 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Grouping Boundary Proposals for Fast Interactive Image Segmentation
Sep 08, 2023
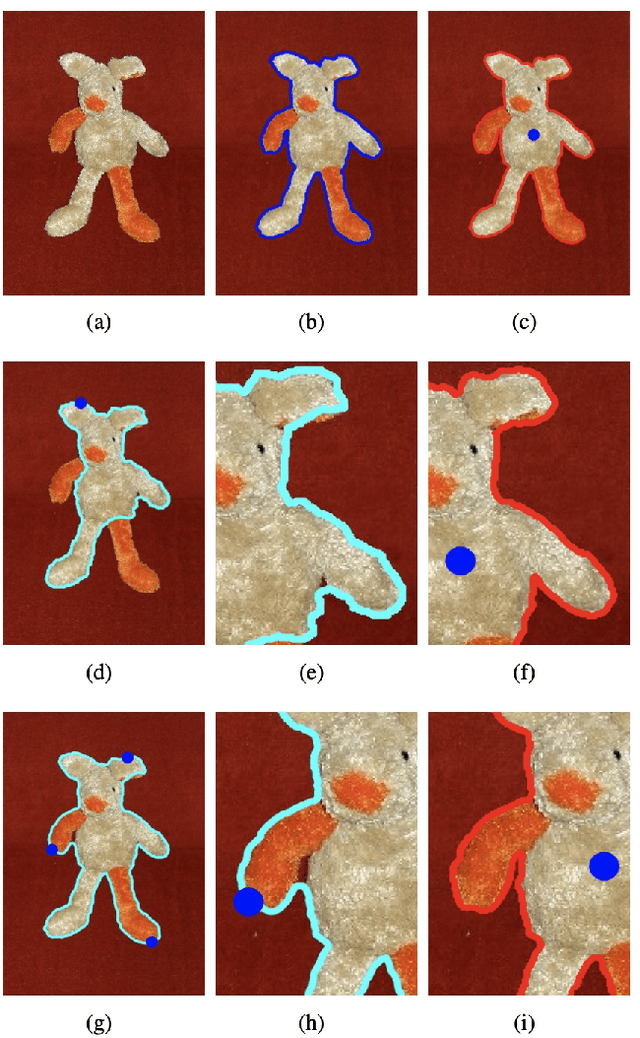
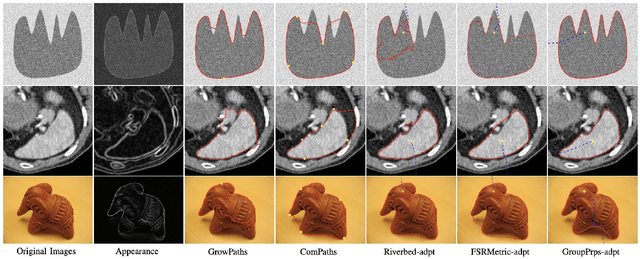

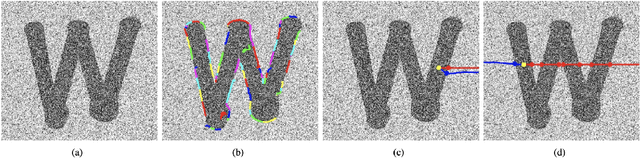
Geodesic models are known as an efficient tool for solving various image segmentation problems. Most of existing approaches only exploit local pointwise image features to track geodesic paths for delineating the objective boundaries. However, such a segmentation strategy cannot take into account the connectivity of the image edge features, increasing the risk of shortcut problem, especially in the case of complicated scenario. In this work, we introduce a new image segmentation model based on the minimal geodesic framework in conjunction with an adaptive cut-based circular optimal path computation scheme and a graph-based boundary proposals grouping scheme. Specifically, the adaptive cut can disconnect the image domain such that the target contours are imposed to pass through this cut only once. The boundary proposals are comprised of precomputed image edge segments, providing the connectivity information for our segmentation model. These boundary proposals are then incorporated into the proposed image segmentation model, such that the target segmentation contours are made up of a set of selected boundary proposals and the corresponding geodesic paths linking them. Experimental results show that the proposed model indeed outperforms state-of-the-art minimal paths-based image segmentation approaches.
From Text to Mask: Localizing Entities Using the Attention of Text-to-Image Diffusion Models
Sep 08, 2023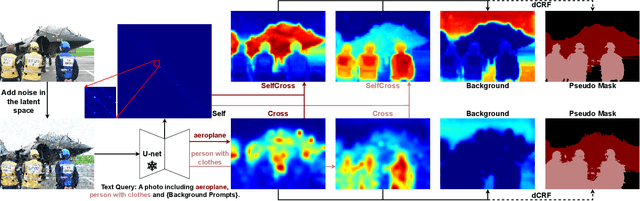
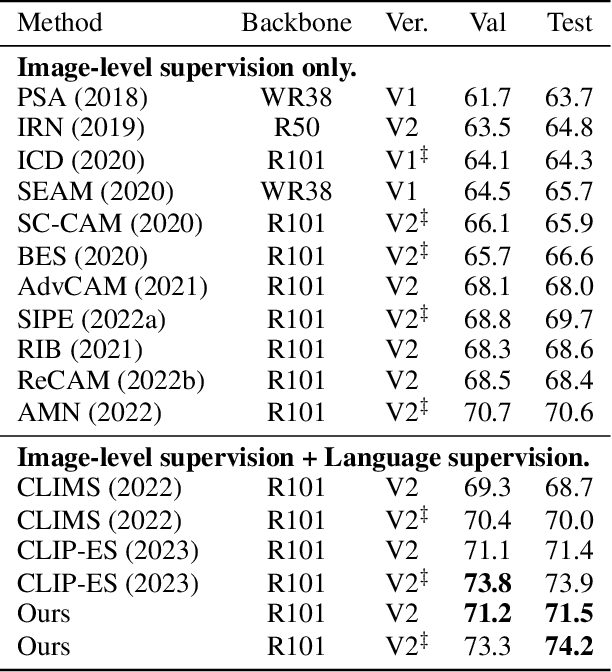

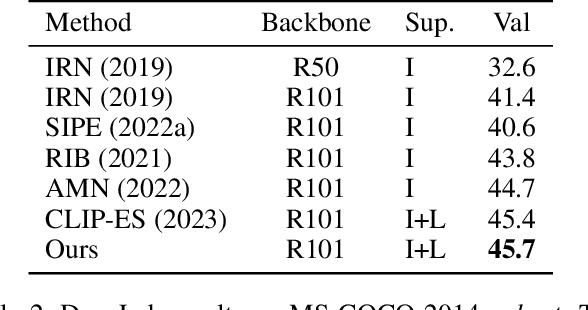
Diffusion models have revolted the field of text-to-image generation recently. The unique way of fusing text and image information contributes to their remarkable capability of generating highly text-related images. From another perspective, these generative models imply clues about the precise correlation between words and pixels. In this work, a simple but effective method is proposed to utilize the attention mechanism in the denoising network of text-to-image diffusion models. Without re-training nor inference-time optimization, the semantic grounding of phrases can be attained directly. We evaluate our method on Pascal VOC 2012 and Microsoft COCO 2014 under weakly-supervised semantic segmentation setting and our method achieves superior performance to prior methods. In addition, the acquired word-pixel correlation is found to be generalizable for the learned text embedding of customized generation methods, requiring only a few modifications. To validate our discovery, we introduce a new practical task called "personalized referring image segmentation" with a new dataset. Experiments in various situations demonstrate the advantages of our method compared to strong baselines on this task. In summary, our work reveals a novel way to extract the rich multi-modal knowledge hidden in diffusion models for segmentation.
3D Denoisers are Good 2D Teachers: Molecular Pretraining via Denoising and Cross-Modal Distillation
Sep 08, 2023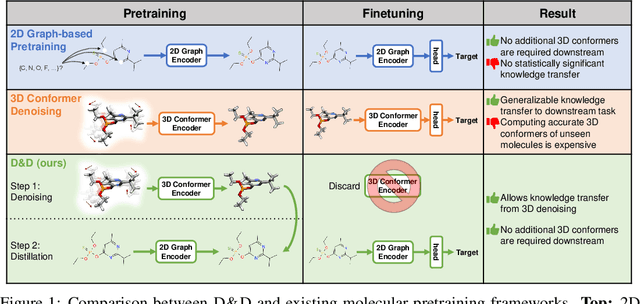
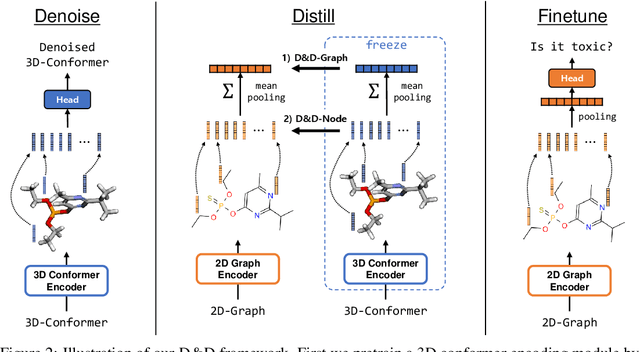
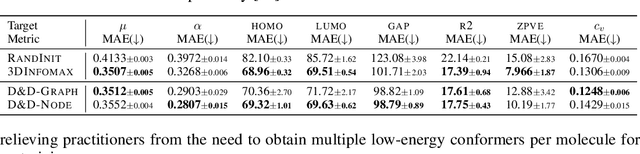
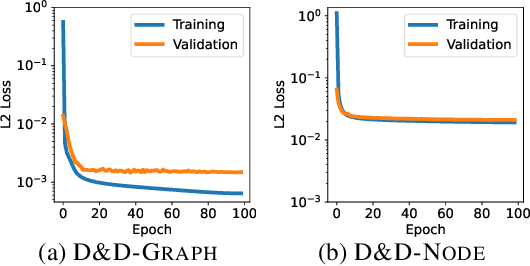
Pretraining molecular representations from large unlabeled data is essential for molecular property prediction due to the high cost of obtaining ground-truth labels. While there exist various 2D graph-based molecular pretraining approaches, these methods struggle to show statistically significant gains in predictive performance. Recent work have thus instead proposed 3D conformer-based pretraining under the task of denoising, which led to promising results. During downstream finetuning, however, models trained with 3D conformers require accurate atom-coordinates of previously unseen molecules, which are computationally expensive to acquire at scale. In light of this limitation, we propose D&D, a self-supervised molecular representation learning framework that pretrains a 2D graph encoder by distilling representations from a 3D denoiser. With denoising followed by cross-modal knowledge distillation, our approach enjoys use of knowledge obtained from denoising as well as painless application to downstream tasks with no access to accurate conformers. Experiments on real-world molecular property prediction datasets show that the graph encoder trained via D&D can infer 3D information based on the 2D graph and shows superior performance and label-efficiency against other baselines.
When Do Program-of-Thoughts Work for Reasoning?
Sep 08, 2023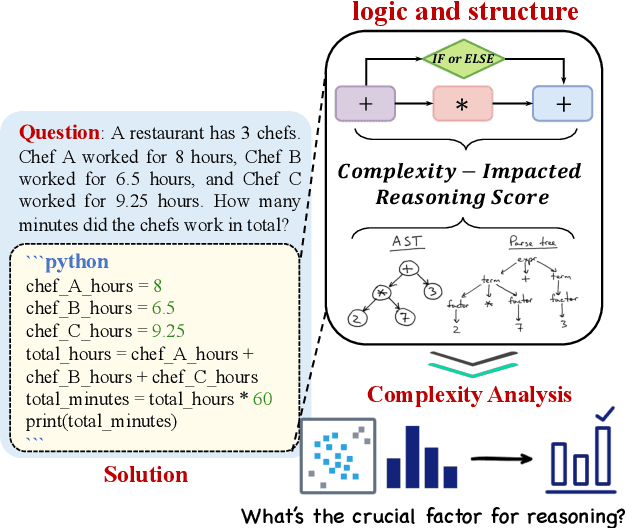
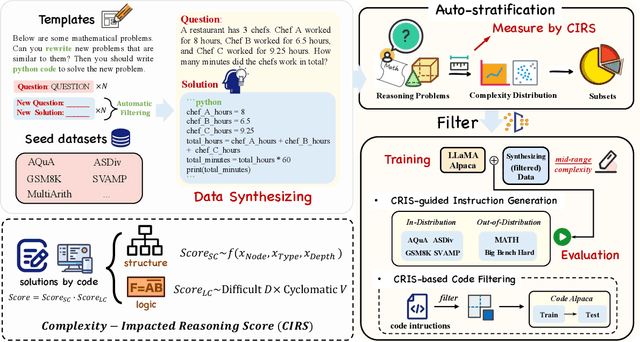
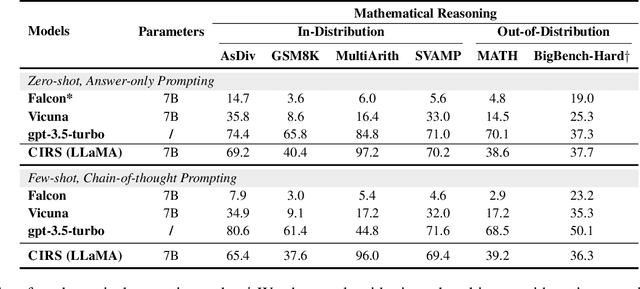
The reasoning capabilities of Large Language Models (LLMs) play a pivotal role in the realm of embodied artificial intelligence. Although there are effective methods like program-of-thought prompting for LLMs which uses programming language to tackle complex reasoning tasks, the specific impact of code data on the improvement of reasoning capabilities remains under-explored. To address this gap, we propose complexity-impacted reasoning score (CIRS), which combines structural and logical attributes, to measure the correlation between code and reasoning abilities. Specifically, we use the abstract syntax tree to encode the structural information and calculate logical complexity by considering the difficulty and the cyclomatic complexity. Through an empirical analysis, we find not all code data of complexity can be learned or understood by LLMs. Optimal level of complexity is critical to the improvement of reasoning abilities by program-aided prompting. Then we design an auto-synthesizing and stratifying algorithm, and apply it to instruction generation for mathematical reasoning and code data filtering for code generation tasks. Extensive results demonstrates the effectiveness of our proposed approach. Code will be integrated into the EasyInstruct framework at https://github.com/zjunlp/EasyInstruct.
Artificial intelligence is ineffective and potentially harmful for fact checking
Sep 01, 2023

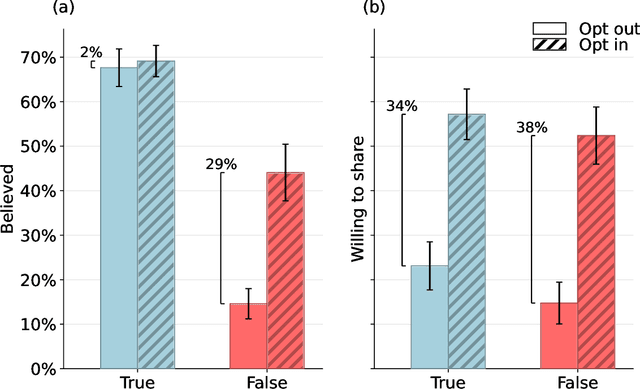
Fact checking can be an effective strategy against misinformation, but its implementation at scale is impeded by the overwhelming volume of information online. Recent artificial intelligence (AI) language models have shown impressive ability in fact-checking tasks, but how humans interact with fact-checking information provided by these models is unclear. Here we investigate the impact of fact checks generated by a popular AI model on belief in, and sharing intent of, political news in a preregistered randomized control experiment. Although the AI performs reasonably well in debunking false headlines, we find that it does not significantly affect participants' ability to discern headline accuracy or share accurate news. However, the AI fact-checker is harmful in specific cases: it decreases beliefs in true headlines that it mislabels as false and increases beliefs for false headlines that it is unsure about. On the positive side, the AI increases sharing intents for correctly labeled true headlines. When participants are given the option to view AI fact checks and choose to do so, they are significantly more likely to share both true and false news but only more likely to believe false news. Our findings highlight an important source of potential harm stemming from AI applications and underscore the critical need for policies to prevent or mitigate such unintended consequences.
FactLLaMA: Optimizing Instruction-Following Language Models with External Knowledge for Automated Fact-Checking
Sep 01, 2023Automatic fact-checking plays a crucial role in combating the spread of misinformation. Large Language Models (LLMs) and Instruction-Following variants, such as InstructGPT and Alpaca, have shown remarkable performance in various natural language processing tasks. However, their knowledge may not always be up-to-date or sufficient, potentially leading to inaccuracies in fact-checking. To address this limitation, we propose combining the power of instruction-following language models with external evidence retrieval to enhance fact-checking performance. Our approach involves leveraging search engines to retrieve relevant evidence for a given input claim. This external evidence serves as valuable supplementary information to augment the knowledge of the pretrained language model. Then, we instruct-tune an open-sourced language model, called LLaMA, using this evidence, enabling it to predict the veracity of the input claim more accurately. To evaluate our method, we conducted experiments on two widely used fact-checking datasets: RAWFC and LIAR. The results demonstrate that our approach achieves state-of-the-art performance in fact-checking tasks. By integrating external evidence, we bridge the gap between the model's knowledge and the most up-to-date and sufficient context available, leading to improved fact-checking outcomes. Our findings have implications for combating misinformation and promoting the dissemination of accurate information on online platforms. Our released materials are accessible at: https://thcheung.github.io/factllama.
Human trajectory prediction using LSTM with Attention mechanism
Sep 01, 2023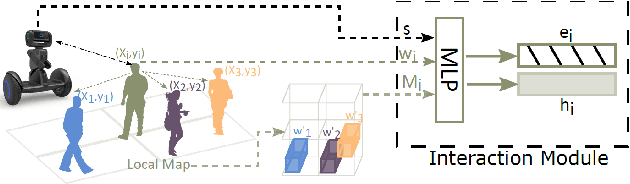
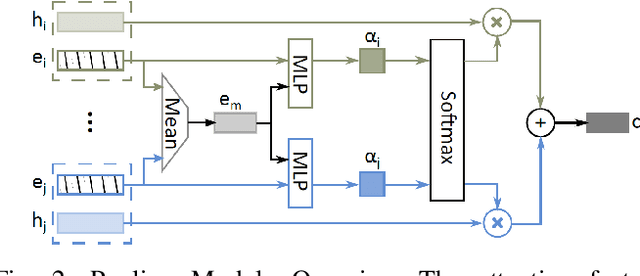
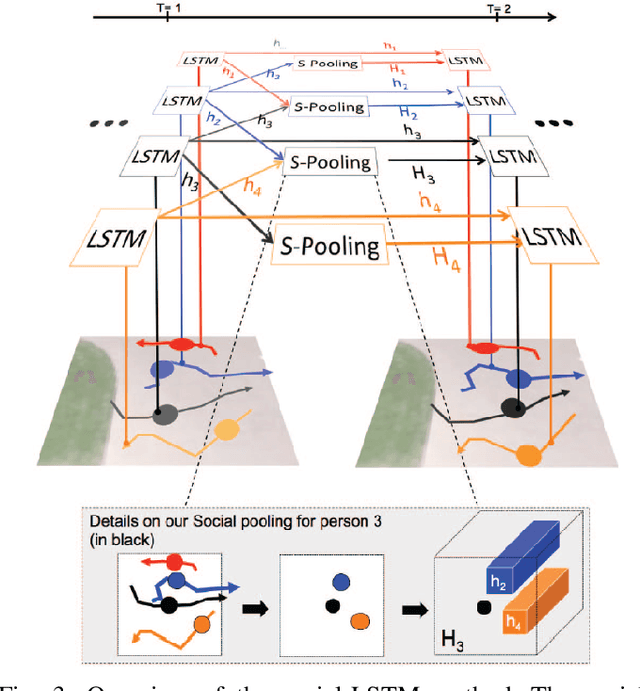
In this paper, we propose a human trajectory prediction model that combines a Long Short-Term Memory (LSTM) network with an attention mechanism. To do that, we use attention scores to determine which parts of the input data the model should focus on when making predictions. Attention scores are calculated for each input feature, with a higher score indicating the greater significance of that feature in predicting the output. Initially, these scores are determined for the target human position, velocity, and their neighboring individual's positions and velocities. By using attention scores, our model can prioritize the most relevant information in the input data and make more accurate predictions. We extract attention scores from our attention mechanism and integrate them into the trajectory prediction module to predict human future trajectories. To achieve this, we introduce a new neural layer that processes attention scores after extracting them and concatenates them with positional information. We evaluate our approach on the publicly available ETH and UCY datasets and measure its performance using the final displacement error (FDE) and average displacement error (ADE) metrics. We show that our modified algorithm performs better than the Social LSTM in predicting the future trajectory of pedestrians in crowded spaces. Specifically, our model achieves an improvement of 6.2% in ADE and 6.3% in FDE compared to the Social LSTM results in the literature.
Trust your Good Friends: Source-free Domain Adaptation by Reciprocal Neighborhood Clustering
Sep 01, 2023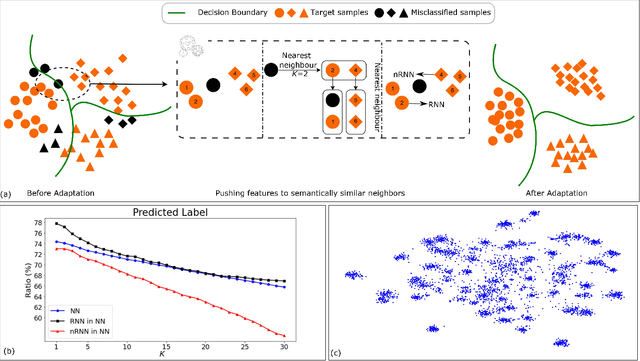
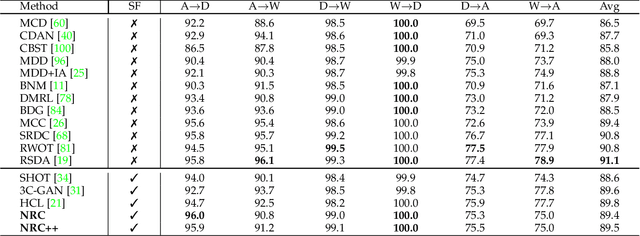
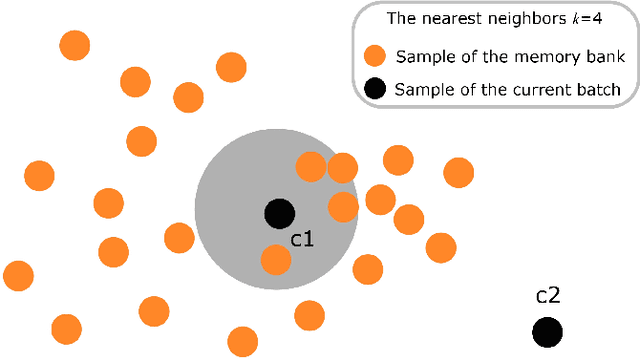
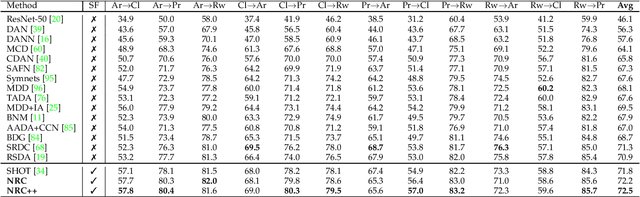
Domain adaptation (DA) aims to alleviate the domain shift between source domain and target domain. Most DA methods require access to the source data, but often that is not possible (e.g. due to data privacy or intellectual property). In this paper, we address the challenging source-free domain adaptation (SFDA) problem, where the source pretrained model is adapted to the target domain in the absence of source data. Our method is based on the observation that target data, which might not align with the source domain classifier, still forms clear clusters. We capture this intrinsic structure by defining local affinity of the target data, and encourage label consistency among data with high local affinity. We observe that higher affinity should be assigned to reciprocal neighbors. To aggregate information with more context, we consider expanded neighborhoods with small affinity values. Furthermore, we consider the density around each target sample, which can alleviate the negative impact of potential outliers. In the experimental results we verify that the inherent structure of the target features is an important source of information for domain adaptation. We demonstrate that this local structure can be efficiently captured by considering the local neighbors, the reciprocal neighbors, and the expanded neighborhood. Finally, we achieve state-of-the-art performance on several 2D image and 3D point cloud recognition datasets.
Squeeze aggregated excitation network
Aug 25, 2023Convolutional neural networks have spatial representations which read patterns in the vision tasks. Squeeze and excitation links the channel wise representations by explicitly modeling on channel level. Multi layer perceptrons learn global representations and in most of the models it is used often at the end after all convolutional layers to gather all the information learned before classification. We propose a method of inducing the global representations within channels to have better performance of the model. We propose SaEnet, Squeeze aggregated excitation network, for learning global channelwise representation in between layers. The proposed module takes advantage of passing important information after squeeze by having aggregated excitation before regaining its shape. We also introduce a new idea of having a multibranch linear(dense) layer in the network. This learns global representations from the condensed information which enhances the representational power of the network. The proposed module have undergone extensive experiments by using Imagenet and CIFAR100 datasets and compared with closely related architectures. The analyzes results that proposed models outputs are comparable and in some cases better than existing state of the art architectures.
Emoji Promotes Developer Participation and Issue Resolution on GitHub
Sep 07, 2023


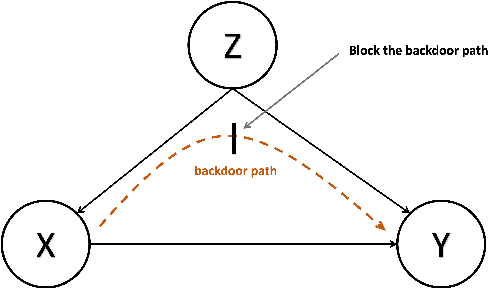
Although remote working is increasingly adopted during the pandemic, many are concerned by the low-efficiency in the remote working. Missing in text-based communication are non-verbal cues such as facial expressions and body language, which hinders the effective communication and negatively impacts the work outcomes. Prevalent on social media platforms, emojis, as alternative non-verbal cues, are gaining popularity in the virtual workspaces well. In this paper, we study how emoji usage influences developer participation and issue resolution in virtual workspaces. To this end, we collect GitHub issues for a one-year period and apply causal inference techniques to measure the causal effect of emojis on the outcome of issues, controlling for confounders such as issue content, repository, and author information. We find that emojis can significantly reduce the resolution time of issues and attract more user participation. We also compare the heterogeneous effect on different types of issues. These findings deepen our understanding of the developer communities, and they provide design implications on how to facilitate interactions and broaden developer participation.