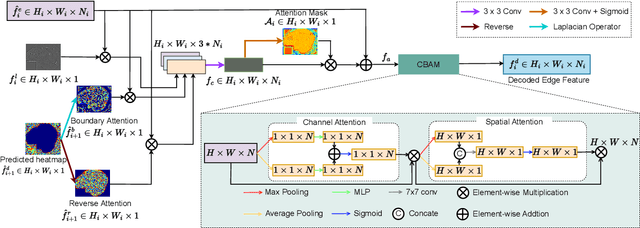
Efficient polyp segmentation in healthcare plays a critical role in enabling early diagnosis of colorectal cancer. However, the segmentation of polyps presents numerous challenges, including the intricate distribution of backgrounds, variations in polyp sizes and shapes, and indistinct boundaries. Defining the boundary between the foreground (i.e. polyp itself) and the background (surrounding tissue) is difficult. To mitigate these challenges, we propose Multi-Scale Edge-Guided Attention Network (MEGANet) tailored specifically for polyp segmentation within colonoscopy images. This network draws inspiration from the fusion of a classical edge detection technique with an attention mechanism. By combining these techniques, MEGANet effectively preserves high-frequency information, notably edges and boundaries, which tend to erode as neural networks deepen. MEGANet is designed as an end-to-end framework, encompassing three key modules: an encoder, which is responsible for capturing and abstracting the features from the input image, a decoder, which focuses on salient features, and the Edge-Guided Attention module (EGA) that employs the Laplacian Operator to accentuate polyp boundaries. Extensive experiments, both qualitative and quantitative, on five benchmark datasets, demonstrate that our EGANet outperforms other existing SOTA methods under six evaluation metrics. Our code is available at \url{https://github.com/DinhHieuHoang/MEGANet}
Resilient source seeking with robot swarms
Sep 06, 2023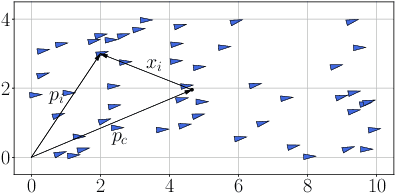
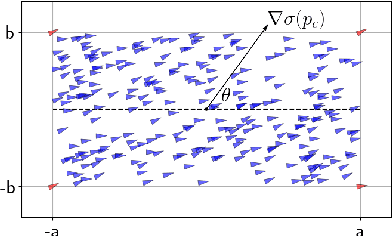
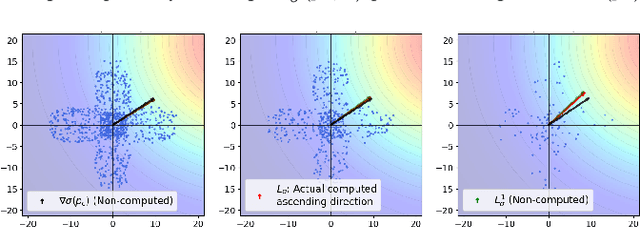
We present a solution for locating the source, or maximum, of an unknown scalar field using a swarm of mobile robots. Unlike relying on the traditional gradient information, the swarm determines an ascending direction to approach the source with arbitrary precision. The ascending direction is calculated from measurements of the field strength at the robot locations and their relative positions concerning the centroid. Rather than focusing on individual robots, we focus the analysis on the density of robots per unit area to guarantee a more resilient swarm, i.e., the functionality remains even if individuals go missing or are misplaced during the mission. We reinforce the robustness of the algorithm by providing sufficient conditions for the swarm shape so that the ascending direction is almost parallel to the gradient. The swarm can respond to an unexpected environment by morphing its shape and exploiting the existence of multiple ascending directions. Finally, we validate our approach numerically with hundreds of robots. The fact that a large number of robots always calculate an ascending direction compensates for the loss of individuals and mitigates issues arising from the actuator and sensor noises.
MAD: Modality Agnostic Distance Measure for Image Registration
Sep 06, 2023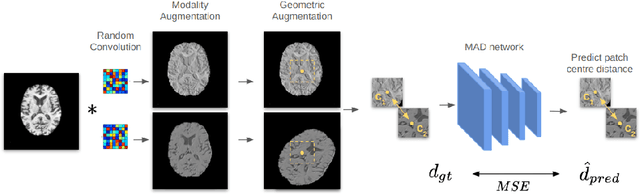
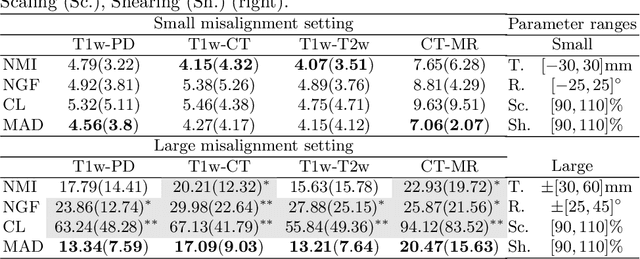
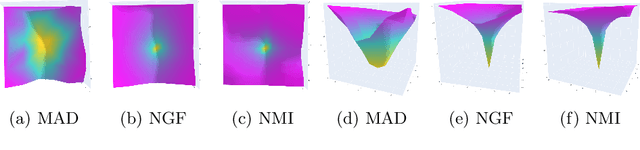

Multi-modal image registration is a crucial pre-processing step in many medical applications. However, it is a challenging task due to the complex intensity relationships between different imaging modalities, which can result in large discrepancy in image appearance. The success of multi-modal image registration, whether it is conventional or learning based, is predicated upon the choice of an appropriate distance (or similarity) measure. Particularly, deep learning registration algorithms lack in accuracy or even fail completely when attempting to register data from an "unseen" modality. In this work, we present Modality Agnostic Distance (MAD), a deep image distance}] measure that utilises random convolutions to learn the inherent geometry of the images while being robust to large appearance changes. Random convolutions are geometry-preserving modules which we use to simulate an infinite number of synthetic modalities alleviating the need for aligned paired data during training. We can therefore train MAD on a mono-modal dataset and successfully apply it to a multi-modal dataset. We demonstrate that not only can MAD affinely register multi-modal images successfully, but it has also a larger capture range than traditional measures such as Mutual Information and Normalised Gradient Fields.
Knowledge Distillation Layer that Lets the Student Decide
Sep 06, 2023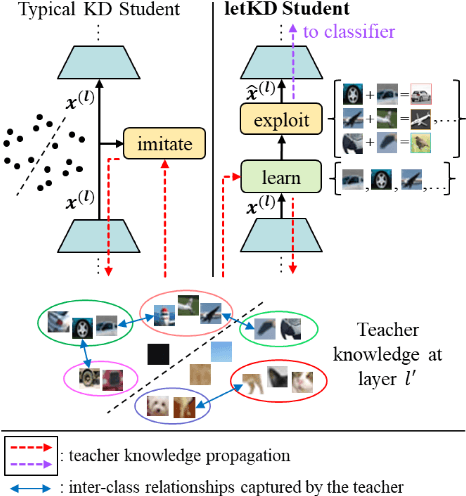
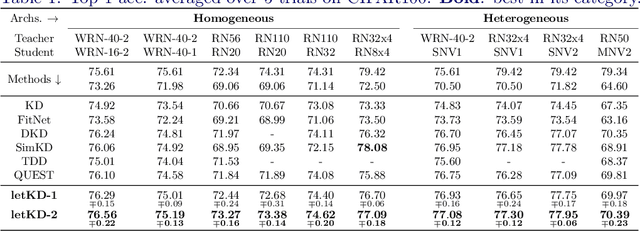
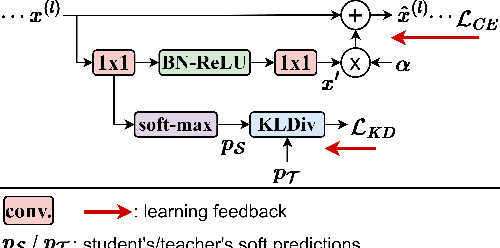
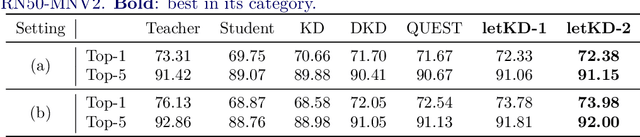
Typical technique in knowledge distillation (KD) is regularizing the learning of a limited capacity model (student) by pushing its responses to match a powerful model's (teacher). Albeit useful especially in the penultimate layer and beyond, its action on student's feature transform is rather implicit, limiting its practice in the intermediate layers. To explicitly embed the teacher's knowledge in feature transform, we propose a learnable KD layer for the student which improves KD with two distinct abilities: i) learning how to leverage the teacher's knowledge, enabling to discard nuisance information, and ii) feeding forward the transferred knowledge deeper. Thus, the student enjoys the teacher's knowledge during the inference besides training. Formally, we repurpose 1x1-BN-ReLU-1x1 convolution block to assign a semantic vector to each local region according to the template (supervised by the teacher) that the corresponding region of the student matches. To facilitate template learning in the intermediate layers, we propose a novel form of supervision based on the teacher's decisions. Through rigorous experimentation, we demonstrate the effectiveness of our approach on 3 popular classification benchmarks. Code is available at: https://github.com/adagorgun/letKD-framework
Measuring Spurious Correlation in Classification: 'Clever Hans' in Translationese
Aug 25, 2023Recent work has shown evidence of 'Clever Hans' behavior in high-performance neural translationese classifiers, where BERT-based classifiers capitalize on spurious correlations, in particular topic information, between data and target classification labels, rather than genuine translationese signals. Translationese signals are subtle (especially for professional translation) and compete with many other signals in the data such as genre, style, author, and, in particular, topic. This raises the general question of how much of the performance of a classifier is really due to spurious correlations in the data versus the signals actually targeted for by the classifier, especially for subtle target signals and in challenging (low resource) data settings. We focus on topic-based spurious correlation and approach the question from two directions: (i) where we have no knowledge about spurious topic information and its distribution in the data, (ii) where we have some indication about the nature of spurious topic correlations. For (i) we develop a measure from first principles capturing alignment of unsupervised topics with target classification labels as an indication of spurious topic information in the data. We show that our measure is the same as purity in clustering and propose a 'topic floor' (as in a 'noise floor') for classification. For (ii) we investigate masking of known spurious topic carriers in classification. Both (i) and (ii) contribute to quantifying and (ii) to mitigating spurious correlations.
Information-Computation Tradeoffs for Learning Margin Halfspaces with Random Classification Noise
Jun 28, 2023We study the problem of PAC learning $\gamma$-margin halfspaces with Random Classification Noise. We establish an information-computation tradeoff suggesting an inherent gap between the sample complexity of the problem and the sample complexity of computationally efficient algorithms. Concretely, the sample complexity of the problem is $\widetilde{\Theta}(1/(\gamma^2 \epsilon))$. We start by giving a simple efficient algorithm with sample complexity $\widetilde{O}(1/(\gamma^2 \epsilon^2))$. Our main result is a lower bound for Statistical Query (SQ) algorithms and low-degree polynomial tests suggesting that the quadratic dependence on $1/\epsilon$ in the sample complexity is inherent for computationally efficient algorithms. Specifically, our results imply a lower bound of $\widetilde{\Omega}(1/(\gamma^{1/2} \epsilon^2))$ on the sample complexity of any efficient SQ learner or low-degree test.
Navigating Out-of-Distribution Electricity Load Forecasting during COVID-19: A Continual Learning Approach Leveraging Human Mobility
Sep 08, 2023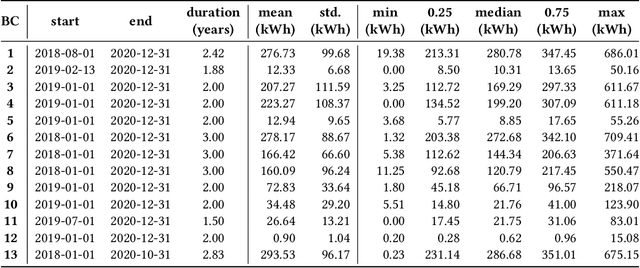
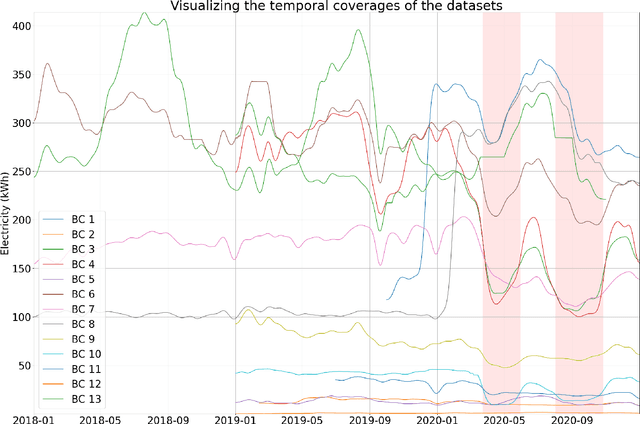
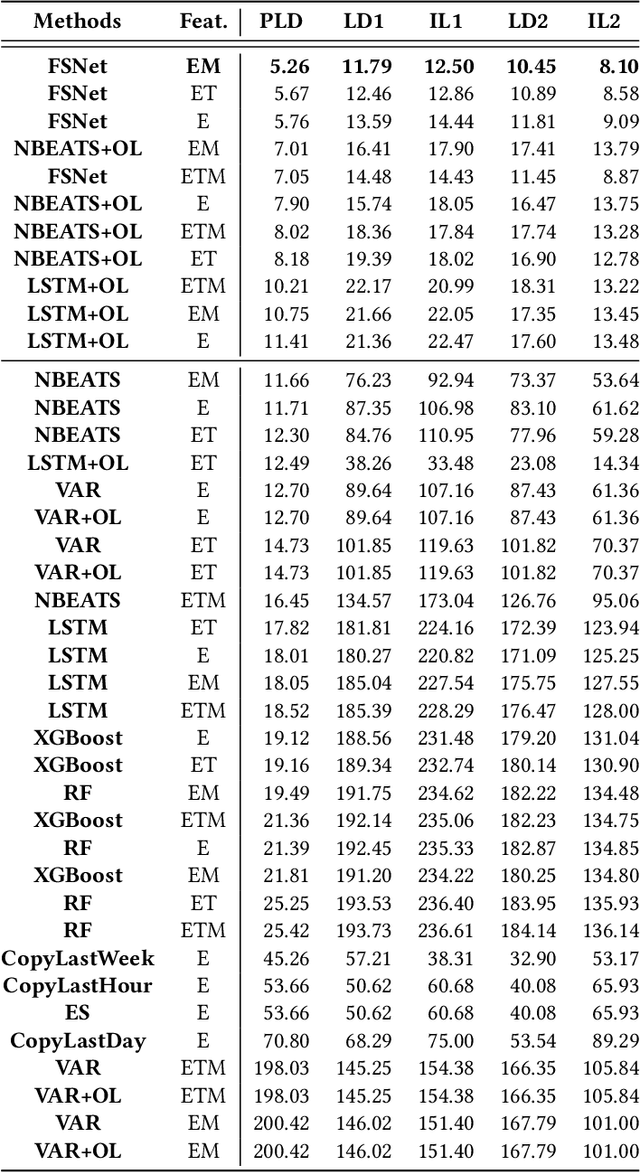
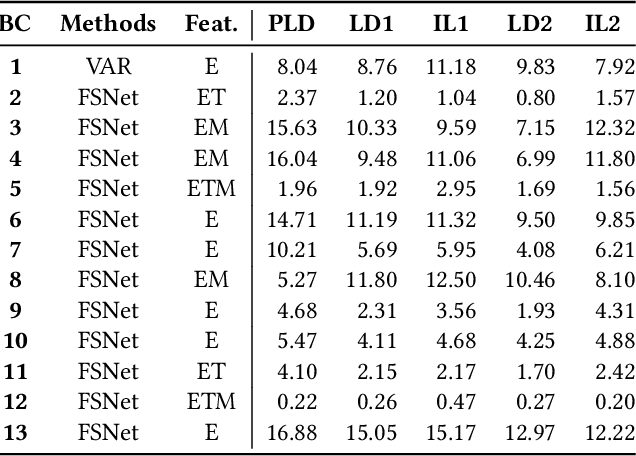
In traditional deep learning algorithms, one of the key assumptions is that the data distribution remains constant during both training and deployment. However, this assumption becomes problematic when faced with Out-of-Distribution periods, such as the COVID-19 lockdowns, where the data distribution significantly deviates from what the model has seen during training. This paper employs a two-fold strategy: utilizing continual learning techniques to update models with new data and harnessing human mobility data collected from privacy-preserving pedestrian counters located outside buildings. In contrast to online learning, which suffers from 'catastrophic forgetting' as newly acquired knowledge often erases prior information, continual learning offers a holistic approach by preserving past insights while integrating new data. This research applies FSNet, a powerful continual learning algorithm, to real-world data from 13 building complexes in Melbourne, Australia, a city which had the second longest total lockdown duration globally during the pandemic. Results underscore the crucial role of continual learning in accurate energy forecasting, particularly during Out-of-Distribution periods. Secondary data such as mobility and temperature provided ancillary support to the primary forecasting model. More importantly, while traditional methods struggled to adapt during lockdowns, models featuring at least online learning demonstrated resilience, with lockdown periods posing fewer challenges once armed with adaptive learning techniques. This study contributes valuable methodologies and insights to the ongoing effort to improve energy load forecasting during future Out-of-Distribution periods.
Robot Localization and Mapping Final Report -- Sequential Adversarial Learning for Self-Supervised Deep Visual Odometry
Sep 08, 2023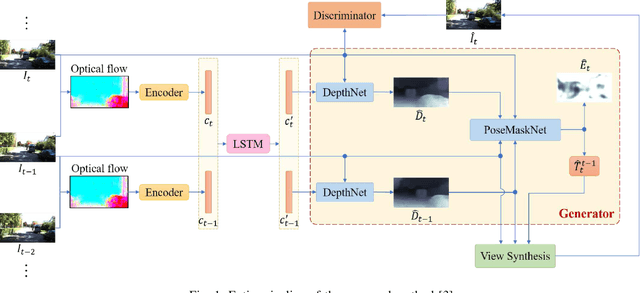

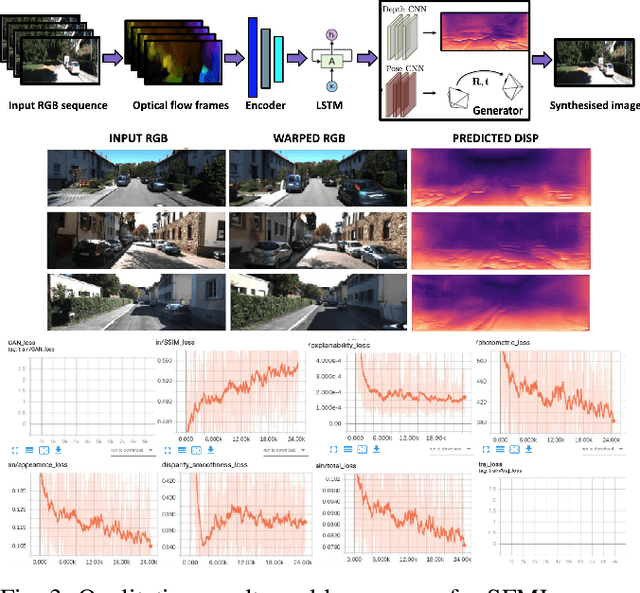
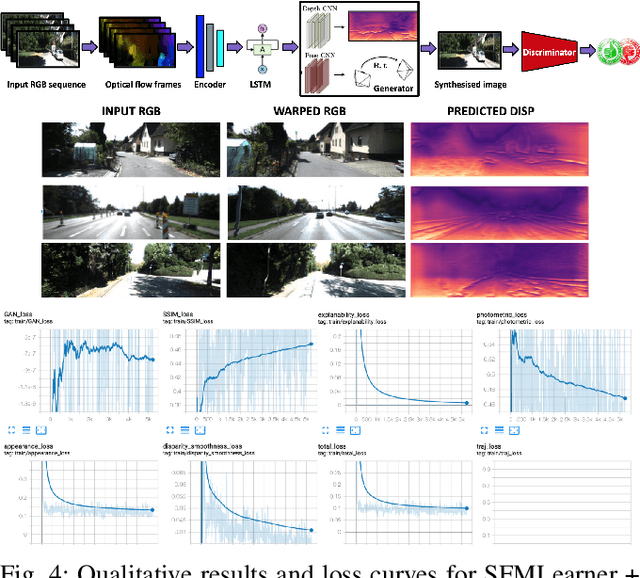
Visual odometry (VO) and SLAM have been using multi-view geometry via local structure from motion for decades. These methods have a slight disadvantage in challenging scenarios such as low-texture images, dynamic scenarios, etc. Meanwhile, use of deep neural networks to extract high level features is ubiquitous in computer vision. For VO, we can use these deep networks to extract depth and pose estimates using these high level features. The visual odometry task then can be modeled as an image generation task where the pose estimation is the by-product. This can also be achieved in a self-supervised manner, thereby eliminating the data (supervised) intensive nature of training deep neural networks. Although some works tried the similar approach [1], the depth and pose estimation in the previous works are vague sometimes resulting in accumulation of error (drift) along the trajectory. The goal of this work is to tackle these limitations of past approaches and to develop a method that can provide better depths and pose estimates. To address this, a couple of approaches are explored: 1) Modeling: Using optical flow and recurrent neural networks (RNN) in order to exploit spatio-temporal correlations which can provide more information to estimate depth. 2) Loss function: Generative adversarial network (GAN) [2] is deployed to improve the depth estimation (and thereby pose too), as shown in Figure 1. This additional loss term improves the realism in generated images and reduces artifacts.
Object-Centric Multiple Object Tracking
Sep 05, 2023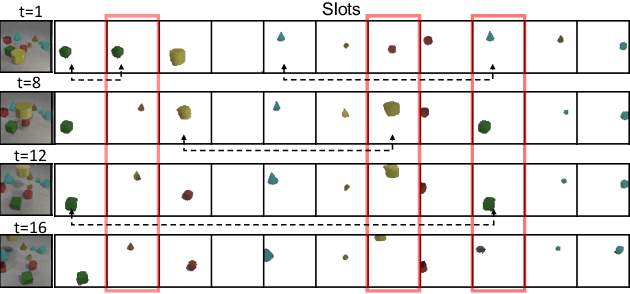
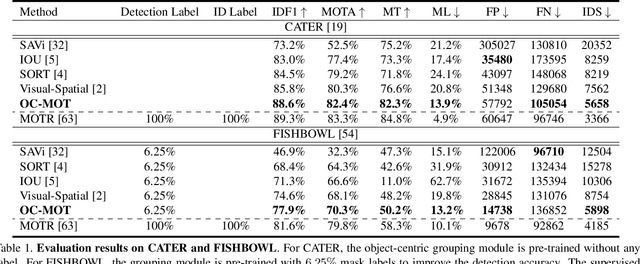
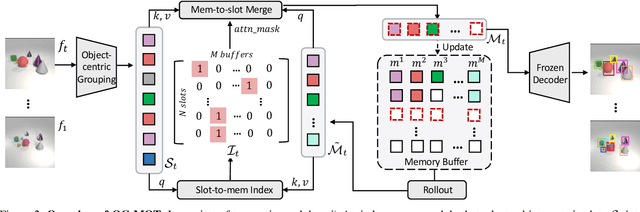
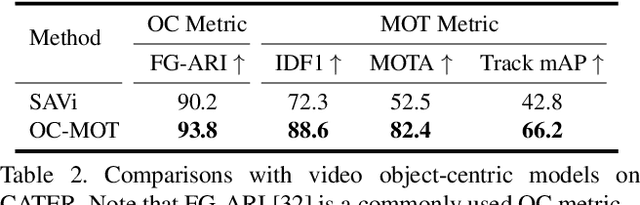
Unsupervised object-centric learning methods allow the partitioning of scenes into entities without additional localization information and are excellent candidates for reducing the annotation burden of multiple-object tracking (MOT) pipelines. Unfortunately, they lack two key properties: objects are often split into parts and are not consistently tracked over time. In fact, state-of-the-art models achieve pixel-level accuracy and temporal consistency by relying on supervised object detection with additional ID labels for the association through time. This paper proposes a video object-centric model for MOT. It consists of an index-merge module that adapts the object-centric slots into detection outputs and an object memory module that builds complete object prototypes to handle occlusions. Benefited from object-centric learning, we only require sparse detection labels (0%-6.25%) for object localization and feature binding. Relying on our self-supervised Expectation-Maximization-inspired loss for object association, our approach requires no ID labels. Our experiments significantly narrow the gap between the existing object-centric model and the fully supervised state-of-the-art and outperform several unsupervised trackers.