 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-Agent Deep Reinforcement Learning for Cooperative and Competitive Autonomous Vehicles using AutoDRIVE Ecosystem
Sep 18, 2023
This work presents a modular and parallelizable multi-agent deep reinforcement learning framework for imbibing cooperative as well as competitive behaviors within autonomous vehicles. We introduce AutoDRIVE Ecosystem as an enabler to develop physically accurate and graphically realistic digital twins of Nigel and F1TENTH, two scaled autonomous vehicle platforms with unique qualities and capabilities, and leverage this ecosystem to train and deploy multi-agent reinforcement learning policies. We first investigate an intersection traversal problem using a set of cooperative vehicles (Nigel) that share limited state information with each other in single as well as multi-agent learning settings using a common policy approach. We then investigate an adversarial head-to-head autonomous racing problem using a different set of vehicles (F1TENTH) in a multi-agent learning setting using an individual policy approach. In either set of experiments, a decentralized learning architecture was adopted, which allowed robust training and testing of the approaches in stochastic environments, since the agents were mutually independent and exhibited asynchronous motion behavior. The problems were further aggravated by providing the agents with sparse observation spaces and requiring them to sample control commands that implicitly satisfied the imposed kinodynamic as well as safety constraints. The experimental results for both problem statements are reported in terms of quantitative metrics and qualitative remarks for training as well as deployment phases.
Co-evolving Vector Quantization for ID-based Recommendation
Sep 02, 2023Category information plays a crucial role in enhancing the quality and personalization of recommendations. Nevertheless, the availability of item category information is not consistently present, particularly in the context of ID-based recommendations. In this work, we propose an alternative approach to automatically learn and generate entity (i.e., user and item) categorical information at different levels of granularity, specifically for ID-based recommendation. Specifically, we devise a co-evolving vector quantization framework, namely COVE, which enables the simultaneous learning and refinement of code representation and entity embedding in an end-to-end manner, starting from the randomly initialized states. With its high adaptability, COVE can be easily integrated into existing recommendation models. We validate the effectiveness of COVE on various recommendation tasks including list completion, collaborative filtering, and click-through rate prediction, across different recommendation models. We will publish the code and data for other researchers to reproduce our work.
Grid-based Hybrid 3DMA GNSS and Terrestrial Positioning
Sep 11, 2023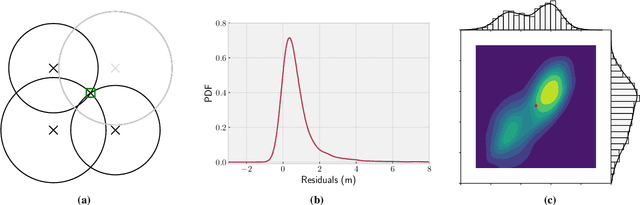

The paper discusses the increasing use of hybridized sensor information for GNSS-based localization and navigation, including the use of 3D map-aided GNSS positioning and terrestrial systems based on different geometric measurement principles. However, both GNSS and terrestrial systems are subject to negative impacts from the propagation environment, which can violate the assumptions of conventionally applied parametric state estimators. Furthermore, dynamic parametric state estimation does not account for multi-modalities within the state space leading to an information loss within the prediction step. In addition, the synchronization of non-deterministic multi-rate measurement systems needs to be accounted. In order to address these challenges, the paper proposes the use of a non-parametric filtering method, specifically a 3DMA multi-epoch Grid Filter, for the tight integration of GNSS and terrestrial signals. Specifically, the fusion of GNSS, Ultra-wide Band (UWB) and vehicle motion data is introduced based on a discrete state representation. Algorithmic challenges, including the use of different measurement models and time synchronization, are addressed. In order to evaluate the proposed method, real-world tests were conducted on an urban automotive testbed in both static and dynamic scenarios. We empirically show that we achieve sub-meter accuracy in the static scenario by averaging a positioning error of $0.64$ m, whereas in the dynamic scenario the average positioning error amounts to $1.62$ m. The paper provides a proof-of-concept of the introduced method and shows the feasibility of the inclusion of terrestrial signals in a 3DMA positioning framework in order to further enhance localization in GNSS-degraded environments.
Practical Homomorphic Aggregation for Byzantine ML
Sep 11, 2023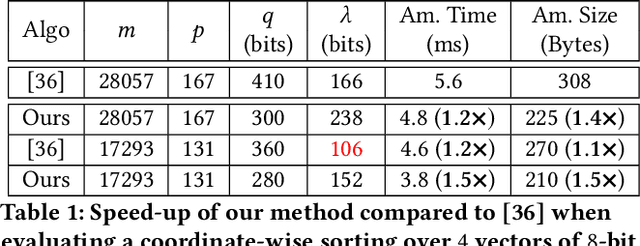
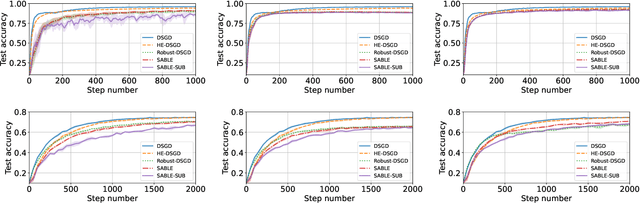
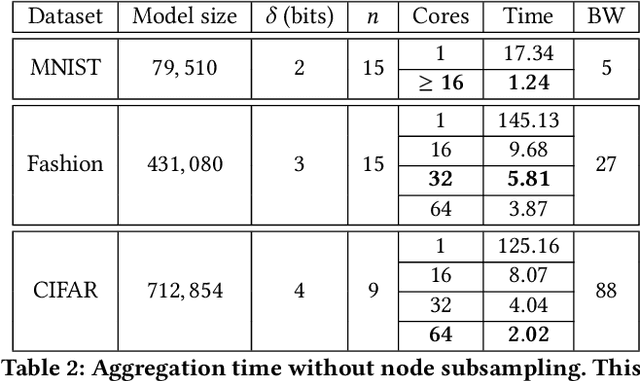
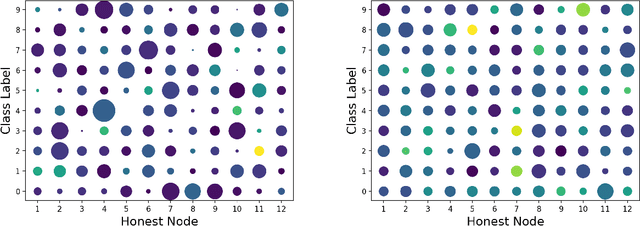
Due to the large-scale availability of data, machine learning (ML) algorithms are being deployed in distributed topologies, where different nodes collaborate to train ML models over their individual data by exchanging model-related information (e.g., gradients) with a central server. However, distributed learning schemes are notably vulnerable to two threats. First, Byzantine nodes can single-handedly corrupt the learning by sending incorrect information to the server, e.g., erroneous gradients. The standard approach to mitigate such behavior is to use a non-linear robust aggregation method at the server. Second, the server can violate the privacy of the nodes. Recent attacks have shown that exchanging (unencrypted) gradients enables a curious server to recover the totality of the nodes' data. The use of homomorphic encryption (HE), a gold standard security primitive, has extensively been studied as a privacy-preserving solution to distributed learning in non-Byzantine scenarios. However, due to HE's large computational demand especially for high-dimensional ML models, there has not yet been any attempt to design purely homomorphic operators for non-linear robust aggregators. In this work, we present SABLE, the first completely homomorphic and Byzantine robust distributed learning algorithm. SABLE essentially relies on a novel plaintext encoding method that enables us to implement the robust aggregator over batching-friendly BGV. Moreover, this encoding scheme also accelerates state-of-the-art homomorphic sorting with larger security margins and smaller ciphertext size. We perform extensive experiments on image classification tasks and show that our algorithm achieves practical execution times while matching the ML performance of its non-private counterpart.
Task-Based MoE for Multitask Multilingual Machine Translation
Sep 11, 2023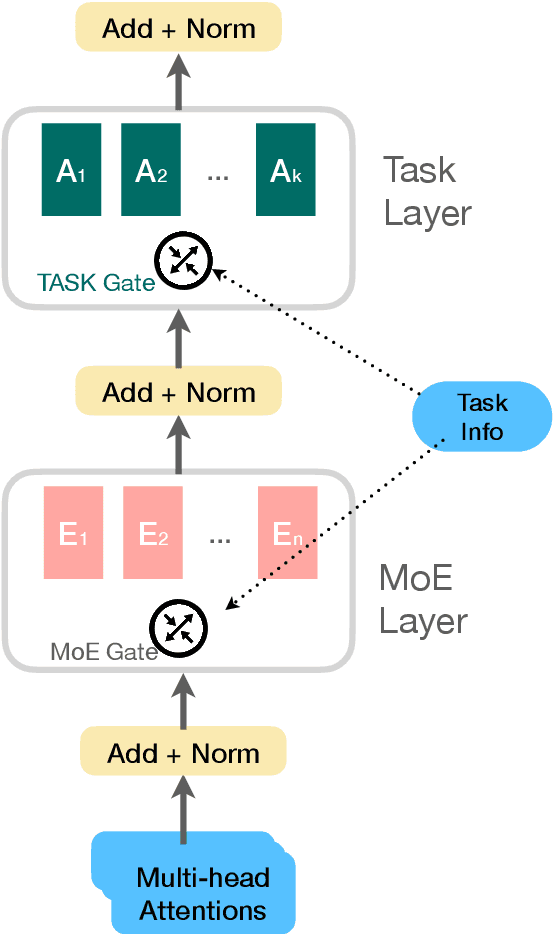
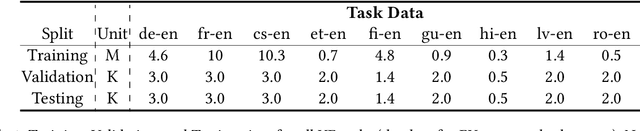
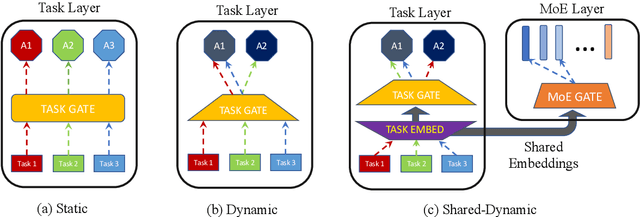
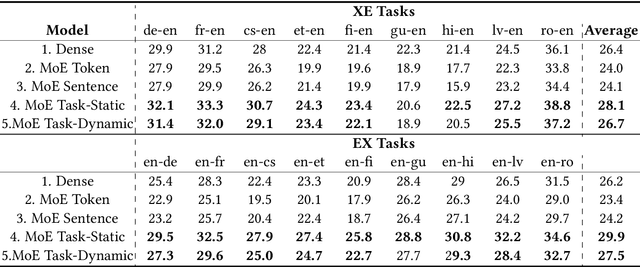
Mixture-of-experts (MoE) architecture has been proven a powerful method for diverse tasks in training deep models in many applications. However, current MoE implementations are task agnostic, treating all tokens from different tasks in the same manner. In this work, we instead design a novel method that incorporates task information into MoE models at different granular levels with shared dynamic task-based adapters. Our experiments and analysis show the advantages of our approaches over the dense and canonical MoE models on multi-task multilingual machine translations. With task-specific adapters, our models can additionally generalize to new tasks efficiently.
RUEL: Retrieval-Augmented User Representation with Edge Browser Logs for Sequential Recommendation
Sep 19, 2023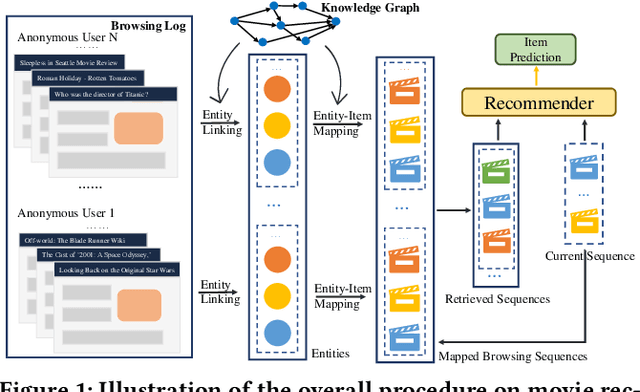
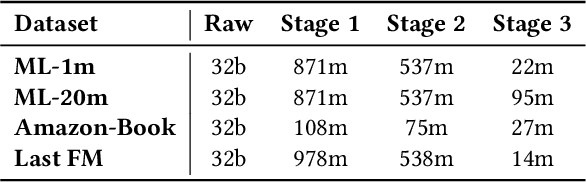
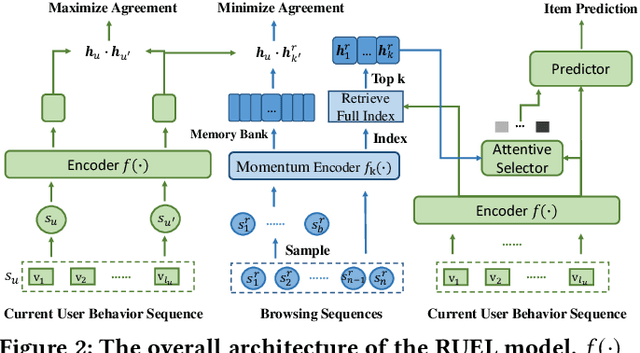
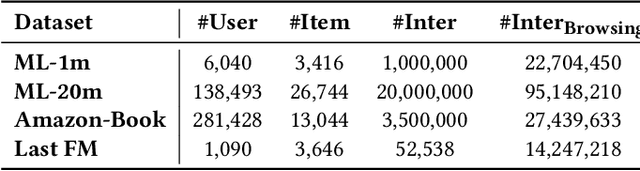
Online recommender systems (RS) aim to match user needs with the vast amount of resources available on various platforms. A key challenge is to model user preferences accurately under the condition of data sparsity. To address this challenge, some methods have leveraged external user behavior data from multiple platforms to enrich user representation. However, all of these methods require a consistent user ID across platforms and ignore the information from similar users. In this study, we propose RUEL, a novel retrieval-based sequential recommender that can effectively incorporate external anonymous user behavior data from Edge browser logs to enhance recommendation. We first collect and preprocess a large volume of Edge browser logs over a one-year period and link them to target entities that correspond to candidate items in recommendation datasets. We then design a contrastive learning framework with a momentum encoder and a memory bank to retrieve the most relevant and diverse browsing sequences from the full browsing log based on the semantic similarity between user representations. After retrieval, we apply an item-level attentive selector to filter out noisy items and generate refined sequence embeddings for the final predictor. RUEL is the first method that connects user browsing data with typical recommendation datasets and can be generalized to various recommendation scenarios and datasets. We conduct extensive experiments on four real datasets for sequential recommendation tasks and demonstrate that RUEL significantly outperforms state-of-the-art baselines. We also conduct ablation studies and qualitative analysis to validate the effectiveness of each component of RUEL and provide additional insights into our method.
Harnessing Collective Intelligence Under a Lack of Cultural Consensus
Sep 19, 2023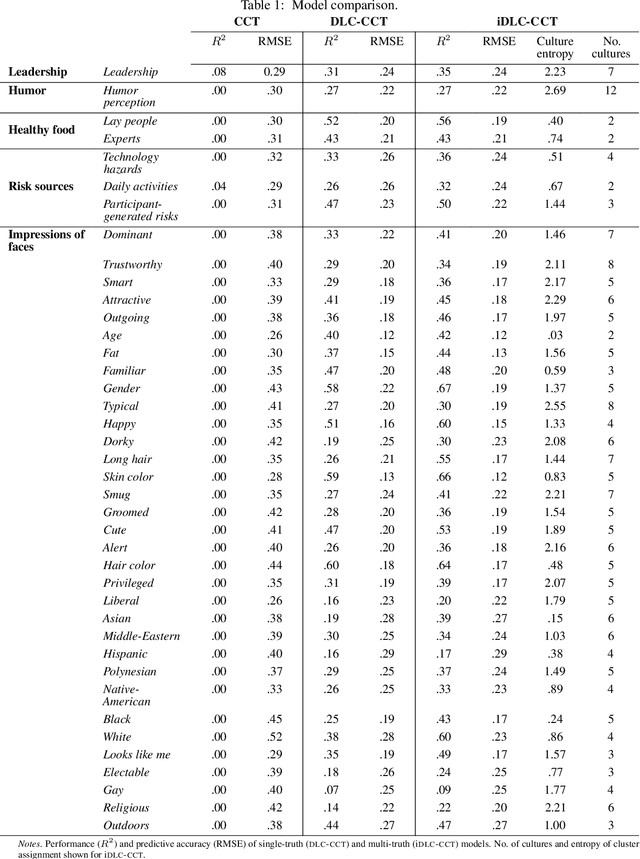
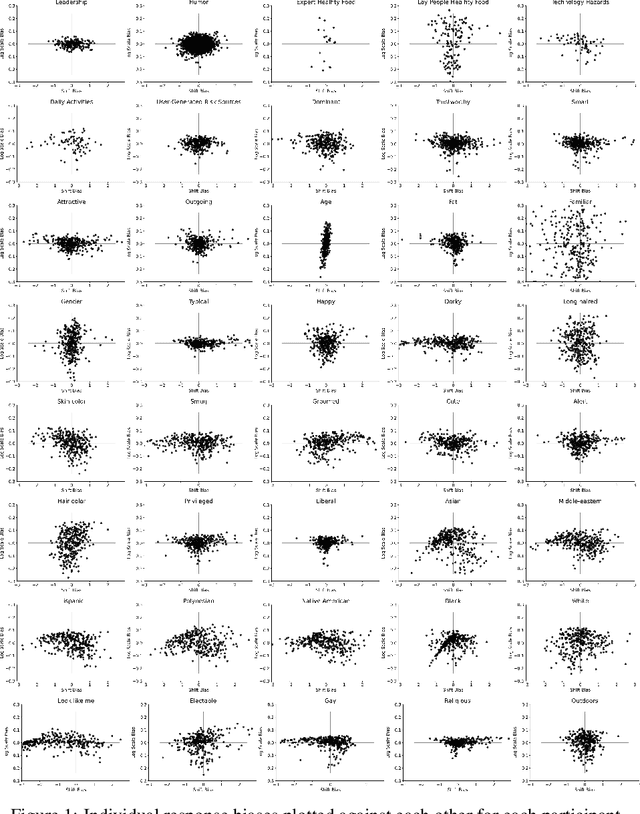
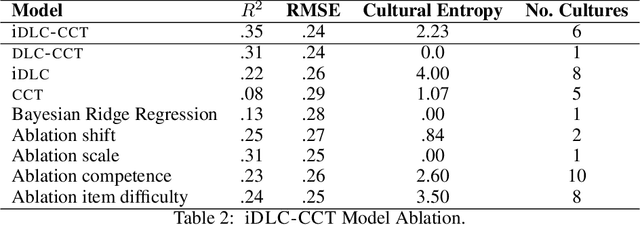
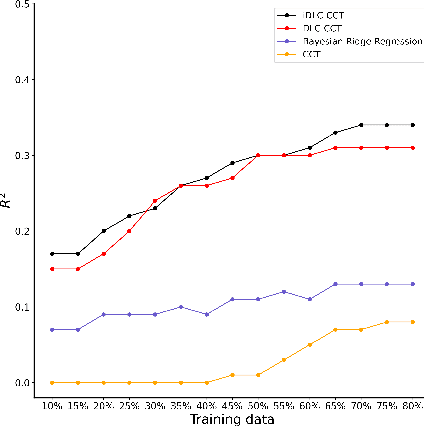
Harnessing collective intelligence to drive effective decision-making and collaboration benefits from the ability to detect and characterize heterogeneity in consensus beliefs. This is particularly true in domains such as technology acceptance or leadership perception, where a consensus defines an intersubjective truth, leading to the possibility of multiple "ground truths" when subsets of respondents sustain mutually incompatible consensuses. Cultural Consensus Theory (CCT) provides a statistical framework for detecting and characterizing these divergent consensus beliefs. However, it is unworkable in modern applications because it lacks the ability to generalize across even highly similar beliefs, is ineffective with sparse data, and can leverage neither external knowledge bases nor learned machine representations. Here, we overcome these limitations through Infinite Deep Latent Construct Cultural Consensus Theory (iDLC-CCT), a nonparametric Bayesian model that extends CCT with a latent construct that maps between pretrained deep neural network embeddings of entities and the consensus beliefs regarding those entities among one or more subsets of respondents. We validate the method across domains including perceptions of risk sources, food healthiness, leadership, first impressions, and humor. We find that iDLC-CCT better predicts the degree of consensus, generalizes well to out-of-sample entities, and is effective even with sparse data. To improve scalability, we introduce an efficient hard-clustering variant of the iDLC-CCT using an algorithm derived from a small-variance asymptotic analysis of the model. The iDLC-CCT, therefore, provides a workable computational foundation for harnessing collective intelligence under a lack of cultural consensus and may potentially form the basis of consensus-aware information technologies.
Robust Visual Tracking by Motion Analyzing
Sep 06, 2023
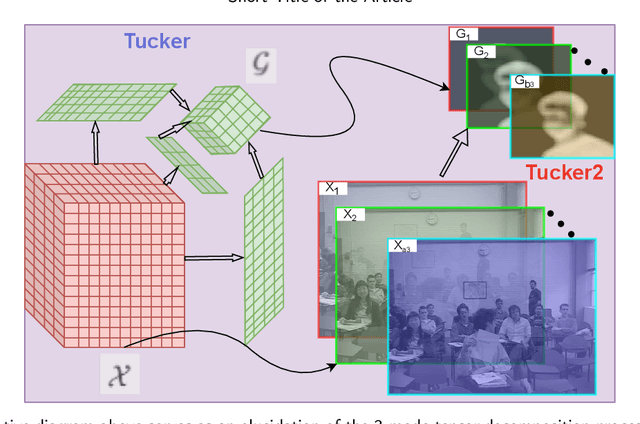
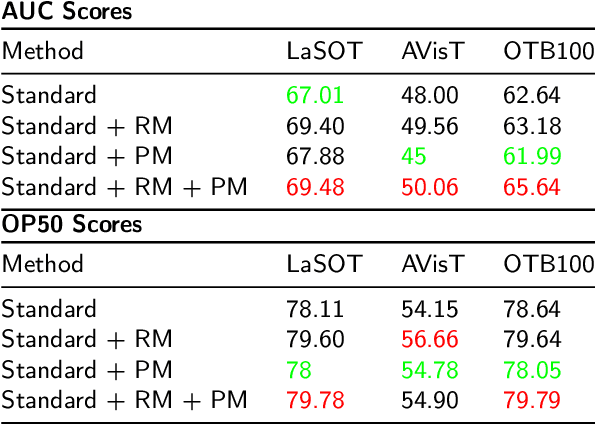
In recent years, Video Object Segmentation (VOS) has emerged as a complementary method to Video Object Tracking (VOT). VOS focuses on classifying all the pixels around the target, allowing for precise shape labeling, while VOT primarily focuses on the approximate region where the target might be. However, traditional segmentation modules usually classify pixels frame by frame, disregarding information between adjacent frames. In this paper, we propose a new algorithm that addresses this limitation by analyzing the motion pattern using the inherent tensor structure. The tensor structure, obtained through Tucker2 tensor decomposition, proves to be effective in describing the target's motion. By incorporating this information, we achieved competitive results on Four benchmarks LaSOT\cite{fan2019lasot}, AVisT\cite{noman2022avist}, OTB100\cite{7001050}, and GOT-10k\cite{huang2019got} LaSOT\cite{fan2019lasot} with SOTA. Furthermore, the proposed tracker is capable of real-time operation, adding value to its practical application.
Intelligence as a Measure of Consciousness
Sep 06, 2023Evaluating artificial systems for signs of consciousness is increasingly becoming a pressing concern, and a rigorous psychometric measurement framework may be of crucial importance in evaluating large language models in this regard. Most prominent theories of consciousness, both scientific and metaphysical, argue for different kinds of information coupling as a necessary component of human-like consciousness. By comparing information coupling in human and animal brains, human cognitive development, emergent abilities, and mental representation development to analogous phenomena in large language models, I argue that psychometric measures of intelligence, such as the g-factor or IQ, indirectly approximate the extent of conscious experience. Based on a broader source of both scientific and metaphysical theories of consciousness, I argue that all systems possess a degree of consciousness ascertainable psychometrically and that psychometric measures of intelligence may be used to gauge relative similarities of conscious experiences across disparate systems, be they artificial or human.
PromptVC: Flexible Stylistic Voice Conversion in Latent Space Driven by Natural Language Prompts
Sep 17, 2023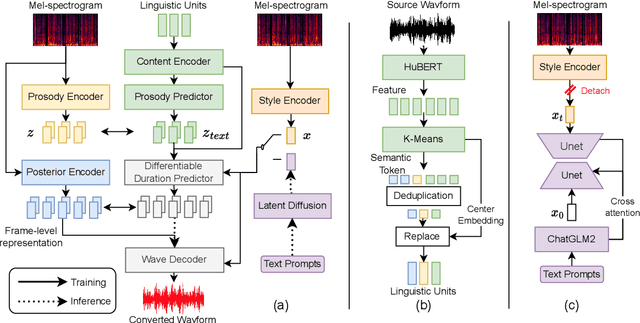

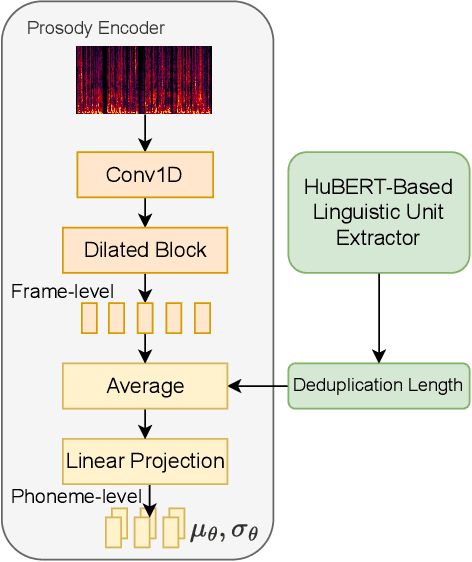
Style voice conversion aims to transform the style of source speech to a desired style according to real-world application demands. However, the current style voice conversion approach relies on pre-defined labels or reference speech to control the conversion process, which leads to limitations in style diversity or falls short in terms of the intuitive and interpretability of style representation. In this study, we propose PromptVC, a novel style voice conversion approach that employs a latent diffusion model to generate a style vector driven by natural language prompts. Specifically, the style vector is extracted by a style encoder during training, and then the latent diffusion model is trained independently to sample the style vector from noise, with this process being conditioned on natural language prompts. To improve style expressiveness, we leverage HuBERT to extract discrete tokens and replace them with the K-Means center embedding to serve as the linguistic content, which minimizes residual style information. Additionally, we deduplicate the same discrete token and employ a differentiable duration predictor to re-predict the duration of each token, which can adapt the duration of the same linguistic content to different styles. The subjective and objective evaluation results demonstrate the effectiveness of our proposed system.