 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Contextual Biasing of Named-Entities with Large Language Models
Sep 01, 2023

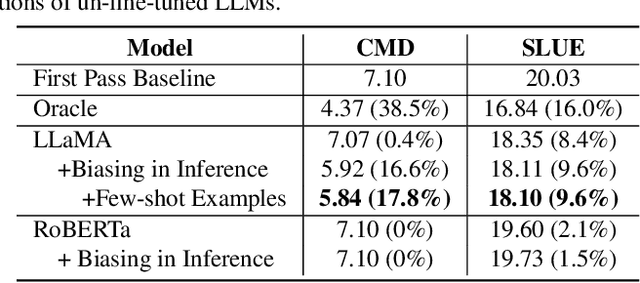
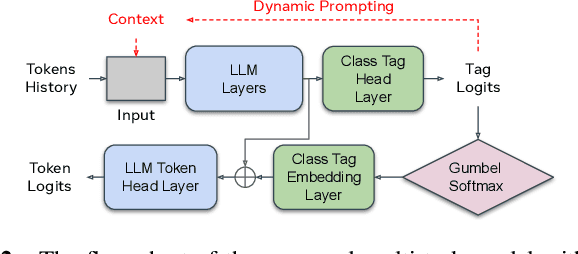
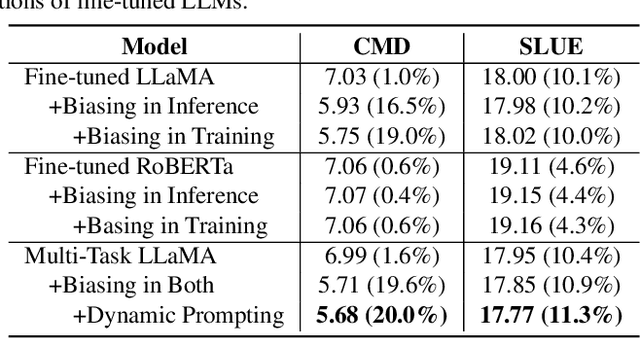
This paper studies contextual biasing with Large Language Models (LLMs), where during second-pass rescoring additional contextual information is provided to a LLM to boost Automatic Speech Recognition (ASR) performance. We propose to leverage prompts for a LLM without fine tuning during rescoring which incorporate a biasing list and few-shot examples to serve as additional information when calculating the score for the hypothesis. In addition to few-shot prompt learning, we propose multi-task training of the LLM to predict both the entity class and the next token. To improve the efficiency for contextual biasing and to avoid exceeding LLMs' maximum sequence lengths, we propose dynamic prompting, where we select the most likely class using the class tag prediction, and only use entities in this class as contexts for next token prediction. Word Error Rate (WER) evaluation is performed on i) an internal calling, messaging, and dictation dataset, and ii) the SLUE-Voxpopuli dataset. Results indicate that biasing lists and few-shot examples can achieve 17.8% and 9.6% relative improvement compared to first pass ASR, and that multi-task training and dynamic prompting can achieve 20.0% and 11.3% relative WER improvement, respectively.
Deep Segmented DMP Networks for Learning Discontinuous Motions
Sep 01, 2023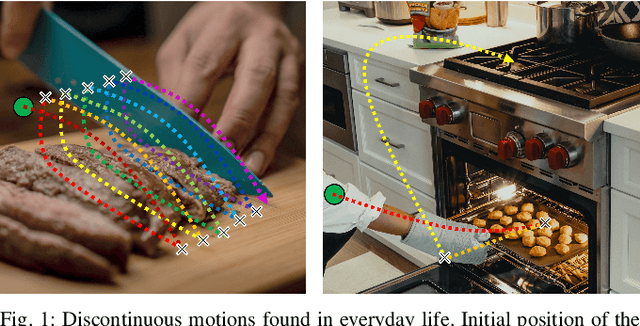
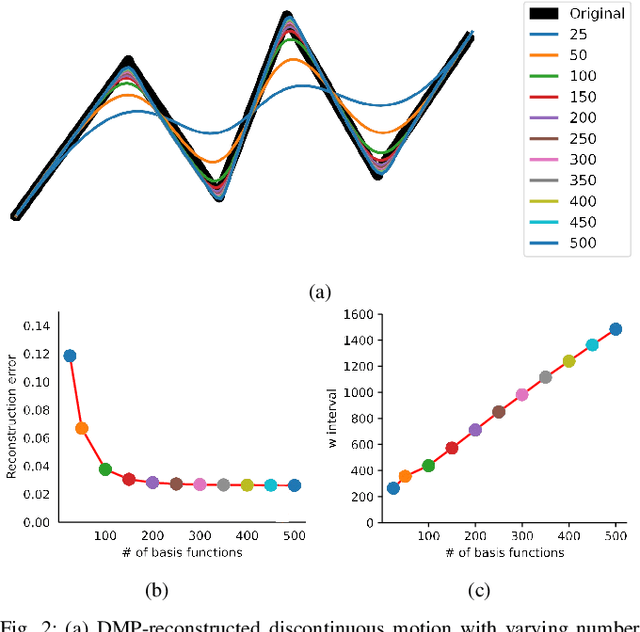
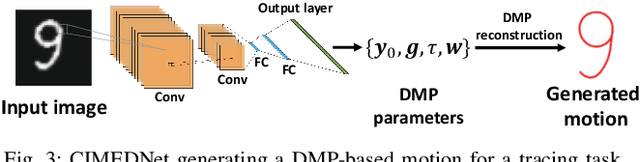
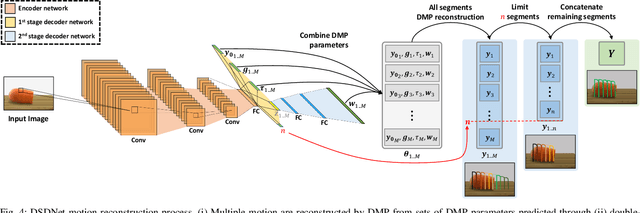
Discontinuous motion which is a motion composed of multiple continuous motions with sudden change in direction or velocity in between, can be seen in state-aware robotic tasks. Such robotic tasks are often coordinated with sensor information such as image. In recent years, Dynamic Movement Primitives (DMP) which is a method for generating motor behaviors suitable for robotics has garnered several deep learning based improvements to allow associations between sensor information and DMP parameters. While the implementation of deep learning framework does improve upon DMP's inability to directly associate to an input, we found that it has difficulty learning DMP parameters for complex motion which requires large number of basis functions to reconstruct. In this paper we propose a novel deep learning network architecture called Deep Segmented DMP Network (DSDNet) which generates variable-length segmented motion by utilizing the combination of multiple DMP parameters predicting network architecture, double-stage decoder network, and number of segments predictor. The proposed method is evaluated on both artificial data (object cutting & pick-and-place) and real data (object cutting) where our proposed method could achieve high generalization capability, task-achievement, and data-efficiency compared to previous method on generating discontinuous long-horizon motions.
Improving Neural Ranking Models with Traditional IR Methods
Aug 29, 2023Neural ranking methods based on large transformer models have recently gained significant attention in the information retrieval community, and have been adopted by major commercial solutions. Nevertheless, they are computationally expensive to create, and require a great deal of labeled data for specialized corpora. In this paper, we explore a low resource alternative which is a bag-of-embedding model for document retrieval and find that it is competitive with large transformer models fine tuned on information retrieval tasks. Our results show that a simple combination of TF-IDF, a traditional keyword matching method, with a shallow embedding model provides a low cost path to compete well with the performance of complex neural ranking models on 3 datasets. Furthermore, adding TF-IDF measures improves the performance of large-scale fine tuned models on these tasks.
Do You Trust ChatGPT? -- Perceived Credibility of Human and AI-Generated Content
Sep 05, 2023This paper examines how individuals perceive the credibility of content originating from human authors versus content generated by large language models, like the GPT language model family that powers ChatGPT, in different user interface versions. Surprisingly, our results demonstrate that regardless of the user interface presentation, participants tend to attribute similar levels of credibility. While participants also do not report any different perceptions of competence and trustworthiness between human and AI-generated content, they rate AI-generated content as being clearer and more engaging. The findings from this study serve as a call for a more discerning approach to evaluating information sources, encouraging users to exercise caution and critical thinking when engaging with content generated by AI systems.
An Improved Upper Bound on the Rate-Distortion Function of Images
Sep 05, 2023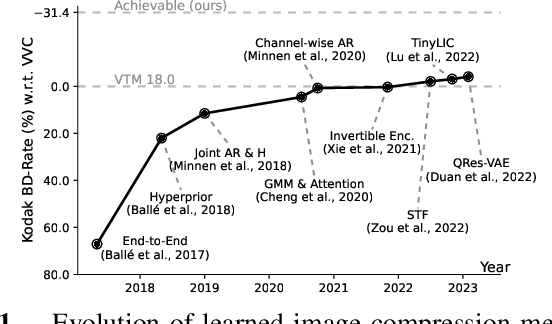

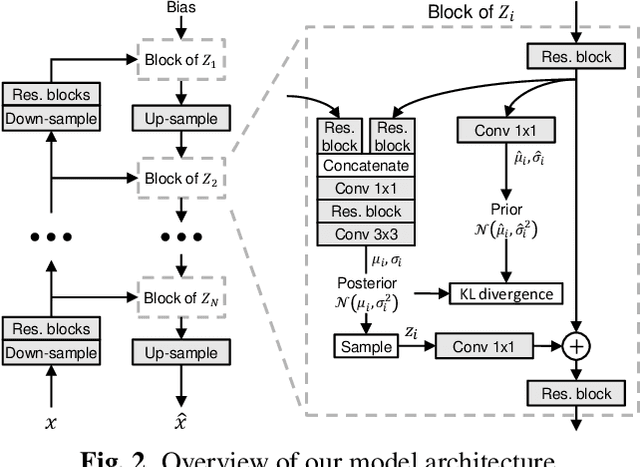
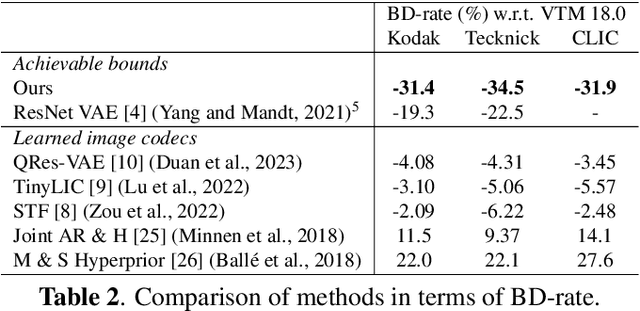
Recent work has shown that Variational Autoencoders (VAEs) can be used to upper-bound the information rate-distortion (R-D) function of images, i.e., the fundamental limit of lossy image compression. In this paper, we report an improved upper bound on the R-D function of images implemented by (1) introducing a new VAE model architecture, (2) applying variable-rate compression techniques, and (3) proposing a novel \ourfunction{} to stabilize training. We demonstrate that at least 30\% BD-rate reduction w.r.t. the intra prediction mode in VVC codec is achievable, suggesting that there is still great potential for improving lossy image compression. Code is made publicly available at https://github.com/duanzhiihao/lossy-vae.
Improving Query-Focused Meeting Summarization with Query-Relevant Knowledge
Sep 05, 2023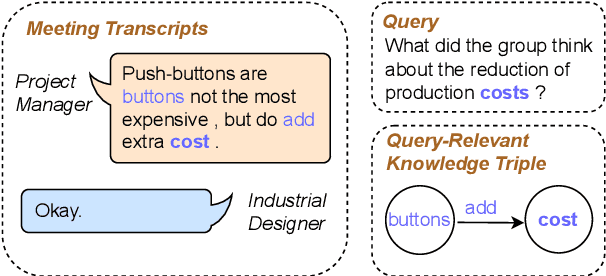
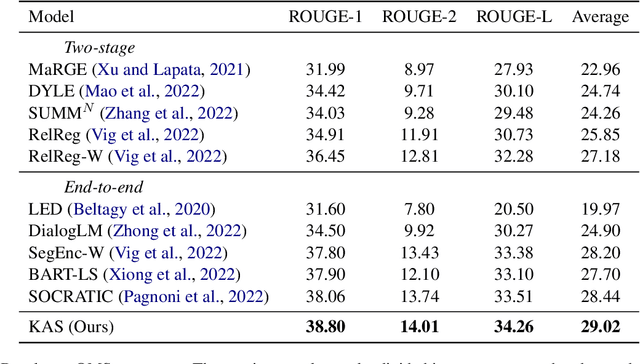
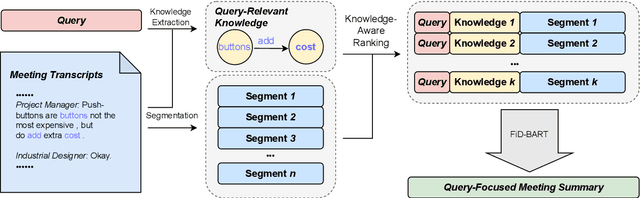

Query-Focused Meeting Summarization (QFMS) aims to generate a summary of a given meeting transcript conditioned upon a query. The main challenges for QFMS are the long input text length and sparse query-relevant information in the meeting transcript. In this paper, we propose a knowledge-enhanced two-stage framework called Knowledge-Aware Summarizer (KAS) to tackle the challenges. In the first stage, we introduce knowledge-aware scores to improve the query-relevant segment extraction. In the second stage, we incorporate query-relevant knowledge in the summary generation. Experimental results on the QMSum dataset show that our approach achieves state-of-the-art performance. Further analysis proves the competency of our methods in generating relevant and faithful summaries.
Dual-path Transformer Based Neural Beamformer for Target Speech Extraction
Sep 07, 2023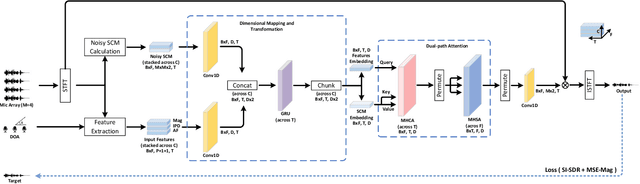
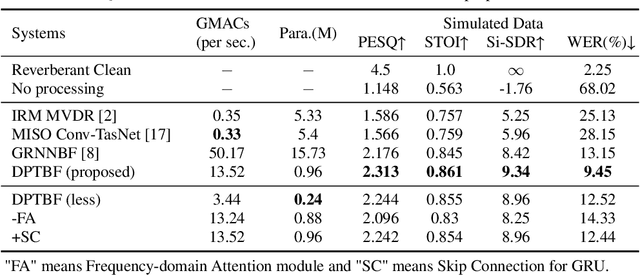
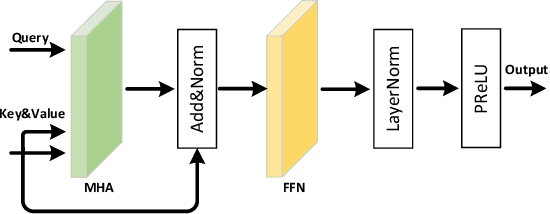
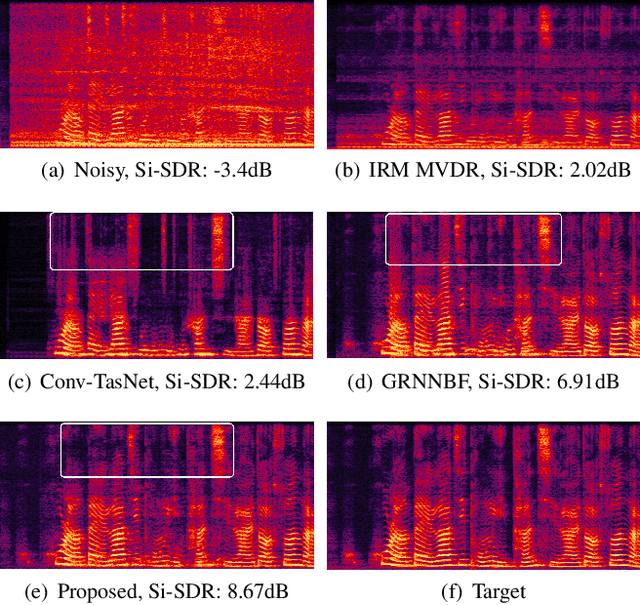
Neural beamformers, which integrate both pre-separation and beamforming modules, have demonstrated impressive effectiveness in target speech extraction. Nevertheless, the performance of these beamformers is inherently limited by the predictive accuracy of the pre-separation module. In this paper, we introduce a neural beamformer supported by a dual-path transformer. Initially, we employ the cross-attention mechanism in the time domain to extract crucial spatial information related to beamforming from the noisy covariance matrix. Subsequently, in the frequency domain, the self-attention mechanism is employed to enhance the model's ability to process frequency-specific details. By design, our model circumvents the influence of pre-separation modules, delivering performance in a more comprehensive end-to-end manner. Experimental results reveal that our model not only outperforms contemporary leading neural beamforming algorithms in separation performance but also achieves this with a significant reduction in parameter count.
Multi-agent Coordination Under Temporal Logic Tasks and Team-Wise Intermittent Communication
Sep 06, 2023Multi-agent systems outperform single agent in complex collaborative tasks. However, in large-scale scenarios, ensuring timely information exchange during decentralized task execution remains a challenge. This work presents an online decentralized coordination scheme for multi-agent systems under complex local tasks and intermittent communication constraints. Unlike existing strategies that enforce all-time or intermittent connectivity, our approach allows agents to join or leave communication networks at aperiodic intervals, as deemed optimal by their online task execution. This scheme concurrently determines local plans and refines the communication strategy, i.e., where and when to communicate as a team. A decentralized potential game is modeled among agents, for which a Nash equilibrium is generated iteratively through online local search. It guarantees local task completion and intermittent communication constraints. Extensive numerical simulations are conducted against several strong baselines.
Large Language Models on Wikipedia-Style Survey Generation: an Evaluation in NLP Concepts
Sep 06, 2023
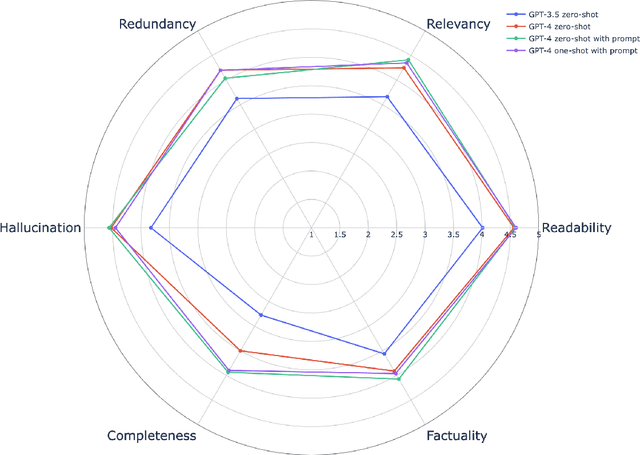

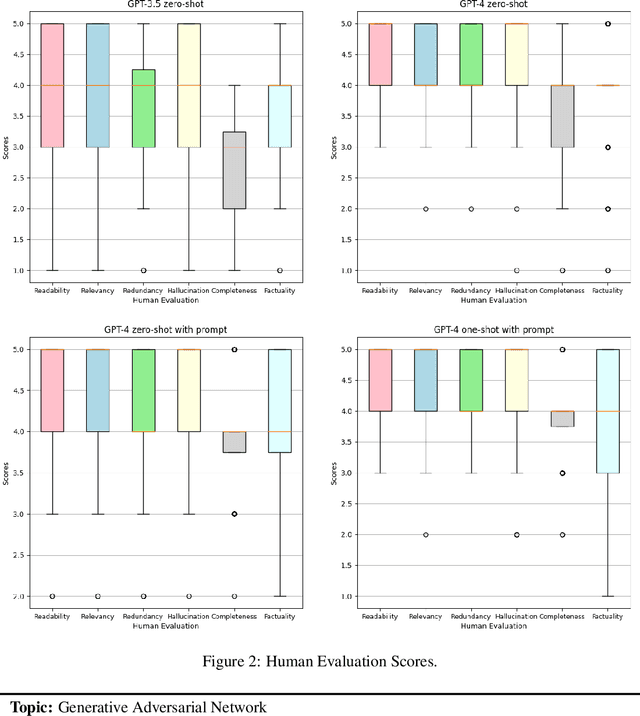
Large Language Models (LLMs) have achieved significant success across various natural language processing (NLP) tasks, encompassing question-answering, summarization, and machine translation, among others. While LLMs excel in general tasks, their efficacy in domain-specific applications remains under exploration. Additionally, LLM-generated text sometimes exhibits issues like hallucination and disinformation. In this study, we assess LLMs' capability of producing concise survey articles within the computer science-NLP domain, focusing on 20 chosen topics. Automated evaluations indicate that GPT-4 outperforms GPT-3.5 when benchmarked against the ground truth. Furthermore, four human evaluators provide insights from six perspectives across four model configurations. Through case studies, we demonstrate that while GPT often yields commendable results, there are instances of shortcomings, such as incomplete information and the exhibition of lapses in factual accuracy.
Graph Theory Applications in Advanced Geospatial Research
Sep 06, 2023Geospatial sciences include a wide range of applications, from environmental monitoring transportation to infrastructure planning, as well as location-based analysis and services. Graph theory algorithms in mathematics have emerged as indispensable tools in these domains due to their capability to model and analyse spatial relationships efficiently. This technical report explores the applications of graph theory algorithms in geospatial sciences, highlighting their role in network analysis, spatial connectivity, geographic information systems, and various other spatial problem-solving scenarios. It provides a comprehensive idea about the key concepts and algorithms of graph theory that assist the modelling processes. The report provides insights into the practical significance of graph theory in addressing real-world geospatial challenges and opportunities. It lists the extensive research, innovative technologies and methodologies implemented in this field.