 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learn to Enhance the Negative Information in Convolutional Neural Network
Jun 18, 2023
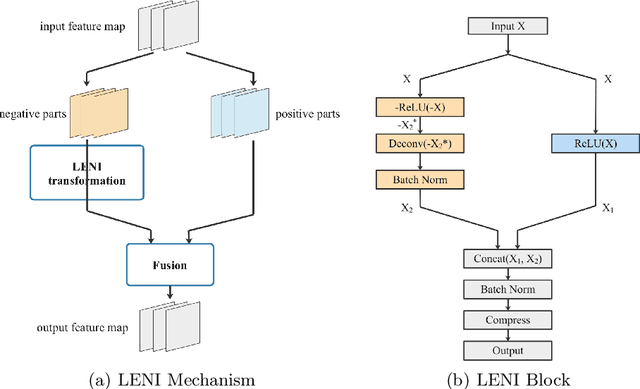
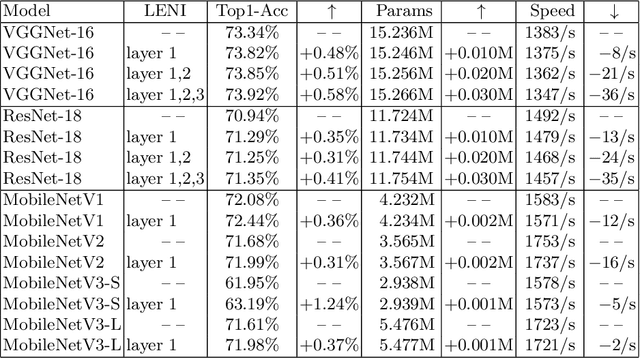
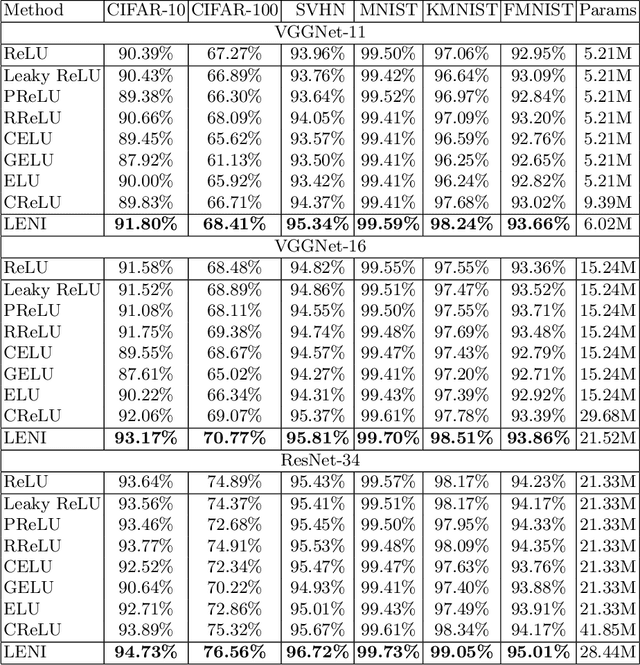
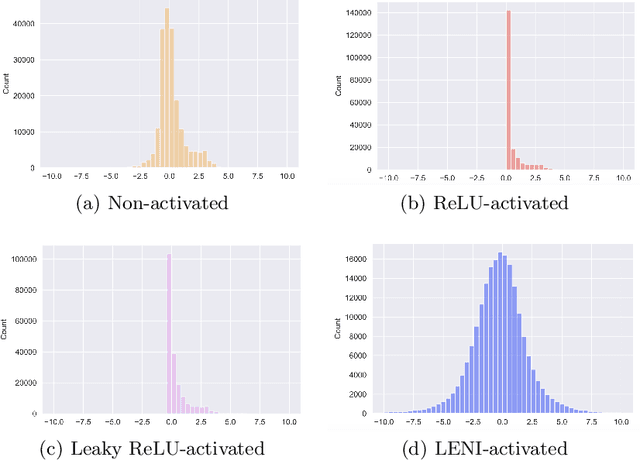
This paper proposes a learnable nonlinear activation mechanism specifically for convolutional neural network (CNN) termed as LENI, which learns to enhance the negative information in CNNs. In sharp contrast to ReLU which cuts off the negative neurons and suffers from the issue of ''dying ReLU'', LENI enjoys the capacity to reconstruct the dead neurons and reduce the information loss. Compared to improved ReLUs, LENI introduces a learnable approach to process the negative phase information more properly. In this way, LENI can enhance the model representational capacity significantly while maintaining the original advantages of ReLU. As a generic activation mechanism, LENI possesses the property of portability and can be easily utilized in any CNN models through simply replacing the activation layers with LENI block. Extensive experiments validate that LENI can improve the performance of various baseline models on various benchmark datasets by a clear margin (up to 1.24% higher top-1 accuracy on ImageNet-1k) with negligible extra parameters. Further experiments show that LENI can act as a channel compensation mechanism, offering competitive or even better performance but with fewer learned parameters than baseline models. In addition, LENI introduces the asymmetry to the model structure which contributes to the enhancement of representational capacity. Through visualization experiments, we validate that LENI can retain more information and learn more representations.
Privacy Side Channels in Machine Learning Systems
Sep 11, 2023Most current approaches for protecting privacy in machine learning (ML) assume that models exist in a vacuum, when in reality, ML models are part of larger systems that include components for training data filtering, output monitoring, and more. In this work, we introduce privacy side channels: attacks that exploit these system-level components to extract private information at far higher rates than is otherwise possible for standalone models. We propose four categories of side channels that span the entire ML lifecycle (training data filtering, input preprocessing, output post-processing, and query filtering) and allow for either enhanced membership inference attacks or even novel threats such as extracting users' test queries. For example, we show that deduplicating training data before applying differentially-private training creates a side-channel that completely invalidates any provable privacy guarantees. Moreover, we show that systems which block language models from regenerating training data can be exploited to allow exact reconstruction of private keys contained in the training set -- even if the model did not memorize these keys. Taken together, our results demonstrate the need for a holistic, end-to-end privacy analysis of machine learning.
Our Deep CNN Face Matchers Have Developed Achromatopsia
Sep 11, 2023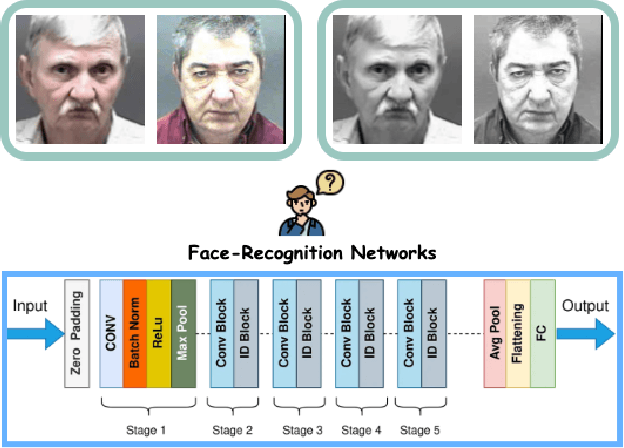
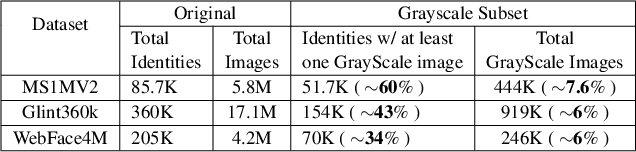
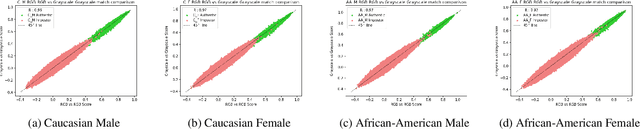
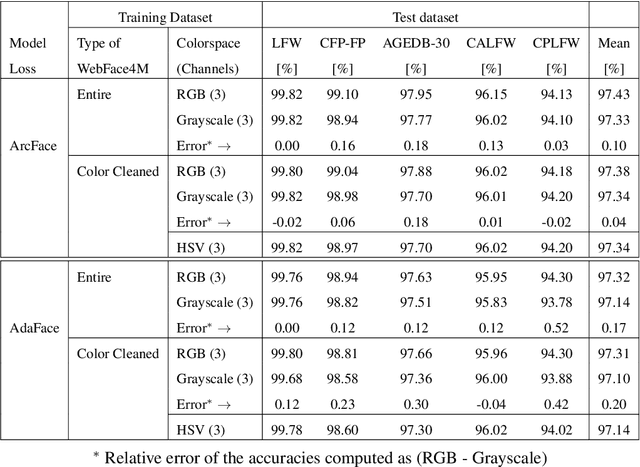
Modern deep CNN face matchers are trained on datasets containing color images. We show that such matchers achieve essentially the same accuracy on the grayscale or the color version of a set of test images. We then consider possible causes for deep CNN face matchers ``not seeing color''. Popular web-scraped face datasets actually have 30 to 60\% of their identities with one or more grayscale images. We analyze whether this grayscale element in the training set impacts the accuracy achieved, and conclude that it does not. Further, we show that even with a 100\% grayscale training set, comparable accuracy is achieved on color or grayscale test images. Then we show that the skin region of an individual's images in a web-scraped training set exhibit significant variation in their mapping to color space. This suggests that color, at least for web-scraped, in-the-wild face datasets, carries limited identity-related information for training state-of-the-art matchers. Finally, we verify that comparable accuracy is achieved from training using single-channel grayscale images, implying that a larger dataset can be used within the same memory limit, with a less computationally intensive early layer.
BoardgameQA: A Dataset for Natural Language Reasoning with Contradictory Information
Jun 13, 2023
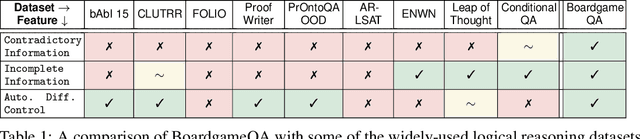

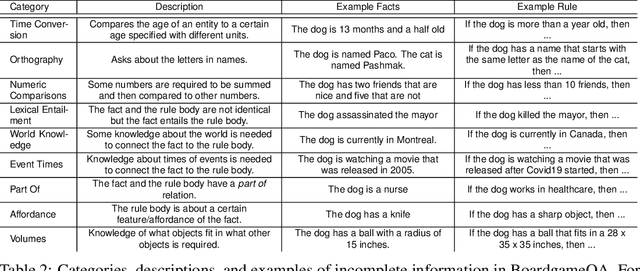
Automated reasoning with unstructured natural text is a key requirement for many potential applications of NLP and for developing robust AI systems. Recently, Language Models (LMs) have demonstrated complex reasoning capacities even without any finetuning. However, existing evaluation for automated reasoning assumes access to a consistent and coherent set of information over which models reason. When reasoning in the real-world, the available information is frequently inconsistent or contradictory, and therefore models need to be equipped with a strategy to resolve such conflicts when they arise. One widely-applicable way of resolving conflicts is to impose preferences over information sources (e.g., based on source credibility or information recency) and adopt the source with higher preference. In this paper, we formulate the problem of reasoning with contradictory information guided by preferences over sources as the classical problem of defeasible reasoning, and develop a dataset called BoardgameQA for measuring the reasoning capacity of LMs in this setting. BoardgameQA also incorporates reasoning with implicit background knowledge, to better reflect reasoning problems in downstream applications. We benchmark various LMs on BoardgameQA and the results reveal a significant gap in the reasoning capacity of state-of-the-art LMs on this problem, showing that reasoning with conflicting information does not surface out-of-the-box in LMs. While performance can be improved with finetuning, it nevertheless remains poor.
CALM: Contrastive Cross-modal Speaking Style Modeling for Expressive Text-to-Speech Synthesis
Aug 30, 2023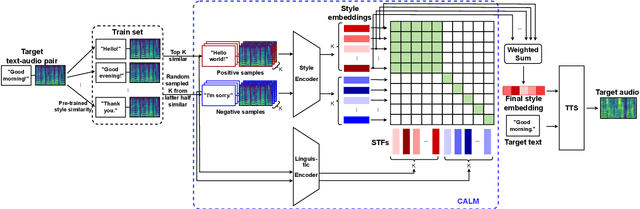
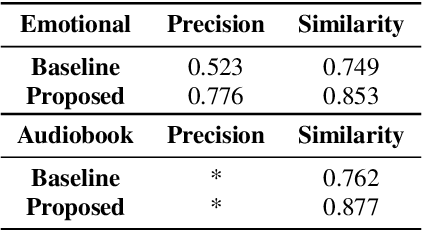
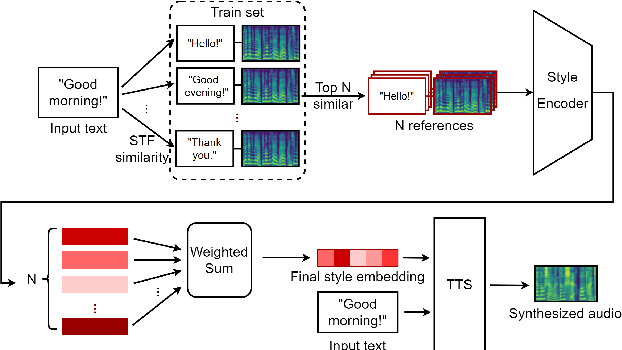

To further improve the speaking styles of synthesized speeches, current text-to-speech (TTS) synthesis systems commonly employ reference speeches to stylize their outputs instead of just the input texts. These reference speeches are obtained by manual selection which is resource-consuming, or selected by semantic features. However, semantic features contain not only style-related information, but also style irrelevant information. The information irrelevant to speaking style in the text could interfere the reference audio selection and result in improper speaking styles. To improve the reference selection, we propose Contrastive Acoustic-Linguistic Module (CALM) to extract the Style-related Text Feature (STF) from the text. CALM optimizes the correlation between the speaking style embedding and the extracted STF with contrastive learning. Thus, a certain number of the most appropriate reference speeches for the input text are selected by retrieving the speeches with the top STF similarities. Then the style embeddings are weighted summarized according to their STF similarities and used to stylize the synthesized speech of TTS. Experiment results demonstrate the effectiveness of our proposed approach, with both objective evaluations and subjective evaluations on the speaking styles of the synthesized speeches outperform a baseline approach with semantic-feature-based reference selection.
STUPD: A Synthetic Dataset for Spatial and Temporal Relation Reasoning
Sep 13, 2023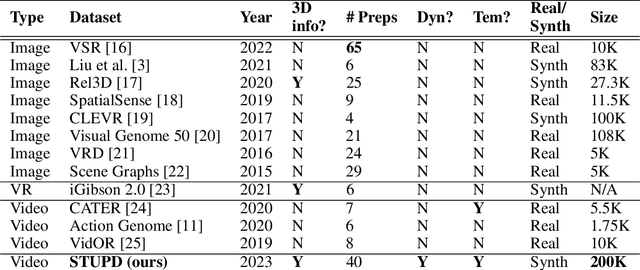

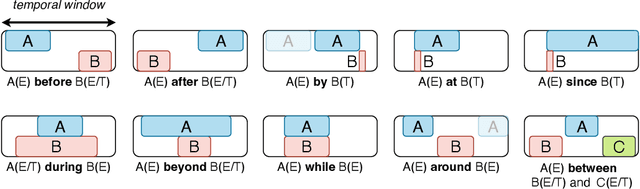
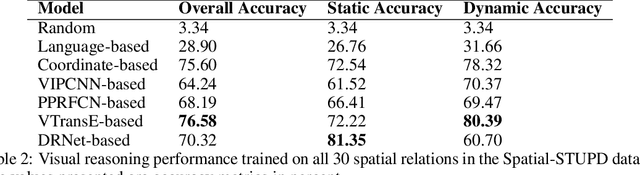
Understanding relations between objects is crucial for understanding the semantics of a visual scene. It is also an essential step in order to bridge visual and language models. However, current state-of-the-art computer vision models still lack the ability to perform spatial reasoning well. Existing datasets mostly cover a relatively small number of spatial relations, all of which are static relations that do not intrinsically involve motion. In this paper, we propose the Spatial and Temporal Understanding of Prepositions Dataset (STUPD) -- a large-scale video dataset for understanding static and dynamic spatial relationships derived from prepositions of the English language. The dataset contains 150K visual depictions (videos and images), consisting of 30 distinct spatial prepositional senses, in the form of object interaction simulations generated synthetically using Unity3D. In addition to spatial relations, we also propose 50K visual depictions across 10 temporal relations, consisting of videos depicting event/time-point interactions. To our knowledge, no dataset exists that represents temporal relations through visual settings. In this dataset, we also provide 3D information about object interactions such as frame-wise coordinates, and descriptions of the objects used. The goal of this synthetic dataset is to help models perform better in visual relationship detection in real-world settings. We demonstrate an increase in the performance of various models over 2 real-world datasets (ImageNet-VidVRD and Spatial Senses) when pretrained on the STUPD dataset, in comparison to other pretraining datasets.
ProMap: Datasets for Product Mapping in E-commerce
Sep 13, 2023
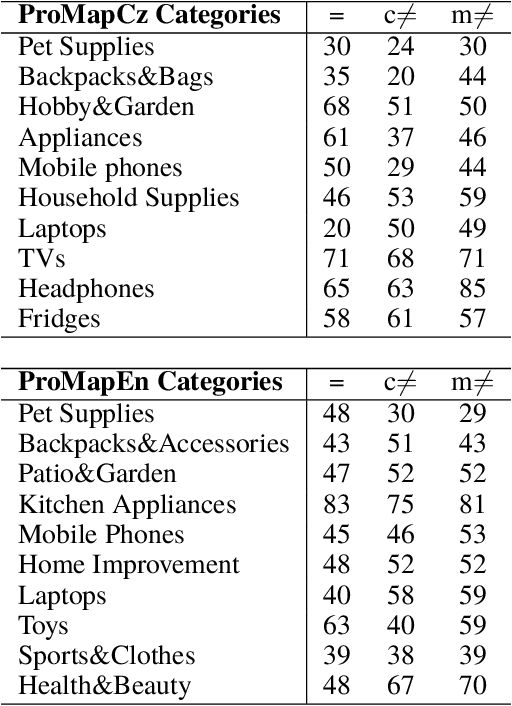

The goal of product mapping is to decide, whether two listings from two different e-shops describe the same products. Existing datasets of matching and non-matching pairs of products, however, often suffer from incomplete product information or contain only very distant non-matching products. Therefore, while predictive models trained on these datasets achieve good results on them, in practice, they are unusable as they cannot distinguish very similar but non-matching pairs of products. This paper introduces two new datasets for product mapping: ProMapCz consisting of 1,495 Czech product pairs and ProMapEn consisting of 1,555 English product pairs of matching and non-matching products manually scraped from two pairs of e-shops. The datasets contain both images and textual descriptions of the products, including their specifications, making them one of the most complete datasets for product mapping. Additionally, the non-matching products were selected in two phases, creating two types of non-matches -- close non-matches and medium non-matches. Even the medium non-matches are pairs of products that are much more similar than non-matches in other datasets -- for example, they still need to have the same brand and similar name and price. After simple data preprocessing, several machine learning algorithms were trained on these and two the other datasets to demonstrate the complexity and completeness of ProMap datasets. ProMap datasets are presented as a golden standard for further research of product mapping filling the gaps in existing ones.
Joint Modeling of Feature, Correspondence, and a Compressed Memory for Video Object Segmentation
Aug 25, 2023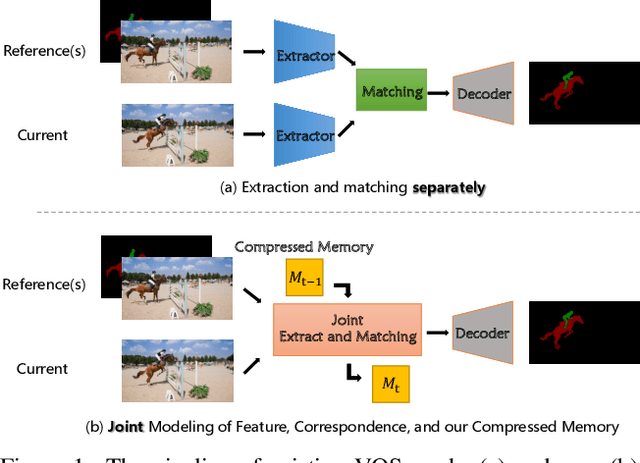
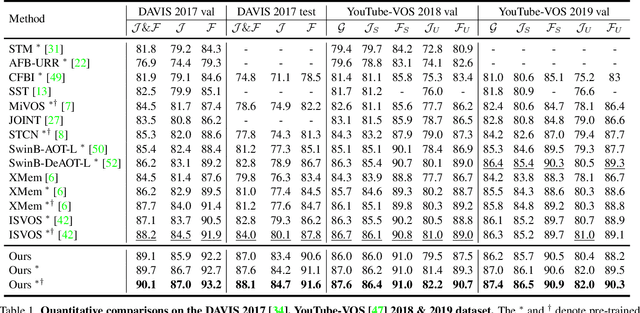
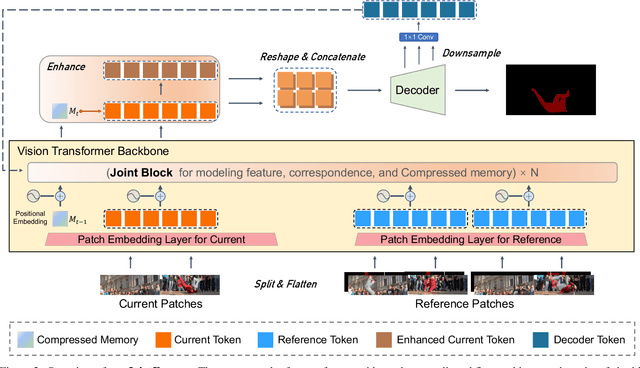
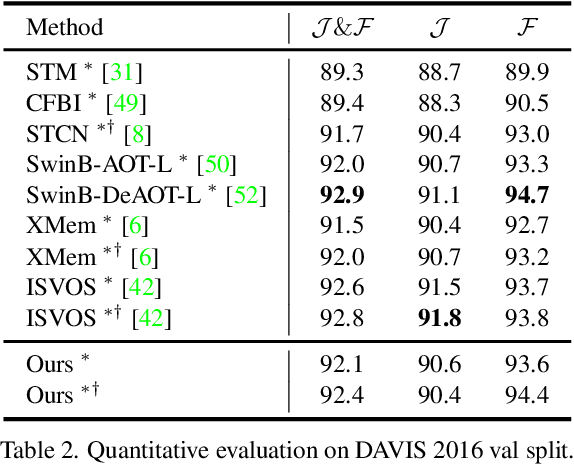
Current prevailing Video Object Segmentation (VOS) methods usually perform dense matching between the current and reference frames after extracting their features. One on hand, the decoupled modeling restricts the targets information propagation only at high-level feature space. On the other hand, the pixel-wise matching leads to a lack of holistic understanding of the targets. To overcome these issues, we propose a unified VOS framework, coined as JointFormer, for joint modeling the three elements of feature, correspondence, and a compressed memory. The core design is the Joint Block, utilizing the flexibility of attention to simultaneously extract feature and propagate the targets information to the current tokens and the compressed memory token. This scheme allows to perform extensive information propagation and discriminative feature learning. To incorporate the long-term temporal targets information, we also devise a customized online updating mechanism for the compressed memory token, which can prompt the information flow along the temporal dimension and thus improve the global modeling capability. Under the design, our method achieves a new state-of-art performance on DAVIS 2017 val/test-dev (89.7% and 87.6%) and YouTube-VOS 2018/2019 val (87.0% and 87.0%) benchmarks, outperforming existing works by a large margin.
Mutual-Guided Dynamic Network for Image Fusion
Aug 24, 2023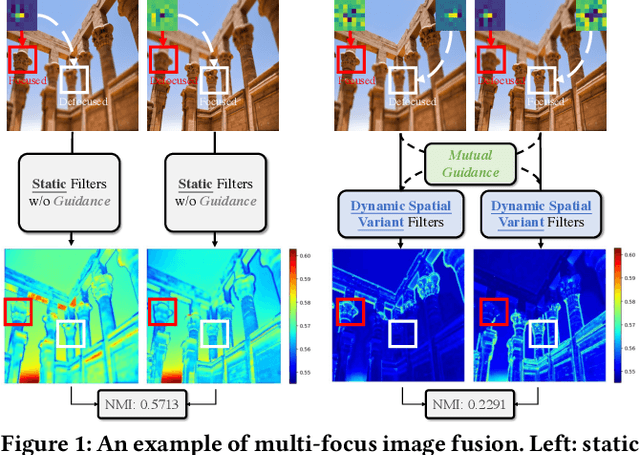

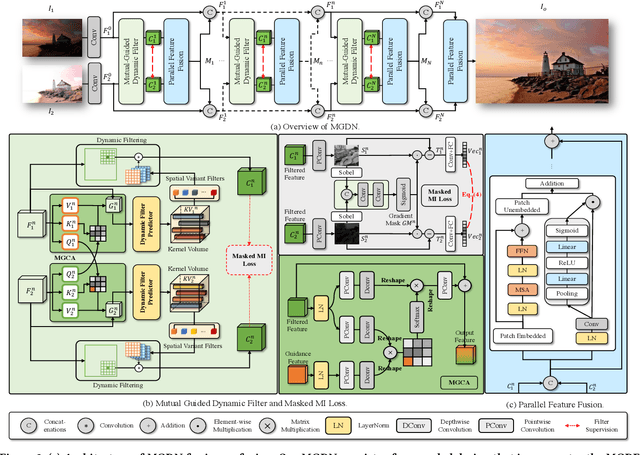
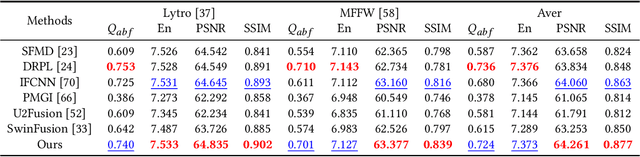
Image fusion aims to generate a high-quality image from multiple images captured under varying conditions. The key problem of this task is to preserve complementary information while filtering out irrelevant information for the fused result. However, existing methods address this problem by leveraging static convolutional neural networks (CNNs), suffering two inherent limitations during feature extraction, i.e., being unable to handle spatial-variant contents and lacking guidance from multiple inputs. In this paper, we propose a novel mutual-guided dynamic network (MGDN) for image fusion, which allows for effective information utilization across different locations and inputs. Specifically, we design a mutual-guided dynamic filter (MGDF) for adaptive feature extraction, composed of a mutual-guided cross-attention (MGCA) module and a dynamic filter predictor, where the former incorporates additional guidance from different inputs and the latter generates spatial-variant kernels for different locations. In addition, we introduce a parallel feature fusion (PFF) module to effectively fuse local and global information of the extracted features. To further reduce the redundancy among the extracted features while simultaneously preserving their shared structural information, we devise a novel loss function that combines the minimization of normalized mutual information (NMI) with an estimated gradient mask. Experimental results on five benchmark datasets demonstrate that our proposed method outperforms existing methods on four image fusion tasks. The code and model are publicly available at: https://github.com/Guanys-dar/MGDN.
ViCGCN: Graph Convolutional Network with Contextualized Language Models for Social Media Mining in Vietnamese
Sep 06, 2023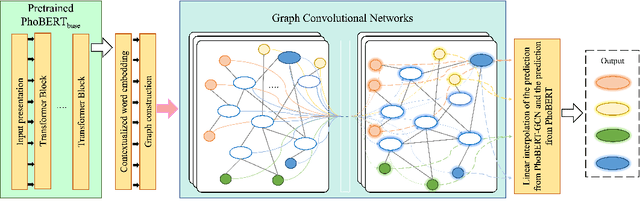
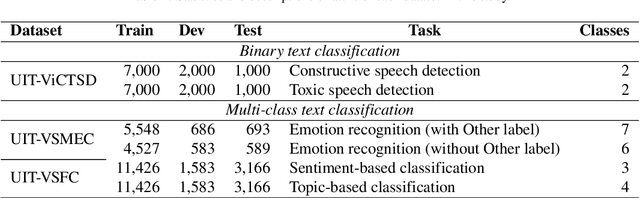
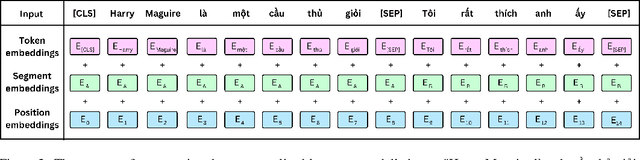
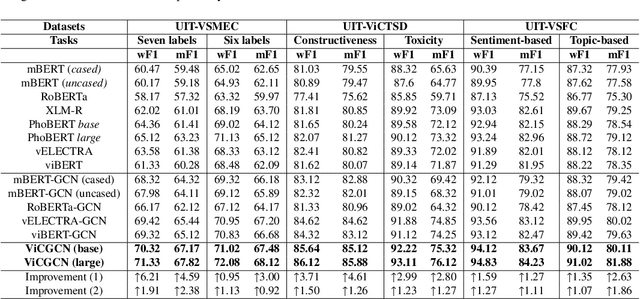
Social media processing is a fundamental task in natural language processing with numerous applications. As Vietnamese social media and information science have grown rapidly, the necessity of information-based mining on Vietnamese social media has become crucial. However, state-of-the-art research faces several significant drawbacks, including imbalanced data and noisy data on social media platforms. Imbalanced and noisy are two essential issues that need to be addressed in Vietnamese social media texts. Graph Convolutional Networks can address the problems of imbalanced and noisy data in text classification on social media by taking advantage of the graph structure of the data. This study presents a novel approach based on contextualized language model (PhoBERT) and graph-based method (Graph Convolutional Networks). In particular, the proposed approach, ViCGCN, jointly trained the power of Contextualized embeddings with the ability of Graph Convolutional Networks, GCN, to capture more syntactic and semantic dependencies to address those drawbacks. Extensive experiments on various Vietnamese benchmark datasets were conducted to verify our approach. The observation shows that applying GCN to BERTology models as the final layer significantly improves performance. Moreover, the experiments demonstrate that ViCGCN outperforms 13 powerful baseline models, including BERTology models, fusion BERTology and GCN models, other baselines, and SOTA on three benchmark social media datasets. Our proposed ViCGCN approach demonstrates a significant improvement of up to 6.21%, 4.61%, and 2.63% over the best Contextualized Language Models, including multilingual and monolingual, on three benchmark datasets, UIT-VSMEC, UIT-ViCTSD, and UIT-VSFC, respectively. Additionally, our integrated model ViCGCN achieves the best performance compared to other BERTology integrated with GCN models.