 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Behind Recommender Systems: the Geography of the ACM RecSys Community
Sep 07, 2023
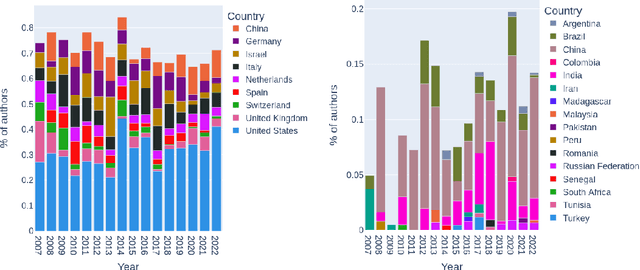
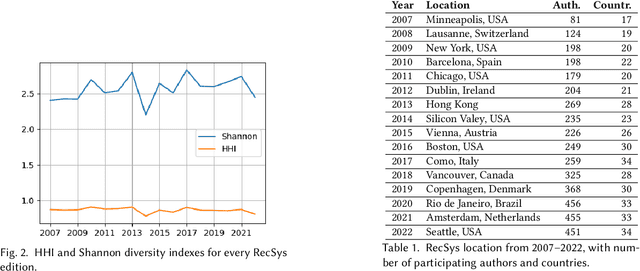
The amount and dissemination rate of media content accessible online is nowadays overwhelming. Recommender Systems filter this information into manageable streams or feeds, adapted to our personal needs or preferences. It is of utter importance that algorithms employed to filter information do not distort or cut out important elements from our perspectives of the world. Under this principle, it is essential to involve diverse views and teams from the earliest stages of their design and development. This has been highlighted, for instance, in recent European Union regulations such as the Digital Services Act, via the requirement of risk monitoring, including the risk of discrimination, and the AI Act, through the requirement to involve people with diverse backgrounds in the development of AI systems. We look into the geographic diversity of the recommender systems research community, specifically by analyzing the affiliation countries of the authors who contributed to the ACM Conference on Recommender Systems (RecSys) during the last 15 years. This study has been carried out in the framework of the Diversity in AI - DivinAI project, whose main objective is the long-term monitoring of diversity in AI forums through a set of indexes.
Decoder-only Architecture for Speech Recognition with CTC Prompts and Text Data Augmentation
Sep 16, 2023Collecting audio-text pairs is expensive; however, it is much easier to access text-only data. Unless using shallow fusion, end-to-end automatic speech recognition (ASR) models require architecture modifications or additional training schemes to use text-only data. Inspired by recent advances in decoder-only language models (LMs), such as GPT-3 and PaLM adopted for speech-processing tasks, we propose using a decoder-only architecture for ASR with simple text augmentation. To provide audio information, encoder features compressed by CTC prediction are used as prompts for the decoder, which can be regarded as refining CTC prediction using the decoder-only model. Because the decoder architecture is the same as an autoregressive LM, it is simple to enhance the model by leveraging external text data with LM training. An experimental comparison using LibriSpeech and Switchboard shows that our proposed models with text augmentation training reduced word error rates from ordinary CTC by 0.3% and 1.4% on LibriSpeech test-clean and testother set, respectively, and 2.9% and 5.0% on Switchboard and CallHome. The proposed model had advantage on computational efficiency compared with conventional encoder-decoder ASR models with a similar parameter setup, and outperformed them on the LibriSpeech 100h and Switchboard training scenarios.
Bridging Dense and Sparse Maximum Inner Product Search
Sep 16, 2023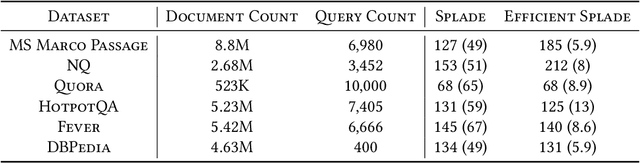
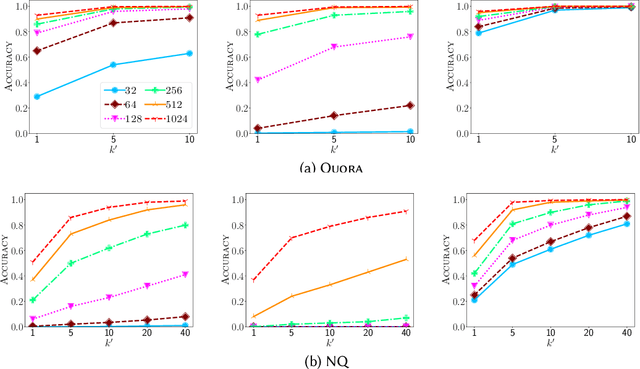
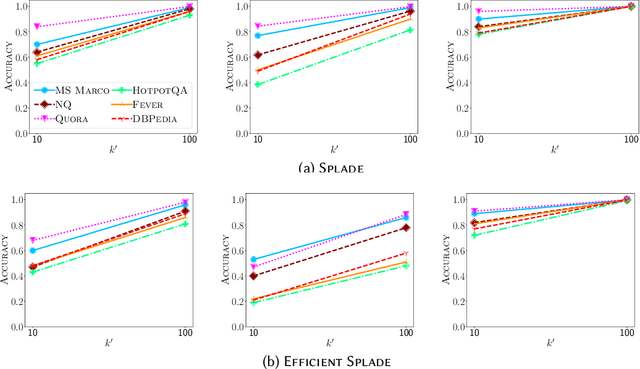

Maximum inner product search (MIPS) over dense and sparse vectors have progressed independently in a bifurcated literature for decades; the latter is better known as top-$k$ retrieval in Information Retrieval. This duality exists because sparse and dense vectors serve different end goals. That is despite the fact that they are manifestations of the same mathematical problem. In this work, we ask if algorithms for dense vectors could be applied effectively to sparse vectors, particularly those that violate the assumptions underlying top-$k$ retrieval methods. We study IVF-based retrieval where vectors are partitioned into clusters and only a fraction of clusters are searched during retrieval. We conduct a comprehensive analysis of dimensionality reduction for sparse vectors, and examine standard and spherical KMeans for partitioning. Our experiments demonstrate that IVF serves as an efficient solution for sparse MIPS. As byproducts, we identify two research opportunities and demonstrate their potential. First, we cast the IVF paradigm as a dynamic pruning technique and turn that insight into a novel organization of the inverted index for approximate MIPS for general sparse vectors. Second, we offer a unified regime for MIPS over vectors that have dense and sparse subspaces, and show its robustness to query distributions.
Multi-camera Bird's Eye View Perception for Autonomous Driving
Sep 19, 2023
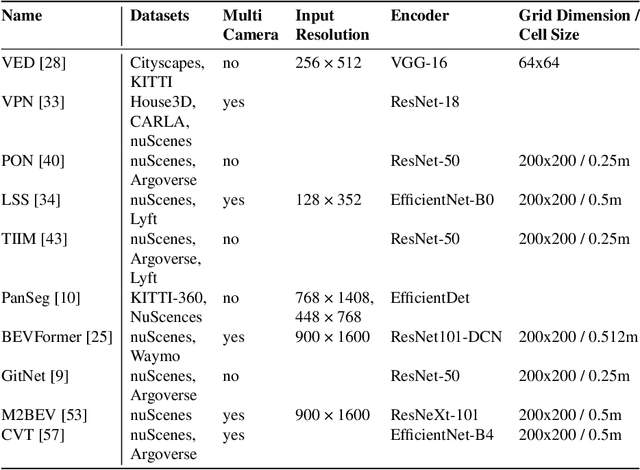
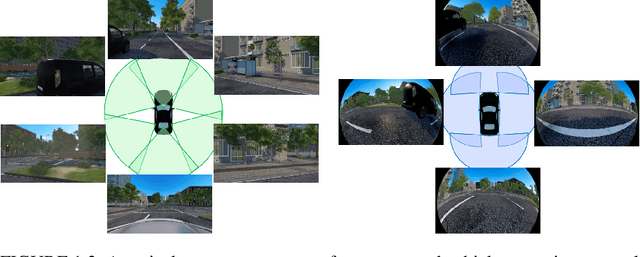
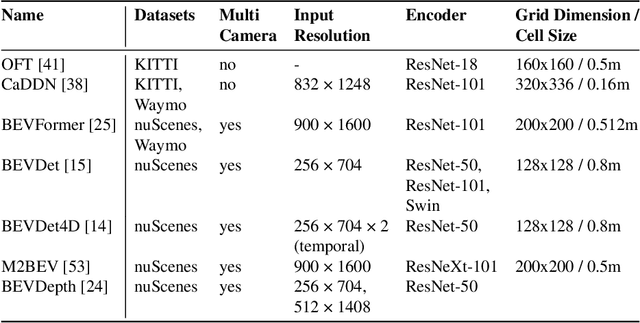
Most automated driving systems comprise a diverse sensor set, including several cameras, Radars, and LiDARs, ensuring a complete 360\deg coverage in near and far regions. Unlike Radar and LiDAR, which measure directly in 3D, cameras capture a 2D perspective projection with inherent depth ambiguity. However, it is essential to produce perception outputs in 3D to enable the spatial reasoning of other agents and structures for optimal path planning. The 3D space is typically simplified to the BEV space by omitting the less relevant Z-coordinate, which corresponds to the height dimension.The most basic approach to achieving the desired BEV representation from a camera image is IPM, assuming a flat ground surface. Surround vision systems that are pretty common in new vehicles use the IPM principle to generate a BEV image and to show it on display to the driver. However, this approach is not suited for autonomous driving since there are severe distortions introduced by this too-simplistic transformation method. More recent approaches use deep neural networks to output directly in BEV space. These methods transform camera images into BEV space using geometric constraints implicitly or explicitly in the network. As CNN has more context information and a learnable transformation can be more flexible and adapt to image content, the deep learning-based methods set the new benchmark for BEV transformation and achieve state-of-the-art performance. First, this chapter discusses the contemporary trends of multi-camera-based DNN (deep neural network) models outputting object representations directly in the BEV space. Then, we discuss how this approach can extend to effective sensor fusion and coupling downstream tasks like situation analysis and prediction. Finally, we show challenges and open problems in BEV perception.
An Improved Encoder-Decoder Framework for Food EnergyEstimation
Sep 01, 2023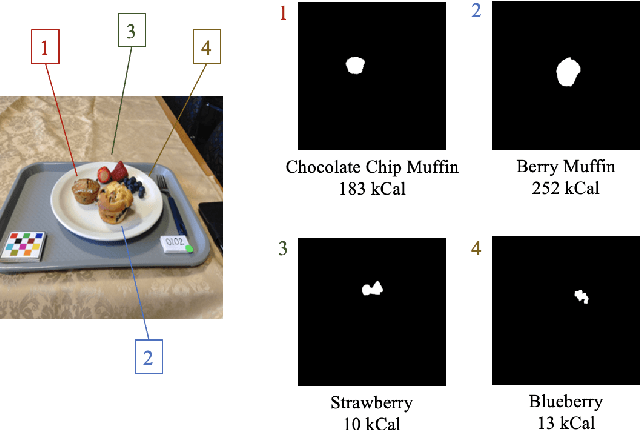

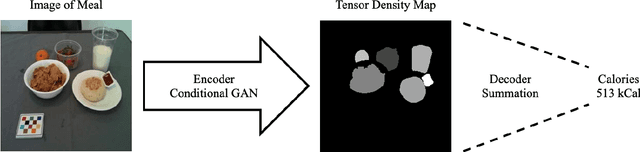

Dietary assessment is essential to maintaining a healthy lifestyle. Automatic image-based dietary assessment is a growing field of research due to the increasing prevalence of image capturing devices (e.g. mobile phones). In this work, we estimate food energy from a single monocular image, a difficult task due to the limited hard-to-extract amount of energy information present in an image. To do so, we employ an improved encoder-decoder framework for energy estimation; the encoder transforms the image into a representation embedded with food energy information in an easier-to-extract format, which the decoder then extracts the energy information from. To implement our method, we compile a high-quality food image dataset verified by registered dietitians containing eating scene images, food-item segmentation masks, and ground truth calorie values. Our method improves upon previous caloric estimation methods by over 10\% and 30 kCal in terms of MAPE and MAE respectively.
Debunking Disinformation: Revolutionizing Truth with NLP in Fake News Detection
Aug 30, 2023The Internet and social media have altered how individuals access news in the age of instantaneous information distribution. While this development has increased access to information, it has also created a significant problem: the spread of fake news and information. Fake news is rapidly spreading on digital platforms, which has a negative impact on the media ecosystem, public opinion, decision-making, and social cohesion. Natural Language Processing(NLP), which offers a variety of approaches to identify content as authentic, has emerged as a potent weapon in the growing war against disinformation. This paper takes an in-depth look at how NLP technology can be used to detect fake news and reveals the challenges and opportunities it presents.
RESTORE: Graph Embedding Assessment Through Reconstruction
Sep 05, 2023
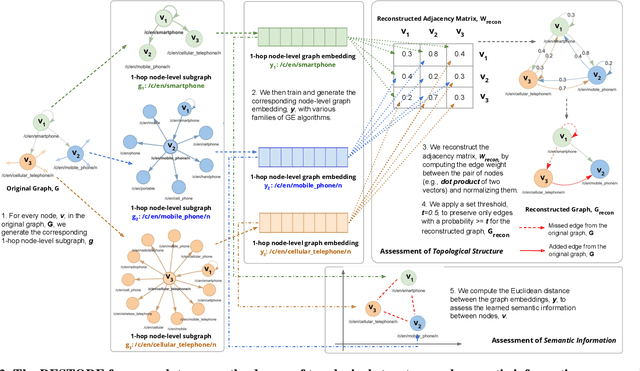
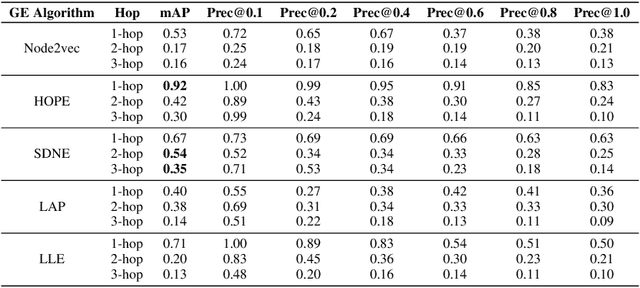
Following the success of Word2Vec embeddings, graph embeddings (GEs) have gained substantial traction. GEs are commonly generated and evaluated extrinsically on downstream applications, but intrinsic evaluations of the original graph properties in terms of topological structure and semantic information have been lacking. Understanding these will help identify the deficiency of the various families of GE methods when vectorizing graphs in terms of preserving the relevant knowledge or learning incorrect knowledge. To address this, we propose RESTORE, a framework for intrinsic GEs assessment through graph reconstruction. We show that reconstructing the original graph from the underlying GEs yields insights into the relative amount of information preserved in a given vector form. We first introduce the graph reconstruction task. We generate GEs from three GE families based on factorization methods, random walks, and deep learning (with representative algorithms from each family) on the CommonSense Knowledge Graph (CSKG). We analyze their effectiveness in preserving the (a) topological structure of node-level graph reconstruction with an increasing number of hops and (b) semantic information on various word semantic and analogy tests. Our evaluations show deep learning-based GE algorithm (SDNE) is overall better at preserving (a) with a mean average precision (mAP) of 0.54 and 0.35 for 2 and 3-hop reconstruction respectively, while the factorization-based algorithm (HOPE) is better at encapsulating (b) with an average Euclidean distance of 0.14, 0.17, and 0.11 for 1, 2, and 3-hop reconstruction respectively. The modest performance of these GEs leaves room for further research avenues on better graph representation learning.
Addressing Feature Imbalance in Sound Source Separation
Sep 11, 2023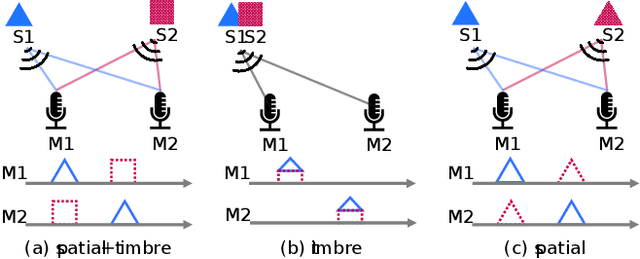
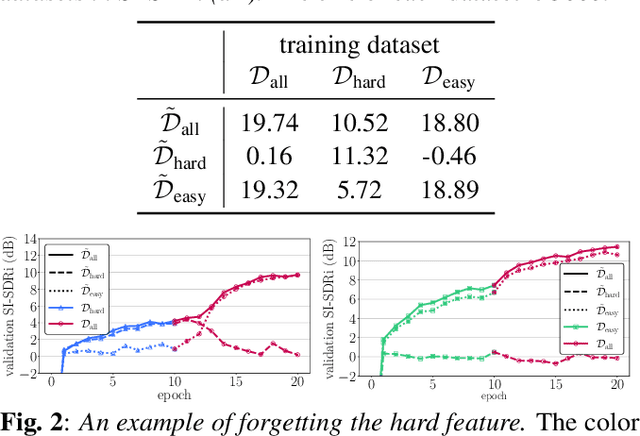


Neural networks often suffer from a feature preference problem, where they tend to overly rely on specific features to solve a task while disregarding other features, even if those neglected features are essential for the task. Feature preference problems have primarily been investigated in classification task. However, we observe that feature preference occurs in high-dimensional regression task, specifically, source separation. To mitigate feature preference in source separation, we propose FEAture BAlancing by Suppressing Easy feature (FEABASE). This approach enables efficient data utilization by learning hidden information about the neglected feature. We evaluate our method in a multi-channel source separation task, where feature preference between spatial feature and timbre feature appears.
CONVERSER: Few-Shot Conversational Dense Retrieval with Synthetic Data Generation
Sep 13, 2023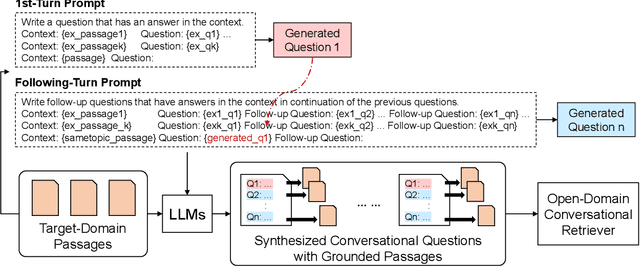
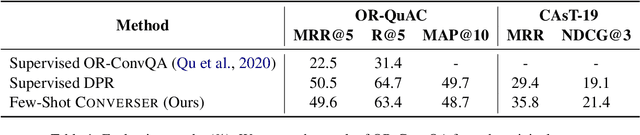
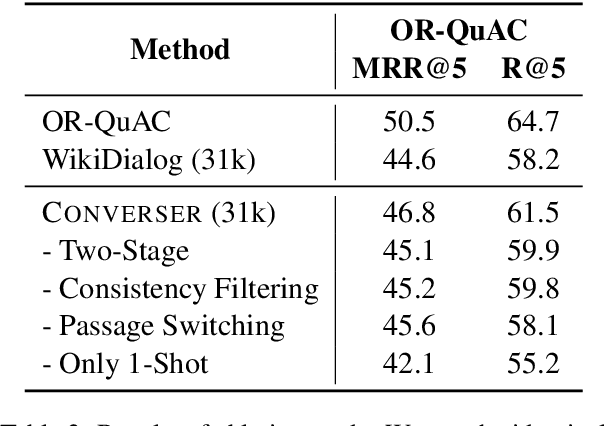
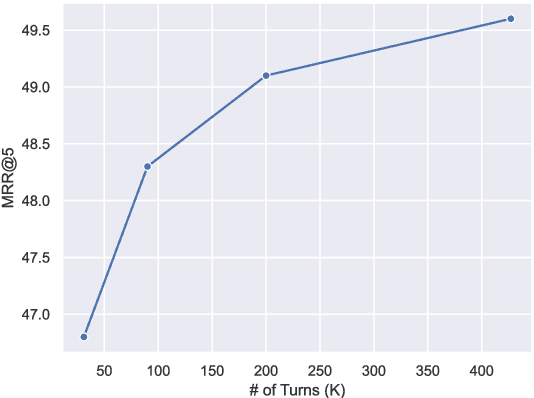
Conversational search provides a natural interface for information retrieval (IR). Recent approaches have demonstrated promising results in applying dense retrieval to conversational IR. However, training dense retrievers requires large amounts of in-domain paired data. This hinders the development of conversational dense retrievers, as abundant in-domain conversations are expensive to collect. In this paper, we propose CONVERSER, a framework for training conversational dense retrievers with at most 6 examples of in-domain dialogues. Specifically, we utilize the in-context learning capability of large language models to generate conversational queries given a passage in the retrieval corpus. Experimental results on conversational retrieval benchmarks OR-QuAC and TREC CAsT 19 show that the proposed CONVERSER achieves comparable performance to fully-supervised models, demonstrating the effectiveness of our proposed framework in few-shot conversational dense retrieval. All source code and generated datasets are available at https://github.com/MiuLab/CONVERSER
On the Local Quadratic Stability of T-S Fuzzy Systems in the Vicinity of the Origin
Sep 13, 2023The main goal of this paper is to introduce new local stability conditions for continuous-time Takagi-Sugeno (T-S) fuzzy systems. These stability conditions are based on linear matrix inequalities (LMIs) in combination with quadratic Lyapunov functions. Moreover, they integrate information on the membership functions at the origin and effectively leverage the linear structure of the underlying nonlinear system in the vicinity of the origin. As a result, the proposed conditions are proved to be less conservative compared to existing methods using fuzzy Lyapunov functions in the literature. Moreover, we establish that the proposed methods offer necessary and sufficient conditions for the local exponential stability of T-S fuzzy systems. The paper also includes discussions on the inherent limitations associated with fuzzy Lyapunov approaches. To demonstrate the theoretical results, we provide comprehensive examples that elucidate the core concepts and validate the efficacy of the proposed conditions.