 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exploring Domain-Specific Enhancements for a Neural Foley Synthesizer
Sep 08, 2023
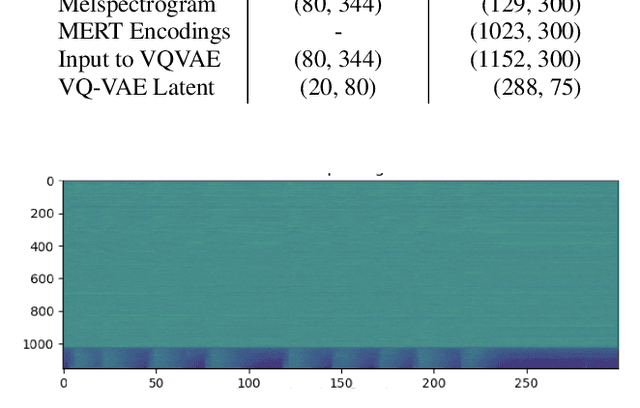

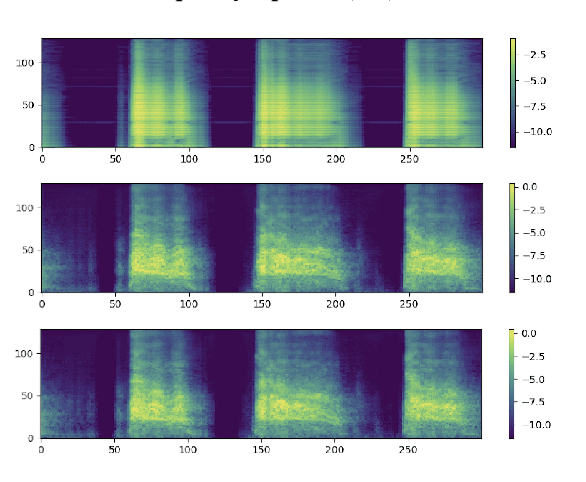
Foley sound synthesis refers to the creation of authentic, diegetic sound effects for media, such as film or radio. In this study, we construct a neural Foley synthesizer capable of generating mono-audio clips across seven predefined categories. Our approach introduces multiple enhancements to existing models in the text-to-audio domain, with the goal of enriching the diversity and acoustic characteristics of the generated foleys. Notably, we utilize a pre-trained encoder that retains acoustical and musical attributes in intermediate embeddings, implement class-conditioning to enhance differentiability among foley classes in their intermediate representations, and devise an innovative transformer-based architecture for optimizing self-attention computations on very large inputs without compromising valuable information. Subsequent to implementation, we present intermediate outcomes that surpass the baseline, discuss practical challenges encountered in achieving optimal results, and outline potential pathways for further research.
Attention De-sparsification Matters: Inducing Diversity in Digital Pathology Representation Learning
Sep 12, 2023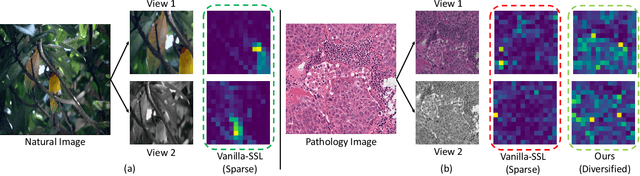
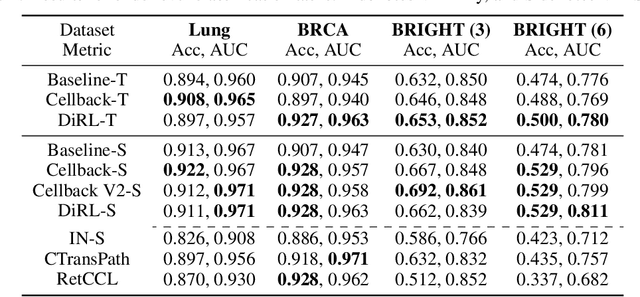
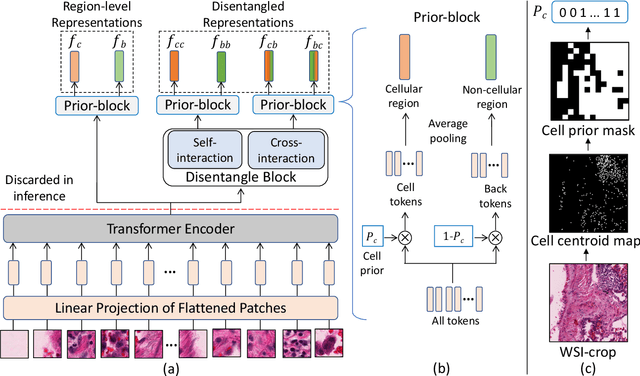
We propose DiRL, a Diversity-inducing Representation Learning technique for histopathology imaging. Self-supervised learning techniques, such as contrastive and non-contrastive approaches, have been shown to learn rich and effective representations of digitized tissue samples with limited pathologist supervision. Our analysis of vanilla SSL-pretrained models' attention distribution reveals an insightful observation: sparsity in attention, i.e, models tends to localize most of their attention to some prominent patterns in the image. Although attention sparsity can be beneficial in natural images due to these prominent patterns being the object of interest itself, this can be sub-optimal in digital pathology; this is because, unlike natural images, digital pathology scans are not object-centric, but rather a complex phenotype of various spatially intermixed biological components. Inadequate diversification of attention in these complex images could result in crucial information loss. To address this, we leverage cell segmentation to densely extract multiple histopathology-specific representations, and then propose a prior-guided dense pretext task for SSL, designed to match the multiple corresponding representations between the views. Through this, the model learns to attend to various components more closely and evenly, thus inducing adequate diversification in attention for capturing context rich representations. Through quantitative and qualitative analysis on multiple tasks across cancer types, we demonstrate the efficacy of our method and observe that the attention is more globally distributed.
ssVERDICT: Self-Supervised VERDICT-MRI for Enhanced Prostate Tumour Characterisation
Sep 12, 2023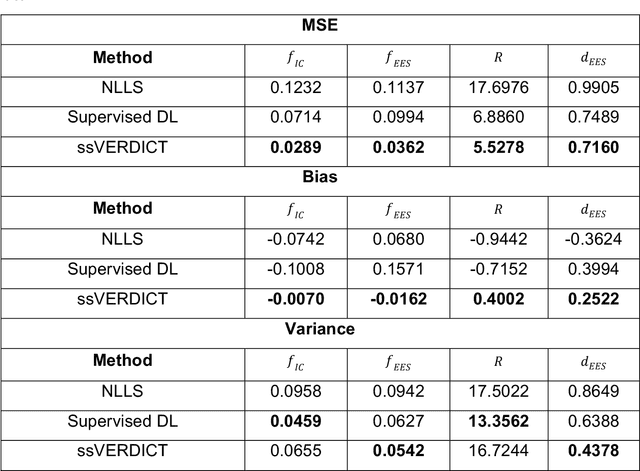
MRI is increasingly being used in the diagnosis of prostate cancer (PCa), with diffusion MRI (dMRI) playing an integral role. When combined with computational models, dMRI can estimate microstructural information such as cell size. Conventionally, such models are fit with a nonlinear least squares (NLLS) curve fitting approach, associated with a high computational cost. Supervised deep neural networks (DNNs) are an efficient alternative, however their performance is significantly affected by the underlying distribution of the synthetic training data. Self-supervised learning is an attractive alternative, where instead of using a separate training dataset, the network learns the features of the input data itself. This approach has only been applied to fitting of trivial dMRI models thus far. Here, we introduce a self-supervised DNN to estimate the parameters of the VERDICT (Vascular, Extracellular and Restricted DIffusion for Cytometry in Tumours) model for prostate. We demonstrate, for the first time, fitting of a complex three-compartment biophysical model with machine learning without the requirement of explicit training labels. We compare the estimation performance to baseline NLLS and supervised DNN methods, observing improvement in estimation accuracy and reduction in bias with respect to ground truth values. Our approach also achieves a higher confidence level for discrimination between cancerous and benign prostate tissue in comparison to the other methods on a dataset of 20 PCa patients, indicating potential for accurate tumour characterisation.
Feature Aggregation Network for Building Extraction from High-resolution Remote Sensing Images
Sep 12, 2023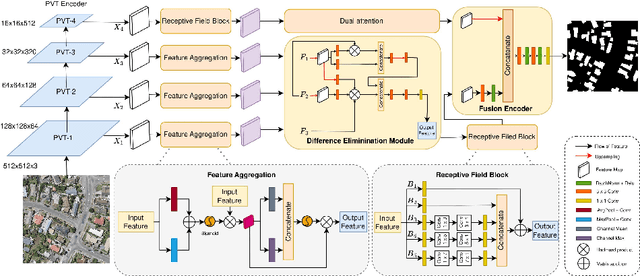
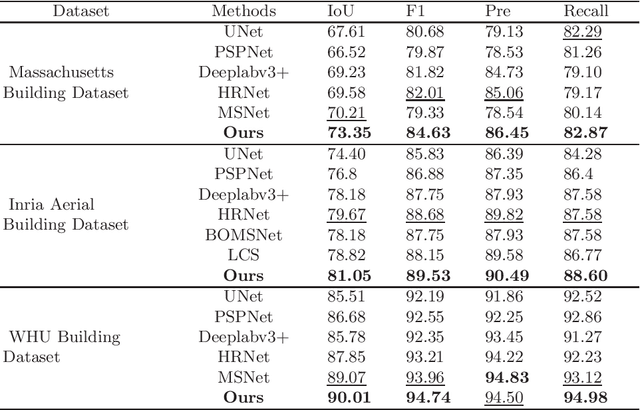

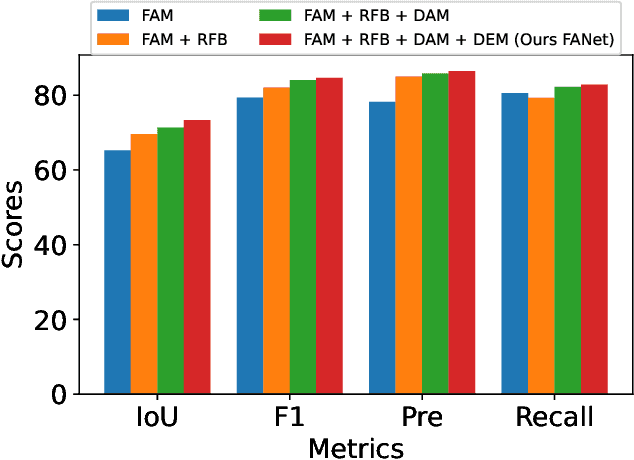
The rapid advancement in high-resolution satellite remote sensing data acquisition, particularly those achieving submeter precision, has uncovered the potential for detailed extraction of surface architectural features. However, the diversity and complexity of surface distributions frequently lead to current methods focusing exclusively on localized information of surface features. This often results in significant intraclass variability in boundary recognition and between buildings. Therefore, the task of fine-grained extraction of surface features from high-resolution satellite imagery has emerged as a critical challenge in remote sensing image processing. In this work, we propose the Feature Aggregation Network (FANet), concentrating on extracting both global and local features, thereby enabling the refined extraction of landmark buildings from high-resolution satellite remote sensing imagery. The Pyramid Vision Transformer captures these global features, which are subsequently refined by the Feature Aggregation Module and merged into a cohesive representation by the Difference Elimination Module. In addition, to ensure a comprehensive feature map, we have incorporated the Receptive Field Block and Dual Attention Module, expanding the receptive field and intensifying attention across spatial and channel dimensions. Extensive experiments on multiple datasets have validated the outstanding capability of FANet in extracting features from high-resolution satellite images. This signifies a major breakthrough in the field of remote sensing image processing. We will release our code soon.
Long-term drought prediction using deep neural networks based on geospatial weather data
Sep 12, 2023
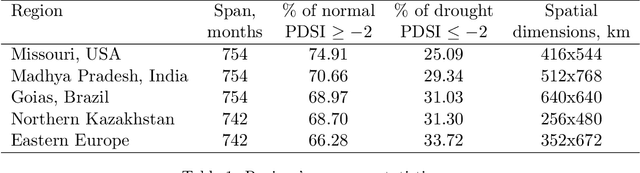
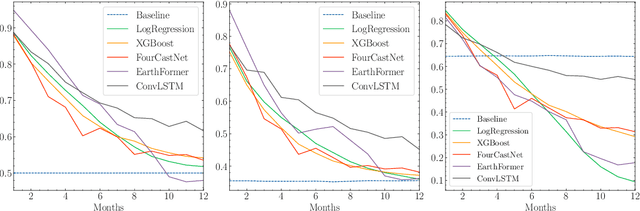
The accurate prediction of drought probability in specific regions is crucial for informed decision-making in agricultural practices. It is important to make predictions one year in advance, particularly for long-term decisions. However, forecasting this probability presents challenges due to the complex interplay of various factors within the region of interest and neighboring areas. In this study, we propose an end-to-end solution to address this issue based on various spatiotemporal neural networks. The models considered focus on predicting the drought intensity based on the Palmer Drought Severity Index (PDSI) for subregions of interest, leveraging intrinsic factors and insights from climate models to enhance drought predictions. Comparative evaluations demonstrate the superior accuracy of Convolutional LSTM (ConvLSTM) and transformer models compared to baseline gradient boosting and logistic regression solutions. The two former models achieved impressive ROC AUC scores from 0.90 to 0.70 for forecast horizons from one to six months, outperforming baseline models. The transformer showed superiority for shorter horizons, while ConvLSTM did so for longer horizons. Thus, we recommend selecting the models accordingly for long-term drought forecasting. To ensure the broad applicability of the considered models, we conduct extensive validation across regions worldwide, considering different environmental conditions. We also run several ablation and sensitivity studies to challenge our findings and provide additional information on how to solve the problem.
GLAD: Content-aware Dynamic Graphs For Log Anomaly Detection
Sep 12, 2023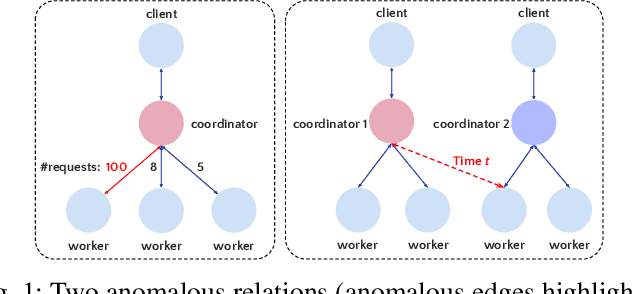
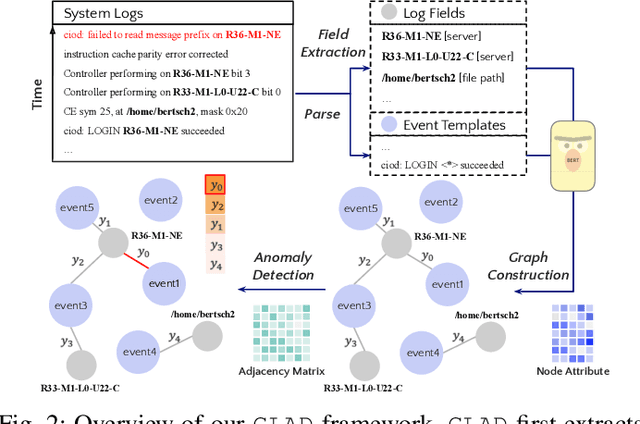
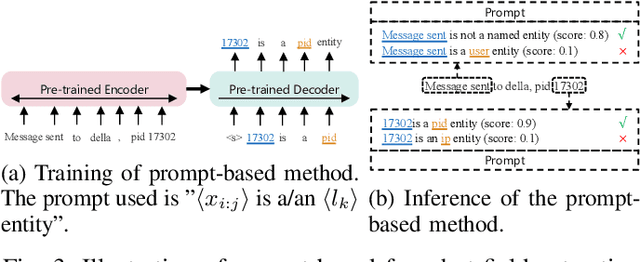

Logs play a crucial role in system monitoring and debugging by recording valuable system information, including events and states. Although various methods have been proposed to detect anomalies in log sequences, they often overlook the significance of considering relations among system components, such as services and users, which can be identified from log contents. Understanding these relations is vital for detecting anomalies and their underlying causes. To address this issue, we introduce GLAD, a Graph-based Log Anomaly Detection framework designed to detect relational anomalies in system logs. GLAD incorporates log semantics, relational patterns, and sequential patterns into a unified framework for anomaly detection. Specifically, GLAD first introduces a field extraction module that utilizes prompt-based few-shot learning to identify essential fields from log contents. Then GLAD constructs dynamic log graphs for sliding windows by interconnecting extracted fields and log events parsed from the log parser. These graphs represent events and fields as nodes and their relations as edges. Subsequently, GLAD utilizes a temporal-attentive graph edge anomaly detection model for identifying anomalous relations in these dynamic log graphs. This model employs a Graph Neural Network (GNN)-based encoder enhanced with transformers to capture content, structural and temporal features. We evaluate our proposed method on three datasets, and the results demonstrate the effectiveness of GLAD in detecting anomalies indicated by varying relational patterns.
An Asynchronous Linear Filter Architecture for Hybrid Event-Frame Cameras
Sep 03, 2023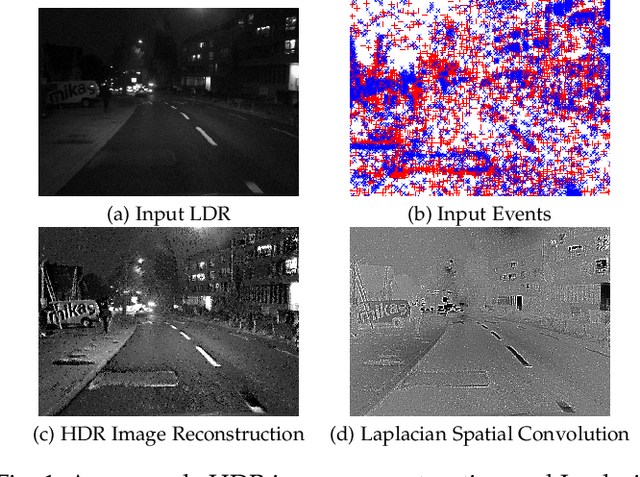
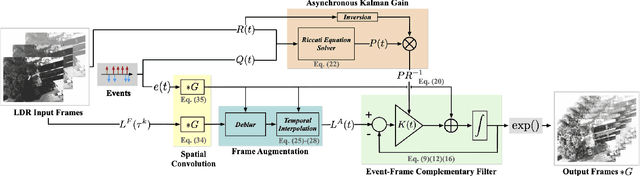

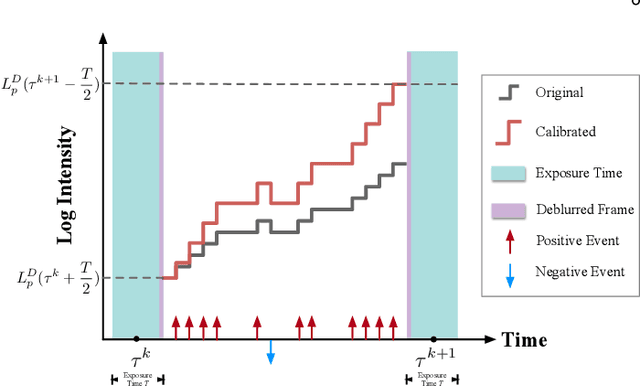
Event cameras are ideally suited to capture High Dynamic Range (HDR) visual information without blur but provide poor imaging capability for static or slowly varying scenes. Conversely, conventional image sensors measure absolute intensity of slowly changing scenes effectively but do poorly on HDR or quickly changing scenes. In this paper, we present an asynchronous linear filter architecture, fusing event and frame camera data, for HDR video reconstruction and spatial convolution that exploits the advantages of both sensor modalities. The key idea is the introduction of a state that directly encodes the integrated or convolved image information and that is updated asynchronously as each event or each frame arrives from the camera. The state can be read-off as-often-as and whenever required to feed into subsequent vision modules for real-time robotic systems. Our experimental results are evaluated on both publicly available datasets with challenging lighting conditions and fast motions, along with a new dataset with HDR reference that we provide. The proposed AKF pipeline outperforms other state-of-the-art methods in both absolute intensity error (69.4% reduction) and image similarity indexes (average 35.5% improvement). We also demonstrate the integration of image convolution with linear spatial kernels Gaussian, Sobel, and Laplacian as an application of our architecture.
Semi-supervised Domain Adaptation with Inter and Intra-domain Mixing for Semantic Segmentation
Aug 30, 2023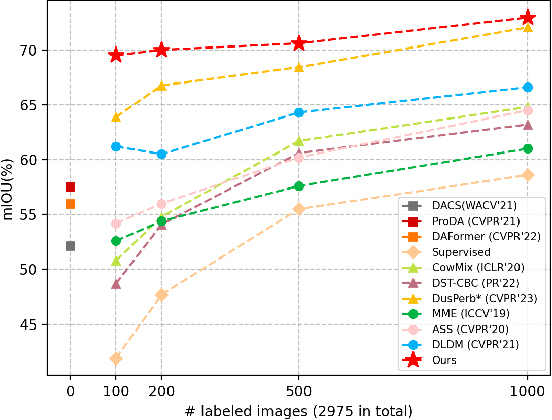
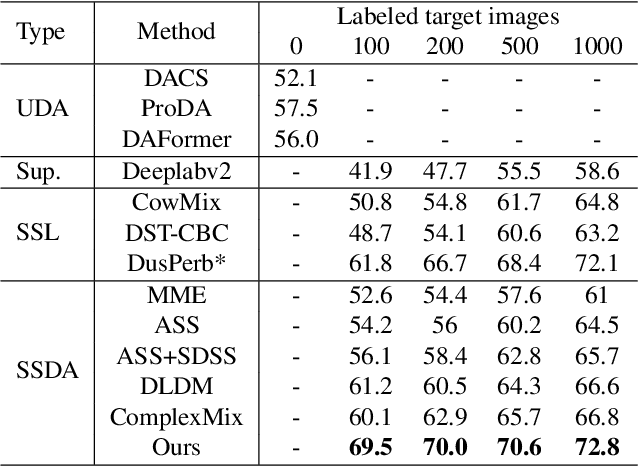
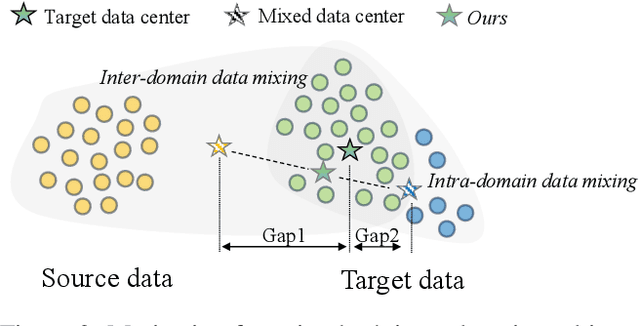
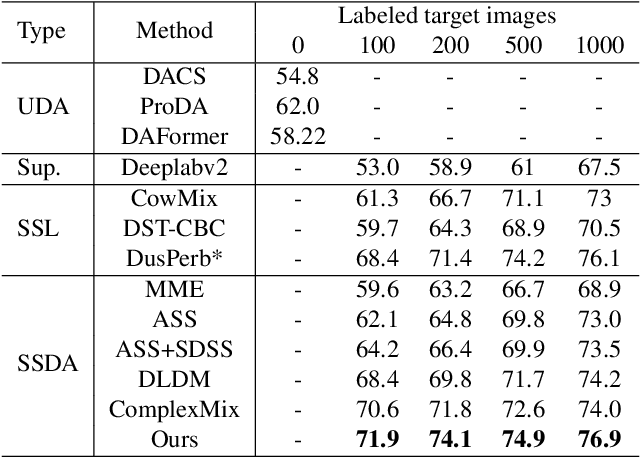
Despite recent advances in semantic segmentation, an inevitable challenge is the performance degradation caused by the domain shift in real application. Current dominant approach to solve this problem is unsupervised domain adaptation (UDA). However, the absence of labeled target data in UDA is overly restrictive and limits performance. To overcome this limitation, a more practical scenario called semi-supervised domain adaptation (SSDA) has been proposed. Existing SSDA methods are derived from the UDA paradigm and primarily focus on leveraging the unlabeled target data and source data. In this paper, we highlight the significance of exploiting the intra-domain information between the limited labeled target data and unlabeled target data, as it greatly benefits domain adaptation. Instead of solely using the scarce labeled data for supervision, we propose a novel SSDA framework that incorporates both inter-domain mixing and intra-domain mixing, where inter-domain mixing mitigates the source-target domain gap and intra-domain mixing enriches the available target domain information. By simultaneously learning from inter-domain mixing and intra-domain mixing, the network can capture more domain-invariant features and promote its performance on the target domain. We also explore different domain mixing operations to better exploit the target domain information. Comprehensive experiments conducted on the GTA5toCityscapes and SYNTHIA2Cityscapes benchmarks demonstrate the effectiveness of our method, surpassing previous methods by a large margin.
Sparse Function-space Representation of Neural Networks
Sep 05, 2023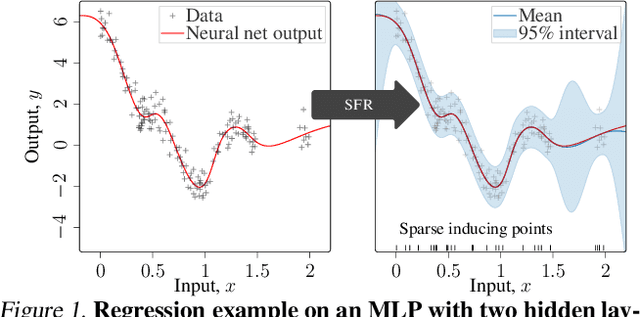
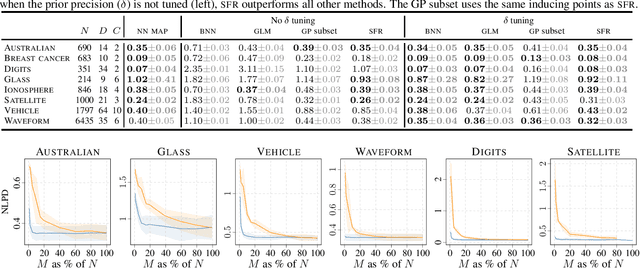
Deep neural networks (NNs) are known to lack uncertainty estimates and struggle to incorporate new data. We present a method that mitigates these issues by converting NNs from weight space to function space, via a dual parameterization. Importantly, the dual parameterization enables us to formulate a sparse representation that captures information from the entire data set. This offers a compact and principled way of capturing uncertainty and enables us to incorporate new data without retraining whilst retaining predictive performance. We provide proof-of-concept demonstrations with the proposed approach for quantifying uncertainty in supervised learning on UCI benchmark tasks.
Dynamic NeRFs for Soccer Scenes
Sep 13, 2023The long-standing problem of novel view synthesis has many applications, notably in sports broadcasting. Photorealistic novel view synthesis of soccer actions, in particular, is of enormous interest to the broadcast industry. Yet only a few industrial solutions have been proposed, and even fewer that achieve near-broadcast quality of the synthetic replays. Except for their setup of multiple static cameras around the playfield, the best proprietary systems disclose close to no information about their inner workings. Leveraging multiple static cameras for such a task indeed presents a challenge rarely tackled in the literature, for a lack of public datasets: the reconstruction of a large-scale, mostly static environment, with small, fast-moving elements. Recently, the emergence of neural radiance fields has induced stunning progress in many novel view synthesis applications, leveraging deep learning principles to produce photorealistic results in the most challenging settings. In this work, we investigate the feasibility of basing a solution to the task on dynamic NeRFs, i.e., neural models purposed to reconstruct general dynamic content. We compose synthetic soccer environments and conduct multiple experiments using them, identifying key components that help reconstruct soccer scenes with dynamic NeRFs. We show that, although this approach cannot fully meet the quality requirements for the target application, it suggests promising avenues toward a cost-efficient, automatic solution. We also make our work dataset and code publicly available, with the goal to encourage further efforts from the research community on the task of novel view synthesis for dynamic soccer scenes. For code, data, and video results, please see https://soccernerfs.isach.be.