 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Amyloid-Beta Axial Plane PET Synthesis from Structural MRI: An Image Translation Approach for Screening Alzheimer's Disease
Sep 01, 2023
In this work, an image translation model is implemented to produce synthetic amyloid-beta PET images from structural MRI that are quantitatively accurate. Image pairs of amyloid-beta PET and structural MRI were used to train the model. We found that the synthetic PET images could be produced with a high degree of similarity to truth in terms of shape, contrast and overall high SSIM and PSNR. This work demonstrates that performing structural to quantitative image translation is feasible to enable the access amyloid-beta information from only MRI.
Random Projections of Sparse Adjacency Matrices
Sep 04, 2023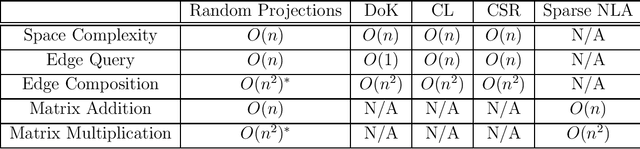
We analyze a random projection method for adjacency matrices, studying its utility in representing sparse graphs. We show that these random projections retain the functionality of their underlying adjacency matrices while having extra properties that make them attractive as dynamic graph representations. In particular, they can represent graphs of different sizes and vertex sets in the same space, allowing for the aggregation and manipulation of graphs in a unified manner. We also provide results on how the size of the projections need to scale in order to preserve accurate graph operations, showing that the size of the projections can scale linearly with the number of vertices while accurately retaining first-order graph information. We conclude by characterizing our random projection as a distance-preserving map of adjacency matrices analogous to the usual Johnson-Lindenstrauss map.
Cross-Utterance Conditioned VAE for Speech Generation
Sep 08, 2023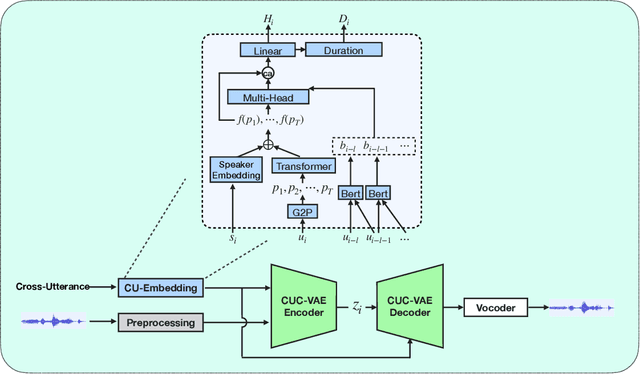
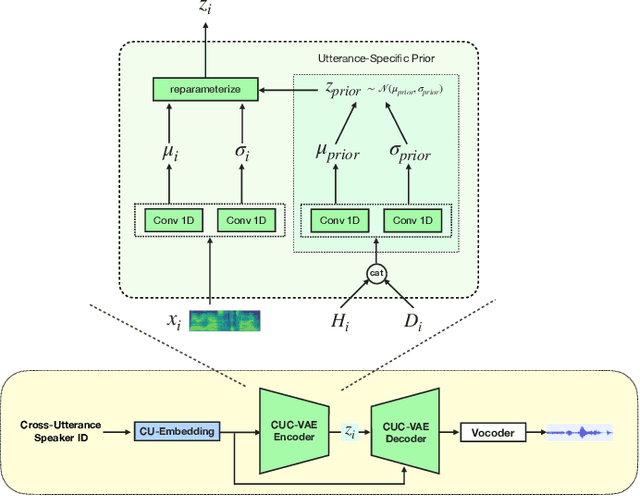
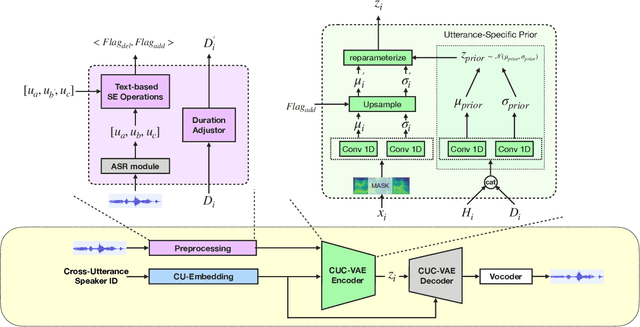

Speech synthesis systems powered by neural networks hold promise for multimedia production, but frequently face issues with producing expressive speech and seamless editing. In response, we present the Cross-Utterance Conditioned Variational Autoencoder speech synthesis (CUC-VAE S2) framework to enhance prosody and ensure natural speech generation. This framework leverages the powerful representational capabilities of pre-trained language models and the re-expression abilities of variational autoencoders (VAEs). The core component of the CUC-VAE S2 framework is the cross-utterance CVAE, which extracts acoustic, speaker, and textual features from surrounding sentences to generate context-sensitive prosodic features, more accurately emulating human prosody generation. We further propose two practical algorithms tailored for distinct speech synthesis applications: CUC-VAE TTS for text-to-speech and CUC-VAE SE for speech editing. The CUC-VAE TTS is a direct application of the framework, designed to generate audio with contextual prosody derived from surrounding texts. On the other hand, the CUC-VAE SE algorithm leverages real mel spectrogram sampling conditioned on contextual information, producing audio that closely mirrors real sound and thereby facilitating flexible speech editing based on text such as deletion, insertion, and replacement. Experimental results on the LibriTTS datasets demonstrate that our proposed models significantly enhance speech synthesis and editing, producing more natural and expressive speech.
Double RIS-Assisted MIMO Systems Over Spatially Correlated Rician Fading Channels and Finite Scatterers
Sep 08, 2023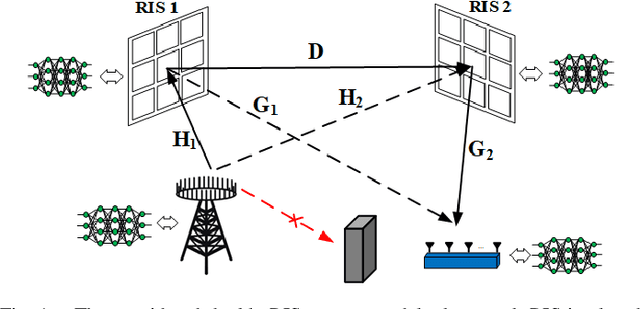
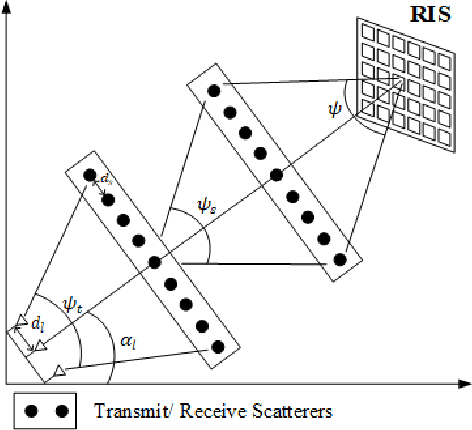
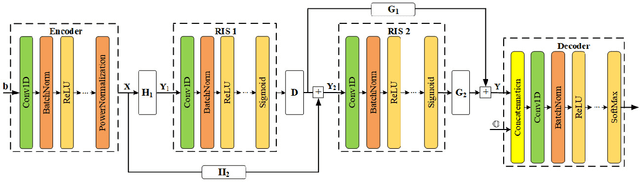
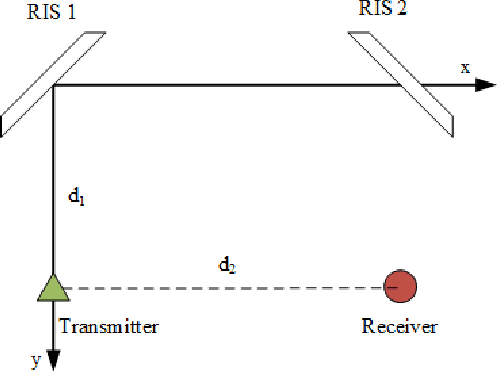
This paper investigates double RIS-assisted MIMO communication systems over Rician fading channels with finite scatterers, spatial correlation, and the existence of a double-scattering link between the transceiver. First, the statistical information is driven in closed form for the aggregated channels, unveiling various influences of the system and environment on the average channel power gains. Next, we study two active and passive beamforming designs corresponding to two objectives. The first problem maximizes channel capacity by jointly optimizing the active precoding and combining matrices at the transceivers and passive beamforming at the double RISs subject to the transmitting power constraint. In order to tackle the inherently non-convex issue, we propose an efficient alternating optimization algorithm (AO) based on the alternating direction method of multipliers (ADMM). The second problem enhances communication reliability by jointly training the encoder and decoder at the transceivers and the phase shifters at the RISs. Each neural network representing a system entity in an end-to-end learning framework is proposed to minimize the symbol error rate of the detected symbols by controlling the transceiver and the RISs phase shifts. Numerical results verify our analysis and demonstrate the superior improvements of phase shift designs to boost system performance.
Counterfactual Explanations via Locally-guided Sequential Algorithmic Recourse
Sep 08, 2023


Counterfactuals operationalised through algorithmic recourse have become a powerful tool to make artificial intelligence systems explainable. Conceptually, given an individual classified as y -- the factual -- we seek actions such that their prediction becomes the desired class y' -- the counterfactual. This process offers algorithmic recourse that is (1) easy to customise and interpret, and (2) directly aligned with the goals of each individual. However, the properties of a "good" counterfactual are still largely debated; it remains an open challenge to effectively locate a counterfactual along with its corresponding recourse. Some strategies use gradient-driven methods, but these offer no guarantees on the feasibility of the recourse and are open to adversarial attacks on carefully created manifolds. This can lead to unfairness and lack of robustness. Other methods are data-driven, which mostly addresses the feasibility problem at the expense of privacy, security and secrecy as they require access to the entire training data set. Here, we introduce LocalFACE, a model-agnostic technique that composes feasible and actionable counterfactual explanations using locally-acquired information at each step of the algorithmic recourse. Our explainer preserves the privacy of users by only leveraging data that it specifically requires to construct actionable algorithmic recourse, and protects the model by offering transparency solely in the regions deemed necessary for the intervention.
Adaptive Distributed Kernel Ridge Regression: A Feasible Distributed Learning Scheme for Data Silos
Sep 08, 2023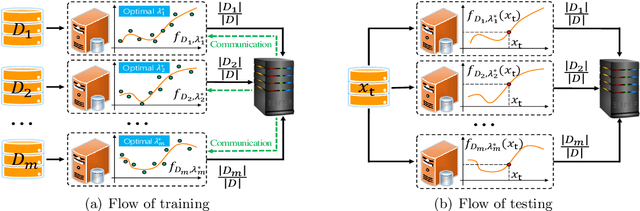

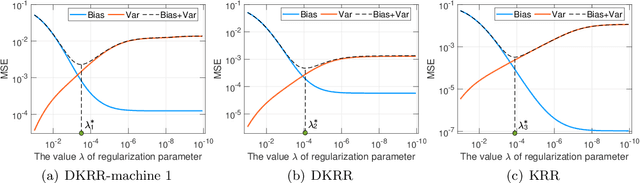
Data silos, mainly caused by privacy and interoperability, significantly constrain collaborations among different organizations with similar data for the same purpose. Distributed learning based on divide-and-conquer provides a promising way to settle the data silos, but it suffers from several challenges, including autonomy, privacy guarantees, and the necessity of collaborations. This paper focuses on developing an adaptive distributed kernel ridge regression (AdaDKRR) by taking autonomy in parameter selection, privacy in communicating non-sensitive information, and the necessity of collaborations in performance improvement into account. We provide both solid theoretical verification and comprehensive experiments for AdaDKRR to demonstrate its feasibility and effectiveness. Theoretically, we prove that under some mild conditions, AdaDKRR performs similarly to running the optimal learning algorithms on the whole data, verifying the necessity of collaborations and showing that no other distributed learning scheme can essentially beat AdaDKRR under the same conditions. Numerically, we test AdaDKRR on both toy simulations and two real-world applications to show that AdaDKRR is superior to other existing distributed learning schemes. All these results show that AdaDKRR is a feasible scheme to defend against data silos, which are highly desired in numerous application regions such as intelligent decision-making, pricing forecasting, and performance prediction for products.
Spatial Modulation with Energy Detection: Diversity Analysis and Experimental Evaluation
Sep 08, 2023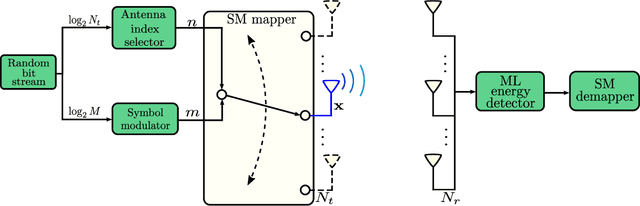

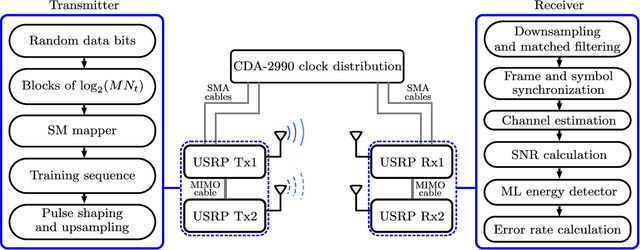
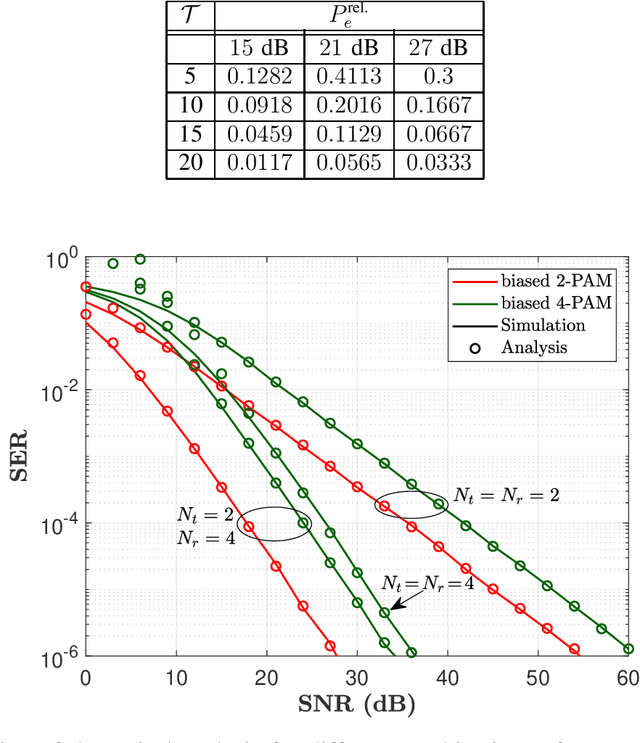
In this paper, we present a non-coherent energy detection scheme for spatial modulation (SM) systems. In particular, the use of SM is motivated by its low-complexity implementation in comparison to multiple-input multiple-output (MIMO) systems, achieved through the activation of a single antenna during transmission. Moreover, energy detection-based communications restrict the channel state information to the magnitude of the fading gains. This consideration makes the design applicable for low-cost low-powered devices since phase estimation and its associated circuitry are avoided. We derive an energy detection metric for a multi-antenna receiver based on the maximum-likelihood (ML) criterion. By considering a biased pulse amplitude modulation, we develop an analytical framework for the SM symbol error rate at high signal-to-noise ratios. Numerical results show that the diversity order is proportional to half the number of receive antennas; this result stems from having partial receiver channel knowledge. In addition, we compare the performance of the proposed scheme with that of the coherent ML receiver and show that the SM energy detector outperforms its coherent counterpart in certain scenarios, particularly when utilizing non-negative constellations. Ultimately, we implement an SM testbed using software-defined radio devices and provide experimental error rate measurements that validate our theoretical contribution.
Biomedical Entity Linking with Triple-aware Pre-Training
Aug 28, 2023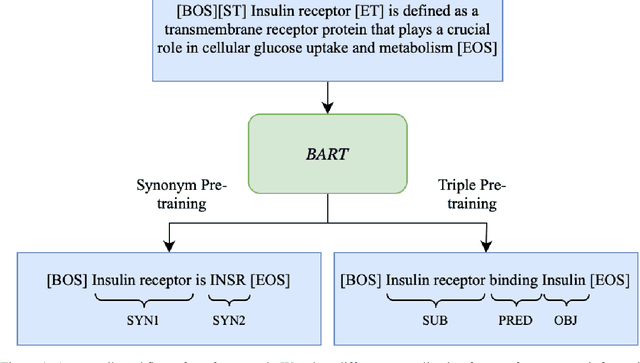
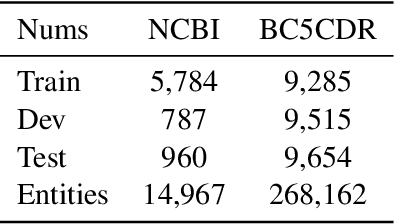
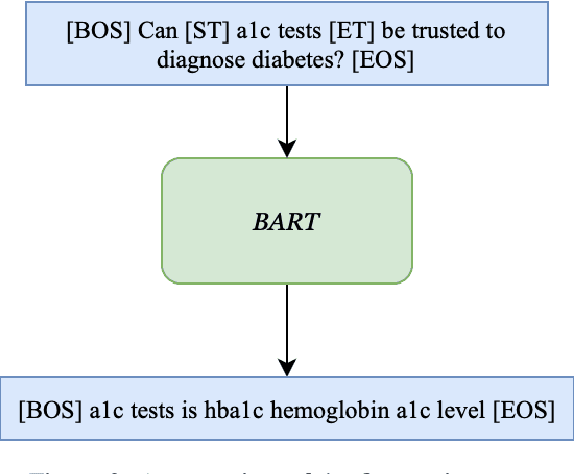
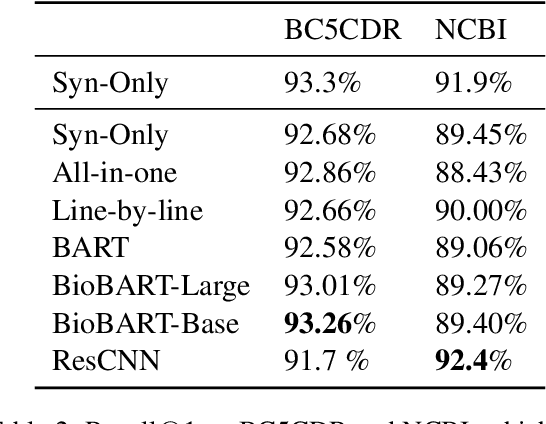
Linking biomedical entities is an essential aspect in biomedical natural language processing tasks, such as text mining and question answering. However, a difficulty of linking the biomedical entities using current large language models (LLM) trained on a general corpus is that biomedical entities are scarcely distributed in texts and therefore have been rarely seen during training by the LLM. At the same time, those LLMs are not aware of high level semantic connection between different biomedical entities, which are useful in identifying similar concepts in different textual contexts. To cope with aforementioned problems, some recent works focused on injecting knowledge graph information into LLMs. However, former methods either ignore the relational knowledge of the entities or lead to catastrophic forgetting. Therefore, we propose a novel framework to pre-train the powerful generative LLM by a corpus synthesized from a KG. In the evaluations we are unable to confirm the benefit of including synonym, description or relational information.
Symbolic Music Representations for Classification Tasks: A Systematic Evaluation
Sep 05, 2023
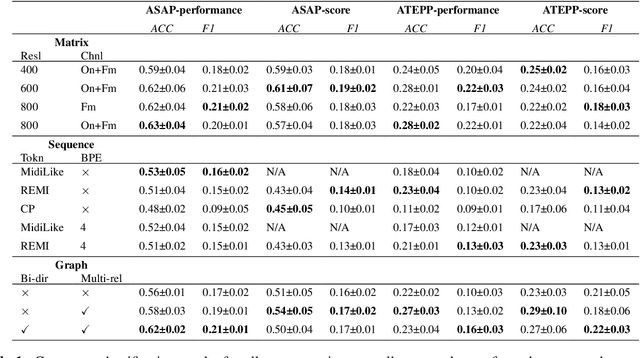
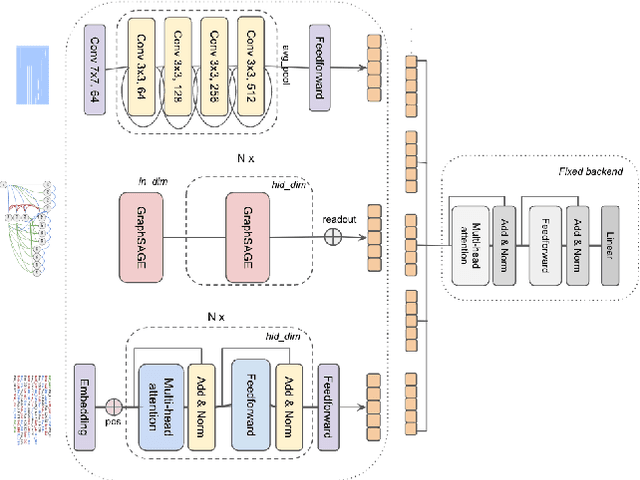
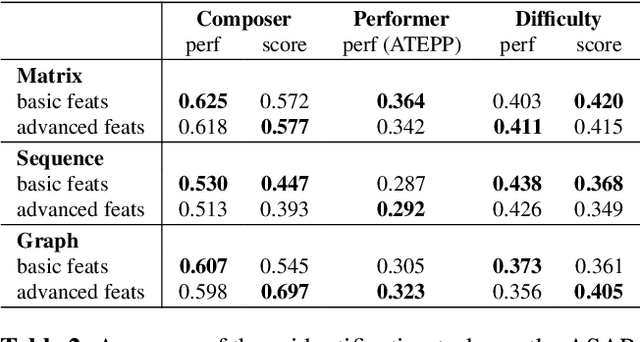
Music Information Retrieval (MIR) has seen a recent surge in deep learning-based approaches, which often involve encoding symbolic music (i.e., music represented in terms of discrete note events) in an image-like or language like fashion. However, symbolic music is neither an image nor a sentence, and research in the symbolic domain lacks a comprehensive overview of the different available representations. In this paper, we investigate matrix (piano roll), sequence, and graph representations and their corresponding neural architectures, in combination with symbolic scores and performances on three piece-level classification tasks. We also introduce a novel graph representation for symbolic performances and explore the capability of graph representations in global classification tasks. Our systematic evaluation shows advantages and limitations of each input representation. Our results suggest that the graph representation, as the newest and least explored among the three approaches, exhibits promising performance, while being more light-weight in training.
Optimal Observation-Intervention Trade-Off in Optimisation Problems with Causal Structure
Sep 05, 2023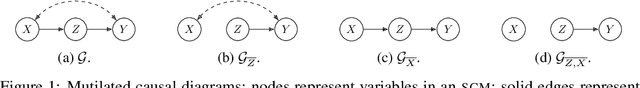


We consider the problem of optimising an expensive-to-evaluate grey-box objective function, within a finite budget, where known side-information exists in the form of the causal structure between the design variables. Standard black-box optimisation ignores the causal structure, often making it inefficient and expensive. The few existing methods that consider the causal structure are myopic and do not fully accommodate the observation-intervention trade-off that emerges when estimating causal effects. In this paper, we show that the observation-intervention trade-off can be formulated as a non-myopic optimal stopping problem which permits an efficient solution. We give theoretical results detailing the structure of the optimal stopping times and demonstrate the generality of our approach by showing that it can be integrated with existing causal Bayesian optimisation algorithms. Experimental results show that our formulation can enhance existing algorithms on real and synthetic benchmarks.