 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Cure the headache of Transformers via Collinear Constrained Attention
Sep 15, 2023
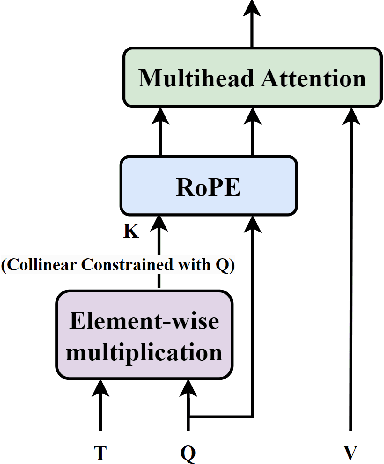
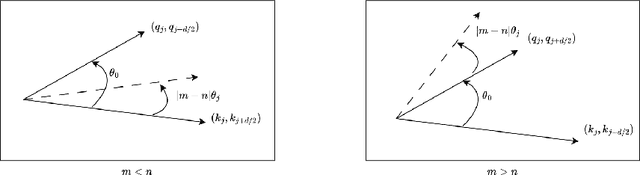
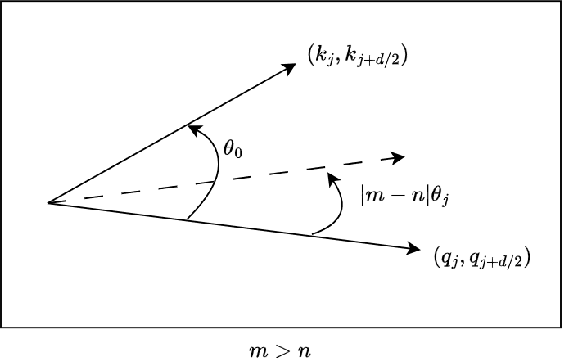

As the rapid progression of practical applications based on Large Language Models continues, the importance of extrapolating performance has grown exponentially in the research domain. In our study, we identified an anomalous behavior in Transformer models that had been previously overlooked, leading to a chaos around closest tokens which carried the most important information. We've coined this discovery the "headache of Transformers". To address this at its core, we introduced a novel self-attention structure named Collinear Constrained Attention (CoCA). This structure can be seamlessly integrated with existing extrapolation, interpolation methods, and other optimization strategies designed for traditional Transformer models. We have achieved excellent extrapolating performance even for 16 times to 24 times of sequence lengths during inference without any fine-tuning on our model. We have also enhanced CoCA's computational and spatial efficiency to ensure its practicality. We plan to open-source CoCA shortly. In the meantime, we've made our code available in the appendix for reappearing experiments.
Product Information Extraction using ChatGPT
Jun 23, 2023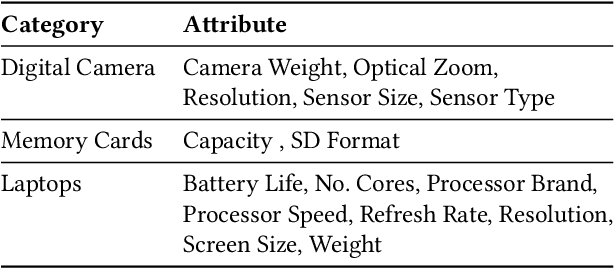
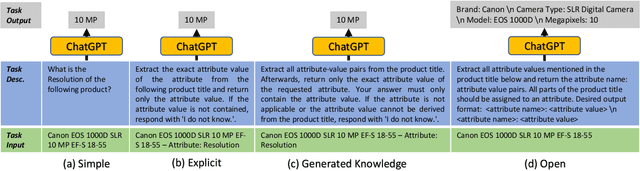
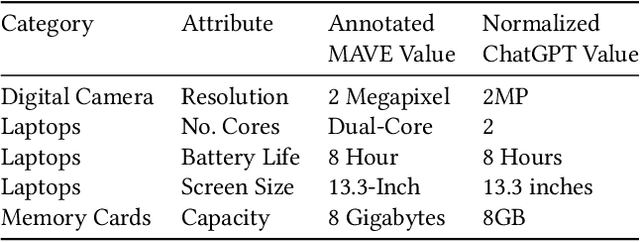
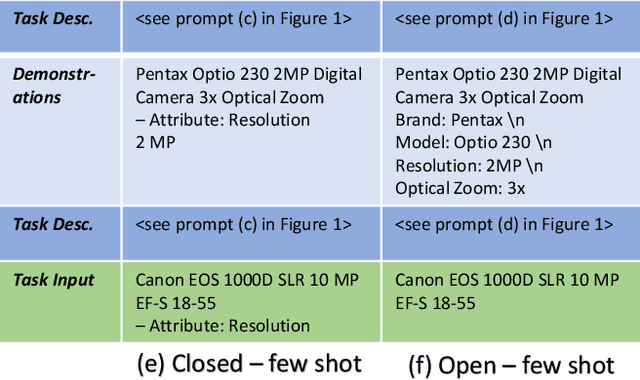
Structured product data in the form of attribute/value pairs is the foundation of many e-commerce applications such as faceted product search, product comparison, and product recommendation. Product offers often only contain textual descriptions of the product attributes in the form of titles or free text. Hence, extracting attribute/value pairs from textual product descriptions is an essential enabler for e-commerce applications. In order to excel, state-of-the-art product information extraction methods require large quantities of task-specific training data. The methods also struggle with generalizing to out-of-distribution attributes and attribute values that were not a part of the training data. Due to being pre-trained on huge amounts of text as well as due to emergent effects resulting from the model size, Large Language Models like ChatGPT have the potential to address both of these shortcomings. This paper explores the potential of ChatGPT for extracting attribute/value pairs from product descriptions. We experiment with different zero-shot and few-shot prompt designs. Our results show that ChatGPT achieves a performance similar to a pre-trained language model but requires much smaller amounts of training data and computation for fine-tuning.
Zero-shot Audio Topic Reranking using Large Language Models
Sep 14, 2023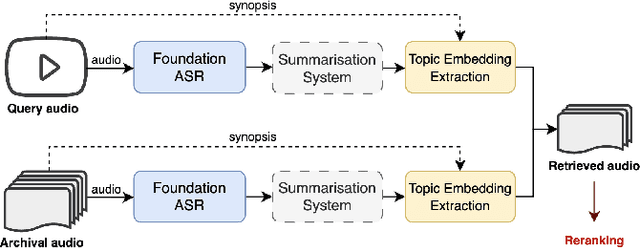
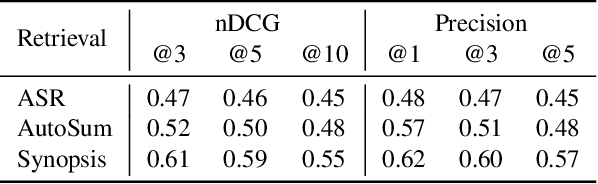
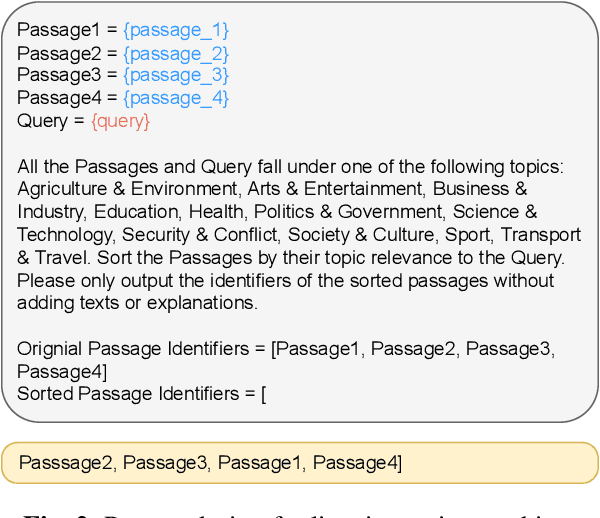
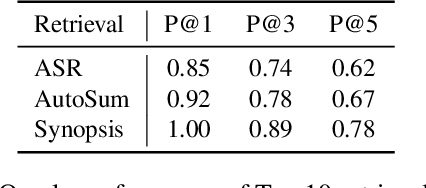
The Multimodal Video Search by Examples (MVSE) project investigates using video clips as the query term for information retrieval, rather than the more traditional text query. This enables far richer search modalities such as images, speaker, content, topic, and emotion. A key element for this process is highly rapid, flexible, search to support large archives, which in MVSE is facilitated by representing video attributes by embeddings. This work aims to mitigate any performance loss from this rapid archive search by examining reranking approaches. In particular, zero-shot reranking methods using large language models are investigated as these are applicable to any video archive audio content. Performance is evaluated for topic-based retrieval on a publicly available video archive, the BBC Rewind corpus. Results demonstrate that reranking can achieve improved retrieval ranking without the need for any task-specific training data.
Multi-Source Domain Adaptation meets Dataset Distillation through Dataset Dictionary Learning
Sep 14, 2023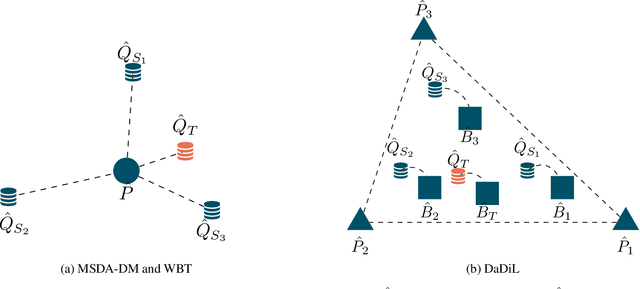
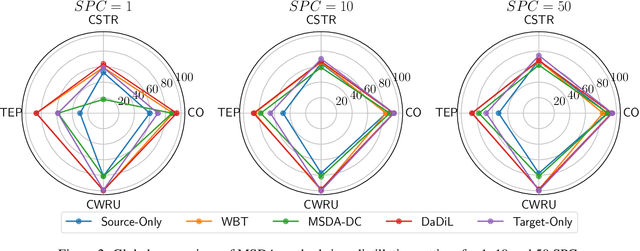
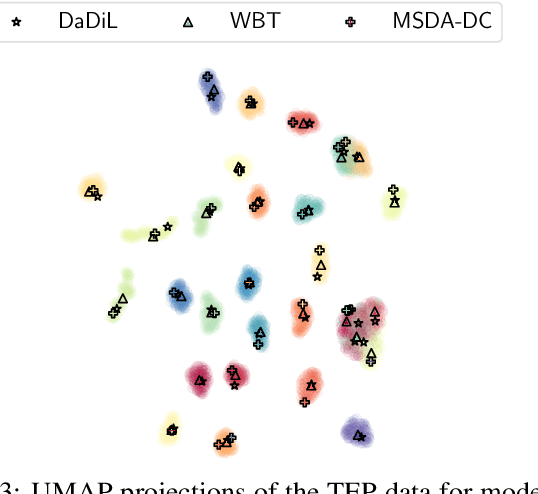
In this paper, we consider the intersection of two problems in machine learning: Multi-Source Domain Adaptation (MSDA) and Dataset Distillation (DD). On the one hand, the first considers adapting multiple heterogeneous labeled source domains to an unlabeled target domain. On the other hand, the second attacks the problem of synthesizing a small summary containing all the information about the datasets. We thus consider a new problem called MSDA-DD. To solve it, we adapt previous works in the MSDA literature, such as Wasserstein Barycenter Transport and Dataset Dictionary Learning, as well as DD method Distribution Matching. We thoroughly experiment with this novel problem on four benchmarks (Caltech-Office 10, Tennessee-Eastman Process, Continuous Stirred Tank Reactor, and Case Western Reserve University), where we show that, even with as little as 1 sample per class, one achieves state-of-the-art adaptation performance.
Connecting the Dots in News Analysis: A Cross-Disciplinary Survey of Media Bias and Framing
Sep 14, 2023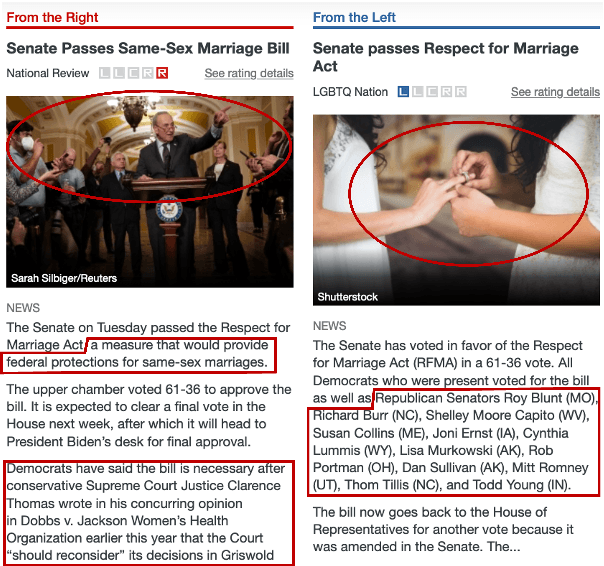
The manifestation and effect of bias in news reporting have been central topics in the social sciences for decades, and have received increasing attention in the NLP community recently. While NLP can help to scale up analyses or contribute automatic procedures to investigate the impact of biased news in society, we argue that methodologies that are currently dominant fall short of addressing the complex questions and effects addressed in theoretical media studies. In this survey paper, we review social science approaches and draw a comparison with typical task formulations, methods, and evaluation metrics used in the analysis of media bias in NLP. We discuss open questions and suggest possible directions to close identified gaps between theory and predictive models, and their evaluation. These include model transparency, considering document-external information, and cross-document reasoning rather than single-label assignment.
CDFSL-V: Cross-Domain Few-Shot Learning for Videos
Sep 07, 2023
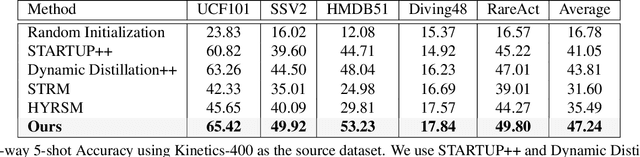
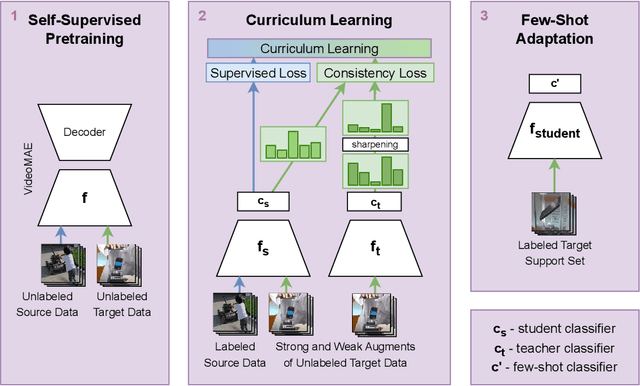

Few-shot video action recognition is an effective approach to recognizing new categories with only a few labeled examples, thereby reducing the challenges associated with collecting and annotating large-scale video datasets. Existing methods in video action recognition rely on large labeled datasets from the same domain. However, this setup is not realistic as novel categories may come from different data domains that may have different spatial and temporal characteristics. This dissimilarity between the source and target domains can pose a significant challenge, rendering traditional few-shot action recognition techniques ineffective. To address this issue, in this work, we propose a novel cross-domain few-shot video action recognition method that leverages self-supervised learning and curriculum learning to balance the information from the source and target domains. To be particular, our method employs a masked autoencoder-based self-supervised training objective to learn from both source and target data in a self-supervised manner. Then a progressive curriculum balances learning the discriminative information from the source dataset with the generic information learned from the target domain. Initially, our curriculum utilizes supervised learning to learn class discriminative features from the source data. As the training progresses, we transition to learning target-domain-specific features. We propose a progressive curriculum to encourage the emergence of rich features in the target domain based on class discriminative supervised features in the source domain. %a schedule that helps with this transition. We evaluate our method on several challenging benchmark datasets and demonstrate that our approach outperforms existing cross-domain few-shot learning techniques. Our code is available at \hyperlink{https://github.com/Sarinda251/CDFSL-V}{https://github.com/Sarinda251/CDFSL-V}
The ParlaSent multilingual training dataset for sentiment identification in parliamentary proceedings
Sep 18, 2023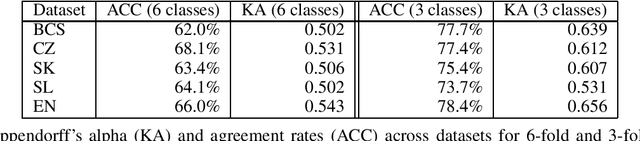
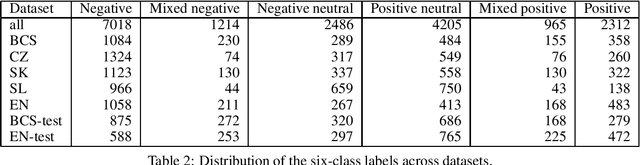
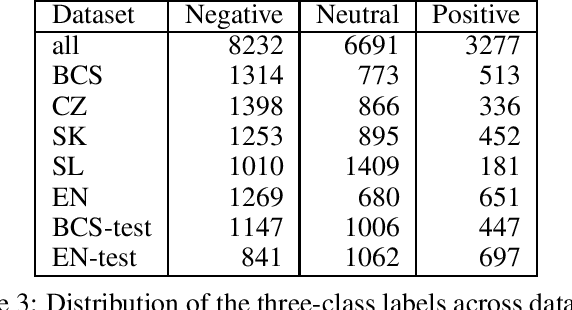
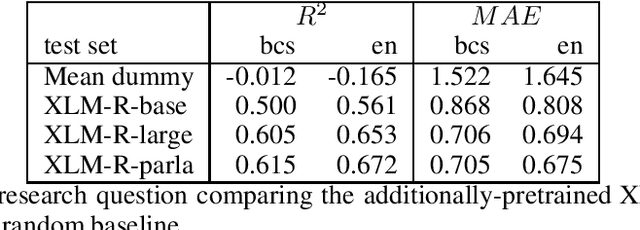
Sentiments inherently drive politics. How we receive and process information plays an essential role in political decision-making, shaping our judgment with strategic consequences both on the level of legislators and the masses. If sentiment plays such an important role in politics, how can we study and measure it systematically? The paper presents a new dataset of sentiment-annotated sentences, which are used in a series of experiments focused on training a robust sentiment classifier for parliamentary proceedings. The paper also introduces the first domain-specific LLM for political science applications additionally pre-trained on 1.72 billion domain-specific words from proceedings of 27 European parliaments. We present experiments demonstrating how the additional pre-training of LLM on parliamentary data can significantly improve the model downstream performance on the domain-specific tasks, in our case, sentiment detection in parliamentary proceedings. We further show that multilingual models perform very well on unseen languages and that additional data from other languages significantly improves the target parliament's results. The paper makes an important contribution to multiple domains of social sciences and bridges them with computer science and computational linguistics. Lastly, it sets up a more robust approach to sentiment analysis of political texts in general, which allows scholars to study political sentiment from a comparative perspective using standardized tools and techniques.
DynaPix SLAM: A Pixel-Based Dynamic SLAM Approach
Sep 18, 2023
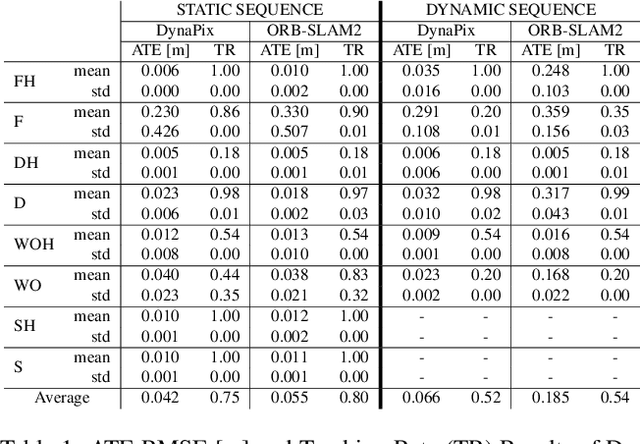
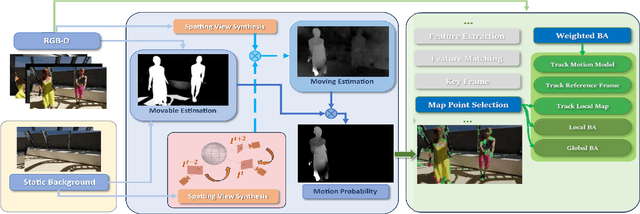
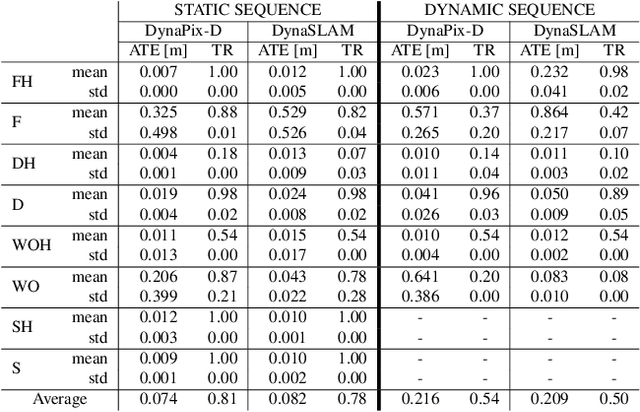
In static environments, visual simultaneous localization and mapping (V-SLAM) methods achieve remarkable performance. However, moving objects severely affect core modules of such systems like state estimation and loop closure detection. To address this, dynamic SLAM approaches often use semantic information, geometric constraints, or optical flow to mask features associated with dynamic entities. These are limited by various factors such as a dependency on the quality of the underlying method, poor generalization to unknown or unexpected moving objects, and often produce noisy results, e.g. by masking static but movable objects or making use of predefined thresholds. In this paper, to address these trade-offs, we introduce a novel visual SLAM system, DynaPix, based on per-pixel motion probability values. Our approach consists of a new semantic-free probabilistic pixel-wise motion estimation module and an improved pose optimization process. Our per-pixel motion probability estimation combines a novel static background differencing method on both images and optical flows from splatted frames. DynaPix fully integrates those motion probabilities into both map point selection and weighted bundle adjustment within the tracking and optimization modules of ORB-SLAM2. We evaluate DynaPix against ORB-SLAM2 and DynaSLAM on both GRADE and TUM-RGBD datasets, obtaining lower errors and longer trajectory tracking times. We will release both source code and data upon acceptance of this work.
PromptST: Prompt-Enhanced Spatio-Temporal Multi-Attribute Prediction
Sep 18, 2023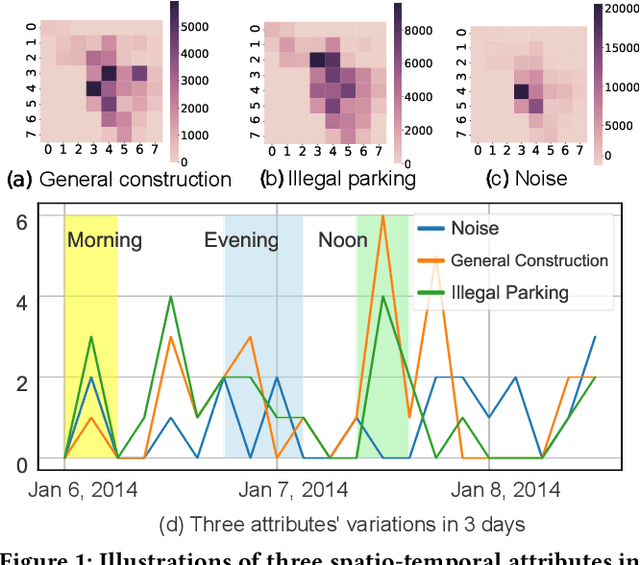
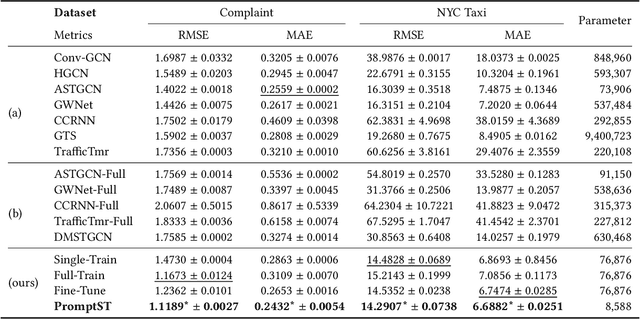
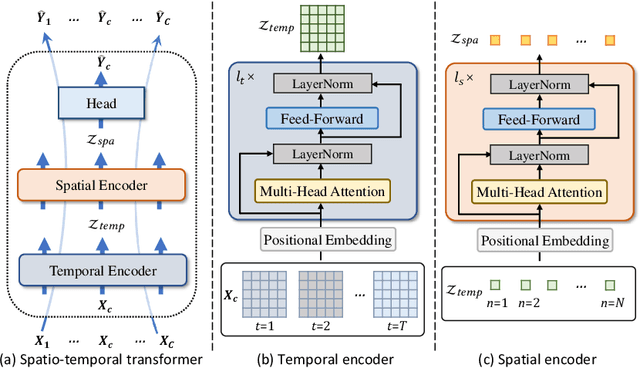
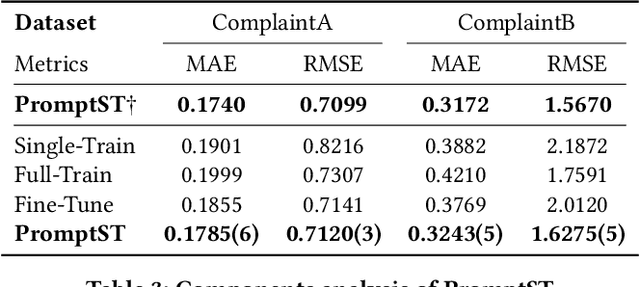
In the era of information explosion, spatio-temporal data mining serves as a critical part of urban management. Considering the various fields demanding attention, e.g., traffic state, human activity, and social event, predicting multiple spatio-temporal attributes simultaneously can alleviate regulatory pressure and foster smart city construction. However, current research can not handle the spatio-temporal multi-attribute prediction well due to the complex relationships between diverse attributes. The key challenge lies in how to address the common spatio-temporal patterns while tackling their distinctions. In this paper, we propose an effective solution for spatio-temporal multi-attribute prediction, PromptST. We devise a spatio-temporal transformer and a parameter-sharing training scheme to address the common knowledge among different spatio-temporal attributes. Then, we elaborate a spatio-temporal prompt tuning strategy to fit the specific attributes in a lightweight manner. Through the pretrain and prompt tuning phases, our PromptST is able to enhance the specific spatio-temoral characteristic capture by prompting the backbone model to fit the specific target attribute while maintaining the learned common knowledge. Extensive experiments on real-world datasets verify that our PromptST attains state-of-the-art performance. Furthermore, we also prove PromptST owns good transferability on unseen spatio-temporal attributes, which brings promising application potential in urban computing. The implementation code is available to ease reproducibility.
A Schedule of Duties in the Cloud Space Using a Modified Salp Swarm Algorithm
Sep 18, 2023



Cloud computing is a concept introduced in the information technology era, with the main components being the grid, distributed, and valuable computing. The cloud is being developed continuously and, naturally, comes up with many challenges, one of which is scheduling. A schedule or timeline is a mechanism used to optimize the time for performing a duty or set of duties. A scheduling process is accountable for choosing the best resources for performing a duty. The main goal of a scheduling algorithm is to improve the efficiency and quality of the service while at the same time ensuring the acceptability and effectiveness of the targets. The task scheduling problem is one of the most important NP-hard issues in the cloud domain and, so far, many techniques have been proposed as solutions, including using genetic algorithms (GAs), particle swarm optimization, (PSO), and ant colony optimization (ACO). To address this problem, in this paper, one of the collective intelligence algorithms, called the Salp Swarm Algorithm (SSA), has been expanded, improved, and applied. The performance of the proposed algorithm has been compared with that of GAs, PSO, continuous ACO, and the basic SSA. The results show that our algorithm has generally higher performance than the other algorithms. For example, compared to the basic SSA, the proposed method has an average reduction of approximately 21% in makespan.