 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Spatial-temporal Vehicle Re-identification
Sep 03, 2023

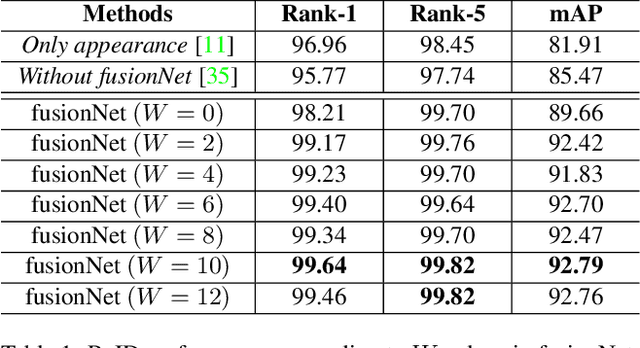
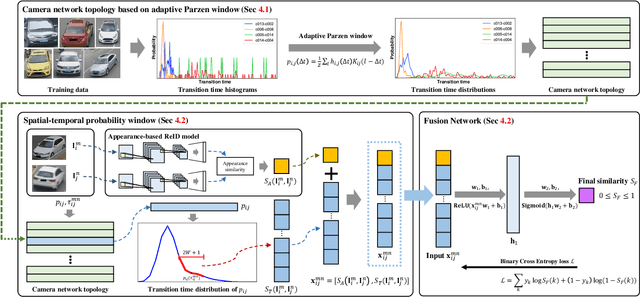
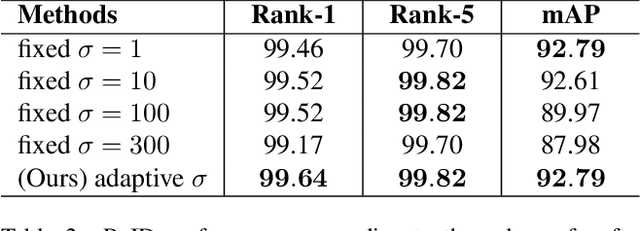
Vehicle re-identification (ReID) in a large-scale camera network is important in public safety, traffic control, and security. However, due to the appearance ambiguities of vehicle, the previous appearance-based ReID methods often fail to track vehicle across multiple cameras. To overcome the challenge, we propose a spatial-temporal vehicle ReID framework that estimates reliable camera network topology based on the adaptive Parzen window method and optimally combines the appearance and spatial-temporal similarities through the fusion network. Based on the proposed methods, we performed superior performance on the public dataset (VeRi776) by 99.64% of rank-1 accuracy. The experimental results support that utilizing spatial and temporal information for ReID can leverage the accuracy of appearance-based methods and effectively deal with appearance ambiguities.
Towards Robust Velocity and Position Estimation of Opponents for Autonomous Racing Using Low-Power Radar
Sep 04, 2023This paper presents the design and development of an intelligent subsystem that includes a novel low-power radar sensor integrated into an autonomous racing perception pipeline to robustly estimate the position and velocity of dynamic obstacles. The proposed system, based on the Infineon BGT60TR13D radar, is evaluated in a real-world scenario with scaled race cars. The paper explores the benefits and limitations of using such a sensor subsystem and draws conclusions based on field-collected data. The results demonstrate a tracking error up to 0.21 +- 0.29 m in distance estimation and 0.39 +- 0.19 m/s in velocity estimation, despite the power consumption in the range of 10s of milliwatts. The presented system provides complementary information to other sensors such as LiDAR and camera, and can be used in a wide range of applications beyond autonomous racing.
Video Task Decathlon: Unifying Image and Video Tasks in Autonomous Driving
Sep 08, 2023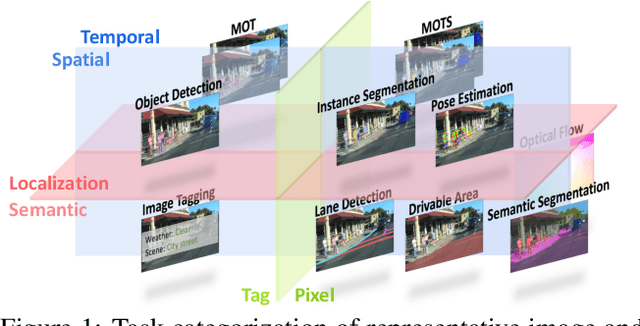

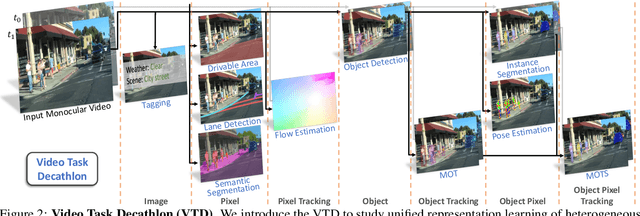
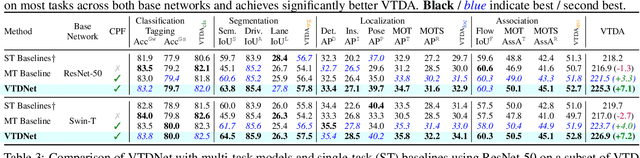
Performing multiple heterogeneous visual tasks in dynamic scenes is a hallmark of human perception capability. Despite remarkable progress in image and video recognition via representation learning, current research still focuses on designing specialized networks for singular, homogeneous, or simple combination of tasks. We instead explore the construction of a unified model for major image and video recognition tasks in autonomous driving with diverse input and output structures. To enable such an investigation, we design a new challenge, Video Task Decathlon (VTD), which includes ten representative image and video tasks spanning classification, segmentation, localization, and association of objects and pixels. On VTD, we develop our unified network, VTDNet, that uses a single structure and a single set of weights for all ten tasks. VTDNet groups similar tasks and employs task interaction stages to exchange information within and between task groups. Given the impracticality of labeling all tasks on all frames, and the performance degradation associated with joint training of many tasks, we design a Curriculum training, Pseudo-labeling, and Fine-tuning (CPF) scheme to successfully train VTDNet on all tasks and mitigate performance loss. Armed with CPF, VTDNet significantly outperforms its single-task counterparts on most tasks with only 20% overall computations. VTD is a promising new direction for exploring the unification of perception tasks in autonomous driving.
DeformToon3D: Deformable 3D Toonification from Neural Radiance Fields
Sep 08, 2023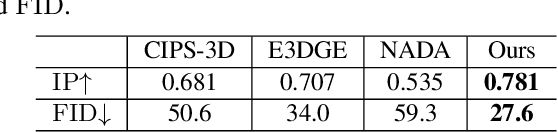
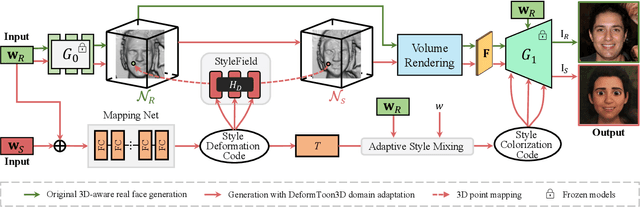

In this paper, we address the challenging problem of 3D toonification, which involves transferring the style of an artistic domain onto a target 3D face with stylized geometry and texture. Although fine-tuning a pre-trained 3D GAN on the artistic domain can produce reasonable performance, this strategy has limitations in the 3D domain. In particular, fine-tuning can deteriorate the original GAN latent space, which affects subsequent semantic editing, and requires independent optimization and storage for each new style, limiting flexibility and efficient deployment. To overcome these challenges, we propose DeformToon3D, an effective toonification framework tailored for hierarchical 3D GAN. Our approach decomposes 3D toonification into subproblems of geometry and texture stylization to better preserve the original latent space. Specifically, we devise a novel StyleField that predicts conditional 3D deformation to align a real-space NeRF to the style space for geometry stylization. Thanks to the StyleField formulation, which already handles geometry stylization well, texture stylization can be achieved conveniently via adaptive style mixing that injects information of the artistic domain into the decoder of the pre-trained 3D GAN. Due to the unique design, our method enables flexible style degree control and shape-texture-specific style swap. Furthermore, we achieve efficient training without any real-world 2D-3D training pairs but proxy samples synthesized from off-the-shelf 2D toonification models.
SayNav: Grounding Large Language Models for Dynamic Planning to Navigation in New Environments
Sep 08, 2023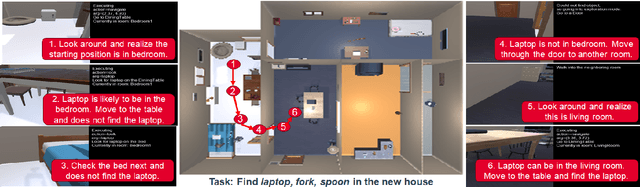
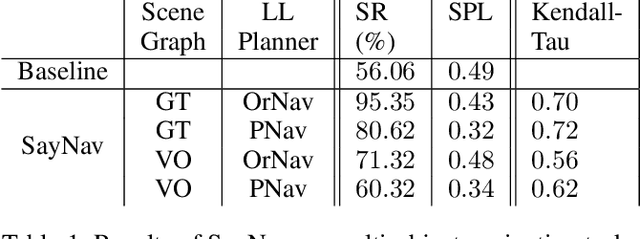
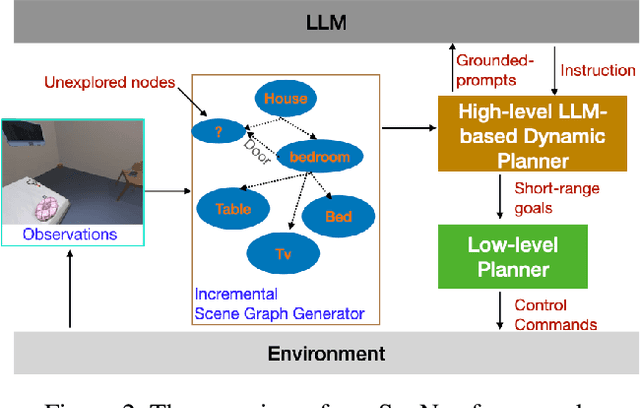
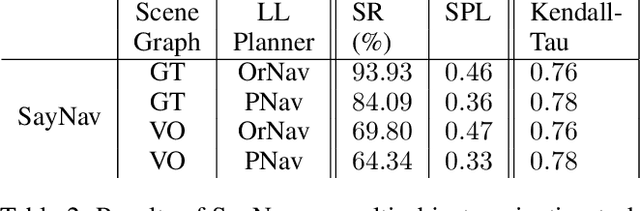
Semantic reasoning and dynamic planning capabilities are crucial for an autonomous agent to perform complex navigation tasks in unknown environments. It requires a large amount of common-sense knowledge, that humans possess, to succeed in these tasks. We present SayNav, a new approach that leverages human knowledge from Large Language Models (LLMs) for efficient generalization to complex navigation tasks in unknown large-scale environments. SayNav uses a novel grounding mechanism, that incrementally builds a 3D scene graph of the explored environment as inputs to LLMs, for generating feasible and contextually appropriate high-level plans for navigation. The LLM-generated plan is then executed by a pre-trained low-level planner, that treats each planned step as a short-distance point-goal navigation sub-task. SayNav dynamically generates step-by-step instructions during navigation and continuously refines future steps based on newly perceived information. We evaluate SayNav on a new multi-object navigation task, that requires the agent to utilize a massive amount of human knowledge to efficiently search multiple different objects in an unknown environment. SayNav outperforms an oracle based Point-nav baseline, achieving a success rate of 95.35% (vs 56.06% for the baseline), under the ideal settings on this task, highlighting its ability to generate dynamic plans for successfully locating objects in large-scale new environments.
Modeling Recommender Ecosystems: Research Challenges at the Intersection of Mechanism Design, Reinforcement Learning and Generative Models
Sep 08, 2023
Modern recommender systems lie at the heart of complex ecosystems that couple the behavior of users, content providers, advertisers, and other actors. Despite this, the focus of the majority of recommender research -- and most practical recommenders of any import -- is on the local, myopic optimization of the recommendations made to individual users. This comes at a significant cost to the long-term utility that recommenders could generate for its users. We argue that explicitly modeling the incentives and behaviors of all actors in the system -- and the interactions among them induced by the recommender's policy -- is strictly necessary if one is to maximize the value the system brings to these actors and improve overall ecosystem "health". Doing so requires: optimization over long horizons using techniques such as reinforcement learning; making inevitable tradeoffs in the utility that can be generated for different actors using the methods of social choice; reducing information asymmetry, while accounting for incentives and strategic behavior, using the tools of mechanism design; better modeling of both user and item-provider behaviors by incorporating notions from behavioral economics and psychology; and exploiting recent advances in generative and foundation models to make these mechanisms interpretable and actionable. We propose a conceptual framework that encompasses these elements, and articulate a number of research challenges that emerge at the intersection of these different disciplines.
Collaborative Route Planning of UAVs, Workers and Cars for Crowdsensing in Disaster Response
Aug 21, 2023Efficiently obtaining the up-to-date information in the disaster-stricken area is the key to successful disaster response. Unmanned aerial vehicles (UAVs), workers and cars can collaborate to accomplish sensing tasks, such as data collection, in disaster-stricken areas. In this paper, we explicitly address the route planning for a group of agents, including UAVs, workers, and cars, with the goal of maximizing the task completion rate. We propose MANF-RL-RP, a heterogeneous multi-agent route planning algorithm that incorporates several efficient designs, including global-local dual information processing and a tailored model structure for heterogeneous multi-agent systems. Global-local dual information processing encompasses the extraction and dissemination of spatial features from global information, as well as the partitioning and filtering of local information from individual agents. Regarding the construction of the model structure for heterogeneous multi-agent, we perform the following work. We design the same data structure to represent the states of different agents, prove the Markovian property of the decision-making process of agents to simplify the model structure, and also design a reasonable reward function to train the model. Finally, we conducted detailed experiments based on the rich simulation data. In comparison to the baseline algorithms, namely Greedy-SC-RP and MANF-DNN-RP, MANF-RL-RP has exhibited a significant improvement in terms of task completion rate.
Utilizing Task-Generic Motion Prior to Recover Full-Body Motion from Very Sparse Signals
Aug 30, 2023The most popular type of devices used to track a user's posture in a virtual reality experience consists of a head-mounted display and two controllers held in both hands. However, due to the limited number of tracking sensors (three in total), faithfully recovering the user in full-body is challenging, limiting the potential for interactions among simulated user avatars within the virtual world. Therefore, recent studies have attempted to reconstruct full-body poses using neural networks that utilize previously learned human poses or accept a series of past poses over a short period. In this paper, we propose a method that utilizes information from a neural motion prior to improve the accuracy of reconstructed user's motions. Our approach aims to reconstruct user's full-body poses by predicting the latent representation of the user's overall motion from limited input signals and integrating this information with tracking sensor inputs. This is based on the premise that the ultimate goal of pose reconstruction is to reconstruct the motion, which is a series of poses. Our results show that this integration enables more accurate reconstruction of the user's full-body motion, particularly enhancing the robustness of lower body motion reconstruction from impoverished signals. Web: https://https://mjsh34.github.io/mp-sspe/
Explainable Active Learning for Preference Elicitation
Sep 01, 2023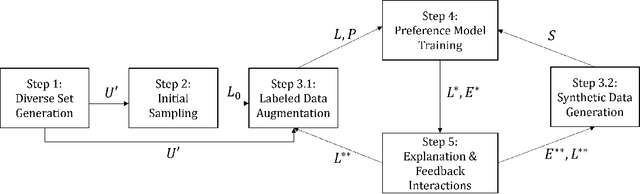
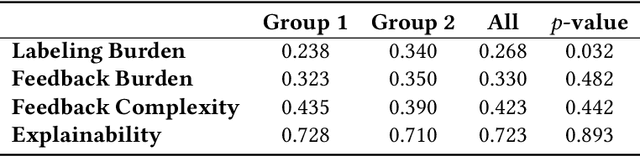

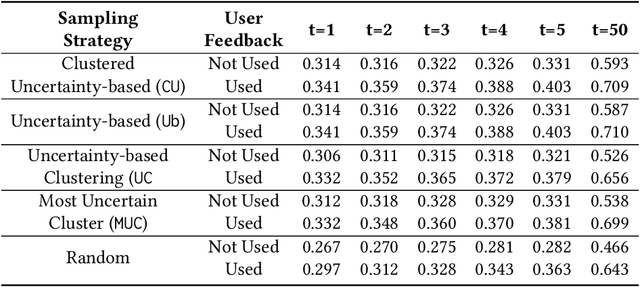
Gaining insights into the preferences of new users and subsequently personalizing recommendations necessitate managing user interactions intelligently, namely, posing pertinent questions to elicit valuable information effectively. In this study, our focus is on a specific scenario of the cold-start problem, where the recommendation system lacks adequate user presence or access to other users' data is restricted, obstructing employing user profiling methods utilizing existing data in the system. We employ Active Learning (AL) to solve the addressed problem with the objective of maximizing information acquisition with minimal user effort. AL operates for selecting informative data from a large unlabeled set to inquire an oracle to label them and eventually updating a machine learning (ML) model. We operate AL in an integrated process of unsupervised, semi-supervised, and supervised ML within an explanatory preference elicitation process. It harvests user feedback (given for the system's explanations on the presented items) over informative samples to update an underlying ML model estimating user preferences. The designed user interaction facilitates personalizing the system by incorporating user feedback into the ML model and also enhances user trust by refining the system's explanations on recommendations. We implement the proposed preference elicitation methodology for food recommendation. We conducted human experiments to assess its efficacy in the short term and also experimented with several AL strategies over synthetic user profiles that we created for two food datasets, aiming for long-term performance analysis. The experimental results demonstrate the efficiency of the proposed preference elicitation with limited user-labeled data while also enhancing user trust through accurate explanations.
Shared Control Based on Extended Lipschitz Analysis With Application to Human-Superlimb Collaboration
Sep 01, 2023This paper presents a quantitative method to construct voluntary manual control and sensor-based reactive control in human-robot collaboration based on Lipschitz conditions. To collaborate with a human, the robot observes the human's motions and predicts a desired action. This predictor is constructed from data of human demonstrations observed through the robot's sensors. Analysis of demonstration data based on Lipschitz quotients evaluates a) whether the desired action is predictable and b) to what extent the action is predictable. If the quotients are low for all the input-output pairs of demonstration data, a predictor can be constructed with a smooth function. In dealing with human demonstration data, however, the Lipschitz quotients tend to be very high in some situations due to the discrepancy between the information that humans use and the one robots can obtain. This paper a) presents a method for seeking missing information or a new variable that can lower the Lipschitz quotients by adding the new variable to the input space, and b) constructs a human-robot shared control system based on the Lipschitz analysis. Those predictable situations are assigned to the robot's reactive control, while human voluntary control is assigned to those situations where the Lipschitz quotients are high even after the new variable is added. The latter situations are deemed unpredictable and are rendered to the human. This human-robot shared control method is applied to assist hemiplegic patients in a bimanual eating task with a Supernumerary Robotic Limb, which works in concert with an unaffected functional hand.