 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An information-Theoretic Approach to Semi-supervised Transfer Learning
Jun 11, 2023
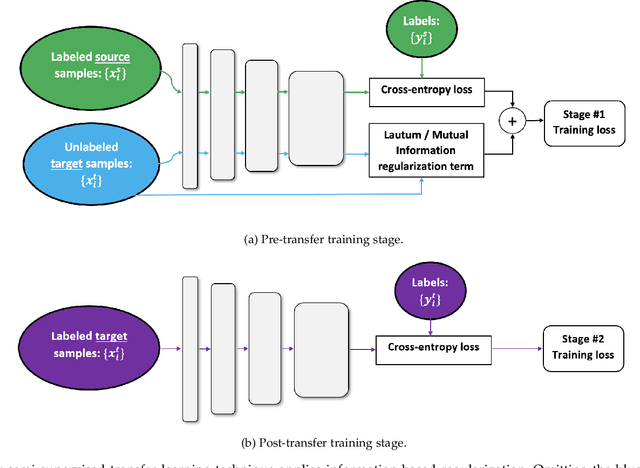
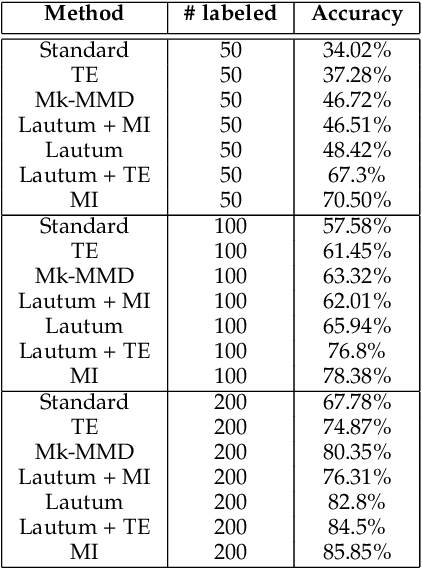
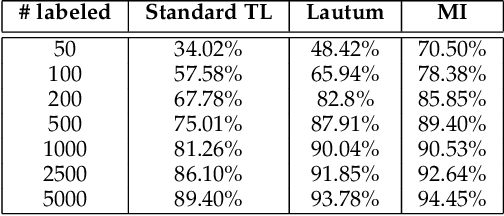
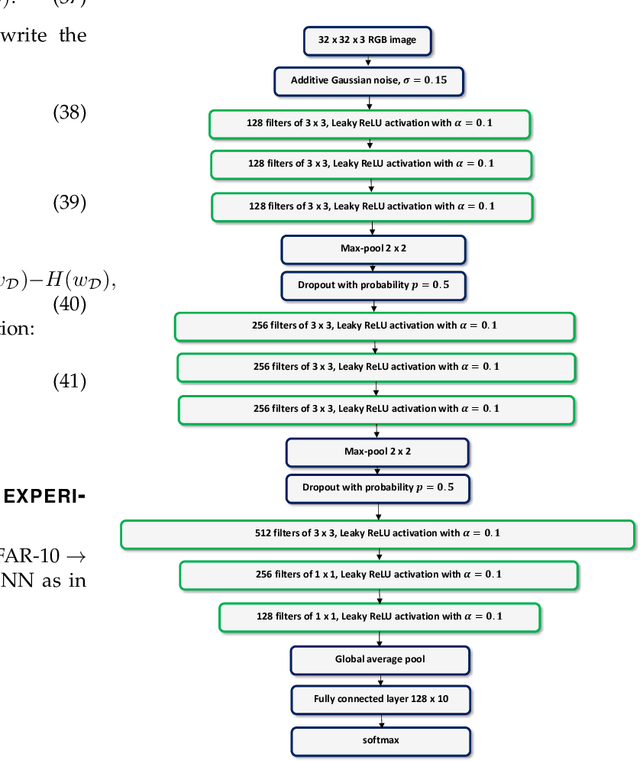
Transfer learning is a valuable tool in deep learning as it allows propagating information from one "source dataset" to another "target dataset", especially in the case of a small number of training examples in the latter. Yet, discrepancies between the underlying distributions of the source and target data are commonplace and are known to have a substantial impact on algorithm performance. In this work we suggest novel information-theoretic approaches for the analysis of the performance of deep neural networks in the context of transfer learning. We focus on the task of semi-supervised transfer learning, in which unlabeled samples from the target dataset are available during network training on the source dataset. Our theory suggests that one may improve the transferability of a deep neural network by incorporating regularization terms on the target data based on information-theoretic quantities, namely the Mutual Information and the Lautum Information. We demonstrate the effectiveness of the proposed approaches in various semi-supervised transfer learning experiments.
Semi-Supervised Semantic Depth Estimation using Symbiotic Transformer and NearFarMix Augmentation
Aug 28, 2023In computer vision, depth estimation is crucial for domains like robotics, autonomous vehicles, augmented reality, and virtual reality. Integrating semantics with depth enhances scene understanding through reciprocal information sharing. However, the scarcity of semantic information in datasets poses challenges. Existing convolutional approaches with limited local receptive fields hinder the full utilization of the symbiotic potential between depth and semantics. This paper introduces a dataset-invariant semi-supervised strategy to address the scarcity of semantic information. It proposes the Depth Semantics Symbiosis module, leveraging the Symbiotic Transformer for achieving comprehensive mutual awareness by information exchange within both local and global contexts. Additionally, a novel augmentation, NearFarMix is introduced to combat overfitting and compensate both depth-semantic tasks by strategically merging regions from two images, generating diverse and structurally consistent samples with enhanced control. Extensive experiments on NYU-Depth-V2 and KITTI datasets demonstrate the superiority of our proposed techniques in indoor and outdoor environments.
Has Sentiment Returned to the Pre-pandemic Level? A Sentiment Analysis Using U.S. College Subreddit Data from 2019 to 2022
Sep 16, 2023
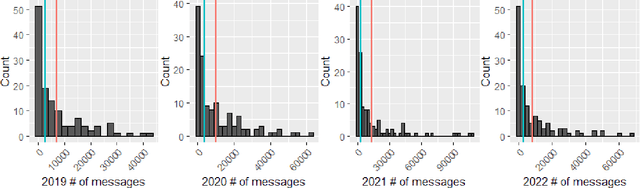
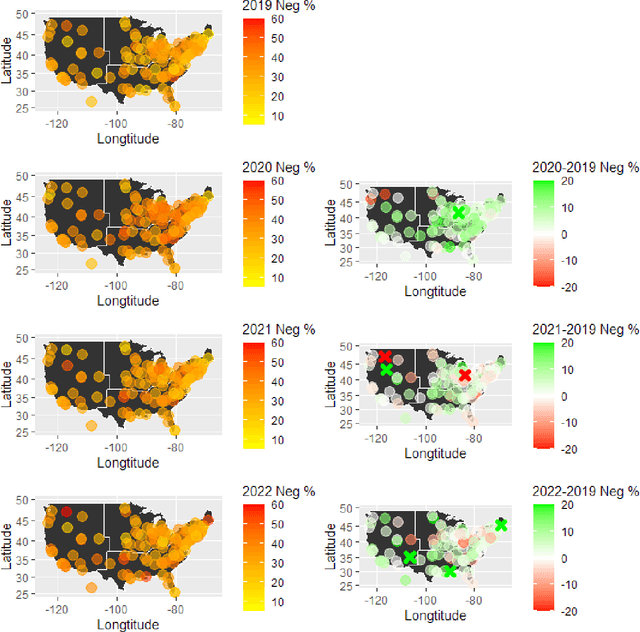
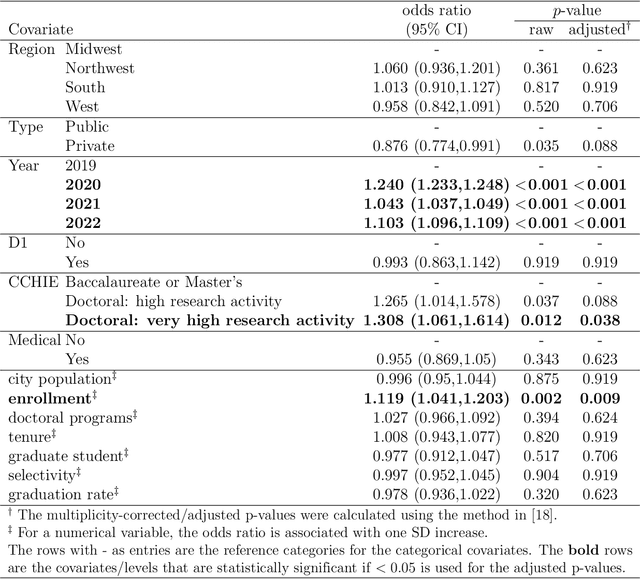
As impact of COVID-19 pandemic winds down, both individuals and society gradually return to pre-pandemic activities. This study aims to explore how people's emotions have changed from the pre-pandemic during the pandemic to post-emergency period and whether it has returned to pre-pandemic level. We collected Reddit data in 2019 (pre-pandemic), 2020 (peak pandemic), 2021, and 2022 (late stages of pandemic, transitioning period to post-emergency period) from subreddits in 128 universities/colleges in the U.S., and a set of school-level characteristics. We predicted two sets of sentiments from a pre-trained Robustly Optimized BERT pre-training approach (RoBERTa) and graph attention network (GAT) that leverages both rich semantic and relational information among posted messages and then applied a logistic stacking method to obtain the final sentiment classification. After obtaining sentiment label for each message, we used a generalized linear mixed-effects model to estimate temporal trend in sentiment from 2019 to 2022 and how school-level factors may affect sentiment. Compared to the year 2019, the odds of negative sentiment in years 2020, 2021, and 2022 are 24%, 4.3%, and 10.3% higher, respectively, which are all statistically significant(adjusted $p$<0.05). Our study findings suggest a partial recovery in the sentiment composition in the post-pandemic-emergency era. The results align with common expectations and provide a detailed quantification of how sentiments have evolved from 2019 to 2022.
A Blackbox Model Is All You Need to Breach Privacy: Smart Grid Forecasting Models as a Use Case
Sep 04, 2023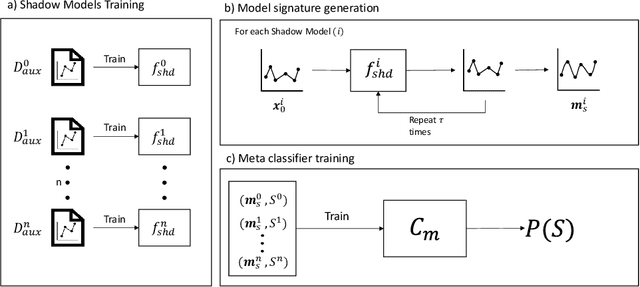
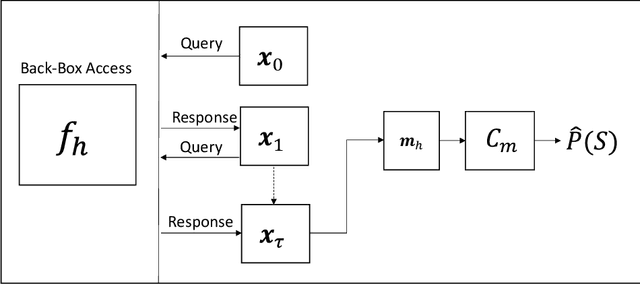
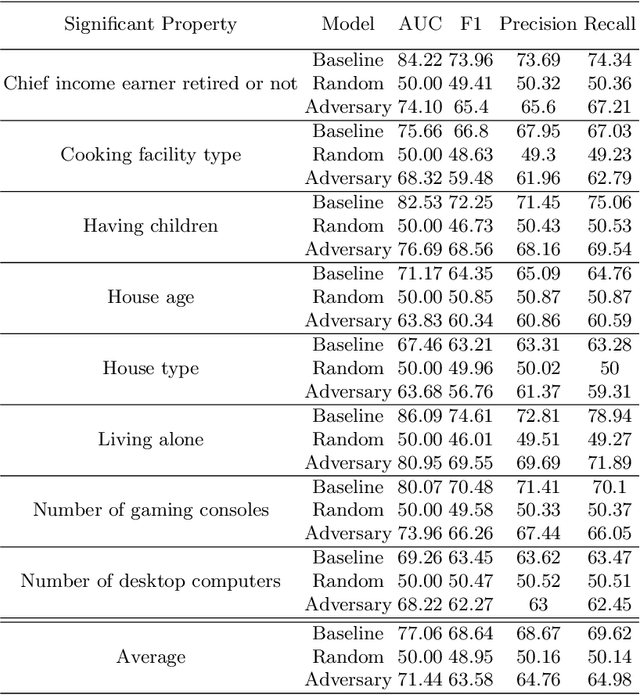
This paper investigates the potential privacy risks associated with forecasting models, with specific emphasis on their application in the context of smart grids. While machine learning and deep learning algorithms offer valuable utility, concerns arise regarding their exposure of sensitive information. Previous studies have focused on classification models, overlooking risks associated with forecasting models. Deep learning based forecasting models, such as Long Short Term Memory (LSTM), play a crucial role in several applications including optimizing smart grid systems but also introduce privacy risks. Our study analyzes the ability of forecasting models to leak global properties and privacy threats in smart grid systems. We demonstrate that a black box access to an LSTM model can reveal a significant amount of information equivalent to having access to the data itself (with the difference being as low as 1% in Area Under the ROC Curve). This highlights the importance of protecting forecasting models at the same level as the data.
TKwinFormer: Top k Window Attention in Vision Transformers for Feature Matching
Aug 29, 2023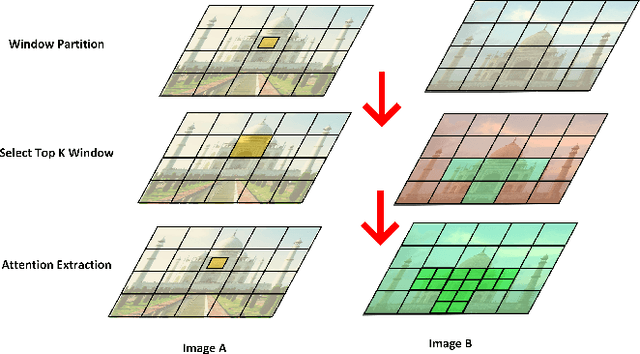
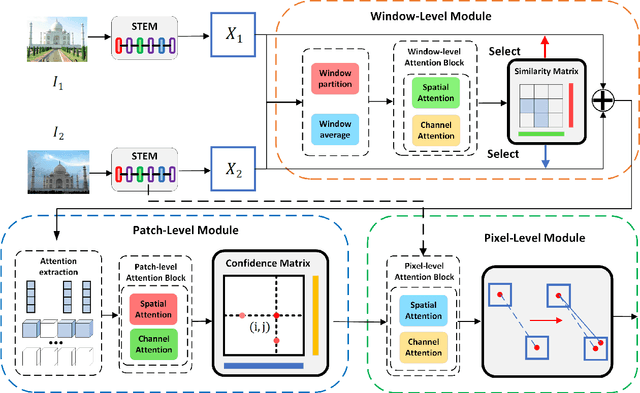
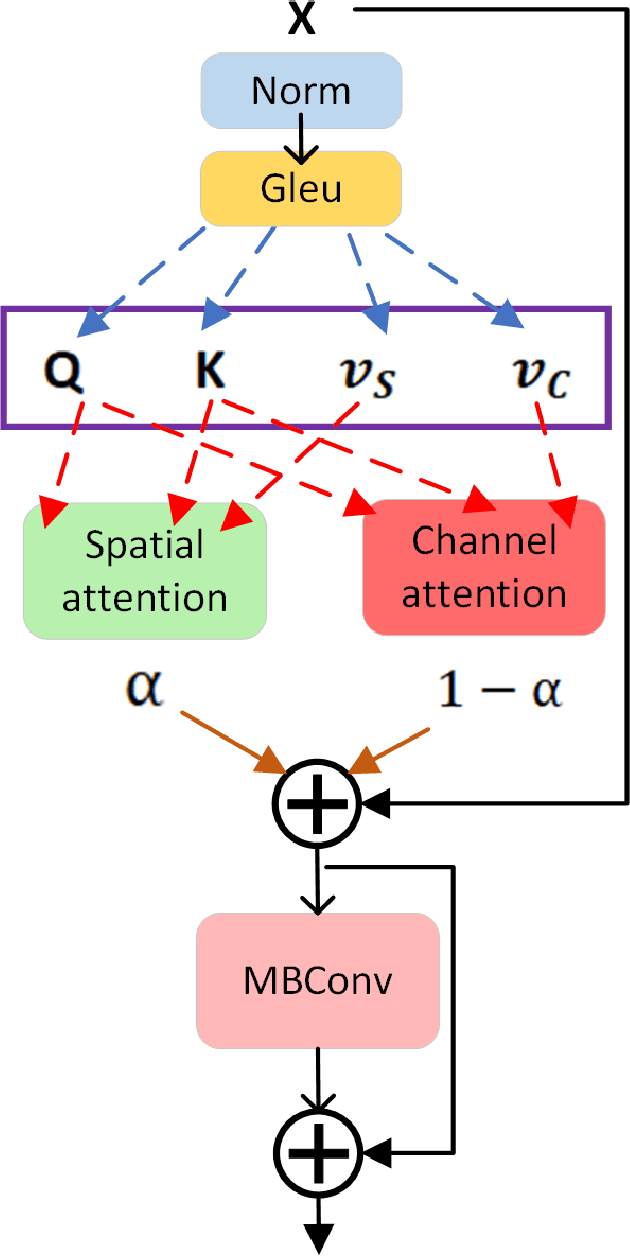
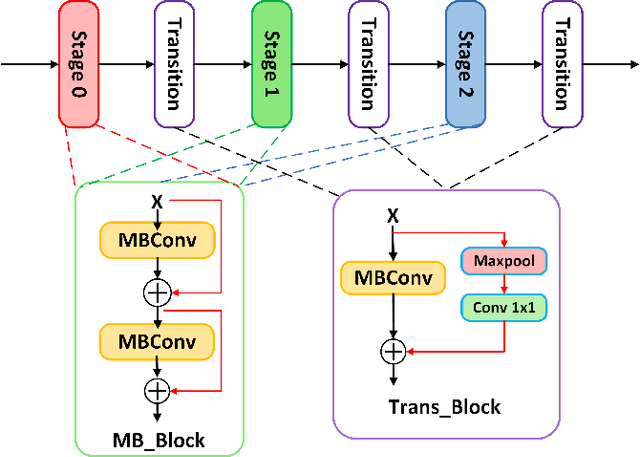
Local feature matching remains a challenging task, primarily due to difficulties in matching sparse keypoints and low-texture regions. The key to solving this problem lies in effectively and accurately integrating global and local information. To achieve this goal, we introduce an innovative local feature matching method called TKwinFormer. Our approach employs a multi-stage matching strategy to optimize the efficiency of information interaction. Furthermore, we propose a novel attention mechanism called Top K Window Attention, which facilitates global information interaction through window tokens prior to patch-level matching, resulting in improved matching accuracy. Additionally, we design an attention block to enhance attention between channels. Experimental results demonstrate that TKwinFormer outperforms state-of-the-art methods on various benchmarks. Code is available at: https://github.com/LiaoYun0x0/TKwinFormer.
CPSP: Learning Speech Concepts From Phoneme Supervision
Sep 01, 2023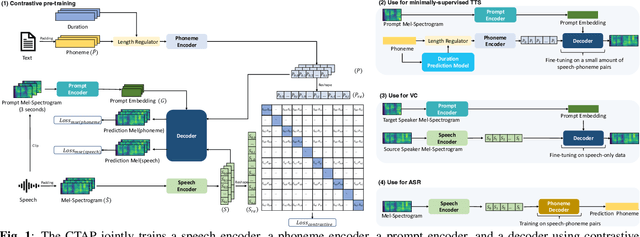
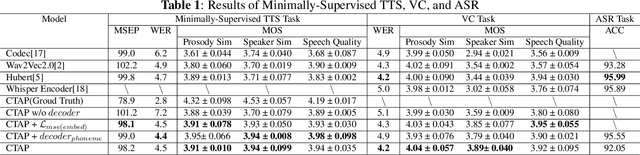
For fine-grained generation and recognition tasks such as minimally-supervised text-to-speech (TTS), voice conversion (VC), and automatic speech recognition (ASR), the intermediate representation extracted from speech should contain information that is between text coding and acoustic coding. The linguistic content is salient, while the paralinguistic information such as speaker identity and acoustic details should be removed. However, existing methods for extracting fine-grained intermediate representations from speech suffer from issues of excessive redundancy and dimension explosion. Additionally, existing contrastive learning methods in the audio field focus on extracting global descriptive information for downstream audio classification tasks, making them unsuitable for TTS, VC, and ASR tasks. To address these issues, we propose a method named Contrastive Phoneme-Speech Pretraining (CPSP), which uses three encoders, one decoder, and contrastive learning to bring phoneme and speech into a joint multimodal space, learning how to connect phoneme and speech at the frame level. The CPSP model is trained on 210k speech and phoneme text pairs, achieving minimally-supervised TTS, VC, and ASR. The proposed CPSP method offers a promising solution for fine-grained generation and recognition downstream tasks in speech processing. We provide a website with audio samples.
Fine-Grained Spatiotemporal Motion Alignment for Contrastive Video Representation Learning
Sep 01, 2023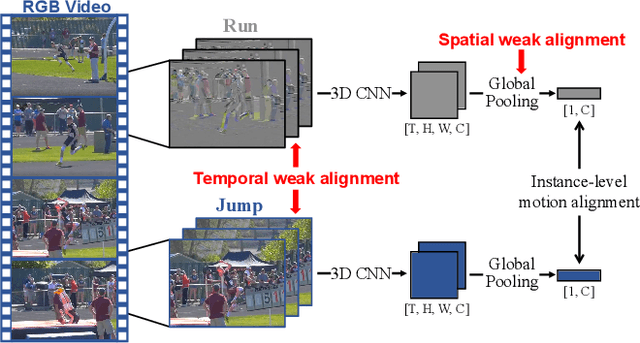
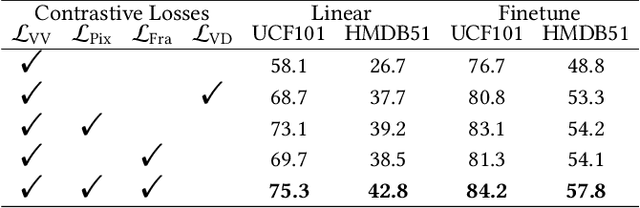
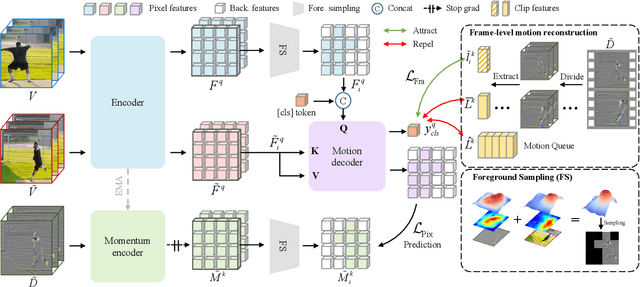
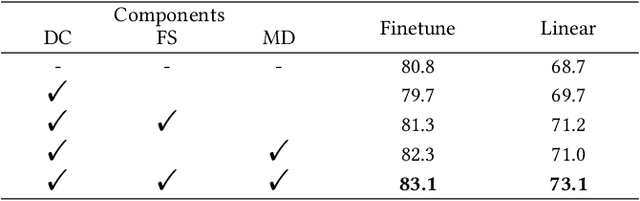
As the most essential property in a video, motion information is critical to a robust and generalized video representation. To inject motion dynamics, recent works have adopted frame difference as the source of motion information in video contrastive learning, considering the trade-off between quality and cost. However, existing works align motion features at the instance level, which suffers from spatial and temporal weak alignment across modalities. In this paper, we present a \textbf{Fi}ne-grained \textbf{M}otion \textbf{A}lignment (FIMA) framework, capable of introducing well-aligned and significant motion information. Specifically, we first develop a dense contrastive learning framework in the spatiotemporal domain to generate pixel-level motion supervision. Then, we design a motion decoder and a foreground sampling strategy to eliminate the weak alignments in terms of time and space. Moreover, a frame-level motion contrastive loss is presented to improve the temporal diversity of the motion features. Extensive experiments demonstrate that the representations learned by FIMA possess great motion-awareness capabilities and achieve state-of-the-art or competitive results on downstream tasks across UCF101, HMDB51, and Diving48 datasets. Code is available at \url{https://github.com/ZMHH-H/FIMA}.
Energy-Constrained Active Exploration Under Incremental-Resolution Symbolic Perception
Sep 13, 2023In this work, we consider the problem of autonomous exploration in search of targets while respecting a fixed energy budget. The robot is equipped with an incremental-resolution symbolic perception module wherein the perception of targets in the environment improves as the robot's distance from targets decreases. We assume no prior information about the total number of targets, their locations as well as their possible distribution within the environment. This work proposes a novel decision-making framework for the resulting constrained sequential decision-making problem by first converting it into a reward maximization problem on a product graph computed offline. It is then solved online as a Mixed-Integer Linear Program (MILP) where the knowledge about the environment is updated at each step, combining automata-based and MILP-based techniques. We demonstrate the efficacy of our approach with the help of a case study and present empirical evaluation in terms of expected regret. Furthermore, the runtime performance shows that online planning can be efficiently performed for moderately-sized grid environments.
Generalizable Neural Fields as Partially Observed Neural Processes
Sep 13, 2023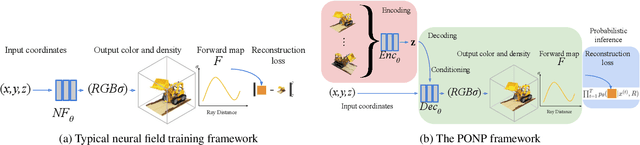

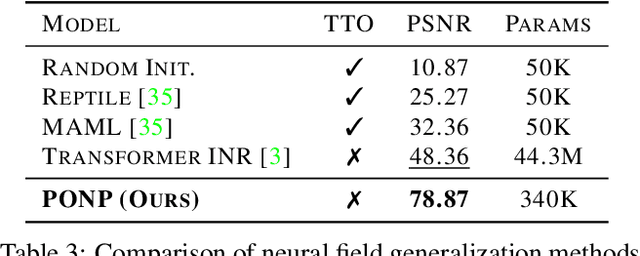
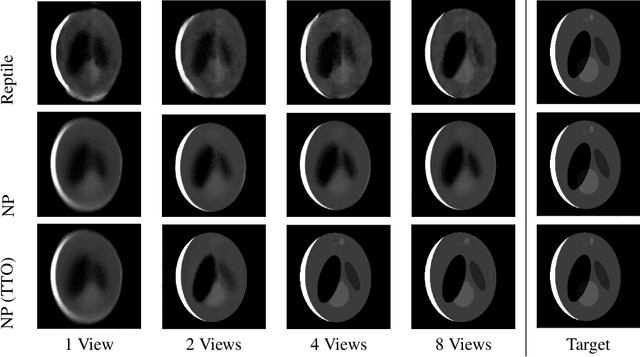
Neural fields, which represent signals as a function parameterized by a neural network, are a promising alternative to traditional discrete vector or grid-based representations. Compared to discrete representations, neural representations both scale well with increasing resolution, are continuous, and can be many-times differentiable. However, given a dataset of signals that we would like to represent, having to optimize a separate neural field for each signal is inefficient, and cannot capitalize on shared information or structures among signals. Existing generalization methods view this as a meta-learning problem and employ gradient-based meta-learning to learn an initialization which is then fine-tuned with test-time optimization, or learn hypernetworks to produce the weights of a neural field. We instead propose a new paradigm that views the large-scale training of neural representations as a part of a partially-observed neural process framework, and leverage neural process algorithms to solve this task. We demonstrate that this approach outperforms both state-of-the-art gradient-based meta-learning approaches and hypernetwork approaches.
FedDIP: Federated Learning with Extreme Dynamic Pruning and Incremental Regularization
Sep 13, 2023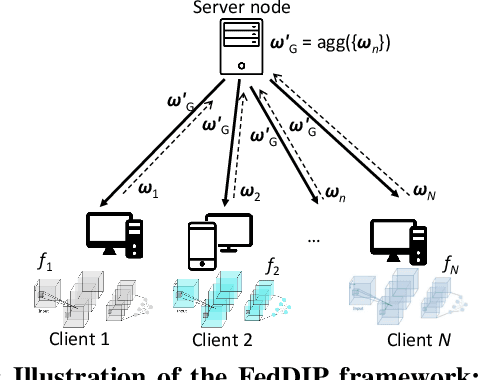
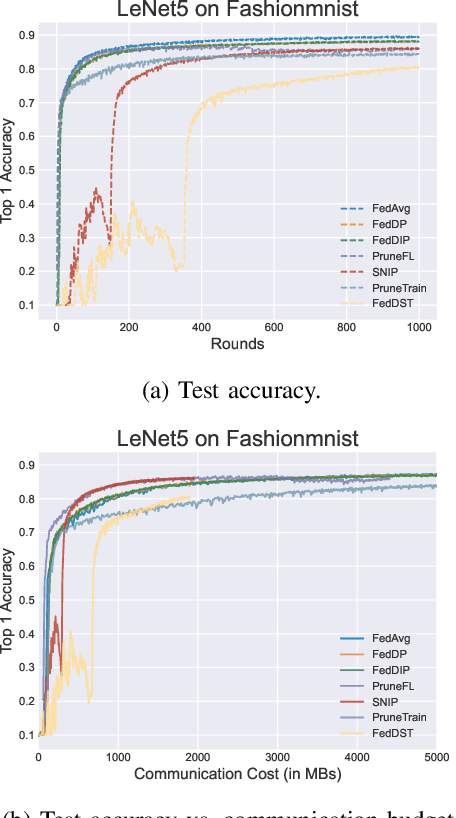
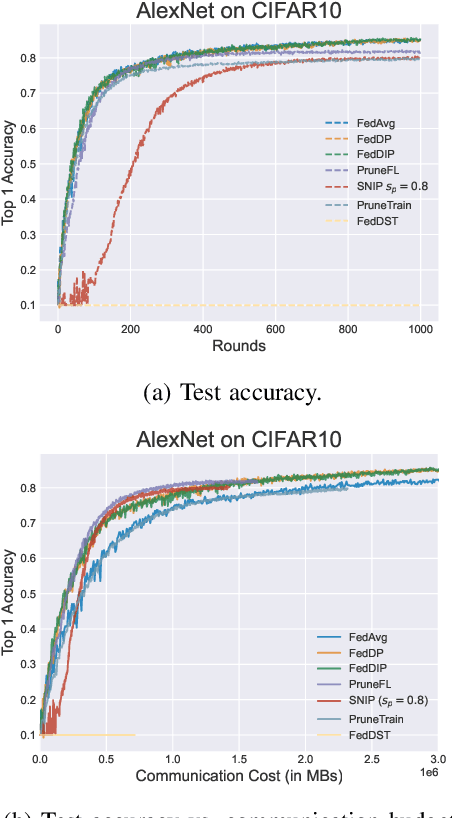
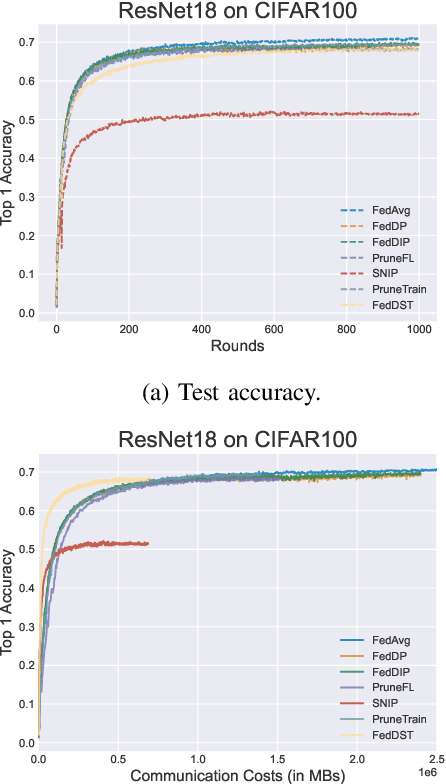
Federated Learning (FL) has been successfully adopted for distributed training and inference of large-scale Deep Neural Networks (DNNs). However, DNNs are characterized by an extremely large number of parameters, thus, yielding significant challenges in exchanging these parameters among distributed nodes and managing the memory. Although recent DNN compression methods (e.g., sparsification, pruning) tackle such challenges, they do not holistically consider an adaptively controlled reduction of parameter exchange while maintaining high accuracy levels. We, therefore, contribute with a novel FL framework (coined FedDIP), which combines (i) dynamic model pruning with error feedback to eliminate redundant information exchange, which contributes to significant performance improvement, with (ii) incremental regularization that can achieve \textit{extreme} sparsity of models. We provide convergence analysis of FedDIP and report on a comprehensive performance and comparative assessment against state-of-the-art methods using benchmark data sets and DNN models. Our results showcase that FedDIP not only controls the model sparsity but efficiently achieves similar or better performance compared to other model pruning methods adopting incremental regularization during distributed model training. The code is available at: https://github.com/EricLoong/feddip.