 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fin-Fact: A Benchmark Dataset for Multimodal Financial Fact Checking and Explanation Generation
Sep 15, 2023
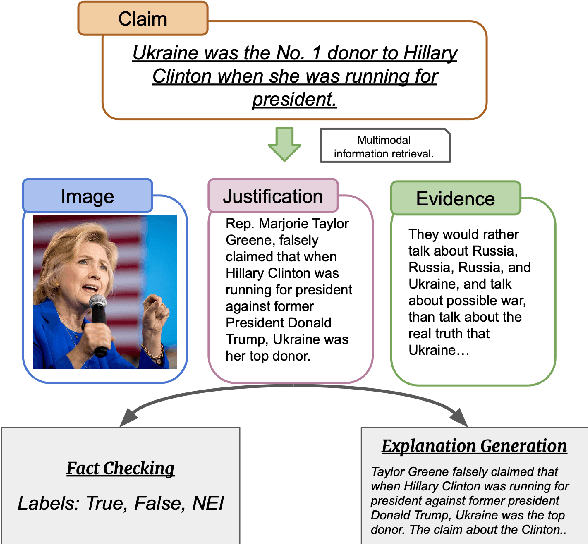

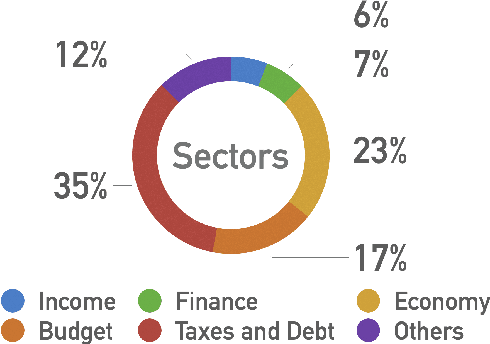
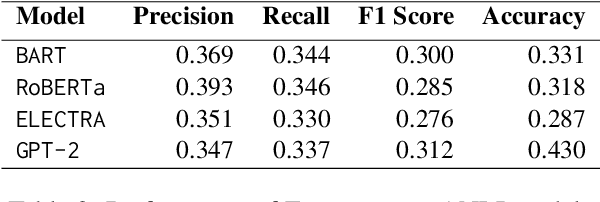
Fact-checking in financial domain is under explored, and there is a shortage of quality dataset in this domain. In this paper, we propose Fin-Fact, a benchmark dataset for multimodal fact-checking within the financial domain. Notably, it includes professional fact-checker annotations and justifications, providing expertise and credibility. With its multimodal nature encompassing both textual and visual content, Fin-Fact provides complementary information sources to enhance factuality analysis. Its primary objective is combating misinformation in finance, fostering transparency, and building trust in financial reporting and news dissemination. By offering insightful explanations, Fin-Fact empowers users, including domain experts and end-users, to understand the reasoning behind fact-checking decisions, validating claim credibility, and fostering trust in the fact-checking process. The Fin-Fact dataset, along with our experimental codes is available at https://github.com/IIT-DM/Fin-Fact/.
Benchmarks for Pirá 2.0, a Reading Comprehension Dataset about the Ocean, the Brazilian Coast, and Climate Change
Sep 19, 2023Pir\'a is a reading comprehension dataset focused on the ocean, the Brazilian coast, and climate change, built from a collection of scientific abstracts and reports on these topics. This dataset represents a versatile language resource, particularly useful for testing the ability of current machine learning models to acquire expert scientific knowledge. Despite its potential, a detailed set of baselines has not yet been developed for Pir\'a. By creating these baselines, researchers can more easily utilize Pir\'a as a resource for testing machine learning models across a wide range of question answering tasks. In this paper, we define six benchmarks over the Pir\'a dataset, covering closed generative question answering, machine reading comprehension, information retrieval, open question answering, answer triggering, and multiple choice question answering. As part of this effort, we have also produced a curated version of the original dataset, where we fixed a number of grammar issues, repetitions, and other shortcomings. Furthermore, the dataset has been extended in several new directions, so as to face the aforementioned benchmarks: translation of supporting texts from English into Portuguese, classification labels for answerability, automatic paraphrases of questions and answers, and multiple choice candidates. The results described in this paper provide several points of reference for researchers interested in exploring the challenges provided by the Pir\'a dataset.
Long-term drought prediction using deep neural networks based on geospatial weather data
Sep 19, 2023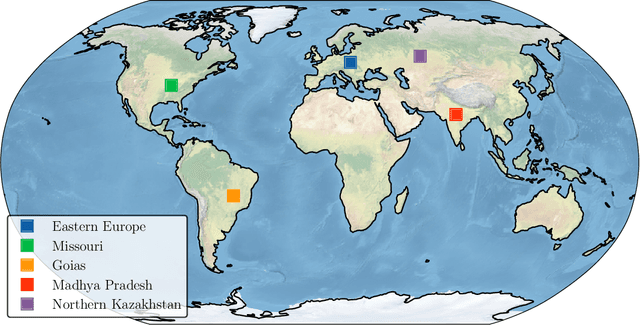
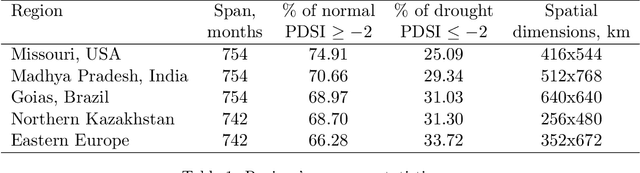
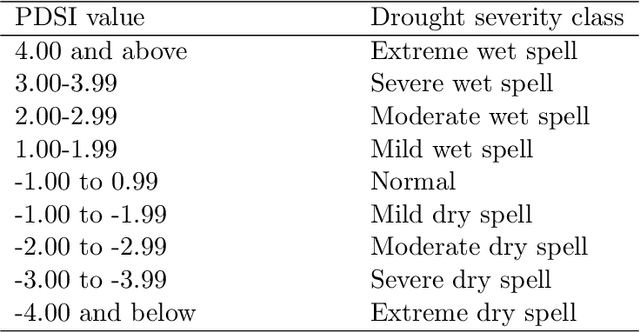
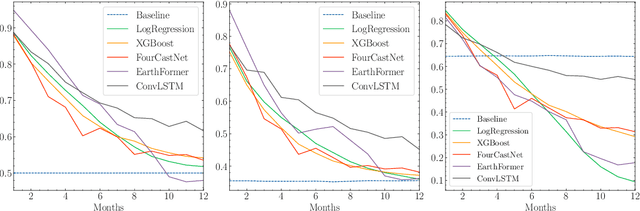
The accurate prediction of drought probability in specific regions is crucial for informed decision-making in agricultural practices. It is important to make predictions one year in advance, particularly for long-term decisions. However, forecasting this probability presents challenges due to the complex interplay of various factors within the region of interest and neighboring areas. In this study, we propose an end-to-end solution to address this issue based on various spatiotemporal neural networks. The models considered focus on predicting the drought intensity based on the Palmer Drought Severity Index (PDSI) for subregions of interest, leveraging intrinsic factors and insights from climate models to enhance drought predictions. Comparative evaluations demonstrate the superior accuracy of Convolutional LSTM (ConvLSTM) and transformer models compared to baseline gradient boosting and logistic regression solutions. The two former models achieved impressive ROC AUC scores from 0.90 to 0.70 for forecast horizons from one to six months, outperforming baseline models. The transformer showed superiority for shorter horizons, while ConvLSTM did so for longer horizons. Thus, we recommend selecting the models accordingly for long-term drought forecasting. To ensure the broad applicability of the considered models, we conduct extensive validation across regions worldwide, considering different environmental conditions. We also run several ablation and sensitivity studies to challenge our findings and provide additional information on how to solve the problem.
A Blueprint for Precise and Fault-Tolerant Analog Neural Networks
Sep 19, 2023Analog computing has reemerged as a promising avenue for accelerating deep neural networks (DNNs) due to its potential to overcome the energy efficiency and scalability challenges posed by traditional digital architectures. However, achieving high precision and DNN accuracy using such technologies is challenging, as high-precision data converters are costly and impractical. In this paper, we address this challenge by using the residue number system (RNS). RNS allows composing high-precision operations from multiple low-precision operations, thereby eliminating the information loss caused by the limited precision of the data converters. Our study demonstrates that analog accelerators utilizing the RNS-based approach can achieve ${\geq}99\%$ of FP32 accuracy for state-of-the-art DNN inference using data converters with only $6$-bit precision whereas a conventional analog core requires more than $8$-bit precision to achieve the same accuracy in the same DNNs. The reduced precision requirements imply that using RNS can reduce the energy consumption of analog accelerators by several orders of magnitude while maintaining the same throughput and precision. Our study extends this approach to DNN training, where we can efficiently train DNNs using $7$-bit integer arithmetic while achieving accuracy comparable to FP32 precision. Lastly, we present a fault-tolerant dataflow using redundant RNS error-correcting codes to protect the computation against noise and errors inherent within an analog accelerator.
Implementing a new fully stepwise decomposition-based sampling technique for the hybrid water level forecasting model in real-world application
Sep 19, 2023Various time variant non-stationary signals need to be pre-processed properly in hydrological time series forecasting in real world, for example, predictions of water level. Decomposition method is a good candidate and widely used in such a pre-processing problem. However, decomposition methods with an inappropriate sampling technique may introduce future data which is not available in practical applications, and result in incorrect decomposition-based forecasting models. In this work, a novel Fully Stepwise Decomposition-Based (FSDB) sampling technique is well designed for the decomposition-based forecasting model, strictly avoiding introducing future information. This sampling technique with decomposition methods, such as Variational Mode Decomposition (VMD) and Singular spectrum analysis (SSA), is applied to predict water level time series in three different stations of Guoyang and Chaohu basins in China. Results of VMD-based hybrid model using FSDB sampling technique show that Nash-Sutcliffe Efficiency (NSE) coefficient is increased by 6.4%, 28.8% and 7.0% in three stations respectively, compared with those obtained from the currently most advanced sampling technique. In the meantime, for series of SSA-based experiments, NSE is increased by 3.2%, 3.1% and 1.1% respectively. We conclude that the newly developed FSDB sampling technique can be used to enhance the performance of decomposition-based hybrid model in water level time series forecasting in real world.
Augmenting Tactile Simulators with Real-like and Zero-Shot Capabilities
Sep 19, 2023Simulating tactile perception could potentially leverage the learning capabilities of robotic systems in manipulation tasks. However, the reality gap of simulators for high-resolution tactile sensors remains large. Models trained on simulated data often fail in zero-shot inference and require fine-tuning with real data. In addition, work on high-resolution sensors commonly focus on ones with flat surfaces while 3D round sensors are essential for dexterous manipulation. In this paper, we propose a bi-directional Generative Adversarial Network (GAN) termed SightGAN. SightGAN relies on the early CycleGAN while including two additional loss components aimed to accurately reconstruct background and contact patterns including small contact traces. The proposed SightGAN learns real-to-sim and sim-to-real processes over difference images. It is shown to generate real-like synthetic images while maintaining accurate contact positioning. The generated images can be used to train zero-shot models for newly fabricated sensors. Consequently, the resulted sim-to-real generator could be built on top of the tactile simulator to provide a real-world framework. Potentially, the framework can be used to train, for instance, reinforcement learning policies of manipulation tasks. The proposed model is verified in extensive experiments with test data collected from real sensors and also shown to maintain embedded force information within the tactile images.
Sample-adaptive Augmentation for Point Cloud Recognition Against Real-world Corruptions
Sep 19, 2023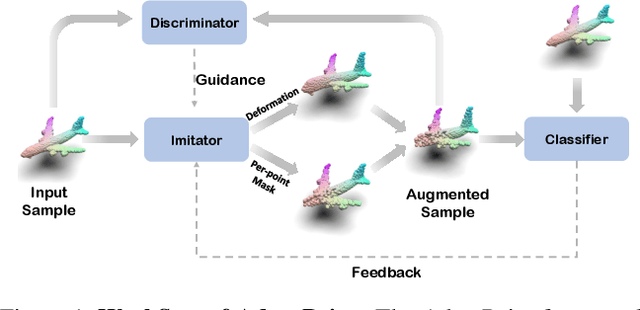
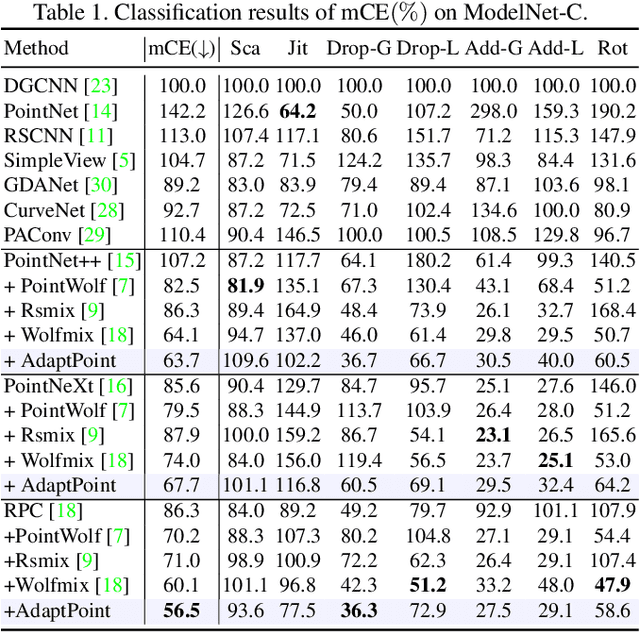
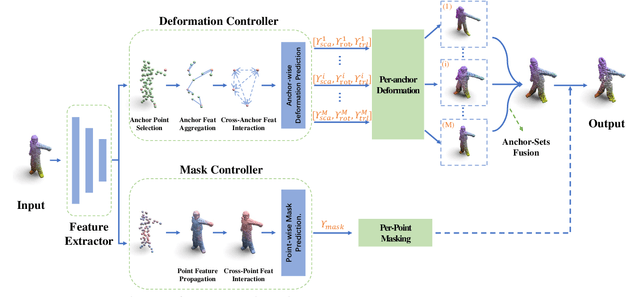

Robust 3D perception under corruption has become an essential task for the realm of 3D vision. While current data augmentation techniques usually perform random transformations on all point cloud objects in an offline way and ignore the structure of the samples, resulting in over-or-under enhancement. In this work, we propose an alternative to make sample-adaptive transformations based on the structure of the sample to cope with potential corruption via an auto-augmentation framework, named as AdaptPoint. Specially, we leverage a imitator, consisting of a Deformation Controller and a Mask Controller, respectively in charge of predicting deformation parameters and producing a per-point mask, based on the intrinsic structural information of the input point cloud, and then conduct corruption simulations on top. Then a discriminator is utilized to prevent the generation of excessive corruption that deviates from the original data distribution. In addition, a perception-guidance feedback mechanism is incorporated to guide the generation of samples with appropriate difficulty level. Furthermore, to address the paucity of real-world corrupted point cloud, we also introduce a new dataset ScanObjectNN-C, that exhibits greater similarity to actual data in real-world environments, especially when contrasted with preceding CAD datasets. Experiments show that our method achieves state-of-the-art results on multiple corruption benchmarks, including ModelNet-C, our ScanObjectNN-C, and ShapeNet-C.
RoadFormer: Duplex Transformer for RGB-Normal Semantic Road Scene Parsing
Sep 19, 2023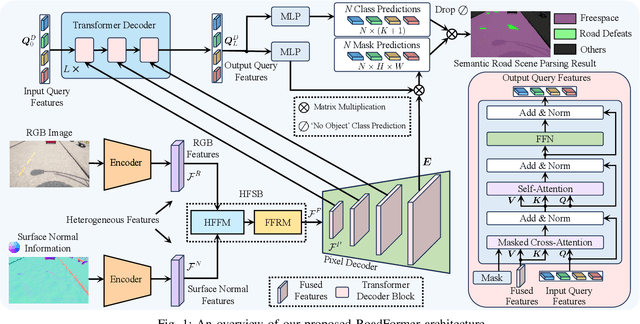
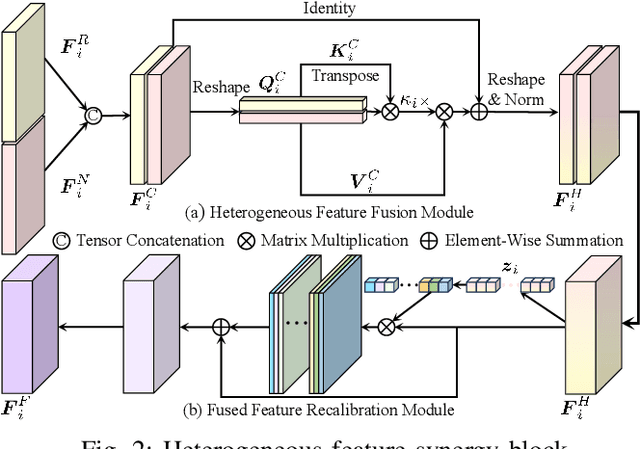
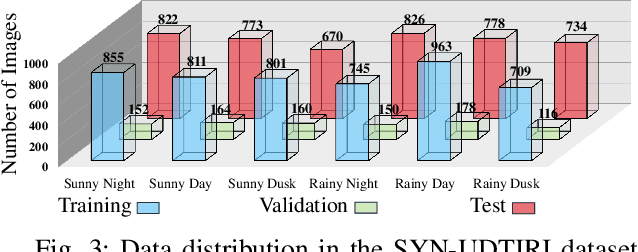

The recent advancements in deep convolutional neural networks have shown significant promise in the domain of road scene parsing. Nevertheless, the existing works focus primarily on freespace detection, with little attention given to hazardous road defects that could compromise both driving safety and comfort. In this paper, we introduce RoadFormer, a novel Transformer-based data-fusion network developed for road scene parsing. RoadFormer utilizes a duplex encoder architecture to extract heterogeneous features from both RGB images and surface normal information. The encoded features are subsequently fed into a novel heterogeneous feature synergy block for effective feature fusion and recalibration. The pixel decoder then learns multi-scale long-range dependencies from the fused and recalibrated heterogeneous features, which are subsequently processed by a Transformer decoder to produce the final semantic prediction. Additionally, we release SYN-UDTIRI, the first large-scale road scene parsing dataset that contains over 10,407 RGB images, dense depth images, and the corresponding pixel-level annotations for both freespace and road defects of different shapes and sizes. Extensive experimental evaluations conducted on our SYN-UDTIRI dataset, as well as on three public datasets, including KITTI road, CityScapes, and ORFD, demonstrate that RoadFormer outperforms all other state-of-the-art networks for road scene parsing. Specifically, RoadFormer ranks first on the KITTI road benchmark. Our source code, created dataset, and demo video are publicly available at mias.group/RoadFormer.
Edge-aware Feature Aggregation Network for Polyp Segmentation
Sep 19, 2023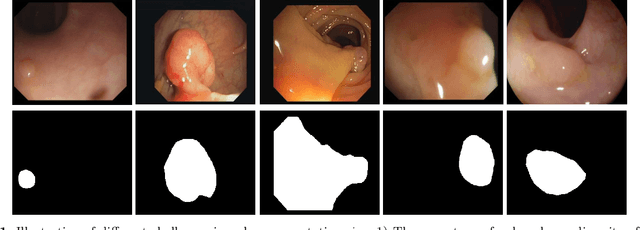
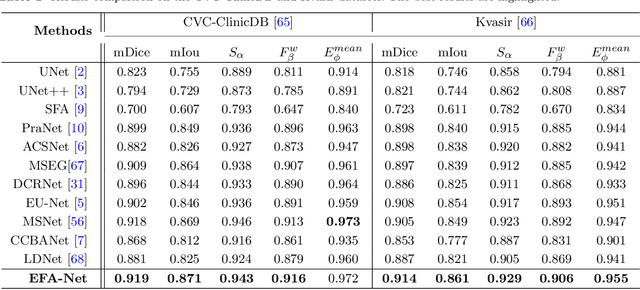
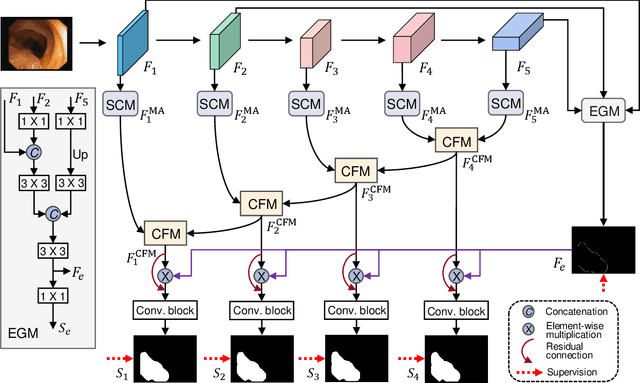
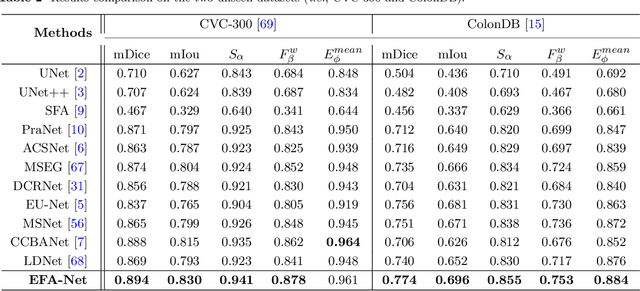
Precise polyp segmentation is vital for the early diagnosis and prevention of colorectal cancer (CRC) in clinical practice. However, due to scale variation and blurry polyp boundaries, it is still a challenging task to achieve satisfactory segmentation performance with different scales and shapes. In this study, we present a novel Edge-aware Feature Aggregation Network (EFA-Net) for polyp segmentation, which can fully make use of cross-level and multi-scale features to enhance the performance of polyp segmentation. Specifically, we first present an Edge-aware Guidance Module (EGM) to combine the low-level features with the high-level features to learn an edge-enhanced feature, which is incorporated into each decoder unit using a layer-by-layer strategy. Besides, a Scale-aware Convolution Module (SCM) is proposed to learn scale-aware features by using dilated convolutions with different ratios, in order to effectively deal with scale variation. Further, a Cross-level Fusion Module (CFM) is proposed to effectively integrate the cross-level features, which can exploit the local and global contextual information. Finally, the outputs of CFMs are adaptively weighted by using the learned edge-aware feature, which are then used to produce multiple side-out segmentation maps. Experimental results on five widely adopted colonoscopy datasets show that our EFA-Net outperforms state-of-the-art polyp segmentation methods in terms of generalization and effectiveness.
Trade-Offs in Decentralized Multi-Antenna Architectures: Sparse Combining Modules for WAX Decomposition
Sep 08, 2023With the increase in the number of antennas at base stations (BSs), centralized multi-antenna architectures have encountered scalability problems from excessive interconnection bandwidth to the central processing unit (CPU), as well as increased processing complexity. Thus, research efforts have been directed towards finding decentralized receiver architectures where a part of the processing is performed at the antenna end (or close to it). A recent paper put forth an information-lossless trade-off between level of decentralization (inputs to CPU) and decentralized processing complexity (multiplications per antenna). This trade-off was obtained by studying a newly defined matrix decomposition--the WAX decomposition--which is directly related to the information-lossless processing that should to be applied in a general framework to exploit the trade-off. {The general framework consists of three stages: a set of decentralized filters, a linear combining module, and a processing matrix applied at the CPU; these three stages are linear transformations which can be identified with the three constituent matrices of the WAX decomposition. The previous work was unable to provide explicit constructions for linear combining modules which are valid for WAX decomposition, while it remarked the importance of these modules being sparse with 1s and 0s so they could be efficiently implemented using hardware accelerators.} In this work we present a number of constructions, as well as possible variations of them, for effectively defining linear combining modules which can be used in the WAX decomposition. Furthermore, we show how these structures facilitate decentralized calculation of the WAX decomposition for applying information-lossless processing in architectures with an arbitrary level of decentralization.
* 16 pages, 6 figures, accepted for publication at IEEE Transactions on Signal Processing