 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Contrastive Grouping with Transformer for Referring Image Segmentation
Sep 02, 2023
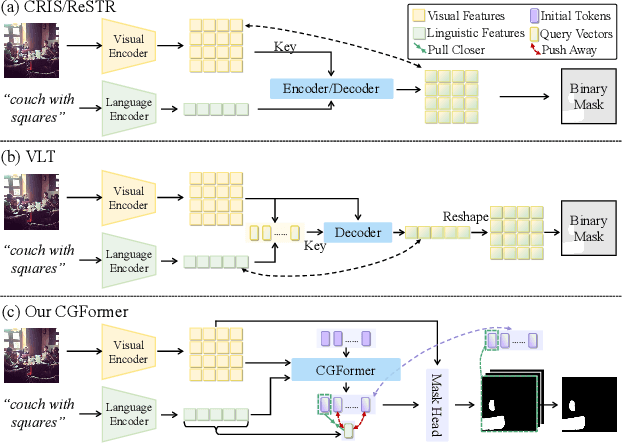
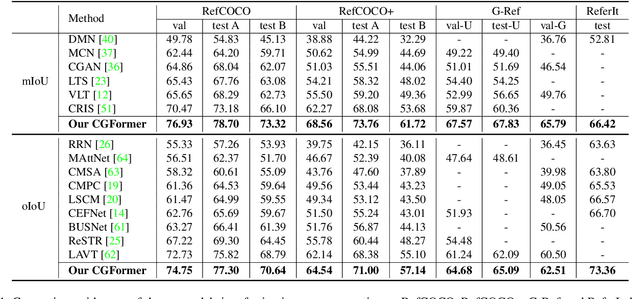
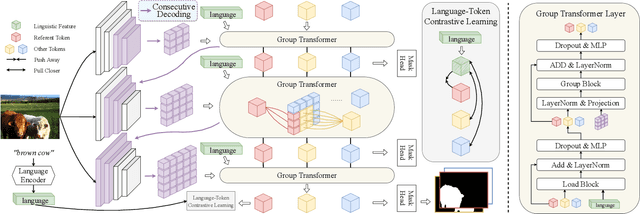
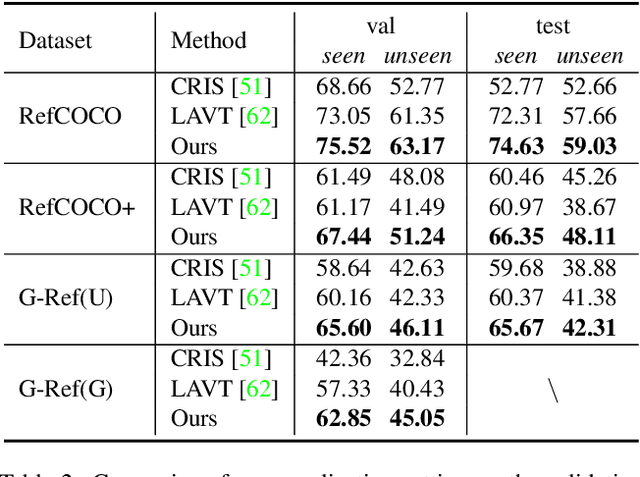
Referring image segmentation aims to segment the target referent in an image conditioning on a natural language expression. Existing one-stage methods employ per-pixel classification frameworks, which attempt straightforwardly to align vision and language at the pixel level, thus failing to capture critical object-level information. In this paper, we propose a mask classification framework, Contrastive Grouping with Transformer network (CGFormer), which explicitly captures object-level information via token-based querying and grouping strategy. Specifically, CGFormer first introduces learnable query tokens to represent objects and then alternately queries linguistic features and groups visual features into the query tokens for object-aware cross-modal reasoning. In addition, CGFormer achieves cross-level interaction by jointly updating the query tokens and decoding masks in every two consecutive layers. Finally, CGFormer cooperates contrastive learning to the grouping strategy to identify the token and its mask corresponding to the referent. Experimental results demonstrate that CGFormer outperforms state-of-the-art methods in both segmentation and generalization settings consistently and significantly.
AGent: A Novel Pipeline for Automatically Creating Unanswerable Questions
Sep 10, 2023
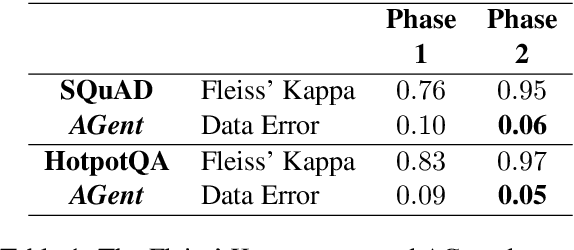
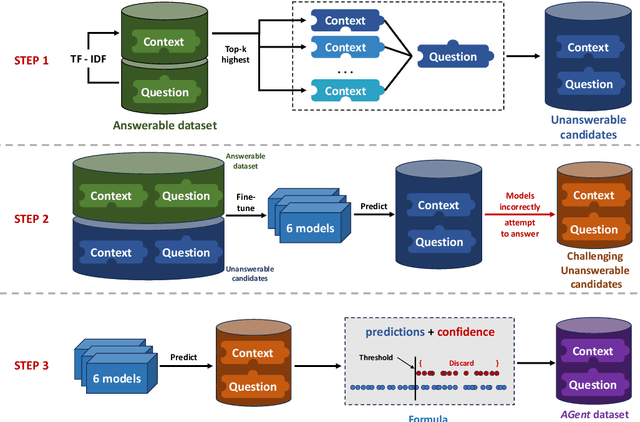
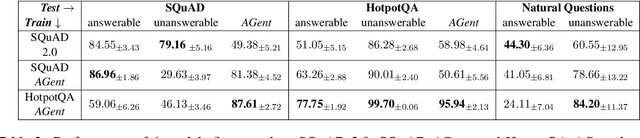
The development of large high-quality datasets and high-performing models have led to significant advancements in the domain of Extractive Question Answering (EQA). This progress has sparked considerable interest in exploring unanswerable questions within the EQA domain. Training EQA models with unanswerable questions helps them avoid extracting misleading or incorrect answers for queries that lack valid responses. However, manually annotating unanswerable questions is labor-intensive. To address this, we propose AGent, a novel pipeline that automatically creates new unanswerable questions by re-matching a question with a context that lacks the necessary information for a correct answer. In this paper, we demonstrate the usefulness of this AGent pipeline by creating two sets of unanswerable questions from answerable questions in SQuAD and HotpotQA. These created question sets exhibit low error rates. Additionally, models fine-tuned on these questions show comparable performance with those fine-tuned on the SQuAD 2.0 dataset on multiple EQA benchmarks.
3D Implicit Transporter for Temporally Consistent Keypoint Discovery
Sep 10, 2023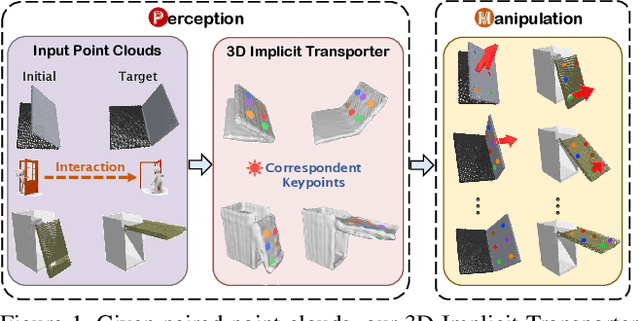
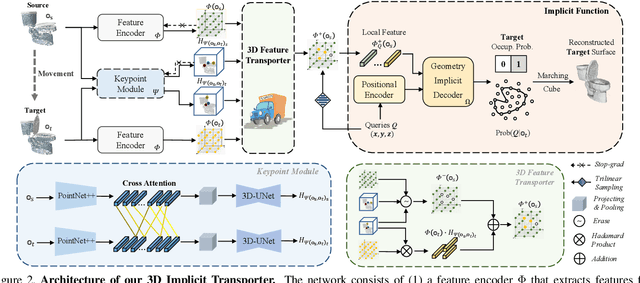
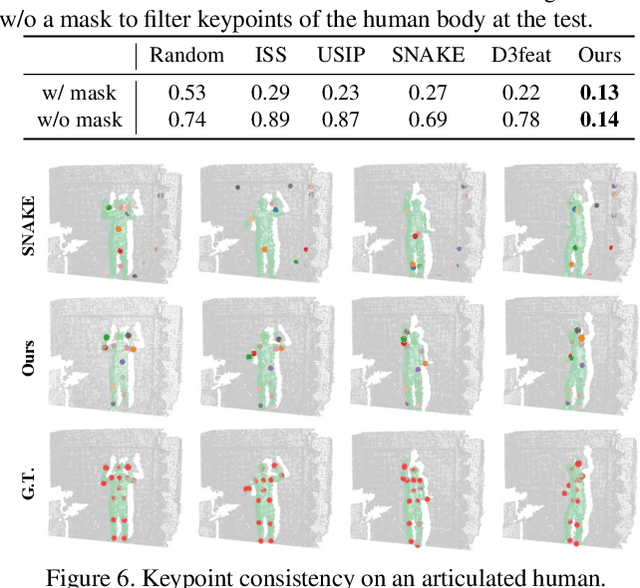
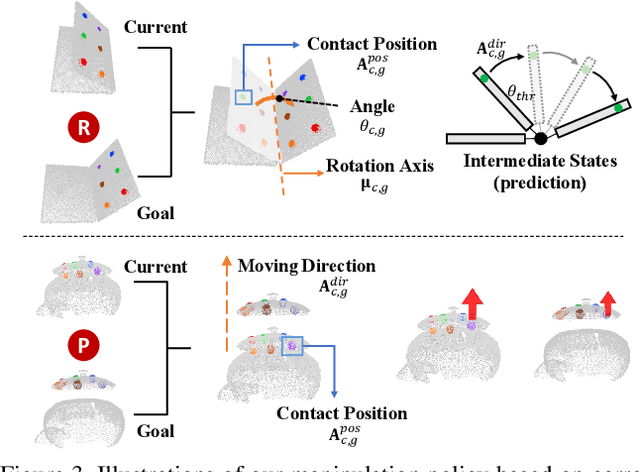
Keypoint-based representation has proven advantageous in various visual and robotic tasks. However, the existing 2D and 3D methods for detecting keypoints mainly rely on geometric consistency to achieve spatial alignment, neglecting temporal consistency. To address this issue, the Transporter method was introduced for 2D data, which reconstructs the target frame from the source frame to incorporate both spatial and temporal information. However, the direct application of the Transporter to 3D point clouds is infeasible due to their structural differences from 2D images. Thus, we propose the first 3D version of the Transporter, which leverages hybrid 3D representation, cross attention, and implicit reconstruction. We apply this new learning system on 3D articulated objects and nonrigid animals (humans and rodents) and show that learned keypoints are spatio-temporally consistent. Additionally, we propose a closed-loop control strategy that utilizes the learned keypoints for 3D object manipulation and demonstrate its superior performance. Codes are available at https://github.com/zhongcl-thu/3D-Implicit-Transporter.
Stable In-hand Manipulation with Finger Specific Multi-agent Shadow Reward
Sep 13, 2023Deep Reinforcement Learning has shown its capability to solve the high degrees of freedom in control and the complex interaction with the object in the multi-finger dexterous in-hand manipulation tasks. Current DRL approaches prefer sparse rewards to dense rewards for the ease of training but lack behavior constraints during the manipulation process, leading to aggressive and unstable policies that are insufficient for safety-critical in-hand manipulation tasks. Dense rewards can regulate the policy to learn stable manipulation behaviors with continuous reward constraints but are hard to empirically define and slow to converge optimally. This work proposes the Finger-specific Multi-agent Shadow Reward (FMSR) method to determine the stable manipulation constraints in the form of dense reward based on the state-action occupancy measure, a general utility of DRL that is approximated during the learning process. Information Sharing (IS) across neighboring agents enables consensus training to accelerate the convergence. The methods are evaluated in two in-hand manipulation tasks on the Shadow Hand. The results show FMSR+IS converges faster in training, achieving a higher task success rate and better manipulation stability than conventional dense reward. The comparison indicates FMSR+IS achieves a comparable success rate even with the behavior constraint but much better manipulation stability than the policy trained with a sparse reward.
Developing a Novel Image Marker to Predict the Responses of Neoadjuvant Chemotherapy (NACT) for Ovarian Cancer Patients
Sep 13, 2023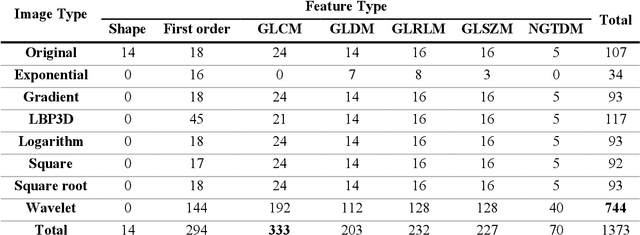
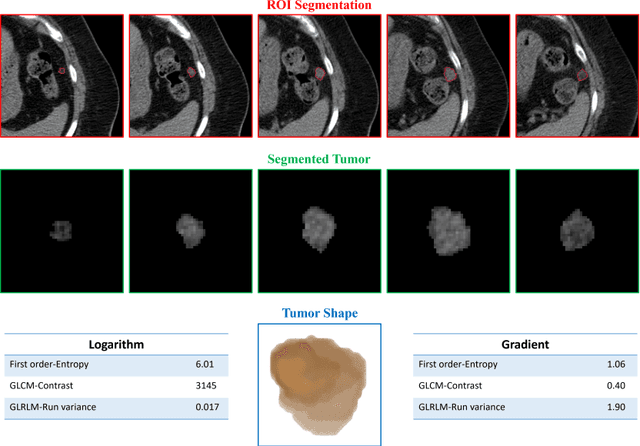
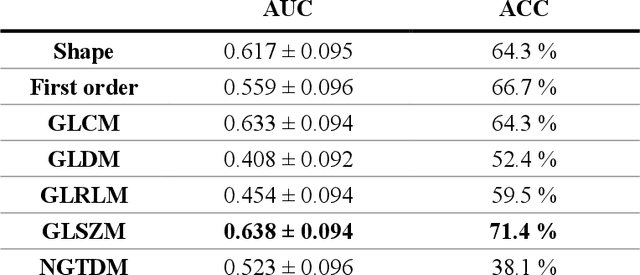
Objective: Neoadjuvant chemotherapy (NACT) is one kind of treatment for advanced stage ovarian cancer patients. However, due to the nature of tumor heterogeneity, the patients' responses to NACT varies significantly among different subgroups. To address this clinical challenge, the purpose of this study is to develop a novel image marker to achieve high accuracy response prediction of the NACT at an early stage. Methods: For this purpose, we first computed a total of 1373 radiomics features to quantify the tumor characteristics, which can be grouped into three categories: geometric, intensity, and texture features. Second, all these features were optimized by principal component analysis algorithm to generate a compact and informative feature cluster. Using this cluster as the input, an SVM based classifier was developed and optimized to create a final marker, indicating the likelihood of the patient being responsive to the NACT treatment. To validate this scheme, a total of 42 ovarian cancer patients were retrospectively collected. A nested leave-one-out cross-validation was adopted for model performance assessment. Results: The results demonstrate that the new method yielded an AUC (area under the ROC [receiver characteristic operation] curve) of 0.745. Meanwhile, the model achieved overall accuracy of 76.2%, positive predictive value of 70%, and negative predictive value of 78.1%. Conclusion: This study provides meaningful information for the development of radiomics based image markers in NACT response prediction.
3D Active Metric-Semantic SLAM
Sep 13, 2023
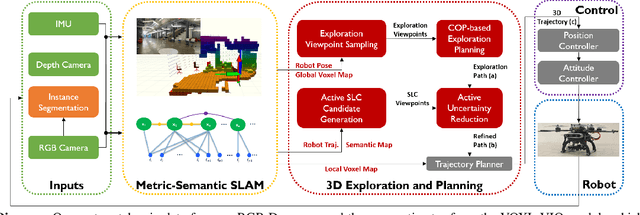
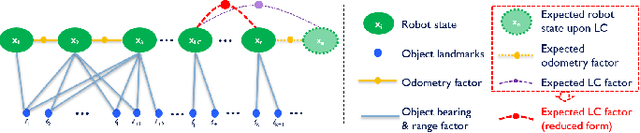
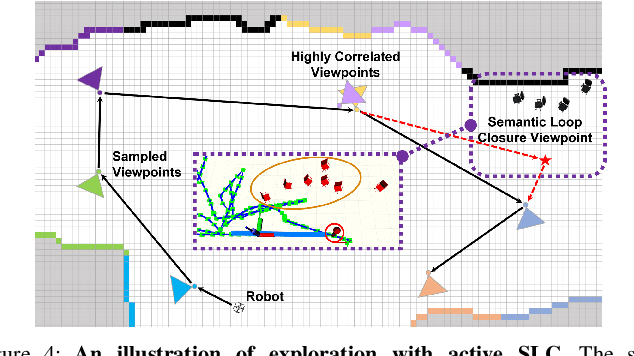
In this letter, we address the problem of exploration and metric-semantic mapping of multi-floor GPS-denied indoor environments using Size Weight and Power (SWaP) constrained aerial robots. Most previous work in exploration assumes that robot localization is solved. However, neglecting the state uncertainty of the agent can ultimately lead to cascading errors both in the resulting map and in the state of the agent itself. Furthermore, actions that reduce localization errors may be at direct odds with the exploration task. We propose a framework that balances the efficiency of exploration with actions that reduce the state uncertainty of the agent. In particular, our algorithmic approach for active metric-semantic SLAM is built upon sparse information abstracted from raw problem data, to make it suitable for SWaP-constrained robots. Furthermore, we integrate this framework within a fully autonomous aerial robotic system that achieves autonomous exploration in cluttered, 3D environments. From extensive real-world experiments, we showed that by including Semantic Loop Closure (SLC), we can reduce the robot pose estimation errors by over 90% in translation and approximately 75% in yaw, and the uncertainties in pose estimates and semantic maps by over 70% and 65%, respectively. Although discussed in the context of indoor multi-floor exploration, our system can be used for various other applications, such as infrastructure inspection and precision agriculture where reliable GPS data may not be available.
Multi-step prediction of chlorophyll concentration based on Adaptive Graph-Temporal Convolutional Network with Series Decomposition
Sep 13, 2023Chlorophyll concentration can well reflect the nutritional status and algal blooms of water bodies, and is an important indicator for evaluating water quality. The prediction of chlorophyll concentration change trend is of great significance to environmental protection and aquaculture. However, there is a complex and indistinguishable nonlinear relationship between many factors affecting chlorophyll concentration. In order to effectively mine the nonlinear features contained in the data. This paper proposes a time-series decomposition adaptive graph-time convolutional network ( AGTCNSD ) prediction model. Firstly, the original sequence is decomposed into trend component and periodic component by moving average method. Secondly, based on the graph convolutional neural network, the water quality parameter data is modeled, and a parameter embedding matrix is defined. The idea of matrix decomposition is used to assign weight parameters to each node. The adaptive graph convolution learns the relationship between different water quality parameters, updates the state information of each parameter, and improves the learning ability of the update relationship between nodes. Finally, time dependence is captured by time convolution to achieve multi-step prediction of chlorophyll concentration. The validity of the model is verified by the water quality data of the coastal city Beihai. The results show that the prediction effect of this method is better than other methods. It can be used as a scientific resource for environmental management decision-making.
Reliability-Latency-Rate Tradeoff in Low-Latency Communications with Finite-Blocklength Coding
Sep 13, 2023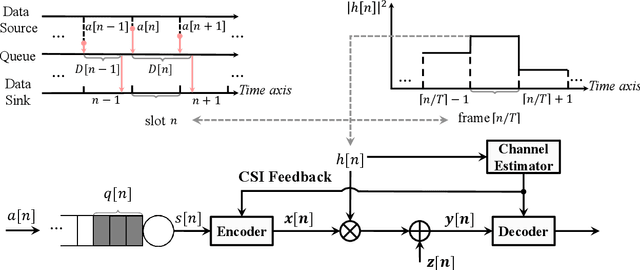
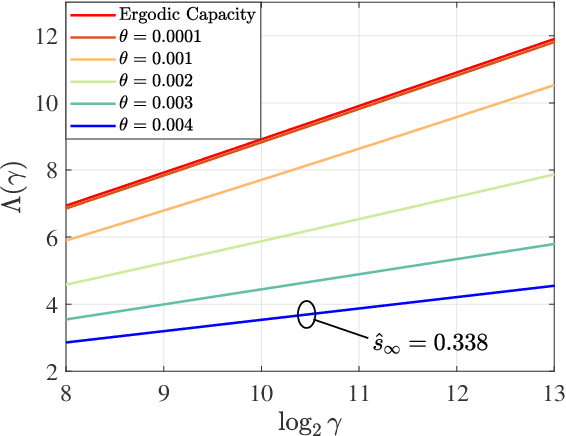
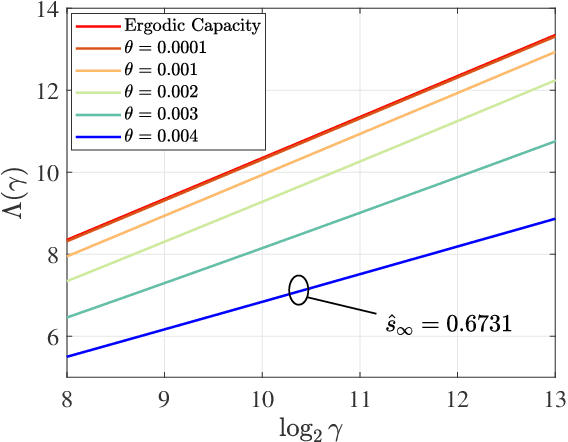
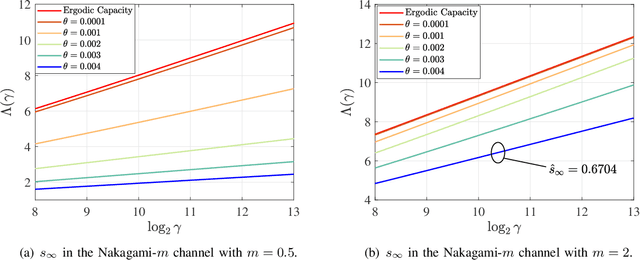
Low-latency communication plays an increasingly important role in delay-sensitive applications by ensuring the real-time exchange of information. However, due to the constraints on the maximum instantaneous power, bounded latency is hard to be guaranteed. In this paper, we investigate the reliability-latency-rate tradeoff in low-latency communications with finite-blocklength coding (FBC). More specifically, we are interested in the fundamental tradeoff between error probability, delay-violation probability (DVP), and service rate. Based on the effective capacity (EC) and normal approximation, we present several gain-conservation inequalities to bound the reliability-latency-rate tradeoffs. In particular, we investigate the low-latency transmissions over an additive white Gaussian noise (AWGN) channel, over a Rayleigh fading channel, with frequency or spatial diversity, and over a Nakagami-$m$ fading channel. To analytically evaluate the quality-of-service-constrained low-latency communications with FBC, an EC-approximation method is further conceived to derive the closed-form expression of quality-of-service-constrained throughput. For delay-sensitive transmissions in which the latency threshold is greater than the channel coherence time, we find an asymptotic form of the tradeoff between the error probability and DVP over the AWGN and Rayleigh fading channels. Our results may provide some insights into the efficient scheduling of low-latency wireless communications in which statistical latency and reliability metrics are adopted.
ChatRule: Mining Logical Rules with Large Language Models for Knowledge Graph Reasoning
Sep 13, 2023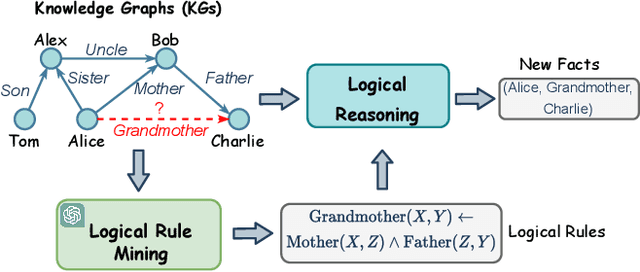
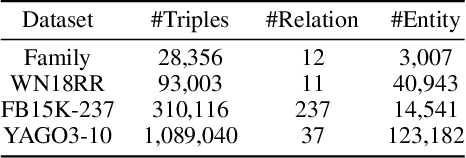
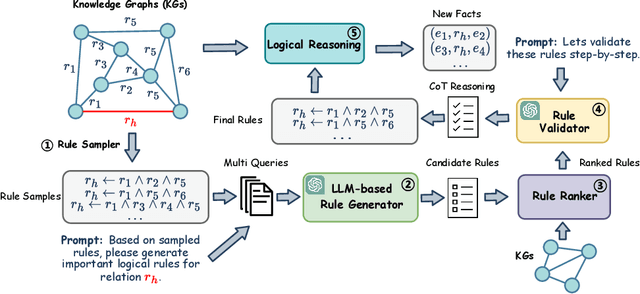
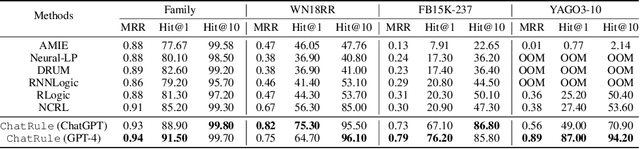
Logical rules are essential for uncovering the logical connections between relations, which could improve the reasoning performance and provide interpretable results on knowledge graphs (KGs). Although there have been many efforts to mine meaningful logical rules over KGs, existing methods suffer from the computationally intensive searches over the rule space and a lack of scalability for large-scale KGs. Besides, they often ignore the semantics of relations which is crucial for uncovering logical connections. Recently, large language models (LLMs) have shown impressive performance in the field of natural language processing and various applications, owing to their emergent ability and generalizability. In this paper, we propose a novel framework, ChatRule, unleashing the power of large language models for mining logical rules over knowledge graphs. Specifically, the framework is initiated with an LLM-based rule generator, leveraging both the semantic and structural information of KGs to prompt LLMs to generate logical rules. To refine the generated rules, a rule ranking module estimates the rule quality by incorporating facts from existing KGs. Last, a rule validator harnesses the reasoning ability of LLMs to validate the logical correctness of ranked rules through chain-of-thought reasoning. ChatRule is evaluated on four large-scale KGs, w.r.t. different rule quality metrics and downstream tasks, showing the effectiveness and scalability of our method.
Edge-aware Hard Clustering Graph Pooling for Brain Imaging Data
Sep 13, 2023
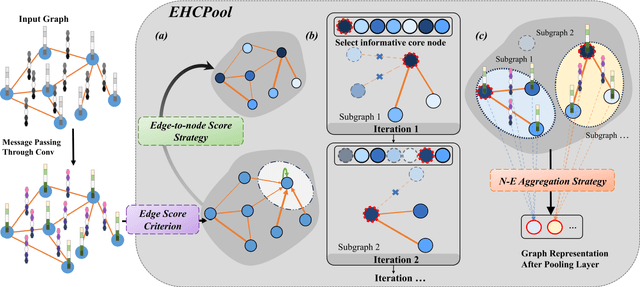
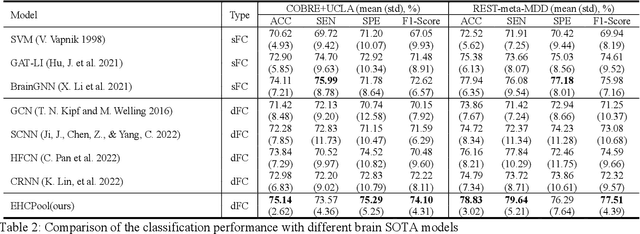

Graph Convolutional Networks (GCNs) can capture non-Euclidean spatial dependence between different brain regions, and the graph pooling operator in GCNs is key to enhancing the representation learning capability and acquiring abnormal brain maps. However, the majority of existing research designs graph pooling operators only from the perspective of nodes while disregarding the original edge features, in a way that not only confines graph pooling application scenarios, but also diminishes its ability to capture critical substructures. In this study, a clustering graph pooling method that first supports multidimensional edge features, called Edge-aware hard clustering graph pooling (EHCPool), is developed. EHCPool proposes the first 'Edge-to-node' score evaluation criterion based on edge features to assess node feature significance. To more effectively capture the critical subgraphs, a novel Iteration n-top strategy is further designed to adaptively learn sparse hard clustering assignments for graphs. Subsequently, an innovative N-E Aggregation strategy is presented to aggregate node and edge feature information in each independent subgraph. The proposed model was evaluated on multi-site brain imaging public datasets and yielded state-of-the-art performance. We believe this method is the first deep learning tool with the potential to probe different types of abnormal functional brain networks from data-driven perspective. Core code is at: https://github.com/swfen/EHCPool.