 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Scribble-based 3D Multiple Abdominal Organ Segmentation via Triple-branch Multi-dilated Network with Pixel- and Class-wise Consistency
Sep 18, 2023
Multi-organ segmentation in abdominal Computed Tomography (CT) images is of great importance for diagnosis of abdominal lesions and subsequent treatment planning. Though deep learning based methods have attained high performance, they rely heavily on large-scale pixel-level annotations that are time-consuming and labor-intensive to obtain. Due to its low dependency on annotation, weakly supervised segmentation has attracted great attention. However, there is still a large performance gap between current weakly-supervised methods and fully supervised learning, leaving room for exploration. In this work, we propose a novel 3D framework with two consistency constraints for scribble-supervised multiple abdominal organ segmentation from CT. Specifically, we employ a Triple-branch multi-Dilated network (TDNet) with one encoder and three decoders using different dilation rates to capture features from different receptive fields that are complementary to each other to generate high-quality soft pseudo labels. For more stable unsupervised learning, we use voxel-wise uncertainty to rectify the soft pseudo labels and then supervise the outputs of each decoder. To further regularize the network, class relationship information is exploited by encouraging the generated class affinity matrices to be consistent across different decoders under multi-view projection. Experiments on the public WORD dataset show that our method outperforms five existing scribble-supervised methods.
Stochastic Deep Koopman Model for Quality Propagation Analysis in Multistage Manufacturing Systems
Sep 18, 2023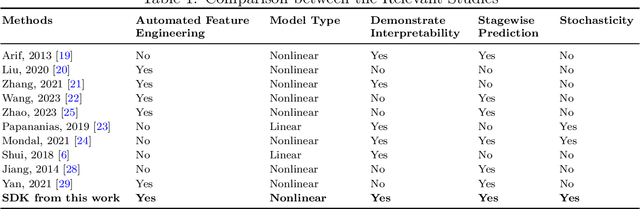
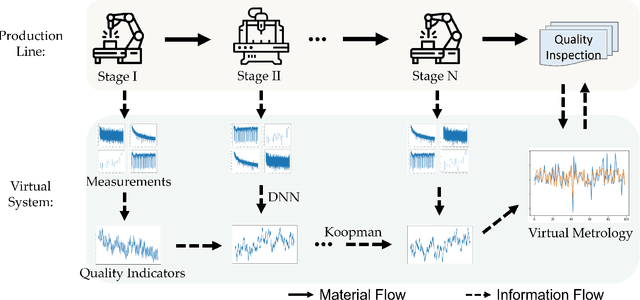
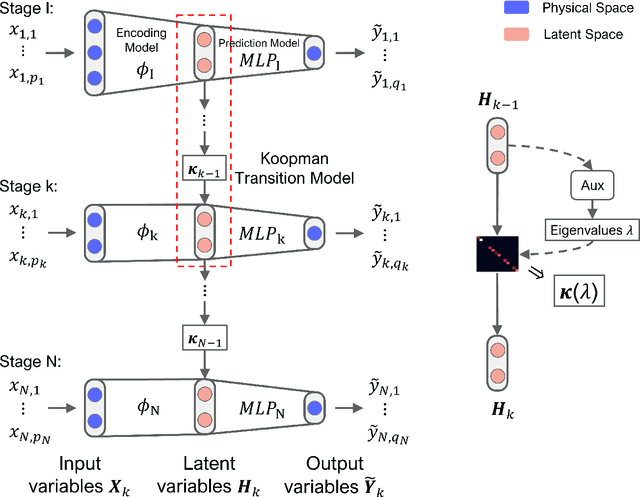
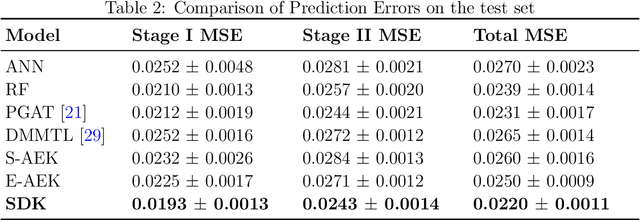
The modeling of multistage manufacturing systems (MMSs) has attracted increased attention from both academia and industry. Recent advancements in deep learning methods provide an opportunity to accomplish this task with reduced cost and expertise. This study introduces a stochastic deep Koopman (SDK) framework to model the complex behavior of MMSs. Specifically, we present a novel application of Koopman operators to propagate critical quality information extracted by variational autoencoders. Through this framework, we can effectively capture the general nonlinear evolution of product quality using a transferred linear representation, thus enhancing the interpretability of the data-driven model. To evaluate the performance of the SDK framework, we carried out a comparative study on an open-source dataset. The main findings of this paper are as follows. Our results indicate that SDK surpasses other popular data-driven models in accuracy when predicting stagewise product quality within the MMS. Furthermore, the unique linear propagation property in the stochastic latent space of SDK enables traceability for quality evolution throughout the process, thereby facilitating the design of root cause analysis schemes. Notably, the proposed framework requires minimal knowledge of the underlying physics of production lines. It serves as a virtual metrology tool that can be applied to various MMSs, contributing to the ultimate goal of Zero Defect Manufacturing.
Securing Fixed Neural Network Steganography
Sep 18, 2023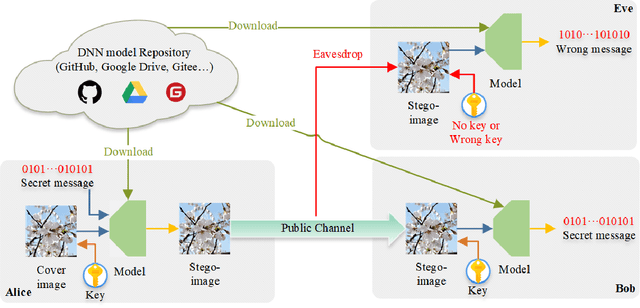

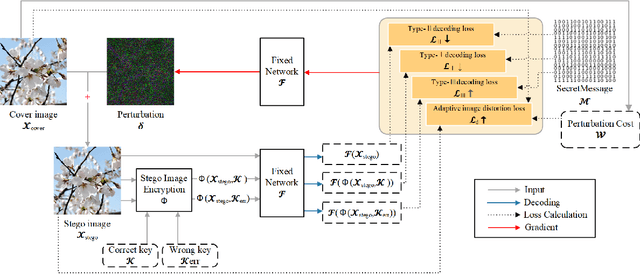
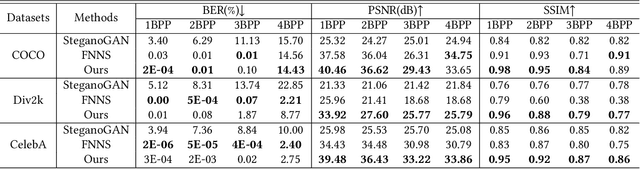
Image steganography is the art of concealing secret information in images in a way that is imperceptible to unauthorized parties. Recent advances show that is possible to use a fixed neural network (FNN) for secret embedding and extraction. Such fixed neural network steganography (FNNS) achieves high steganographic performance without training the networks, which could be more useful in real-world applications. However, the existing FNNS schemes are vulnerable in the sense that anyone can extract the secret from the stego-image. To deal with this issue, we propose a key-based FNNS scheme to improve the security of the FNNS, where we generate key-controlled perturbations from the FNN for data embedding. As such, only the receiver who possesses the key is able to correctly extract the secret from the stego-image using the FNN. In order to improve the visual quality and undetectability of the stego-image, we further propose an adaptive perturbation optimization strategy by taking the perturbation cost into account. Experimental results show that our proposed scheme is capable of preventing unauthorized secret extraction from the stego-images. Furthermore, our scheme is able to generate stego-images with higher visual quality than the state-of-the-art FNNS scheme, especially when the FNN is a neural network for ordinary learning tasks.
Double Deep Q-Learning-based Path Selection and Service Placement for Latency-Sensitive Beyond 5G Applications
Sep 18, 2023Nowadays, as the need for capacity continues to grow, entirely novel services are emerging. A solid cloud-network integrated infrastructure is necessary to supply these services in a real-time responsive, and scalable way. Due to their diverse characteristics and limited capacity, communication and computing resources must be collaboratively managed to unleash their full potential. Although several innovative methods have been proposed to orchestrate the resources, most ignored network resources or relaxed the network as a simple graph, focusing only on cloud resources. This paper fills the gap by studying the joint problem of communication and computing resource allocation, dubbed CCRA, including function placement and assignment, traffic prioritization, and path selection considering capacity constraints and quality requirements, to minimize total cost. We formulate the problem as a non-linear programming model and propose two approaches, dubbed B\&B-CCRA and WF-CCRA, based on the Branch \& Bound and Water-Filling algorithms to solve it when the system is fully known. Then, for partially known systems, a Double Deep Q-Learning (DDQL) architecture is designed. Numerical simulations show that B\&B-CCRA optimally solves the problem, whereas WF-CCRA delivers near-optimal solutions in a substantially shorter time. Furthermore, it is demonstrated that DDQL-CCRA obtains near-optimal solutions in the absence of request-specific information.
Effects of Explanation Strategies to Resolve Failures in Human-Robot Collaboration
Sep 18, 2023

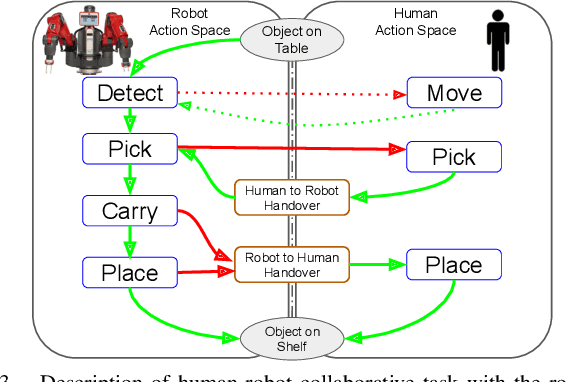
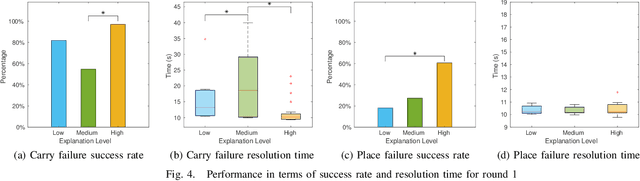
Despite significant improvements in robot capabilities, they are likely to fail in human-robot collaborative tasks due to high unpredictability in human environments and varying human expectations. In this work, we explore the role of explanation of failures by a robot in a human-robot collaborative task. We present a user study incorporating common failures in collaborative tasks with human assistance to resolve the failure. In the study, a robot and a human work together to fill a shelf with objects. Upon encountering a failure, the robot explains the failure and the resolution to overcome the failure, either through handovers or humans completing the task. The study is conducted using different levels of robotic explanation based on the failure action, failure cause, and action history, and different strategies in providing the explanation over the course of repeated interaction. Our results show that the success in resolving the failures is not only a function of the level of explanation but also the type of failures. Furthermore, while novice users rate the robot higher overall in terms of their satisfaction with the explanation, their satisfaction is not only a function of the robot's explanation level at a certain round but also the prior information they received from the robot.
Adaptive Reorganization of Neural Pathways for Continual Learning with Hybrid Spiking Neural Networks
Sep 18, 2023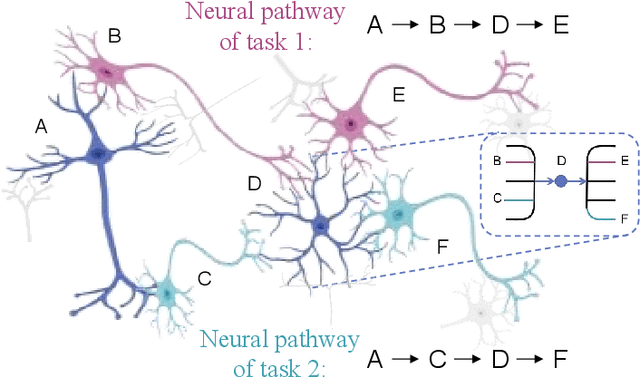
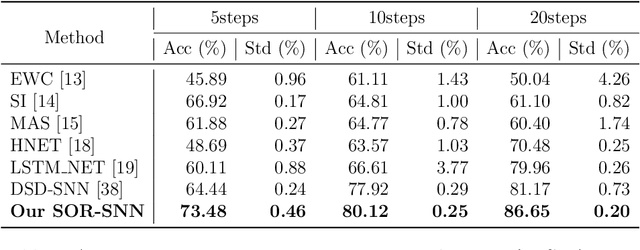
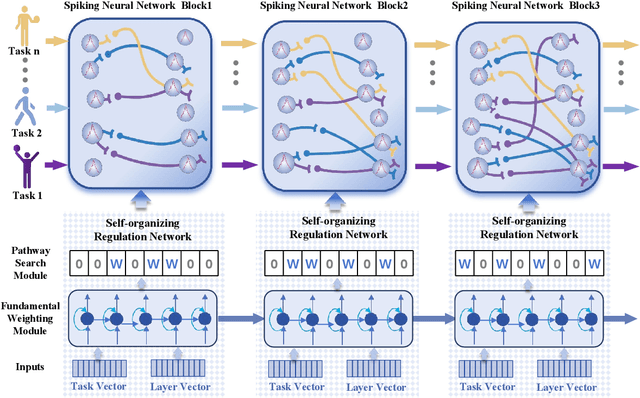
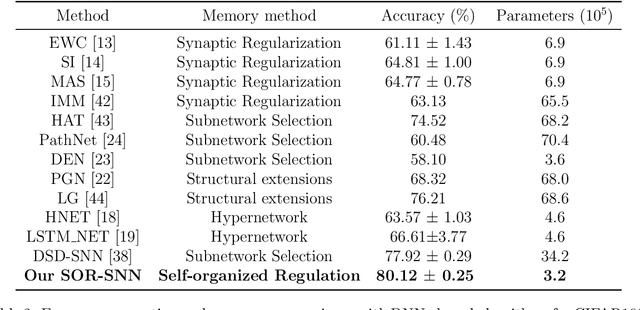
The human brain can self-organize rich and diverse sparse neural pathways to incrementally master hundreds of cognitive tasks. However, most existing continual learning algorithms for deep artificial and spiking neural networks are unable to adequately auto-regulate the limited resources in the network, which leads to performance drop along with energy consumption rise as the increase of tasks. In this paper, we propose a brain-inspired continual learning algorithm with adaptive reorganization of neural pathways, which employs Self-Organizing Regulation networks to reorganize the single and limited Spiking Neural Network (SOR-SNN) into rich sparse neural pathways to efficiently cope with incremental tasks. The proposed model demonstrates consistent superiority in performance, energy consumption, and memory capacity on diverse continual learning tasks ranging from child-like simple to complex tasks, as well as on generalized CIFAR100 and ImageNet datasets. In particular, the SOR-SNN model excels at learning more complex tasks as well as more tasks, and is able to integrate the past learned knowledge with the information from the current task, showing the backward transfer ability to facilitate the old tasks. Meanwhile, the proposed model exhibits self-repairing ability to irreversible damage and for pruned networks, could automatically allocate new pathway from the retained network to recover memory for forgotten knowledge.
Muti-Stage Hierarchical Food Classification
Sep 03, 2023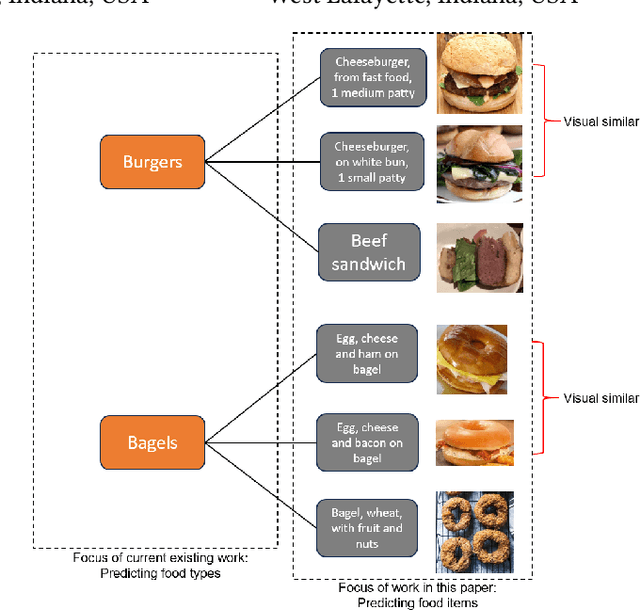
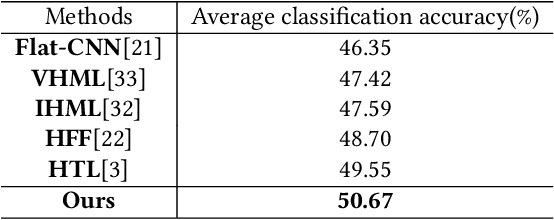
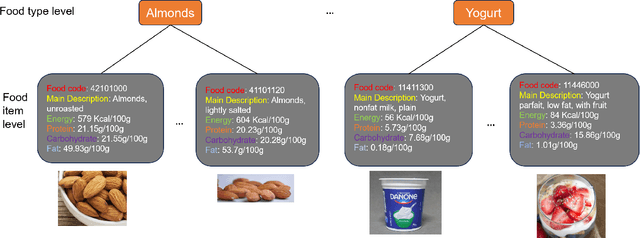
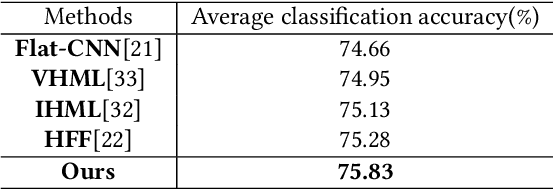
Food image classification serves as a fundamental and critical step in image-based dietary assessment, facilitating nutrient intake analysis from captured food images. However, existing works in food classification predominantly focuses on predicting 'food types', which do not contain direct nutritional composition information. This limitation arises from the inherent discrepancies in nutrition databases, which are tasked with associating each 'food item' with its respective information. Therefore, in this work we aim to classify food items to align with nutrition database. To this end, we first introduce VFN-nutrient dataset by annotating each food image in VFN with a food item that includes nutritional composition information. Such annotation of food items, being more discriminative than food types, creates a hierarchical structure within the dataset. However, since the food item annotations are solely based on nutritional composition information, they do not always show visual relations with each other, which poses significant challenges when applying deep learning-based techniques for classification. To address this issue, we then propose a multi-stage hierarchical framework for food item classification by iteratively clustering and merging food items during the training process, which allows the deep model to extract image features that are discriminative across labels. Our method is evaluated on VFN-nutrient dataset and achieve promising results compared with existing work in terms of both food type and food item classification.
PreprintResolver: Improving Citation Quality by Resolving Published Versions of ArXiv Preprints using Literature Databases
Sep 04, 2023The growing impact of preprint servers enables the rapid sharing of time-sensitive research. Likewise, it is becoming increasingly difficult to distinguish high-quality, peer-reviewed research from preprints. Although preprints are often later published in peer-reviewed journals, this information is often missing from preprint servers. To overcome this problem, the PreprintResolver was developed, which uses four literature databases (DBLP, SemanticScholar, OpenAlex, and CrossRef / CrossCite) to identify preprint-publication pairs for the arXiv preprint server. The target audience focuses on, but is not limited to inexperienced researchers and students, especially from the field of computer science. The tool is based on a fuzzy matching of author surnames, titles, and DOIs. Experiments were performed on a sample of 1,000 arXiv-preprints from the research field of computer science and without any publication information. With 77.94 %, computer science is highly affected by missing publication information in arXiv. The results show that the PreprintResolver was able to resolve 603 out of 1,000 (60.3 %) arXiv-preprints from the research field of computer science and without any publication information. All four literature databases contributed to the final result. In a manual validation, a random sample of 100 resolved preprints was checked. For all preprints, at least one result is plausible. For nine preprints, more than one result was identified, three of which are partially invalid. In conclusion the PreprintResolver is suitable for individual, manually reviewed requests, but less suitable for bulk requests. The PreprintResolver tool (https://preprintresolver.eu, Available from 2023-08-01) and source code (https://gitlab.com/ippolis_wp3/preprint-resolver, Accessed: 2023-07-19) is available online.
Detecting Violations of Differential Privacy for Quantum Algorithms
Sep 09, 2023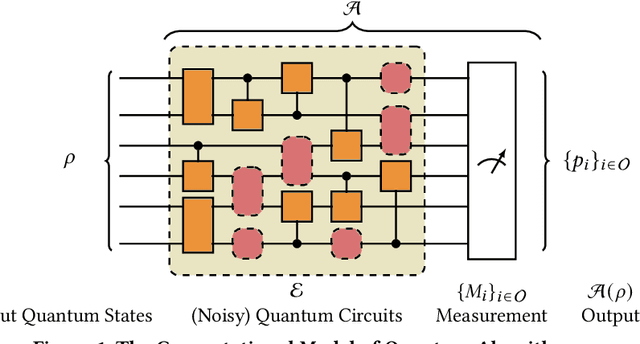
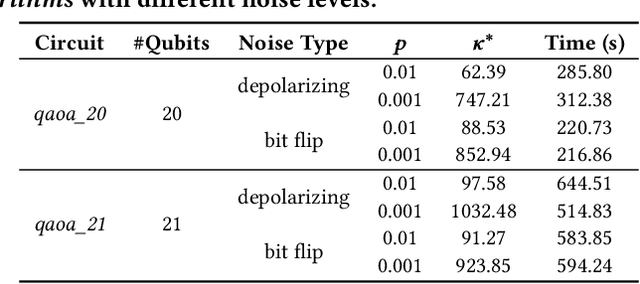
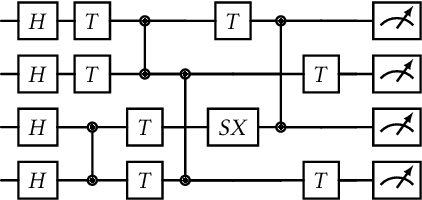
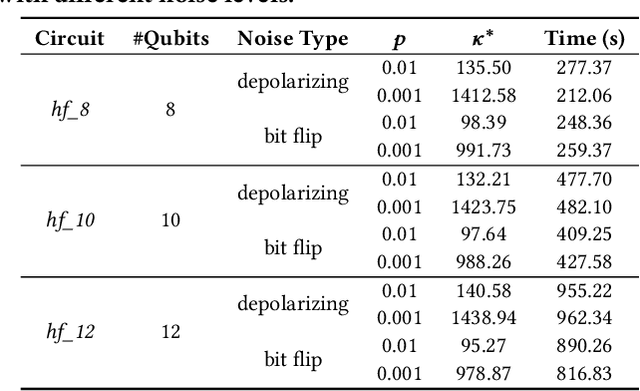
Quantum algorithms for solving a wide range of practical problems have been proposed in the last ten years, such as data search and analysis, product recommendation, and credit scoring. The concern about privacy and other ethical issues in quantum computing naturally rises up. In this paper, we define a formal framework for detecting violations of differential privacy for quantum algorithms. A detection algorithm is developed to verify whether a (noisy) quantum algorithm is differentially private and automatically generate bugging information when the violation of differential privacy is reported. The information consists of a pair of quantum states that violate the privacy, to illustrate the cause of the violation. Our algorithm is equipped with Tensor Networks, a highly efficient data structure, and executed both on TensorFlow Quantum and TorchQuantum which are the quantum extensions of famous machine learning platforms -- TensorFlow and PyTorch, respectively. The effectiveness and efficiency of our algorithm are confirmed by the experimental results of almost all types of quantum algorithms already implemented on realistic quantum computers, including quantum supremacy algorithms (beyond the capability of classical algorithms), quantum machine learning models, quantum approximate optimization algorithms, and variational quantum eigensolvers with up to 21 quantum bits.
Towards Real-World Burst Image Super-Resolution: Benchmark and Method
Sep 09, 2023
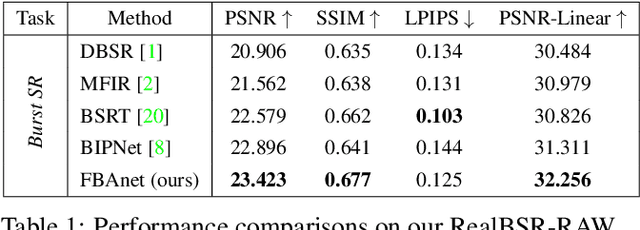
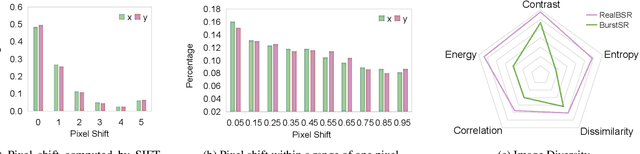
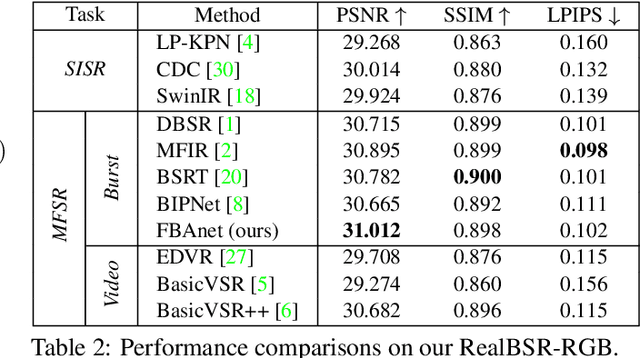
Despite substantial advances, single-image super-resolution (SISR) is always in a dilemma to reconstruct high-quality images with limited information from one input image, especially in realistic scenarios. In this paper, we establish a large-scale real-world burst super-resolution dataset, i.e., RealBSR, to explore the faithful reconstruction of image details from multiple frames. Furthermore, we introduce a Federated Burst Affinity network (FBAnet) to investigate non-trivial pixel-wise displacements among images under real-world image degradation. Specifically, rather than using pixel-wise alignment, our FBAnet employs a simple homography alignment from a structural geometry aspect and a Federated Affinity Fusion (FAF) strategy to aggregate the complementary information among frames. Those fused informative representations are fed to a Transformer-based module of burst representation decoding. Besides, we have conducted extensive experiments on two versions of our datasets, i.e., RealBSR-RAW and RealBSR-RGB. Experimental results demonstrate that our FBAnet outperforms existing state-of-the-art burst SR methods and also achieves visually-pleasant SR image predictions with model details. Our dataset, codes, and models are publicly available at https://github.com/yjsunnn/FBANet.