 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MESIA: Understanding and Leveraging Supplementary Nature of Method-level Comments for Automatic Comment Generation
Mar 26, 2024
Code comments are important for developers in program comprehension. In scenarios of comprehending and reusing a method, developers expect code comments to provide supplementary information beyond the method signature. However, the extent of such supplementary information varies a lot in different code comments. In this paper, we raise the awareness of the supplementary nature of method-level comments and propose a new metric named MESIA (Mean Supplementary Information Amount) to assess the extent of supplementary information that a code comment can provide. With the MESIA metric, we conduct experiments on a popular code-comment dataset and three common types of neural approaches to generate method-level comments. Our experimental results demonstrate the value of our proposed work with a number of findings. (1) Small-MESIA comments occupy around 20% of the dataset and mostly fall into only the WHAT comment category. (2) Being able to provide various kinds of essential information, large-MESIA comments in the dataset are difficult for existing neural approaches to generate. (3) We can improve the capability of existing neural approaches to generate large-MESIA comments by reducing the proportion of small-MESIA comments in the training set. (4) The retrained model can generate large-MESIA comments that convey essential meaningful supplementary information for methods in the small-MESIA test set, but will get a lower BLEU score in evaluation. These findings indicate that with good training data, auto-generated comments can sometimes even surpass human-written reference comments, and having no appropriate ground truth for evaluation is an issue that needs to be addressed by future work on automatic comment generation.
On the Monotonicity of Information Aging
Mar 06, 2024In this paper, we analyze the monotonicity of information aging in a remote estimation system, where historical observations of a Gaussian autoregressive AR(p) process are used to predict its future values. We consider two widely used loss functions in estimation: (i) logarithmic loss function for maximum likelihood estimation and (ii) quadratic loss function for MMSE estimation. The estimation error of the AR(p) process is written as a generalized conditional entropy which has closed-form expressions. By using a new information-theoretic tool called $\epsilon$-Markov chain, we can evaluate the divergence of the AR(p) process from being a Markov chain. When the divergence $\epsilon$ is large, the estimation error of the AR(p) process can be far from a non-decreasing function of the Age of Information (AoI). Conversely, for small divergence $\epsilon$, the inference error is close to a non-decreasing AoI function. Each observation is a short sequence taken from the AR(p) process. As the observation sequence length increases, the parameter $\epsilon$ progressively reduces to zero, and hence the estimation error becomes a non-decreasing AoI function. These results underscore a connection between the monotonicity of information aging and the divergence of from being a Markov chain.
Entertainment chatbot for the digital inclusion of elderly people without abstraction capabilities
Mar 29, 2024Current language processing technologies allow the creation of conversational chatbot platforms. Even though artificial intelligence is still too immature to support satisfactory user experience in many mass market domains, conversational interfaces have found their way into ad hoc applications such as call centres and online shopping assistants. However, they have not been applied so far to social inclusion of elderly people, who are particularly vulnerable to the digital divide. Many of them relieve their loneliness with traditional media such as TV and radio, which are known to create a feeling of companionship. In this paper we present the EBER chatbot, designed to reduce the digital gap for the elderly. EBER reads news in the background and adapts its responses to the user's mood. Its novelty lies in the concept of "intelligent radio", according to which, instead of simplifying a digital information system to make it accessible to the elderly, a traditional channel they find familiar -- background news -- is augmented with interactions via voice dialogues. We make it possible by combining Artificial Intelligence Modelling Language, automatic Natural Language Generation and Sentiment Analysis. The system allows accessing digital content of interest by combining words extracted from user answers to chatbot questions with keywords extracted from the news items. This approach permits defining metrics of the abstraction capabilities of the users depending on a spatial representation of the word space. To prove the suitability of the proposed solution we present results of real experiments conducted with elderly people that provided valuable insights. Our approach was considered satisfactory during the tests and improved the information search capabilities of the participants.
ChainNet: Structured Metaphor and Metonymy in WordNet
Mar 29, 2024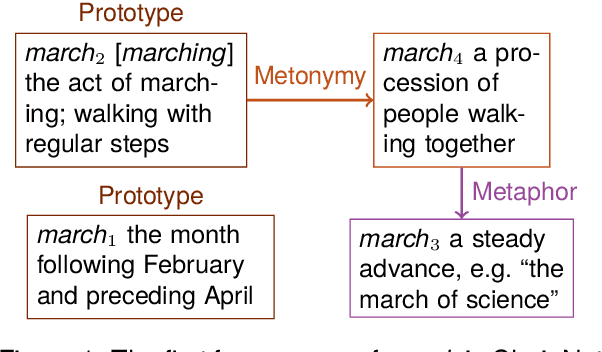
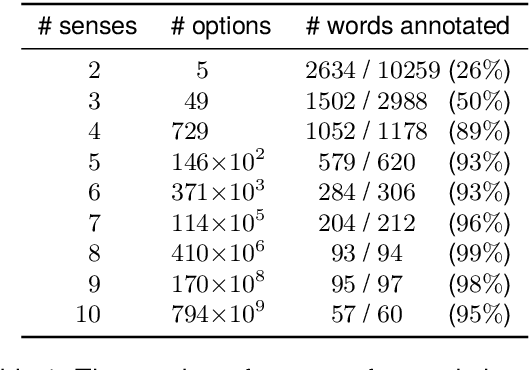

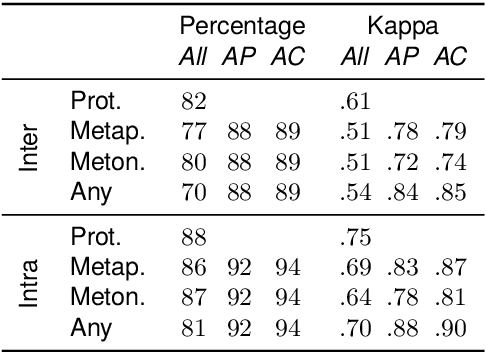
The senses of a word exhibit rich internal structure. In a typical lexicon, this structure is overlooked: a word's senses are encoded as a list without inter-sense relations. We present ChainNet, a lexical resource which for the first time explicitly identifies these structures. ChainNet expresses how senses in the Open English Wordnet are derived from one another: every nominal sense of a word is either connected to another sense by metaphor or metonymy, or is disconnected in the case of homonymy. Because WordNet senses are linked to resources which capture information about their meaning, ChainNet represents the first dataset of grounded metaphor and metonymy.
The Solution for the ICCV 2023 1st Scientific Figure Captioning Challenge
Mar 26, 2024In this paper, we propose a solution for improving the quality of captions generated for figures in papers. We adopt the approach of summarizing the textual content in the paper to generate image captions. Throughout our study, we encounter discrepancies in the OCR information provided in the official dataset. To rectify this, we employ the PaddleOCR toolkit to extract OCR information from all images. Moreover, we observe that certain textual content in the official paper pertains to images that are not relevant for captioning, thereby introducing noise during caption generation. To mitigate this issue, we leverage LLaMA to extract image-specific information by querying the textual content based on image mentions, effectively filtering out extraneous information. Additionally, we recognize a discrepancy between the primary use of maximum likelihood estimation during text generation and the evaluation metrics such as ROUGE employed to assess the quality of generated captions. To bridge this gap, we integrate the BRIO model framework, enabling a more coherent alignment between the generation and evaluation processes. Our approach ranked first in the final test with a score of 4.49.
Instance-Adaptive and Geometric-Aware Keypoint Learning for Category-Level 6D Object Pose Estimation
Mar 28, 2024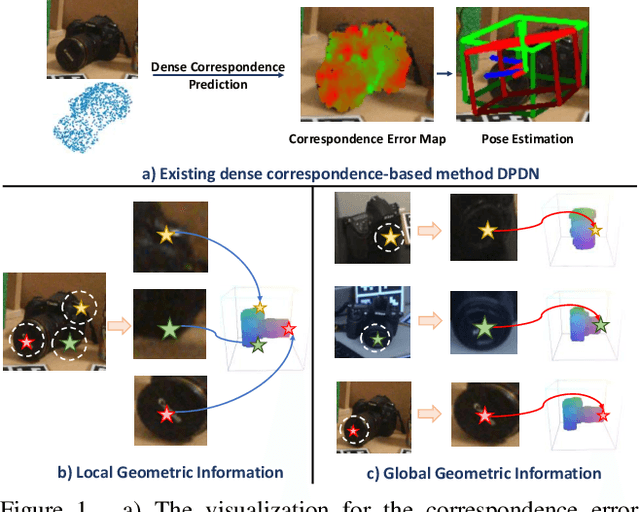
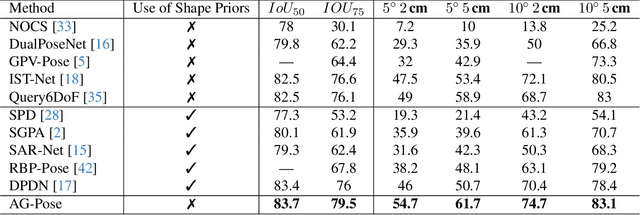
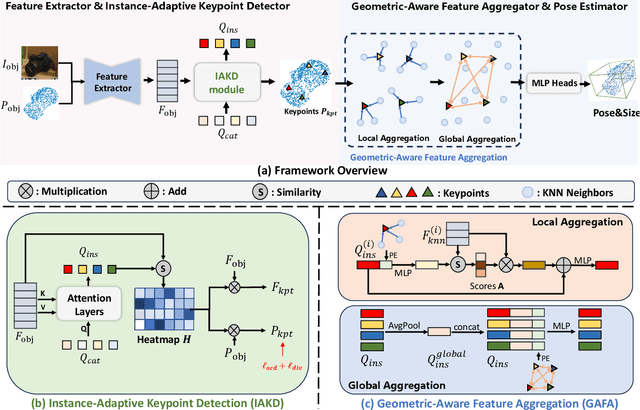
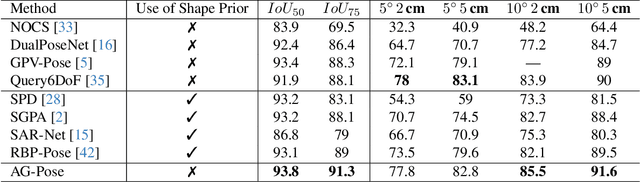
Category-level 6D object pose estimation aims to estimate the rotation, translation and size of unseen instances within specific categories. In this area, dense correspondence-based methods have achieved leading performance. However, they do not explicitly consider the local and global geometric information of different instances, resulting in poor generalization ability to unseen instances with significant shape variations. To deal with this problem, we propose a novel Instance-Adaptive and Geometric-Aware Keypoint Learning method for category-level 6D object pose estimation (AG-Pose), which includes two key designs: (1) The first design is an Instance-Adaptive Keypoint Detection module, which can adaptively detect a set of sparse keypoints for various instances to represent their geometric structures. (2) The second design is a Geometric-Aware Feature Aggregation module, which can efficiently integrate the local and global geometric information into keypoint features. These two modules can work together to establish robust keypoint-level correspondences for unseen instances, thus enhancing the generalization ability of the model.Experimental results on CAMERA25 and REAL275 datasets show that the proposed AG-Pose outperforms state-of-the-art methods by a large margin without category-specific shape priors.
Taming Lookup Tables for Efficient Image Retouching
Mar 28, 2024The widespread use of high-definition screens in edge devices, such as end-user cameras, smartphones, and televisions, is spurring a significant demand for image enhancement. Existing enhancement models often optimize for high performance while falling short of reducing hardware inference time and power consumption, especially on edge devices with constrained computing and storage resources. To this end, we propose Image Color Enhancement Lookup Table (ICELUT) that adopts LUTs for extremely efficient edge inference, without any convolutional neural network (CNN). During training, we leverage pointwise (1x1) convolution to extract color information, alongside a split fully connected layer to incorporate global information. Both components are then seamlessly converted into LUTs for hardware-agnostic deployment. ICELUT achieves near-state-of-the-art performance and remarkably low power consumption. We observe that the pointwise network structure exhibits robust scalability, upkeeping the performance even with a heavily downsampled 32x32 input image. These enable ICELUT, the first-ever purely LUT-based image enhancer, to reach an unprecedented speed of 0.4ms on GPU and 7ms on CPU, at least one order faster than any CNN solution. Codes are available at https://github.com/Stephen0808/ICELUT.
Single-Shared Network with Prior-Inspired Loss for Parameter-Efficient Multi-Modal Imaging Skin Lesion Classification
Mar 28, 2024In this study, we introduce a multi-modal approach that efficiently integrates multi-scale clinical and dermoscopy features within a single network, thereby substantially reducing model parameters. The proposed method includes three novel fusion schemes. Firstly, unlike current methods that usually employ two individual models for for clinical and dermoscopy modalities, we verified that multimodal feature can be learned by sharing the parameters of encoder while leaving the individual modal-specific classifiers. Secondly, the shared cross-attention module can replace the individual one to efficiently interact between two modalities at multiple layers. Thirdly, different from current methods that equally optimize dermoscopy and clinical branches, inspired by prior knowledge that dermoscopy images play a more significant role than clinical images, we propose a novel biased loss. This loss guides the single-shared network to prioritize dermoscopy information over clinical information, implicitly learning a better joint feature representation for the modal-specific task. Extensive experiments on a well-recognized Seven-Point Checklist (SPC) dataset and a collected dataset demonstrate the effectiveness of our method on both CNN and Transformer structures. Furthermore, our method exhibits superiority in both accuracy and model parameters compared to currently advanced methods.
LLMs Are Few-Shot In-Context Low-Resource Language Learners
Mar 27, 2024In-context learning (ICL) empowers large language models (LLMs) to perform diverse tasks in underrepresented languages using only short in-context information, offering a crucial avenue for narrowing the gap between high-resource and low-resource languages. Nonetheless, there is only a handful of works explored ICL for low-resource languages with most of them focusing on relatively high-resource languages, such as French and Spanish. In this work, we extensively study ICL and its cross-lingual variation (X-ICL) on 25 low-resource and 7 relatively higher-resource languages. Our study not only assesses the effectiveness of ICL with LLMs in low-resource languages but also identifies the shortcomings of in-context label alignment, and introduces a more effective alternative: query alignment. Moreover, we provide valuable insights into various facets of ICL for low-resource languages. Our study concludes the significance of few-shot in-context information on enhancing the low-resource understanding quality of LLMs through semantically relevant information by closing the language gap in the target language and aligning the semantics between the targeted low-resource and the high-resource language that the model is proficient in. Our work highlights the importance of advancing ICL research, particularly for low-resource languages.
Common Sense Enhanced Knowledge-based Recommendation with Large Language Model
Mar 27, 2024Knowledge-based recommendation models effectively alleviate the data sparsity issue leveraging the side information in the knowledge graph, and have achieved considerable performance. Nevertheless, the knowledge graphs used in previous work, namely metadata-based knowledge graphs, are usually constructed based on the attributes of items and co-occurring relations (e.g., also buy), in which the former provides limited information and the latter relies on sufficient interaction data and still suffers from cold start issue. Common sense, as a form of knowledge with generality and universality, can be used as a supplement to the metadata-based knowledge graph and provides a new perspective for modeling users' preferences. Recently, benefiting from the emergent world knowledge of the large language model, efficient acquisition of common sense has become possible. In this paper, we propose a novel knowledge-based recommendation framework incorporating common sense, CSRec, which can be flexibly coupled to existing knowledge-based methods. Considering the challenge of the knowledge gap between the common sense-based knowledge graph and metadata-based knowledge graph, we propose a knowledge fusion approach based on mutual information maximization theory. Experimental results on public datasets demonstrate that our approach significantly improves the performance of existing knowledge-based recommendation models.