 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards a Zero-Data, Controllable, Adaptive Dialog System
Mar 26, 2024
Conversational Tree Search (V\"ath et al., 2023) is a recent approach to controllable dialog systems, where domain experts shape the behavior of a Reinforcement Learning agent through a dialog tree. The agent learns to efficiently navigate this tree, while adapting to information needs, e.g., domain familiarity, of different users. However, the need for additional training data hinders deployment in new domains. To address this, we explore approaches to generate this data directly from dialog trees. We improve the original approach, and show that agents trained on synthetic data can achieve comparable dialog success to models trained on human data, both when using a commercial Large Language Model for generation, or when using a smaller open-source model, running on a single GPU. We further demonstrate the scalability of our approach by collecting and testing on two new datasets: ONBOARD, a new domain helping foreign residents moving to a new city, and the medical domain DIAGNOSE, a subset of Wikipedia articles related to scalp and head symptoms. Finally, we perform human testing, where no statistically significant differences were found in either objective or subjective measures between models trained on human and generated data.
Random-coupled Neural Network
Mar 26, 2024Improving the efficiency of current neural networks and modeling them in biological neural systems have become popular research directions in recent years. Pulse-coupled neural network (PCNN) is a well applicated model for imitating the computation characteristics of the human brain in computer vision and neural network fields. However, differences between the PCNN and biological neural systems remain: limited neural connection, high computational cost, and lack of stochastic property. In this study, random-coupled neural network (RCNN) is proposed. It overcomes these difficulties in PCNN's neuromorphic computing via a random inactivation process. This process randomly closes some neural connections in the RCNN model, realized by the random inactivation weight matrix of link input. This releases the computational burden of PCNN, making it affordable to achieve vast neural connections. Furthermore, the image and video processing mechanisms of RCNN are researched. It encodes constant stimuli as periodic spike trains and periodic stimuli as chaotic spike trains, the same as biological neural information encoding characteristics. Finally, the RCNN is applicated to image segmentation, fusion, and pulse shape discrimination subtasks. It is demonstrated to be robust, efficient, and highly anti-noised, with outstanding performance in all applications mentioned above.
Integrating Mamba Sequence Model and Hierarchical Upsampling Network for Accurate Semantic Segmentation of Multiple Sclerosis Legion
Mar 26, 2024Integrating components from convolutional neural networks and state space models in medical image segmentation presents a compelling approach to enhance accuracy and efficiency. We introduce Mamba HUNet, a novel architecture tailored for robust and efficient segmentation tasks. Leveraging strengths from Mamba UNet and the lighter version of Hierarchical Upsampling Network (HUNet), Mamba HUNet combines convolutional neural networks local feature extraction power with state space models long range dependency modeling capabilities. We first converted HUNet into a lighter version, maintaining performance parity and then integrated this lighter HUNet into Mamba HUNet, further enhancing its efficiency. The architecture partitions input grayscale images into patches, transforming them into 1D sequences for processing efficiency akin to Vision Transformers and Mamba models. Through Visual State Space blocks and patch merging layers, hierarchical features are extracted while preserving spatial information. Experimental results on publicly available Magnetic Resonance Imaging scans, notably in Multiple Sclerosis lesion segmentation, demonstrate Mamba HUNet's effectiveness across diverse segmentation tasks. The model's robustness and flexibility underscore its potential in handling complex anatomical structures. These findings establish Mamba HUNet as a promising solution in advancing medical image segmentation, with implications for improving clinical decision making processes.
Learning to Visually Localize Sound Sources from Mixtures without Prior Source Knowledge
Mar 26, 2024The goal of the multi-sound source localization task is to localize sound sources from the mixture individually. While recent multi-sound source localization methods have shown improved performance, they face challenges due to their reliance on prior information about the number of objects to be separated. In this paper, to overcome this limitation, we present a novel multi-sound source localization method that can perform localization without prior knowledge of the number of sound sources. To achieve this goal, we propose an iterative object identification (IOI) module, which can recognize sound-making objects in an iterative manner. After finding the regions of sound-making objects, we devise object similarity-aware clustering (OSC) loss to guide the IOI module to effectively combine regions of the same object but also distinguish between different objects and backgrounds. It enables our method to perform accurate localization of sound-making objects without any prior knowledge. Extensive experimental results on the MUSIC and VGGSound benchmarks show the significant performance improvements of the proposed method over the existing methods for both single and multi-source. Our code is available at: https://github.com/VisualAIKHU/NoPrior_MultiSSL
Self-Rectifying Diffusion Sampling with Perturbed-Attention Guidance
Mar 26, 2024Recent studies have demonstrated that diffusion models are capable of generating high-quality samples, but their quality heavily depends on sampling guidance techniques, such as classifier guidance (CG) and classifier-free guidance (CFG). These techniques are often not applicable in unconditional generation or in various downstream tasks such as image restoration. In this paper, we propose a novel sampling guidance, called Perturbed-Attention Guidance (PAG), which improves diffusion sample quality across both unconditional and conditional settings, achieving this without requiring additional training or the integration of external modules. PAG is designed to progressively enhance the structure of samples throughout the denoising process. It involves generating intermediate samples with degraded structure by substituting selected self-attention maps in diffusion U-Net with an identity matrix, by considering the self-attention mechanisms' ability to capture structural information, and guiding the denoising process away from these degraded samples. In both ADM and Stable Diffusion, PAG surprisingly improves sample quality in conditional and even unconditional scenarios. Moreover, PAG significantly improves the baseline performance in various downstream tasks where existing guidances such as CG or CFG cannot be fully utilized, including ControlNet with empty prompts and image restoration such as inpainting and deblurring.
Motion Generation from Fine-grained Textual Descriptions
Mar 26, 2024



The task of text2motion is to generate human motion sequences from given textual descriptions, where the model explores diverse mappings from natural language instructions to human body movements. While most existing works are confined to coarse-grained motion descriptions, e.g., "A man squats.", fine-grained descriptions specifying movements of relevant body parts are barely explored. Models trained with coarse-grained texts may not be able to learn mappings from fine-grained motion-related words to motion primitives, resulting in the failure to generate motions from unseen descriptions. In this paper, we build a large-scale language-motion dataset specializing in fine-grained textual descriptions, FineHumanML3D, by feeding GPT-3.5-turbo with step-by-step instructions with pseudo-code compulsory checks. Accordingly, we design a new text2motion model, FineMotionDiffuse, making full use of fine-grained textual information. Our quantitative evaluation shows that FineMotionDiffuse trained on FineHumanML3D improves FID by a large margin of 0.38, compared with competitive baselines. According to the qualitative evaluation and case study, our model outperforms MotionDiffuse in generating spatially or chronologically composite motions, by learning the implicit mappings from fine-grained descriptions to the corresponding basic motions. We release our data at https://github.com/KunhangL/finemotiondiffuse.
Evaluating the Efficacy of Prompt-Engineered Large Multimodal Models Versus Fine-Tuned Vision Transformers in Image-Based Security Applications
Mar 26, 2024The success of Large Language Models (LLMs) has led to a parallel rise in the development of Large Multimodal Models (LMMs), such as Gemini-pro, which have begun to transform a variety of applications. These sophisticated multimodal models are designed to interpret and analyze complex data, integrating both textual and visual information on a scale previously unattainable, opening new avenues for a range of applications. This paper investigates the applicability and effectiveness of prompt-engineered Gemini-pro LMMs versus fine-tuned Vision Transformer (ViT) models in addressing critical security challenges. We focus on two distinct tasks: a visually evident task of detecting simple triggers, such as small squares in images, indicative of potential backdoors, and a non-visually evident task of malware classification through visual representations. Our results highlight a significant divergence in performance, with Gemini-pro falling short in accuracy and reliability when compared to fine-tuned ViT models. The ViT models, on the other hand, demonstrate exceptional accuracy, achieving near-perfect performance on both tasks. This study not only showcases the strengths and limitations of prompt-engineered LMMs in cybersecurity applications but also emphasizes the unmatched efficacy of fine-tuned ViT models for precise and dependable tasks.
Enhancing Historical Image Retrieval with Compositional Cues
Mar 21, 2024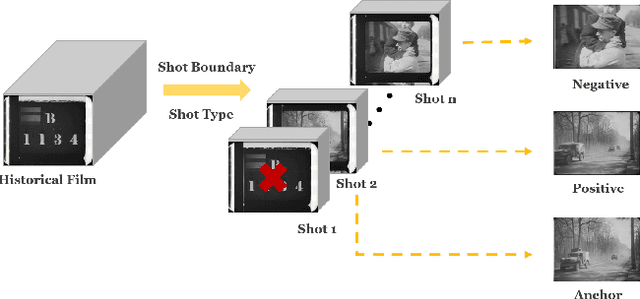

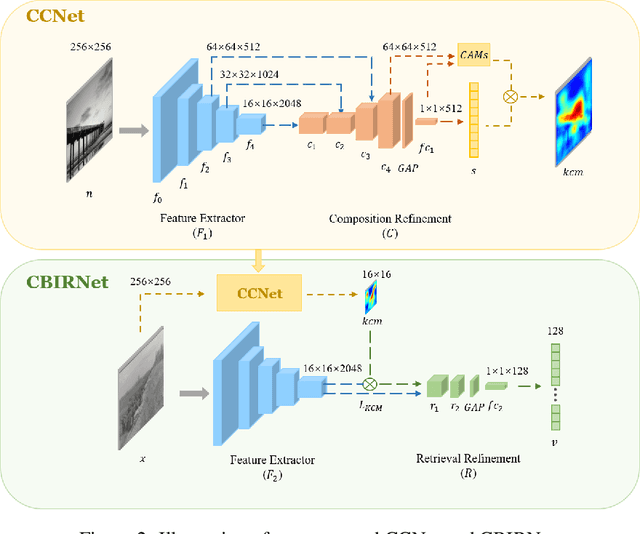
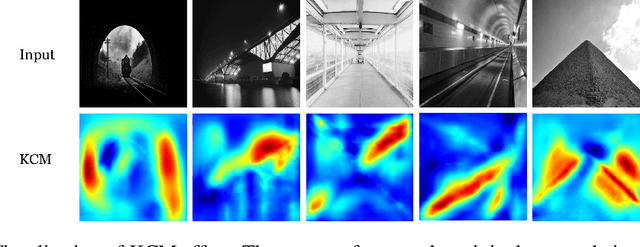
In analyzing vast amounts of digitally stored historical image data, existing content-based retrieval methods often overlook significant non-semantic information, limiting their effectiveness for flexible exploration across varied themes. To broaden the applicability of image retrieval methods for diverse purposes and uncover more general patterns, we innovatively introduce a crucial factor from computational aesthetics, namely image composition, into this topic. By explicitly integrating composition-related information extracted by CNN into the designed retrieval model, our method considers both the image's composition rules and semantic information. Qualitative and quantitative experiments demonstrate that the image retrieval network guided by composition information outperforms those relying solely on content information, facilitating the identification of images in databases closer to the target image in human perception. Please visit https://github.com/linty5/CCBIR to try our codes.
Revisiting the Sleeping Beauty problem
Mar 25, 2024The Sleeping Beauty problem is a probability riddle with no definite solution for more than two decades and its solution is of great interest in many fields of knowledge. There are two main competing solutions to the problem: the halfer approach, and the thirder approach. The main reason for disagreement in the literature is connected to the use of different probability spaces to represent the same probabilistic riddle. In this work, we analyse the problem from a mathematical perspective, identifying probability distributions induced directly from the thought experiment's rules. The precise choices of probability spaces provide both halfer and thirder solutions to the problem. To try and decide on which approach to follow, a criterion involving the information available to Sleeping Beauty is proposed.
REFRAME: Reflective Surface Real-Time Rendering for Mobile Devices
Mar 25, 2024This work tackles the challenging task of achieving real-time novel view synthesis on various scenes, including highly reflective objects and unbounded outdoor scenes. Existing real-time rendering methods, especially those based on meshes, often have subpar performance in modeling surfaces with rich view-dependent appearances. Our key idea lies in leveraging meshes for rendering acceleration while incorporating a novel approach to parameterize view-dependent information. We decompose the color into diffuse and specular, and model the specular color in the reflected direction based on a neural environment map. Our experiments demonstrate that our method achieves comparable reconstruction quality for highly reflective surfaces compared to state-of-the-art offline methods, while also efficiently enabling real-time rendering on edge devices such as smartphones.