 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Shared Control Based on Extended Lipschitz Analysis With Application to Human-Superlimb Collaboration
Sep 01, 2023
This paper presents a quantitative method to construct voluntary manual control and sensor-based reactive control in human-robot collaboration based on Lipschitz conditions. To collaborate with a human, the robot observes the human's motions and predicts a desired action. This predictor is constructed from data of human demonstrations observed through the robot's sensors. Analysis of demonstration data based on Lipschitz quotients evaluates a) whether the desired action is predictable and b) to what extent the action is predictable. If the quotients are low for all the input-output pairs of demonstration data, a predictor can be constructed with a smooth function. In dealing with human demonstration data, however, the Lipschitz quotients tend to be very high in some situations due to the discrepancy between the information that humans use and the one robots can obtain. This paper a) presents a method for seeking missing information or a new variable that can lower the Lipschitz quotients by adding the new variable to the input space, and b) constructs a human-robot shared control system based on the Lipschitz analysis. Those predictable situations are assigned to the robot's reactive control, while human voluntary control is assigned to those situations where the Lipschitz quotients are high even after the new variable is added. The latter situations are deemed unpredictable and are rendered to the human. This human-robot shared control method is applied to assist hemiplegic patients in a bimanual eating task with a Supernumerary Robotic Limb, which works in concert with an unaffected functional hand.
RBA-GCN: Relational Bilevel Aggregation Graph Convolutional Network for Emotion Recognition
Aug 18, 2023Emotion recognition in conversation (ERC) has received increasing attention from researchers due to its wide range of applications. As conversation has a natural graph structure, numerous approaches used to model ERC based on graph convolutional networks (GCNs) have yielded significant results. However, the aggregation approach of traditional GCNs suffers from the node information redundancy problem, leading to node discriminant information loss. Additionally, single-layer GCNs lack the capacity to capture long-range contextual information from the graph. Furthermore, the majority of approaches are based on textual modality or stitching together different modalities, resulting in a weak ability to capture interactions between modalities. To address these problems, we present the relational bilevel aggregation graph convolutional network (RBA-GCN), which consists of three modules: the graph generation module (GGM), similarity-based cluster building module (SCBM) and bilevel aggregation module (BiAM). First, GGM constructs a novel graph to reduce the redundancy of target node information. Then, SCBM calculates the node similarity in the target node and its structural neighborhood, where noisy information with low similarity is filtered out to preserve the discriminant information of the node. Meanwhile, BiAM is a novel aggregation method that can preserve the information of nodes during the aggregation process. This module can construct the interaction between different modalities and capture long-range contextual information based on similarity clusters. On both the IEMOCAP and MELD datasets, the weighted average F1 score of RBA-GCN has a 2.17$\sim$5.21\% improvement over that of the most advanced method.
Channel and Spatial Relation-Propagation Network for RGB-Thermal Semantic Segmentation
Aug 24, 2023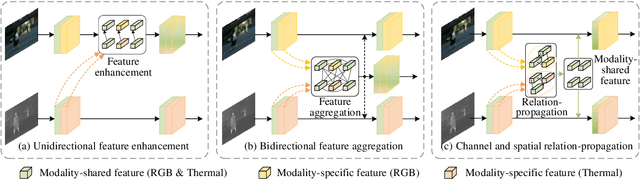
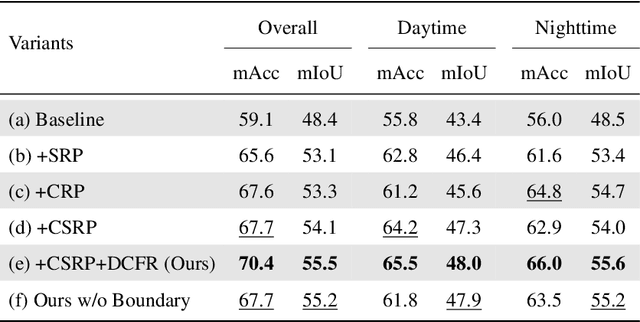
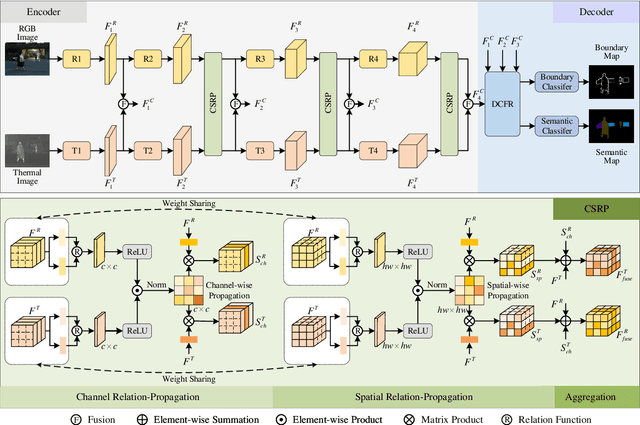
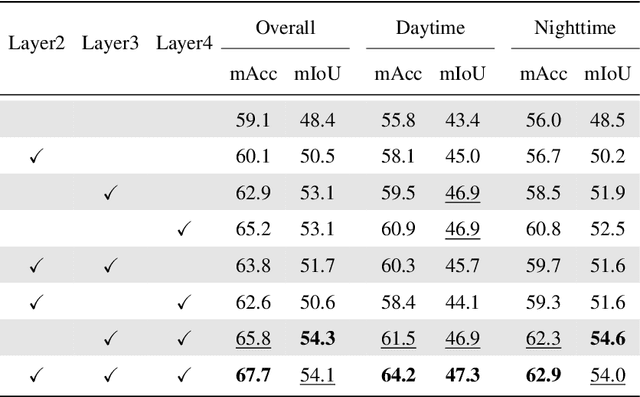
RGB-Thermal (RGB-T) semantic segmentation has shown great potential in handling low-light conditions where RGB-based segmentation is hindered by poor RGB imaging quality. The key to RGB-T semantic segmentation is to effectively leverage the complementarity nature of RGB and thermal images. Most existing algorithms fuse RGB and thermal information in feature space via concatenation, element-wise summation, or attention operations in either unidirectional enhancement or bidirectional aggregation manners. However, they usually overlook the modality gap between RGB and thermal images during feature fusion, resulting in modality-specific information from one modality contaminating the other. In this paper, we propose a Channel and Spatial Relation-Propagation Network (CSRPNet) for RGB-T semantic segmentation, which propagates only modality-shared information across different modalities and alleviates the modality-specific information contamination issue. Our CSRPNet first performs relation-propagation in channel and spatial dimensions to capture the modality-shared features from the RGB and thermal features. CSRPNet then aggregates the modality-shared features captured from one modality with the input feature from the other modality to enhance the input feature without the contamination issue. While being fused together, the enhanced RGB and thermal features will be also fed into the subsequent RGB or thermal feature extraction layers for interactive feature fusion, respectively. We also introduce a dual-path cascaded feature refinement module that aggregates multi-layer features to produce two refined features for semantic and boundary prediction. Extensive experimental results demonstrate that CSRPNet performs favorably against state-of-the-art algorithms.
PMVC: Data Augmentation-Based Prosody Modeling for Expressive Voice Conversion
Aug 21, 2023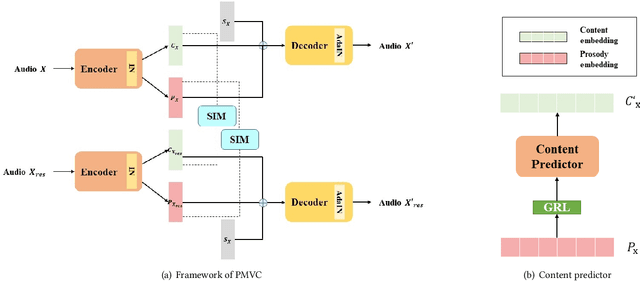

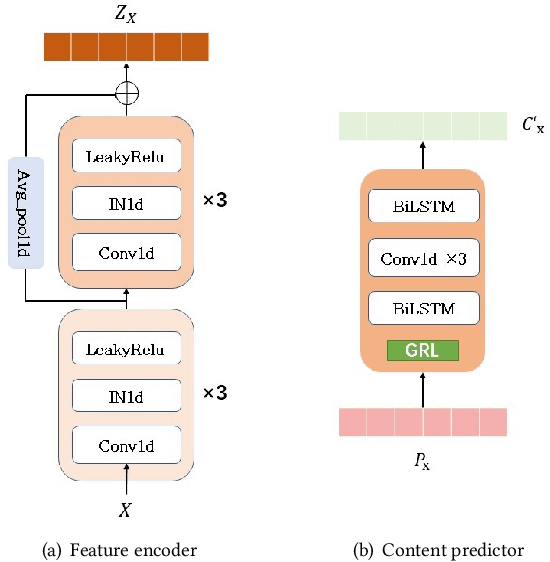
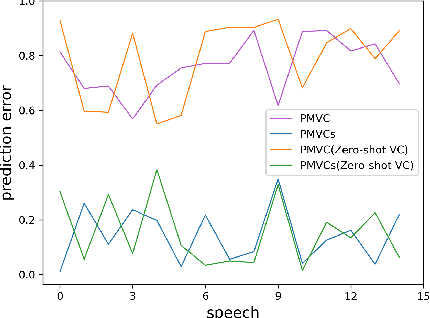
Voice conversion as the style transfer task applied to speech, refers to converting one person's speech into a new speech that sounds like another person's. Up to now, there has been a lot of research devoted to better implementation of VC tasks. However, a good voice conversion model should not only match the timbre information of the target speaker, but also expressive information such as prosody, pace, pause, etc. In this context, prosody modeling is crucial for achieving expressive voice conversion that sounds natural and convincing. Unfortunately, prosody modeling is important but challenging, especially without text transcriptions. In this paper, we firstly propose a novel voice conversion framework named 'PMVC', which effectively separates and models the content, timbre, and prosodic information from the speech without text transcriptions. Specially, we introduce a new speech augmentation algorithm for robust prosody extraction. And building upon this, mask and predict mechanism is applied in the disentanglement of prosody and content information. The experimental results on the AIShell-3 corpus supports our improvement of naturalness and similarity of converted speech.
Probabilistic solar flare forecasting using historical magnetogram data
Aug 29, 2023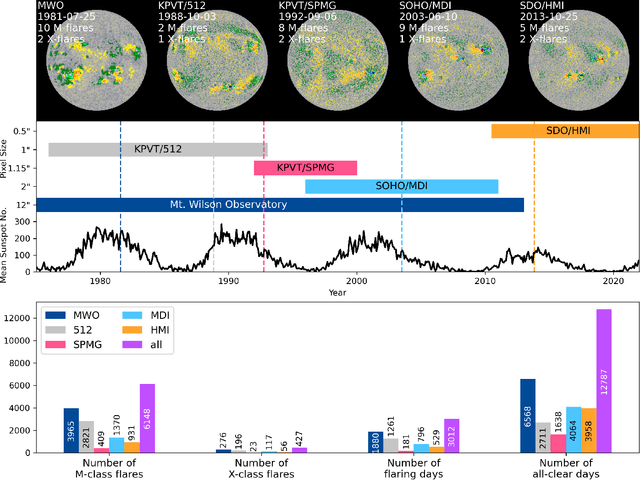

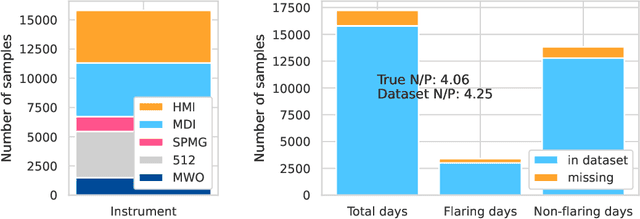

Solar flare forecasting research using machine learning (ML) has focused on high resolution magnetogram data from the SDO/HMI era covering Solar Cycle 24 and the start of Solar Cycle 25, with some efforts looking back to SOHO/MDI for data from Solar Cycle 23. In this paper, we consider over 4 solar cycles of daily historical magnetogram data from multiple instruments. This is the first attempt to take advantage of this historical data for ML-based flare forecasting. We apply a convolutional neural network (CNN) to extract features from full-disk magnetograms together with a logistic regression model to incorporate scalar features based on magnetograms and flaring history. We use an ensemble approach to generate calibrated probabilistic forecasts of M-class or larger flares in the next 24 hours. Overall, we find that including historical data improves forecasting skill and reliability. We show that single frame magnetograms do not contain significantly more relevant information than can be summarized in a small number of scalar features, and that flaring history has greater predictive power than our CNN-extracted features. This indicates the importance of including temporal information in flare forecasting models.
Enhancing Robot Learning through Learned Human-Attention Feature Maps
Aug 29, 2023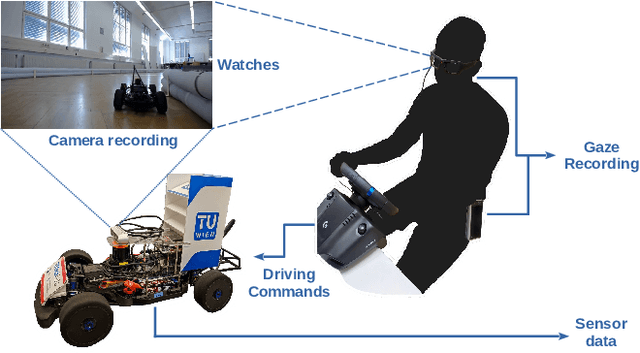
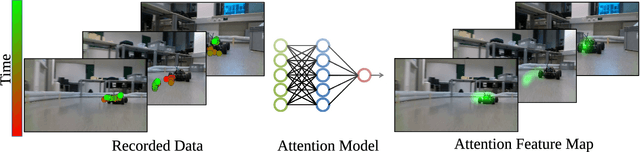
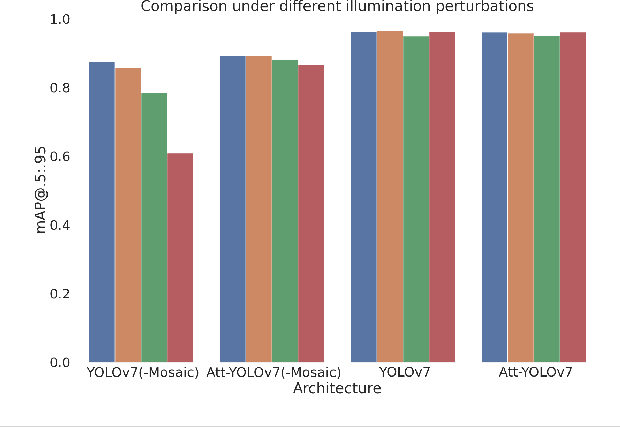
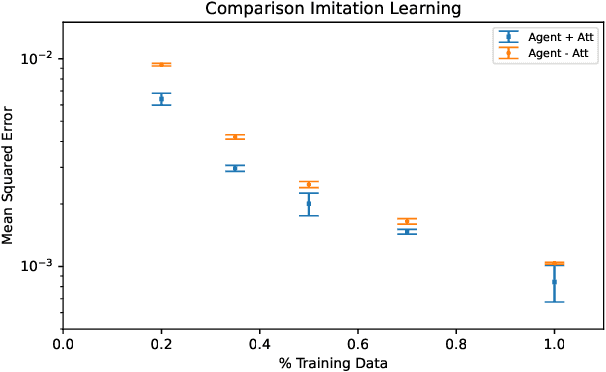
Robust and efficient learning remains a challenging problem in robotics, in particular with complex visual inputs. Inspired by human attention mechanism, with which we quickly process complex visual scenes and react to changes in the environment, we think that embedding auxiliary information about focus point into robot learning would enhance efficiency and robustness of the learning process. In this paper, we propose a novel approach to model and emulate the human attention with an approximate prediction model. We then leverage this output and feed it as a structured auxiliary feature map into downstream learning tasks. We validate this idea by learning a prediction model from human-gaze recordings of manual driving in the real world. We test our approach on two learning tasks - object detection and imitation learning. Our experiments demonstrate that the inclusion of predicted human attention leads to improved robustness of the trained models to out-of-distribution samples and faster learning in low-data regime settings. Our work highlights the potential of incorporating structured auxiliary information in representation learning for robotics and opens up new avenues for research in this direction. All code and data are available online.
Benchmarking the Generation of Fact Checking Explanations
Aug 29, 2023Fighting misinformation is a challenging, yet crucial, task. Despite the growing number of experts being involved in manual fact-checking, this activity is time-consuming and cannot keep up with the ever-increasing amount of Fake News produced daily. Hence, automating this process is necessary to help curb misinformation. Thus far, researchers have mainly focused on claim veracity classification. In this paper, instead, we address the generation of justifications (textual explanation of why a claim is classified as either true or false) and benchmark it with novel datasets and advanced baselines. In particular, we focus on summarization approaches over unstructured knowledge (i.e. news articles) and we experiment with several extractive and abstractive strategies. We employed two datasets with different styles and structures, in order to assess the generalizability of our findings. Results show that in justification production summarization benefits from the claim information, and, in particular, that a claim-driven extractive step improves abstractive summarization performances. Finally, we show that although cross-dataset experiments suffer from performance degradation, a unique model trained on a combination of the two datasets is able to retain style information in an efficient manner.
Learning Bottleneck Transformer for Event Image-Voxel Feature Fusion based Classification
Aug 23, 2023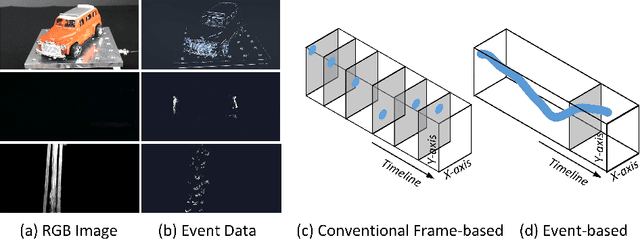

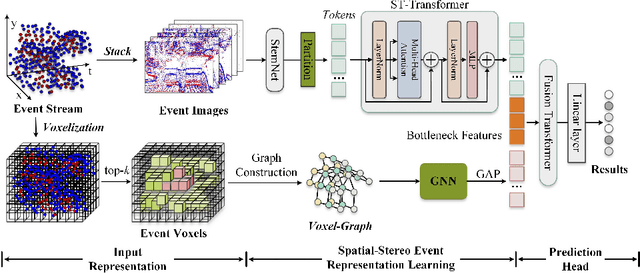

Recognizing target objects using an event-based camera draws more and more attention in recent years. Existing works usually represent the event streams into point-cloud, voxel, image, etc, and learn the feature representations using various deep neural networks. Their final results may be limited by the following factors: monotonous modal expressions and the design of the network structure. To address the aforementioned challenges, this paper proposes a novel dual-stream framework for event representation, extraction, and fusion. This framework simultaneously models two common representations: event images and event voxels. By utilizing Transformer and Structured Graph Neural Network (GNN) architectures, spatial information and three-dimensional stereo information can be learned separately. Additionally, a bottleneck Transformer is introduced to facilitate the fusion of the dual-stream information. Extensive experiments demonstrate that our proposed framework achieves state-of-the-art performance on two widely used event-based classification datasets. The source code of this work is available at: \url{https://github.com/Event-AHU/EFV_event_classification}
Timely Fusion of Surround Radar/Lidar for Object Detection in Autonomous Driving Systems
Sep 09, 2023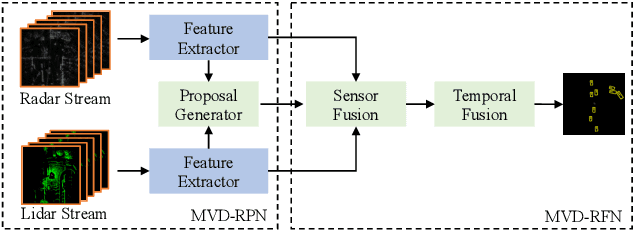
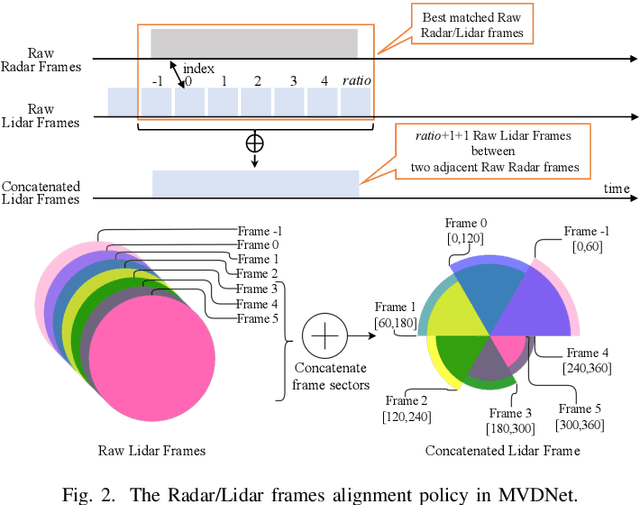
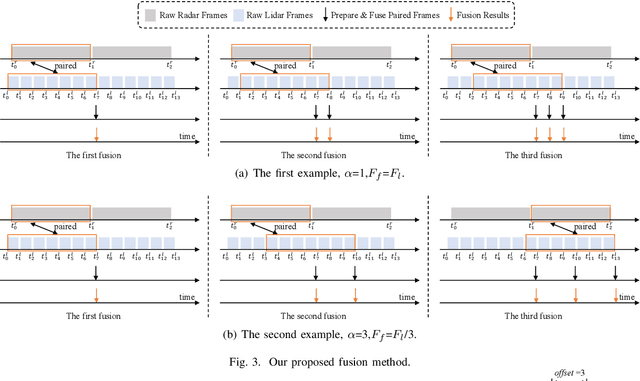
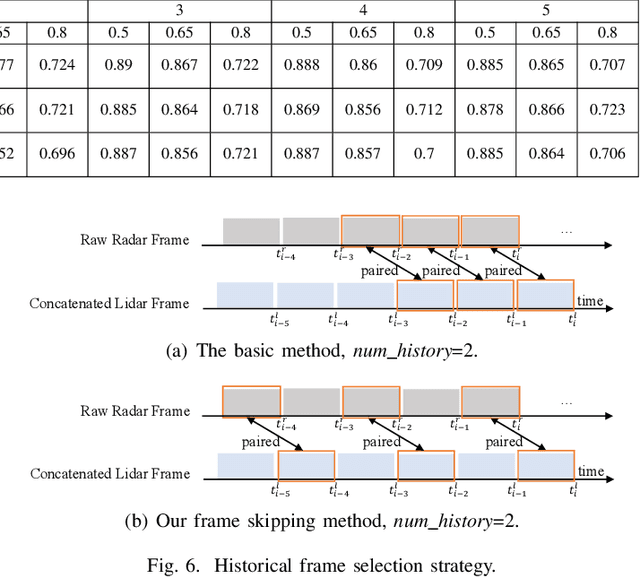
Fusing Radar and Lidar sensor data can fully utilize their complementary advantages and provide more accurate reconstruction of the surrounding for autonomous driving systems. Surround Radar/Lidar can provide 360-degree view sampling with the minimal cost, which are promising sensing hardware solutions for autonomous driving systems. However, due to the intrinsic physical constraints, the rotating speed of surround Radar, and thus the frequency to generate Radar data frames, is much lower than surround Lidar. Existing Radar/Lidar fusion methods have to work at the low frequency of surround Radar, which cannot meet the high responsiveness requirement of autonomous driving systems.This paper develops techniques to fuse surround Radar/Lidar with working frequency only limited by the faster surround Lidar instead of the slower surround Radar, based on the state-of-the-art object detection model MVDNet. The basic idea of our approach is simple: we let MVDNet work with temporally unaligned data from Radar/Lidar, so that fusion can take place at any time when a new Lidar data frame arrives, instead of waiting for the slow Radar data frame. However, directly applying MVDNet to temporally unaligned Radar/Lidar data greatly degrades its object detection accuracy. The key information revealed in this paper is that we can achieve high output frequency with little accuracy loss by enhancing the training procedure to explore the temporal redundancy in MVDNet so that it can tolerate the temporal unalignment of input data. We explore several different ways of training enhancement and compare them quantitatively with experiments.
A Spatiotemporal Deep Neural Network for Fine-Grained Multi-Horizon Wind Prediction
Sep 09, 2023The prediction of wind in terms of both wind speed and direction, which has a crucial impact on many real-world applications like aviation and wind power generation, is extremely challenging due to the high stochasticity and complicated correlation in the weather data. Existing methods typically focus on a sub-set of influential factors and thus lack a systematic treatment of the problem. In addition, fine-grained forecasting is essential for efficient industry operations, but has been less attended in the literature. In this work, we propose a novel data-driven model, Multi-Horizon SpatioTemporal Network (MHSTN), generally for accurate and efficient fine-grained wind prediction. MHSTN integrates multiple deep neural networks targeting different factors in a sequence-to-sequence (Seq2Seq) backbone to effectively extract features from various data sources and produce multi-horizon predictions for all sites within a given region. MHSTN is composed of four major modules. First, a temporal module fuses coarse-grained forecasts derived by Numerical Weather Prediction (NWP) and historical on-site observation data at stations so as to leverage both global and local atmospheric information. Second, a spatial module exploits spatial correlation by modeling the joint representation of all stations. Third, an ensemble module weighs the above two modules for final predictions. Furthermore, a covariate selection module automatically choose influential meteorological variables as initial input. MHSTN is already integrated into the scheduling platform of one of the busiest international airports of China. The evaluation results demonstrate that our model outperforms competitors by a significant margin.