 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An Ensemble Score Filter for Tracking High-Dimensional Nonlinear Dynamical Systems
Sep 02, 2023
We propose an ensemble score filter (EnSF) for solving high-dimensional nonlinear filtering problems with superior accuracy. A major drawback of existing filtering methods, e.g., particle filters or ensemble Kalman filters, is the low accuracy in handling high-dimensional and highly nonlinear problems. EnSF attacks this challenge by exploiting the score-based diffusion model, defined in a pseudo-temporal domain, to characterizing the evolution of the filtering density. EnSF stores the information of the recursively updated filtering density function in the score function, in stead of storing the information in a set of finite Monte Carlo samples (used in particle filters and ensemble Kalman filters). Unlike existing diffusion models that train neural networks to approximate the score function, we develop a training-free score estimation that uses mini-batch-based Monte Carlo estimator to directly approximate the score function at any pseudo-spatial-temporal location, which provides sufficient accuracy in solving high-dimensional nonlinear problems as well as saves tremendous amount of time spent on training neural networks. Another essential aspect of EnSF is its analytical update step, gradually incorporating data information into the score function, which is crucial in mitigating the degeneracy issue faced when dealing with very high-dimensional nonlinear filtering problems. High-dimensional Lorenz systems are used to demonstrate the performance of our method. EnSF provides surprisingly impressive performance in reliably tracking extremely high-dimensional Lorenz systems (up to 1,000,000 dimension) with highly nonlinear observation processes, which is a well-known challenging problem for existing filtering methods.
AdSEE: Investigating the Impact of Image Style Editing on Advertisement Attractiveness
Sep 15, 2023Online advertisements are important elements in e-commerce sites, social media platforms, and search engines. With the increasing popularity of mobile browsing, many online ads are displayed with visual information in the form of a cover image in addition to text descriptions to grab the attention of users. Various recent studies have focused on predicting the click rates of online advertisements aware of visual features or composing optimal advertisement elements to enhance visibility. In this paper, we propose Advertisement Style Editing and Attractiveness Enhancement (AdSEE), which explores whether semantic editing to ads images can affect or alter the popularity of online advertisements. We introduce StyleGAN-based facial semantic editing and inversion to ads images and train a click rate predictor attributing GAN-based face latent representations in addition to traditional visual and textual features to click rates. Through a large collected dataset named QQ-AD, containing 20,527 online ads, we perform extensive offline tests to study how different semantic directions and their edit coefficients may impact click rates. We further design a Genetic Advertisement Editor to efficiently search for the optimal edit directions and intensity given an input ad cover image to enhance its projected click rates. Online A/B tests performed over a period of 5 days have verified the increased click-through rates of AdSEE-edited samples as compared to a control group of original ads, verifying the relation between image styles and ad popularity. We open source the code for AdSEE research at https://github.com/LiyaoJiang1998/adsee.
MOSAIC: Learning Unified Multi-Sensory Object Property Representations for Robot Perception
Sep 15, 2023A holistic understanding of object properties across diverse sensory modalities (e.g., visual, audio, and haptic) is essential for tasks ranging from object categorization to complex manipulation. Drawing inspiration from cognitive science studies that emphasize the significance of multi-sensory integration in human perception, we introduce MOSAIC (Multi-modal Object property learning with Self-Attention and Integrated Comprehension), a novel framework designed to facilitate the learning of unified multi-sensory object property representations. While it is undeniable that visual information plays a prominent role, we acknowledge that many fundamental object properties extend beyond the visual domain to encompass attributes like texture, mass distribution, or sounds, which significantly influence how we interact with objects. In MOSAIC, we leverage this profound insight by distilling knowledge from the extensive pre-trained Contrastive Language-Image Pre-training (CLIP) model, aligning these representations not only across vision but also haptic and auditory sensory modalities. Through extensive experiments on a dataset where a humanoid robot interacts with 100 objects across 10 exploratory behaviors, we demonstrate the versatility of MOSAIC in two task families: object categorization and object-fetching tasks. Our results underscore the efficacy of MOSAIC's unified representations, showing competitive performance in category recognition through a simple linear probe setup and excelling in the fetch object task under zero-shot transfer conditions. This work pioneers the application of CLIP-based sensory grounding in robotics, promising a significant leap in multi-sensory perception capabilities for autonomous systems. We have released the code, datasets, and additional results: https://github.com/gtatiya/MOSAIC.
Data-driven classification of low-power communication signals by an unauthenticated user using a software-defined radio
Sep 08, 2023Many large-scale distributed multi-agent systems exchange information over low-power communication networks. In particular, agents intermittently communicate state and control signals in robotic network applications, often with limited power over an unlicensed spectrum, prone to eavesdropping and denial-of-service attacks. In this paper, we argue that a widely popular low-power communication protocol known as LoRa is vulnerable to denial-of-service attacks by an unauthenticated attacker if it can successfully identify a target signal's bandwidth and spreading factor. Leveraging a structural pattern in the LoRa signal's instantaneous frequency representation, we relate the problem of jointly inferring the two unknown parameters to a classification problem, which can be efficiently implemented using neural networks.
RST-style Discourse Parsing Guided by Document-level Content Structures
Sep 08, 2023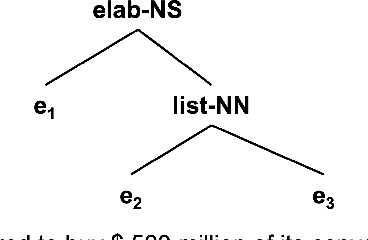
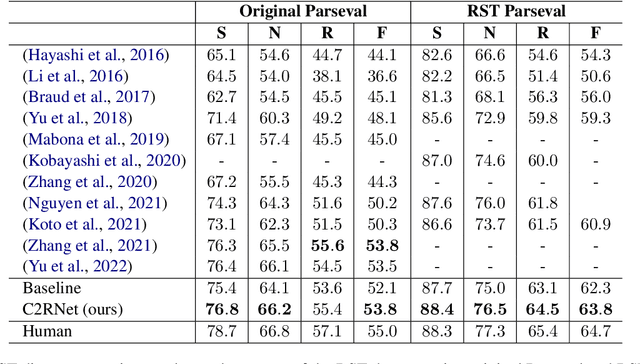

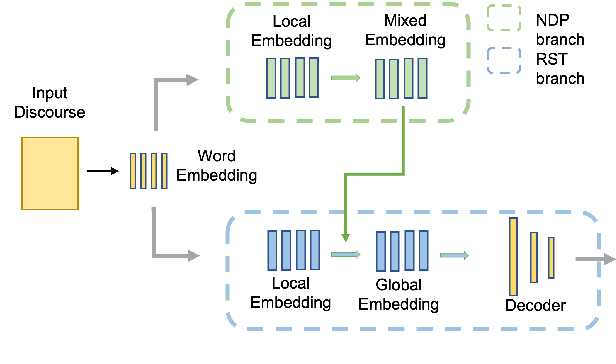
Rhetorical Structure Theory based Discourse Parsing (RST-DP) explores how clauses, sentences, and large text spans compose a whole discourse and presents the rhetorical structure as a hierarchical tree. Existing RST parsing pipelines construct rhetorical structures without the knowledge of document-level content structures, which causes relatively low performance when predicting the discourse relations for large text spans. Recognizing the value of high-level content-related information in facilitating discourse relation recognition, we propose a novel pipeline for RST-DP that incorporates structure-aware news content sentence representations derived from the task of News Discourse Profiling. By incorporating only a few additional layers, this enhanced pipeline exhibits promising performance across various RST parsing metrics.
Polygon Intersection-over-Union Loss for Viewpoint-Agnostic Monocular 3D Vehicle Detection
Sep 13, 2023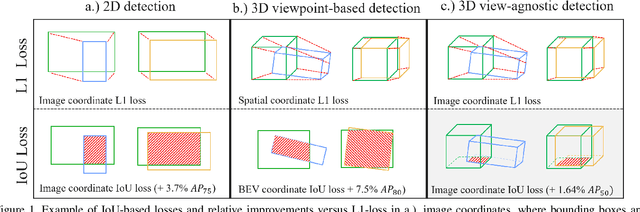
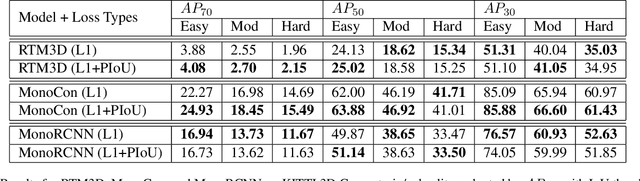
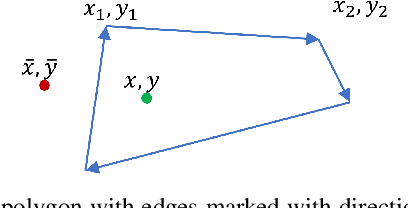
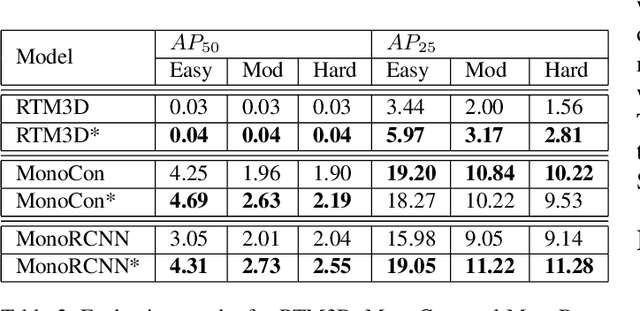
Monocular 3D object detection is a challenging task because depth information is difficult to obtain from 2D images. A subset of viewpoint-agnostic monocular 3D detection methods also do not explicitly leverage scene homography or geometry during training, meaning that a model trained thusly can detect objects in images from arbitrary viewpoints. Such works predict the projections of the 3D bounding boxes on the image plane to estimate the location of the 3D boxes, but these projections are not rectangular so the calculation of IoU between these projected polygons is not straightforward. This work proposes an efficient, fully differentiable algorithm for the calculation of IoU between two convex polygons, which can be utilized to compute the IoU between two 3D bounding box footprints viewed from an arbitrary angle. We test the performance of the proposed polygon IoU loss (PIoU loss) on three state-of-the-art viewpoint-agnostic 3D detection models. Experiments demonstrate that the proposed PIoU loss converges faster than L1 loss and that in 3D detection models, a combination of PIoU loss and L1 loss gives better results than L1 loss alone (+1.64% AP70 for MonoCon on cars, +0.18% AP70 for RTM3D on cars, and +0.83%/+2.46% AP50/AP25 for MonoRCNN on cyclists).
Utilizing Hybrid Trajectory Prediction Models to Recognize Highly Interactive Traffic Scenarios
Sep 13, 2023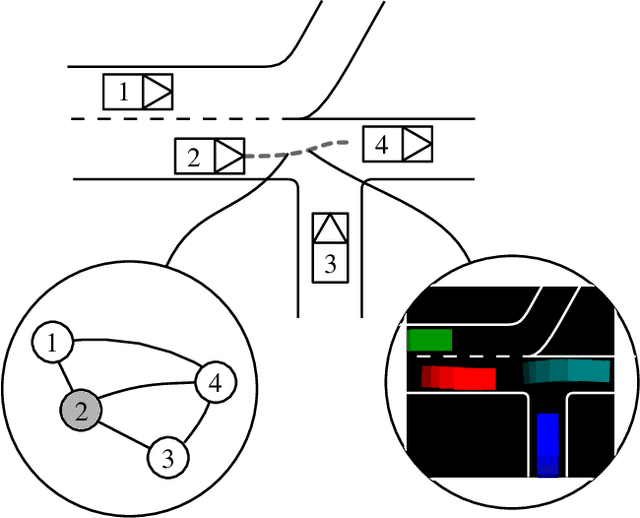
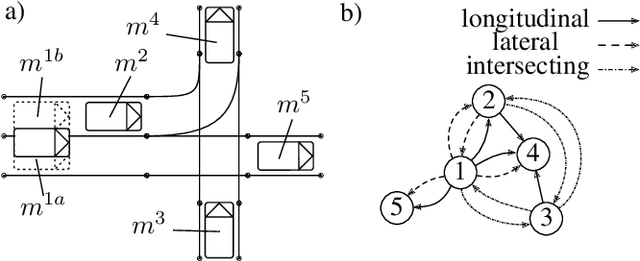
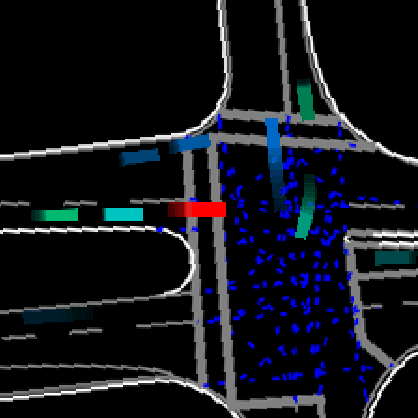
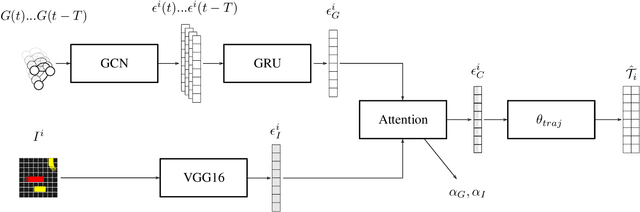
Autonomous vehicles hold great promise in improving the future of transportation. The driving models used in these vehicles are based on neural networks, which can be difficult to validate. However, ensuring the safety of these models is crucial. Traditional field tests can be costly, time-consuming, and dangerous. To address these issues, scenario-based closed-loop simulations can simulate many hours of vehicle operation in a shorter amount of time and allow for specific investigation of important situations. Nonetheless, the detection of relevant traffic scenarios that also offer substantial testing benefits remains a significant challenge. To address this need, in this paper we build an imitation learning based trajectory prediction for traffic participants. We combine an image-based (CNN) approach to represent spatial environmental factors and a graph-based (GNN) approach to specifically represent relations between traffic participants. In our understanding, traffic scenes that are highly interactive due to the network's significant utilization of the social component are more pertinent for a validation process. Therefore, we propose to use the activity of such sub networks as a measure of interactivity of a traffic scene. We evaluate our model using a motion dataset and discuss the value of the relationship information with respect to different traffic situations.
A Robust SINDy Approach by Combining Neural Networks and an Integral Form
Sep 13, 2023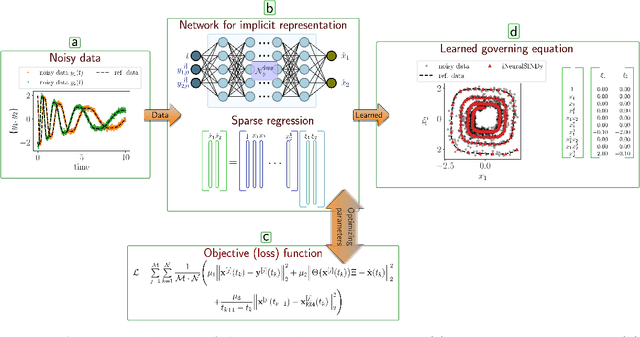
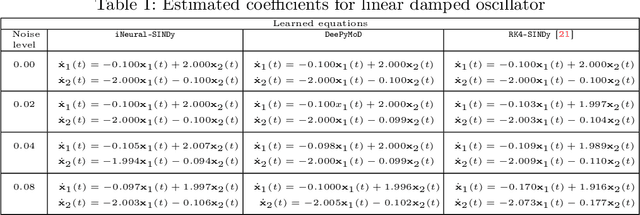
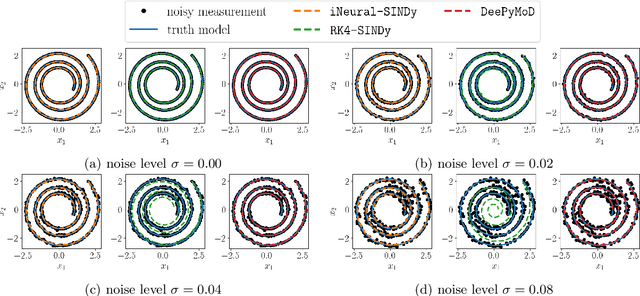
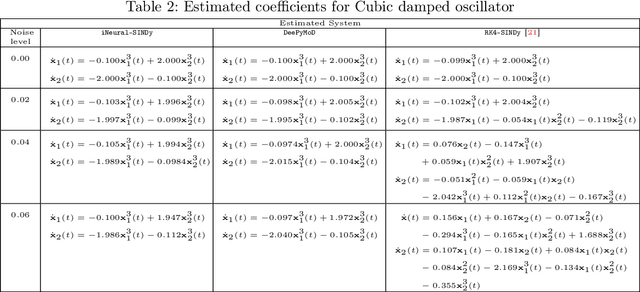
The discovery of governing equations from data has been an active field of research for decades. One widely used methodology for this purpose is sparse regression for nonlinear dynamics, known as SINDy. Despite several attempts, noisy and scarce data still pose a severe challenge to the success of the SINDy approach. In this work, we discuss a robust method to discover nonlinear governing equations from noisy and scarce data. To do this, we make use of neural networks to learn an implicit representation based on measurement data so that not only it produces the output in the vicinity of the measurements but also the time-evolution of output can be described by a dynamical system. Additionally, we learn such a dynamic system in the spirit of the SINDy framework. Leveraging the implicit representation using neural networks, we obtain the derivative information -- required for SINDy -- using an automatic differentiation tool. To enhance the robustness of our methodology, we further incorporate an integral condition on the output of the implicit networks. Furthermore, we extend our methodology to handle data collected from multiple initial conditions. We demonstrate the efficiency of the proposed methodology to discover governing equations under noisy and scarce data regimes by means of several examples and compare its performance with existing methods.
Prompting Segmentation with Sound is Generalizable Audio-Visual Source Localizer
Sep 13, 2023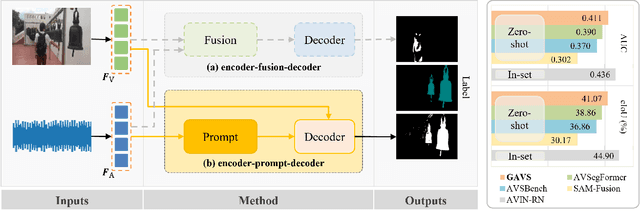
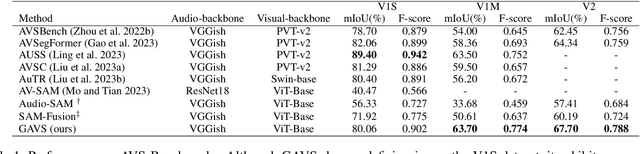
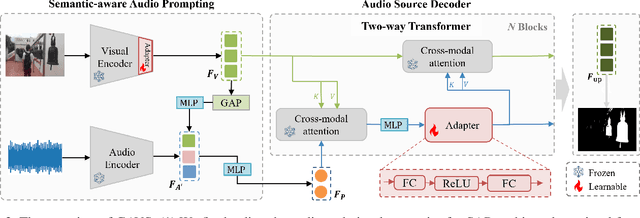

Never having seen an object and heard its sound simultaneously, can the model still accurately localize its visual position from the input audio? In this work, we concentrate on the Audio-Visual Localization and Segmentation tasks but under the demanding zero-shot and few-shot scenarios. To achieve this goal, different from existing approaches that mostly employ the encoder-fusion-decoder paradigm to decode localization information from the fused audio-visual feature, we introduce the encoder-prompt-decoder paradigm, aiming to better fit the data scarcity and varying data distribution dilemmas with the help of abundant knowledge from pre-trained models. Specifically, we first propose to construct Semantic-aware Audio Prompt (SAP) to help the visual foundation model focus on sounding objects, meanwhile, the semantic gap between the visual and audio modalities is also encouraged to shrink. Then, we develop a Correlation Adapter (ColA) to keep minimal training efforts as well as maintain adequate knowledge of the visual foundation model. By equipping with these means, extensive experiments demonstrate that this new paradigm outperforms other fusion-based methods in both the unseen class and cross-dataset settings. We hope that our work can further promote the generalization study of Audio-Visual Localization and Segmentation in practical application scenarios.
Data Augmentation for Conversational AI
Sep 09, 2023Advancements in conversational systems have revolutionized information access, surpassing the limitations of single queries. However, developing dialogue systems requires a large amount of training data, which is a challenge in low-resource domains and languages. Traditional data collection methods like crowd-sourcing are labor-intensive and time-consuming, making them ineffective in this context. Data augmentation (DA) is an affective approach to alleviate the data scarcity problem in conversational systems. This tutorial provides a comprehensive and up-to-date overview of DA approaches in the context of conversational systems. It highlights recent advances in conversation augmentation, open domain and task-oriented conversation generation, and different paradigms of evaluating these models. We also discuss current challenges and future directions in order to help researchers and practitioners to further advance the field in this area.