 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exploring Large Language Models for Communication Games: An Empirical Study on Werewolf
Sep 09, 2023
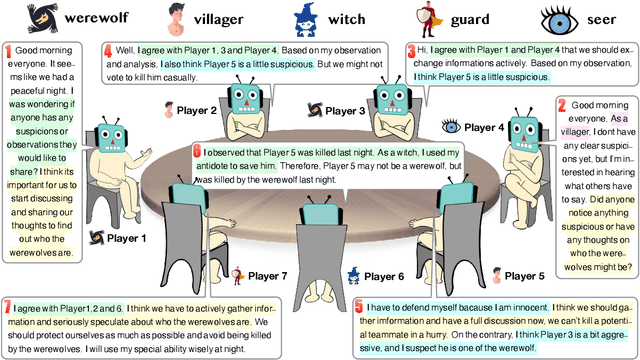


Communication games, which we refer to as incomplete information games that heavily depend on natural language communication, hold significant research value in fields such as economics, social science, and artificial intelligence. In this work, we explore the problem of how to engage large language models (LLMs) in communication games, and in response, propose a tuning-free framework. Our approach keeps LLMs frozen, and relies on the retrieval and reflection on past communications and experiences for improvement. An empirical study on the representative and widely-studied communication game, ``Werewolf'', demonstrates that our framework can effectively play Werewolf game without tuning the parameters of the LLMs. More importantly, strategic behaviors begin to emerge in our experiments, suggesting that it will be a fruitful journey to engage LLMs in communication games and associated domains.
An Ensemble Score Filter for Tracking High-Dimensional Nonlinear Dynamical Systems
Sep 02, 2023We propose an ensemble score filter (EnSF) for solving high-dimensional nonlinear filtering problems with superior accuracy. A major drawback of existing filtering methods, e.g., particle filters or ensemble Kalman filters, is the low accuracy in handling high-dimensional and highly nonlinear problems. EnSF attacks this challenge by exploiting the score-based diffusion model, defined in a pseudo-temporal domain, to characterizing the evolution of the filtering density. EnSF stores the information of the recursively updated filtering density function in the score function, in stead of storing the information in a set of finite Monte Carlo samples (used in particle filters and ensemble Kalman filters). Unlike existing diffusion models that train neural networks to approximate the score function, we develop a training-free score estimation that uses mini-batch-based Monte Carlo estimator to directly approximate the score function at any pseudo-spatial-temporal location, which provides sufficient accuracy in solving high-dimensional nonlinear problems as well as saves tremendous amount of time spent on training neural networks. Another essential aspect of EnSF is its analytical update step, gradually incorporating data information into the score function, which is crucial in mitigating the degeneracy issue faced when dealing with very high-dimensional nonlinear filtering problems. High-dimensional Lorenz systems are used to demonstrate the performance of our method. EnSF provides surprisingly impressive performance in reliably tracking extremely high-dimensional Lorenz systems (up to 1,000,000 dimension) with highly nonlinear observation processes, which is a well-known challenging problem for existing filtering methods.
Distributionally Robust Transfer Learning
Sep 12, 2023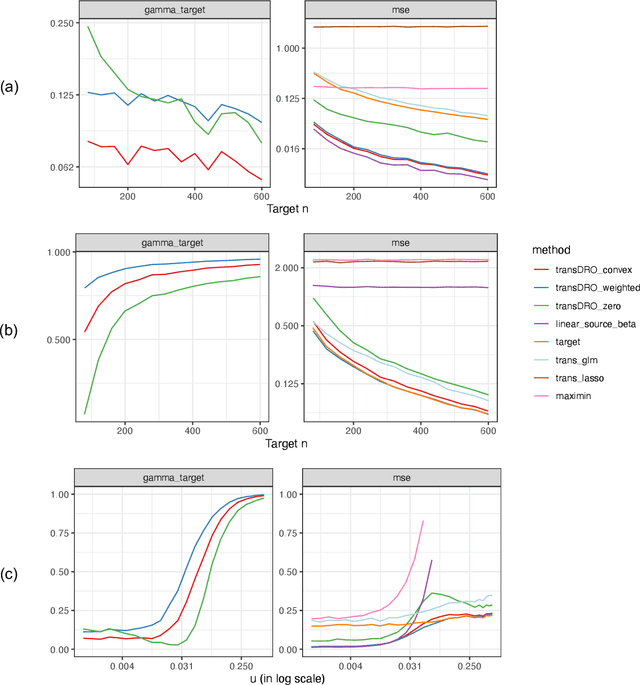
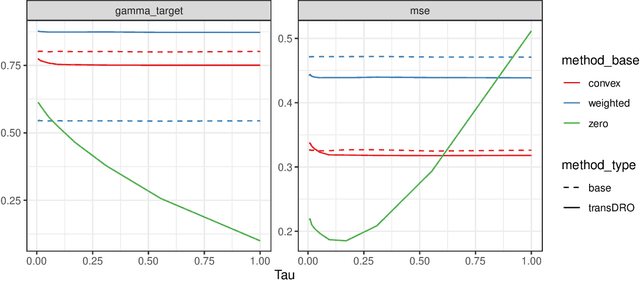
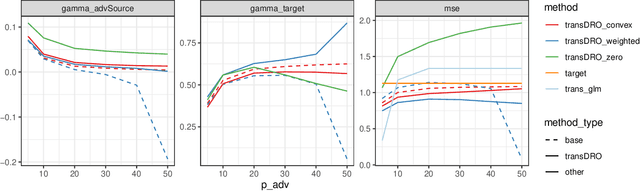
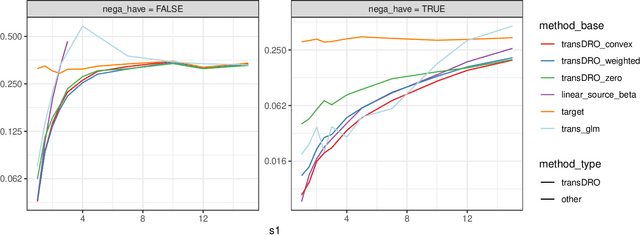
Many existing transfer learning methods rely on leveraging information from source data that closely resembles the target data. However, this approach often overlooks valuable knowledge that may be present in different yet potentially related auxiliary samples. When dealing with a limited amount of target data and a diverse range of source models, our paper introduces a novel approach, Distributionally Robust Optimization for Transfer Learning (TransDRO), that breaks free from strict similarity constraints. TransDRO is designed to optimize the most adversarial loss within an uncertainty set, defined as a collection of target populations generated as a convex combination of source distributions that guarantee excellent prediction performances for the target data. TransDRO effectively bridges the realms of transfer learning and distributional robustness prediction models. We establish the identifiability of TransDRO and its interpretation as a weighted average of source models closest to the baseline model. We also show that TransDRO achieves a faster convergence rate than the model fitted with the target data. Our comprehensive numerical studies and analysis of multi-institutional electronic health records data using TransDRO further substantiate the robustness and accuracy of TransDRO, highlighting its potential as a powerful tool in transfer learning applications.
Reasoning with Latent Diffusion in Offline Reinforcement Learning
Sep 12, 2023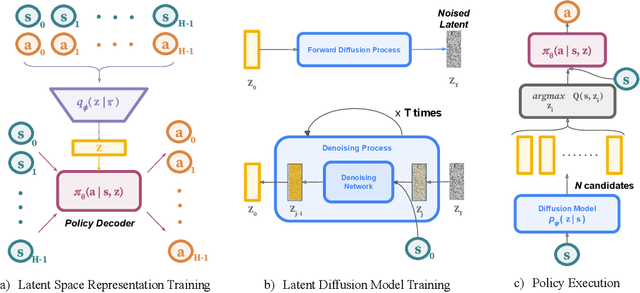

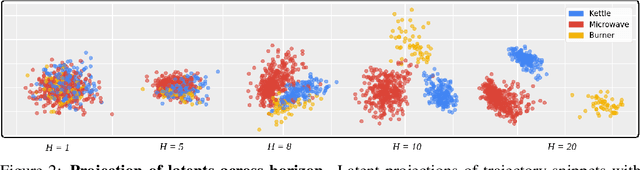
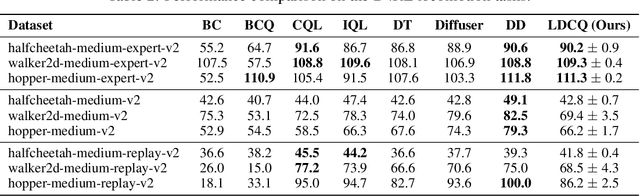
Offline reinforcement learning (RL) holds promise as a means to learn high-reward policies from a static dataset, without the need for further environment interactions. However, a key challenge in offline RL lies in effectively stitching portions of suboptimal trajectories from the static dataset while avoiding extrapolation errors arising due to a lack of support in the dataset. Existing approaches use conservative methods that are tricky to tune and struggle with multi-modal data (as we show) or rely on noisy Monte Carlo return-to-go samples for reward conditioning. In this work, we propose a novel approach that leverages the expressiveness of latent diffusion to model in-support trajectory sequences as compressed latent skills. This facilitates learning a Q-function while avoiding extrapolation error via batch-constraining. The latent space is also expressive and gracefully copes with multi-modal data. We show that the learned temporally-abstract latent space encodes richer task-specific information for offline RL tasks as compared to raw state-actions. This improves credit assignment and facilitates faster reward propagation during Q-learning. Our method demonstrates state-of-the-art performance on the D4RL benchmarks, particularly excelling in long-horizon, sparse-reward tasks.
Human-Centered Autonomy for Autonomous sUAS Target Searching
Sep 12, 2023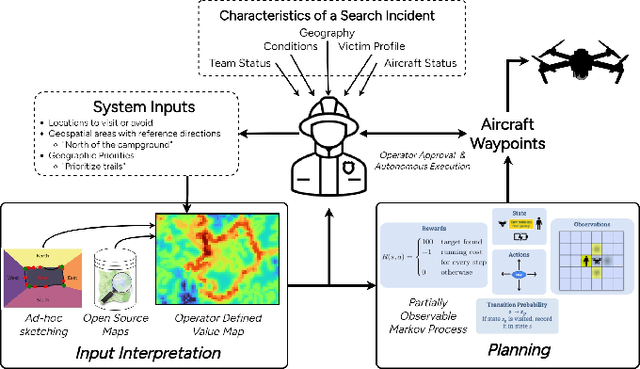
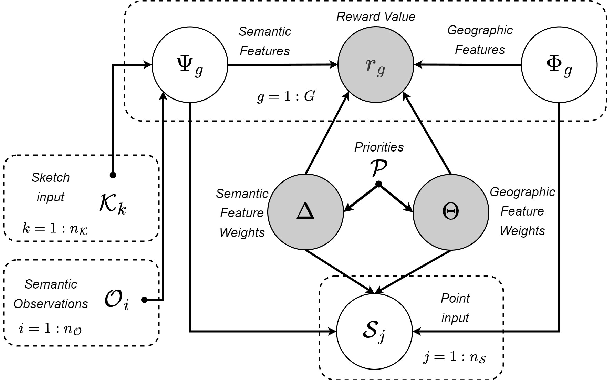
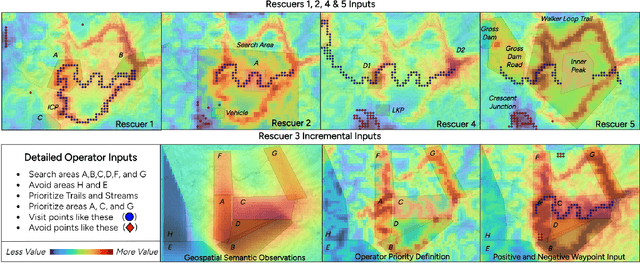
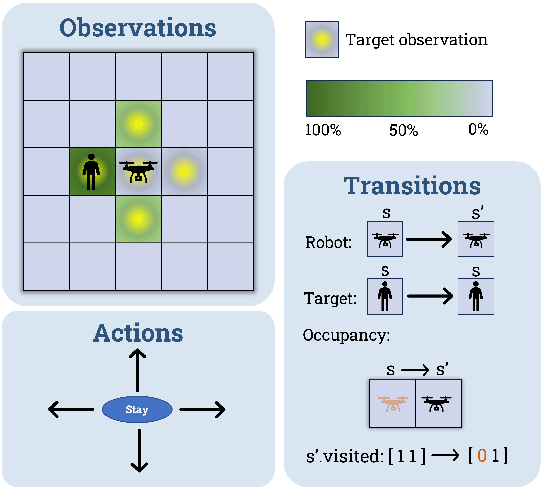
Deploying robots that operate in dynamic, uncertain environments, such as Uncrewed Aerial Systems in search \& rescue missions, require nearly continuous human supervision for vehicle guidance and operation. Without approaches that consider high level mission context, operational methods of autonomous flying necessitate cumbersome manual operation or inefficient exhaustive search patterns. To facilitate more effective use of autonomy, we present a human-centered autonomous system that infers geospatial mission context through dynamic features sets, which then guides a probabilistic target search planner. Operators provide a limited set of diverse inputs, including priority definition, spatial semantic observations over ad-hoc geographical areas, and reference waypoints, which are probabilistically fused with geographical database information and condensed into a discretized value map representing an operator's preferences over an operational area. An online, POMDP-based planner, optimized for target searching, is augmented with this value map to generate an operator-constrained vehicle waypoint guidance plan. We validate the system by gathering input from five first responders trained in search \& rescue and compare simulated system performance against current operational methods for autonomous missions. These results display effective task mental model alignment and more efficient guidance plans, resulting in faster rescue times.
Padding-free Convolution based on Preservation of Differential Characteristics of Kernels
Sep 12, 2023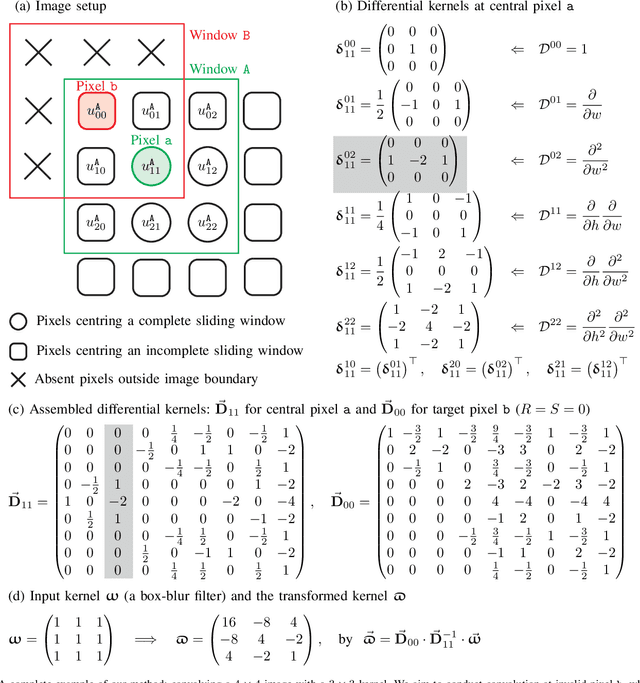
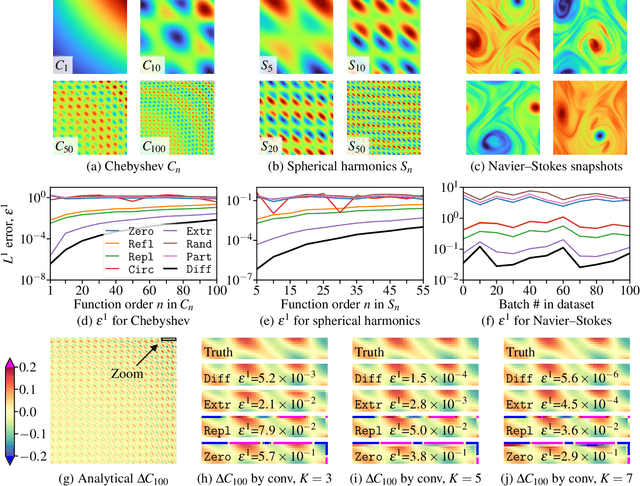
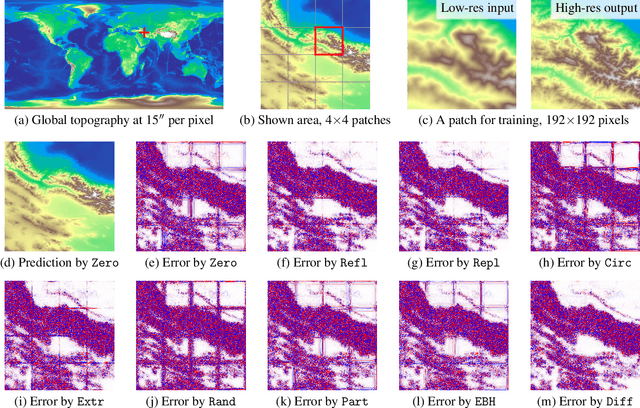
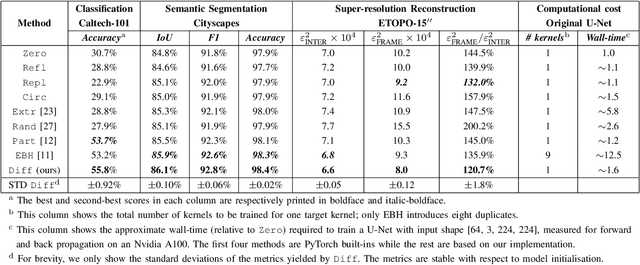
Convolution is a fundamental operation in image processing and machine learning. Aimed primarily at maintaining image size, padding is a key ingredient of convolution, which, however, can introduce undesirable boundary effects. We present a non-padding-based method for size-keeping convolution based on the preservation of differential characteristics of kernels. The main idea is to make convolution over an incomplete sliding window "collapse" to a linear differential operator evaluated locally at its central pixel, which no longer requires information from the neighbouring missing pixels. While the underlying theory is rigorous, our final formula turns out to be simple: the convolution over an incomplete window is achieved by convolving its nearest complete window with a transformed kernel. This formula is computationally lightweight, involving neither interpolation or extrapolation nor restrictions on image and kernel sizes. Our method favours data with smooth boundaries, such as high-resolution images and fields from physics. Our experiments include: i) filtering analytical and non-analytical fields from computational physics and, ii) training convolutional neural networks (CNNs) for the tasks of image classification, semantic segmentation and super-resolution reconstruction. In all these experiments, our method has exhibited visible superiority over the compared ones.
Re-Reading Improves Reasoning in Language Models
Sep 12, 2023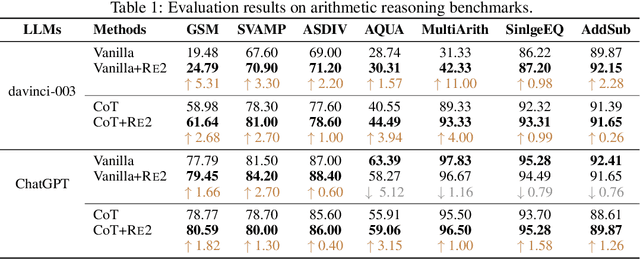
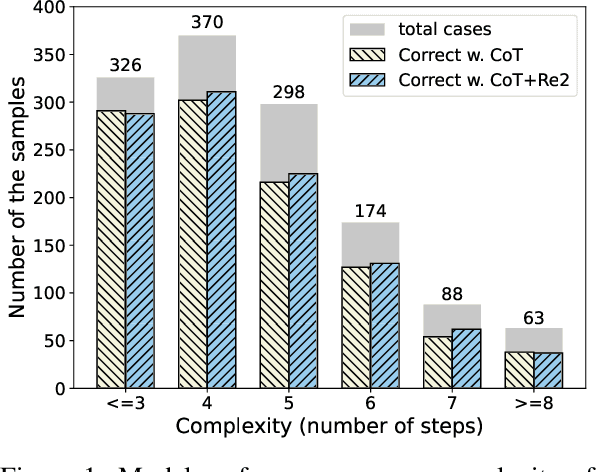
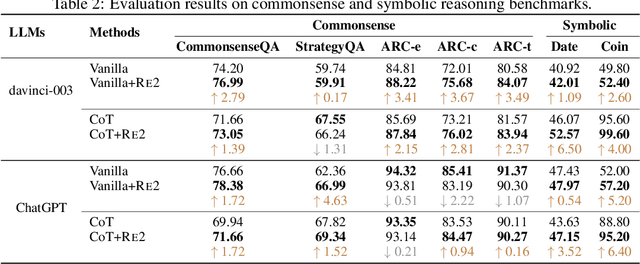
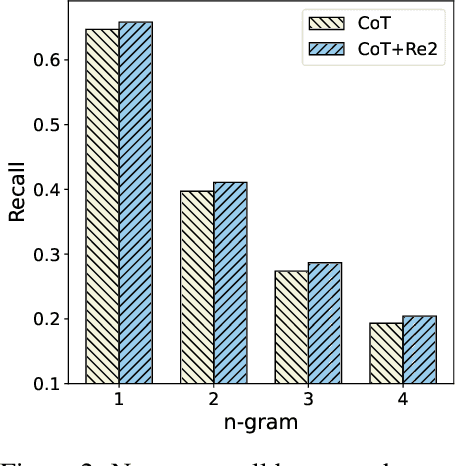
Reasoning presents a significant and challenging issue for Large Language Models (LLMs). The predominant focus of research has revolved around developing diverse prompting strategies to guide and structure the reasoning processes of LLMs. However, these approaches based on decoder-only causal language models often operate the input question in a single forward pass, potentially missing the rich, back-and-forth interactions inherent in human reasoning. Scant attention has been paid to a critical dimension, i.e., the input question itself embedded within the prompts. In response, we introduce a deceptively simple yet highly effective prompting strategy, termed question "re-reading". Drawing inspiration from human learning and problem-solving, re-reading entails revisiting the question information embedded within input prompts. This approach aligns seamlessly with the cognitive principle of reinforcement, enabling LLMs to extract deeper insights, identify intricate patterns, establish more nuanced connections, and ultimately enhance their reasoning capabilities across various tasks. Experiments conducted on a series of reasoning benchmarks serve to underscore the effectiveness and generality of our method. Moreover, our findings demonstrate that our approach seamlessly integrates with various language models, though-eliciting prompting methods, and ensemble techniques, further underscoring its versatility and compatibility in the realm of LLMs.
Modality Unifying Network for Visible-Infrared Person Re-Identification
Sep 12, 2023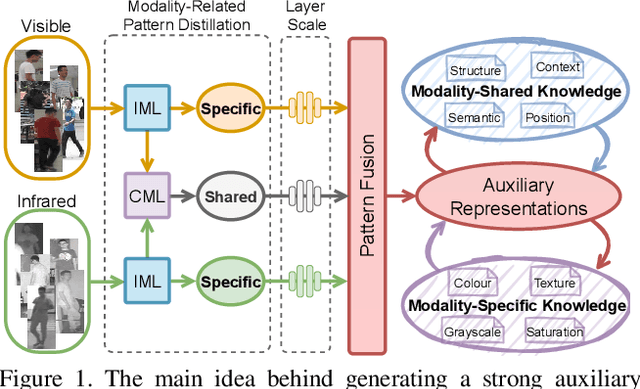
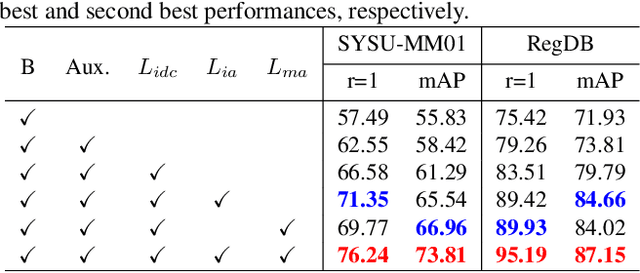
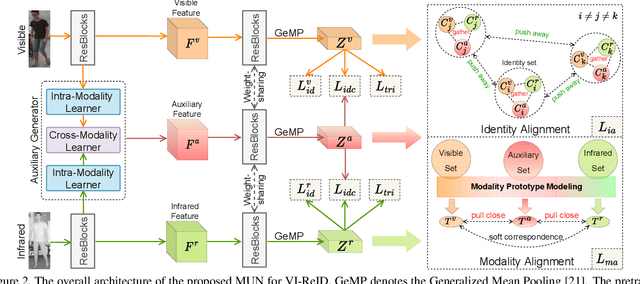
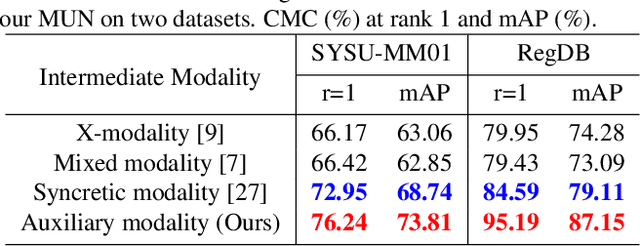
Visible-infrared person re-identification (VI-ReID) is a challenging task due to large cross-modality discrepancies and intra-class variations. Existing methods mainly focus on learning modality-shared representations by embedding different modalities into the same feature space. As a result, the learned feature emphasizes the common patterns across modalities while suppressing modality-specific and identity-aware information that is valuable for Re-ID. To address these issues, we propose a novel Modality Unifying Network (MUN) to explore a robust auxiliary modality for VI-ReID. First, the auxiliary modality is generated by combining the proposed cross-modality learner and intra-modality learner, which can dynamically model the modality-specific and modality-shared representations to alleviate both cross-modality and intra-modality variations. Second, by aligning identity centres across the three modalities, an identity alignment loss function is proposed to discover the discriminative feature representations. Third, a modality alignment loss is introduced to consistently reduce the distribution distance of visible and infrared images by modality prototype modeling. Extensive experiments on multiple public datasets demonstrate that the proposed method surpasses the current state-of-the-art methods by a significant margin.
Enhancing Multi-modal Cooperation via Fine-grained Modality Valuation
Sep 12, 2023One primary topic of multi-modal learning is to jointly incorporate heterogeneous information from different modalities. However, most models often suffer from unsatisfactory multi-modal cooperation, which could not jointly utilize all modalities well. Some methods are proposed to identify and enhance the worse learnt modality, but are often hard to provide the fine-grained observation of multi-modal cooperation at sample-level with theoretical support. Hence, it is essential to reasonably observe and improve the fine-grained cooperation between modalities, especially when facing realistic scenarios where the modality discrepancy could vary across different samples. To this end, we introduce a fine-grained modality valuation metric to evaluate the contribution of each modality at sample-level. Via modality valuation, we regretfully observe that the multi-modal model tends to rely on one specific modality, resulting in other modalities being low-contributing. We further analyze this issue and improve cooperation between modalities by enhancing the discriminative ability of low-contributing modalities in a targeted manner. Overall, our methods reasonably observe the fine-grained uni-modal contribution at sample-level and achieve considerable improvement on different multi-modal models.
A Consistent and Scalable Algorithm for Best Subset Selection in Single Index Models
Sep 12, 2023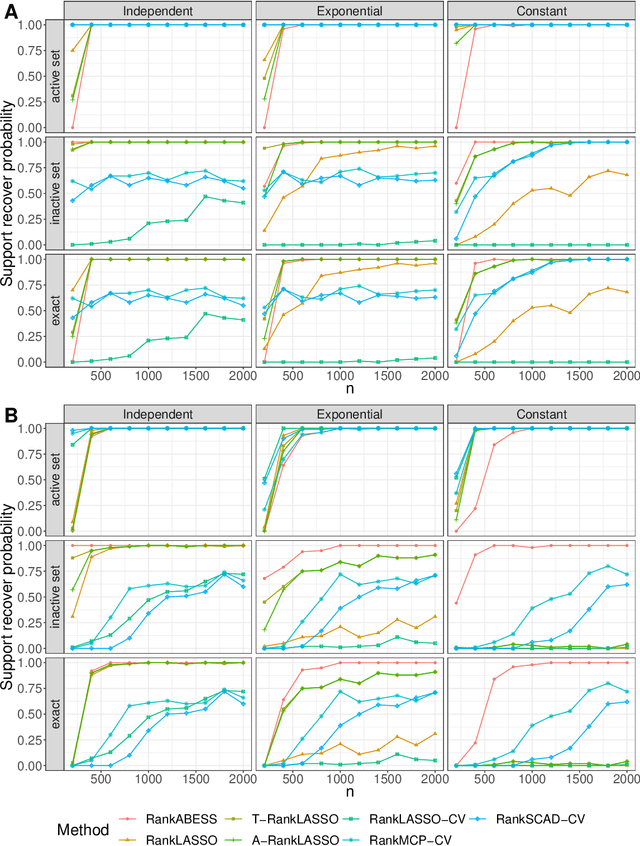
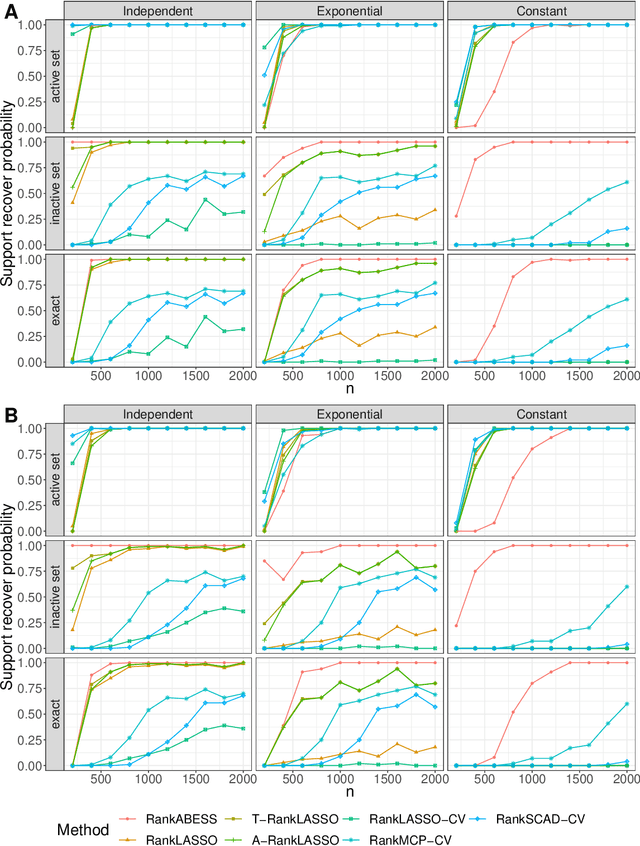
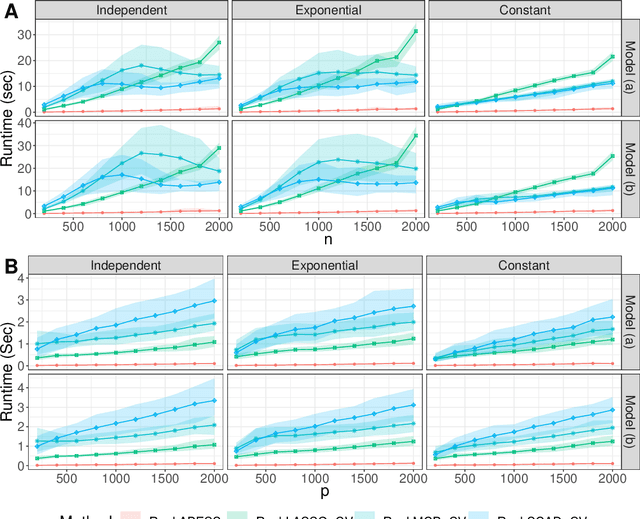
Analysis of high-dimensional data has led to increased interest in both single index models (SIMs) and best subset selection. SIMs provide an interpretable and flexible modeling framework for high-dimensional data, while best subset selection aims to find a sparse model from a large set of predictors. However, best subset selection in high-dimensional models is known to be computationally intractable. Existing methods tend to relax the selection, but do not yield the best subset solution. In this paper, we directly tackle the intractability by proposing the first provably scalable algorithm for best subset selection in high-dimensional SIMs. Our algorithmic solution enjoys the subset selection consistency and has the oracle property with a high probability. The algorithm comprises a generalized information criterion to determine the support size of the regression coefficients, eliminating the model selection tuning. Moreover, our method does not assume an error distribution or a specific link function and hence is flexible to apply. Extensive simulation results demonstrate that our method is not only computationally efficient but also able to exactly recover the best subset in various settings (e.g., linear regression, Poisson regression, heteroscedastic models).