 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Optimal Contracts: How to Exploit Small Action Spaces
Sep 18, 2023
We study principal-agent problems in which a principal commits to an outcome-dependent payment scheme -- called contract -- in order to induce an agent to take a costly, unobservable action leading to favorable outcomes. We consider a generalization of the classical (single-round) version of the problem in which the principal interacts with the agent by committing to contracts over multiple rounds. The principal has no information about the agent, and they have to learn an optimal contract by only observing the outcome realized at each round. We focus on settings in which the size of the agent's action space is small. We design an algorithm that learns an approximately-optimal contract with high probability in a number of rounds polynomial in the size of the outcome space, when the number of actions is constant. Our algorithm solves an open problem by Zhu et al.[2022]. Moreover, it can also be employed to provide a $\tilde{\mathcal{O}}(T^{4/5})$ regret bound in the related online learning setting in which the principal aims at maximizing their cumulative utility, thus considerably improving previously-known regret bounds.
Dealing with negative samples with multi-task learning on span-based joint entity-relation extraction
Sep 18, 2023
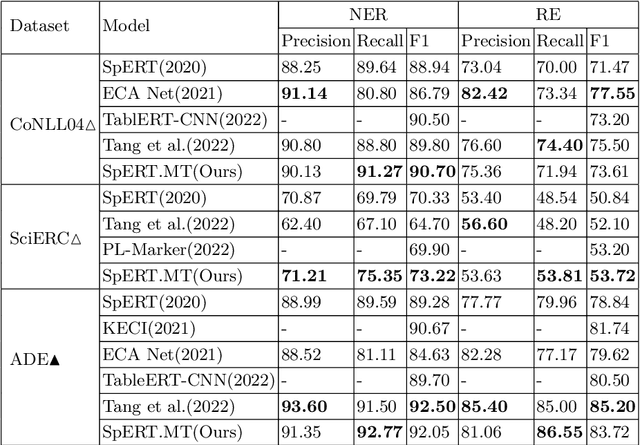
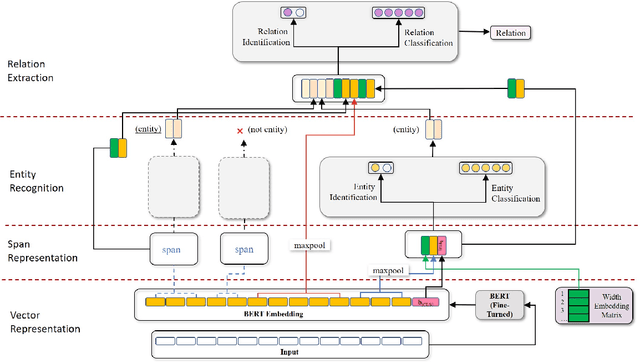
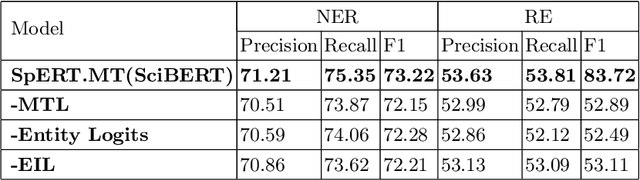
Recent span-based joint extraction models have demonstrated significant advantages in both entity recognition and relation extraction. These models treat text spans as candidate entities, and span pairs as candidate relationship tuples, achieving state-of-the-art results on datasets like ADE. However, these models encounter a significant number of non-entity spans or irrelevant span pairs during the tasks, impairing model performance significantly. To address this issue, this paper introduces a span-based multitask entity-relation joint extraction model. This approach employs the multitask learning to alleviate the impact of negative samples on entity and relation classifiers. Additionally, we leverage the Intersection over Union(IoU) concept to introduce the positional information into the entity classifier, achieving a span boundary detection. Furthermore, by incorporating the entity Logits predicted by the entity classifier into the embedded representation of entity pairs, the semantic input for the relation classifier is enriched. Experimental results demonstrate that our proposed SpERT.MT model can effectively mitigate the adverse effects of excessive negative samples on the model performance. Furthermore, the model demonstrated commendable F1 scores of 73.61\%, 53.72\%, and 83.72\% on three widely employed public datasets, namely CoNLL04, SciERC, and ADE, respectively.
Ugly Ducklings or Swans: A Tiered Quadruplet Network with Patient-Specific Mining for Improved Skin Lesion Classification
Sep 18, 2023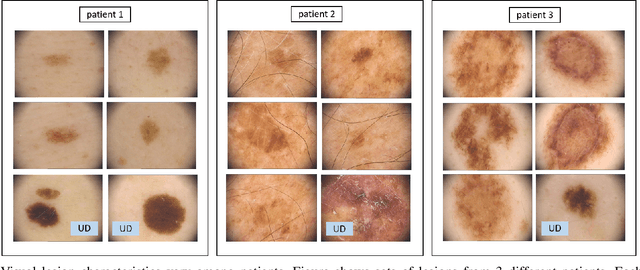
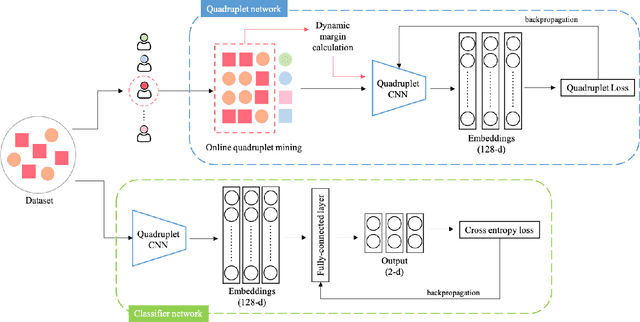
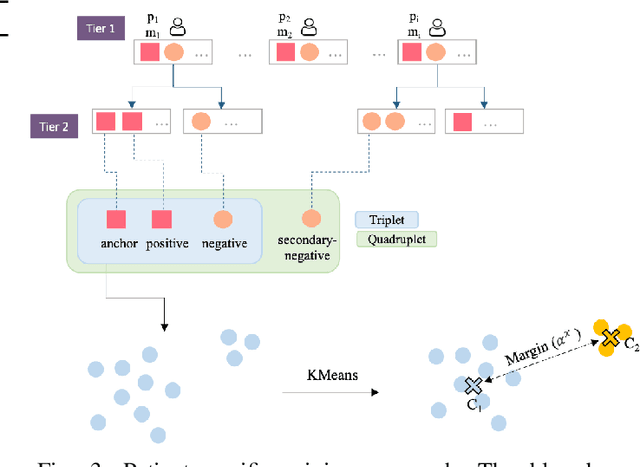
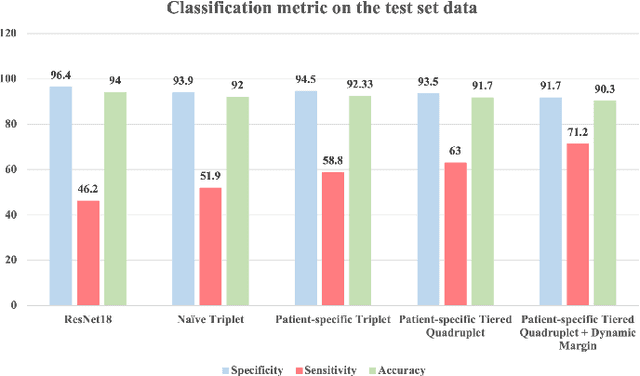
An ugly duckling is an obviously different skin lesion from surrounding lesions of an individual, and the ugly duckling sign is a criterion used to aid in the diagnosis of cutaneous melanoma by differentiating between highly suspicious and benign lesions. However, the appearance of pigmented lesions, can change drastically from one patient to another, resulting in difficulties in visual separation of ugly ducklings. Hence, we propose DMT-Quadruplet - a deep metric learning network to learn lesion features at two tiers - patient-level and lesion-level. We introduce a patient-specific quadruplet mining approach together with a tiered quadruplet network, to drive the network to learn more contextual information both globally and locally between the two tiers. We further incorporate a dynamic margin within the patient-specific mining to allow more useful quadruplets to be mined within individuals. Comprehensive experiments show that our proposed method outperforms traditional classifiers, achieving 54% higher sensitivity than a baseline ResNet18 CNN and 37% higher than a naive triplet network in classifying ugly duckling lesions. Visualisation of the data manifold in the metric space further illustrates that DMT-Quadruplet is capable of classifying ugly duckling lesions in both patient-specific and patient-agnostic manner successfully.
DFormer: Rethinking RGBD Representation Learning for Semantic Segmentation
Sep 18, 2023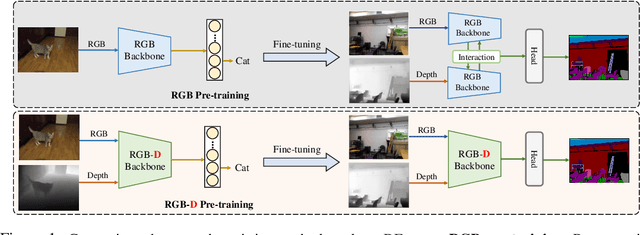
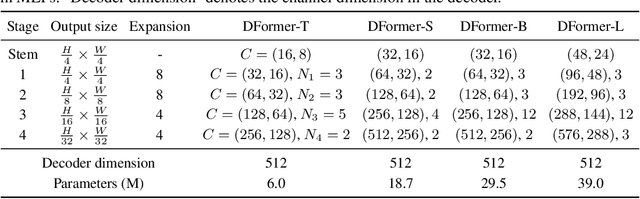
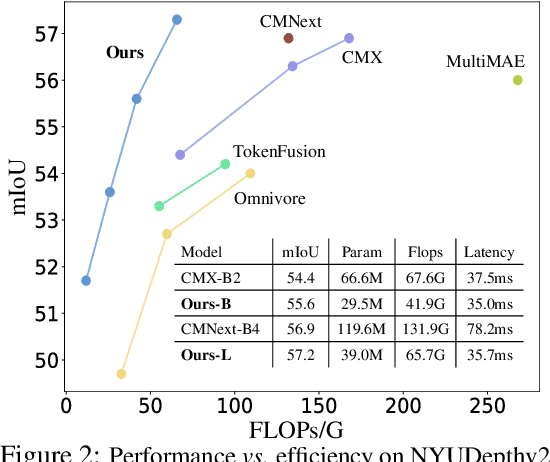
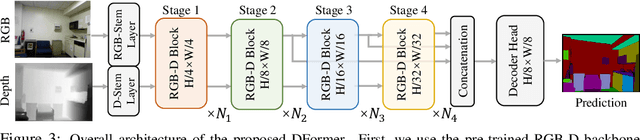
We present DFormer, a novel RGB-D pretraining framework to learn transferable representations for RGB-D segmentation tasks. DFormer has two new key innovations: 1) Unlike previous works that aim to encode RGB features,DFormer comprises a sequence of RGB-D blocks, which are tailored for encoding both RGB and depth information through a novel building block design; 2) We pre-train the backbone using image-depth pairs from ImageNet-1K, and thus the DFormer is endowed with the capacity to encode RGB-D representations. It avoids the mismatched encoding of the 3D geometry relationships in depth maps by RGB pre-trained backbones, which widely lies in existing methods but has not been resolved. We fine-tune the pre-trained DFormer on two popular RGB-D tasks, i.e., RGB-D semantic segmentation and RGB-D salient object detection, with a lightweight decoder head. Experimental results show that our DFormer achieves new state-of-the-art performance on these two tasks with less than half of the computational cost of the current best methods on two RGB-D segmentation datasets and five RGB-D saliency datasets. Our code is available at: https://github.com/VCIP-RGBD/DFormer.
HTEC: Human Transcription Error Correction
Sep 18, 2023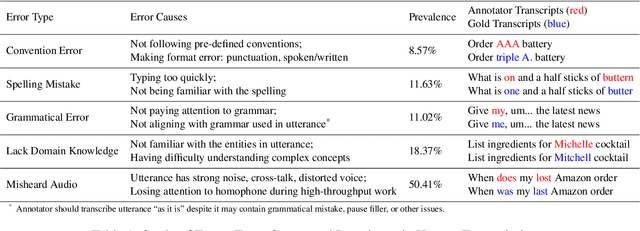
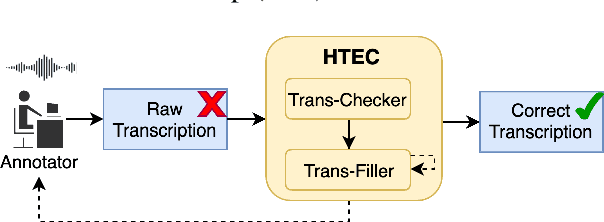

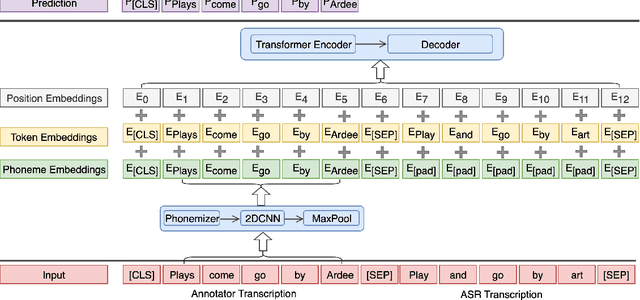
High-quality human transcription is essential for training and improving Automatic Speech Recognition (ASR) models. Recent study~\cite{libricrowd} has found that every 1% worse transcription Word Error Rate (WER) increases approximately 2% ASR WER by using the transcriptions to train ASR models. Transcription errors are inevitable for even highly-trained annotators. However, few studies have explored human transcription correction. Error correction methods for other problems, such as ASR error correction and grammatical error correction, do not perform sufficiently for this problem. Therefore, we propose HTEC for Human Transcription Error Correction. HTEC consists of two stages: Trans-Checker, an error detection model that predicts and masks erroneous words, and Trans-Filler, a sequence-to-sequence generative model that fills masked positions. We propose a holistic list of correction operations, including four novel operations handling deletion errors. We further propose a variant of embeddings that incorporates phoneme information into the input of the transformer. HTEC outperforms other methods by a large margin and surpasses human annotators by 2.2% to 4.5% in WER. Finally, we deployed HTEC to assist human annotators and showed HTEC is particularly effective as a co-pilot, which improves transcription quality by 15.1% without sacrificing transcription velocity.
Proposition from the Perspective of Chinese Language: A Chinese Proposition Classification Evaluation Benchmark
Sep 18, 2023Existing propositions often rely on logical constants for classification. Compared with Western languages that lean towards hypotaxis such as English, Chinese often relies on semantic or logical understanding rather than logical connectives in daily expressions, exhibiting the characteristics of parataxis. However, existing research has rarely paid attention to this issue. And accurately classifying these propositions is crucial for natural language understanding and reasoning. In this paper, we put forward the concepts of explicit and implicit propositions and propose a comprehensive multi-level proposition classification system based on linguistics and logic. Correspondingly, we create a large-scale Chinese proposition dataset PEACE from multiple domains, covering all categories related to propositions. To evaluate the Chinese proposition classification ability of existing models and explore their limitations, We conduct evaluations on PEACE using several different methods including the Rule-based method, SVM, BERT, RoBERTA, and ChatGPT. Results show the importance of properly modeling the semantic features of propositions. BERT has relatively good proposition classification capability, but lacks cross-domain transferability. ChatGPT performs poorly, but its classification ability can be improved by providing more proposition information. Many issues are still far from being resolved and require further study.
Turbo Coded OFDM-OQAM Using Hilbert Transform
Sep 18, 2023Orthogonal frequency division multiplexing (OFDM) with offset quadrature amplitude modulation (OQAM) has been widely discussed in the literature and is considered a popular waveform for 5th generation (5G) wireless telecommunications and beyond. In this work, we show that OFDM-OQAM can be generated using the Hilbert transform and is equivalent to single sideband modulation (SSB), that has roots in analog telecommunications. The transmit filter for OFDM-OQAM is complex valued whose real part is given by the pulse corresponding to the root raised cosine spectrum and the imaginary part is the Hilbert transform of the real part. The real-valued digital information (message) are passed through the transmit filter and frequency division multiplexed on orthogonal subcarriers. The message bandwidth corresponding to each subcarrier is assumed to be narrow enough so that the channel can be considered ideal. Therefore, at the receiver, a matched filter can used to recover the message. Turbo coding is used to achieve bit-error-rate (BER) as low as $10^{-5}$ at an average signal-to-noise ratio (SNR) per bit close to 0 db. The system has been simulated in discrete time.
Joint Demosaicing and Denoising with Double Deep Image Priors
Sep 18, 2023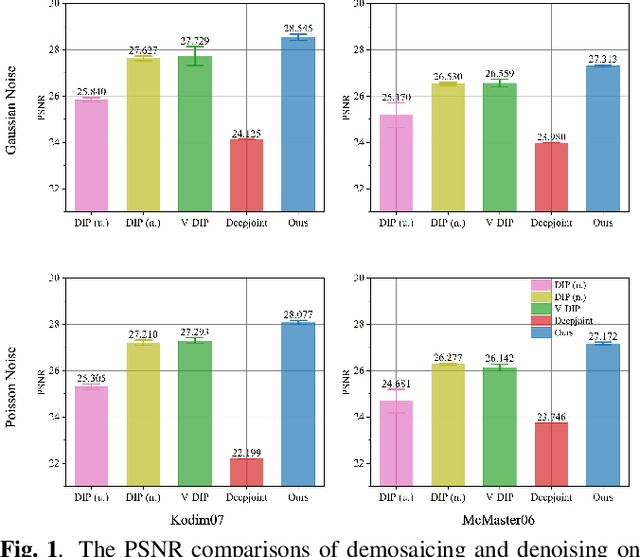
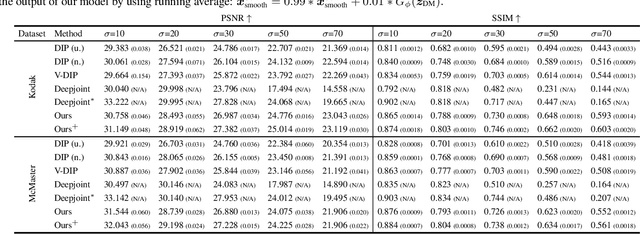
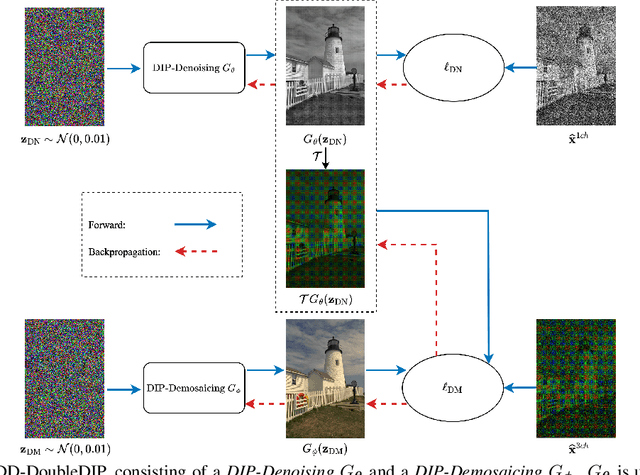
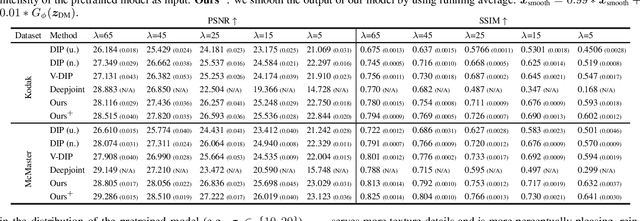
Demosaicing and denoising of RAW images are crucial steps in the processing pipeline of modern digital cameras. As only a third of the color information required to produce a digital image is captured by the camera sensor, the process of demosaicing is inherently ill-posed. The presence of noise further exacerbates this problem. Performing these two steps sequentially may distort the content of the captured RAW images and accumulate errors from one step to another. Recent deep neural-network-based approaches have shown the effectiveness of joint demosaicing and denoising to mitigate such challenges. However, these methods typically require a large number of training samples and do not generalize well to different types and intensities of noise. In this paper, we propose a novel joint demosaicing and denoising method, dubbed JDD-DoubleDIP, which operates directly on a single RAW image without requiring any training data. We validate the effectiveness of our method on two popular datasets -- Kodak and McMaster -- with various noises and noise intensities. The experimental results show that our method consistently outperforms other compared methods in terms of PSNR, SSIM, and qualitative visual perception.
UNICON: A unified framework for behavior-based consumer segmentation in e-commerce
Sep 18, 2023Data-driven personalization is a key practice in fashion e-commerce, improving the way businesses serve their consumers needs with more relevant content. While hyper-personalization offers highly targeted experiences to each consumer, it requires a significant amount of private data to create an individualized journey. To alleviate this, group-based personalization provides a moderate level of personalization built on broader common preferences of a consumer segment, while still being able to personalize the results. We introduce UNICON, a unified deep learning consumer segmentation framework that leverages rich consumer behavior data to learn long-term latent representations and utilizes them to extract two pivotal types of segmentation catering various personalization use-cases: lookalike, expanding a predefined target seed segment with consumers of similar behavior, and data-driven, revealing non-obvious consumer segments with similar affinities. We demonstrate through extensive experimentation our framework effectiveness in fashion to identify lookalike Designer audience and data-driven style segments. Furthermore, we present experiments that showcase how segment information can be incorporated in a hybrid recommender system combining hyper and group-based personalization to exploit the advantages of both alternatives and provide improvements on consumer experience.
SR-PredictAO: Session-based Recommendation with High-Capability Predictor Add-On
Sep 20, 2023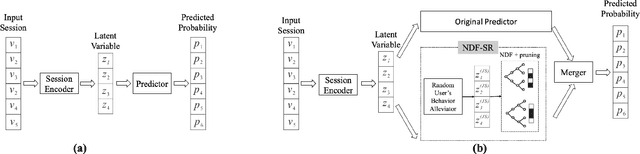
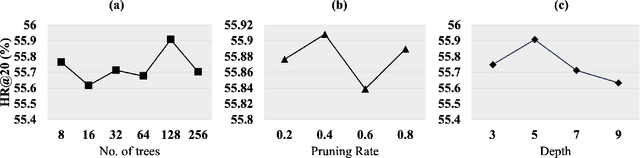
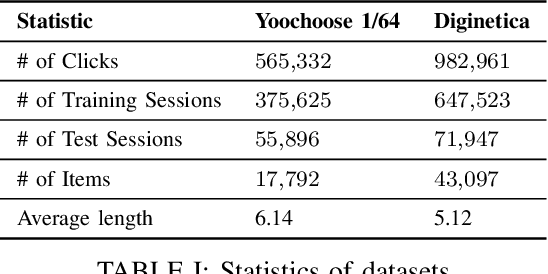
Session-based recommendation, aiming at making the prediction of the user's next item click based on the information in a single session only even in the presence of some random user's behavior, is a complex problem. This complex problem requires a high-capability model of predicting the user's next action. Most (if not all) existing models follow the encoder-predictor paradigm where all studies focus on how to optimize the encoder module extensively in the paradigm but they ignore how to optimize the predictor module. In this paper, we discover the existing critical issue of the low-capability predictor module among existing models. Motivated by this, we propose a novel framework called \emph{\underline{S}ession-based \underline{R}ecommendation with \underline{Pred}ictor \underline{A}dd-\underline{O}n} (SR-PredictAO). In this framework, we propose a high-capability predictor module which could alleviate the effect of random user's behavior for prediction. It is worth mentioning that this framework could be applied to any existing models, which could give opportunities for further optimizing the framework. Extensive experiments on two real benchmark datasets for three state-of-the-art models show that \emph{SR-PredictAO} out-performs the current state-of-the-art model by up to 2.9\% in HR@20 and 2.3\% in MRR@20. More importantly, the improvement is consistent across almost all the existing models on all datasets, which could be regarded as a significant contribution in the field.